
- 1【NLP Tool -- JieBa】Jieba实现TF-IDF和TextRank文本关键字提取(附代码)_python 使用jieba,将下列一段文字分别利用tf-idf和textrank算法提取关键词,并
- 2在 WordPress 中使用 AI 改善 SEO 的 10 种方法
- 3Eclipse的CDT插件配置_eclipse cdt
- 4新兴技术成熟度曲线
- 5Java动态导出excel列_java导出excel动态列
- 6明翰全日制英国硕士学术写作V0.1(持续更新)_假设和倾向(assumptions and biases)怎么写
- 7PyTorch-----torch.flatten()函数
- 8Bert 结构详解_bert的结构组成
- 9【CSS】css转换、css过渡、css动画_09_css变换和过渡
- 10论文中的实验环境配置_论文运行环境
ECCV 2022 | 融合全局和局部注意力的场景文字检测方法
赞
踩

©作者 | Hanbo Cheng
单位 | NJUST
研究方向 | 场景文字检测

论文标题:
GLASS: Global to Local Attention for Scene-Text Spotting
论文链接:
https://arxiv.org/abs/2208.03364

Abstract
本篇文章针对端到端的 Scene-Text Spotting 任务,提出里一个新颖的 Module :GLASS (Global-to-Local Attention mechaniSm for text Spotting)。