- 1【机器学习基础】无监督学习(5)——生成模型_数据生成模型
- 2微信小程序_微信开发者工具开启多个页面
- 3毕业设计超市进销存管理系统源码
- 4Mac OS下JDK1.7安装_mac os jdk1.7
- 5Android Studio ——在不root手机的情况下读取Data目录下的文件_adb查看文件目录
- 6构造c语言的上下文无关文法,正则文法和上下文无关文法
- 72022华为软件精英挑战赛比赛经历
- 8yolov5 过拟合 欠拟合_yolo 欠拟合
- 9鸿蒙开发 - 状态管理之@Observed和@ObjectLink
- 10Linux 十四 修改文件操作权限 用户文件权限详解_14.修改linux权限每个数字代表的含义
知识图谱论文阅读(十八)【KDD2019】AKUPM: Attention-Enhanced Knowledge-Aware User Preference Model for Recommend
赞
踩

论文题目: AKUPM: Attention-Enhanced Knowledge-Aware User Preference Model for Recommendation
论文代码:
论文链接:
想法
- 什么叫折射到关系空间? (添加了一个关系矩阵,但是关系矩阵为啥要加?)
- 什么叫做自适应?
- 其中 h v u , m 0 h_{v_{u,m}}^0 hvu,m0表示和item v u , m v_{u,m} vu,m连接的实体。如果为0,则表示是历史点击的初始items
创新
(1)提出了崭新的基于自适应自注意力模型,同时是第一次将用户和被包含的实体的交互分为两种的;
(2)通过将实体映射到关系空间和利用自监督机制,intra(使用关系矩阵)和inter(自注意力模型,就是会考虑用户交互过的item之间的关系)将会被描述。 这样AKUPM能够找到和每个用户包含的实体最相关的。
摘要
难点:
KG的引入确实一定程度改变了冷启动和稀疏问题,但是也包含了许多不相关的实体来表示user的嵌入。 很多论文并没有意识到该问题。
我们:
探索这些实体之间的交互!从而根据交互区别对待生成相关特征。
首先: 我们将实体之间的交互分为了两种:inter-entity-interaction和intra-entity-interaction。 Inter-entity-interaction是实体之间的交互,它影响实体代表用户的重要性; intra-entity-interaction当涉及到不同的关系时,一个实体就会有不同的特征。 (如果还是有点抽象,可以看Introduction中的举例)
考虑这两种交互,我们提出了AKUPM模型来进行点击率(CTR)预测,具体地说, Inter-entity-interaction,自注意力网络会被用来通过学习每个实体与用户之间适当的重要性来捕获实体间的交互; 此外,intra-entity-interaction通过将每个实体映射到其连接的关系空间中来获得该实体的特征,从而对实体内部的相互作用进行建模。
