
- 1如何在Linux CentOS部署宝塔面板并实现固定公网地址访问内网宝塔_centos 7 安装宝塔
- 2Github 3k+ stars 南科大 VIP Lab 近期开源 Track-Anything | SAM + VOS: 一键视频标注_track anything算法
- 3基于C++的RRT代码学习_rrt算法c++代码
- 4docker访问外部数据库_从docker容器连接到远程MySQL数据库
- 5mysql网络投票系统设计_PHP+MySQL投票系统的设计和实现分享
- 6Ubuntu22.04 部署项目常用知识
- 7使用ESP8266(基于官方SDK)接入阿里云物联网平台_阿里云物联网json和alinkjson
- 8使用 MongoDB Atlas 无服务器实例更高效地开发应用程序_小程序使用mongodb atlas来进行部署
- 9Error running graph component for node train_RulePolicy2.ActionNotFoundException: Cannot access act_error running graph component for node train_dietc
- 10程序员+本硕博——一站式导航——收集+转载+讲解_程序员导航 - 程序员一站式导航
1、JAVA基础_java中怎么判断list集合第二条对象某个字段的大于第一条
赞
踩
接口和抽象类
- abstract 抽象类
- extends实现继承
- 用super调用父类的方法
- interface 接口
- 可以通过implements关键字实现接口
- 一个类实现了某个接口后必须实现该接口中定义的所有方法
- 与继承不同,一个类可以实现多个接口,该类需要实现这些接口中定义的所有方法
- 接口和接口之间可以存在继承关系
- 允许接口中出现非抽象方法,但需要default(默认)关键字修饰
- 接口的静态方法必须用接口名本身调用
匿名内部类
new 类|抽象类名|或者接口名() {
重写方法;
};
- 匿名内部类是一个没有名字的内部类
- 匿名内部类写出来就会产生一个匿名内部类的对象
- 匿名内部类的对象类型相当于是当前new的那个类的类型的子类类型
- 匿名内部类的代码可以实现代码进一步的简化(回扣主题)
API
- currentTimeMillis 返回当前系统的时间毫秒值形式
- arraycopy (数据源数组, 起始索引, 目的地数组, 起始索引, 拷贝个数) 数组拷贝
- BigDecimal可以用于解决浮点型运算精度失真的问题
| 方法名 | 说明 |
|---|---|
| public BigDecimal add(BigDecimal b) | 加法 |
| public BigDecimal subtract(BigDecimal b) | 减法 |
| public BigDecimal multiply(BigDecimal b) | 乘法 |
| public BigDecimal divide(BigDecimal b) | 除法 |
| public BigDecimal divide (另一个BigDecimal对象,精确几位,舍入模式) | 除法 |
- Objects的常见方法:
| 方法名 | 说明 |
|---|---|
| public static boolean equals(Object a, Object b) | 比较两个对象的,底层会先进行非空判断,从而可以避免空指针异常。再进行equals比较 |
| public static boolean isNull(Object obj) | 判断变量是否为null ,为null返回true ,反之 |
使用时 Object.equals()
- String
String是不可变字符串的原因?
每次的修改其实都是产生并指向了新的字符串对象String变量,原来的字符串对象都是没有改变的。
- 1
- 2
字符串常量池:当使用双引号创建字符串对象的时候,系统会检查该字符串是否在字符串常量池中存在
n不存在:创建新字符串对象。
n存在:不会重新创建,而是直接复用同一个字符串对象。
- 1
- 2
- 3
- 字符串的内容比较:推荐使用“equals”比较
| 方法名 | 说明 |
|---|---|
| public boolean equals (Object anObject) | 将此字符串与指定对象进行比较。只关心字符内容是否一致! |
| public boolean equalsIgnoreCase (String anotherString) | 将此字符串与指定对象进行比较,忽略大小写比较字符串。只关心字符内容是否一致! |
- String常用API遍历
| 方法名 | 说明 |
|---|---|
| public int length() | 返回此字符串的长度 |
| public char charAt(int index) | 获取某个索引位置处的字符 |
| public char[] toCharArray( ): | 将当前字符串拆分为字符数组并返回 |
- String常用API-截取
| 方法名 | 说明 |
|---|---|
| public String substring(int beginIndex, int endIndex) | 根据开始和结束索引进行截取,得到新的字符串(包前不包后) |
| public String substring(int beginIndex) | 从传入的索引处截取,截取到末尾,得到新的字符串 |
- String常用API-分割、替换
| 方法名 | 说明 |
|---|---|
| public String replace(CharSequence target, CharSequence replacement) | 使用新值,将字符串中的旧值替换,得到新的字符串 |
| public String[] split(String regex) | 根据传入的规则切割字符串,得到字符串数组 |
Arrays.toString() 用于输出数组
- StringBuilder概述
StringBuilder/StringBuffer是一个可变的字符串类,我们可以把它看成是一个容器
| 方法名称 | 说明 |
|---|---|
| public StringBuilder append(任意类型) | 添加数据并返回StringBuilder对象本身 |
| public StringBuilder reverse() | 将对象的内容反转 |
| public int length() | 返回对象内容长度 |
