
热门标签
热门文章
- 1Python 文件IO:JSON 文件的读取与写入_binary io 写入json
- 23分钟学会写文心一言指令_如何给文心一言下命令
- 3熬夜整理了2021年Python最新学习资料,分享给学弟学妹们【大学生必备】_这里限制了文件发送哦! python编程学习资料、源码 扣裙自取:837424592 谢
- 4Linux 操作系统 03 - 用户和组管理_创建~/zhangsan.txt文件
- 5gradle环境配置及仓库配置_gradle仓库
- 6python的time库
- 7java 《十五》io读取jsonObject和jsonArray文件返回json_ioutils.tostring()返回的是json串吗
- 8《深入理解Android内核设计思想(第2版)(上下册)》之Android源码下载及编译_深入理解android内核设计思想 第2版 pdf 下载
- 9windows cmd 批处理脚本命令行压缩工具7z zip压缩文件 自动压缩脚本
- 10qt label设置字体大小_木辛老师的编程课堂:Python和Qt之页面布局实战篇(一)...
当前位置: article > 正文
Prometheus接入AlterManager配置企业微信告警(基于K8S环境部署)_prometheus微信告警
作者:weixin_40725706 | 2024-04-08 05:29:28
赞
踩
prometheus微信告警
注意:请基于 Prometheus+Grafana监控K8S集群(基于K8S环境部署)文章之上做本次实验。
一、创建企业微信机器人
1、创建企业微信机器人
应用管理 > 机器人 > 创建应用
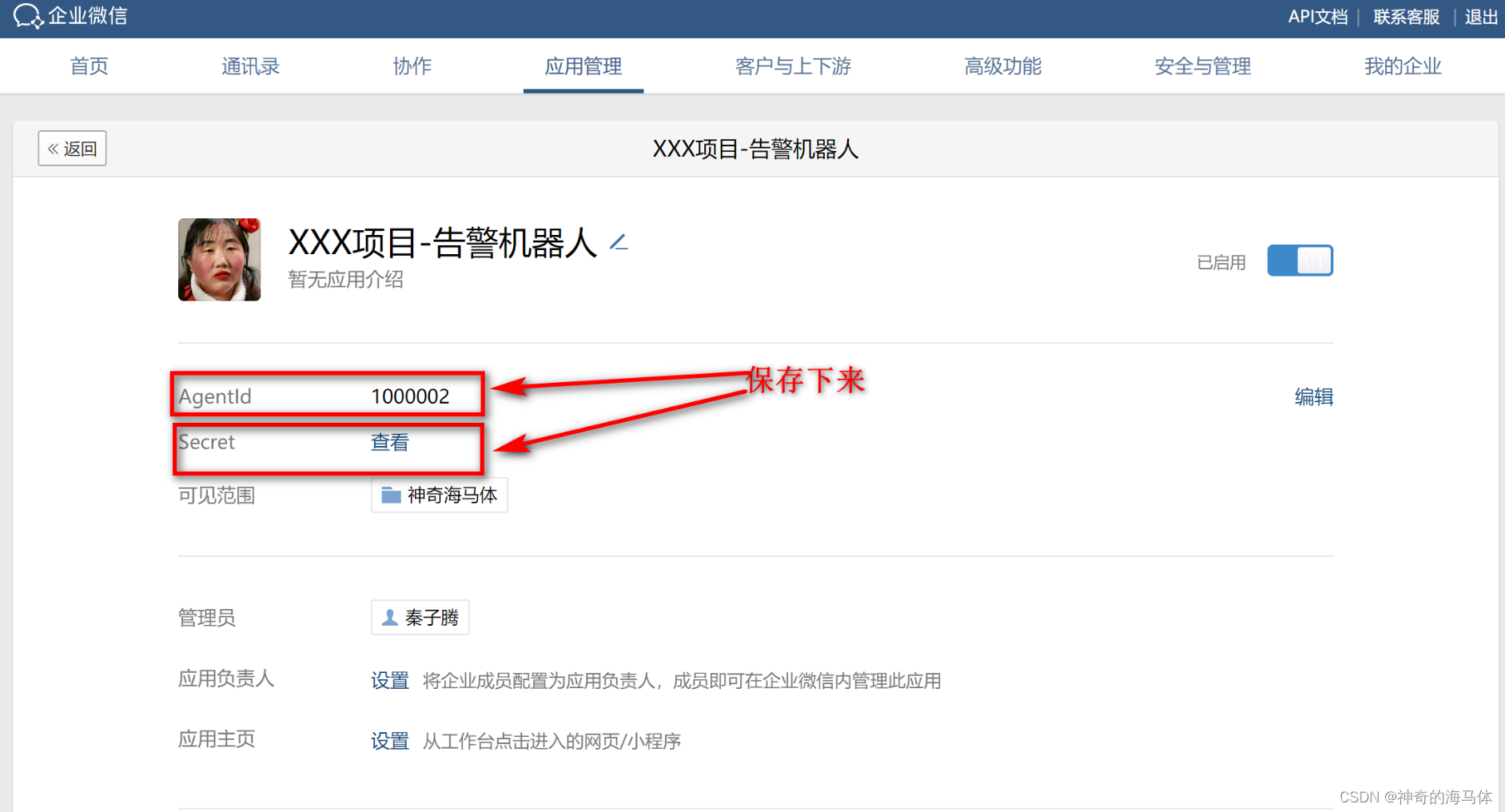
创建好之后如上图,我们获取 点击查看获取 Secret 值。
2、获取企业ID
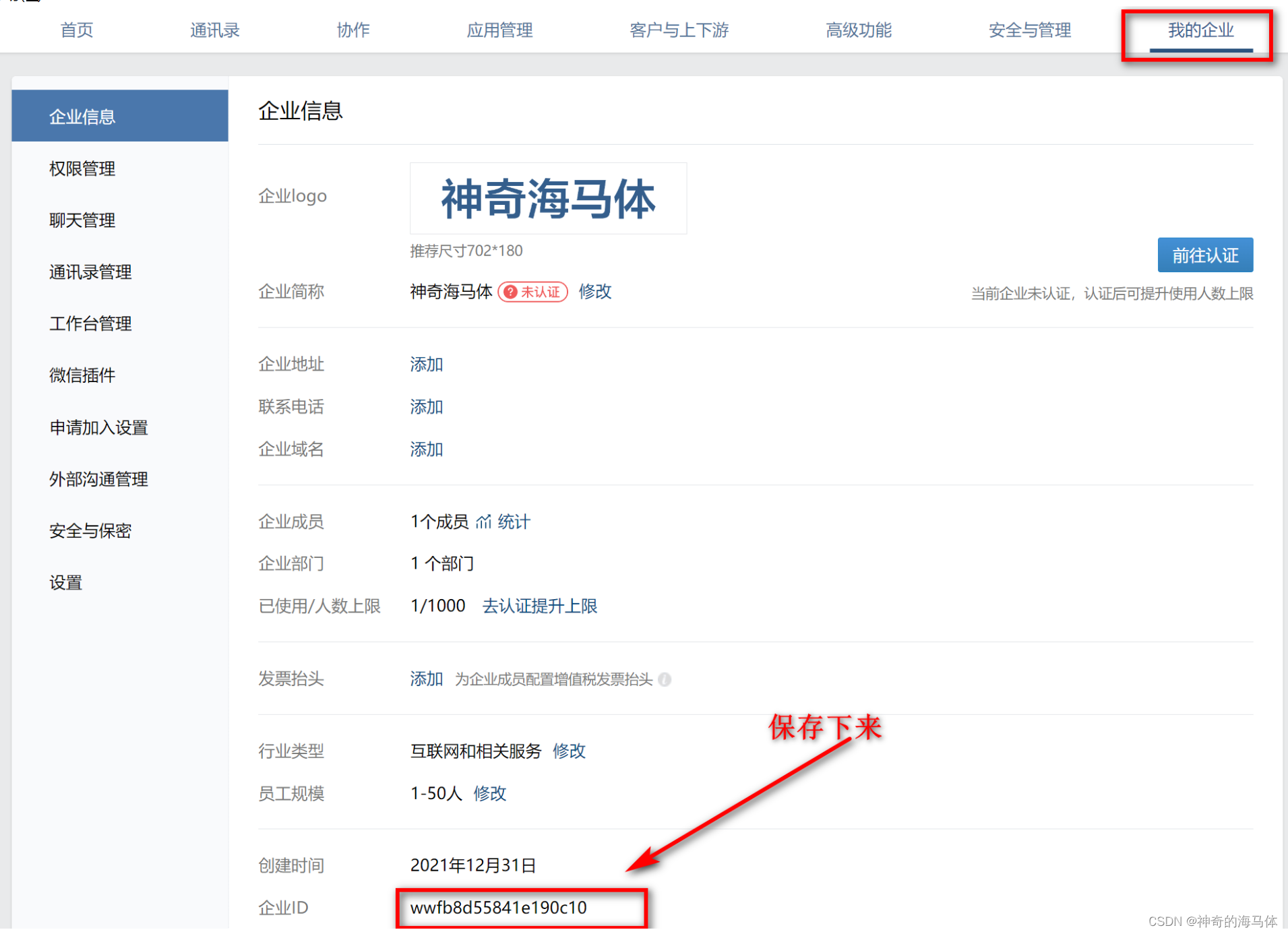
二、配置AlterManager告警发送至企业微信
1、创建AlterManager ConfigMap资源清单
vim alertmanager-cm.yaml --- kind: ConfigMap apiVersion: v1 metadata: name: alertmanager namespace: prometheus data: alertmanager.yml: |- templates: - '/alertmanager/template/WeChat.tmpl' global: resolve_timeout: 1m smtp_smarthost: 'smtp.163.com:25' smtp_from: '18145536045@163.com' smtp_auth_username: '18145536045@163.com' smtp_auth_password: 'KCGZFUDCCKMNZMKB' smtp_require_tls: false route: group_by: [alertname] group_wait: 10s group_interval: 10s repeat_interval: 10m receiver: wechat-001 receivers: - name: 'wechat-001' wechat_configs: - corp_id: wwfb8d55841e190c10 # 企业ID to_user: '@all' # 发送所有人 agent_id: 1000002 # agentID api_secret: wa6kWECFthSpvdhcF-RPgjrIBzUvm-SpqXXXXXXXXXX # secret

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
执行YAML资源清单:
kubectl apply -f alertmanager-cm.yaml
- 1
三、Prometheus接入AlterManager配置
1、创建新的Prometheus ConfigMap资源清单,添加监控K8S集群告警规则
vim prometheus-alertmanager-cfg.yaml --- kind: ConfigMap apiVersion: v1 metadata: labels: app: prometheus name: prometheus-config namespace: prometheus data: prometheus.yml: | rule_files: - /etc/prometheus/rules.yml # 告警规则位置 alerting: alertmanagers: - static_configs: - targets: ["localhost:9093"] # 接入AlterManager global: scrape_interval: 15s scrape_timeout: 10s evaluation_interval: 1m scrape_configs: - job_name: 'kubernetes-node' kubernetes_sd_configs: - role: node relabel_configs: - source_labels: [__address__] regex: '(.*):10250' replacement: '${1}:9100' target_label: __address__ action: replace - action: labelmap regex: __meta_kubernetes_node_label_(.+) - job_name: 'kubernetes-node-cadvisor' kubernetes_sd_configs: - role: node scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - action: labelmap regex: __meta_kubernetes_node_label_(.+) - target_label: __address__ replacement: kubernetes.default.svc:443 - source_labels: [__meta_kubernetes_node_name] regex: (.