评价指标: AUC、ACC和Recall@top-K
1. Introduction
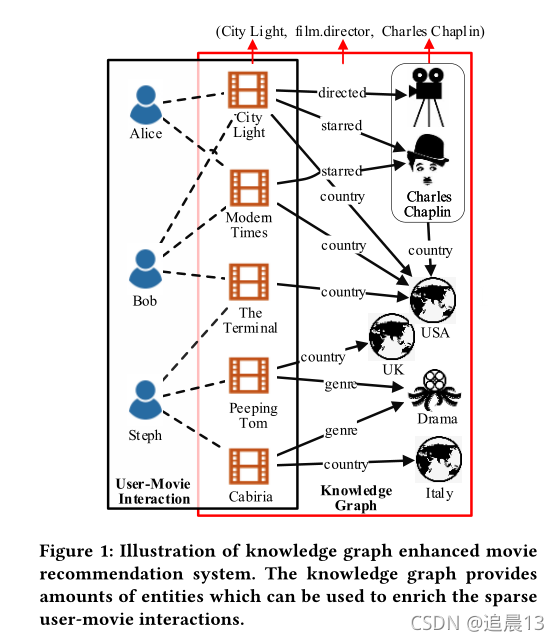
前人的缺点:
DKN(CNN)和RippleNet都利用KG来丰富在RS的users/items的表示。然鹅,图中包含的实体本身与items/users之间的关系并没有被研究,因此推荐结果可能会受到一些不相关的合并实体的影响。
以电影推荐为例,每个用户都由KG中与之相连的实体决定,而它们之间的交互可以从两方面定义:
1)Inter-entity-interaction: (出发点是别的实体对用户的影响)由于实体之间的相互作用,一个实体包含在不同的实体集中时,其重要性会有很大的差异。比如上面的图中,对于Bob来说,看的电影基本都来自USA,而对于Steph而言,来自各个国家,那么USA实体对Bob的影响要高于Steph。
2)Intra-entity-interaction:(出发点是自己,自己对不同电影的喜好)对于特定的用户,实体在涉及不同的关系时可能会表现出不同的特征。比如上图中,Alice喜欢City Lights 因为Charles Chaplin是该电影的导演,那么她可能喜欢Modern Time,因为Charles Chaplin是该不的主演。
整个模型架构是: 给定user-item pair,AKUPM的目的就是预测CTR(点击率)。 首先初始化: 一个用户的表示将会被和用户点击过的items所丰富。 而这些被点击的items将会被初始化,然后沿着KG从近到远的传播。 这样,就可以初始化user和其点击的items。 其次再进行inter\intra-entity interaction! 我们的贡献主要被总结如下:
(1)提出了崭新的基于自适应自注意力模型,同时是第一次将用户和被包含的实体的交互分为两种的;
(2)通过将实体映射到关系空间和利用自监督机制,intra和inter将会被描述。 这样AKUPM能够找到和每个用户包含的实体最相关的。
2 RELATED WORK
2.1 Knowledge Graph Embedding
自行看论文综述! TransE、R等等! 本文使用TransR
2.2 Attention Mechanism
在本文中,我们提出使用注意机制来探讨输入item与被整合实体之间的关系。此外,引入自注意机制,通过给每个实体分配适当的权重,在关联实体集合下生成被包含实体的表示
2.3 Knowledge-Aware Recommendation
也可以去看综述! 包含了分开的,基于路径的,基于两种方法的!
3 PRELIMINARIES
常见的定义,user集合、item集、交互矩阵; 知识图谱G、三元组、交互矩阵中实体和知识图谱中实体的对应。
最终的目标就是CTR:

4 提出的方法
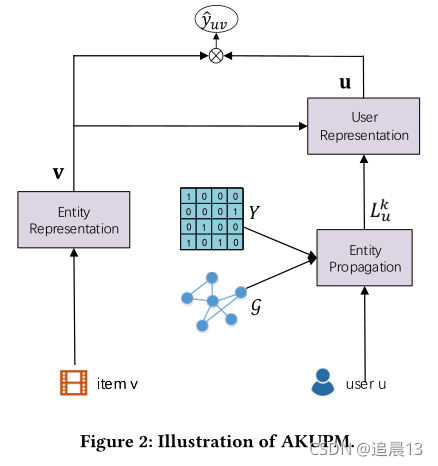
