
- 1pytorch_pretrained_bert库报错: Model name ‘pretrained\chinese_L-12_H-768_A-12‘ was not found in model
- 2关于监控摄像头小程序直播使用流程及主要应用_雄迈摄像头如何在微信小程序使用
- 3面试题:Java虚拟机JVM的组成
- 4python+离散小波变换+不同系数的波形_librosa 小波
- 5XSS一-WEB攻防-XSS跨站&反射型&存储型&DOM型&标签闭合&输入输出&JS代码解析
- 6CentOS 安装Cursor --- Draft
- 7机器学习领域中各学派划分——符号主义、频率主义、贝叶斯主义、连接主义核心思想和理论_符号主义与连接主义的优势与缺陷分别是什么
- 8curl 通过代理服务器访问外网的接口_curl通过代理访问接口
- 9Nvidia Jetson AGX Xavier 安装 Swin-Transformer-Object-Detection_mmcv-full jetson
- 10SSE通信方式 使用流信息向浏览器推送信息_浏览器如何查看到sse返回的信息内容
深入浅出理解word2vec模型 (理论与源码分析)
赞
踩
深入浅出理解word2vec模型 (理论与源码分析)
文章源码下载地址:点我下载http://inf.zhihang.info/resources/pay/7692.html
对于算法工程师来说, Word2Vec 可以说是大家耳熟能详的一种词向量计算算法,Goole在2013年一开源该算法就引起了工业界与学术界的广泛关注。
一般来说,word2vec 是基于序列中隔得越近的word越相似的基础假设来训练的模型, 模型的损失函数也是基于该原理进行设计的。 最初word2vec是用来训练得到词向量,后面把它引申用于进行序列类(seq/list)数据中各个item ( 后面把word,node,item 等序列元素统称为 item ) 的embeding生成。
Google的论文以及广大算法工程师们已经从大量的实践中证明:两个item间的向量距离能够反映它们之间的关系(通常通过L2距离或余弦相似度得到), 并且两个item之间的语义关系计算可以用 他们的embeding 计算来代替。论文中提出的一个有意思的例子是:
Embedding(woman)=Embedding(man)+[Embedding(queen)-Embedding(king)]。
embeding 的这个特性为可量化和可计算的item关系打开了新世界的大门,具有非常重要的参考意义。
(1) Word2Vec基础
我们都知道,Word2Vec最初是作为语言模型提出的,实际是一种从大量文本语料中以无监督方式学习语义知识的浅层神经网络模型,包括Skip-Gram 和 Continuous Bag Of Words(简称CBOW)两种网络结构。
(1.1)Skip-Gram和CBOW 结构
Skip-Gram和CBOW都可以表示成由输入层(Input) 、映射层(Projection) 和 输出层(Output)组成的神经网络。其中 Skip-Gram 的目标是根据当前词来预测上下文中各词的生成概率,而 CBOW 的目标是根据上下文出现的词来预测当前词的生成概率。 网络结构图如下所示:
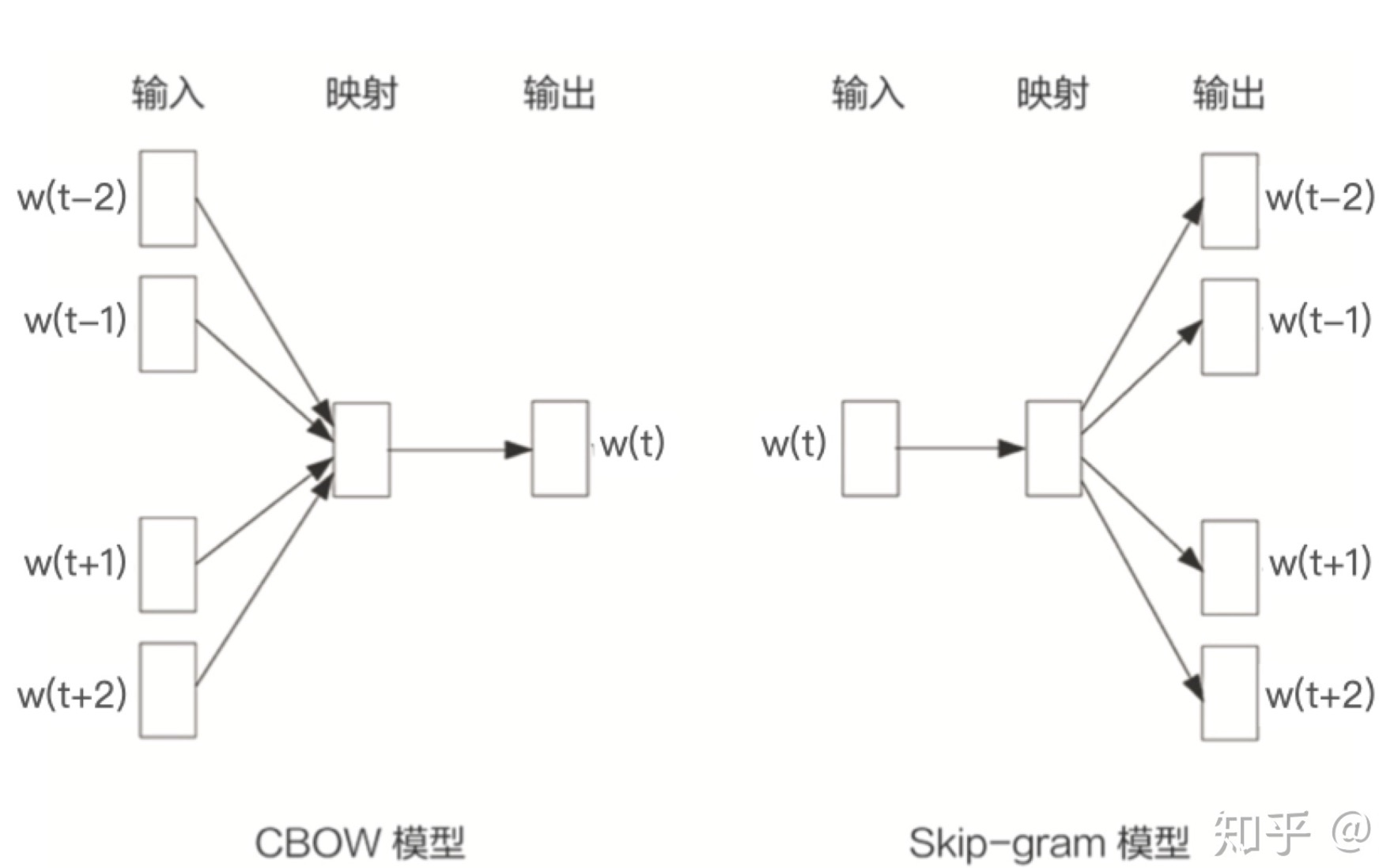
上图中,w(t) 为当前所关注的词,而w(t-2),w(t-1),w(t+1),w(t+2)为上下文出现的单词。这里前后滑动窗口的大小均设置为2。
输入与输出均是语料库数据自身,所以底层本质上Word2Vec是无监督模型。
输入层 每个词由独热编码方式表示,即所有词均表示成一个N维向量,其中N为词汇表中单词的总数。在向量中,每个词都将与之对应的维度置为1,其余维度均为0。
