
- 1深度学习处理器_,什么情况下指令级能在深度学习处理器中发挥作用
- 2Agx配置yolov5环境_2s-gcn runs文件夹权重文件下载
- 3android 命令行编译jar,Android Studio中gradle命令指定打jar包...
- 4Linux之环境变量_linux 环境变量
- 5Python数值插值和曲线拟合_python外汇远期曲线插值
- 6在有序数组中,统计某一元素出现的次数_统计有序数组里出现的次数c语言
- 76.1 函数(1) (素数、牛顿迭代法求平方根)_迭代法求素数
- 8SAP Fiori的ABAP编程模型-在Fiori中使用Fiori Elements讲解_abap fioir
- 9Appium Desired Capabilities 学习备注_appium中 'desired_capabilities'的报错
- 10SQLiteC/C++接口详细介绍sqlite3_stmt类(十三)
web前端高频面试题:如何保证Redis缓存与数据库的同步?_redis如何实现与数据库保持同步
赞
踩
今天老朱要给大家分享一道关于数据库缓存同步的面试题,希望通过这道面试题可以帮助大家搞定面试官。
一. 数据缓存
数据缓存在高并发的系统设计中很常见,因为Redis确实能有效地解决数据库和磁盘的I/O瓶颈,当一个高并发接口要查询低频修改的数据时,我们都建议用Redis实现数据缓存。
一般的缓存实现思路如下:
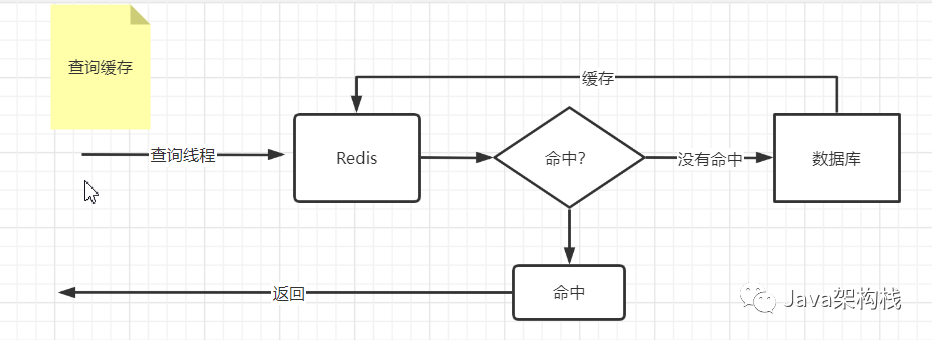