上图显示了AKUPM的整体框架,对于一个用户而言,为了包含从一个KG中包含与他相关的丰富的实体从而探索他的兴趣,一个基于用户点击历史的特殊设计的实体传播(4.1)将会被用于包含许多的实体。 接下来为了描述这些被包含的实体之间的intra-entity-interactions,我们建议将实体嵌入到关系空间中(4.2)。 为了对inter-entity-interactions进行建模(4.3),我们应用一个自注意网络来获得每一组实体的表示。这样实体的表示更新完了,,我们提出应用一个注意网络根据输入item来表示user,通过聚合具有适当权重的实体表示。最后,根据输入用户和输入项的潜在表示进行CTR预测。
4.1实体传播
实体传播的说明。所有灰色圆圈表示合并实体。不同蓝环的实体属于不同的对应实体集。

不是所有的实体都对用户有用,所以为了过滤这些噪音,我们建议合并从用户点击历史沿着知识图的关系传播的实体,这样每个合并的实体都与用户相关。

原始的实体传播的定义为:
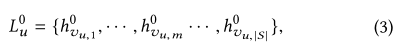
其中
h
v
u
,
m
0
h_{v_{u,m}}^0
hvu,m0表示和item
v
u
,
m
v_{u,m}
vu,m连接的实体。如果为0,则表示是历史点击的初始items。 然后
L
0
L^0
L0中的实体可以伴随着relation来迭代的传播,这样可以达到更多联系的实体。 然后我们定义实体的
k
t
h
k^{th}
kth集合如下:
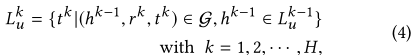
4.2 Entity Representation(intra-entity-interactions)
我们首先应用TransR初始化实体。对于每个三元组 ( h , r , t ) ∈ G (h,r,t)\in \mathcal{G} (h,r,t)∈G中的h、r和t都被初始化为d维度向量。 对于每个关系r,我们设置一个投影矩阵 R ∈ R d × d \mathrm {R}\in \mathbb{R}^{d \times d} R∈Rd×d,它将实体从实体空间映射到对应的关系空间(是一个要学习的矩阵,是一个参数),如下所示:

上面将头和尾都转化为关系空间。
而对于初始的items(用户点击的items),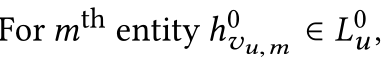 ,是没有关系被嵌入的(这里看出是传入的关系,而不是传出的关系)。 所以这个实体只是它本身的嵌入:
,是没有关系被嵌入的(这里看出是传入的关系,而不是传出的关系)。 所以这个实体只是它本身的嵌入:

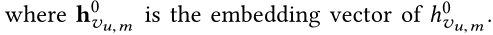
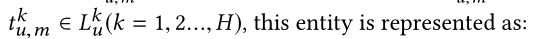

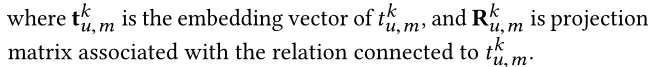
除此之外,输入item v的表示
v
\mathrm{v}
v是不投影到关系空间的:

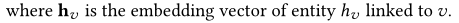
综上:除了用户历史点击的原始items和输入item之外,其它都需要经过关系矩阵