| public String toString() | 通过toString()就可以实现把StringBuilder转换为String |
- 定义字符串使用String
- 拼接、修改等操作字符串使用StringBuilder
- SimpleDateFormat 类作用
- SimpleDateFormat 可以对Date对象或者时间毫秒值格式化成我们喜欢的时间形式
- SimpleDateFormat也可以把字符串的时间形式解析成日期对象。
- 格式化(从 Date 到 String )
public final String format(Date date):将日期格式化成日期/时间字符串
public final String format(Object time):将时间毫秒值式化成日期/时间字符串
- 解析(从 String 到 Date )
public Date parse(String source):从给定字符串的开始解析文本以生成日期
Data中getTime()转换为毫秒显示
-
Calendar概述
Calendar代表了系统此刻日期对应的日历对象
| 方法名 | 说明 |
|---|---|
| public static Calendar getInstance() | 获取当前日历对象 |
| 方法名 | 说明 |
|---|---|
| public int get(int field) | 取日期中的某个字段信息。 |
| public void set(int field,int value) | 修改日历的某个字段信息。 |
| public void add(int field,int amount) | 为某个字段增加/减少指定的值 |
| public final Date getTime() | 拿到此刻日期对象。 |
| public long getTimeInMillis() | 拿到此刻时间毫秒值 |
- Arrays类的常用API
| 方法名 | 说明 |
|---|---|
| public static [String] toString(类型[] a) | 对数组进行排序 |
| public static void sort(类型[] a) | 对数组进行默认升序排序 |
| public static void sort(类型[] a, [Comparator]<? super T> c) | 使用比较器对象自定义排序 |
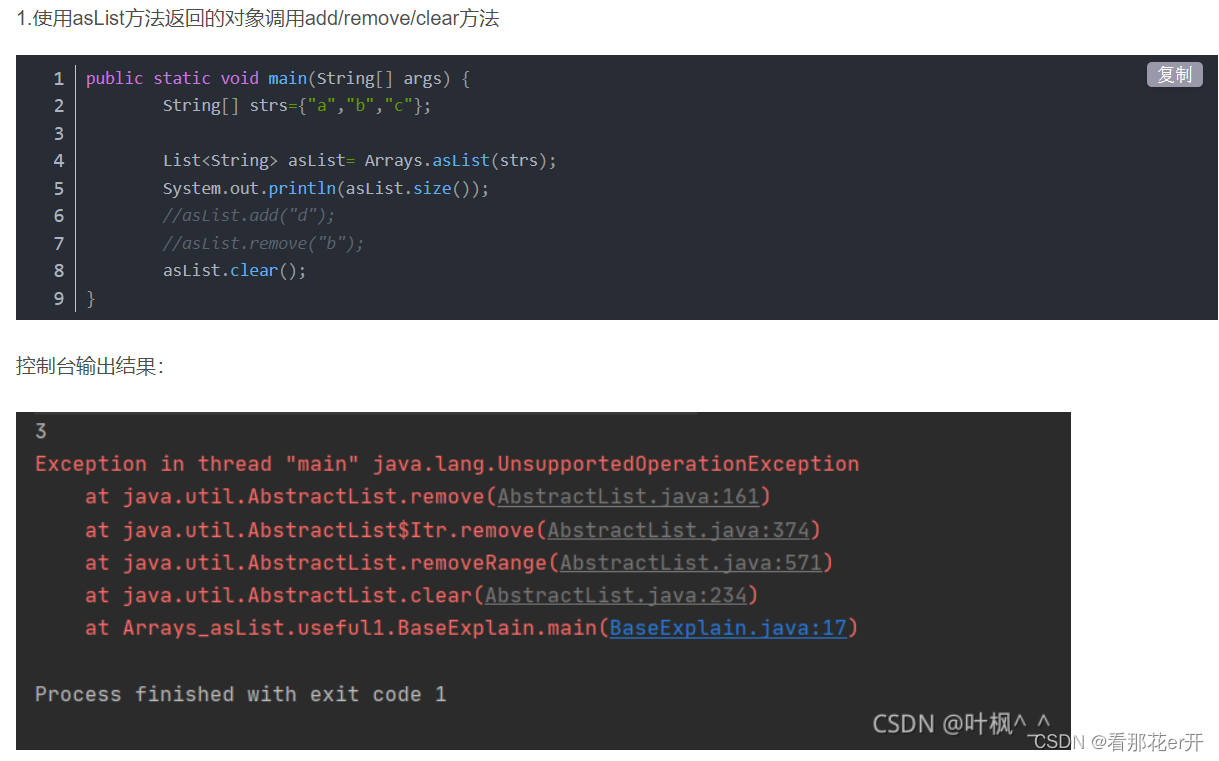
| asList | 将数组或一些元素转为集合 |
asList方法返回值得到的集合并不是我们通常使用的List集合,asList()方法把数组转换成集合时,不能使用其修改集合相关的方法,如果使用修改集合相关的方法add/remove/clear方法会抛出java.lang.UnsupportedOperationException的异常。
- Lambda表达式的简化格式
注意:Lambda表达式只能简化函数式接口的匿名内部类的写法形式
函数式接口是只有一个方法 @FunactionInterface是函数式方法的标志
集合
- collection集合存储元素的类型特点 collection是个接口
- 集合又可以理解成对象集合,集合中只能存储引用类型的数据。
- 默认集合是存储任意对象的,可以使用泛型约束集合编译阶段只能操作某种数据类型。
- 集合要存储基本数据类型要用到包装类
基本数据类型和其对应对象之间的转换变得很方便,想把基本数据类型存入集合中,直接存就可以了,系统会自动将其装箱成封装类,然后加入集合当中 集合和泛型都只支持引用数据类型
- Collection集合常用API
| 方法名称 | 说明 |
|---|---|
| public boolean add(E e) | 把给定的对象添加到当前集合中 |
| public void clear() | 清空集合中所有的元素 |
| public boolean remove(E e) | 把给定的对象在当前集合中删除 |
| public boolean contains(Object obj) | 判断当前集合中是否包含给定的对象 |
| public boolean isEmpty() | 判断当前集合是否为空 |
| public int size() | 返回集合中元素的个数。 |
| public Object[] toArray() | 把集合中的元素,存储到数组中 |
List系列集合:有序,可重复,有索引
ArrayList底层是基于数组实现的,根据查询元素快,增删相对慢
LinkedList底层基于双链表实现的,查询元素慢,增删首尾元素是非常快的
- LinkedList可以有栈和队列两种情况
- 栈:先进后出、后进先出 push(addFirst)/pop(removeFirst)
- 队列:先进先出、后进后出 addLast/removeLast
如果查询多增删少就用ArrayList 如果查询少增删首尾多就用LinkedList
- Collection集合遍历方式
- Iterator迭代器 ||只适用于集合 边遍历边删除,不知道元素的索引位置
- foreach/增强for循环 适合只是为了遍历的集合
- for循环 知道索引的位置
- lambda表达式
| 方法名称 | 说明 |
|---|---|
| boolean hasNext() | 询问当前位置是否有元素存在,存在返回true ,不存在返回false |
| E next() | 获取当前位置的元素,并同时将迭代器对象移向下一个位置,注意防止取出越界。 |
for(元素数据类型 变量名 : 数组或者Collection集合) {
//在此处使用变量即可,该变量就是元素
}
//forEach进行遍历
for(Object aa : c){
System.out.println(aa);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
| 方法名称 | 说明 |
|---|---|
| default void forEach(Consumer<? super T> action): | 结合lambda遍历集合 |
apples.forEach(a -> System.out.println(a));
- 1
集合存储自定义类型存的是对象的地址
需要删除集合中某个特定的元素的时候边遍历边删除会直接报错 应该使用迭代器自身的删除方法it.remove() 或者使用for循环倒着删除
泛型
valueOf将输入的字符串进行转换
- 1
通配符:?