在 映射层(也称隐含层) 中,K个隐含单元的取值可以由N维输入向量以及隐含单元之间的N*K维权重矩阵计算得到。在CBOW中,还需要将各个输入词所计算出的隐含单元求和,这里是得到各个 输入词embeding 之后进行了sum pooling 操作(当然也可以选择别的pooling方式,如 Average), 得到一个K维隐藏向量。Skip-Gram 这里则是仅仅得到当前关注词的embeding, 无需pooling操作 。
同理,输出层 向量的值可以通过隐含层向量(K维)以及连接隐含层和输出层之间的KN维权重矩阵计算得到。输出层也是一个N维向量,每维与词汇表中的每个单词对应。这里,CBOW和 Skip-Gram 均是用一个 1K维的隐含层数据(embeding)和 KN 维度的数据计算得到 1*N 维度的logit值, 最后对输出层的 N维度向量(N维度logit值)应用SoftMax激活函数,可以计算出每个单词的生成概率。然后再和每个单词是0或1的标签计算损失。
(1.2) Skip-Gram和CBOW 优劣点分析
关于 Skip-Gram和 CBOW 模型的对比分析,知乎上的卡门同学分析的非常具有特色,具有很强的参考意义。
从上面图中,我们也可以看出:
Skip-Gram 是用中心词来预测周围的词,在skip-gram中,会利用周围的词的预测结果情况,使用GradientDecent来不断的调整中心词的词向量,最终所有的文本遍历完毕之后,也就得到了文本所有词的词向量。但是在skip-gram当中,每个词都要收到周围的词的影响,每个词在作为中心词的时候,都要进行K次的预测、调整。因此, 当数据量较少,或者词为生僻词出现次数较少时, 这种多次的调整会使得词向量相对的更加准确。
CBOW 是用上下文词预测中心词,从而得到中心词的预测结果情况,使用GradientDesent方法不断去优化调整周围词的向量。当训练完成之后,每个词都会作为中心词,把周围词的embeding进行了调整,这样也就获得了整个文本里所有词的词向量。 要注意的是, cbow的对周围词的调整是统一的:求出的gradient的值会同样的作用到每个周围词的词向量当中去。尽管cbow从另外一个角度来说,某个词也是会受到多次周围词的影响(多次将其包含在内的窗口移动),进行词向量的跳帧,但是他的调整是跟周围的词一起调整的,grad的值会平均分到该词上, 相当于该生僻词没有收到专门的训练,它只是沾了周围词的光而已。
因此,从更通俗的角度来说:
在Skip-Gram里面,每个词在作为中心词的时候,实际上是 1个学生 VS K个老师,K个老师(周围词)都会对学生(中心词)进行“专业”的训练,这样学生(中心词)的“能力”(向量结果)相对就会扎实(准确)一些,但是这样肯定会使用更长的时间。CBOW是 1个老师 VS K个学生,K个学生(周围词)都会从老师(中心词)那里学习知识,但是老师(中心词)是一视同仁的,教给大家的一样的知识。
所以,一般来说 CBOW比Skip-Gram训练速度快,训练过程更加稳定,原因是CBOW使用上下文的方式进行训练,每个训练step会见到更多样本。而在生僻字(出现频率低的字)处理上,skip-gram比CBOW效果更好,学习的词向量更细致,原因就如上面分析: CBOW 是公共课,Skip-gram 是私教 。
(2) Skip-Gram模型详解
书接上文, 在我们现实中的数据集中绝大部份的数据都是高维稀疏的数据集,大量的实践证明Skip-Gram确实效果更好,所以这里以 Skip-Gram为框架讲解Word2Vec模型的细节。
(2.1) 损失函数说明
如上文图中右边所示,Skip-Gram的学习任务是用中间的词与预测周围的词,训练得到词的embedding便可以用于下游任务。Skip-Gram 的形式化定义: 给定单词序列 W1, W2, W3 … Wt, 选取一个长度为2m+1(目标词前后各选取m个词)的滑动窗口,将滑动窗口从左到右华东区,每移动一次,窗口中的词组就形成了一个训练样本。
我们知道, 概率是用于已知模型参数,预测接下来观测到样本的结果; 而似然性用语已知某些观测所得到的结果,对有关事务的性质参数进行估计。