这个模块结合了 image 中的 global feature(大尺度,低分辨率)和 local feature(小尺度,高分辨率)对任务进行端到端的训练。同时文章还提出了一个新的基于旋转的损失函数,优化了模型对旋转字体的识别。通过实验,该模块和损失函数可以显著增加现有模型的 performance。
文章试图解决什么问题?
端到端的 Scene-Text Spotting 的一个主要挑战是文字尺度的变化(large text/ small text),以及文字存在旋转角度。
文章主要的贡献
提出了新颖的 GLASS 模块,在极端尺度变化的情况下增强了模型的性能;
设计了一个周期的,针对旋转的损失函数(具体是正弦函数的形式),增强了模型对于任意旋转角度的 scene text 的 Spotting 性能;
在几个数据集上 ICDAR 2015, Total-Text, TextOCR,Rotated ICDAR 2013上取得了 SOTA 的结果;
将 GLASS 模块应用到现成的 Scene Text Spotting 框架上,使得这些模型的性能得到了提升(说明来 GLASS 的泛用性)。

Methodology
论文中的模型结构如下:
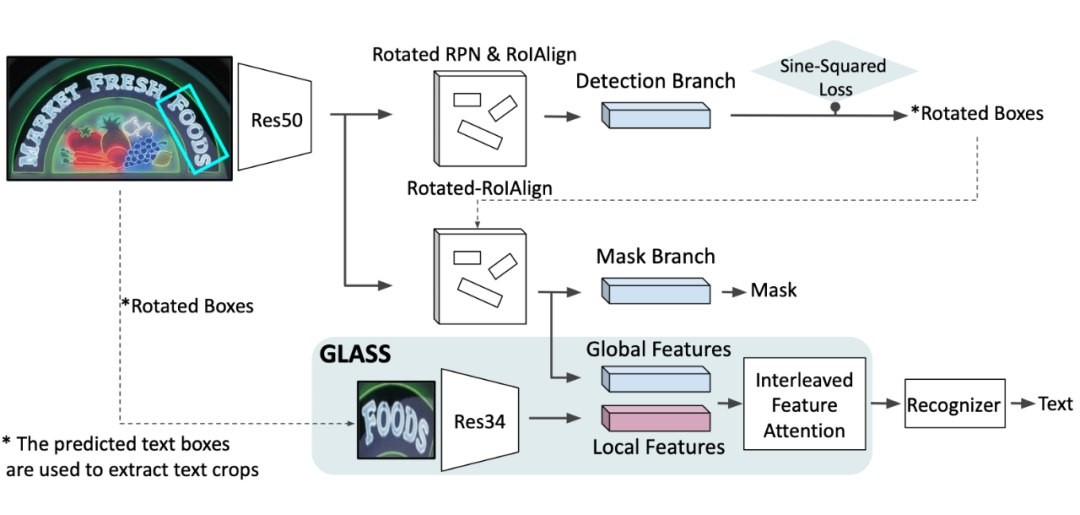
2.1 GLASS
GLASS 主要针对的分支是 recognition branch,这里是 GLASS 中的运算示意图:
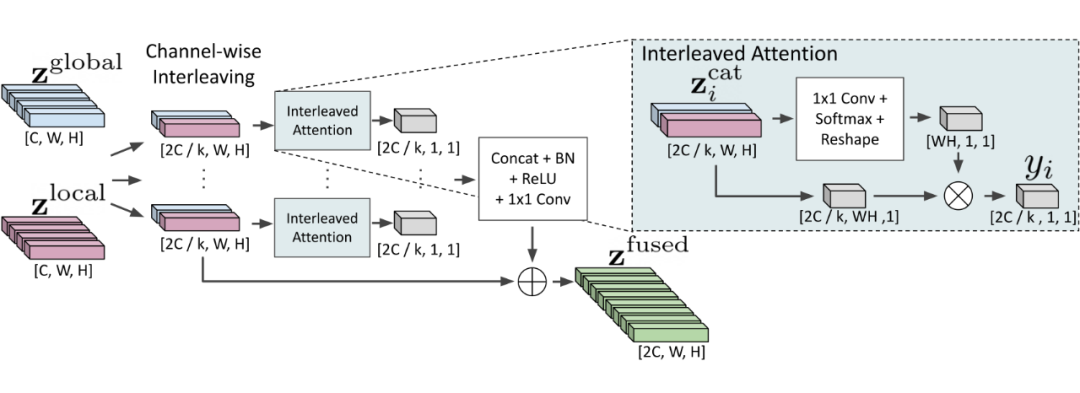
首先关于 Global feature 和 Local feature 从何而来?也就是 , 。