-
? 可以在“使用泛型”的时候代表一切类型。
-
E T K V 是在定义泛型的时候使用的。
泛型的上下限:
-
?extends Car: ?必须是Car或者其子类 泛型上限
-
? super Car : ?必须是Car或者其父类 泛型下限数据结构
- 各种数据结构的特点和作用是什么样的
- 队列:先进先出,后进后出。
- 栈:后进先出,先进后出。
- 数组:内存连续区域,查询快,增删慢。
- 链表:元素是游离的,查询慢,首尾操作极快。
- 二叉树:永远只有一个根节点, 每个结点不超过2个子节点的树。
- 查找二叉树:小的左边,大的右边,但是可能树很高,查询性能变差。
- 平衡查找二叉树:让树的高度差不大于1,增删改查都提高了。
- 红黑树(就是基于红黑规则实现了自平衡的排序二叉树)
Set集合
- HashSet(基于哈希表) : 无序、不重复、无索引
创建一个默认长度16的数组,数组名table,根据元素的哈希值跟数组的长度求余计算出应存入的位置**(哈希算法)**
长度为8,再添加自动转成红黑树
在实现类中实现Set去重复要对hashCode()和equals()进行重写,自动生成即可
- LinkedHashSet(基于哈希表和双链表):有序、不重复、无索引
底层数据结构是依然哈希表,只是每个元素又额外的多了一个双链表的机制记录存储的顺序
- TreeSet(基于红黑树):排序、不重复、无索引
底层是基于红黑树的数据结构实现排序的,增删改查性能都较好
TreeSet集合是一定要排序的,可以将元素按照指定的规则进行排序
- 1
- 2
-
对于数值类型:Integer , Double,官方默认按照大小进行升序排序
-
对于字符串类型:默认按照首字符的编号升序排序 A65 a97 (1 的字节是 50)
-
对于自定义类型如Student对象,TreeSet无法直接排序
TreeSet集合存储对象的的时候有2种方式可以设计自定义比较规则
方式一:类实现Comparable接口,重写比较规则
让自定义的类(如学生类)实现(interface)Comparable接口重写里面的compareTo方法来定制比较规则。//实现Comparable接口 public class Apple implements Comparable<Apple> //重写comparTo方法 @Override public int compareTo(Apple o) { return this.weight - o.weight >=0 ? 1 : -1; }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
方式二:集合自定义Comparator比较器对象,重写比较规则
TreeSet集合有参数构造器,可以设置Comparator接口对应的比较器对象,来定制比较规则。//在定义Set集合的时候写比较器(优先级较高) Set<Apple> set = new TreeSet<>(( o1, o2) -> o2.getWeight() - o1.getWeight() >= 0 ? 1 : -1); Double.compare() //对Double类型的数据进行比较的方法- 1
- 2
- 3
- 4
两种方式中,关于返回值的规则:
-
如果认为第一个元素大于第二个元素返回正整数即可。
-
如果认为第一个元素小于第二个元素返回负整数即可。
-
如果认为第一个元素等于第二个元素返回0即可,此时Treeset集合只会保留一个元素,认为两者重复。
如果TreeSet集合存储的对象有实现比较规则,集合也自带比较器,默认使用集合自带的比较器排序
重写equals()方法和hashcode()方法 是为了去除两个相同的对象
例:想通过一个学生的学号以及姓名来判断是否是同一个学生。可是 根据程序的运行结果(打印出的为false)来看,即使是学号与姓名两个字段都完全的相同,判断出的学生也不是相同的。
所以通过重写quals()方法和hashcode()方法可以解决
可变参数
可变参数用在形参中可以接收多个数据。
可变参数的格式:数据类型…参数名称
//在参数类型后面加上三个点 ...
//可以接收多个数据并进行输出
public static void run(int...a){
System.out.println(Arrays.toString(a));
}
- 1
- 2
- 3
- 4
- 5
可变参数的注意事项:
1.一个形参列表中可变参数只能有一个
2.可变参数必须放在形参列表的最后面
Collections集合工具类
- Collections并不属于集合,是用来操作集合的工具类
| 方法名称 | 说明 |
|---|---|
| public static boolean addAll(Collection<? super T> c, T… elements) | 给集合对象批量添加元素 |
| public static void shuffle(List<?> list) | 打乱List集合元素的顺序 |
| public static List subList (int fromIndex , int toIndex) | 根据集合的索引,取集合中特定位置的元素 |
//addAll利用可变参数进行添加
List<Integer> name = new ArrayList<>();
Collections.addAll(name,78,25,12,98,10,26,55);
//添加对象要使用 new 对象类型 的形式进行添加
List<Apple> apples = new ArrayList<>();
Collections.addAll(apples, new Apple("紫","紫色",10.9,300), new Apple("蓝","蓝色",6.9,700));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
Collections排序相关API
- 使用范围:只能对于List集合的排序
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list) | 将集合中元素按照默认规则排序 |
本方式不可以直接对自定义类型的List集合排序,除非自定义类型实现了比较规则Comparable接口
| 方法名称 | 说明 |
|---|---|
| public static void sort(List list,Comparator<? super T> c) | 将集合中元素按照指定规则排序 |
//在sort方法中写比较器,自定义比较方法
Collections.sort(apples,(o1 , o2) -> o2.getWeight() - o1.getWeight() >= 0 ? 1 : -1);
//或者实现Comparable接口,重写comparTo方法
@Override
public int compareTo(Apple o) {
return this.weight - o.weight; //List的集合中存储相同大小的元素可以进行保留,所以不用进行比较
}
Double.compare() //对Double类型的数据进行比较的方法
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
Map集合
Map是接口
Map集合的每个元素的格式:key=value(键值对元素) Map集合非常适合做类购物车这样的业务场景
Map集合体系特点
- Map集合的特点都是由键决定的。
- Map集合的键是无序,不重复的,无索引的,值不做要求(可以重复)。
- Map集合后面重复的键对应的值会覆盖前面重复键的值。
- Map集合的键值对都可以为null。
Map的API
| 方法名称 | 说明 |
|---|---|
| V put(K key,V value) | 添加元素 |
| V remove(Object key) | 根据键删除键值对元素 |
| void clear() | 移除所有的键值对元素 |
| boolean containsKey(Object key) | 判断集合是否包含指定的键 |
| boolean containsValue(Object value) | 判断集合是否包含指定的值 |
| boolean isEmpty() | 判断集合是否为空 |
| int size() | 集合的长度,也就是集合中键值对的个数 |
| 方法名称 | 说明 |
|---|---|
| Set keySet() //定义的是set集合来接 | 获取所有键的集合 |
| Collection values() //定义Collcetion集合来接 | 获取所有值的集合 |
| V get(Object key) | 根据键获取值 |
| 方法名称 | 说明 |
|---|---|
| Map putAll (Map map) | 连接两个map集合 |
Map集合的遍历
-
先根据keySet()获取键,然后在用get来获取值 //分开取
//将map集合遍历 for (String key : map.keySet()){ System.out.println(key + map.get(key)); }- 1
- 2
- 3
- 4
-
键值对