其实缓存的实现思路很简单,这个思路能保证只有第一次查询的是数据库,后续的访问查询的都是Redis,这样不仅提高了接口的访问效率,还在一定程度上实现了数据库的读写分离。
那么现在问题来了,如果我们的数据库数据发生了变化,Redis怎么保证和数据库里的数据一致呢?这个问题就是我们今天要探讨的缓存同步问题。
二. 缓存同步分析
缓存同步这个思路相信大家很快就能搞清楚,大概思路如下:

当我们对业务库做了修改,我们可以通过同步更新的方式去同步,也可以通过暴力删除Redis的方式去同步。因为删除Redis,会再次查询数据库的最新数据,这样就可以达成同步的目的。但不管你使用哪种方式,都会存在一些意想不到的问题,如下:
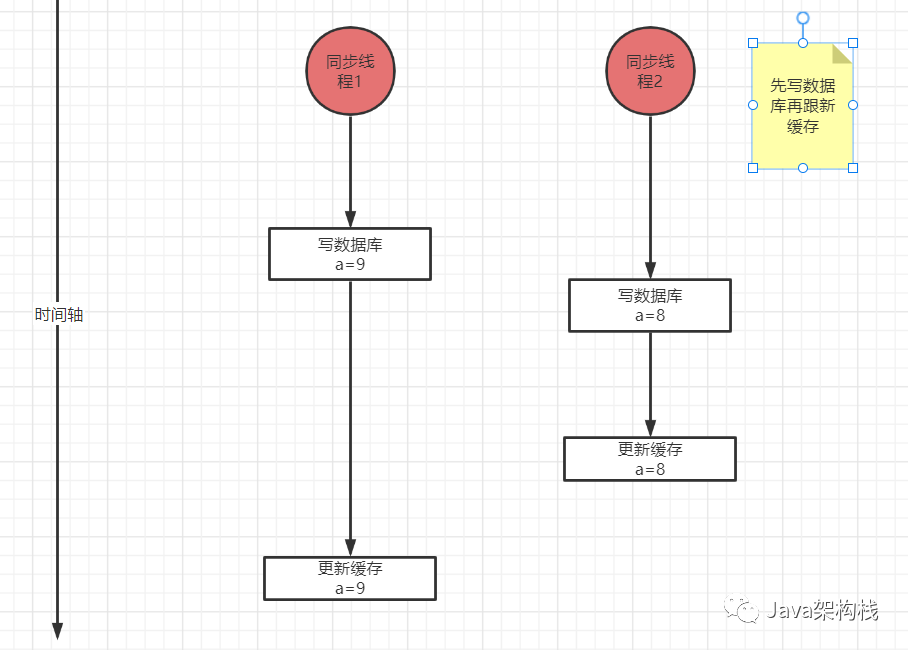
先写数据库,再更新Redis,上图中演示了一种极端情况,按照时间轴的发展,数据库里的最新值是8,但Redis中的最新值是9,并没有一致。

如果我们先更新Redis,再写数据库,按照时间轴,Redis里的最新值是8 ,数据库里的最新值是9,还是没有保持一致。
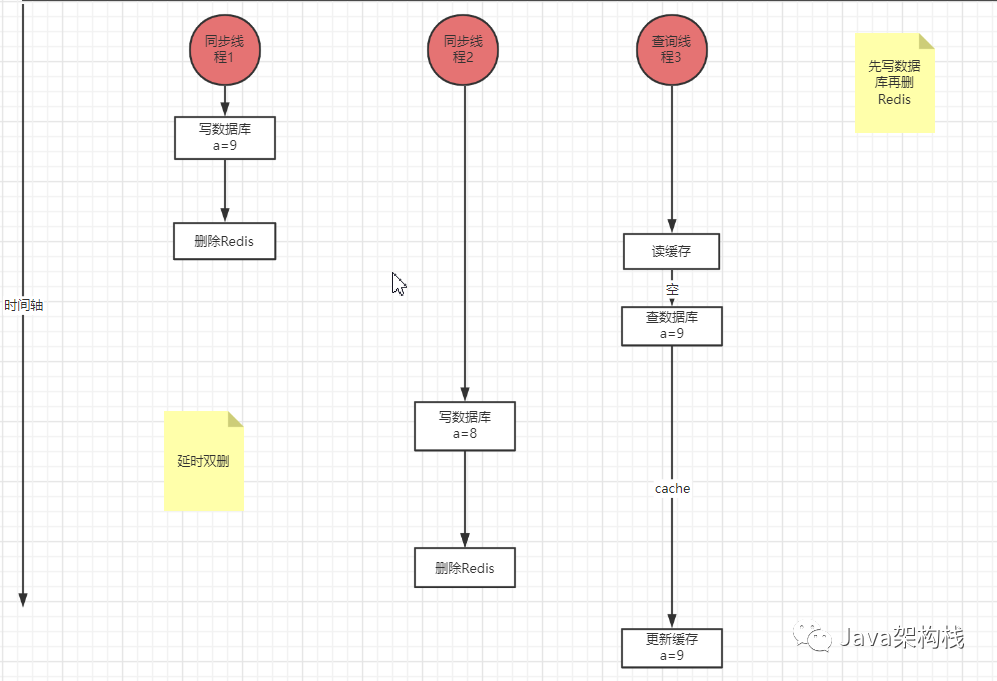
先写数据库,再删Redis,这也不行。
如上图,当数据库里的值为9,然后再删Redis。假如这时有一个读线程来了,发现Redis数据没了,这个读线程立即查询数据库,读到的就是9。然而不巧的是另外一个写线程将数据库改为8 ,也就是说数据库最新为8,结果缓存发生在更新数据库之后,缓存最新的值就是9,还是不能一致。
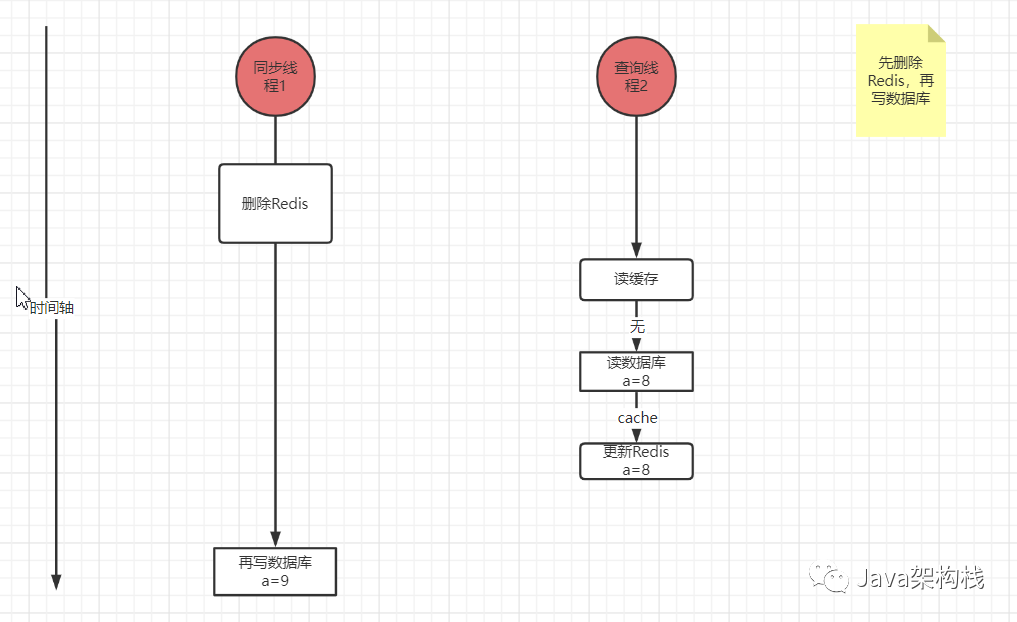