+) target_label: __metrics_path__ replacement: /api/v1/nodes/${1}/proxy/metrics/cadvisor - job_name: 'kubernetes-apiserver' kubernetes_sd_configs: - role: endpoints scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token relabel_configs: - source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_service_name, __meta_kubernetes_endpoint_port_name] action: keep regex: default;kubernetes;https - job_name: 'kubernetes-service-endpoints' kubernetes_sd_configs: - role: endpoints relabel_configs: - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape] action: keep regex: true - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scheme] action: replace target_label: __scheme__ regex: (https?) - source_labels: [__meta_kubernetes_service_annotation_prometheus_io_path] action: replace target_label: __metrics_path__ regex: (.+) - source_labels: [__address__, __meta_kubernetes_service_annotation_prometheus_io_port] action: replace target_label: __address__ regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 - action: labelmap regex: __meta_kubernetes_service_label_(.+) - source_labels: [__meta_kubernetes_namespace] action: replace target_label: kubernetes_namespace - source_labels: [__meta_kubernetes_service_name] action: replace target_label: kubernetes_name - job_name: 'kubernetes-pods' # 监控Pod配置,添加注解后才可以被发现 kubernetes_sd_configs: - role: pod relabel_configs: - action: keep regex: true source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_scrape - action: replace regex: (.+) source_labels: - __meta_kubernetes_pod_annotation_prometheus_io_path target_label: __metrics_path__ - action: replace regex: ([^:]+)(?::\d+)?;(\d+) replacement: $1:$2 source_labels: - __address__ - __meta_kubernetes_pod_annotation_prometheus_io_port target_label: __address__ - action: labelmap regex: __meta_kubernetes_pod_label_(.+) - action: replace source_labels: - __meta_kubernetes_namespace target_label: kubernetes_namespace - action: replace source_labels: - __meta_kubernetes_pod_name target_label: kubernetes_pod_name - job_name: 'kubernetes-etcd' # 监控etcd配置 scheme: https tls_config: ca_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ca.crt cert_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.crt key_file: /var/run/secrets/kubernetes.io/k8s-certs/etcd/server.key scrape_interval: 5s static_configs: - targets: ['16.32.15.200:2379'] rules.yml: | # K8S集群告警规则配置文件 groups: - name: example rules: - alert: apiserver的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: apiserver的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-apiserver"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: etcd的cpu使用率大于80% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过80%" - alert: etcd的cpu使用率大于90% expr: rate(process_cpu_seconds_total{job=~"kubernetes-etcd"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}组件的cpu使用率超过90%" - alert: kube-state-metrics的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: kube-state-metrics的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-state-metrics"}[1m]) * 100 > 0 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: coredns的cpu使用率大于80% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 80 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过80%" value: "{{ $value }}%" threshold: "80%" - alert: coredns的cpu使用率大于90% expr: rate(process_cpu_seconds_total{k8s_app=~"kube-dns"}[1m]) * 100 > 90 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.k8s_app}}组件的cpu使用率超过90%" value: "{{ $value }}%" threshold: "90%" - alert: kube-proxy打开句柄数>600 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kube-proxy打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-kube-proxy"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>600 expr: process_open_fds{job=~"kubernetes-schedule"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-schedule打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-schedule"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>600 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-controller-manager打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-controller-manager"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>600 expr: process_open_fds{job=~"kubernetes-apiserver"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-apiserver打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-apiserver"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>600 expr: process_open_fds{job=~"kubernetes-etcd"} > 600 for: 2s labels: severity: warnning annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>600" value: "{{ $value }}" - alert: kubernetes-etcd打开句柄数>1000 expr: process_open_fds{job=~"kubernetes-etcd"} > 1000 for: 2s labels: severity: critical annotations: description: "{{$labels.instance}}的{{$labels.job}}打开句柄数>1000" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 600 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过600" value: "{{ $value }}" - alert: coredns expr: process_open_fds{k8s_app=~"kube-dns"} > 1000 for: 2s labels: severity: critical annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 打开句柄数超过1000" value: "{{ $value }}" - alert: kube-proxy expr: process_virtual_memory_bytes{job=~"kubernetes-kube-proxy"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: scheduler expr: process_virtual_memory_bytes{job=~"kubernetes-schedule"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-controller-manager expr: process_virtual_memory_bytes{job=~"kubernetes-controller-manager"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-apiserver