把Map集合转换成Set集合,Set集合中每个元素都是键值对实体类型了。遍历Set集合,然后提取键以及提取值。
方法名称 说明 Set<Map.Entry<K,V>> xxx = map.entrySet() 获取所有键值对对象的集合 K getKey() 获得键 V getValue() 获取值 //键值对遍历 Set<Map.Entry<String,Integer>> set = map.entrySet(); for (Map.Entry<String,Integer> entry : set){ System.out.println(entry.getKey() + entry.getValue()); }- 1
- 2
- 3
- 4
- 5
- 6
-
forEach()进行遍历
//使用forEach()进行遍历 map.forEach((s , i) -> System.out.println(s + i));- 1
- 2
Map集合是根据键来去重复
实际上:Set系列集合的底层就是Map实现的,只是Set集合中的元素只要键数据,不要值数据而已。
HashMap的特点和底层原理
- 由键决定:无序、不重复、无索引。HashMap底层是哈希表结构的。
- 依赖hashCode方法和equals方法保证键的唯一。
- 如果键要存储的是自定义对象,需要**重写hashCode和equals方法**。
- 基于哈希表,增删改查的性能都较好。
LinkedHashMap
由键决定:有序、不重复、无索引。
这里的有序指的是保证存储和取出的元素顺序一致
原理:底层数据结构是依然哈希表,只是每个键值对元素又额外的多了一个双链表的机制记录存储的顺序
TreeMap
由键决定特性:不重复、无索引、可排序
可排序:按照键数据的大小默认升序(由小到大)排序。只能对键排序。
注意:TreeMap集合是一定要排序的,可以默认排序,也可以将键按照指定的规则进行排序
TreeMap跟TreeSet一样底层原理是一样的。
TreeMap的排序方式有两种,同上TreeSet排序
Stream流、算法、异常
创建不可变集合
不可变集合,就是集合中的元素不可被修改的
在List、Set、Map接口中,都存在of方法,可以创建一个不可变的集合(Set和Map集合不能里面的元素进行重复去除)
Stream流
目的**:用于解决已有集合/**数组类库既有的弊端。简化集合和数组操作的API
Stream流的三类方法
Stream流操作集合或者数组的第一步是先得到对应的Stream流,然后才能使用它的功能。
- 获取Stream流
创建一条流水线,并把数据放到流水线上准备进行操作
-
可以使用Collection接口中的默认方法stream()生成流
名称 说明 default Stream stream() 获取当前集合对象的Stream流 Stream<String> stream = list.stream();- 1
//Map获取Stream流 Map<String,Integer> map = new HashMap<>(); //获取map集合的key值 Stream<String> key = map.keySet().stream(); //获取map集合的value值 Stream<Integer> values = map.values().stream(); //获取键值对 Stream<Map.Entry<String,Integer>> entryStream = map.entrySet().stream();- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
-
数组获取Stream流的方式
| 名称 | 说明 |
|---|---|
| public static Stream stream(T[] array) | 获取当前数组的Stream流 |
| public static Stream of(T… values) | 获取当前数组/可变数据的Stream流 |
String[] arrays = {"Java","C++","C#"};
Stream<String> a = Arrays.stream(arrays);
Stream<String> b = Stream.of(arrays);
- 1
- 2
- 3
- 中间方法
流水线上的操作。一次操作完毕之后,还可以继续进行其他操作
| 名称 | 说明 |
|---|---|
| Stream filter(Predicate<? super T> predicate) | 用于对流中的数据进行过滤。 |
| Stream limit(long maxSize) | 获取前几个元素 |
| Stream skip(long n) | 跳过前几个元素 |
| Stream distinct() | 去除流中重复的元素。依赖(hashCode和equals方法) |
| static Stream concat(Stream a, Stream b) | 合并a和b两个流为一个流 |
| Stream map() | 加工方法,把原来的元素加工以后,重新放上去 |
| Stream findFirst() | 找到Stream流的第一个 |
中间方法也称为非终结方法,调用完成后返回新的Stream流可以继续使用,支持链式编程。
在Stream流中无法直接修改集合,数组等数据源中的数据
- 终结方法
一个Stream流只能有一个终结方法,是流水线上的最后一个操作
| 名称 | 说明 |
|---|---|
| void forEach(Consumer action) | 对此流的每个元素执行遍历操作 |
| long count() | 返回此流中的元素数 |
终结操作方法,调用完成后流就无法继续使用了,原因是不会返回Stream了
收集Stream流
就是把Stream流的操作后的结果数据转回到集合或者数组中去
| 名称 | 说明 |
|---|---|
| R collect(Collector collector) | 开始收集Stream流,指定收集器 |
Stream<String> stream = list.stream().filter(s -> s.startsWith("张")).filter(s -> s.length() == 2);
//将stream流输出
List<String> list2 = stream.collect(Collectors.toList());
- 1
- 2
- 3
数组是使用toArray()方法进行输出
工具类Collectors提供了具体的收集方式
| 名称 | 说明 |
|---|---|
| public static Collector toList() | 把元素收集到List集合中 |
| public static Collector toSet() | 把元素收集到Set集合中 |
| public static Collector toMap(Function keyMapper , Function valueMapper) | 把元素收集到Map集合中 |
Stream流是操作集合/数组的手段,操作的结果数据最终要恢复到集合或者数组中去
Stream流只能收集一次
异常
编译时异常:没有继承RuntimeExcpetion的异常,编译阶段就会出错。
运行时异常**:**继承自RuntimeException的异常或者其子类,编译阶段不报错。
异常处理方式1 —— throws
throws:用在方法上,可以将方法内部出现的异常抛出去给本方法的调用者处理
异常处理方式2 —— try…catch…
监视捕获异常,用在方法内部,可以将方法内部出现的异常直接捕获处理。
这种方式还可以,发生异常的方法自己独立完成异常的处理,程序可以继续往下执行。
try{
// 可能出现异常的代码!
}catch (Exception e){
e.printStackTrace(); // 直接打印异常栈信息
}
Exception可以捕获处理一切异常类型!
- 1
- 2
- 3
- 4
- 5
- 6
异常处理方式3 —— 前两者结合
方法直接将异通过throws抛出去给调用者
调用者收到异常后直接捕获处理。
throw : 用在方法里面创建异常对象并从此点抛出
throws :用在方法上排除方法内部的异常给方法的调用者
自定义异常
//编译时继承Exception,重写前两个方法
public class AynuException extends Exception{
public AynuException() { }
public AynuException(String message) {
super(message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
1、自定义编译时异常
定义一个异常类继承Exception.
重写构造器。
在出现异常的地方用throw new 自定义对象抛出,
作用:编译时异常是编译阶段就报错,提醒更加强烈,一定需要处理!!
2、自定义运行时异常
定义一个异常类继承RuntimeException.
重写构造器。
在出现异常的地方用throw new 自定义对象抛出!
作用:提醒不强烈,编译阶段不报错!!运行时才可能出现!!
