
- 1什么是Spring?它有哪些好处?_csdn中spring是什么
- 2金融数据分析用哪些分析软件Python,R还是SQL?_金融学需要用到的工具和软件
- 3i.MX6ULL(十五) 根文件系统_imx6ull 根文件系统
- 4基于强化学习的可解释性推荐 文献三篇_强化学习经典文献
- 5Txt文本编码格式说明
- 6Android Studio 在XML编辑无代码提示_android studio写代码没有提示
- 7java OA 系统开发二:数据库设计之oa数据库设计_java oa多级审批 数据库设计
- 8Python|Pyppeteer获取去哪儿酒店数据(20)_python爬取酒店数据
- 9微服务学习 | Springboot整合Dubbo+Nacos实现RPC调用_springboot rpc调用注解
- 10Python Conda报错:Collecting package metadata (current_repodata.json): failed_conda create -n py14 python==3.8.5 collecting pack
OpenAI 15秒重建逼真人声,百度早就实现啦!只需2秒生成完美音色,免费使用
赞
踩
大家好,我是卖萌酱。
这两天,卖萌酱发现有不少读者小伙伴都在关注几天前我们介绍的OpenAI刚刚发布的这个名为Voice Engine 的语音引擎。这个听起来颇为“Amazing”的“黑科技”,可以仅仅凭借一段15秒的声音样本,就能精准模仿这段声音主人的语音语调。
分享几个网站
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
克隆爱豆的声音让爱豆每晚给我讲睡前故事?各种配音剪辑未来又可以玩的飞起?甚至再放飞一点想象快进到具身机器人感情丰沛血肉饱满的与人开始对话?

不过在放飞想象之余,单看Voice Engine这功能,卖萌酱却总觉得似曾相识好像在哪里见过,果然,这两天在卖萌酱高强度网上冲浪时,就发现了一个“秘密”——嗯?怎么这OpenAI这看起来炫酷无比的语音引擎,已经被百度早早上线的文心一言APP里一个小小的“酷功能”给实现了???
一、只用两秒,制造定制声音?
打开文心一言APP,我们可以定制专属的智能体,而在声音选择一项里,就有这个“创建我的声音”的功能。
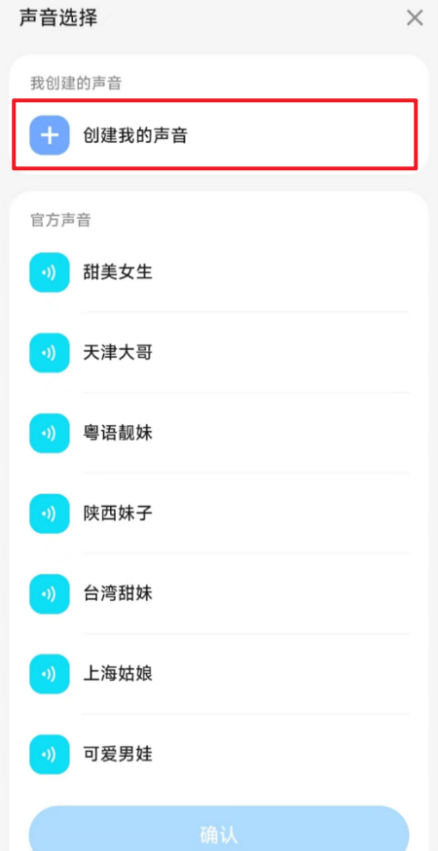

操作十分简单,只要简单说一句话,就可以创建一个完美模仿自己声音特点的“语音助手”,让我们首先来听听原声:
原声,夕小瑶科技说,10秒
在检查完声音质量后,只需要两秒左右,一个属于自己的“语音库”便被构建完毕。

