
- 1乐高机器人EV3的PID巡线控制——附源程序_乐高pid巡线程序
- 2Java、数据库等面试题大全_java和数据库面试
- 3算法工程师成长必备——一套小白也能看懂的算法书!(文末留言赠书)
- 4无人机航摄地面站航线设计主要参数_地面分辨率与航高的关系公式
- 5Azure 网络(VNet) 到 Azure网络(VNet) 连接_azure vnet gateway
- 62023华为od机试C卷【密码解密】C++ 实现_给定一段 “密文”字符串 s ,其中字符都是经过 “密码本” 映射的,现需要将“密文
- 7isis 网络 level 2 iih_ISIS路由协议(中间系统到中间系统)
- 8FPGA高端项目:解码索尼IMX390 MIPI相机转HDMI输出,提供FPGA开发板+2套工程源码+技术支持
- 9SpringCache的了解与使用_spring.cache.type
- 10【Kafka】Kafka监控工具Kafka-eagle简介
google最新大语言模型gemma本地化部署_gemma 要求
赞
踩
Gemma是google推出的新一代大语言模型,构建目标是本地化、开源、高性能。

与同类大语言模型对比,它不仅对硬件的依赖更小,性能却更高。关键是完全开源,使得对模型在具有行业特性的场景中,有了高度定制的能力。
Gemma模型当下有四个版本,Gemma 7b, 2b, 2b-it, 7b-it 。通俗来说,2b及精简小巧,覆盖了现代流行的语言,对硬件依赖小。7b是常规型的,要有的基本都有了,硬件上最低需要8gb内存(显存)。后缀带it的版本,可适用于nvidia较新显卡,支持int8(fp8), tensorrt核心。但我的40hx硬件被阉割太厉害,连fp16都跑不起来,就没测试了。
安装环境:
我的硬件环境是虚拟机环境,40hx显卡直通,linux系统,远程访问。软件环境需要目标是ollama及open-webui。ollama是大语言模型的一个运行环境,open-webui是基于openAI及ollama的一个前端界面。目前ollama只支持nvidia的GPU加速,别的显卡就不讨论了。
安装过程:
1. 虚拟机安装,这边需要注意的是,显卡必须直通,CPU必须在主机直通模式。不然GPU加速就不能成功。
2. 安装常用的软件,wget curl git nvidia-toolkit
3. 确认环境:nvidia-smi看一下显卡是不是正常驱动,cat /proc/cpuinfo 看一下AVX是否加载。这二点决定了GPU加速
4. 在linux上运行:(要科学)
curl -fsSL https://ollama.com/install.sh | sh然后等待安装完成,安装完成后,执行 ollama run gemma:2b 或者 ollama run gemma:7b 等模型下载完毕后,就进入字符界面,你就可以跟机器交流了。按ctrl-d可退出。
5. 远程访问:
因为我是在服务器上安装的,操作需要在PC上,所以需要做一下远程
sudo nano /etc/systemd/system/ollama.service (我是ubuntu系统debian类似,其它系统查看services配置方法)
在nano中,[Service]下面加一行 Environment="OLLAMA_HOST=0.0.0.0:11434"
保存退出后,执行 sudo systemctl daemon-reload 再执行 sudo systemctl restart ollama
PC端打开浏览器,访问http://你的服务器IP:11434 如果显示ollama表示已经成功了。
6. open-webui安装
现在的linux发布版本,基本都预装了docker环境,如果你的linux刚好没有,就先安装docker
然后运行 sudo docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
其中3000可以换成你想要的发布端口。
等待安装完成后,访问http://你的服务器IP:3000
7. 配置
第一次登录是需要注册自己id的(sign up) 注册好后,进入系统,默认是已经可以找到ollama模型的。其它配置自己摸索吧,针对Gemma模型的关键配置是在setting下
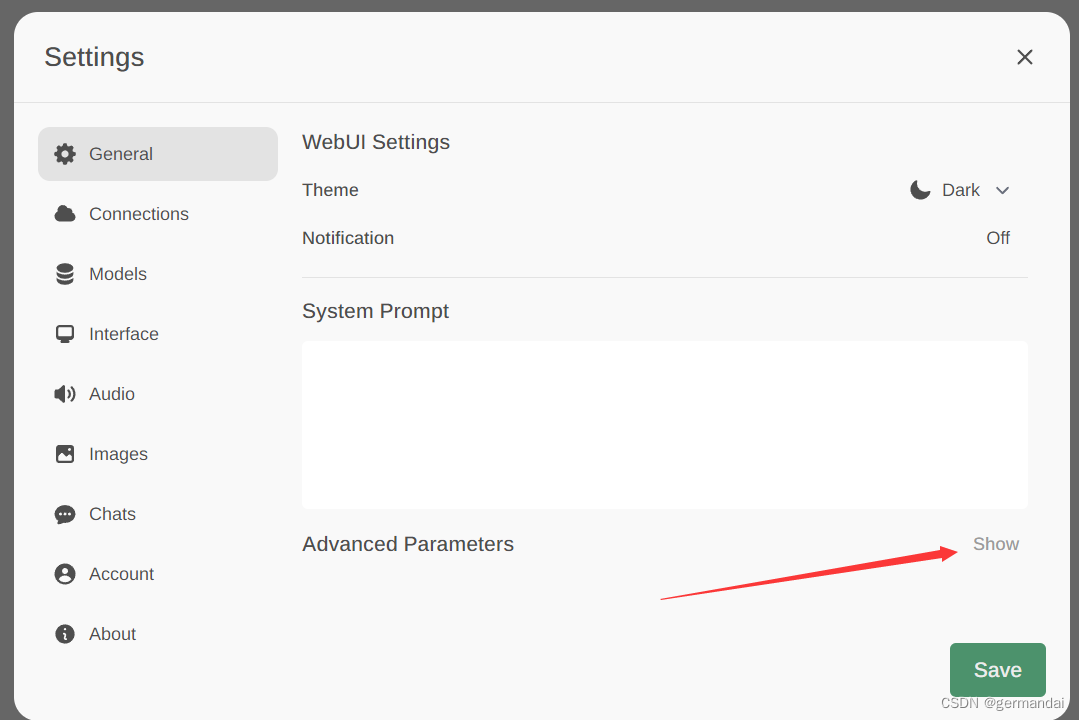
点击上图这个Show, 然后找到 Context Length这是上下文中的内容关联长度,Ollama默认是2048, 所以你会发现跟机器聊几句就聊不到一起了,Gemma可以设置到8192,这样就可以愉快地聊上很久。另一个是Max Tokens,默认长度是128, Gemma据说可以达到6T个tokens, 这二个参数,在GPU加速时,一个是占了显存,一个是占了性能。ollama为了保持各种模型的兼容性,这二项参数上留得很保守,在Gemma与40hx这样的适配上,可适当增加。
教程结束,祝玩得愉快!