日志
输出到控制台的配置标志
//输出在控制台用CONSOLE
<appender name="CONSOLE" class="ch.qos.logback.core.ConsoleAppender">
- 1
- 2
- 3
//输出在日志文件用FILE
<appender name="FILE" class="ch.qos.logback.core.rolling.RollingFileAppender">
- 1
- 2
- 3
创建一个LogBack的核心日志对象,用于记录日志文件的信息,且以后会收到配置文件的控制
//创建一个LogBack的核心日志对象,用于记录日志文件的信息,且以后会收到配置文件的控制
public static final Logger LOGGER = LoggerFactory.getLogger(LogeDemo.class);
- 1
- 2
多线程
-
方式一:继承Thread类方式实现
①定义一个类MyThread继承java.lang.Thread类
②在MyThread类中重写run()方法
③创建MyThread类的对象
④调用线程对象的start()方法启动线程
子线程和主线程是随机并发推进执行
子线程的启动必须放到主线程输出的前面才可以随机执行
优点:编码简单 缺点:线程类已经继承Thread,无法继承其他类,不利于扩展。- 1
- 2
-
方式二:实现Runnable接口
①定义一个线程任务类MyRunnable实现Runnable接口
②在线程任务类MyRunnable类中重写run()方法
③创建线程任务类MyRunnable的对象
④创建Thread类的线程对象,把线程任务MyRunnable的对象作为构造器的参数封装成线程对象。
⑤调用线程对象的start()启动线程
线程任务Runnable需要调用构造器Thread把线程任务封装成一个线程对象
方法名称 说明 public Thread(String name) 可以为当前线程指定名称 public Thread(Runnable target) 封装Runnable对象成为线程对象 public Thread(Runnable target ,String name ) 封装Runnable对象成为线程对象,并指定线程名称 优点:线程任务类只是实现接口,可以继续继承类和实现接口,扩展性强。 缺点:编程多一层对象包装。- 1
- 2
- 3
Runnable r = new MyRunnable(); Thread t = new Thread(r);- 1
- 2
-
方式三:实现Callable接口
定义一个类MyCallable实现Callable接口
在MyCallable类中重写call()方法
创建MyCallable类的对象
创建Future的实现类FutureTask对象,把MyCallable对象作为构造器的参数
创建Thread类的对象,把FutureTask对象作为构造器的参数
启动线程
优点:线程任务类只是实现接口,可以继续继承类和实现接口,扩展性强。可以在线程执行完毕后去获取线程执行的结果。 缺点:编码复杂一点。- 1
- 2
Callable接口创建的多线程可以返回方法 主要是FutureTask
FutureTask有get的API能够获取返回的方法
//创建一个Callable的任务对象 Callable<String> c = new MyCallable(10); //把Callable的任务对象封装成FutureTask (未来任务对象) /** * 1、未来任务对象在执行完毕之后会获取线程执行的结构 * 2、未来文物对象是一个Runable的实例 */ FutureTask<String> futureTask = new FutureTask<>(c); Thread t = new Thread(futureTask); t.start(); System.out.println(futureTask.get());- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
| 线程创建方式 | 优点 | 缺点 |
|---|---|---|
| 继承Thread类 | 编程比较简单,可以直接使用Thread类中的方法 | 可以扩展性较差, 不能再继承其他的类 |
| 实现Runnable、 | 扩展性强,实现该接口的同时还可以继承其他的类。 | 编程相对复杂 |
| Callable接口 | 扩展性强,实现该接口的同时还可以继承其他的类。可以得到线程执行的结果 | 编程相对复杂 |
常用API
Thread获取和设置线程名称
| 方法名称 | 说明 |
|---|---|
| String getName() | 获取当前线程的名称,默认线程名称是Thread-索引 |
| void setName(String name) | 将此线程的名称更改为指定的名称,通过构造器也可以设置线程名称 |
Thread的构造器
| 方法名称 | 说明 |
|---|---|
| public Thread(String name) | 可以为当前线程指定名称 |
| public Thread(Runnable target) | 封装Runnable对象成为线程对象 |
| public Thread(Runnable target ,String name ) | 封装Runnable对象成为线程对象,并指定线程名称 |
Thread类获得当前线程的对象
| 方法名称 | 说明 |
|---|---|
| public static Thread currentThread(): | 返回对当前正在执行的线程对象的引用 |
-
此方法是Thread类的静态方法,可以直接使用Thread类调用。
-
这个方法是在哪个线程执行中调用的,就会得到哪个线程对象。
Thread类的线程休眠方法
| 方法名称 | 说明 |
|---|---|
| public static void sleep(long time) | 让线程休眠指定的时间,单位为毫秒。 |
设置线程的优先级
| 方法名称 | 说明 |
|---|---|
| public final void setPriority(int newPriority) | 设置线程的优先级 |
| public final int getPriority() | 获取线程的优先级 |
Thread类提供3个级别:
// 最低优先级
public static final int MIN_PRIORITY = 1;
// 默认优先级
public static final int NORM_PRIORITY = 5;// 最高优先级
public static final int MAX_PRIORITY = 10;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
线程同步问题
-
方式一:同步代码块
作用:把出现线程安全问题的核心代码给上锁。
原理:每次只能一个线程进入,执行完毕以后自动解锁,其他线程才可以进来执行。
synchronized(锁对象(this)) { 多条语句操作共享资源的代码 }- 1
- 2
- 3
对于实例方法建议使用this作为锁对象,此时this应该代表共享资源对象才优雅(例如账户对象)
对于静态方法建议使用字节码类名.class对象作为锁对象。
-
方式二:同步方法
作用:把出现线程安全问题的核心方法给上锁。
原理:每次只能一个线程进入,执行完毕以后自动解锁,其他线程才可以进来执行。
修饰符 synchronized 返回值类型 方法名称(形参列表) { 多条语句操作共享资源的代码 }- 1
- 2
- 3
-
方式三:Lock锁
Lock实现提供比使用synchronized方法和语句可以获得更广泛的锁定操作。
Lock是接口不能直接实例化,这里采用它的实现类ReentrantLock来构建Lock锁对象。
最好使用 try…catch…finally
| 方法名称 | 说明 |
|---|---|
| public ReentrantLock() | 获得Lock锁的实现类对象 |
Lock的API
| 方法名称 | 说明 |
|---|---|
| void lock() | 获得锁 |
| void unlock() | 释放锁 |
//定义一个锁
public static final Lock LOCK = new ReentrantLock();
//上锁
LOCK.lock();
//解锁
LOCK.unlock();
- 1
- 2
- 3
- 4
- 5
- 6
//死锁 package com.aynu.demo01_thread; public class TestDemo { //定义两个商品对象 public static Object resources1 = new Object(); public static Object resources2 = new Object(); public static void main(String[] args) { new Thread(new Runnable() { @Override public void run() { synchronized (resources1){ System.out.println("店家获取商品1,开始请求商品2"); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resources2){ System.out.println("店家获取商品2"); } } } }).start(); new Thread(new Runnable() { @Override public void run() { synchronized (resources2){ System.out.println("店家获取商品2,开始请求商品1"); try { Thread.sleep(3000); } catch (InterruptedException e) { e.printStackTrace(); } synchronized (resources1){ System.out.println("店家获取商品1"); } } } }).start(); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