expr: process_virtual_memory_bytes{job=~"kubernetes-apiserver"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kubernetes-etcd expr: process_virtual_memory_bytes{job=~"kubernetes-etcd"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: kube-dns expr: process_virtual_memory_bytes{k8s_app=~"kube-dns"} > 2000000000 for: 2s labels: severity: warnning annotations: description: "插件{{$labels.k8s_app}}({{$labels.instance}}): 使用虚拟内存超过2G" value: "{{ $value }}" - alert: HttpRequestsAvg expr: sum(rate(rest_client_requests_total{job=~"kubernetes-kube-proxy|kubernetes-kubelet|kubernetes-schedule|kubernetes-control-manager|kubernetes-apiservers"}[1m])) > 1000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): TPS超过1000" value: "{{ $value }}" threshold: "1000" - alert: Pod_restarts expr: kube_pod_container_status_restarts_total{namespace=~"kube-system|default|monitor-sa"} > 0 for: 2s labels: severity: warnning annotations: description: "在{{$labels.namespace}}名称空间下发现{{$labels.pod}}这个pod下的容器{{$labels.container}}被重启,这个监控指标是由{{$labels.instance}}采集的" value: "{{ $value }}" threshold: "0" - alert: Pod_waiting expr: kube_pod_container_status_waiting_reason{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}启动异常等待中" value: "{{ $value }}" threshold: "1" - alert: Pod_terminated expr: kube_pod_container_status_terminated_reason{namespace=~"kube-system|default|monitor-sa"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.pod}}下的{{$labels.container}}被删除" value: "{{ $value }}" threshold: "1" - alert: Etcd_leader expr: etcd_server_has_leader{job="kubernetes-etcd"} == 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前没有leader" value: "{{ $value }}" threshold: "0" - alert: Etcd_leader_changes expr: rate(etcd_server_leader_changes_seen_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 当前leader已发生改变" value: "{{ $value }}" threshold: "0" - alert: Etcd_failed expr: rate(etcd_server_proposals_failed_total{job="kubernetes-etcd"}[1m]) > 0 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}): 服务失败" value: "{{ $value }}" threshold: "0" - alert: Etcd_db_total_size expr: etcd_debugging_mvcc_db_total_size_in_bytes{job="kubernetes-etcd"} > 10000000000 for: 2s labels: team: admin annotations: description: "组件{{$labels.job}}({{$labels.instance}}):db空间超过10G" value: "{{ $value }}" threshold: "10G" - alert: Endpoint_ready expr: kube_endpoint_address_not_ready{namespace=~"kube-system|default"} == 1 for: 2s labels: team: admin annotations: description: "空间{{$labels.namespace}}({{$labels.instance}}): 发现{{$labels.endpoint}}不可用" value: "{{ $value }}" threshold: "1" - name: 物理节点状态-监控告警 rules: - alert: 物理节点cpu使用率 expr: 100-avg(irate(node_cpu_seconds_total{mode="idle"}[5m])) by(instance)*100 > 90 for: 