
- 1如何用实时数据分析辅助企业智能决策,这个高效的解决方案了解下?_企业数据如何智能分析技术手段
- 2原创10个python自动化化案例,一口一个高效办公!_python办公自动化案例
- 3STM32学习和实践笔记(15):STM32中断系统
- 4这个全面对标 OpenAI 的国产大模型,性能已达 90% GPT-4_国内平替openai大模型
- 5解决在命令行中出现usrlocalhadooplibexechadoop-functions.sh 行 1185 dirname 未找到命令_/export/server/hadoop/libexec/hadoop-functions.sh:
- 6SAP HR Schema 详解(三) - 二、工资核算基础
- 7Django(9)|基于reseful-api风格的Django-framework_django restful api
- 8opencv 写入 mp4 文件 C++用VideoWriter写入视频
- 9微信小程序--层叠轮播图_微信小程序实现堆叠式轮播
- 10知识图谱基本工具Neo4j使用笔记 四 :使用csv文件批量导入图谱数据_neo4j导入csv关系
锁屏面试题百日百刷-hadoop篇(一)_百万hadoop考生
赞
踩
1.HDFS的存储机制(读写流程)?
HDFS存储机制,包括HDFS的写入过程和读取过程两个部分
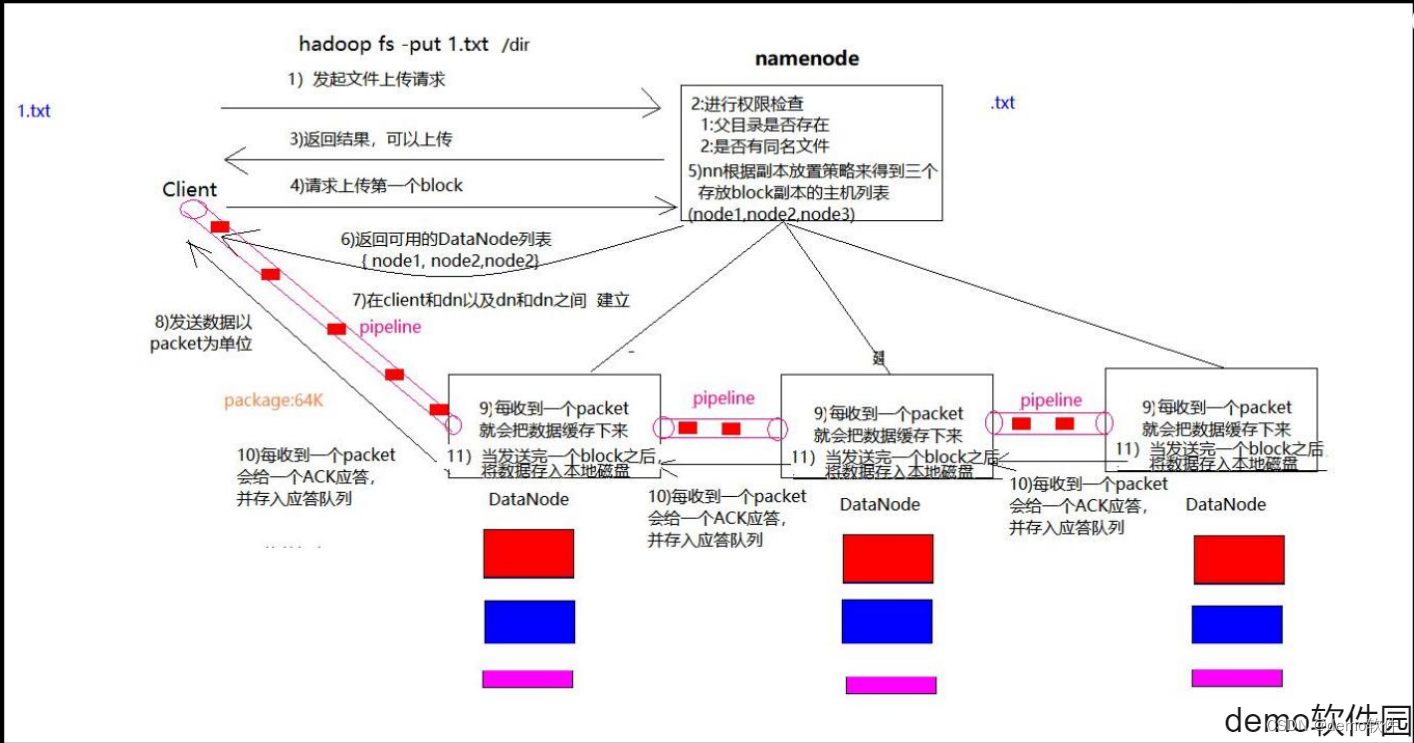
- 客户端向namenode请求上传文件,namenode检查目标文件是否已存在,父目录是否存在。
- namenode返回是否可以上传。
- 客户端请求第一个block上传到哪几个datanode服务器上。
- namenode返回3个datanode节点,分别为dn1、dn2、dn3。
- 客户端请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
- dn1、dn2、dn3逐级应答客户端
- 客户端开始往dn1上传第一个block(先从磁盘读取数据放到一个本地内存缓存),以packet为单位,dn1收到一个packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答
- 当一个block传输完成之后,客户端再次请求namenode上传第二个block的服务器。(重复执行3-7步)
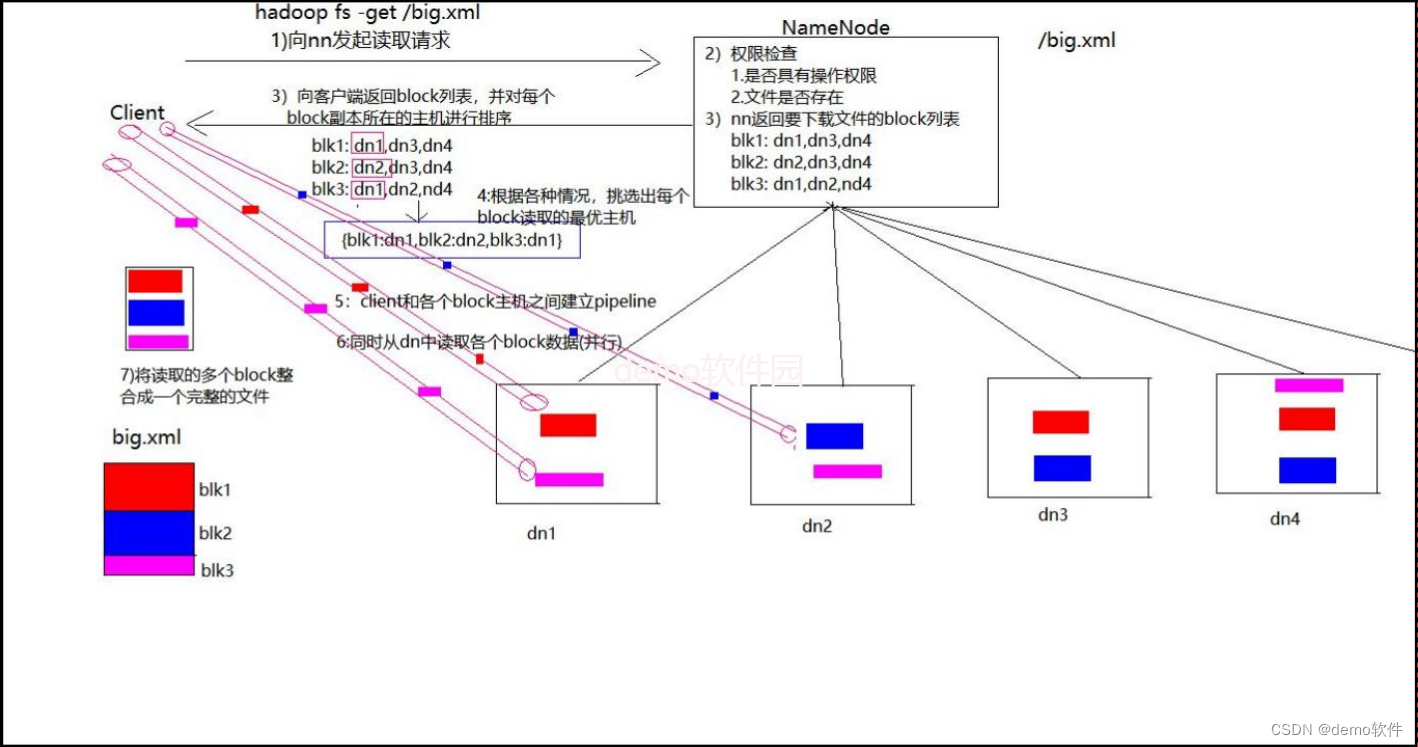
- 客户端向namenode请求下载文件,namenode通过查询元数据,找到文件块所在的datanode地址。
- 挑选一台datanode(就近原则,然后随机)服务器,请求读取数据。
- datanode开始传输数据给客户端(从磁盘里面读取数据放入流,以packet为单位来做校验)。
- 客户端以packet为单位接收,先在本地缓存,然后写入目标文件。