Global 特征来自 detection 分支(具体是 FPN feature),具体特征的采样范围仍然受 bbox 限制,但通过 FPN 各级采样,其感知域比 local feature 要大
Local 特征来自于 detection 分支生成的 bbox,因为只有一个选框,所以分辨率更高(主要针对小尺度 text)。
2.2 Global和local的融合
● first
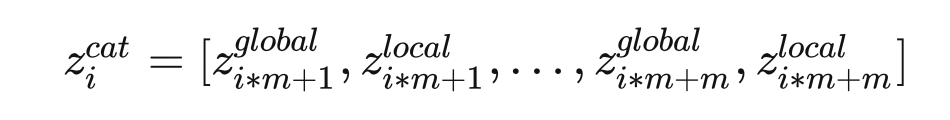
用文字概括一下:原本 , 的大小都是 ,现在将他们的 Channel 分成 k 等分,,再将他们以上述的形式 concat 起来, 最终变成 channel 为 的向量(共WH)。
● second
这一部分将简单的 concat 深度的 fuse:
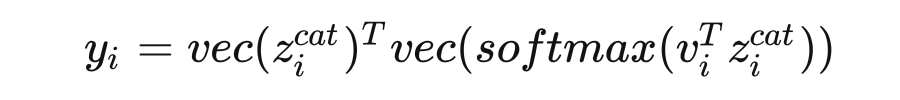
其中 是一个可学习的向量, 将 tesor reshape 成 的形式。
这一步相当于通过注意力机制得到一个初步融合的特征 。
● third
这一步:
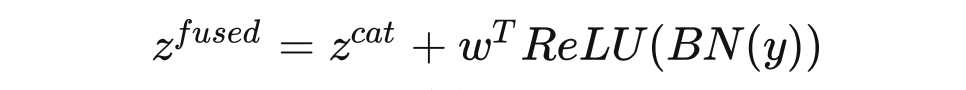
其中 是一个可学习的向量,实际上就是一个 1*1 的卷积, 是批标准化。
2.3 Orientation Prediction
本文针对一个 bbox 设置了 5 个描述参数,2 个描述中心坐标,2个用于描述 H,W,1 个用于描述旋转角度,整个 bbox 的 loss function:
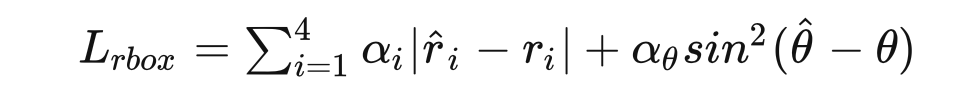
