
热门标签
热门文章
- 1xuniren(Fay数字人开源社区项目)NeRF模型训练教程_fay数字人搭建流程
- 2边缘计算盒子与云计算:谁更适合您的业务需求?
- 3这些年来,编程领域有什么重要进展?回顾过去,展望未来
- 4使用FileStream来读取数据_iformfile 读取文件内容
- 5抛弃torch.cat,拥抱AFF_aff注意力
- 6CUDA各版本官方下载地址_cuda12.0下载网址
- 7大模型和向量数据库怎么搭建 RAG 系统?Step by step 例子来了。
- 8spacy包及trained pipelines安装教程_spacy python包
- 9NeurIPS2023 大语言模型(LLM)方向优质论文汇总!_llm模型相关论文
- 102021-07/08收集字节跳动---Java提前批面试题_字节提前批面试 算法
当前位置: article > 正文
预训练语言模型概述(持续更新ing...)_预训练语言模型综述
作者:weixin_40725706 | 2024-04-05 08:04:54
赞
踩
预训练语言模型综述
1. 万物起源-文本表征和词向量
- 语言模型:对自然语言进行建模
序列化概率模型的思想,如在给定的语境下预测下一个词出现的概率
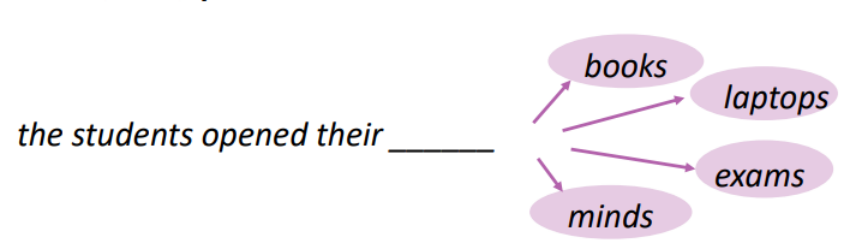
- n-gram语言模型:通过统计数据中给定词在长度为n的上文的条件下出现的频率来表征这些词在相应语境下的条件概率。
基本思路是基于给定文本信息,预测下一个最可能出现的词语。N=1称为unigram,表示下一词的出现不依赖于前面的任何词;N=2称为bigram,表示下一词仅依赖前面紧邻的一个词语,依次类推。