而在 Skip-Gram中每个词 Wt 都决定了相邻的词
Wt+j , 在观测序列已定的情况下,我们可以基于极大似然估计的方法,希望所有样本的条件概率 P( Wt+j / Wt ) 之积最大,这里使用对数概率。因此Skip-Gram的目标函数是最大化平均的对数概率,即:
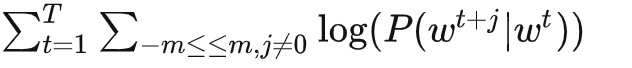
其中 m 是窗口大小,m越大则样本数越多,预测准确性越高,但同时训练时间也越长。当然我们还会在上述公司前面乘以 负 1/ T 以方便现有最优化方法的梯度优化。
作为一个多分类问题,Skip-Gram 定义概率 P( Wt+j / Wt ) 的最直接的方法是使用SoftMax函数。 假设我们用一个向量 Vw表示词w, 用词之间的内积距离VitVj表示两词语义的接近程度。则条件概率 P( Wt+j / Wt ) 可以用下式给出:
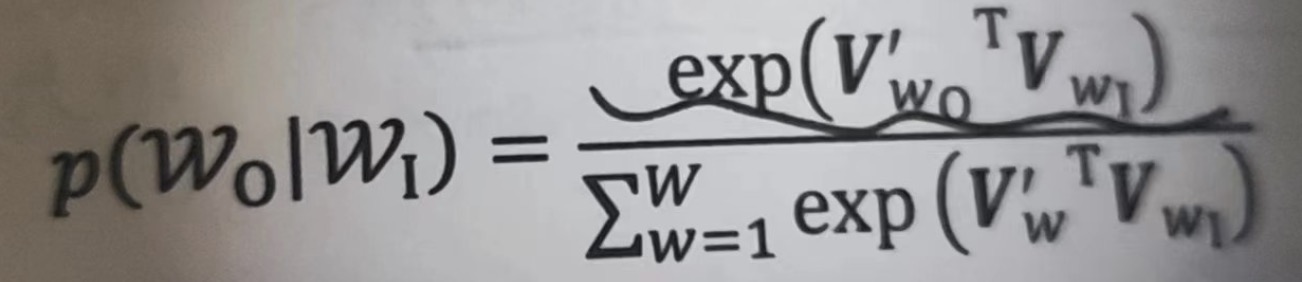
其中,Wo代表Wt+j , 被称为输出词; Wi 代表 Wt, 被称为输入词。 注意在上面的公式中,Wo和Wi 并不在一个向量空间内,Vwo 和Vwi 分别是词W的输出向量表达和输入向量表达。
在上文里我们曾经说过,从输入层到映射层的维度为 N * K,而从映射层到输出层的维度为 K * N。 这也就是说每个单词均有两套向量表达方式。实践证明:每个单词用两套向量表达的方式通常效果比单套向量表达方式的效果好,因为两套向量表达的方式应用到下游任务时可以去取两个embeding的平均值。
(2.2) 训练过程优化
需要注意,我们上面说的输入层和输出层的维度 N 是词表中单词的总数,在现实中通常都非常大,千万甚至上亿的量级都是非常常见。但事实上,完全遵循原始的Word2Vec多分类结构的训练方法并不可行。
假设语料库中词的数量为1KW,则意味着输出层神经元有1KW个,在每次迭代更新到隐藏层神经元的权重时,都需要计算所有字典中1KW个词的预测误差,这在实际计算 的时候是不切实际的。
Word2vec 提出了2种方法解决该问题,一种是层次化的 Hierarchical Softmax, 另一种是
负采样(Negative Sampling) 。
层次softmax 基本思想是将复杂的归一化概率分解为一系列条件概率乘积的形式,每一层条件概率对应一个二分类问题,通过逻辑回归函数可以去拟合。对v个词的概率归一化问题就转化成了对logv个词的概率拟合问题。Hierarchical softmax通过构造一棵二叉树将目标概率的计算复杂度从最初的V降低到了logV的量级。但是却增加了词与词之间的耦合性。比如一个word出现的条件概率的变化会影响到其路径上所有非叶子节点的概率变化。间接地对其他word出现的条件概率带来影响, 同时层次softmax 也因为实现比较困难,效率较低且并没有比负采样更好的效果,所以在现实中使用的并不多。
这里我们主要说明 负采样 (Negative Sampling ) 的方式。相比于原来需要计算所有字典中所有词的预测误差,负采样的方法只需要对采样出的几个负样本计算预测误差。再次情况下,word2vec 模型的优化目标从一个多分类问题退化成了一个近似二分类问题。
其优化目标定义为:
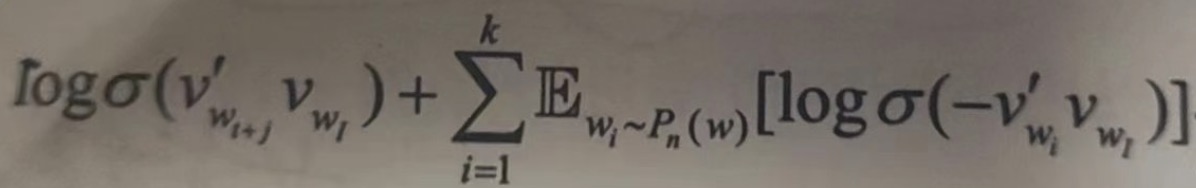
其中,Pn(w) 是噪声分布,采样生成k个负样本,任务变成从噪声中区分出目标单词 Wo, 整体的计算量与K成线性关系,K在经验上去2~20即可,远小于 Hierarchical Softmax 所需要的 log(W) 词计算。
Pn(w) 的经验取值是一元分布的四分之三次方,效果远超简单的一元分布或均匀分布。
(3) 实践经验
类似于 Word2Vec根据单词序列数据训练Embedding,我们也可以把用户行为点击过的item序列数据 喂给Word2Vec 算法,训练得到item 的Embeding , 这种方式也称为 item2Vec 。
(3.1) 灵活构建序列