2s labels: severity: ccritical annotations: summary: "{{ $labels.instance }}cpu使用率过高" description: "{{ $labels.instance }}的cpu使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: 物理节点内存使用率 expr: (node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Buffers_bytes + node_memory_Cached_bytes)) / node_memory_MemTotal_bytes * 100 > 90 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}内存使用率过高" description: "{{ $labels.instance }}的内存使用率超过90%,当前使用率[{{ $value }}],需要排查处理" - alert: InstanceDown expr: up == 0 for: 2s labels: severity: critical annotations: summary: "{{ $labels.instance }}: 服务器宕机" description: "{{ $labels.instance }}: 服务器延时超过2分钟" - alert: 物理节点磁盘的IO性能 expr: 100-(avg(irate(node_disk_io_time_seconds_total[1m])) by(instance)* 100) < 60 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入磁盘IO使用率过高!" description: "{{$labels.mountpoint }} 流入磁盘IO大于60%(目前使用:{{$value}})" - alert: 入网流量带宽 expr: ((sum(rate (node_network_receive_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流入网络带宽过高!" description: "{{$labels.mountpoint }}流入网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: 出网流量带宽 expr: ((sum(rate (node_network_transmit_bytes_total{device!~'tap.*|veth.*|br.*|docker.*|virbr*|lo*'}[5m])) by (instance)) / 100) > 102400 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 流出网络带宽过高!" description: "{{$labels.mountpoint }}流出网络带宽持续5分钟高于100M. RX带宽使用率{{$value}}" - alert: TCP会话 expr: node_netstat_Tcp_CurrEstab > 1000 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} TCP_ESTABLISHED过高!" description: "{{$labels.mountpoint }} TCP_ESTABLISHED大于1000%(目前使用:{{$value}}%)" - alert: 磁盘容量 expr: 100-(node_filesystem_free_bytes{fstype=~"ext4|xfs"}/node_filesystem_size_bytes {fstype=~"ext4|xfs"}*100) > 80 for: 2s labels: severity: critical annotations: summary: "{{$labels.mountpoint}} 磁盘分区使用率过高!" description: "{{$labels.mountpoint }} 磁盘分区使用大于80%(目前使用:{{$value}}%)"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 181
- 182
- 183
- 184
- 185
- 186
- 187
- 188
- 189
- 190
- 191
- 192
- 193
- 194
- 195
- 196
- 197
- 198
- 199
- 200
- 201
- 202
- 203
- 204
- 205
- 206
- 207
- 208
- 209
- 210
- 211
- 212
- 213
- 214
- 215
- 216
- 217
- 218
- 219
- 220
- 221
- 222
- 223
- 224
- 225
- 226
- 227
- 228
- 229
- 230
- 231
- 232
- 233
- 234
- 235
- 236
- 237
- 238
- 239
- 240
- 241
- 242
- 243
- 244
- 245
- 246
- 247
- 248
- 249
- 250
- 251
- 252
- 253
- 254
- 255
- 256
- 257
- 258
- 259
- 260
- 261
- 262
- 263
- 264
- 265
- 266
- 267
- 268
- 269
- 270
- 271
- 272
- 273
- 274
- 275
- 276
- 277
- 278
- 279
- 280
- 281
- 282
- 283
- 284
- 285
- 286
- 287
- 288
- 289
- 290
- 291
- 292
- 293
- 294
- 295
- 296
- 297
- 298
- 299
- 300
- 301
- 302
- 303
- 304
- 305
- 306
- 307
- 308
- 309
- 310
- 311
- 312
- 313
- 314
- 315