这个损失函数,针对前四个参数采用了 L1 norm,针对角度,设计了一个基于正弦函数的 loss,不难看出有这样的特性,偏移 k*180 的 loss=0,并且这一部分是可以求导的。同时满足了合理性和可导。
2.4 Global to Local End-to-End Text Spotting(模型总述)
整个模型的 backbone 是 ResNet50 和 FPN。 通过是哦那个 Rotated-RoIAlign,在 FPN 的各个层级上采样得到。对于 先对输入图像做 Rotated-RoIAlign,再使用 ResNet34 抽取特征得到。使用上述的 GLASS 得到融合特征 用它完成 text 的 recognition。关于 mask branch,仅仅采用了 global feature(这一点和 Mask R-CNN 的处理基本一致,应该不是文章的重点)
模型的总体优化目标:
:选框 loss
:mask loss,和 mask R-CNN 一致
:recognition loss

Experiment
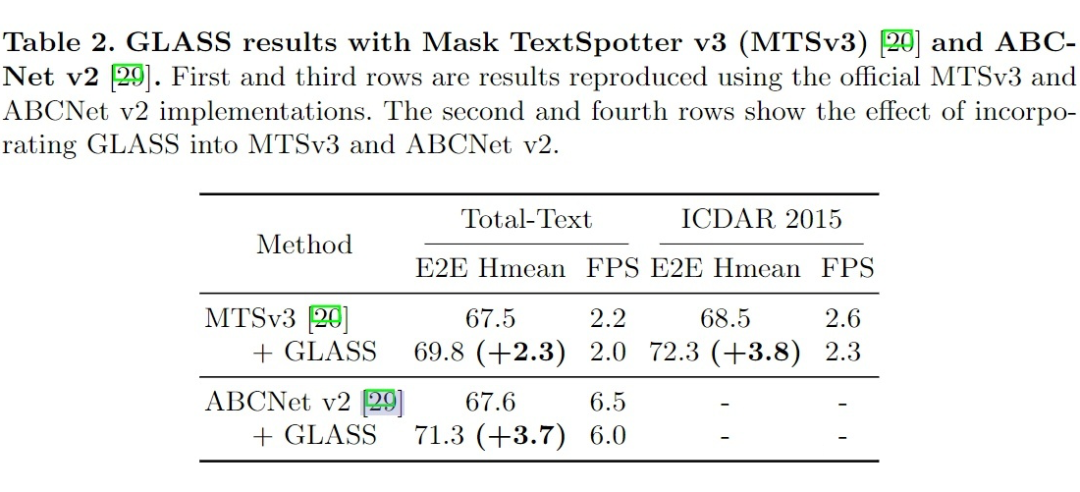
文章在几个 benchmark 上测试了方法的表现,并且和 SOTA 模型做了比较。同时,文章也尝试将 GLASS 融合进了两个较为常见的 E2E,Scene-text spotting 网络(Mask TextSpotter v3, ABCnet v2),并测试了融合后的性能。此外又做了一些消融实验。
3.1 Comparison with SOTA