P ( w 1 , w 2 , … , w n ) = P ( w 1 ) ⋅ P ( w 2 ∣ w 1 ) ⋅ … ⋅ P ( w n ∣ w 1 , w 2 , … , w n − 1 ) P(w_1,w_2,\dots,w_n)=P(w_1)\boldsymbol{\cdot} P(w_2|w_1)\boldsymbol{\cdot}\dots\boldsymbol{\cdot}P(w_n|w_1,w_2,\dots,w_{n-1}) P(w1,w2,…,wn)=P(w1)⋅P(w2∣w1)⋅…⋅P(wn∣w1,w2,…,wn−1)
(马尔科夫假设) - 学习语言结构:人工标注然后分类
- 前向神经网络(FFNN)语言模型(维度灾难)和循环神经网络(RNN)语言模型(长距离依赖)
2. 万恶之源transformers
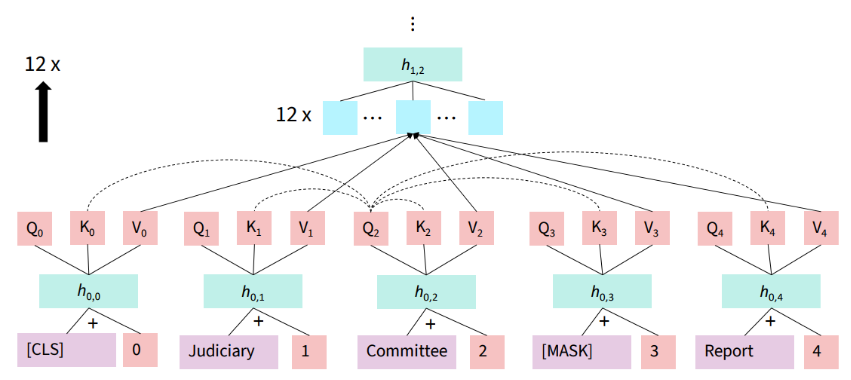
3. 训练目标
- Standard Language Model (SLM):用multi-class one-label分类任务范式,用autogressive范式,每次预测序列中的下一个token。常用于left to right模型,但也可以用于其他顺序。
- denoising objectives:对输入进行扰动,预测原始输入
- Corrupted Text Reconstruction (CTR):仅计算扰动部分的损失函数
- Full Text Reconstruction (FTR):计算所有输入文本的损失函数(无论是否经扰动)
其他各种Auxiliary Objective:
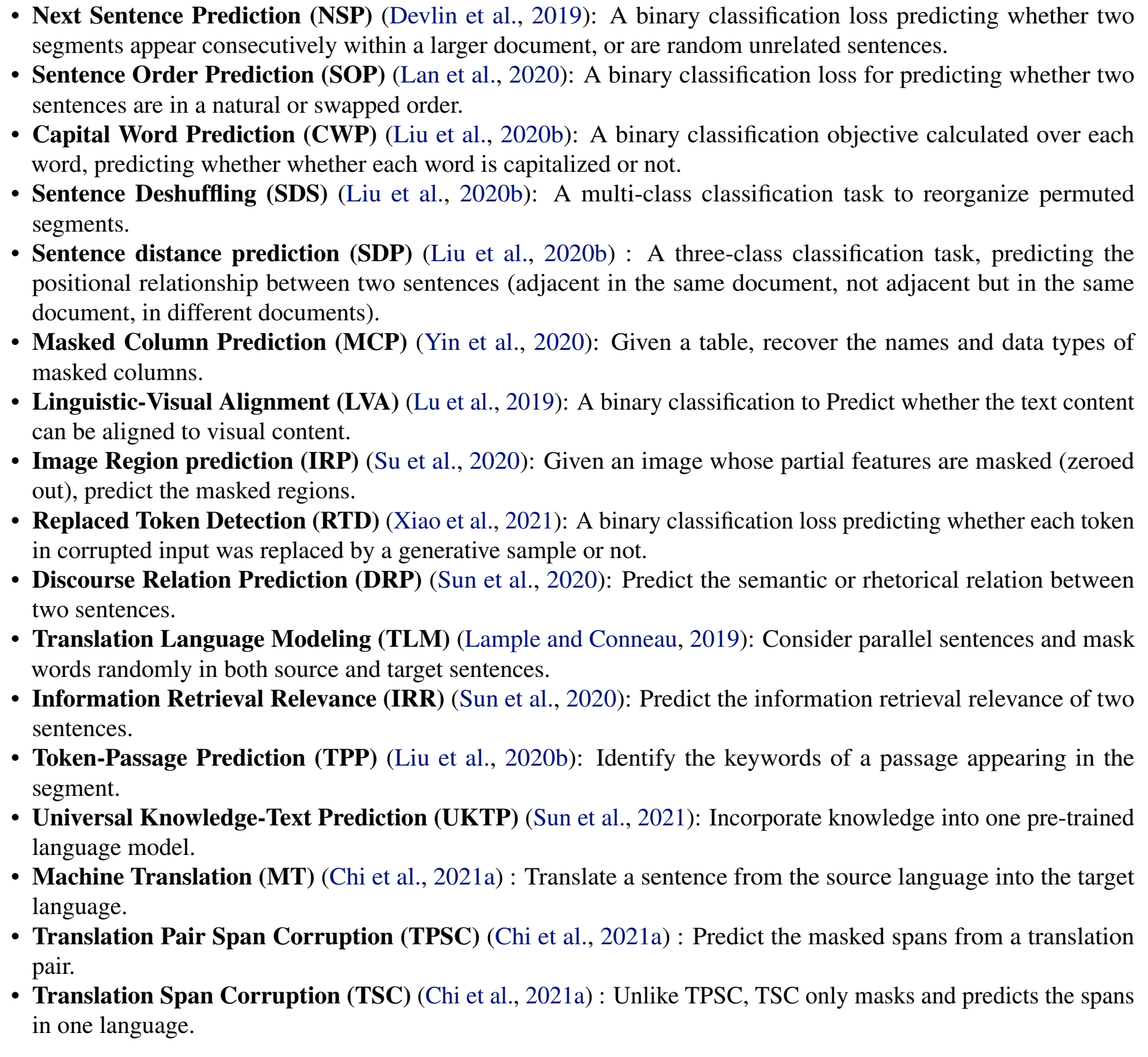