在使用Word2Vec学习的过程中,喂入模型的item序列的构建是非常重要的,我们可以在item ID序列中加入item的类目等属性信息来构建序列。我们构建的序列并不一定紧紧只有一个类别的数据,例如这个序列也可以是: userid, ip,sn, email , 但是在某些情况下,为了更好的建模用户和各个属性的关系,我们可以构建这样的序列: userid, ip,userid,sn,userid,email。
构建序列的方法是非常灵活的,我们根据自己的理解和业务需要动态调整即可。
同样,在基于随机游走的 Graph Embeding 算法中,我们可以在同构图上使用深度游走( deepwalk ) 的方法,或则在异构图上使用元路径 (meta path) 的方法得到一些 item 的游走序列,然后把这些序列喂入 skip-gram 模型中, 也可以得到不错的效果。
(3.2) Airbnb的word2vec建模实践
这里要重点介绍下 Airbnb在2018年 发布在KDD 的最佳论文 Real-time Personalization using Embeddings for Search Ranking at Airbnb。
该论文中介绍了embedding在 Airbnb 爱彼迎房源搜索排序和实时个性化推荐中的实践。他们使用了 listing embeddings(房源嵌入)和 用户点击行为来学习用户的短期兴趣,用user-type & listing type embeddings和用户预定行为来学习用户的长期兴趣,并且这两种方法都成功上线,用于实时个性化生成推荐。
其论文中有很多值得参考的点,这里简单列举下:
(1) Airbnb 利用session内点击数据构建了序列建模用户的短期兴趣。
(2) 将预定房源引入目标函数,即不管这个被预定房源在不在word2vec的滑动窗口中都架设这个被预定房源与滑动窗口的中心房源相关,即相当于引入了一个全局上下文到目标函数中。
(3) 基于某些属性规则做相似用户和相似房源的聚合,用户和房源被定义在同一个向量空间中,用word2vec负采样的方法训练,可以同时得到用户和房源的Embedding,二者之间的Cos相似度代表了用户对某些房源的长期兴趣偏好。
(4) 把搜索词和房源置于同一向量空间进行Embeding。
(5) 与中心房源同一市场的房源集合中进行随机采样作为负样本,可以更好发现同一市场内部房源的差异性。
才开始作者在看论文的时候想自己去复现一下论文,结果发现网络上也搜不到论文中介绍的如何自定义损失函数的方法,知乎上联系Airbnb的官方账号也没有收到回复,悲催。
(3.3) 一种可行的实践
最后,作者经过苦苦摸索,终于找到了自己的解决方法,下面进行简单的介绍:
首先要想清楚的一个点是:我们喂入模型中的序列其实就是我们训练Word2Vec模型的样本。观察上面的损失函数公式我们发觉,损失函数其实就是基于我们开篇所介绍的假设:序列中隔得越近的word越相似 。 然后,我们用设计好的相应的数据去训练模型,是不是意味着我们就修改了模型的训练目标呢。
例如:上面第5点,论文中介绍说,在目标函数中引入了同一地区的负样本集合加入到损失函数,那我们在构建样本pair的时候,是不是可以让负样本的选择符合论文中说的方式,然后构建成 (pos sample, same place neg sample, -1 ) 这样的形式的样本添加到原来的样本集中呢。
这里我想说明的一点就是:我们选择什么样的样本输入模型,就等价于在模型训练的损失函数中加入了什么类型的损失。明着看起来是添加负样本,没有修改模型,但是本质上就是修改了损失函数。
基于此,对于一切的序列数据,我们都可以选择Word2Vec(推荐Skip-Gram)进行序列item的embeding学习,只是我们要重点关注训练样本序列的构建,因为这涉及到我们模型最终的训练目标。
我不知道这一点我说清楚了没有,但是希望你能理解我大概要表示的意思,如有任何问题,欢迎联系我进行讨论哈 ~
(4)代码时刻
talk is cheap , show me the code !!!
下面的代码是使用tensorflow2.0,采用了tf.keras 中阶API来构建模型结构,其中包括了如何构建word2vec需要的pair数据,如何在一元表上完成负采样,如何导出word对应的embeding 以及如何提高模型的训练速度。本代码具有详细的注释以及实现的思路说明,具有极高的参考价值与可重用性,有问题欢迎讨论~
该工程完整代码,可以去 算法全栈之路 公众号回复 word2vec源码 下载。
@ 欢迎关注作者公众号 算法全栈之路
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from tensorflow.python.ops import array_ops
from tensorflow.python.util import nest
import tensorflow as tf
from tensorflow.keras.layers import *
from tensorflow.keras.models import Model
from tensorflow.keras.optimizers import Adam
import tensorflow.keras.backend as backend
from tensorflow.python.ops import control_flow_ops
from collections import defaultdict
import numpy as np
import tqdm
import math
import random
class SaveEmbPerEpoch(tf.keras.callbacks.Callback):
def set_emb(self, emb, vocab, inverse_vocab, word_embedding_file):
self.word_embedding_file = word_embedding_file
self.words_embedding_in = emb
self.vocabulary = vocab
self.inverse_vocab = inverse_vocab
def on_epoch_end(self, epoch, logs=None):
with open(self.word_embedding_file + '.{}'.format(epoch), 'w') as f:
weights = self.words_embedding_in.get_weights()[0]
for i in range(len(self.vocabulary)):
emb = weights[i, :]
line = '{} {}\n'.format(
self.inverse_vocab[i],
' '.join([str(x) for x in emb])
)
f.write(line)
# wget http://mattmahoney.net/dc/text8.zip -O text8.gz
# gzip -d text8.gz -f
train_file = './train.txt'
class Word2Vec(object):
def __init__(self, train_file, sample=1e-4, embedding_dim=200):
# 训练文件
self.train_file = train_file
# 最大句子长度
self.MAX_SENTENCE_LENGTH = 1024
# 过滤掉词语频率低于count 的词语在count中
self.min_count = 5
# 子采样权重
self.subsampling_power = 0.75
# 采样率
self.sample = sample
# 根据训练数据产生的词典 word freq 字典保存起来
self.save_vocab = './vocab.txt'
# 窗口大熊啊
self.window = 5
# 每个中心词,选择一个上下文词构建一个正样本,就随机采样选择几个负样本.
self.negative = 5
# 从源码中还是从论文中的构建样本方式 源码[context_word, word] or 论文[word, context_word]
self.skip_gram_by_src = True
# 维度
self.embedding_dim = embedding_dim
# 保存embeding 的文件
self.word_embedding_file = 'word_embedding.txt'
self.tfrecord_file = 'word_pairs.tfrecord'
self.train_file = "./train.txt"
self.vocabulary = None
self.next_random = 1
# 词表最大尺寸,一元模型表大小
self.table_size = 10 ** 8
self.batch_size = 256
self.epochs = 1
# 是否生成tf_redocd数据参与训练
self.gen_tfrecord = True
# build vocabulary
print('build vocabulary ...')
self.build_vocabulary()
# build dataset
print('transfer data to tfrecord ...')
# 是否生成 tf_record格式的数据
if self.gen_tfrecord:
self.data_to_tfrecord()
# 使用from_generator,速度非常慢,遍历100个句子需要50s
# self.dataset = tf.data.Dataset.from_generator(
# self.train_data_generator,
# output_types=(tf.int32, tf.int32),
# output_shapes=((2,), (),)
# ).batch(self.batch_size).prefetch(1)
print('parse tfrecord data to dataset ...')
# 使用tfrecord后,100个句子需要6s
self.dataset = self.make_dataset()
# build model
print('build model ...')
self.build_model()
# 构建训练数据集合,也就是解析tfrecord数据
def make_dataset(self):
# 解析单个样本
def parse_tfrecord(record):
features = tf.io.parse_single_example(
record,
features={
'pair': tf.io.FixedLenFeature([2], tf.int64),
'label': tf.io.FixedLenFeature([1], tf.float32)
})
label = features['label']
pair = features['pair']
return pair, label
# 读入tfrecord file
dataset = tf.data.TFRecordDataset(self.tfrecord_file) \
.map(parse_tfrecord, num_parallel_calls=8) \
.batch(self.batch_size).prefetch(self.batch_size)
return dataset
# 输入 word ,采样率
# 构建一元模型表,进行高效的负采样
# 概率大小和数组宽度保持了一致性,在数组上随机采样,就是按照概率分层抽样
def build_unigram_table(self, word_prob):
# 构建unigram 表,一元表
self.table = [0] * self.table_size
word_index = 1
# 用当前词语index的采样概率当前词语的长度
# 初始化当前长度
cur_length = word_prob[word_index]
for a in range(len(self.table)):
# 对表中每一个元素,找到该下表对应词语的index,也就是该词语
# 每个词语对应一个下标,不满足下面那个判断条件的时候,当前下标放的元素依然是word_index
self.table[a] = word_index
# 当满足这个条件的时候,就需要进一步更新下标对应的值了。
# 保持下标占比a 和概率占比cur_length处于一致的空间,不一致的时候就修改放的元素。
# 占比比较
if a / len(self.table) > cur_length:
# 下一位放word_index+1
word_index += 1
# cur_len 构建了累计分布函数
cur_length += word_prob[word_index]
# Misra-Gries算法
# 使用Misra-Gries算法,当词汇字典的大小到达极限值时,访问词典的每一个key,将其value值的大小-1,
# 当某个key的value为0时将其移除字典,直到能够加入新的key.
if word_index >= len(self.vocabulary):
word_index -= 1
def build_vocabulary(self):
# 构建词频字典
word_freqs = defaultdict(int)
# 循环读取训练数据,得到某一行的各个单词
for tokens in self.data_gen():
# tokens 里得到某一行的各个单词
for token in tokens:
word_freqs[token] += 1
# 低频过滤
word_freqs = {word: freq for word, freq in word_freqs.items() \
if freq >= self.min_count}
# 按照词语频率降序构建字典 {word :index },index 从1开始
self.vocabulary = {word: index + 1 for (index, (word, freq)) in enumerate(
sorted(word_freqs.items(), key=lambda x: x[1], reverse=True))}
# index 0 特殊处理
self.vocabulary['</s>'] = 0
# 倒排表 index,word
self.inverse_vocab = {index: token for token, index in self.vocabulary.items()}
# save vocab
with open(self.save_vocab, 'w') as f:
for i in range(len(self.vocabulary)):
word = self.inverse_vocab[i]
if i > 0:
freq = word_freqs[word]
else:
freq = 0
f.write(f"{word} {freq}\n")
# 负采样的采样概率,f(w)^(3/4)/Z
# 采样率计算的分母, 归一化求和,频率分布的 3/4
train_words_ns = sum([freq ** (self.subsampling_power) for freq in word_freqs.values()])
# 得到每一个单词index对应的采样频率
self.ns_word_prob = {self.vocabulary[word]: (freq ** self.subsampling_power) / train_words_ns for word, freq in
word_freqs.items()}
# 构建一元模型,在上面随机采样就可以做到word分布上的分层抽样
self.build_unigram_table(self.ns_word_prob)
# self.unigrams_prob = [0]
# for i in range(1, len(self.vocabulary)):
# # print(inverse_vocab[i])
# self.unigrams_prob.append(self.ns_word_prob[i])
# (sqrt(vocab[word].cn / (sample * train_words)) + 1) * (sample * train_words) / vocab[word].cn;
# subsampling
# 如果采样率大于0
if self.sample > 0:
# 所有频率的和
train_words = sum([freq for freq in word_freqs.values()])
# 根据每个词语的频率得到drop ratio
self.subsampling_drop_ratio = {
word: (math.sqrt(freq / (self.sample * train_words)) + 1) * (self.sample * train_words) / freq \
for word, freq in word_freqs.items()
}
# 构建 word2vec 模型
def build_model(self):
vocab_size = len(self.vocabulary)
# embedding_dim = 100
inputs = Input(shape=(2,))
target = inputs[:, 0:1]
context = inputs[:, 1:2]
self.words_embedding_in = tf.keras.layers.Embedding(
vocab_size,
self.embedding_dim,
input_length=1,
name="word_embedding_in"
)
self.words_embedding_out = tf.keras.layers.Embedding(
vocab_size,
self.embedding_dim,
input_length=1,
name="word_embedding_out"
)
word_emb = self.words_embedding_in(target) # batch_size,1,embeing_size
context_emb = self.words_embedding_out(context)
dots = tf.keras.layers.Dot(axes=(2, 2))([word_emb, context_emb])
outputs = tf.keras.layers.Flatten()(dots)
self.model = Model(inputs, outputs)
self.model.compile(
optimizer='adam',
# loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
# loss=tf.keras.losses.binary_crossentropy(from_logits=True),
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
# 模型训练
def train(self):
# tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
my_callback = SaveEmbPerEpoch()
my_callback.set_emb(self.words_embedding_in,
self.vocabulary,
self.inverse_vocab,
self.word_embedding_file)
self.model.fit(word2vec.dataset, epochs=self.epochs, callbacks=[my_callback])
def save_word_embeddings(self):
with open(self.word_embedding_file, 'w') as f:
f.write('{} {}\n'.format(len(self.vocabulary), self.embedding_dim))
weights = self.words_embedding_in.get_weights()[0]
for i in range(len(self.vocabulary)):
emb = weights[i, :]
line = '{} {}\n'.format(
self.inverse_vocab[i],
','.join([str(x) for x in emb])
)
f.write(line)
def data_to_tfrecord(self):
# 写入到 tf_record file
with tf.io.TFRecordWriter(self.tfrecord_file) as writer:
# 得到进度条
for item in tqdm.tqdm(self.train_data_gen()):
# list [context_word,word], 1.0/0.0
# [word, context_word]
pair, label = item
feature = {
'pair': tf.train.Feature(int64_list=tf.train.Int64List(value=pair)),
'label': tf.train.Feature(float_list=tf.train.FloatList(value=[label]))
}
example = tf.train.Example(features=tf.train.Features(feature=feature))
writer.write(example.SerializeToString())
# 生成训练数据,生成完成之后传入下一个方法生成tf_record 数据
def train_data_gen(self):
cnt = 0
sample_list = []
# 得到上面采样过的所有的多行训练的单词 token_index
for tokens_index in self.tokens_gen():
# print(len(tokens_index), cnt)
# 当前行的token 列表
for i in range(len(tokens_index)):
# print('cnt={}, i={}'.format(cnt, i))
# 总共已经处理多少个单词了
cnt += 1
# 当前序列已经处理了当前第 i 个了。
# 当前单词的 index, 中心词
word = tokens_index[i]
# 生成一个窗口大小之内的随机数
b = random.randint(0, self.window - 1)
# 中心词前取几个,后取几个的分界线
window_t = self.window - b
# c为上下文坐标
# context_ = [tokens_index[c] for c in range(i - window_t, i + window_t + 1) \
# if c >=0 and c <=len(tokens_index) and c != i]
# print('window_t = {}, contexts words={}'.format(window_t, context_))
# 中心词为i ,i前取 i - window_t个,i 后取 i + window_t + 1个。
for c in range(i - window_t, i + window_t + 1):
# 越界的和中心词跳过。
if c < 0 or c >= len(tokens_index) or c == i:
continue
# 当前列表中的当前中心词的上下文
#
context_word = tokens_index[c]
# print('c={}, context_word={}'.format(c, context_word))
# 构造副样本
# 采用np.random.choice的方法,10句话要5分钟。
# 采用tf.random.fixed_unigram_candidate_sampler,10句话要7分钟。
# 所以最后还得用hash的方法搞。10句话基本不需要时间
# 但是改成dataset后,仍然需要5s
# neg_indexs = [np.random.choice(
# list(self.ns_word_prob.keys()),
# p=list(self.ns_word_prob.values())) for _ in range(self.negative)]
#
# 做self.negative 次负采样
# 每个中心词,选择一个上下文词构建一个正样本,就随机采样选择几个负样本.
neg_indexs = [self.table[random.randint(0, len(self.table) - 1)] \
for _ in range(self.negative)]
# 调用当前函数就返回一个迭代值,下次迭代时,代码从 yield 当前的下一条语句继续执行,
# 而函数的本地变量看起来和上次中断执行前是完全一样的,于是函数继续执行,直到再次遇到 yield。
if self.skip_gram_by_src:
# 从源码中还是从论文中的构建样本方式 源码[context_word, word] or 论文[word, context_word]
# 返回正样本
sample_list.append(([context_word, word], 1.0))
# 遍历负采样样本
for negative_word in neg_indexs:
# 如果负采样的词不等于当前词
if negative_word != word:
# 返回一组负样本,替换掉中心词语
sample_list.append(([context_word, negative_word], 0.0))
else:
# 和上面的唯一性区别就是
sample_list.append(([context_word, word], 1.0))
for negative_word in neg_indexs:
if negative_word != word:
sample_list.append(([context_word, negative_word], 0.0))
return sample_list
# 返回 token_index list ,训练的单词
def tokens_gen(self):
cnt = 0
lines_tokens_list = []
all_tokens_count = 0
# 读入原始训练数据,得到所有行的数据
for tokens in self.data_gen():
# 当前行
tokens_index = []
for token in tokens:
if token not in self.vocabulary:
continue
if self.sample > 0:
# 如果需要进行采样
# 得到word,drop_ratio概率,大于这个概率就丢弃
if np.random.uniform(0, 1) > self.subsampling_drop_ratio[token]:
# if self.subsampling_drop_ratio[token] < self.w2v_random():
continue
# 添加该训练词语的索引
tokens_index.append(self.vocabulary[token])
all_tokens_count += 1
# if cnt == 10:
# return None
cnt += 1
lines_tokens_list.append(tokens_index)
print("lines_tokens_list line len :" + str(cnt))
print("lines_tokens_list all tokens :" + str(all_tokens_count))
return lines_tokens_list
def data_generator_from_memery(self):
data = open(train_file).readlines()[0].split(' ')
cur_tokens = []
index = 0
while index + 100 < len(data):
yield data[index: index + 100]
index += 100
yield data[index:]
# for i in range(len(data)):
# cur_tokens.append(data[i])
# if i % 100 == 0:
# yield cur_tokens
# cur_tokens = []
# 数据生成方法
def data_gen(self):
raw_data_list = []
prev = ''
# 读取训练数据文件
with open(train_file) as f:
# 死循环去读
while True:
# 单词读取最大句子长度
buffer = f.read(self.MAX_SENTENCE_LENGTH)
if not buffer:
break
# print('|{}|'.format(buffer))
# 把句子分割成各行
lines = (prev + buffer).split('\n')
# print(len(lines))
for idx, line in enumerate(lines):
# 处理当前行
# 分成一个个词
tokens = line.split(' ')
if idx == len(lines) - 1:
# 最后一行
cur_tokens = [x for x in tokens[:-1] if x]
# 把当前 MAX_SENTENCE_LENGTH 最后一个词保存起来, 和下一次读取的时候进行拼接
prev = tokens[-1]
else:
# 返回当前行的各个词语
cur_tokens = [x for x in tokens if x]
raw_data_list.append(cur_tokens)
print("raw_data_list length:" + str(len(raw_data_list)))
return raw_data_list
if __name__ == "__main__":
print(tf.__version__)
word2vec = Word2Vec(train_file, sample=1e-4)
word2vec.train()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
到这里,深入浅出理解word2vec模型理论与源码分析就完成了,欢迎留言交流 ~
码字不易,觉得有收获就点赞、分享、再看三连吧~
算法全栈之路