线程通讯(等待和唤醒)
| 方法名称 | 说明 |
|---|---|
| void wait() | 导致当前线程等待,直到另一个线程调用该对象的 notify()方法或 notifyAll()方法 |
| void notify() | 唤醒正在等待对象监视器(锁对象)的单个线程 |
| void notifyAll() | 唤醒正在等待对象监视器(锁对象)的所有线程 |
虚拟机中线程的六种状态:
新建状态( NEW ) ——————> 创建线程对象
就绪状态( RUNNABLE ) ——————> start方法
阻塞状态( BLOCKED ) ——————> 无法获得锁对象
等待状态( WAITING ) ——————> wait方法
计时等待( TIMED_WAITING )——————> sleep方法
结束状态( TERMINATED ) ———————> 全部代码运行完毕 或 代码异常终止
线程池
线程池是一种多线程处理形式,可以集中保存一些长久存活的线程对象,负责创建、复用、管理线程
提高响应速度: 减少了创建新线程的时间
降低资源消耗:重复利用线程池中线程,不需要每次都创建、销毁
便于线程管理:线程池可以集中管理并发线程的数量
线程池API
| 方法名称 | 说明 |
|---|---|
| void execute(Runnable command) | 执行任务/命令,没有返回值,一般用来执行 Runnable |
| Future submit(Callable task) | 执行任务,有返回值,一般又来执行 Callable |
| void shutdown() | 关闭连接池 (等线程结束) |
| 方法名称 | 说明 |
|---|---|
| Executors.newCachedThreadPool() | 创建一个可根据需要创建新线程的线程池 Ø |
| Executors.newFixedThreadPool(n) | 创建一个可重用固定线程数的线程池 Ø |
| Executors.newSingleThreadExecutor() | 创建一个只有一个线程的线程池 |
| Executors.newScheduledThreadPool(n) | 创建一个大小无限的线程池。此线程池支持定时以及周期性执行任务的需求 |
Executors.newSingleThreadExecutor:
创建一个单线程的线程池,也就是相当于单线程串行执行所有任务。如果这个唯一线程因为异常结束会有一个新的线程替代它。
Executors.newFixedThreadPool(n)
创建固定大小的线程池。每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小。
线程池的大小一旦达到最大值就会保持不变,如果某个线程因为执行异常而结束,那么线程池会补充一个新线程。
Executors.newCachedThreadPool:
创建一个可缓存的线程池,如果线程池的大小超过了处理任务所需要的线程,就会回收部分空闲(60秒不执行任务)的线程。
当任务数增加时,此线程池又可以智能的添加新线程来处理任务。
此线程池不会对线程池大小做限制,线程池大小完全依赖于操作系统(或者说JVM)能够创建的最大线程大小。
Executors.newScheduledThreadPool(n)
只固定核心线程数量,任务超限后创建的新线程的数量不受限制。此线程池支持定时以及周期性执行任务的需求
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Executors是官方自带的线程池
//Executors工具类构建线程池对象-提交Runnable任务
//创建一个固定线程数量的线程池
ExecutorService service = Executors.newFixedThreadPool(3);
//创建Runnable对象
Runnable runnable = new MyThread();
//把Runnable对象放进线程池里
service.execute(runnable);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
//创建一个只有3个线程的线程池
ExecutorService service = Executors.newFixedThreadPool(3);
//将线程放进线程池中,并定义Future对象来接收
//未来文物对象是一个Runable的实例
Future<String> f4 = service.submit(new MyCallable(400));
//通过get对象获取值
try {
String rs4 = f4.get();
System.out.println(rs4);
} catch (Exception e) {
e.printStackTrace();
}
service.shutdown();
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
Volatile可以保证操作的原子性吗?
只能保证线程每次在使用共享数据的时候是最新值**。**
但是不能保证原子性**。**
//加上volatile能够使共享数据及时更新到最新值
private volatile double money = 10000
- 1
- 2
原子性
所谓的原子性是指在一次操作或者多次操作中,要么所有的操作全部都得到执行且不会受任何因素的干扰而中
要么所有的操作都不执行,多个操作是一个不可以分割的整体。
最终要能保证线程安全
保证原子性
//保证程序的原子性
//初始化一个指定值的原子型Integer
public AtomicInteger integer = new AtomicInteger();
@Override
public void run() {
for (int i = 0; i < 100; i++) {
//以原子方式将当前值加1,先加后取
System.out.println("当前人数是" + integer.incrementAndGet());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
原子类AtomicInteger
| 构造器 | 详解 |
|---|---|
| public AtomicInteger() | 初始化一个默认值为0的原子型Integer |
| public AtomicInteger(int initialValue) | 初始化一个指定值的原子型Integer |
| 方法 | 详解 |
|---|---|
| int get(): | 获取值 |
| int getAndIncrement(): | 以原子方式将当前值加1,先取后加。 |
| int incrementAndGet() | 以原子方式将当前值加1,先加后取。 |
| int addAndGet(int data) | 以原子方式将当前值增量加,先加后取。 |
| int getAndSet(int value) | 以原子方式将当前值增量加,先取后加。 |
AtomicInteger原理
AtomicInteger原理是:自旋锁+CAS算法
CAS算法:
有三个操作的数:内存值,旧的值A,要修改的值B
当旧的值A==内存值,修改成功,将内存值改为新的值B
当旧的值A!=内存值,修改失败,不做任何操作,并重新获取现在的最新值
重新获取最新值的动作就是自旋
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
File、递归、IO流
File表示要读写的文件\文件夹在哪
- 可以对文件进行创建,删除、获取文本本身信息等操作**。**
- 但是不能读写文件内容**。**
路径用 “ / ” 或者 " \\ "
| 方法名称 | 说明 |
|---|---|
| public File(String pathname) | 根据文件路径创建文件对象 |
| public File(String parent, String child) | 从父路径名字符串和子路径名字符串创建文件对象 |
| public File(File parent, String child) | 根据父路径对应文件对象和子路径名字符串创建文件对象 |
File对象的路径可以定位文件和文件夹
File封装的对象仅仅是一个路径名。这个路径可以是存在的,也可以是不存在的
绝对路径:从盘符开始
相对路径:不带盘符,默认相对到当前工程下的目录寻找
| 方法名称 | 说明 |
|---|---|
| public boolean isDirectory() | 测试此抽象路径名表示的File是否为文件夹 |
| public boolean isFile() | 测试此抽象路径名表示的File是否为文件 |
| public boolean exists() | 测试此抽象路径名表示的File是否存在 |
| public String getAbsolutePath() | 返回此抽象路径名的绝对路径名字符串 |
| public String getPath() | 将此抽象路径名转换为路径名字符串 |
| public String getName() | 返回由此抽象路径名表示的文件或文件夹的名称 |
| public long lastModified() | 返回文件最后修改的时间毫秒值 |
File类的创建功能
| 方法名称 | 说明 |
|---|---|
| public boolean createNewFile() | 创建一个新的空的文件 |