2.HDFS中大量小文件带来的问题以及解决的方案
问题:
hadoop中目录,文件和块都会以对象的形式保存在namenode的内存中,大概每个对象会占用150bytes.小文件数量多会大量占用namenode的内存;使namenode读取元数据速度变慢,启动时间延长;还因为占用内存过大,导致gc时间增加等.
解决办法:
两个角度,一是从根源解决小文件的产生,二是解决不了就选择合并.从数据来源入手,如每小时抽取一次改为每天抽取一次等方法来积累数据量.如果小文件无可避免,一般就采用合并的方式解决.可以写一个MR任务读取某个目录下的所有小文件,并重写为一个大文件.
3.HDFS三个核心组件时什么,分别有什么作用?
1-NameNode.集群的核心,是整个文件系统的管理节点.维护着
a)文件系统的文件目录结构和元数据信息
b)文件与数据块列表的对应关系
2-DataNode.存放具体数据块的节点,主要负责数据的读写,定期向NameNode发送心跳3-SecondaryNameNode.辅助节点,同步NameNode中的元数据信息,辅助NameNode对fsimage和editsLog进行合并.
4.fsimage和editlogs是做什么用的?
fsimage文件存储的是Hadoop的元数据文件,如果namenode发生故障,最近的fsimage文件会被载入到内存中,用来重构元数据的最近状态,再从相关点开始向前执行editlogs文件中记录的每个事务.
文件系统客户端执行写操作时,这些事务会首先记录到日志文件中.
在namenode运行期间,客户端对hdfs的写操作都保存到edit文件中,久而久之就会造成edit文件变得很大,这对namenode的运行没有影响,但是如果namenode重启,它会将fsimage中的内容映射到内存中,然后再一条一条执行edit文件中的操作,所以日志文件太大会导致重启速度很慢.所以在namenode运行的时候就要将editlogs和fsimage定期合并.
5.namenode的工作机制?
第一阶段:NameNode启动
- 第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
- 客户端对元数据进行增删改的请求。
- NameNode记录操作日志,更新滚动日志。
- NameNode在内存中对元数据进行增删改。
第二阶段:SecondaryNameNode工作
- SecondaryNameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
- SecondaryNameNode请求执行CheckPoint。
- NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到SecondaryNameNode。
(5)SecondaryNameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。