- 316
- 317
- 318
- 319
- 320
- 321
- 322
- 323
- 324
- 325
- 326
- 327
- 328
- 329
- 330
- 331
- 332
- 333
- 334
- 335
- 336
- 337
- 338
- 339
- 340
- 341
- 342
- 343
- 344
- 345
- 346
- 347
- 348
- 349
- 350
- 351
- 352
- 353
- 354
- 355
- 356
- 357
- 358
- 359
- 360
- 361
- 362
- 363
- 364
- 365
- 366
- 367
- 368
- 369
- 370
- 371
- 372
- 373
- 374
- 375
- 376
- 377
- 378
- 379
- 380
- 381
- 382
- 383
- 384
- 385
- 386
- 387
- 388
- 389
- 390
- 391
- 392
- 393
- 394
- 395
- 396
- 397
- 398
- 399
- 400
- 401
- 402
- 403
- 404
- 405
- 406
- 407
- 408
- 409
- 410
- 411
- 412
- 413
- 414
- 415
- 416
- 417
- 418
- 419
- 420
- 421
- 422
- 423
- 424
- 425
- 426
- 427
- 428
- 429
- 430
- 431
- 432
- 433
- 434
- 435
- 436
- 437
- 438
- 439
- 440
- 441
- 442
- 443
- 444
- 445
- 446
- 447
- 448
- 449
- 450
- 451
- 452
- 453
- 454
- 455
- 456
- 457
- 458
- 459
- 460
- 461
- 462
- 463
- 464
- 465
- 466
- 467
- 468
- 469
- 470
- 471
- 472
- 473
- 474
- 475
- 476
- 477
- 478
- 479
- 480
- 481
- 482
- 483
- 484
- 485
- 486
执行资源清单:
kubectl apply -f prometheus-alertmanager-cfg.yaml
- 1
2、由于在prometheus中新增了etcd,所以生成一个etcd-certs,这个在部署prometheus需要
kubectl -n prometheus create secret generic etcd-certs --from-file=/etc/kubernetes/pki/etcd/server.key --from-file=/etc/kubernetes/pki/etcd/server.crt --from-file=/etc/kubernetes/pki/etcd/ca.crt
- 1
四、部署Prometheus+AlterManager(放到一个Pod中)
1、在node-1节点创建/data/alertmanager目录,存放alertmanager数据
mkdir /data/alertmanager/template -p
chmod -R 777 /data/alertmanager
- 1
- 2
2、在node-1节点创建WeChat报警模板
vim /data/alertmanager/template/WeChat.tmpl {{ define "wechat.default.message" }} {{- if gt (len .Alerts.Firing) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} =========xxx环境监控报警 ========= 告警状态:{{ .Status }} 告警级别:{{ .Labels.severity }} 告警类型:{{ $alert.Labels.alertname }} 故障主机: {{ $alert.Labels.instance }} {{ $alert.Labels.pod }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 触发阀值:{{ .Annotations.value }} 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- if gt (len .Alerts.Resolved) 0 -}} {{- range $index, $alert := .Alerts -}} {{- if eq $index 0 }} =========xxx环境异常恢复 ========= 告警类型:{{ .Labels.alertname }} 告警状态:{{ .Status }} 告警主题: {{ $alert.Annotations.summary }} 告警详情: {{ $alert.Annotations.message }}{{ $alert.Annotations.description}}; 故障时间: {{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} 恢复时间: {{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} {{- if gt (len $alert.Labels.instance) 0 }} 实例信息: {{ $alert.Labels.instance }} {{- end }} ========= = end = ========= {{- end }} {{- end }} {{- end }} {{- end }}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
3、删除旧的prometheus deployment资源
kubectl delete deploy prometheus-server -n prometheus
- 1
4、创建deployment资源