4.3 Attention-based User Representation
常用方法:
对于H+1实体的集合
L
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
L_u^k(k=0,1,...,H)
Luk(k=0,1,...,H),一个常用的方式来生成用户的表示
u
\mathrm{u}
u就是充分利用这些实体集合的表示,也就是
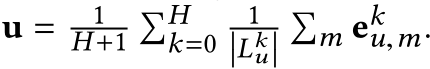
上面的
e
\mathrm{e}
e是我们添加了intra-entity(乘关系矩阵后的)的实体表示!!
而
L
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
L_u^k(k=0,1,...,H)
Luk(k=0,1,...,H)是所有的邻居哦!
所以上面的式子就是把所有的和u相关的都聚在一起求平均! 这是没有考虑inter-entity的!
作者的方法: (分成两组,每组一个聚合)
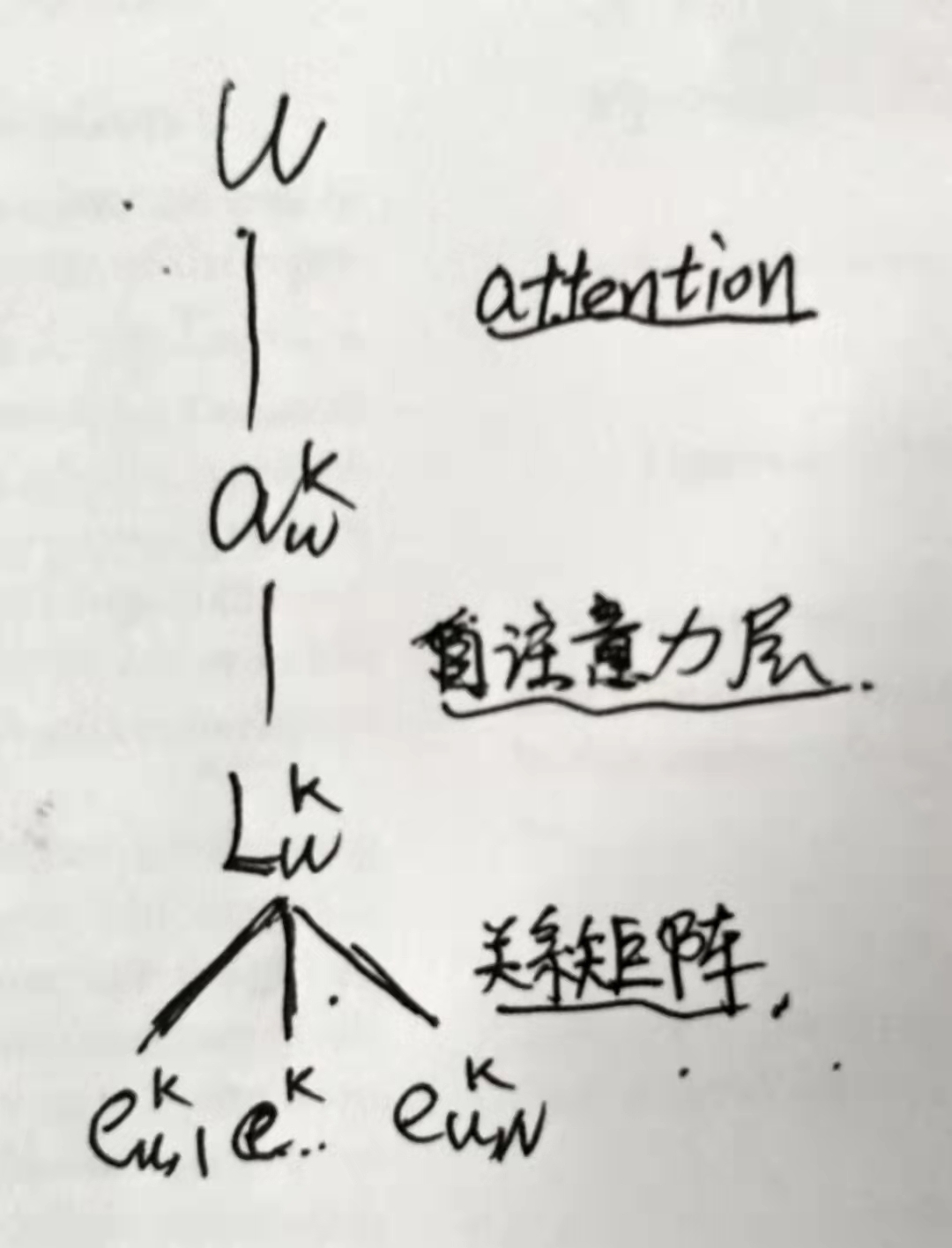
然而,这种方法忽略了第1节中讨论的inter-entity-interactions。
首先,我们对每组
L
u
k
L_u^k
Luk应用一个自注意力层来学习一个潜在的表示
a
u
k
a_u^k
auk,捕获其实体之间的交互后来更新它;其次,得到
a
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
a_u^k(k=0,1,...,H)
auk(k=0,1,...,H)后,不管这个输入item
v
v
v,我们需要添加一个注意力network来计算每个
a
u
k
(
k
=
0
,
1
,
.
.
.
,
H
)
a_u^k(k=0,1,...,H)
auk(k=0,1,...,H)的重要性。而这表示了用户对不同输入item的不同兴趣(因为这里的每一层邻居从外到内聚合的话,基本每个item代表了一种风格!)。
-
自注意力
首先什么是attention mechanism和self attention? 注意力机制可以描述为将query和一组key-value pairs映射到输出。输出是values的加权和计算得来的,其中分配给每个value的权重是通过查询和相应key的兼容性函数(兼容性分数,可以为内积计算的)。 在自监督中,the query, key and value 都是一样的。
(这里的兼容性函数其实就是查询集和key的点击,查看两个的相似度)
在我们中,我们采用了一个scaled dot-product 注意力。 整个的为 a u k a_u^k auk的计算过程在下图展示。
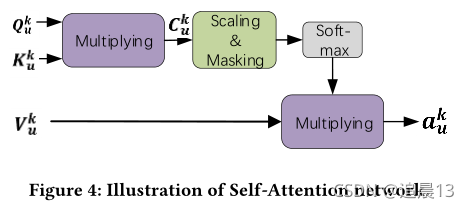
其中,对于每个 L u k L_u^k Luk,查询集 Q u k Q_u^k Quk、键值 K u k K_u^k Kuk和值 V u k V_u^k Vuk都是从 e u , m k e_{u,m}^k eu,mk得到的!
