
- 1There were errors checking the update sites: SocketException: java.security.NoSuchAlgorithmException
- 2最全的mysql常用语句大全_mysql语句
- 3面试经典 150 题 4 —(哈希表)— 242. 有效的字母异位词
- 4毕业设计| STM32单片机控制的智能家居系统设计_单片机智能家居毕业设计
- 5Comate: 百度智能云的代码助手_comate代码助手
- 6如何更换git远程仓库地址_切换git远程地址命令
- 7UCOS-II代码OSStart()函数分析
- 8手写数据库toadb 保姆级教程来了
- 9想升职加薪?网络安全行业推荐考取的证书_知了汇智cisp-pte
- 10js 正则只能输入大于0的数字——正则表达式基础_正则大于0
MySQL数据库SQL总结_mysql数据库—sql汇总
赞
踩
SQL查询
数据查询是数据库的核心操作。SQL提供了SELECT语句进行数据查询,该语句具有灵活的使用方式和丰富的功能。
查询格式
SELECT [ALL|DISTINCT] <目标表达式>[,目标表达式] …
FROM <表名或视图名> [,<表名或视图名>…]|(<SELECT语句>)[AS]<别名>
[WHERE <条件表达式>]
[GROUP BY <列名1>[HAVING<条件表达式>]]
[ORDER BY <列名2>[ASC|DESC]]
- 1
- 2
- 3
- 4
- 5
select后默认是all,在表中,可能会包含重复值。这并不成问题,不过,有时也许希望仅仅列出不同(distinct)的值。这时就需要在select后面加上distinct。关键词distinct用于返回唯一不同的值。
DESC降序排列 如:300、200、100
ASC 升序排列 如:100、200、300
关于 in和exists的使用区别
-
in()适合B表比A表数据小的情况
-
exists()适合B表比A表数据大的情况
-
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
select * from A
where id in(select id from B)
- 1
- 2
以上查询使用了in语句,in()只执行一次,它查出B表中的所有id字段并缓存起来.之后,检查A表的id是否与B表中的id相等,如果相等则将A表的记录加入结果集中,直到遍历完A表的所有记录.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A);
Array B=(select id from B);
for(int i=0;i<A.length;i++) {
for(int j=0;j<B.length;j++) {
if(A[i].id==B[j].id) {
resultSet.add(A[i]);
break;
}
}
}
return resultSet;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看出,当B表数据较大时不适合使用in(),因为它会B表数据全部遍历一次.
如:A表有10000条记录,B表有1000000条记录,那么最多有可能遍历100001000000次,效率很差.
再如:A表有10000条记录,B表有100条记录,那么最多有可能遍历10000100次,遍历次数大大减少,效率大大提升.
结论:in()适合B表比A表数据小的情况
select a.* from A a
where exists(select 1 from B b where a.id=b.id)
- 1
- 2
带有exists的子查询不返回任何数据,只产生逻辑真值"true”或逻辑假值"false",以上查询使用了exists语句,exists()会执行A.length次,它并不缓存exists()结果集,因为exists()结果集的内容并不重要,重要的是结果集中是否有记录,如果有则返回true,没有则返回false.
它的查询过程类似于以下过程
List resultSet=[];
Array A=(select * from A)
for(int i=0;i<A.length;i++) {
if(exists(A[i].id) { //执行select 1 from B b where b.id=a.id是否有记录返回
resultSet.add(A[i]);
}
}
return resultSet;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
当B表比A表数据大时适合使用exists(),因为它没有那么遍历操作,只需要再执行一次查询就行.
如:A表有10000条记录,B表有1000000条记录,那么exists()会执行10000次去判断A表中的id是否与B表中的id相等.
如:A表有10000条记录,B表有100000000条记录,那么exists()还是执行10000次,因为它只执行A.length次,可见B表数据越多,越适合exists()发挥效果.
再如:A表有10000条记录,B表有100条记录,那么exists()还是执行10000次,还不如使用in()遍历10000*100次,因为in()是在内存里遍历比较,而exists()需要查询数据库,我们都知道查询数据库所消耗的性能更高,而内存比较很快.
结论:exists()适合B表比A表数据大的情况
当A表数据与B表数据一样大时,in与exists效率差不多,可任选一个使用.