vim prometheus-alertmanager-deploy.yaml --- apiVersion: apps/v1 kind: Deployment metadata: name: prometheus-server namespace: prometheus labels: app: prometheus spec: replicas: 1 selector: matchLabels: app: prometheus component: server #matchExpressions: #- {key: app, operator: In, values: [prometheus]} #- {key: component, operator: In, values: [server]} template: metadata: labels: app: prometheus component: server annotations: prometheus.io/scrape: 'false' spec: nodeName: node-1 # 调度到node-1节点 serviceAccountName: prometheus # 指定sa服务账号 containers: - name: prometheus image: prom/prometheus:v2.33.5 imagePullPolicy: IfNotPresent command: - "/bin/prometheus" args: - "--config.file=/etc/prometheus/prometheus.yml" - "--storage.tsdb.path=/prometheus" - "--storage.tsdb.retention=24h" - "--web.enable-lifecycle" ports: - containerPort: 9090 protocol: TCP volumeMounts: - mountPath: /etc/prometheus name: prometheus-config - mountPath: /prometheus/ name: prometheus-storage-volume - name: k8s-certs mountPath: /var/run/secrets/kubernetes.io/k8s-certs/etcd/ - name: alertmanager #image: prom/alertmanager:v0.14.0 image: prom/alertmanager:v0.23.0 imagePullPolicy: IfNotPresent args: - "--config.file=/etc/alertmanager/alertmanager.yml" - "--log.level=debug" ports: - containerPort: 9093 protocol: TCP name: alertmanager volumeMounts: - name: alertmanager-config mountPath: /etc/alertmanager - name: alertmanager-storage mountPath: /alertmanager - name: localtime mountPath: /etc/localtime volumes: - name: prometheus-config configMap: name: prometheus-config - name: prometheus-storage-volume hostPath: path: /data type: Directory - name: k8s-certs secret: secretName: etcd-certs - name: alertmanager-config configMap: name: alertmanager - name: alertmanager-storage hostPath: path: /data/alertmanager type: DirectoryOrCreate - name: localtime hostPath: path: /usr/share/zoneinfo/Asia/Shanghai
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
执行YAML资源清单:
kubectl apply -f prometheus-alertmanager-deploy.yaml
- 1
查看状态:
kubectl get pods -n prometheus
- 1

5、创建AlterManager SVC资源
vim alertmanager-svc.yaml --- apiVersion: v1 kind: Service metadata: labels: name: prometheus kubernetes.io/cluster-service: 'true' name: alertmanager namespace: prometheus spec: ports: - name: alertmanager nodePort: 30066 port: 9093 protocol: TCP targetPort: 9093 selector: app: prometheus sessionAffinity: None type: NodePort
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
执行YAML资源清单:
kubectl apply -f alertmanager-svc.yaml
- 1
查看状态:
kubectl get svc -n prometheus
- 1

五、测试告警
浏览器访问:http://IP:30066
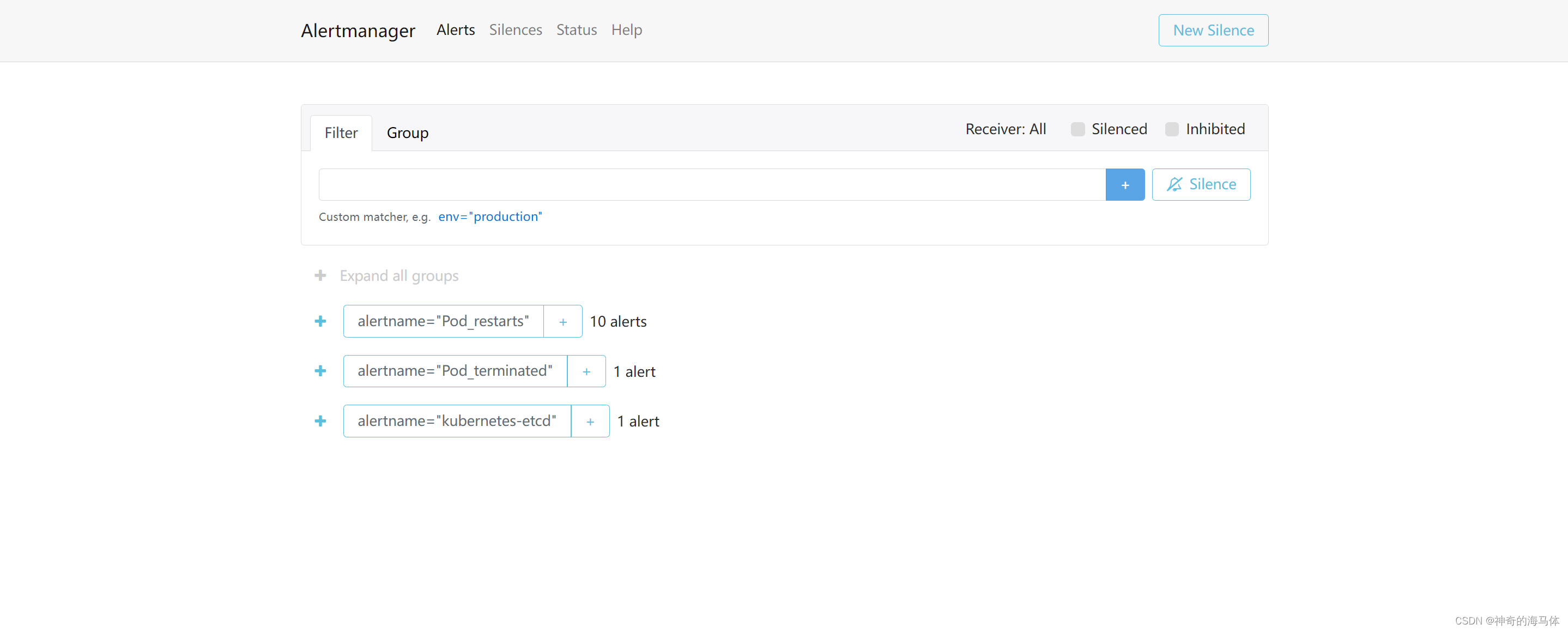
如上图可以看到,Prometheus的告警信息已经发到AlterManager了,AlertManager收到报警数据后,会将警报信息进行分组,然后根据AlertManager配置的 group_wait 时间先进行等待。等wait时间过后再发送报警信息至企业微信!