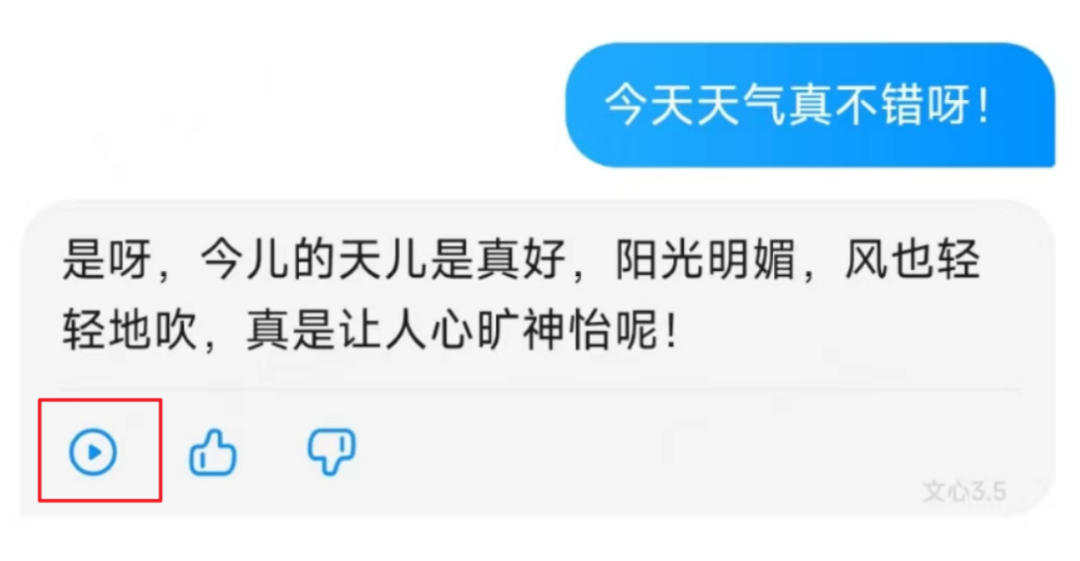
在未来和这个智能体所有的对话,都可以通过点击下方的播放键来使用我们自己合成的自己的音色完成语音播报。
甚至于,点击下方对话框上的通话按钮:
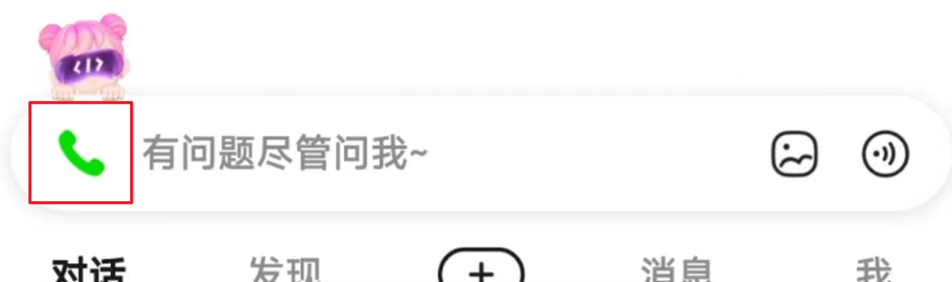
还可以与我们自己构建的数字分身实时通话!音色音调也完全保持一致