如果我们先删Redis再写数据库,写线程上来把Redis删了,读线程立即读数据库,比如读到的旧数据是8,然后写线程再改数据库为9,这时数据库最新为9,但Redis中的值是8,结果还是不一致。
三. 缓存同步解决思路
上面分析了四种情况,它们在极端情况下都不能保证数据库和Redis的双写一致性,那到底为什么不能呢?问题到底出在哪里了,其实原因很简单,就是我们不能保证数据库和redis操作的原子性!在我们进行这两个操作时,总是有别的线程在破坏数据,所以才会出现各种问题,那怎么解决呢?我们先来看看下面的解决思路:

这个思路大致是这样的,写线程只负责改数据库,不要去参与Redis同步的问题,Redis同步交给一个严格顺序的pipeline解决。这个pipeline的流程是,当数据库发生数据变化会立即产生binlog日志,我们可以借助阿里的canal组件去监听binlog,同时解析binlog,将解析的结果以消息的方式发送给MQ。MQ要保证严格顺序,再通过消费者去消费消息,将最新的数据覆盖更新到Redis,到此就能解决缓存的同步。
四. 落地实现
至于缓存与数据库同步的具体实现代码,因为内容太多,也有点复杂,通过文字描述不是很清楚,大家可以参考老朱的免费视频,链接如下:
https://www.bilibili.com/video/BV1Ui4y1P7rk?p=21&vd_source=38e1109a5988dacfa2c0311dc12c4c2c
https://www.bilibili.com/video/BV1Ui4y1P7rk?p=22&vd_source=38e1109a5988dacfa2c0311dc12c4c2c
*威哥Java学习交流Q群:691533824
加群备注:CSDN