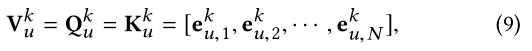
其中N是邻居实体的数量,而且是一个超参数。 如果 ∣ L u k ∣ ≥ N \left | L_u^k \right | \ge N ∣∣Luk∣∣≥N,那么就该随机从中选N个;相反,则需要全部设置为Null(也就是zero vectors)。
兼容性函数查询集 Q u k Q_u^k Quk和键值 K u k K_u^k Kuk之间的被这样计算:


最终对每个 a u k a_u^k auk上应用softmax函数:
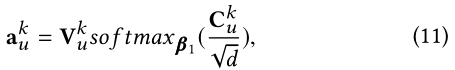
d \sqrt{d} d 用于缩放兼容性矩阵(兼容性分数),以避免式子10中的点积变得过大。 最后softmax 函数最终计算每列 e u , m k ∈ V k ( m = 1 , . . . , N ) e_{u,m}^k \in V^k(m=1, ...,N) eu,mk∈Vk(m=1,...,N)的权重,
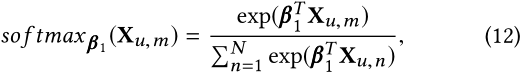
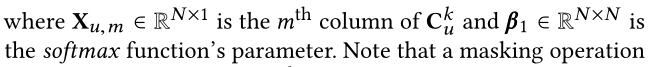
注意这里我们在softmax之前,会进行masking操作(也就是 C u k C_u^k Cuk的对角线都设置为0),这样可以避免兼容性分数太大。 -
注意力机制
在根据式子11得到权重总和后,我们获得了潜在表示 a u k ∈ R d , ( k = 0 , . . . , H ) a_u^k \in \mathbb{R}^d,(k=0,...,H) auk∈Rd,(k=0,...,H)。 和 a u k a_u^k auk是由 e u , m k e_{u,m}^k eu,mk的权重总和得到一样, u \mathrm{u} u也是由 a u k a_u^k auk的权重总和得到的。
和上面一样,查询集 Q u k Q_u^k Quk、键值 K u k K_u^k Kuk和值 V u k V_u^k Vuk被这样定义:
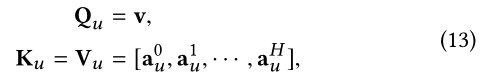
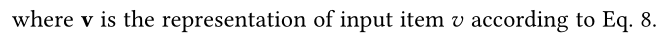
这样u和式子11一样,被这样计算:
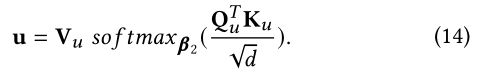
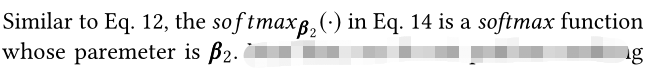
这里,我们不会使用masking,因此查询集和key集合不相同。
最后,根据用户的表示量和项目的表示量v,计算出预测的CTR

5 LEARNING ALGORITHM
给定user-item的交互矩阵
Y
Y
Y和知识图谱
G
\mathcal{G}
G, 目的是学习AKUPM的最优参数
假定
Θ
\Theta
Θ表明AKUPM中所有的参数,这里包含了h、t、r的嵌入,前面说的关系映射矩阵(映射空间)
R
\mathrm{R}
R,自注意力网络的参数
β
1
\beta_1
β1和注意力网络的参数
β
2
\beta_2
β2,在观察了
G
\mathcal{G}
G和
Y
Y
Y后,我们希望最大化参数
Θ
\Theta
Θ的后验概率:
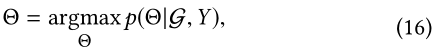
这个等价于最大化下面的:
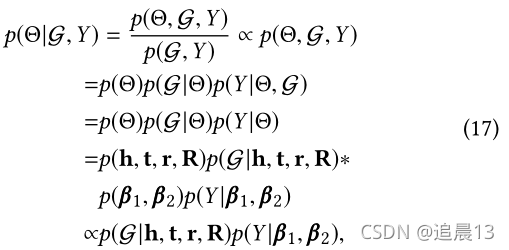

下一节讲解评估知识图谱和隐式反馈的优化细节
5.1 Likelihood of Observed Knowledge Graph and Implicit Feedback
对于三元组
(
h
,
r
,
t
)
∈
G
(h,r,t)\in \mathcal{G}
(h,r,t)∈G,我们根据下面的工作,并定义分数函数:
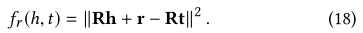
上面的都放到了关系空间中!