卖萌酱试着与自己创建的智能体聊了两句,好家伙,这哪里还是什么让人出戏的机械造物,这简直就是自己的“数字分声”!
合成声音,夕小瑶科技说,22秒

老实讲,百度这个体验感如此好的语音合成功能带给卖萌酱的震撼要比OpenAI发布的一个简单Demo和音频演示要大的多,而除了惊讶于语音合成质量与生成速度以外,卖萌酱也惊奇于百度已经悄无声息的把这样一个听起来还相当新奇的“黑科技”如此成熟的内嵌于自己推出的产品应用之中。
而作为一个技术宅(不是),自然,卖萌酱也想探究一下这个“酷功能”背后的技术背景。
二、解秘语音合成,数字分身是怎么炼成的?
卖萌酱关注百度语音合成技术已久,会发现百度的语音技术团队不仅仅是所有互联网行业中最早自主研发语音技术的团队,也是国内最先将深入学习引入到语音合成之中的团队。
在大模型语音助手、数字分身这些最近才火爆起来的应用场景以外,百度的语音合成团队之前是业界首个将个性化离线合成落地到导航场景中的团队,这里的关键词是离线。
对于导航场景下的语音合成问题,由于当汽车在高速行驶过程中,导航语音播报必须要做到稳定与可靠,因此语音合成便需要在手机端侧离线完成。而在此基础上,当用户不仅仅需要“标准化导航”,而更需要“个性化导航”时,这样一个离线的个性化语音合成便成为了技术难点。而百度的语音合成团队做到了用户仅需录制3-20句话,5分钟后就可获得自己声音的音库,在得到音库后,后续一切导航的播报均可在离线场景下的完成,完全无需网络。
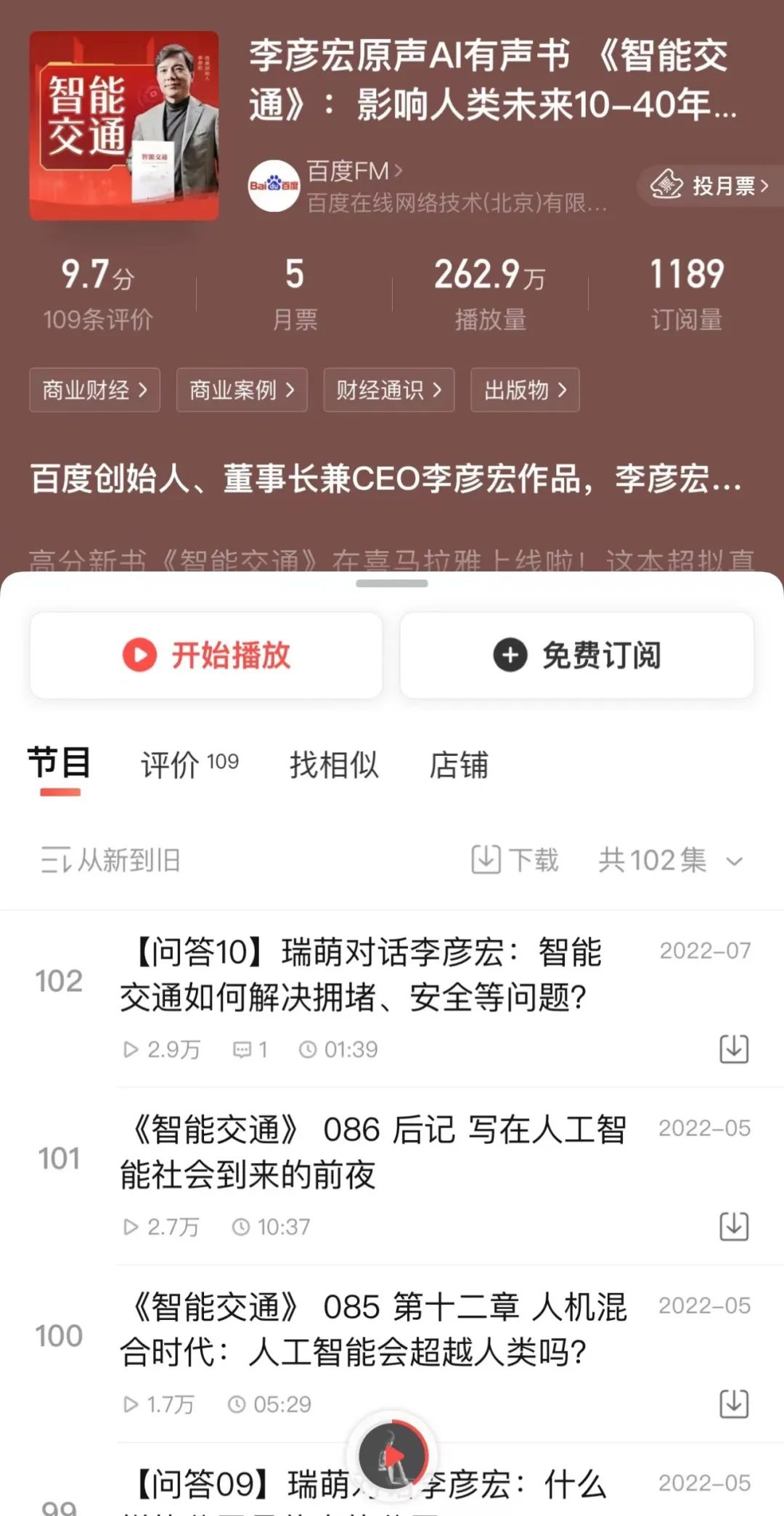
而时间来到2022年4月,世界读书日前夕,喜马拉雅APP上线了百度创始人、董事长兼CEO李彦宏的《智能交通》一书,除却关于介绍中国智能交通发展现状与前景的内容本身,这本书当时最引人关注的一点就是它的音频版是通过李彦宏公开的300句话的录音,通过AIGC的语言合成技术创作生成的,相比于导航场景,《智能交通》有声书有86集,共20万字,而百度的语言合成团队却仅仅依靠300句话就生成了媲美专业音库的语音内容,截至目前累积播放已经达到262万。 可能如果不是新闻,普通用户都无法分辨朗读是语音合成还是真人朗诵。
建立在这些个性化语音合成的工作基础之上,当时间来到2023年,伴随着大模型的出现,依托文心文本大模型以及百度语音团队研发的语音合成大模型,百度语音合成团队成功实现了Zero-shot 云端个性化语音合成,这也正是前面卖萌酱可以快速构建数字分身的关键。
一方面,从技术上来看,百度研发了跨模态跨领域的语音识别和语音合成一体化建模技术,通过被广泛用在语音识别中的隐马尔可夫技术捕捉语音合成中的韵律信息,使用大语音模型的建模技术端到端的完成语音识别到语音合成的一体化建模,再依赖于大模型的能力,结合Prompt技术,从而实现了无需微调,完全Zero-shot的方式快速生成自然、流畅的个性化合成声音。
而另一方面,从工程上来看,百度也摒弃了以往通过精确标注得到合成数据的路子,而是使用语音增强、说话人聚类和语音识别技术,对大量无标注语料进行自动挖掘和处理,从而获得了大量的丰富韵律的说话人数据,大大提升了模型的能力。