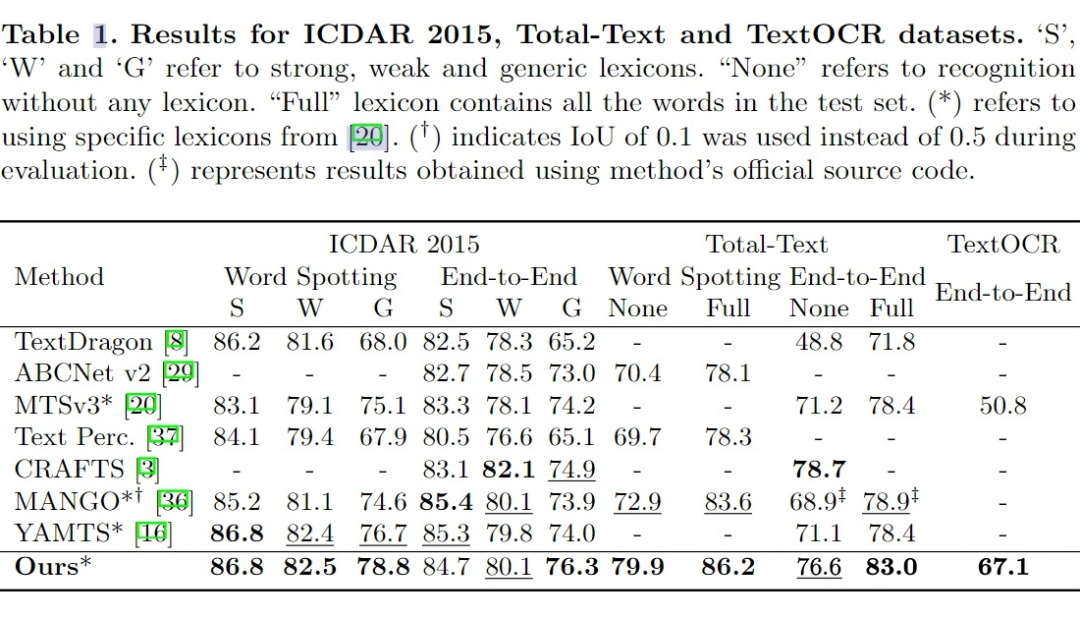
针对不同的文字旋转角,和别的模型对比 performance,可以看出 GLASS 能很好的应对旋转过的文字。
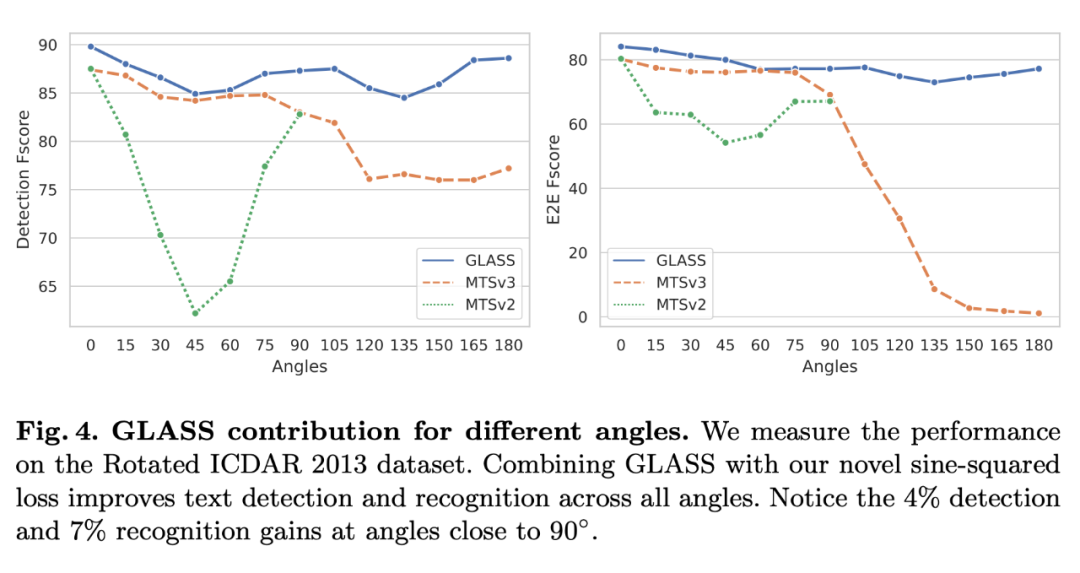
3.2 Incorporating GLASS into other methods
可以看出,加入了 GLASS 之后,其他模型在 Total-Text 和 ICDAR2015 数据集上都有提升,尽管处理速度些许变慢。
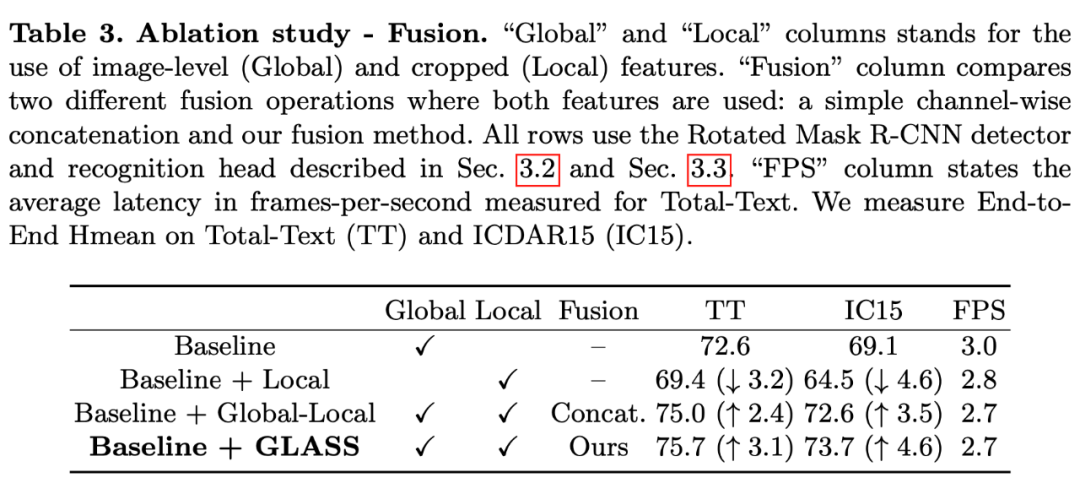
3.3 消融实验
关于是否使用 Global 和 Local feature,以及是否 fuse 它们,和以什么样的方式 fuse 做了消融实验。可以看出采用全局和局部特征+ GLASS 融合,可以取得最好的表现。
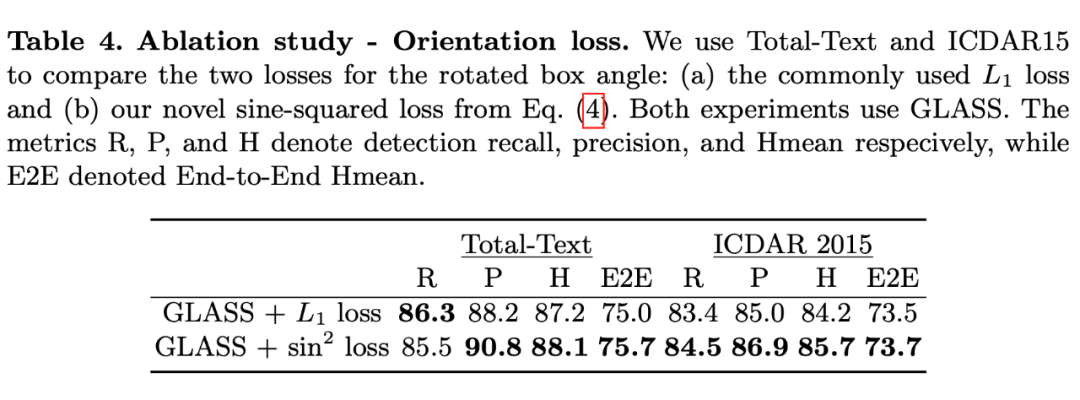
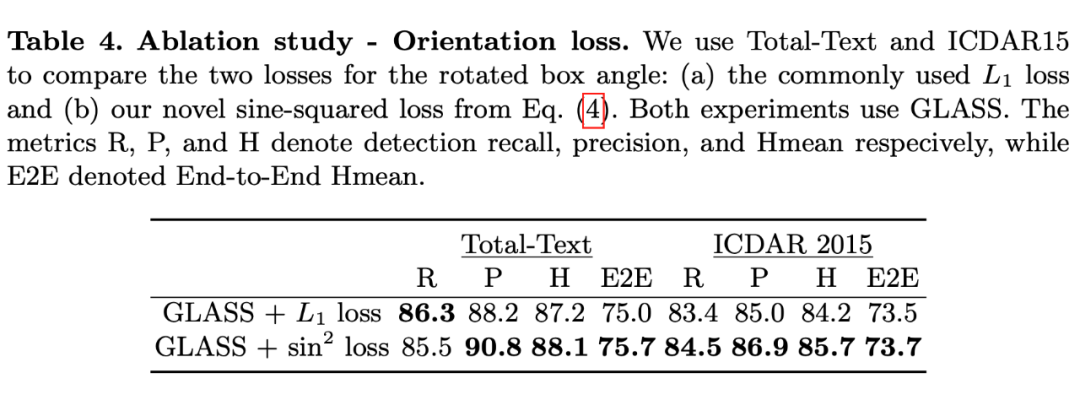
针对 bbox 的损失函数做了消融实验,主要是是否用基于正弦的方式计算角度的 loss,还是说使用 L1norm。可以看出基于正弦函数的方法明显更优。
GLASS 对于识别不同尺度文字的影响,可以看出增加了 GLASS 以后,对于各种尺度的文字识别,performance 都有提升。
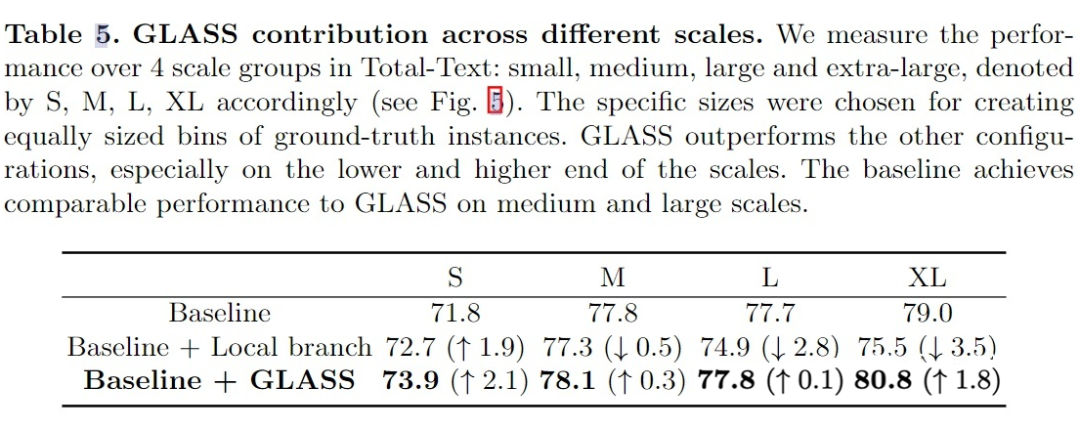

仅仅针对 recognition branch 做的消融实验,这里使用 ground truth bbox,消除 detection branch 的影响。可以看出 GLASS 对于 recognition 有提升。