SQL实战
detail表如下

1、查询A单位2021-03-04的付款总额
select * from detail where corp='A单位' and time='2021-03-04'
- 1
2、查询金额从200到400的记录交易笔数
select COUNT(*) from detail where amt BETWEEN '200' and '400'
- 1
count(*)和count(字段名) 查出的结果相同 结果为查出的记录总条数
3、查询问题中包含“通”的最大付款总额
select AMT from detail
where SUB like '%通%'
group by AMT desc
limit 1
- 1
- 2
- 3
- 4
limit接受一个或两个数字参数,参数必须是一个整数常量,如果给定两个常量,第一个参数为开始位置(默认为0),第二个参数表示要检索的行数
limit n 等价于limit 0,n
limit 5 //等价于limit 0,5 意为检索前5个记录行
4、将c单位,用途为水费的交易时间修改为2021-4-08
update detail
set time='2021-4-08'
where corp='c单位'
- 1
- 2
- 3
5、查询所有表中的AMT总和
select sum(AMT) from detail
- 1
6、把查到记录中的AMT-50后定义别名为money
SELECT AMT-50 as money FROM `detail`
- 1
使用 AS ,定义别名
格式:<表达式> AS <别名>
mysql的默认查询是不区分大小写的
如果需要区分大小写,可以利用Binary关键字在查询时设置查询语句区分大小写,语法为“select * from 表名 WHERE binary 字段=字段值”。
联结表(详情见博客MySQL中表连接方式)
1、内连接
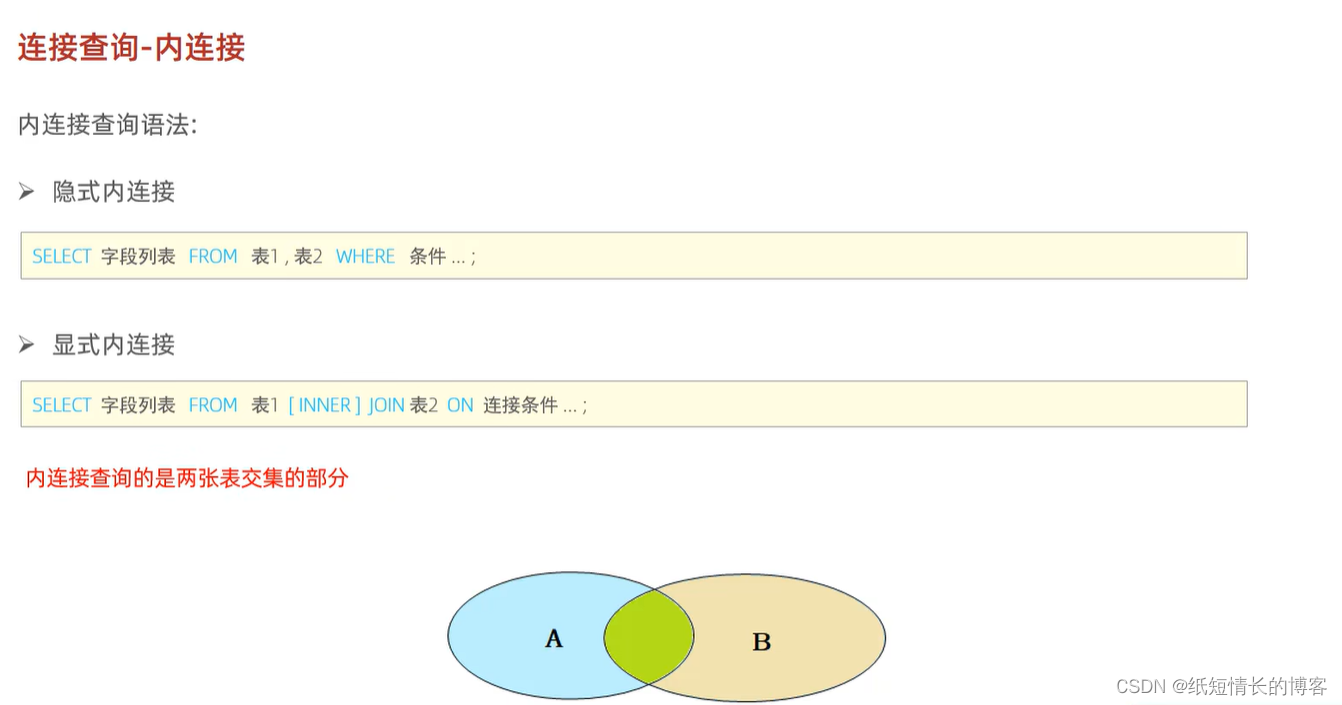
select * FROM t1,t2;
-- 内部连接
select * FROM t1 inner join t2;
- 1
- 2
- 3
2、左外连接(left join)

-- left outer join中outer可以省略不写,right join 同理,写上这个关键字只是意味着可读性好
select * from t1 left join t2 on t1.id = t2.id
- 1
- 2
3、右外连接(right join)
select * from t1 right join t2 on t1.id = t2.id
- 1
防止SQL注入的方法
sql注入,简单来说就是用户在前端web页面输入恶意的sql语句用来欺骗后端服务器去执行恶意的sql代码,从而导致数据库数据泄露或者遭受攻击。
1.PreparedStatement(简单又有效的方法-预编译语句集)
当我们在使用数据库时,如何去防止sql注入的发生呢?我们自然而然地就会想到在用JDBC进行连接时使用PreparedStatement类去代替Statement,或者传入的条件参数完全不使用String字符串,同样地,在用mybatis时,则尽量使用#{param}占位符的方式去避免sql注入,其实jdbc和mybatis的原理是一致的。我们都知道当我们使用PreparedStatement去写sql语句时,程序会对该条sql首先进行预编译,然后会将传入的字符串参数以字符串的形式去处理,即会在参数的两边自动加上单引号(’param’),而Statement则是直接简单粗暴地通过人工的字符串拼接的方式去写sql,那这样就很容易被sql注入。
采用预编译语句集,它内置了处理SQL注入的能力,只要使用它的setXXX方法传值即可。
使用好处:
(1).代码的可读性和可维护性.
(2).PreparedStatement尽最大可能提高性能.
(3).最重要的一点是极大地提高了安全性.
原理:
sql注入只对sql语句的准备(编译)过程有破坏作用
而PreparedStatement已经准备好了,执行阶段只是把输入串作为数据处理,
而不再对sql语句进行解析,准备,因此也就避免了sql注入问题.
2.使用正则表达式过滤传入的参数
3.字符串过滤
Mybatis中#{}与${}的区别
- #{}方式能够很大程度防止sql注入(安全),${}方式无法防止Sql注入
- 在JDBC能使用占位符的地方,最好优先使用#{}
- 在JDBC不支持使用占位符的地方,就只能使用${},典型情况就是 动态参数
详解如下:
Mybatis中#{}与${}的区别 https://blog.csdn.net/qq_44543508/article/details/97106696
在mysql的innodb引擎中,允许唯一索引的字段中出现多个null值 null值表示未知,因此两个null比较结果既不相等,也不不等,结果仍然未知,因此,多个null值的存在不违反唯一约束,所以是合理的。