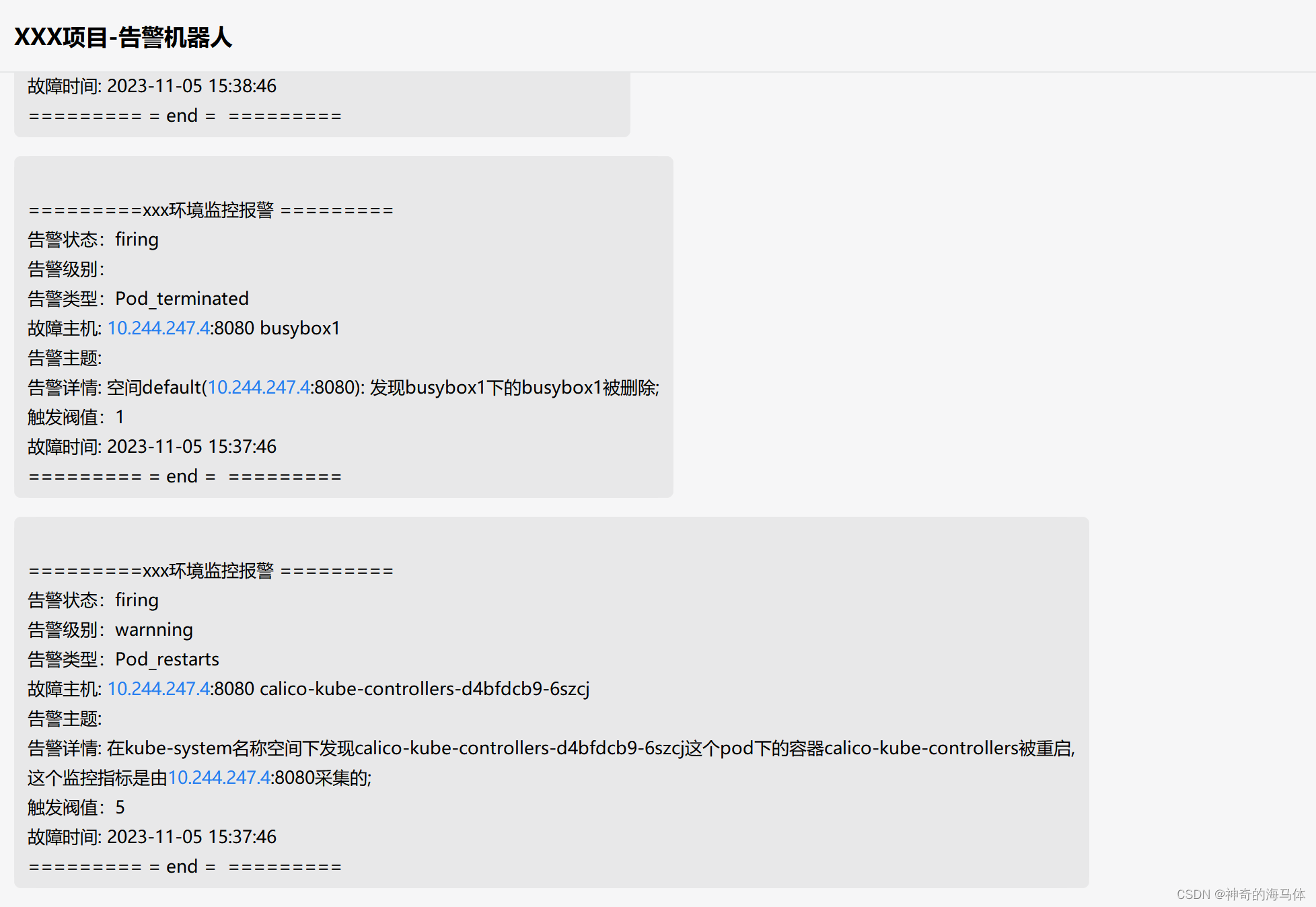
如上图,告警信息已经成功发往企业微信了!!!
本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/383286
推荐阅读
相关标签