Rethink
1. 本文针对尺度不同,以及旋转角的问题做了一些特化的设计,并取得了不错的效果。这里提到的使用 FPN 提取 Global 特征(low resolution),使用直接的 feature map 提取 local 特征,再将两组特征加以融合的方法十分值得学习。再以后遇到 scale 方面的问题,或许可以采用类似的思路。
2. 文章结尾提到:在一些场景文字,各个字符间隔较大时,以及遇到一些不规则的字体时,模型会出现误判,这也是未来的一个努力方向。

一些误判样例:
针对第一个问题:我认为主要还是尺度的问题,以及卷积感知域的问题。字符本身的尺度相较于单词的尺度太小。或许可以采用类似 ViT 的一些方法(让我想到了 SwinSpotter 那篇文章),利用 transformer 可以将两个较远的像素点产生联系的特性处理这个问题。但这个问题显然更加复杂,因为两个相隔较远的字符,去判断他们属于一个 word,似乎需要一些先验知识的支持。
关于不规则字体:之前读过一篇基于知识图谱,通过 scene-text 完成 img captioning 任务的文章(knowledge Mining with SceneText for Fine-Grained Recognition),或许图片也可以反作用于文字,比如说这个 Flower(第二行第三个),似乎根据图片可以做一些 inference。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