4. Noising Functions

- Masking:mask可以是根据分布随机生成的,也可以根据prior knowledge设计(如上图中的实体)。
特殊的掩码方式:全词掩码WWM(谷歌)、实体、短语(百度ERNIE)、n-gram掩码、动态掩码(RoBERTa)、基于语言知识的掩码(二郎神) - Replacement:span由另一种信息而非
[MASK]填充 - Deletion:常与FTR loss共用
- Permutation
5. Directionality of Representations
- Left-to-Right
- Bidirectional
- 混合
应用这些策略的方式:attention masking

6. Typical Pre-training Methods

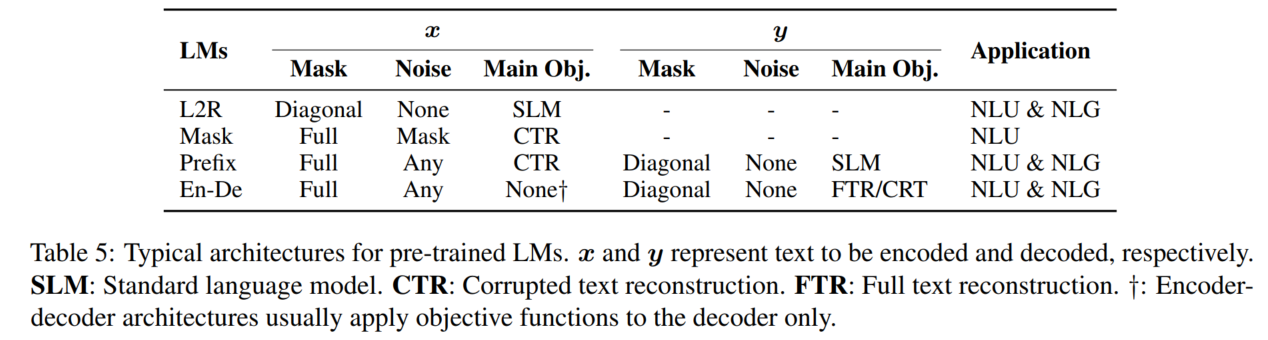
6.1 Left-to-Right Language Model
简称L2R LMs(AR LM变体)
预测下一个单词,或计算当前一系列单词出现的概率:

right-to-left LM类似:
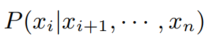
6.2 Masked Language Models
简称MLM
6.3 Prefix and Encoder-Decoder
用全连接mask编码输入,以AR方式解码输出。
- Prefix Language Model:在同一套参数下,输出部分是left-to-right,输入部分是全连接mask。输入部分常用CTR目标,输出部分常用标准conditional language modeling目标
- Encoder-decoder:与Prefix Language Model类似,但编码和解码用不同的模型参数
7. 各模型总结

我又写了一个新的博文。具体对这两个博文的合并和解耦工作以后再做吧,现在先凑合看好了:各种预训练模型的理论和调用方式大全

8. 其他transformer架构细节
- 位置编码
- 绝对位置编码APE
- 参数式相对位置编码RPE
- LN层的位置
- Post-LN
- Pre-LN(可去除warm-up学习率阶段)
- Sandwich-LN
- MoE层:该组件通过在网络中引入多个专家来减少需要激活的神经元数量,以此提升模型的计算效率
- 多粒度训练:指的是不同分词粒度
- 外部信息
- 命名实体(百度ERNIE)
- 知识图谱(百度ERNIE3.0,鹏城-百度文心,神舟)
- 语言学知识(Chinese BERT,孟子)
- 特定知识
- 多模态
- 高效计算
- 特定领域
- 英文预训练模型在中文语料库上训练且开源的中文版本
9. 本文撰写过程中使用的参考资料
- Pre-train, Prompt, and Predict: A Systematic Survey of Prompting Methods in Natural Language Processing
- 中文预训练模型研究进展:只对整体框架做了转述,具体内容还未在两篇博文中做详细概述
- 斯坦福大学Christopher Manning:Transformer语言模型为什么能取得突破:这是智源大会2020年的报告,我只看了文本,没看视频
10. 还没看,但是感觉可能会用得到的参考资料
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/364381
推荐阅读

相关标签