| public boolean mkdir() | 创建一个单级文件夹 |
| public boolean mkdirs() | 创建一个多级文件夹 |
| 方法名称 | 说明 |
|---|---|
| public boolean delete() | 删除由此抽象路径名表示的文件或空文件夹 |
遍历
| 方法名称 | 说明 |
|---|---|
| public String[] list() | 获取当前目录下所有的"一级文件名称"到一个字符串数组中去返回。 |
| public File[] listFiles()(常用) | 获取当前目录下所有的"一级文件对象"到一个文件对象数组中去返回(重点) |
public File[] listFiles()
能够进行一些API的操作,如delete()、getAbsolutePath()等
- 1
- 2
当调用者不存在时,返回null
当调用者是一个文件时,返回null
当调用者是一个空文件夹时,返回一个长度为0的数组
当调用者是一个有内容的文件夹时,将里面所有文件和文件夹的路径放在File数组中返回
当调用者是一个有隐藏文件的文件夹时,将里面所有文件和文件夹的路径放在File数组中返回,包含隐藏内容
当调用者是一个需要权限才能进入的文件夹时,返回null
UTF-8 中文汉字占三个字节
GBK 中文汉字占两个字节
String编码
| 方法名称 | 说明 |
|---|---|
| byte[] getBytes() | 使用平台的默认字符集将该 String编码为一系列字节,将结果存储到新的字节数组中 |
| byte[] getBytes(String charsetName) | 使用指定的字符集将该 String编码为一系列字节,将结果存储到新的字节数组中 |
String name = "ab123我爱你中国";
//存储到字节数组中
//使用平台的默认字符集将该 String编码为一系列字节,将结果存储到新的字节数组中
byte[] bytes = name.getBytes();
//存储到自定义类型的字节数组中
byte[] bytes1 = name.getBytes("GBK");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
String解码
| 构造器 | 说明 |
|---|---|
| String(byte[] bytes) | 通过使用平台的默认字符集解码指定的字节数组来构造新的 String |
| String(byte[] bytes, String charsetName) | 通过指定的字符集解码指定的字节数组来构造新的 String |
//解码操作
String name1 = new String(bytes);
String name2 = new String(bytes1,"GBK");
- 1
- 2
- 3
IO流
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-Xd9OzkZO-1650192791119)(C:\Users\姜硕\AppData\Roaming\Typora\typora-user-images\image-20220410181555809.png)]
文件字节输入流:FileInputStream
作用:以内存为基准,把磁盘文件中的数据以字节的形式读取到内存中去。
| 构造器 | 说明 |
|---|---|
| public FileInputStream(File file) | 创建字节输入流管道与源文件对象接通 |
| public FileInputStream(String pathname) | 创建字节输入流管道与源文件路径接通 |
| 方法名称 | 说明 |
|---|---|
| public int read() | 每次读取一个字节返回,如果字节已经没有可读的返回-1 |
| public int read(byte[] buffer) | 每次读取一个字节数组返回,如果字节已经没有可读的返回-1 |
性能较慢
读取中文字符输出无法避免乱码问题
//输出字节
//定义一个输入流
InputStream id = new FileInputStream("day10_resources\\one.txt");
System.out.println((char) id.read());
- 1
- 2
- 3
- 4
- 5
//定义一个存储数量为3字节的字节数组
byte[] b1 = new byte[3];
//把磁盘文件中的数据以字节数组的形式读取到内存中去 每次返回读取字节的数量
int len = is.read(b1);
//对字节数组进行解码
String s1 = new String(b1);
String s1 = new String(b1,0,3); //定义解码的数量,读多少到多少
System.out.println(len + " " + s1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
//输出全部字节 File file = new File("day10_resources\\one.txt"); //定义一个输入流 InputStream is = new FileInputStream(file); byte[] bytes = new byte[(int)file.length()]; int len = is.read(bytes); String s = new String(bytes); System.out.println(len + " " + s); ———————————————————————————————————————————————————————————————————————————————————— InputStream is = new FileInputStream("day10_resources\\one.txt"); //readAll()是自带的API,输出全部字节 byte[] bytes = is.readAll(); System.out.println(new String(bytes));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
文件输出流
文件字节输出流:FileOutputStream
作用:以内存为基准,把内存中的数据以字节的形式写出到磁盘文件中去的流。
调用FileOutputStream会自动创建文件
| 构造器 | 说明 |
|---|---|
| public FileOutputStream(File file) | 创建字节输出流管道与源文件对象接通 |
| public FileOutputStream(File file,boolean append) | 创建字节输出流管道与源文件对象接通,可追加数据 |
| public FileOutputStream(String filepath) | 创建字节输出流管道与源文件路径接通 |
| public FileOutputStream(String filepath,boolean append) | 创建字节输出流管道与源文件路径接通,可追加数据 |
文件字节输出流写数据出去的API
| 方法名称 | 说明 |
|---|---|
| public void write(int a) | 写一个字节出去 |
| public void write(byte[] buffer) | 写一个字节数组出去 |
| public void write(byte[] buffer , int pos , int len) | 写一个字节数组的一部分出去。 |
| 方法 | 说明 |
|---|---|
| flush() | 刷新流,还可以继续写数据 |
| close() | 关闭流,释放资源,但是在关闭之前会先刷新流。一旦关闭,就不能再写数据 |
重复对同一个文件写数据会对之前的数据进行覆盖
| public FileOutputStream(String filepath,boolean append) append为 true可以追加数据 | 创建字节输出流管道与源文件路径接通,可追加数据 |
|---|
os.write(“\r\n”.getBytes()) // /r/n是为了不同系统的兼容
OutputStream os = new FileOutputStream("day10_resources\\two.txt",true);
//使用平台的默认字符集将该 String编码为一系列字节,将结果存储到新的字节数组中
byte[] b = "123中国afccccccccdsf".getBytes();
os.write(b);
os.write("\r\n".getBytes());
- 1
- 2
- 3
- 4
- 5
- 6
IO流的资源释放
-
try-catch-finally
资源用完不会自动释放
被finally控制的语句最终一定会执行,除非JVM退出
-
try-with-resource
资源用完会自动释放
JDK 7 以及 JDK 9的()中只能放置资源对象,否则报错
资源都是实现了Closeable/AutoCloseable接口的类对象
try (InputStream is = new FileInputStream("C:\\壁纸\\0d59f1719109ca1439d7413844d3c226.jpg"); OutputStream os = new FileOutputStream("C:\\Users\\姜硕\\Desktop\\杂\\壁纸\\"); ){ //定义一个字节数组,负责复制数据 byte[] buffer = new byte[1024]; int len; while ((len = is.read(buffer)) != -1){ os.write(buffer,0,len); } } catch (Exception e) { e.printStackTrace(); }- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
