
- 1深度学习——COCO全身关键点提取部分指定的关键点
- 22024年计算语言学与自然语言处理国际会议(CLNLP 2024) | Ei、Scopus双检索_nlpcc2024
- 3CentOS8 Yum安装MySQL_yum install mysql-community-server last metadata e
- 4BERT模型—4.BERT模型在关系分类任务上的微调_bert分类任务
- 5【HarmonyOS】JavaUI组件触摸事件分发_鸿蒙中组件的事件分发机制
- 6蓝桥杯青少创意编程python组_2019年12月份 python 蓝桥杯青少组
- 7数据挖掘实战:基于KMeans算法对超市客户进行聚类分群_基于k-means聚类的数据挖掘大作业
- 8计算机毕业设计PHP基于微信平台的大学生时间规划管理小程序设计(源码+程序+uni+lw+部署)_大学生活微信小程序源码
- 9ai文案生成该用什么软件?六款智能、高效、个性化的创作利器_ai智能文案生成器
- 10利用python 完成leetcode84 柱状图中最大的矩形_python给定n个非负整数,柱子高度,面积
基于BERT模型的知识库问答(KBQA)系统_nlpcc 2016 kbqa knowledge base
赞
踩
一、知识库KB-QA的介绍
参考链接:https://zhuanlan.zhihu.com/p/25735572
1、什么是知识库
“奥巴马出生在火奴鲁鲁。”
“姚明是中国人。”
“谢霆锋的爸爸是谢贤。”
这些就是一条条知识,而把大量的知识汇聚起来就成为了知识库。我们可以在wiki百科,百度百科等百科全书查阅到大量的知识。然而,这些百科全书的知识组建形式是非结构化的自然语言,这样的组织方式很适合人们阅读但并不适合计算机去处理。为了方便计算机的处理和理解,我们需要更加形式化、简洁化的方式去表示知识,那就是三元组(triple)。
1.1 三元组(triple)
“奥巴马出生在火奴鲁鲁。” 可以用三元组表示为 (BarackObama, PlaceOfBirth, Honolulu)。
这里我们可以简单的把三元组理解为 (实体entity,实体关系relation,实体entity),进一步的,如果我们把实体看作是结点,把实体关系(包括属性,类别等等)看作是一条边,那么包含了大量三元组的知识库就成为了一个庞大的知识图。
2、什么是知识库问答
知识库问答(knowledge base question answering,KB-QA)即给定自然语言问题,通过对问题进行语义理解和解析,进而利用知识库进行查询、推理得出答案。如下图所示
与对话系统、对话机器人的交互式对话不同,KB-QA具有以下特点:
- 答案:回答的答案是知识库中的实体或实体关系,或者no-answer(即该问题在KB中找不到答案),当然这里答案不一定唯一,比如 中国的城市有哪些 。而对话系统则回复的是自然语言句子,有时甚至需要考虑上下文语境。
- 评价标准:回召率 (Recall),精确率 (Precision) ,F1-Score。而对话系统的评价标准以人工评价为主,以及BLEU和Perplexity。
当我们在百度询问 2016年奥斯卡最佳男主角 时,百度会根据知识库进行查询和推理,返回答案,这其实就是KB-QA的一个应用。
3、知识库问答的主流方法
关于KB-QA传统的可以分为三类
1、语义解析
2、信息抽取
3、向量建模
以上三种不是重点,详细的内容参考https://zhuanlan.zhihu.com/p/25735572
3.1 深度学习
随着深度学习(Deep Learning)在⾃然语⾔处理领域的⻜速发展,从15年开始,开始涌现出⼀系列基 于深度学习的KB-QA⽂章,通过深度学习对传统的⽅法进⾏提升,取得了较好的效果,⽐如:
使⽤卷积神经⽹络对向量建模⽅法进⾏提升,使⽤卷积神经⽹络对语义解析⽅法进⾏提升,使⽤⻓短时记忆⽹络(LSTM),卷积神经⽹络共同进⾏实体关系分类,使⽤记忆⽹络(Memory Networks),注意⼒机制(Attention Mechanism)进⾏KB-QA。
直到2018年底,BERT对NLP的巨⼤突破,使得⽤BERT进⾏KB-QA也取得了较好的效果。本项⽬基于BERT模型实现。
二、项目介绍
主要目标,构建一个公共的知识库问答系统,从用户所提出的问题,对知识库进行检索,返回一个确定的答案,或者没有答案。
项目代码部分在github:https://github.com/997261095/bert-kbqa
1、数据集介绍
NLPCC全称⾃然语⾔处理与中⽂计算会议(The Conference on Natural Language Processing and Chinese Computing),它是由中国计算机学会(CCF)主办的 CCF 中⽂信息技术专业委员会年度学术会议,专注于⾃然语⾔处理及中⽂计算领域的学术和应⽤创新。源数据集:http://tcci.ccf.org.cn/conference/2016/pages/page05_evadata.html
本项目所使用的数据集是已经被预处理好的三元组 : https://github.com/huangxiangzhou/NLPCC2016KBQA
有两个文件 nlpcc-iccpol-2016.kbqa.training-data,nlpcc-iccpol-2016.kbqa.testing-data
文件内容样式:

2、数据集处理
2.1 切分数据
training-data样本数14609,testing-data样本数9870 。
运行 1_split_data.py 重新切分一下数据,在路径".\bert-kbqa\input\data\NLPCC2016KBQA"得到 train.txt dev.txt test.txt三个文件。三个文件的样本数量分别是 14609,4935,4925
2.2 构造命名实体识别(NER)数据集
运行 2-construct_dataset_ner.py 得到命名实体识别数据集,在路径 "bert-kbqa\input\data\ner_data"得到

txt文件是ner数据集,csv是后面数据库所需要的。
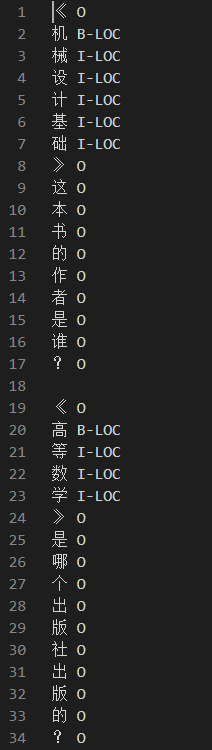
由于只需要识别实体,所以只标记处实体和非实体,供三个类别["O","B-LOC","I-LOC"],ner的数据:
2.3 构建属性相似度的数据
一个问题(样本)自己的属性为正例,再随机从剩余的,非自身属性中选取5个作为负例。运行文件
3-construct_dataset_attribute.py得到。如图: 行末为1的是正例,行末为0是负例。

2.4 构建数据库(Mysql)的数据
mysql的安装配置,这里就不展开了。假设各位mysql都已经存在。
运行文件 5-triple_clean.py 得到所需要数据,运行 6-load_dbdata.py 创建数据库,加载数据。
3、模型介绍
bert是基于transformer的decoder部分做的预训练模型,这里以项目为主 ,原理部分不展开
bert 论文:https://arxiv.org/abs/1810.04805
bert翻译的中文博客 :https://blog.csdn.net/qq_41664845/article/details/84787969#comments
bert的源代码(pytorch) :https://github.com/huggingface/transformers
CRF知乎专栏:https://zhuanlan.zhihu.com/p/44042528
模型基于bert,主要有两个模型
模型1:BertCrf 用 BertForTokenClassification + crf 模型 用于识别出问题中的实体,是查询数据库的基础。
运行文件 NER_main.py 训练
模型2: BertForSequenceClassification , 用于句子分类。把问题 和 属性拼接到一起,判断问题要问的是不是这个属性。
运行文件 SIM_main.py 训练
需要说明一下,当在数据库查询的属性在问题中已经出现,则此时认为该问题所对应的属性已经找到,不需要经过模型2来判断,以达到节约时间的目的。
例如:
问题:《机械设计基础》这本书的作者是谁?
在数据库查找的“作者”这个属性在问题中出现了,则直接返回对应的答案。
项目工作的流程:

4、最终效果
模型1 BertCrf 最佳模型,在测试集的表现:

模型二 BertForSequenceClassification 最佳模型,在训练集的表现

在测试集,找了一些问题,属性没有完全在问题中出现,问答对话的效果:

整体看起来还可以。
三、总结
1、这里只说了模型的大概思路,具体的实现和细节要看代码,很多细节难以用文字和图片完全陈述清楚
github链接 : https://github.com/997261095/bert-kbqa
2、数据集是开放的,数据的质量对模型的影响很大,仔细看看数据集,其实发现很多错误和疑似矛盾重复的标注
3、该项目还有很多值得完善的地方,本人NLP小白,多多包涵。有问题一起交流学习。
四、后续
1、 这个博客2019年11月份完成了,粗略的展示了以下对于BERT模型在pytorch框架下的基本用法,原本只是我自己学习记录用的,到今天2020年5月,有幸被一部分朋友关注到了。很多人说他们在运行代码时,使用sklearn.metrics 输出不了micro avg,报出key Error的错误。我并没有去具体看看这个错误到底是什么原因导致。初步估计是sklearn版本不同,key值被删除了或者更改了,自己只需要的打印出来看看即可。这里只是我计算 准确率,召回率,F1的一个API,你可以换成任何计算 这三个值的API,甚至自己写出 计算这三个值的方法。对于这种问题,其实很基础,要学会自己调试,依赖包肯定会一直更新的,自己要善于学习。
有很大一部分人是学生,可能硬件条件达不到,很难训练出最后的两个模型,在这里我的部分(有些被我删除了,我没想到还有用)训练日志和两个最佳模型(best_ner.bin,best_sim.bin)一起打包,上传至百度网盘:链接,提取码:7sl9 。这个不建议想要学习的朋友们直接使用,如果即使用直接使用,也最好把代码全部看完,跑通。