结合技术上的创新和工程上的改进,最终百度语音合成团队实现了上述那样准确、快速的个性化语音合成应用,生成的音频质量完美的保留了作为Prompt的音频数据的情感、风格和自然度,并且,这项功能还对不同年龄、性别的人群具备极高的鲁棒性,还是之前的例子,当儿童用童声原声时:
儿童原声,夕小瑶科技说,10秒
个性化语音合成依然可以保持完美的合成效果:
童声合成,夕小瑶科技说,7秒
而对于方言口音较重的用户:
方言原声,夕小瑶科技说,12秒
合成依然鲁棒!
方言合成,夕小瑶科技说,6秒
三、不仅仅是黑科技!更是落地应用!
2023年3月5日,长江日报的记者将下面这段音频播放给了83岁的薛三元老人:
雷锋合成声音,夕小瑶科技说,1分钟
“这个一听就是雷锋,很符合雷锋的讲话风格!” 薛三元老人如是说“他讲话比较快,就是一个湖南娃”。薛三元老人是雷锋的生前战友,曾担任过雷锋的班长和排长。在“AI还原原声·听雷锋读《雷锋日记》”活动上,利用百度语音合成团队提供的新一代面向AIGC的语音合成技术方案,成功让薛三元老人再次听到了雷锋的声音。

事实上,不仅仅是简单的让一个大模型或AI助理开口说话,面向更广阔的社会应用,语音合成技术还有广泛的可被探索的应用空间,除了让雷锋读雷锋故事,伴随着直播电商行业的发展,趋于白热化竞争的市场需要有新的突破口。而AI数字人,数字分身等技术也被认为是在这一庞大市场下,许多超级主播们的新的增长点。而除此之外,放眼更广泛的社会生活的方方面面,个性化语音合成技术还可以做到辅助教学、帮助听障人群、促进社区服务等等
而落地于这些方面,百度以及百度的语音合成团队已经探索了许多。相较于Voice Engine技术发烧友式的“突然出现”,在我们没有看到的地方,百度的语音合成技术已经积淀良久,在各个领域都探索了不同的应用。
其实,对于任何一项技术而言,除却它的“技术之美”以外,更多的还是要看它应用于社会各个方面对社会带来的改变,而这一点,其实要比许多在技术层面的刷榜秀肌肉要重要许多。
而从这一点出发,我们或许可以看到,百度想做的可能不仅仅是一个“AI黑科技”,也许更是希望实实在在把AI转化为生产力转化为驱动力,让AI真正推动社会发展,真正造福社会吧!