我们会随机地取消tail实体,从而组成新的知识图谱
(
h
,
r
,
t
′
)
∉
G
(h, r, t') \notin \mathcal{G}
(h,r,t′)∈/G,然后创建新的知识图谱
G
′
\mathcal{G}'
G′,这样一个四元组
(
h
,
r
,
t
,
t
′
)
∈
G
′
(h, r, t, t') \in \mathcal{G}'
(h,r,t,t′)∈G′,并且计算它的似然估计,
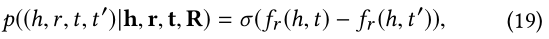
因此,观察到的知识图的似概率可以描述为:
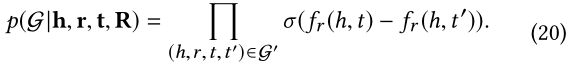
对于每个属于矩阵 Y Y Y里的条目 y u v y_{uv} yuv,概率可以定义为伯努利分布的乘积:
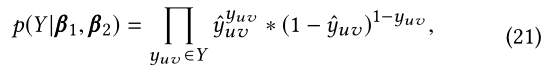
其中
y
^
u
v
\hat{y}_{uv}
y^uv是式子15的输入对
(
u
,
v
)
(u, v)
(u,v)的CTR预测
5.2 Loss Function
将式子20和式子21放到式子16:
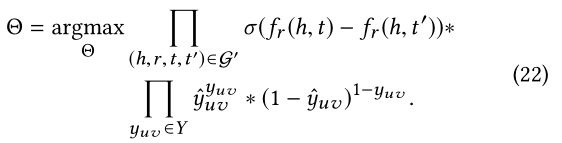
对Eq. 22取负对数并加入正则项后,我们得到AKUPM的损失函数如下:
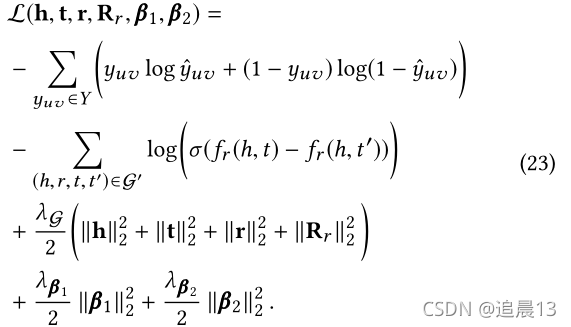
为了最小化Eq. 23中的目标,我们使用了一个批处理梯度下降算法,通过整个观测到的训练集
Y
Y
Y和
G
′
\mathcal{G}'
G′,并使用损失函数的相应梯度更新每个参数
6 EXPERIMENTS
数据集: MovieLens-1M 和 Book-Crossing