字符输入流
字节流读取中文输出会有乱码,字符输入更适合读中文
| 方法名称 | 说明 |
|---|---|
| void write(int c) | 写一个字符 |
| void write(char[] cbuf) | 写入一个字符数组 |
| void write(char[] cbuf, int off, int len) | 写入字符数组的一部分 |
| void write(String str) | 写一个字符串 |
| void write(String str, int off, int len) | 写一个字符串的一部分 |
| void write(int c) | 写一个字符 |
高级缓冲流
高级的缓冲流把低级流进行了改装,提供了默认自带8KB的缓冲区
可以提高原始字节流、字符流读写数据的性能
功能上并无很大变化,只是性能提升了
字节缓冲输入流管道自带了一个8KB的缓冲池,每次可以直接借用操作系统的功能最多提取8KB的数据到缓冲池中去
以后我们直接从缓冲池读取数据,所以性能较好
字节缓冲输出流管道自带了8KB缓冲池,数据就直接写入到缓冲池中去,写数据性能极高了
//创建一个字节输入流
InputStream is = new FileInputStream("day10_resources\\two.txt");
//把字节输入流放进管道,包装成高级的字节缓冲输入流
BufferedInputStream bis = new BufferedInputStream(is);
- 1
- 2
- 3
- 4
| 方法 | 说明 |
|---|---|
| public String readLine() | 读取一行数据返回,如果读取没有完毕,无行可读返回null |
字符输入转换流
| 构造器 | 说明 |
|---|---|
| public InputStreamReader(InputStream is) | 可以把原始的字节流按照代码默认编码转换成字符输入流。几乎不用,与默认的FileReader一样。 |
| public InputStreamReader(InputStream is ,String charset) | 可以把原始的字节流按照指定编码转换成字符输入流,这样字符流中的字符就不乱码了(重点) |
字符输出转换流
| 构造器 | 说明 |
|---|---|
| public OutputStreamWriter(OutputStream os) | 可以把原始的字节输出流按照代码默认编码转换成字符输出流。几乎不用。 |
| public OutputStreamWriter(OutputStream os,String charset) | 可以把原始的字节输出流按照指定编码转换成字符输出流(重点) |
把对象数据存入到文件中去
| 方法名称 | 说明 |
|---|---|
| public final void writeObject(Object obj) | 把对象写出去到对象序列化流的文件中去 |
打印流可以实现方便、高效的打印数据到文件中去
| 构造器 | 说明 |
|---|---|
| public PrintStream(OutputStream os) | 打印流直接通向字节输出流管道 |
| public PrintStream(File f) | 打印流直接通向文件对象 |
| public PrintStream(String filepath) | 打印流直接通向文件路径 |
| 方法 | 说明 |
|---|---|
| public void print(Xxx xx) | 打印任意类型的数据出去 |
PrintStream和PrintWriter的区别
l打印数据功能上是一模一样的。
l两者在打印功能上都是简洁方便,性能高效(核心优势)
lPrintStream属于继承自字节输出流OutputStream的子类,支持写字节数据的方法
lPrintWriter属于继承自字符输出流Writer的子类,支持写字符数据出去
网络编程
CS架构:客户端—服务器
BS架构:浏览器—服务器
Java用哪个类来代表IP对象 lInetAddress
特殊IP地址:127.0.0.1,也可以是localhost:是回送地址也称本地回环地址,也称本机IP,永远只会寻找当前所在本机。
InetAddress API****如下
| 名称 | 说明 |
|---|---|
| public static InetAddress getByName(String host) | 确定主机名称的IP地址。主机名称可以是机器名称,也可以是IP地址 |
| public String getHostName() | 获取此IP地址的主机名 |
| public String getHostAddress() | 返回文本显示中的IP地址字符串 |
| public boolean isReachable(int timeout) | 判断多少毫秒内可以接通主机,接通返回 |
1.端口号的作用是什么?标识正在计算机设备上运行的进程(程序)
TCP通信方式
客户端Socket
| 构造器 | 说明 |
|---|---|
| public Socket(String host , int port) | 创建发送端的Socket对象与服务端连接,参数为服务端程序的ip和端口。 |
Socket类成员方法
| 方法 | 说明 |
|---|---|
| OutputStream getOutputStream() | 获得字节输出流对象 |
| InputStream getInputStream() | 获得字节输入流对象 |
服务端ServlerSocket
| 构造器 | 说明 |
|---|---|
| public ServerSocket(int port) | 注册服务端端口 |
ServlerSocket类成员方法
| 方法 | 说明 |
|---|---|
| public Socket accept() | 等待接收客户端的Socket通信连接,连接成功返回服务端Socket对象与客户端建立端到端通信 |
Socket代表管道
ServerSocket注册端口,接收客户端Socket管道连接
System.out.println("服务端启动成功!!");
//1、注册服务器
ServerSocket serverSocket = new ServerSocket(9876);
//2、开始接收客户端的socket管道连接请求
//注意:在这里等待客户端的socket管道连接
Socket socket = serverSocket.accept();
//3、字节输入流
InputStream is = socket.getInputStream();
//4、把低级的字节输入流包装成高级的缓冲字符输入流
BufferedReader br = new BufferedReader(new InputStreamReader(is));
//5、按照行读读取
String line;
while ((line = br.readLine()) != null) {
System.out.println(socket.getRemoteSocketAddress() + "发来的" + line);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
System.out.println("启动客户端!!!"); //1、连接与服务器的Socket管道连接 Socket socket = new Socket("127.0.0.1",9876); //2、从Socket管道中得到哟个字节输出流管道 OutputStream os = socket.getOutputStream(); //3、把低级的输出流包装成高级的输出流 PrintStream ps = new PrintStream(os); //4、发送数据 Scanner sc = new Scanner(System.in); while (true){ System.out.println("请输入:"); String msg = sc.nextLine(); ps.println(msg); ps.flush(); } /127.0.0.1:8023发来的efewfewa
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
单元测试、反射、注解、XML
jdk1.4
| 注解 | 说明 |
|---|---|
| @Test | 测试方法 |
| @Before | 用来修饰实例方法,该方法会在每一个测试方法执行之前执行一次。 一般用于初始化对象 |
| @After | 用来修饰实例方法,该方法会在每一个测试方法执行之后执行一次。 一般用于关闭资源 |
| @BeforeClass | 用来静态修饰方法,该方法会在所有测试方法之前只执行一次。 |
| @AfterClass | 用来静态修饰方法,该方法会在所有测试方法之后只执行一次。 |
jdk1.5
| 注解 | 说明 |
|---|---|
| @Test | 测试方法 |
| @BeforeEach | 用来修饰实例方法,该方法会在每一个测试方法执行之前执行一次。 |
| @AfterEach | 用来修饰实例方法,该方法会在每一个测试方法执行之后执行一次。 |
| @BeforeAll | 用来静态修饰方法,该方法会在所有测试方法之前只执行一次。 |
| @AfterAll | 用来静态修饰方法,该方法会在所有测试方法之后只执行一次。 |
元注解有两个:
@Target: 约束自定义注解只能在哪些地方使用,
@Retention:申明注解的生命周期
在xml文件中"<“,”>"是会报错,输入<![CDATA[ …内容… ]]> 快捷键CD