因为AKUPM是基于隐式反馈的,所以我们会设置阈值将现有数据集从显示反馈转化为隐式反馈。 具体的就是将他/她所有不低于阈值的评分转换为积极的隐式反馈,也将相同数量的未打分的电影设置为消极的。
对比的模型: CKE、DKN、RippleNet、LibFM和DeepWide;

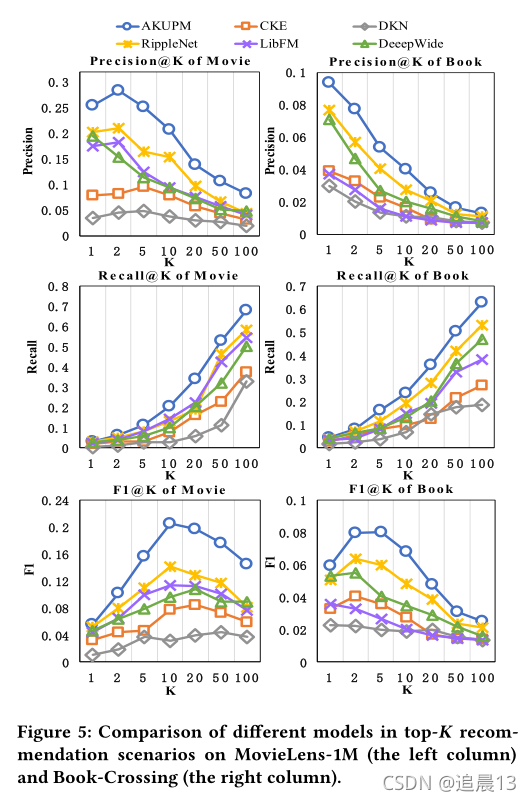
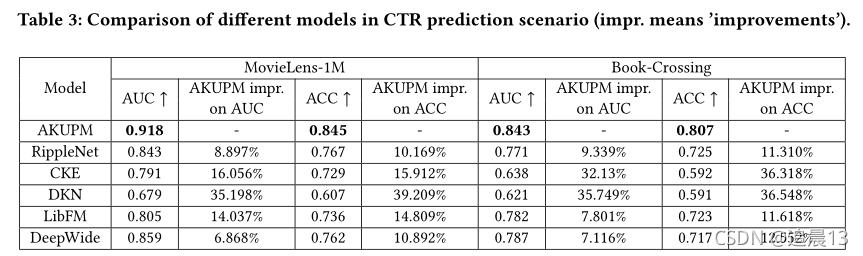
(2)所有模型在Book-Crossing数据集上的表现都不如在MovieLens-1M数据集上的表现。主要原因是Book-Crossing数据集的每用户平均正反馈(3.91)远小于MovieLens-1M数据集(62.44)。因此,在Book-Crossing数据集上没有足够的信息来让模型了解用户的兴趣
(3)与其他相比,DKN表现最差。原因可能是,电影或书籍的标题比新闻短得多,使得单词级嵌入和实体级嵌入包含的信息不足,无法提出建议。
(4)CKE在我们的实验中表现很差。原因可能有两个:文本描述和可视图像在我们的数据集中不可用;AKUPM和RippleNet包含了许多可能与输入项相关的实体,而CKE只使用与输入项直接相关的一个实体进行推荐。
(5)嵌入是有用的
(6)RippleNet在所有基线中几乎达到了最佳性能。AKUPM和RippleNet在合并实体以表示用户的层次偏好方面是相似的。然而,RippleNet没有探索用户和合并实体之间的关系,因此结果可能会受到不相关实体的很大影响。
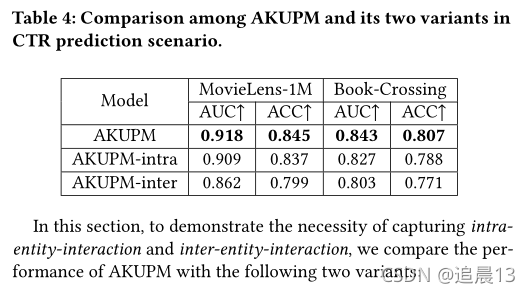
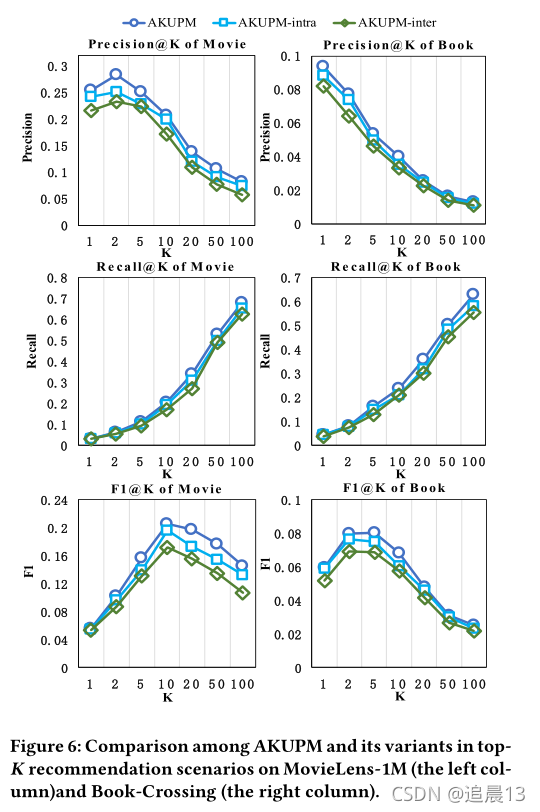
下面是消融实验: