
- 12024年华为OD机试真题-考勤信息-Python-OD统一考试(C卷)
- 2【QT】QT元对象系统
- 3FFmpeg 调用 Android MediaCodec 进行硬解码(附源码)
- 4RUST腐蚀服务器添加 TAGS标签教程
- 5Unity——Animation_unity animation
- 6ETL工具之datax_datax断点续传
- 72022年第15届中国大学生计算机设计大赛_917267119
- 8spring,springMVC,springboot三者的关系_spring springboot springmvc的关系
- 9kettle error–只有一个输入记录期待设置变量并且至少已经收到2个变量_只有一个输入记录期待设置变量并且至少已经收到2个变量.
- 10电大统考计算机应用基础单选题,电大远程网络教育计算机应用基础统考题集真题.doc...
RabbitMQ实战超详细教程_rabbitmq实战教学
赞
踩
文章目录
1. 常见消息中间件大 PK
说到消息中间件,估计大伙多多少少都能讲出来一些,ActiveMQ、RabbitMQ、RocketMQ、Kafka 等等各种以及 JMS、AMQP 等各种协议,然而这些消息中间件各自都有什么特点,我们在开发中又该选择哪种呢?今天松哥就来和小伙伴们梳理一下。
1.1 几种协议
先来说说消息中间件中常见的几个协议。
1.1.1 JMS
1.1.1.1 JMS 介绍
先来说说 JMS。
JMS 全称 Java Message Service,类似于 JDBC,不同于 JDBC,JMS 是 JavaEE 的消息服务接口,JMS 主要有两个版本:
- 1.1
- 2.0。
两者相比,后者主要是简化了收发消息的代码。
考虑到消息中间件是一个非常常用的工具,所以 JavaEE 为此制定了专门的规范 JMS。
不过和 JDBC 一样,JMS 作为规范,他只是一套接口,并不包含具体的实现,如果我们要使用 JMS,那么一般还需要对应的实现,这就像使用 JDBC 需要对应的驱动一样。
1.1.1.2 JMS 模型
JMS 消息服务支持两种消息模型:
- 点对点或队列模型
- 发布 / 订阅模型
在点对点或队列模型下,一个生产者向一个特定的队列发布消息,一个消费者从该队列中读取消息。这里,生产者知道消费者的队列,并直接将消息发送到对应的队列。这是一种点对点的消息模型,这种模式被概括为:
- 只有一个消费者将获得消息。
- 生产者不需要在消费者消费该消息期间处于运行状态,消费者也同样不需要在消息发送时处于运行状态,即消息的生产者和消费者是完全解耦的。
- 每一个成功处理的消息都由消息消费者签收。
发布者 / 订阅者模型支持向一个特定的消息主题发布消息,消费者则可以定义自己感兴趣的主题,这是一种点对面的消息模型,这种模式可以被概括为:
- 多个消费者可以消费消息。
- 在发布者和订阅者之间存在时间依赖性,发布者需要创建一个订阅(subscription),以便客户能够订阅;订阅者必须保持在线状态以接收消息;当然,如果订阅者创建了持久的订阅,那么在订阅者未连接时,消息生产者发布的消息将会在订阅者重新连接时重新发布。
1.1.1.3 JMS 实现
开源的支持 JMS 的消息中间件有:
- Kafka
- Apache ActiveMQ
- JBoss 社区的 HornetQ
- Joram
- Coridan 的 MantaRay
- OpenJMS
一些商用的支持 JMS 的消息中间件有:
- WebLogic Server JMS
- EMS
- GigaSpaces
- iBus
- IONA JMS
- IQManager(2005 年 8 月被 Sun Microsystems 并购)
- JMS+
- Nirvana
- SonicMQ
- WebSphere MQ
这里有不少是松哥考古挖掘出来的,其实对于我们日常开发接触较多的,可能就是 Kafka 和 ActiveMQ。
1.1.2 AMQP
1.1.2.1 AMQP 简介
另一个和消息中间件有关的协议就是 AMQP 了。
Message Queue 的需求由来已久,80 年代最早在金融交易中,高盛等公司采用 Teknekron 公司的产品,当时的 Message Queue 软件叫做:the information bus(TIB)。 TIB 被电信和通讯公司采用,路透社收购了 Teknekron 公司。之后,IBM 开发了 MQSeries,微软开发了 Microsoft Message Queue(MSMQ)。这些商业 MQ 供应商的问题是厂商锁定,价格高昂。2001 年,Java Message Service 试图解决锁定和交互性的问题,但对应用来说反而更加麻烦了。
于是 2004 年,摩根大通和 iMatrix 开始着手 Advanced Message Queuing Protocol (AMQP)开放标准的开发。2006 年,AMQP 规范发布。2007 年,Rabbit 技术公司基于 AMQP 标准开发的 RabbitMQ 1.0 发布。
目前 RabbitMQ 的最新版本为 3.5.7,基于 AMQP 0-9-1。
在 AMQP 协议中,消息收发涉及到如下一些概念:
- Broker: 接收和分发消息的应用,我们日常所用的 RabbitMQ 就是一个 Message Broker。
- Virtual host: 出于多租户和安全因素设计的,把 AMQP 的基本组件划分到一个虚拟的分组中,类似于网络中的 namespace 概念。当多个不同的用户使用同一个 RabbitMQ 提供的服务时,可以划分出多个 vhost,每个用户在自己的 vhost 中创建
exchange/queue等,这个松哥之前写过专门的文章,传送门:RabbitMQ 中的 VirtualHost 该如何理解。 - Connection: publisher/consumer 和 broker 之间的 TCP 连接,断开连接的操作只会在 client 端进行,Broker 不会断开连接,除非出现网络故障或 broker 服务出现问题。
- Channel: 如果每一次访问 RabbitMQ 都建立一个 Connection,在消息量大的时候建立 TCP Connection 的开销将是巨大的,效率也较低。Channel 是在 Connection 内部建立的逻辑连接,如果应用程序支持多线程,通常每个 Thread 创建单独的 Channel 进行通讯,AMQP method 包含了 Channel id 帮助客户端和 Message Broker 识别 Channel,所以 Channel 之间是完全隔离的。Channel 作为轻量级的 Connection 极大减少了操作系统建立 TCP Connection 的开销,关于 Channel,松哥在 RabbitMQ 管理页面该如何使用一文中也做过详细介绍。
- Exchange: Message 到达 Broker 的第一站,根据分发规则,匹配查询表中的 routing key,分发消息到 queue 中去。常用的类型有:direct (点对点), topic(发布订阅) 以及 fanout (广播)。
- Queue: 消息最终被送到这里等待 Consumer 取走,一个 Message 可以被同时拷贝到多个 queue 中。
- Binding: Exchange 和 Queue 之间的虚拟连接,binding 中可以包含 routing key,Binding 信息被保存到 Exchange 中的查询表中,作为 Message 的分发依据。
1.1.2.2 AMQP 实现
来看看实现了 AMQP 协议的一些具体的消息中间件产品都有哪些。
- Apache Qpid
- Apache ActiveMQ
- RabbitMQ
可能有小伙伴奇怪咋还有 ActiveMQ?其实 ActiveMQ 不仅支持 JMS,也支持 AMQP,这个松哥后面细说。
另外还有大家熟知的阿里出品的 RocketMQ,这个是自定义了一套协议,社区也提供了 JMS,但是不太成熟,后面松哥细说。
1.1.3 MQTT
做物联网开发的小伙伴应该会经常接触这个协议,MQTT(Message Queuing Telemetry Transport,消息队列遥测传输)是 IBM 开发的一个即时通讯协议,目前看来算是物联网开发中比较重要的协议之一了,该协议支持所有平台,几乎可以把所有联网物品和外部连接起来,被用来当做传感器和 Actuator(比如通过 Twitter 让房屋联网)的通信协议,它的优点是格式简洁、占用带宽小、支持移动端通信、支持 PUSH、适用于嵌入式系统。
1.1.4 XMPP
XMPP(可扩展消息处理现场协议,Extensible Messaging and Presence Protocol)是一个基于 XML 的协议,多用于即时消息(IM)以及在线现场探测,适用于服务器之间的准即时操作。核心是基于 XML 流传输,这个协议可能最终允许因特网用户向因特网上的其他任何人发送即时消息,即使其操作系统和浏览器不同。 它的优点是通用公开、兼容性强、可扩展、安全性高,缺点是 XML 编码格式占用带宽大。
1.1.5 JMS Vs AMQP
对于我们 Java 工程师而言,大家日常接触较多的应该是 JMS 和 AMQP 协议,既然 JMS 和 AMQP 都是协议,那么两者有什么区别呢?来看下面一张图:
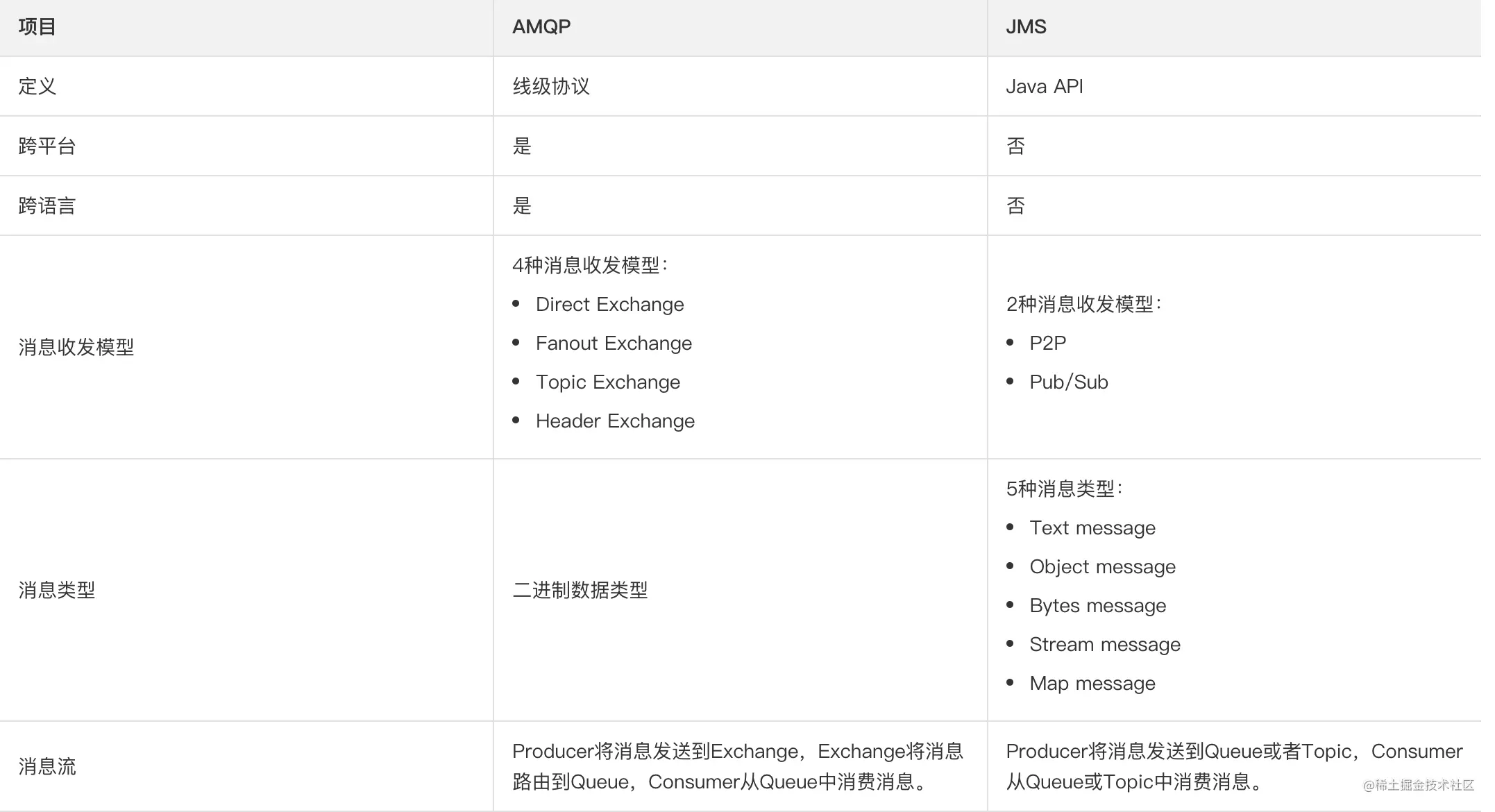
这张图说的很清楚了,我就不啰嗦了。
1.2. 重要产品
1.2.1 ActiveMQ
ActiveMQ 是 Apache 下的一个子项目,使用完全支持 JMS1.1 和 J2EE1.4 规范的 JMS Provider 实现,少量代码就可以高效地实现高级应用场景,并且支持可插拔的传输协议,如:in-VM, TCP, SSL, NIO, UDP, multicast, JGroups and JXTA transports。
ActiveMQ 支持常用的多种语言客户端如 C++、Java、.Net,、Python、 Php、 Ruby 等。
现在的 ActiveMQ 分为两个版本:
- ActiveMQ Classic
- ActiveMQ Artemis
这里的 ActiveMQ Classic 就是原来的 ActiveMQ,而 ActiveMQ Artemis 是在 RedHat 捐赠的 HornetQ 服务器代码的基础上开发的,两者代码完全不同,后者支持 JMS2.0,使用基于 Netty 的异步 IO,大大提升了性能,更为神奇的是,后者不仅支持 JMS 协议,还支持 AMQP 协议、STOMP 以及 MQTT,可以说后者的玩法相当丰富。
因此大家在使用时,建议直接选择 ActiveMQ Artemis。
1.2.2 RabbitMQ
RabbitMQ 算是 AMQP 体系下最为重要的产品了,它基于 Erlang 语言开发实现,估计很多人被 RabbitMQ 的安装折磨过,松哥建议安装 RabbitMQ 直接用 Docker,省心省力(公号后台回复 docker 有教程)。
RabbitMQ 支持 AMQP、XMPP、SMTP、STOMP 等多种协议,功能强大,适用于企业级开发。
来看一张 RabbitMQ 的结构图:
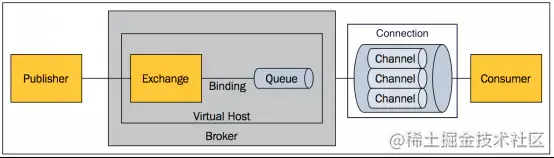
关于 RabbitMQ,松哥最近发了十来篇教程了,这里就不再啰嗦了。
1.2.3 RocketMQ
RocketMQ 是阿里开源的一款分布式消息中间件,原名 Metaq,从 3.0 版本开始改名为 RocketMQ,是阿里参照 Kafka 设计思想使用 Java 语言实现的一套 MQ。RocketMQ 将阿里内部多款 MQ 产品(Notify、Metaq)进行整合,只维护核心功能,去除了所有其他运行时依赖,保证核心功能最简化,在此基础上配合阿里上述其他开源产品实现不同场景下 MQ 的架构,目前主要用于订单交易系统。
RocketMQ 具有以下特点:
- 保证严格的消息顺序。
- 提供针对消息的过滤功能。
- 提供丰富的消息拉取模式。
- 高效的订阅者水平扩展能力。
- 实时的消息订阅机制。
- 亿级消息堆积能力
对于 Java 工程师而言,这也是一种经常会用到的 MQ。
1.2.4 Kafka
Kafka 是 Apache 下的一个开源流处理平台,由 Scala 和 Java 编写。Kafka 是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作(网页浏览,搜索和其他用户的行动)流数据。Kafka 的目的是通过 Hadoop 的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。
Kafka 具有以下特性:
- 快速持久化:通过磁盘顺序读写与零拷贝机制,可以在 O(1) 的系统开销下进行消息持久化。
- 高吞吐:在一台普通的服务器上既可以达到 10W/s 的吞吐速率。
- 高堆积:支持 topic 下消费者较长时间离线,消息堆积量大。
- 完全的分布式系统:Broker、Producer、Consumer 都原生自动支持分布式,通过 Zookeeper 可以自动实现更加复杂的负载均衡。
- 支持 Hadoop 数据并行加载。
大数据开发中大家可能会经常接触 Kafka,Java 开发中也会接触,但是相对来说可能接触的少一些。
1.2.5 ZeroMQ
ZeroMQ 号称最快的消息队列系统,它专门为高吞吐量 / 低延迟的场景开发,在金融界的应用中经常使用,偏重于实时数据通信场景。ZeroMQ 不是单独的服务,而是一个嵌入式库,它封装了网络通信、消息队列、线程调度等功能,向上层提供简洁的 API,应用程序通过加载库文件,调用 API 函数来实现高性能网络通信。
ZeroMQ 的特性:
- 无锁的队列模型:对于跨线程间的交互(用户端和 session)之间的数据交换通道 pipe,采用无锁的队列算法 CAS,在 pipe 的两端注册有异步事件,在读或者写消息到 pipe 时,会自动触发读写事件。
- 批量处理的算法:对于批量的消息,进行了适应性的优化,可以批量的接收和发送消息。
- 多核下的线程绑定,无须 CPU 切换:区别于传统的多线程并发模式,信号量或者临界区,ZeroMQ 充分利用多核的优势,每个核绑定运行一个工作者线程,避免多线程之间的 CPU 切换开销。
1.2.6 其他
另外还有如 Redis 也能做消息队列,松哥之前也发过文章和大家介绍用 Redis 做普通消息队列和延迟消息队列,这里也就不啰嗦了。
1.3. 比较
最后,我们再来通过一张图来比较下各个消息中间件。

小伙伴们在公众号后台回复 mqpkmq,可以获取这个 Excel 表格链接。
2. RabbitMQ 管理页面
RabbitMQ 的 web 管理页面相信很多小伙伴都用过,随便点一下估计也都知道啥意思,不过本着精益求精的思想,松哥还是想和大家捋一捋这个管理页面的各个细节。
2.1 概览
首先,这个 Web 管理页面大概就像下图这样:
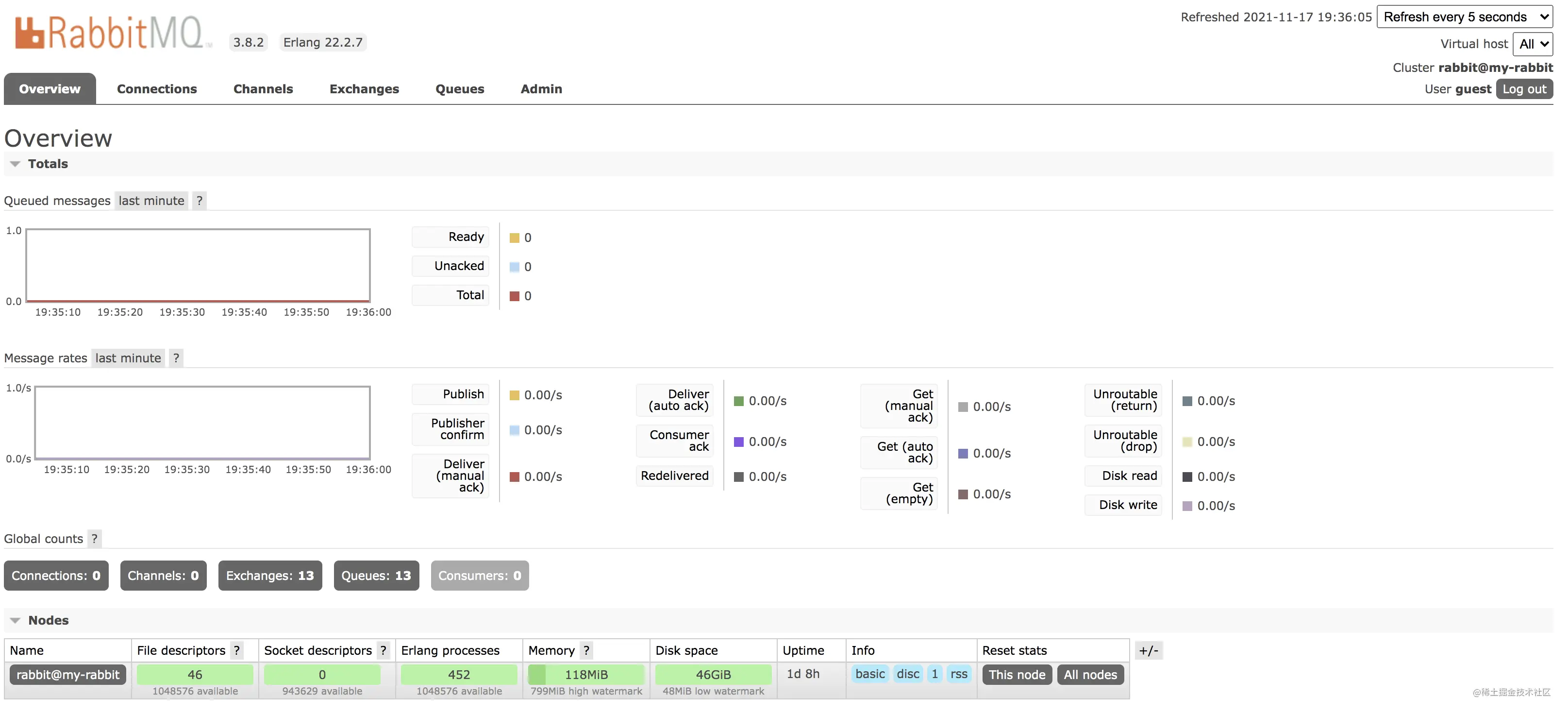
首先一共有六个选项卡:
- Overview:这里可以概览 RabbitMQ 的整体情况,如果是集群,也可以查看集群中各个节点的情况。包括 RabbitMQ 的端口映射信息等,都可以在这个选项卡中查看。
- Connections:这个选项卡中是连接上 RabbitMQ 的生产者和消费者的情况。
- Channels:这里展示的是 “通道” 信息,关于 “通道” 和“连接”的关系,松哥在后文再和大家详细介绍。
- Exchange:这里展示所有的交换机信息。
- Queue:这里展示所有的队列信息。
- Admin:这里展示所有的用户信息。
右上角是页面刷新的时间,默认是 5 秒刷新一次,展示的是所有的 Virtual host。
这是整个管理页面的一个大致情况,接下来我们来逐个介绍。
2.2 Overview
Overview 中分了如下一些功能模块:
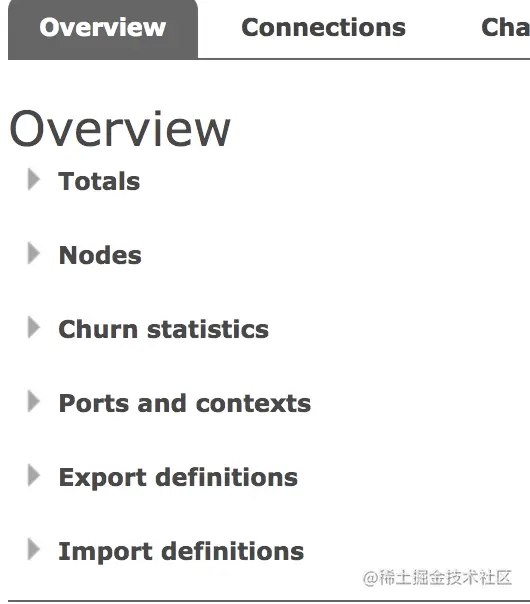
分别是:
Totals:
Totals 里面有 准备消费的消息数、待确认的消息数、消息总数以及消息的各种处理速率(发送速率、确认速率、写入硬盘速率等等)。

Nodes:
Nodes 其实就是支撑 RabbitMQ 运行的一些机器,相当于集群的节点。

点击每个节点,可以查看节点的详细信息。
Churn statistics:
这个不好翻译,里边展示的是 Connection、Channel 以及 Queue 的创建 / 关闭速率。

Ports and contexts:

这个里边展示了端口的映射信息以及 Web 的上下文信息。
- 5672 是 RabbitMQ 通信端口。
- 15672 是 Web 管理页面端口。
- 25672 是集群通信端口。
Export definitions && Import definitions:
最后面这两个可以导入导出当前实例的一些配置信息:

2.3 Connections
这里主要展示的是当前连接上 RabbitMQ 的信息,无论是消息生产者还是消息消费者,只要连接上来了这里都会显示出来。
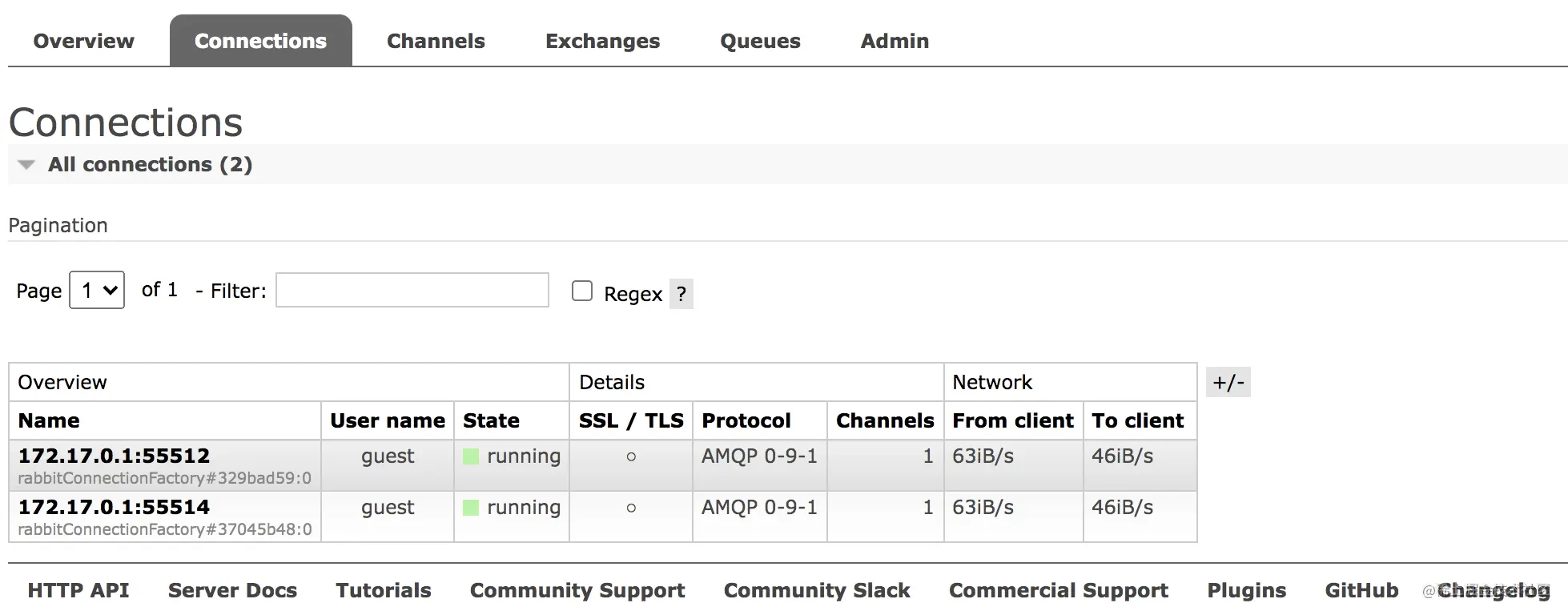
注意协议中的 AMQP 0-9-1 指的是 AMQP 协议的版本号。
其他属性含义如下:
- User name:当前连接使用的用户名。
- State:当前连接的状态,running 表示运行中;idle 表示空闲。
- SSL/TLS:表示是否使用 ssl 进行连接。
- Channels:当前连接创建的通道总数。
- From client:每秒发出的数据包。
- To client:每秒收到的数据包。
点击连接名称可以查看每一个连接的详情。
在详情中可以查看每一个连接的通道数以及其他详细信息,也可以强制关闭一个连接。
2.4 Channels
这个地方展示的是通道的信息:
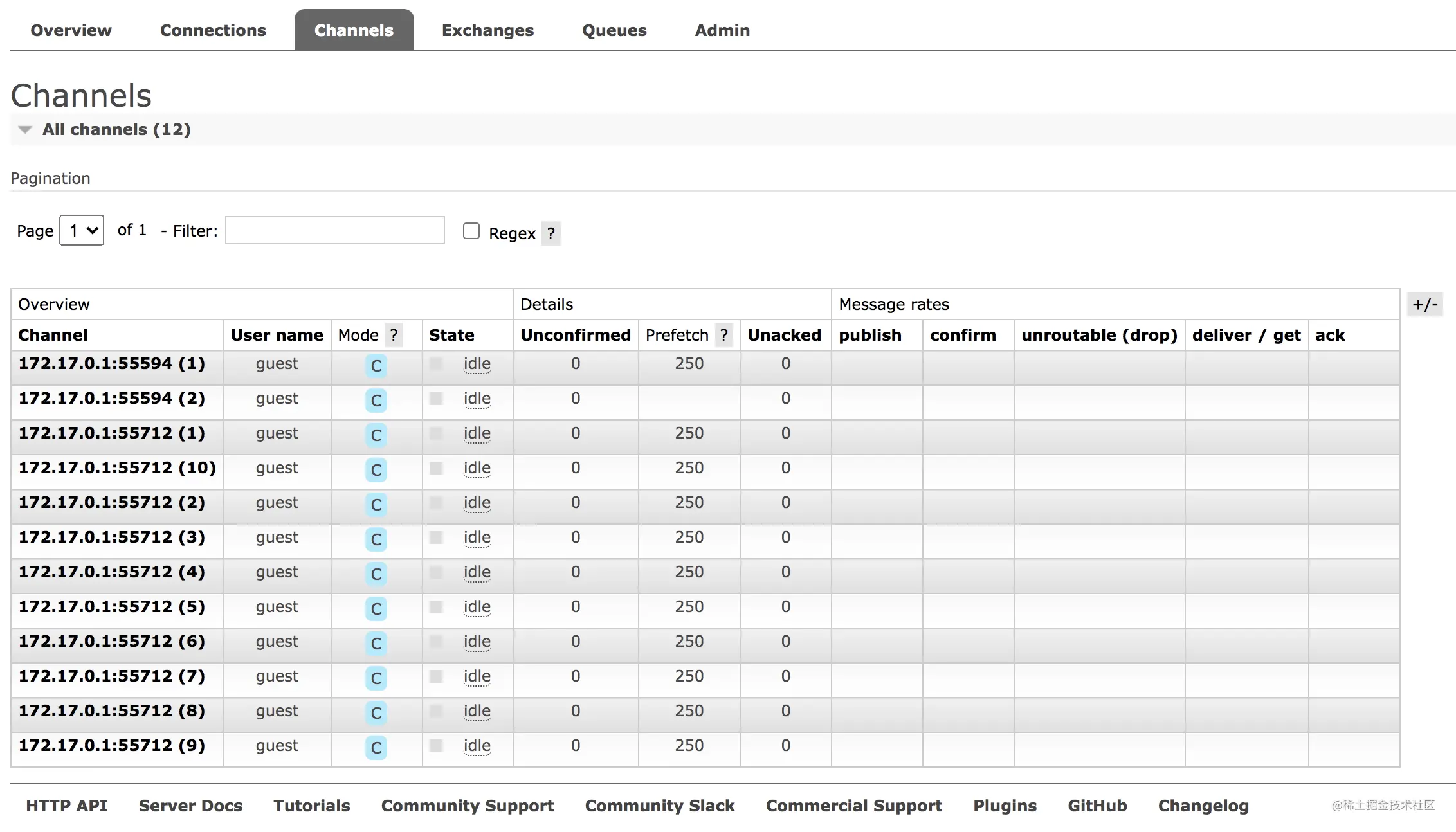
那么什么是通道呢?
一个连接(IP)可以有多个通道,如上图,一共是两个连接,但是一共有 12 个通道。
一个连接可以有多个通道,这个多个通道通过多线程实现,一般情况下,我们在通道中创建队列、交换机等。
生产者的通道一般会立马关闭;消费者是一直监听的,通道几乎是会一直存在。
上面各项参数含义分别如下:
- Channel:通道名称。
- User name:该通道登录使用的用户名。
- Model:通道确认模式,C 表示 confirm;T 表示事务。
- State:通道当前的状态,running 表示运行中;idle 表示空闲。
- Unconfirmed:待确认的消息总数。
- Prefetch:Prefetch 表示每个消费者最大的能承受的未确认消息数目,简单来说就是用来指定一个消费者一次可以从 RabbitMQ 中获取多少条消息并缓存在消费者中,一旦消费者的缓冲区满了,RabbitMQ 将会停止投递新的消息到该消费者中直到它发出有消息被 ack 了。总的来说,消费者负责不断处理消息,不断 ack,然后只要 unAcked 数少于 prefetch * consumer 数目,RabbitMQ 就不断将消息投递过去。
- Unacker:待 ack 的消息总数。
- publish:消息生产者发送消息的速率。
- confirm:消息生产者确认消息的速率。
- unroutable (drop):表示未被接收,且已经删除了的消息。
- deliver/get:消息消费者获取消息的速率。
- ack:消息消费者 ack 消息的速率。
2.5 Exchange
这个地方展示交换机信息:

这里会展示交换机的各种信息。
Type 表示交换机的类型。
Features 有两个取值 D 和 I。
D 表示交换机持久化,将交换机的属性在服务器内部保存,当 MQ 的服务器发生意外或关闭之后,重启 RabbitMQ 时不需要重新手动或执行代码去建立交换机,交换机会自动建立,相当于一直存在。
I 表示这个交换机不可以被消息生产者用来推送消息,仅用来进行交换机和交换机之间的绑定。
Message rate in 表示消息进入的速率。 Message rate out 表示消息出去的速率。
点击下方的 Add a new exchange 可以创建一个新的交换机。
2.6 Queue
这个选项卡就是用来展示消息队列的:
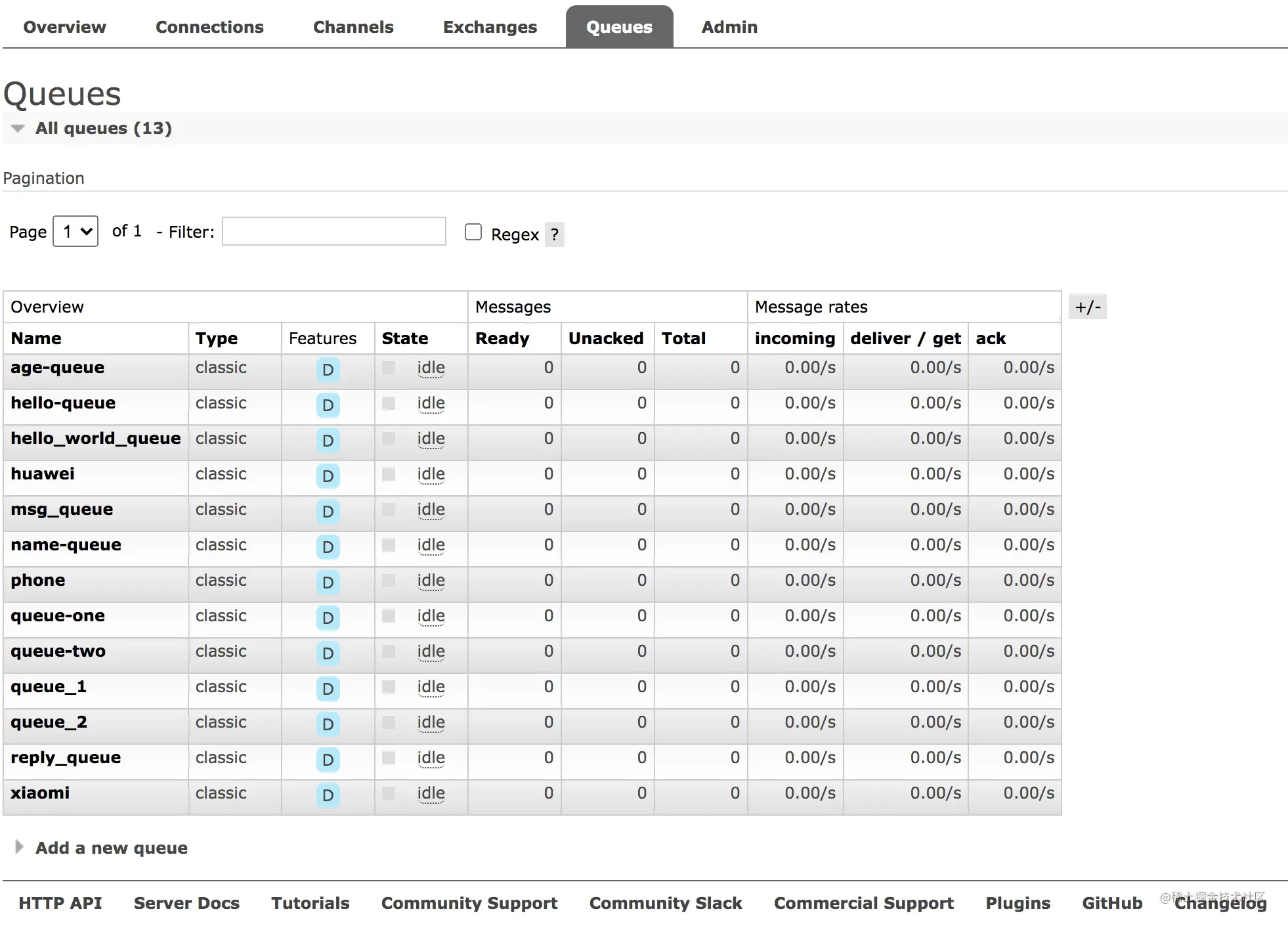
各项含义如下:
- Name:表示消息队列名称。
- Type:表示消息队列的类型,除了上图的 classic,另外还有一种消息类型是 Quorum。两个区别如下图:

- Features:表示消息队列的特性,D 表示消息队列持久化。
- State:表示当前队列的状态,running 表示运行中;idle 表示空闲。
- Ready:表示待消费的消息总数。
- Unacked:表示待应答的消息总数。
- Total:表示消息总数 Ready+Unacked。
- incoming:表示消息进入的速率。
- deliver/get:表示获取消息的速率。
- ack:表示消息应答的速率。
点击下方的 Add a new queue 可以添加一个新的消息队列。
点击每一个消息队列的名称,可以进入到消息队列中。进入到消息队列后,可以完成对消息队列的进一步操作,例如:
- 将消息队列和某一个交换机进行绑定。
- 发送消息。
- 获取一条消息。
- 移动一条消息(需要插件的支持)。
- 删除消息队列。
- 清空消息队列中的消息。
- …
如下图:

2.7 Admin
这里是做一些用户管理操作,如下图:

各项属性含义如下:
- Name:表示用户名称。
- Tags:表示角色标签,只能选取一个。
- Can access virtual hosts:表示允许进入的虚拟主机。
- Has password:表示这个用户是否设置了密码。
常见的两个操作时管理用户和虚拟主机。
点击下方的 Add a user 可以添加一个新的用户,添加用户的时候需要给用户设置 Tags,其实就是用户角色,如下:
- none:
不能访问 management plugin
- management:
用户可以通过 AMQP 做的任何事 列出自己可以通过 AMQP 登入的 virtual hosts 查看自己的 virtual hosts 中的 queues, exchanges 和 bindings 查看和关闭自己的 channels 和 connections 查看有关自己的 virtual hosts 的 “全局” 的统计信息,包含其他用户在这些 virtual hosts 中的活动
- policymaker:
management 可以做的任何事 查看、创建和删除自己的 virtual hosts 所属的 policies 和 parameters
- monitoring:
management 可以做的任何事 列出所有 virtual hosts,包括他们不能登录的 virtual hosts 查看其他用户的 connections 和 channels 查看节点级别的数据如 clustering 和 memory 使用情况 查看真正的关于所有 virtual hosts 的全局的统计信息
- administrator:
policymaker 和 monitoring 可以做的任何事 创建和删除 virtual hosts 查看、创建和删除 users 查看创建和删除 permissions 关闭其他用户的 connections
- impersonator(模拟者)
模拟者,无法登录管理控制台。
另外,这里也可以进行虚拟主机 virtual host 的操作,后面小节会和大家介绍虚拟主机。
3. RabbitMQ 七种消息收发方式
本小节来和小伙伴们分享一下 RabbitMQ 的七种消息传递形式。一起来看看。
大部分情况下,我们可能都是在 Spring Boot 或者 Spring Cloud 环境下使用 RabbitMQ,因此本文我也主要从这两个方面来和大家分享 RabbitMQ 的用法。
3.1 RabbitMQ 架构简介
一图胜千言,如下:
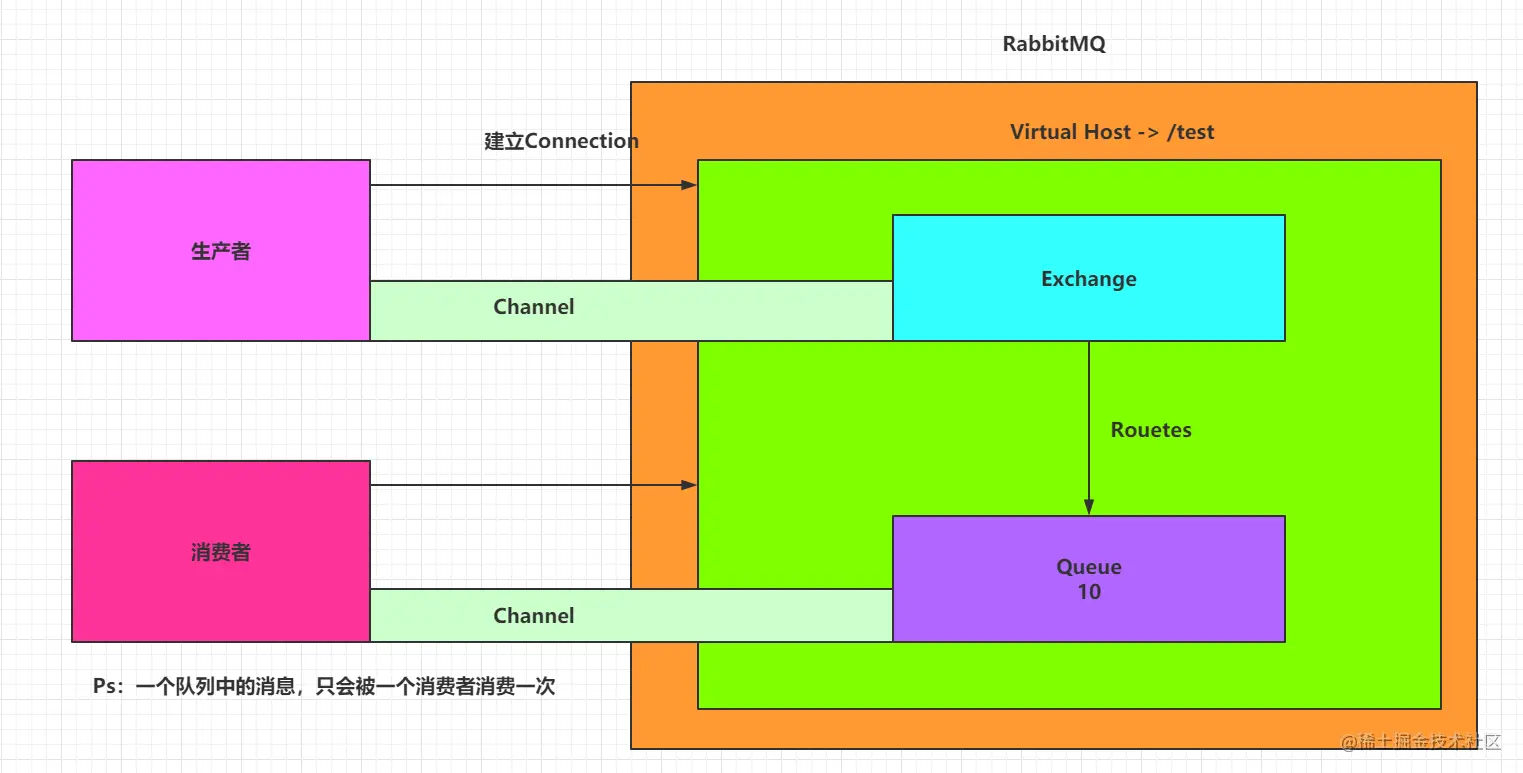
这张图中涉及到如下一些概念:
- 生产者(Publisher):发布消息到 RabbitMQ 中的交换机(Exchange)上。
- 交换机(Exchange):和生产者建立连接并接收生产者的消息。
- 消费者(Consumer):监听 RabbitMQ 中的 Queue 中的消息。
- 队列(Queue):Exchange 将消息分发到指定的 Queue,Queue 和消费者进行交互。
- 路由(Routes):交换机转发消息到队列的规则。
3.2 准备工作
大家知道,RabbitMQ 是 AMQP 阵营里的产品,Spring Boot 为 AMQP 提供了自动化配置依赖 spring-boot-starter-amqp,因此首先创建 Spring Boot 项目并添加该依赖,如下:
项目创建成功后,在 application.properties 中配置 RabbitMQ 的基本连接信息,如下:
spring.rabbitmq.host=localhost
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.port=5672
- 1
- 2
- 3
- 4
- 5
接下来进行 RabbitMQ 配置,在 RabbitMQ 中,所有的消息生产者提交的消息都会交由 Exchange 进行再分配,Exchange 会根据不同的策略将消息分发到不同的 Queue 中。
RabbitMQ 官网介绍了如下几种消息分发的形式:
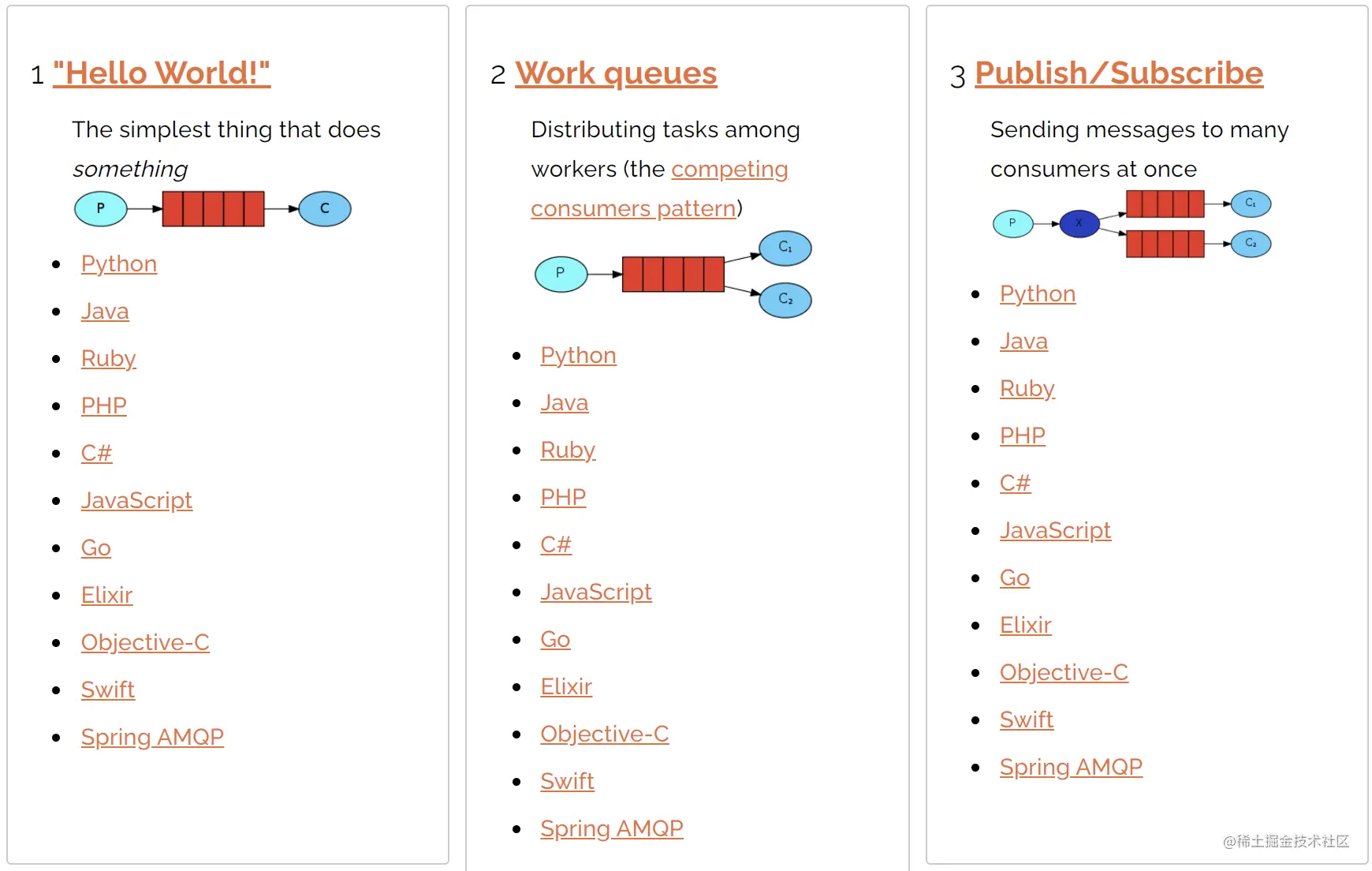


这里给出了七种,其中第七种是消息确认,消息确认这块松哥之前发过相关的文章,传送门:
所以这里我主要和大家介绍前六种消息收发方式。
3.3 消息收发
3.3.1 Hello World
咦?这个咋没有交换机?这个其实是默认的交换机,我们需要提供一个生产者一个队列以及一个消费者。消息传播图如下:

来看看代码实现:
先来看看队列的定义:
@Configuration
public class HelloWorldConfig {
public static final String HELLO_WORLD_QUEUE_NAME = "hello_world_queue";
@Bean
Queue queue1() {
return new Queue(HELLO_WORLD_QUEUE_NAME);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
再来看看消息消费者的定义:
@Component
public class HelloWorldConsumer {
@RabbitListener(queues = HelloWorldConfig.HELLO_WORLD_QUEUE_NAME)
public void receive(String msg) {
System.out.println("msg = " + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
消息发送:
@SpringBootTest
class RabbitmqdemoApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
rabbitTemplate.convertAndSend(HelloWorldConfig.HELLO_WORLD_QUEUE_NAME, "hello");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
这个时候使用的其实是默认的直连交换机(DirectExchange),DirectExchange 的路由策略是将消息队列绑定到一个 DirectExchange 上,当一条消息到达 DirectExchange 时会被转发到与该条消息 routing key 相同的 Queue 上,例如消息队列名为 “hello-queue”,则 routingkey 为 “hello-queue” 的消息会被该消息队列接收。
3.3.2 Work queues
这种情况是这样的:
一个生产者,一个默认的交换机(DirectExchange),一个队列,两个消费者,如下图:

一个队列对应了多个消费者,默认情况下,由队列对消息进行平均分配,消息会被分到不同的消费者手中。消费者可以配置各自的并发能力,进而提高消息的消费能力,也可以配置手动 ack,来决定是否要消费某一条消息。
先来看并发能力的配置,如下:
@Component
public class HelloWorldConsumer {
@RabbitListener(queues = HelloWorldConfig.HELLO_WORLD_QUEUE_NAME)
public void receive(String msg) {
System.out.println("receive = " + msg);
}
@RabbitListener(queues = HelloWorldConfig.HELLO_WORLD_QUEUE_NAME,concurrency = "10")
public void receive2(String msg) {
System.out.println("receive2 = " + msg+"------->"+Thread.currentThread().getName());
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
可以看到,第二个消费者我配置了 concurrency 为 10,此时,对于第二个消费者,将会同时存在 10 个子线程去消费消息。
启动项目,在 RabbitMQ 后台也可以看到一共有 11 个消费者。
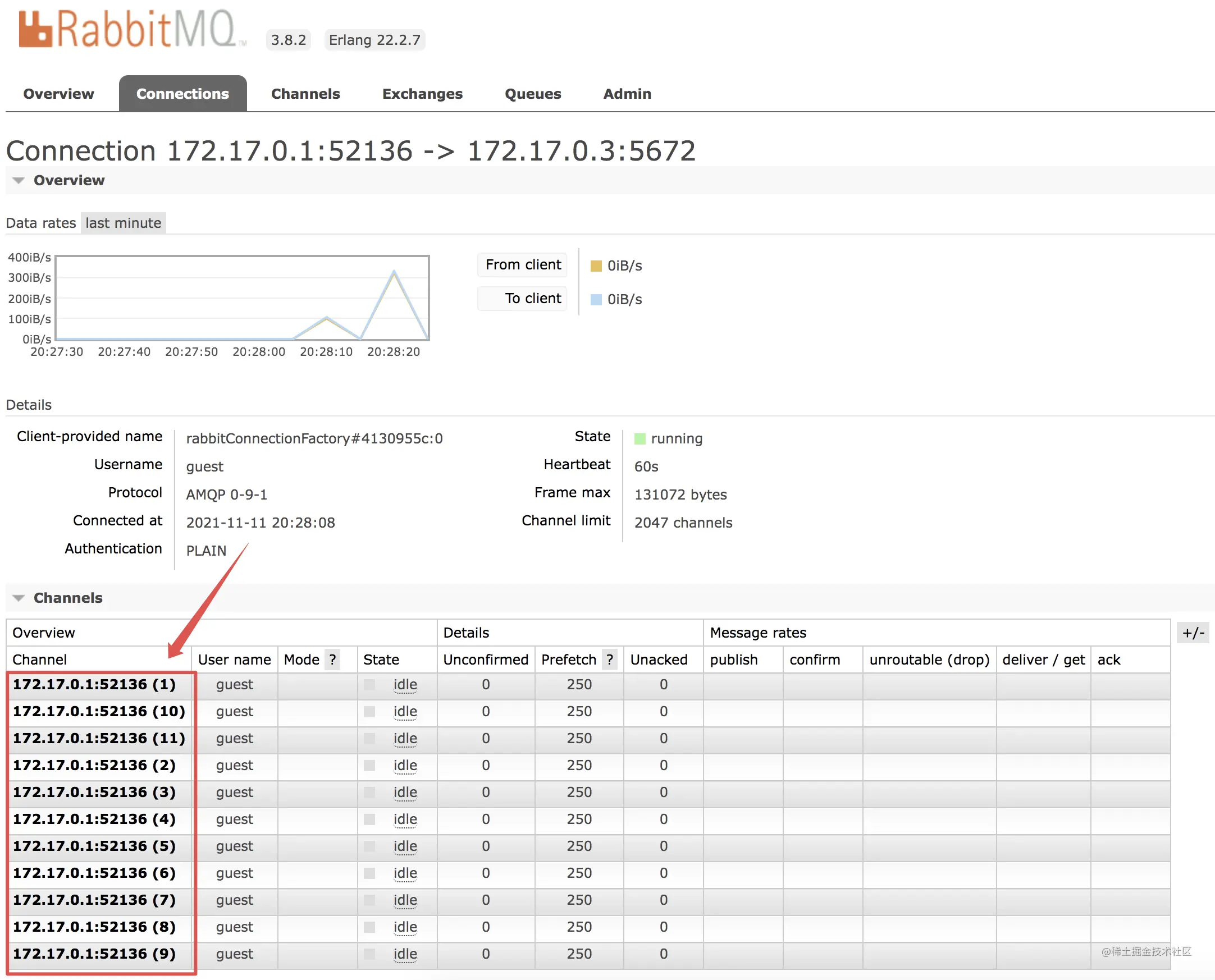
此时,如果生产者发送 10 条消息,就会一下都被消费掉。
消息发送方式如下:
@SpringBootTest
class RabbitmqdemoApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
for (int i = 0; i < 10; i++) {
rabbitTemplate.convertAndSend(HelloWorldConfig.HELLO_WORLD_QUEUE_NAME, "hello");
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
消息消费日志如下:

可以看到,消息都被第二个消费者消费了。但是小伙伴们需要注意,事情并不总是这样(多试几次就可以看到差异),消息也有可能被第一个消费者消费(只是由于第二个消费者有十个线程一起开动,所以第二个消费者消费的消息占比更大)。
当然消息消费者也可以开启手动 ack,这样可以自行决定是否消费 RabbitMQ 发来的消息,配置手动 ack 的方式如下:
spring.rabbitmq.listener.simple.acknowledge-mode=manual
- 1
- 2
消费代码如下:
@Component
public class HelloWorldConsumer {
@RabbitListener(queues = HelloWorldConfig.HELLO_WORLD_QUEUE_NAME)
public void receive(Message message,Channel channel) throws IOException {
System.out.println("receive="+message.getPayload());
channel.basicAck(((Long) message.getHeaders().get(AmqpHeaders.DELIVERY_TAG)),true);
}
@RabbitListener(queues = HelloWorldConfig.HELLO_WORLD_QUEUE_NAME, concurrency = "10")
public void receive2(Message message, Channel channel) throws IOException {
System.out.println("receive2 = " + message.getPayload() + "------->" + Thread.currentThread().getName());
channel.basicReject(((Long) message.getHeaders().get(AmqpHeaders.DELIVERY_TAG)), true);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
此时第二个消费者拒绝了所有消息,第一个消费者消费了所有消息。
这就是 Work queues 这种情况。
3.3.3 Publish/Subscribe
再来看发布订阅模式,这种情况是这样:
一个生产者,多个消费者,每一个消费者都有自己的一个队列,生产者没有将消息直接发送到队列,而是发送到了交换机,每个队列绑定交换机,生产者发送的消息经过交换机,到达队列,实现一个消息被多个消费者获取的目的。需要注意的是,如果将消息发送到一个没有队列绑定的 Exchange 上面,那么该消息将会丢失,这是因为在 RabbitMQ 中 Exchange 不具备存储消息的能力,只有队列具备存储消息的能力,如下图:

这种情况下,我们有四种交换机可供选择,分别是:
- Direct
- Fanout
- Topic
- Header
我分别来给大家举一个简单例子看下。
3.3.3.1 Direct
DirectExchange 的路由策略是将消息队列绑定到一个 DirectExchange 上,当一条消息到达 DirectExchange 时会被转发到与该条消息 routing key 相同的 Queue 上,例如消息队列名为 “hello-queue”,则 routingkey 为 “hello-queue” 的消息会被该消息队列接收。DirectExchange 的配置如下:
@Configuration public class RabbitDirectConfig { public final static String DIRECTNAME = "javaboy-direct"; @Bean Queue queue() { return new Queue("hello-queue"); } @Bean DirectExchange directExchange() { return new DirectExchange(DIRECTNAME, true, false); } @Bean Binding binding() { return BindingBuilder.bind(queue()) .to(directExchange()).with("direct"); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 首先提供一个消息队列 Queue,然后创建一个 DirectExchange 对象,三个参数分别是名字,重启后是否依然有效以及长期未用时是否删除。
- 创建一个 Binding 对象将 Exchange 和 Queue 绑定在一起。
- DirectExchange 和 Binding 两个 Bean 的配置可以省略掉,即如果使用 DirectExchange,可以只配置一个 Queue 的实例即可。
再来看看消费者:
@Component
public class DirectReceiver {
@RabbitListener(queues = "hello-queue")
public void handler1(String msg) {
System.out.println("DirectReceiver:" + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
通过 @RabbitListener 注解指定一个方法是一个消息消费方法,方法参数就是所接收到的消息。然后在单元测试类中注入一个 RabbitTemplate 对象来进行消息发送,如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class RabbitmqApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
public void directTest() {
rabbitTemplate.convertAndSend("hello-queue", "hello direct!");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
最终执行结果如下:

3.3.3.2 Fanout
FanoutExchange 的数据交换策略是把所有到达 FanoutExchange 的消息转发给所有与它绑定的 Queue 上,在这种策略中,routingkey 将不起任何作用,FanoutExchange 配置方式如下:
@Configuration public class RabbitFanoutConfig { public final static String FANOUTNAME = "sang-fanout"; @Bean FanoutExchange fanoutExchange() { return new FanoutExchange(FANOUTNAME, true, false); } @Bean Queue queueOne() { return new Queue("queue-one"); } @Bean Queue queueTwo() { return new Queue("queue-two"); } @Bean Binding bindingOne() { return BindingBuilder.bind(queueOne()).to(fanoutExchange()); } @Bean Binding bindingTwo() { return BindingBuilder.bind(queueTwo()).to(fanoutExchange()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
在这里首先创建 FanoutExchange,参数含义与创建 DirectExchange 参数含义一致,然后创建两个 Queue,再将这两个 Queue 都绑定到 FanoutExchange 上。接下来创建两个消费者,如下:
@Component
public class FanoutReceiver {
@RabbitListener(queues = "queue-one")
public void handler1(String message) {
System.out.println("FanoutReceiver:handler1:" + message);
}
@RabbitListener(queues = "queue-two")
public void handler2(String message) {
System.out.println("FanoutReceiver:handler2:" + message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
两个消费者分别消费两个消息队列中的消息,然后在单元测试中发送消息,如下:
@RunWith(SpringRunner.class)
@SpringBootTest
public class RabbitmqApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
public void fanoutTest() {
rabbitTemplate
.convertAndSend(RabbitFanoutConfig.FANOUTNAME,
null, "hello fanout!");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
注意这里发送消息时不需要 routingkey,指定 exchange 即可,routingkey 可以直接传一个 null。
最终执行日志如下:

3.3.3.3 Topic
TopicExchange 是比较复杂但是也比较灵活的一种路由策略,在 TopicExchange 中,Queue 通过 routingkey 绑定到 TopicExchange 上,当消息到达 TopicExchange 后,TopicExchange 根据消息的 routingkey 将消息路由到一个或者多个 Queue 上。TopicExchange 配置如下:
@Configuration public class RabbitTopicConfig { public final static String TOPICNAME = "sang-topic"; @Bean TopicExchange topicExchange() { return new TopicExchange(TOPICNAME, true, false); } @Bean Queue xiaomi() { return new Queue("xiaomi"); } @Bean Queue huawei() { return new Queue("huawei"); } @Bean Queue phone() { return new Queue("phone"); } @Bean Binding xiaomiBinding() { return BindingBuilder.bind(xiaomi()).to(topicExchange()) .with("xiaomi.#"); } @Bean Binding huaweiBinding() { return BindingBuilder.bind(huawei()).to(topicExchange()) .with("huawei.#"); } @Bean Binding phoneBinding() { return BindingBuilder.bind(phone()).to(topicExchange()) .with("#.phone.#"); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 首先创建 TopicExchange,参数和前面的一致。然后创建三个 Queue,第一个 Queue 用来存储和 “xiaomi” 有关的消息,第二个 Queue 用来存储和 “huawei” 有关的消息,第三个 Queue 用来存储和 “phone” 有关的消息。
- 将三个 Queue 分别绑定到 TopicExchange 上,第一个 Binding 中的 “xiaomi.#” 表示消息的 routingkey 凡是以 “xiaomi” 开头的,都将被路由到名称为 “xiaomi” 的 Queue 上,第二个 Binding 中的 “huawei.#” 表示消息的 routingkey 凡是以 “huawei” 开头的,都将被路由到名称为 “huawei” 的 Queue 上,第三个 Binding 中的 “#.phone.#” 则表示消息的 routingkey 中凡是包含 “phone” 的,都将被路由到名称为 “phone” 的 Queue 上。
接下来针对三个 Queue 创建三个消费者,如下:
@Component
public class TopicReceiver {
@RabbitListener(queues = "phone")
public void handler1(String message) {
System.out.println("PhoneReceiver:" + message);
}
@RabbitListener(queues = "xiaomi")
public void handler2(String message) {
System.out.println("XiaoMiReceiver:"+message);
}
@RabbitListener(queues = "huawei")
public void handler3(String message) {
System.out.println("HuaWeiReceiver:"+message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
然后在单元测试中进行消息的发送,如下:
@RunWith(SpringRunner.class) @SpringBootTest public class RabbitmqApplicationTests { @Autowired RabbitTemplate rabbitTemplate; @Test public void topicTest() { rabbitTemplate.convertAndSend(RabbitTopicConfig.TOPICNAME, "xiaomi.news","小米新闻.."); rabbitTemplate.convertAndSend(RabbitTopicConfig.TOPICNAME, "huawei.news","华为新闻.."); rabbitTemplate.convertAndSend(RabbitTopicConfig.TOPICNAME, "xiaomi.phone","小米手机.."); rabbitTemplate.convertAndSend(RabbitTopicConfig.TOPICNAME, "huawei.phone","华为手机.."); rabbitTemplate.convertAndSend(RabbitTopicConfig.TOPICNAME, "phone.news","手机新闻.."); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
根据 RabbitTopicConfig 中的配置,第一条消息将被路由到名称为 “xiaomi” 的 Queue 上,第二条消息将被路由到名为 “huawei” 的 Queue 上,第三条消息将被路由到名为 “xiaomi” 以及名为 “phone” 的 Queue 上,第四条消息将被路由到名为 “huawei” 以及名为 “phone” 的 Queue 上,最后一条消息则将被路由到名为 “phone” 的 Queue 上。
3.3.3.4 Header
HeadersExchange 是一种使用较少的路由策略,HeadersExchange 会根据消息的 Header 将消息路由到不同的 Queue 上,这种策略也和 routingkey 无关,配置如下:
@Configuration public class RabbitHeaderConfig { public final static String HEADERNAME = "javaboy-header"; @Bean HeadersExchange headersExchange() { return new HeadersExchange(HEADERNAME, true, false); } @Bean Queue queueName() { return new Queue("name-queue"); } @Bean Queue queueAge() { return new Queue("age-queue"); } @Bean Binding bindingName() { Map<String, Object> map = new HashMap<>(); map.put("name", "sang"); return BindingBuilder.bind(queueName()) .to(headersExchange()).whereAny(map).match(); } @Bean Binding bindingAge() { return BindingBuilder.bind(queueAge()) .to(headersExchange()).where("age").exists(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
这里的配置大部分和前面介绍的一样,差别主要体现的 Binding 的配置上,第一个 bindingName 方法中,whereAny 表示消息的 Header 中只要有一个 Header 匹配上 map 中的 key/value,就把该消息路由到名为 “name-queue” 的 Queue 上,这里也可以使用 whereAll 方法,表示消息的所有 Header 都要匹配。whereAny 和 whereAll 实际上对应了一个名为 x-match 的属性。bindingAge 中的配置则表示只要消息的 Header 中包含 age,不管 age 的值是多少,都将消息路由到名为 “age-queue” 的 Queue 上。
接下来创建两个消息消费者:
@Component
public class HeaderReceiver {
@RabbitListener(queues = "name-queue")
public void handler1(byte[] msg) {
System.out.println("HeaderReceiver:name:"
+ new String(msg, 0, msg.length));
}
@RabbitListener(queues = "age-queue")
public void handler2(byte[] msg) {
System.out.println("HeaderReceiver:age:"
+ new String(msg, 0, msg.length));
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
注意这里的参数用 byte 数组接收。然后在单元测试中创建消息的发送方法,这里消息的发送也和 routingkey 无关,如下:
@RunWith(SpringRunner.class) @SpringBootTest public class RabbitmqApplicationTests { @Autowired RabbitTemplate rabbitTemplate; @Test public void headerTest() { Message nameMsg = MessageBuilder .withBody("hello header! name-queue".getBytes()) .setHeader("name", "sang").build(); Message ageMsg = MessageBuilder .withBody("hello header! age-queue".getBytes()) .setHeader("age", "99").build(); rabbitTemplate.send(RabbitHeaderConfig.HEADERNAME, null, ageMsg); rabbitTemplate.send(RabbitHeaderConfig.HEADERNAME, null, nameMsg); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
这里创建两条消息,两条消息具有不同的 header,不同 header 的消息将被发到不同的 Queue 中去。
最终执行效果如下:

3.3.4 Routing
这种情况是这样:
一个生产者,一个交换机,两个队列,两个消费者,生产者在创建 Exchange 后,根据 RoutingKey 去绑定相应的队列,并且在发送消息时,指定消息的具体 RoutingKey 即可。
如下图:

这个就是按照 routing key 去路由消息,我这里就不再举例子了,大家可以参考 3.3.1 小结。
3.3.5 Topics
这种情况是这样:
一个生产者,一个交换机,两个队列,两个消费者,生产者创建 Topic 的 Exchange 并且绑定到队列中,这次绑定可以通过 * 和 # 关键字,对指定 RoutingKey 内容,编写时注意格式 xxx.xxx.xxx 去编写。
如下图:
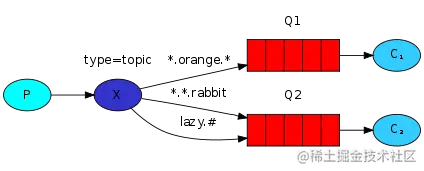
这个我也就不举例啦,前面 3.3.3 小节已经举过例子了,不再赘述。
3.3.6 RPC
RPC 这种消息收发形式,松哥前两天刚刚写了文章和大家介绍,这里就不多说了,传送门:
3.3.7 Publisher Confirms
这种发送确认松哥之前有写过相关文章,传送门:
4. RabbitMQ 实现 RPC
说到 RPC(Remote Procedure Call Protocol 远程过程调用协议),小伙伴们脑海里蹦出的估计都是 RESTful API、Dubbo、WebService、Java RMI、CORBA 等。
其实,RabbitMQ 也给我们提供了 RPC 功能,并且使用起来很简单。
松哥通过一个简单的案例来和大家分享一下 Spring Boot+RabbitMQ 如何实现一个简单的 RPC 调用。
注意
关于 RabbitMQ 实现 RPC 调用,有的小伙伴可能会有一些误解,心想这还不简单?搞两个消息队列 queue_1 和 queue_2,首先客户端发送消息到 queue_1 上,服务端监听 queue_1 上的消息,收到之后进行处理;处理完成后,服务端发送消息到 queue_2 队列上,然后客户端监听 queue_2 队列上的消息,这样就知道服务端的处理结果了。
这种方式不是不可以,就是有点麻烦!RabbitMQ 中提供了现成的方案可以直接使用,非常方便。接下来我们就一起来学习下。
4.1 架构
先来看一个简单的架构图:
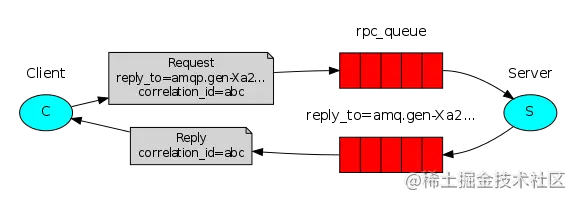
这张图把问题说的很明白了:
- 首先 Client 发送一条消息,和普通的消息相比,这条消息多了两个关键内容:一个是 correlation_id,这个表示这条消息的唯一 id,还有一个内容是 reply_to,这个表示消息回复队列的名字。
- Server 从消息发送队列获取消息并处理相应的业务逻辑,处理完成后,将处理结果发送到 reply_to 指定的回调队列中。
- Client 从回调队列中读取消息,就可以知道消息的执行情况是什么样子了。
这种情况其实非常适合处理异步调用。
4.2 实践
接下来我们通过一个具体的例子来看看这个怎么玩。
4.2.1 客户端开发
首先我们来创建一个 Spring Boot 工程名为 producer,作为消息生产者,创建时候添加 web 和 rabbitmq 依赖,如下图:

项目创建成功之后,首先在 application.properties 中配置 RabbitMQ 的基本信息,如下:
spring.rabbitmq.host=localhost
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.publisher-confirm-type=correlated
spring.rabbitmq.publisher-returns=true
- 1
- 2
- 3
- 4
- 5
- 6
这个配置前面四行都好理解,我就不赘述,后面两行:首先是配置消息确认方式,我们通过 correlated 来确认,只有开启了这个配置,将来的消息中才会带 correlation_id,只有通过 correlation_id 我们才能将发送的消息和返回值之间关联起来。最后一行配置则是开启发送失败退回。
接下来我们来提供一个配置类,如下:
/** * @author 江南一点雨 * @微信公众号 江南一点雨 * @网站 http://www.itboyhub.com * @国际站 http://www.javaboy.org * @微信 a_java_boy * @GitHub https://github.com/lenve * @Gitee https://gitee.com/lenve */ @Configuration public class RabbitConfig { public static final String RPC_QUEUE1 = "queue_1"; public static final String RPC_QUEUE2 = "queue_2"; public static final String RPC_EXCHANGE = "rpc_exchange"; /** * 设置消息发送RPC队列 */ @Bean Queue msgQueue() { return new Queue(RPC_QUEUE1); } /** * 设置返回队列 */ @Bean Queue replyQueue() { return new Queue(RPC_QUEUE2); } /** * 设置交换机 */ @Bean TopicExchange exchange() { return new TopicExchange(RPC_EXCHANGE); } /** * 请求队列和交换器绑定 */ @Bean Binding msgBinding() { return BindingBuilder.bind(msgQueue()).to(exchange()).with(RPC_QUEUE1); } /** * 返回队列和交换器绑定 */ @Bean Binding replyBinding() { return BindingBuilder.bind(replyQueue()).to(exchange()).with(RPC_QUEUE2); } /** * 使用 RabbitTemplate发送和接收消息 * 并设置回调队列地址 */ @Bean RabbitTemplate rabbitTemplate(ConnectionFactory connectionFactory) { RabbitTemplate template = new RabbitTemplate(connectionFactory); template.setReplyAddress(RPC_QUEUE2); template.setReplyTimeout(6000); return template; } /** * 给返回队列设置监听器 */ @Bean SimpleMessageListenerContainer replyContainer(ConnectionFactory connectionFactory) { SimpleMessageListenerContainer container = new SimpleMessageListenerContainer(); container.setConnectionFactory(connectionFactory); container.setQueueNames(RPC_QUEUE2); container.setMessageListener(rabbitTemplate(connectionFactory)); return container; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
这个配置类中我们分别配置了消息发送队列 msgQueue 和消息返回队列 replyQueue,然后将这两个队列和消息交换机进行绑定。这个都是 RabbitMQ 的常规操作,没啥好说的。
在 Spring Boot 中我们负责消息发送的工具是 RabbitTemplate,默认情况下,系统自动提供了该工具,但是这里我们需要对该工具重新进行定制,主要是添加消息发送的返回队列,最后我们还需要给返回队列设置一个监听器。
好啦,接下来我们就可以开始具体的消息发送了:
/** * @author 江南一点雨 * @微信公众号 江南一点雨 * @网站 http://www.itboyhub.com * @国际站 http://www.javaboy.org * @微信 a_java_boy * @GitHub https://github.com/lenve * @Gitee https://gitee.com/lenve */ @RestController public class RpcClientController { private static final Logger logger = LoggerFactory.getLogger(RpcClientController.class); @Autowired private RabbitTemplate rabbitTemplate; @GetMapping("/send") public String send(String message) { // 创建消息对象 Message newMessage = MessageBuilder.withBody(message.getBytes()).build(); logger.info("client send:{}", newMessage); //客户端发送消息 Message result = rabbitTemplate.sendAndReceive(RabbitConfig.RPC_EXCHANGE, RabbitConfig.RPC_QUEUE1, newMessage); String response = ""; if (result != null) { // 获取已发送的消息的 correlationId String correlationId = newMessage.getMessageProperties().getCorrelationId(); logger.info("correlationId:{}", correlationId); // 获取响应头信息 HashMap<String, Object> headers = (HashMap<String, Object>) result.getMessageProperties().getHeaders(); // 获取 server 返回的消息 id String msgId = (String) headers.get("spring_returned_message_correlation"); if (msgId.equals(correlationId)) { response = new String(result.getBody()); logger.info("client receive:{}", response); } } return response; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
这块的代码其实也都是一些常规代码,我挑几个关键的节点说下:
- 消息发送调用 sendAndReceive 方法,该方法自带返回值,返回值就是服务端返回的消息。
- 服务端返回的消息中,头信息中包含了 spring_returned_message_correlation 字段,这个就是消息发送时候的 correlation_id,通过消息发送时候的 correlation_id 以及返回消息头中的 spring_returned_message_correlation 字段值,我们就可以将返回的消息内容和发送的消息绑定到一起,确认出这个返回的内容就是针对这个发送的消息的。
这就是整个客户端的开发,其实最最核心的就是 sendAndReceive 方法的调用。调用虽然简单,但是准备工作还是要做足够。例如如果我们没有在 application.properties 中配置 correlated,发送的消息中就没有 correlation_id,这样就无法将返回的消息内容和发送的消息内容关联起来。
4.2.2 服务端开发
再来看看服务端的开发。
首先创建一个名为 consumer 的 Spring Boot 项目,创建项目添加的依赖和客户端开发创建的依赖是一致的,不再赘述。
然后配置 application.properties 配置文件,该文件的配置也和客户端中的配置一致,不再赘述。
接下来提供一个 RabbitMQ 的配置类,这个配置类就比较简单,单纯的配置一下消息队列并将之和消息交换机绑定起来,如下:
/** * @author 江南一点雨 * @微信公众号 江南一点雨 * @网站 http://www.itboyhub.com * @国际站 http://www.javaboy.org * @微信 a_java_boy * @GitHub https://github.com/lenve * @Gitee https://gitee.com/lenve */ @Configuration public class RabbitConfig { public static final String RPC_QUEUE1 = "queue_1"; public static final String RPC_QUEUE2 = "queue_2"; public static final String RPC_EXCHANGE = "rpc_exchange"; /** * 配置消息发送队列 */ @Bean Queue msgQueue() { return new Queue(RPC_QUEUE1); } /** * 设置返回队列 */ @Bean Queue replyQueue() { return new Queue(RPC_QUEUE2); } /** * 设置交换机 */ @Bean TopicExchange exchange() { return new TopicExchange(RPC_EXCHANGE); } /** * 请求队列和交换器绑定 */ @Bean Binding msgBinding() { return BindingBuilder.bind(msgQueue()).to(exchange()).with(RPC_QUEUE1); } /** * 返回队列和交换器绑定 */ @Bean Binding replyBinding() { return BindingBuilder.bind(replyQueue()).to(exchange()).with(RPC_QUEUE2); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
最后我们再来看下消息的消费:
@Component
public class RpcServerController {
private static final Logger logger = LoggerFactory.getLogger(RpcServerController.class);
@Autowired
private RabbitTemplate rabbitTemplate;
@RabbitListener(queues = RabbitConfig.RPC_QUEUE1)
public void process(Message msg) {
logger.info("server receive : {}",msg.toString());
Message response = MessageBuilder.withBody(("i'm receive:"+new String(msg.getBody())).getBytes()).build();
CorrelationData correlationData = new CorrelationData(msg.getMessageProperties().getCorrelationId());
rabbitTemplate.sendAndReceive(RabbitConfig.RPC_EXCHANGE, RabbitConfig.RPC_QUEUE2, response, correlationData);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
这里的逻辑就比较简单了:
- 服务端首先收到消息并打印出来。
- 服务端提取出原消息中的 correlation_id。
- 服务端调用 sendAndReceive 方法,将消息发送给 RPC_QUEUE2 队列,同时带上 correlation_id 参数。
服务端的消息发出后,客户端将收到服务端返回的结果。
OK,大功告成。
4.2.3 测试
接下来我们进行一个简单测试。
首先启动 RabbitMQ。
接下来分别启动 producer 和 consumer,然后在 postman 中调用 producer 的接口进行测试,如下:
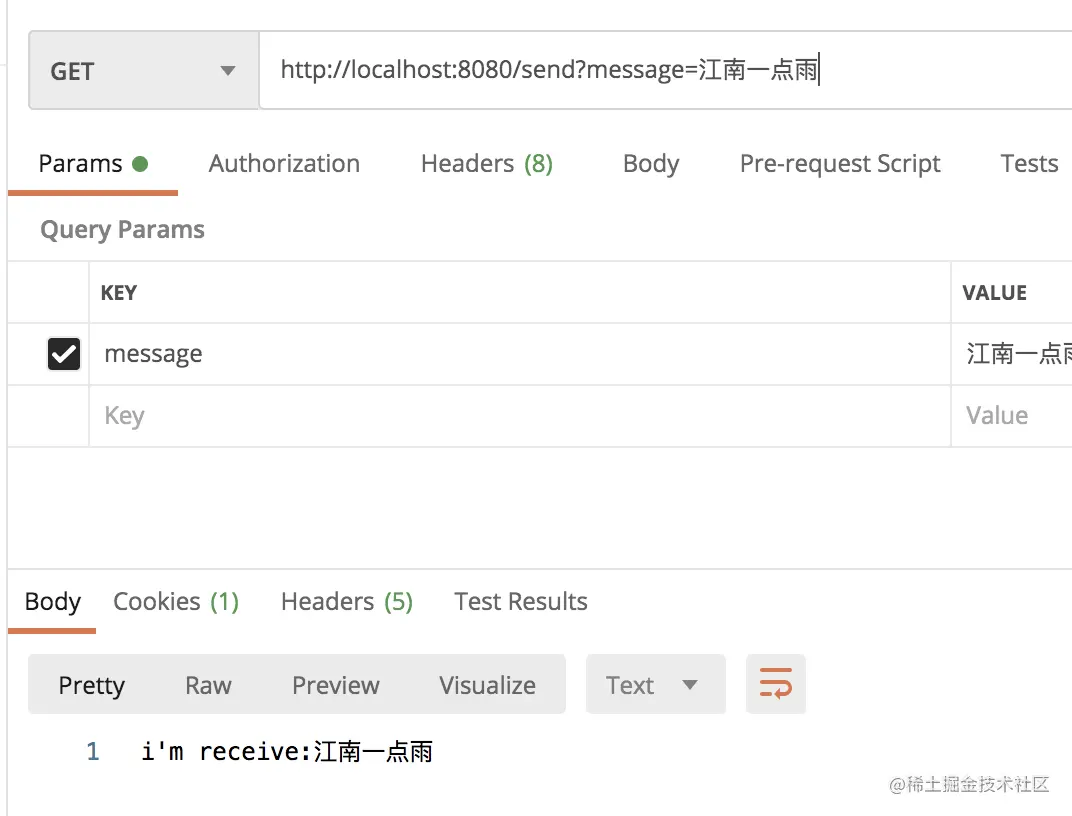
可以看到,已经收到了服务端的返回信息。
来看看 producer 的运行日志:

可以看到,消息发送出去后,同时也收到了 consumer 返回的信息。

可以看到,consumer 也收到了客户端发来的消息。
5. RabbitMQ 消息有效期
RabbitMQ 中的消息长期未被消费会过期吗?用过 RabbitMQ 的小伙伴可能都有这样的疑问,松哥来和大家捋一捋这个问题。
5.1 默认情况
首先我们来看看默认情况。
默认情况下,消息是不会过期的,也就是我们平日里在消息发送时,如果不设置任何消息过期的相关参数,那么消息是不会过期的,即使消息没被消费掉,也会一直存储在队列中。
这种情况具体代码就不用我再演示了吧,松哥之前的文章凡是涉及到 RabbitMQ 的,基本上都是这样的。
5.2 TTL
TTL(Time-To-Live),消息存活的时间,即消息的有效期。如果我们希望消息能够有一个存活时间,那么我们可以通过设置 TTL 来实现这一需求。如果消息的存活时间超过了 TTL 并且还没有被消息,此时消息就会变成死信,关于死信以及死信队列,松哥后面再和大家介绍。
TTL 的设置有两种不同的方式:
- 在声明队列的时候,我们可以在队列属性中设置消息的有效期,这样所有进入该队列的消息都会有一个相同的有效期。
- 在发送消息的时候设置消息的有效期,这样不同的消息就具有不同的有效期。
那如果两个都设置了呢?
以时间短的为准。
当我们设置了消息有效期后,消息过期了就会被从队列中删除了(进入到死信队列,后文一样,不再标注),但是两种方式对应的删除时机有一些差异:
- 对于第一种方式,当消息队列设置过期时间的时候,那么消息过期了就会被删除,因为消息进入 RabbitMQ 后是存在一个消息队列中,队列的头部是最早要过期的消息,所以 RabbitMQ 只需要一个定时任务,从头部开始扫描是否有过期消息,有的话就直接删除。
- 对于第二种方式,当消息过期后并不会立马被删除,而是当消息要投递给消费者的时候才会去删除,因为第二种方式,每条消息的过期时间都不一样,想要知道哪条消息过期,必须要遍历队列中的所有消息才能实现,当消息比较多时这样就比较耗费性能,因此对于第二种方式,当消息要投递给消费者的时候才去删除。
介绍完 TTL 之后,接下来我们来看看具体用法。
接下来所有代码松哥都以 Spring Boot 中封装的 AMPQ 为例来讲解。
5.2.1 单条消息过期
我们先来看单条消息的过期时间。
首先创建一个 Spring Boot 项目,引入 Web 和 RabbitMQ 依赖,如下:

然后在 application.properties 中配置一下 RabbitMQ 的连接信息,如下:
spring.rabbitmq.host=127.0.0.1
spring.rabbitmq.port=5672
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.virtual-host=/
- 1
- 2
- 3
- 4
- 5
接下来稍微配置一下消息队列:
@Configuration public class QueueConfig { public static final String JAVABOY_QUEUE_DEMO = "javaboy_queue_demo"; public static final String JAVABOY_EXCHANGE_DEMO = "javaboy_exchange_demo"; public static final String HELLO_ROUTING_KEY = "hello_routing_key"; @Bean Queue queue() { return new Queue(JAVABOY_QUEUE_DEMO, true, false, false); } @Bean DirectExchange directExchange() { return new DirectExchange(JAVABOY_EXCHANGE_DEMO, true, false); } @Bean Binding binding() { return BindingBuilder.bind(queue()) .to(directExchange()) .with(HELLO_ROUTING_KEY); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这个配置类主要干了三件事:配置消息队列、配置交换机以及将两者绑定在一起。
- 首先配置一个消息队列,new 一个 Queue:第一个参数是消息队列的名字;第二个参数表示消息是否持久化;第三个参数表示消息队列是否排他,一般我们都是设置为 false,即不排他;第四个参数表示如果该队列没有任何订阅的消费者的话,该队列会被自动删除,一般适用于临时队列。
- 配置一个 DirectExchange 交换机。
- 将交换机和队列绑定到一起。
这段配置应该很简单,没啥好解释的,有一个排他性,松哥这里稍微多说两句:
关于排他性,如果设置为 true,则该消息队列只有创建它的 Connection 才能访问,其他的 Connection 都不能访问该消息队列,如果试图在不同的连接中重新声明或者访问排他性队列,那么系统会报一个资源被锁定的错误。另一方面,对于排他性队列而言,当连接断掉的时候,该消息队列也会自动删除(无论该队列是否被声明为持久性队列都会被删除)。
接下来提供一个消息发送接口,如下:
@RestController
public class HelloController {
@Autowired
RabbitTemplate rabbitTemplate;
@GetMapping("/hello")
public void hello() {
Message message = MessageBuilder.withBody("hello javaboy".getBytes())
.setExpiration("10000")
.build();
rabbitTemplate.convertAndSend(QueueConfig.JAVABOY_QUEUE_DEMO, message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
在创建 Message 对象的时候我们可以设置消息的过期时间,这里设置消息的过期时间为 10 秒。
这就可以啦!
接下来我们启动项目,进行消息发送测试。当消息发送成功之后,由于没有消费者,所以这条消息并不会被消费。打开 RabbitMQ 管理页面,点击到 Queues 选项卡,10s 之后,我们会发现消息已经不见了:

很简单吧!
单条消息设置过期时间,就是在消息发送的时候设置一下消息有效期即可。
5.2.2 队列消息过期
给队列设置消息过期时间,方式如下:
@Bean
Queue queue() {
Map<String, Object> args = new HashMap<>();
args.put("x-message-ttl", 10000);
return new Queue(JAVABOY_QUEUE_DEMO, true, false, false, args);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
设置完成后,我们修改消息的发送逻辑,如下:
@RestController
public class HelloController {
@Autowired
RabbitTemplate rabbitTemplate;
@GetMapping("/hello")
public void hello() {
Message message = MessageBuilder.withBody("hello javaboy".getBytes())
.build();
rabbitTemplate.convertAndSend(QueueConfig.JAVABOY_QUEUE_DEMO, message);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
可以看到,消息正常发送即可,不用设置消息过期时间。
OK,启动项目,发送一条消息进行测试。查看 RabbitMQ 管理页面,如下:

可以看到,消息队列的 Features 属性为 D 和 TTL,D 表示消息队列中消息持久化,TTL 则表示消息会过期。
10s 之后刷新页面,发现消息数量已经恢复为 0。
这就是给消息队列设置消息过期时间,一旦设置了,所有进入到该队列的消息都有一个过期时间了。
5.2.3 特殊情况
还有一种特殊情况,就是将消息的过期时间 TTL 设置为 0,这表示如果消息不能立马消费则会被立即丢掉,这个特性可以部分替代 RabbitMQ3.0 以前支持的 immediate 参数,之所以所部分代替,是因为 immediate 参数在投递失败会有 basic.return 方法将消息体返回(这个功能可以利用死信队列来实现)。
具体代码松哥就不演示了,这个应该比较容易。
5.3 死信队列
有小伙伴不禁要问,被删除的消息去哪了?真的被删除了吗?非也非也!这就涉及到死信队列了,接下来我们来看看死信队列。
5.3.1 死信交换机
死信交换机,Dead-Letter-Exchange 即 DLX。
死信交换机用来接收死信消息(Dead Message)的,那什么是死信消息呢?一般消息变成死信消息有如下几种情况:
- 消息被拒绝 (Basic.Reject/Basic.Nack) ,井且设置 requeue 参数为 false
- 消息过期
- 队列达到最大长度
当消息在一个队列中变成了死信消息后,此时就会被发送到 DLX,绑定 DLX 的消息队列则称为死信队列。
DLX 本质上也是一个普普通通的交换机,我们可以为任意队列指定 DLX,当该队列中存在死信时,RabbitMQ 就会自动的将这个死信发布到 DLX 上去,进而被路由到另一个绑定了 DLX 的队列上(即死信队列)。
5.3.2 死信队列
这个好理解,绑定了死信交换机的队列就是死信队列。
5.3.3 实践
我们来看一个简单的例子。
首先我们来创建一个死信交换机,接着创建一个死信队列,再将死信交换机和死信队列绑定到一起:
public static final String DLX_EXCHANGE_NAME = "dlx_exchange_name"; public static final String DLX_QUEUE_NAME = "dlx_queue_name"; public static final String DLX_ROUTING_KEY = "dlx_routing_key"; /** * 配置死信交换机 * * @return */ @Bean DirectExchange dlxDirectExchange() { return new DirectExchange(DLX_EXCHANGE_NAME, true, false); } /** * 配置死信队列 * @return */ @Bean Queue dlxQueue() { return new Queue(DLX_QUEUE_NAME); } /** * 绑定死信队列和死信交换机 * @return */ @Bean Binding dlxBinding() { return BindingBuilder.bind(dlxQueue()) .to(dlxDirectExchange()) .with(DLX_ROUTING_KEY); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
这其实跟普通的交换机,普通的消息队列没啥两样。
接下来为消息队列配置死信交换机,如下:
@Bean
Queue queue() {
Map<String, Object> args = new HashMap<>();
//设置消息过期时间
args.put("x-message-ttl", 0);
//设置死信交换机
args.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME);
//设置死信 routing_key
args.put("x-dead-letter-routing-key", DLX_ROUTING_KEY);
return new Queue(JAVABOY_QUEUE_DEMO, true, false, false, args);
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
就两个参数:
x-dead-letter-exchange:配置死信交换机。x-dead-letter-routing-key:配置死信routing_key。
这就配置好了。
将来发送到这个消息队列上的消息,如果发生了 nack、reject 或者过期等问题,就会被发送到 DLX 上,进而进入到与 DLX 绑定的消息队列上。
死信消息队列的消费和普通消息队列的消费并无二致:
@RabbitListener(queues = QueueConfig.DLX_QUEUE_NAME)
public void dlxHandle(String msg) {
System.out.println("dlx msg = " + msg);
}
- 1
- 2
- 3
- 4
很容易吧~
6. RabbitMQ 实现延迟队列
定时任务各种各样,常见的定时任务例如日志备份,我们可能在每天凌晨 3 点去备份,这种固定时间的定时任务我们一般采用 cron 表达式就能轻松的实现,还有一些比较特殊的定时任务,向大家看电影中的定时炸弹,3 分钟后爆炸,这种定时任务就不太好用 cron 去描述,因为开始时间不确定,我们开发中有的时候也会遇到类似的需求,例如:
- 在电商项目中,当我们下单之后,一般需要 20 分钟之内或者 30 分钟之内付款,否则订单就会进入异常处理逻辑中,被取消,那么进入到异常处理逻辑中,就可以当成是一个延迟队列。
- 我买了一个智能砂锅,可以用来煮粥,上班前把素材都放到锅里,然后设置几点几分开始煮粥,这样下班后就可以喝到香喷喷的粥了,那么这个煮粥的指令也可以看成是一个延迟任务,放到一个延迟队列中,时间到了再执行。
- 公司的会议预定系统,在会议预定成功后,会在会议开始前半小时通知所有预定该会议的用户。
- 安全工单超过 24 小时未处理,则自动拉企业微信群提醒相关责任人。
- 用户下单外卖以后,距离超时时间还有 10 分钟时提醒外卖小哥即将超时。
- …
很多场景下我们都需要延迟队列。
本文以 RabbitMQ 为例来和大家聊一聊延迟队列的玩法。
整体上来说,在 RabbitMQ 上实现定时任务有两种方式:
- 利用 RabbitMQ 自带的消息过期和死信队列机制,实现定时任务。
- 使用 RabbitMQ 的 rabbitmq_delayed_message_exchange 插件来实现定时任务,这种方案较简单。
两种用法我们分别来看。
6.1 用插件
6.1.1 安装插件
首先我们需要下载 rabbitmq_delayed_message_exchange 插件,这是一个 GitHub 上的开源项目,我们直接下载即可:
- https://github.com/rabbitmq/rabbitmq-delayed-message-exchange/releases
选择适合自己的版本,我这里选择最新的 3.9.0 版。
下载完成后在命令行执行如下命令将下载文件拷贝到 Docker 容器中去:
docker cp ./rabbitmq_delayed_message_exchange-3.9.0.ez some-rabbit:/plugins
- 1
这里第一个参数是宿主机上的文件地址,第二个参数是拷贝到容器的位置。
接下来再执行如下命令进入到 RabbitMQ 容器中:
docker exec -it some-rabbit /bin/bash
- 1
进入到容器之后,执行如下命令启用插件:
rabbitmq-plugins enable rabbitmq_delayed_message_exchange
- 1
启用成功之后,还可以通过如下命令查看所有安装的插件,看看是否有我们刚刚安装过的插件,如下:
rabbitmq-plugins list
- 1
- 2
命令的完整执行过程如下图:

OK,配置完成之后,接下来我们执行 exit 命令退出 RabbitMQ 容器。然后开始编码。
6.1.2 消息收发
接下来开始消息收发。
首先我们创建一个 Spring Boot 项目,引入 Web 和 RabbitMQ 依赖,如下:
项目创建成功后,在 application.properties 中配置 RabbitMQ 的基本信息,如下:
spring.rabbitmq.host=localhost
spring.rabbitmq.password=guest
spring.rabbitmq.username=guest
spring.rabbitmq.virtual-host=/
- 1
- 2
- 3
- 4
接下来提供一个 RabbitMQ 的配置类:
@Configuration public class RabbitConfig { public static final String QUEUE_NAME = "javaboy_delay_queue"; public static final String EXCHANGE_NAME = "javaboy_delay_exchange"; public static final String EXCHANGE_TYPE = "x-delayed-message"; @Bean Queue queue() { return new Queue(QUEUE_NAME, true, false, false); } @Bean CustomExchange customExchange() { Map<String, Object> args = new HashMap<>(); args.put("x-delayed-type", "direct"); return new CustomExchange(EXCHANGE_NAME, EXCHANGE_TYPE, true, false,args); } @Bean Binding binding() { return BindingBuilder.bind(queue()) .to(customExchange()).with(QUEUE_NAME).noargs(); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
这里主要是交换机的定义有所不同,小伙伴们需要注意。
这里我们使用的交换机是 CustomExchange,这是一个 Spring 中提供的交换机,创建 CustomExchange 时有五个参数,含义分别如下:
- 交换机名称。
- 交换机类型,这个地方是固定的。
- 交换机是否持久化。
- 如果没有队列绑定到交换机,交换机是否删除。
- 其他参数。
最后一个 args 参数中,指定了交换机消息分发的类型,这个类型就是大家熟知的 direct、fanout、topic 以及 header 几种,用了哪种类型,将来交换机分发消息就按哪种方式来。
接下来我们再创建一个消息消费者:
@Component
public class MsgReceiver {
private static final Logger logger = LoggerFactory.getLogger(MsgReceiver.class);
@RabbitListener(queues = RabbitConfig.QUEUE_NAME)
public void handleMsg(String msg) {
logger.info("handleMsg,{}",msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
打印一下消息内容即可。
接下来再写一个单元测试方法来发送消息:
@SpringBootTest
class MqDelayedMsgDemoApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() throws UnsupportedEncodingException {
Message msg = MessageBuilder.withBody(("hello 江南一点雨"+new Date()).getBytes("UTF-8")).setHeader("x-delay", 3000).build();
rabbitTemplate.convertAndSend(RabbitConfig.EXCHANGE_NAME, RabbitConfig.QUEUE_NAME, msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
在消息头中设置消息的延迟时间。
好啦,接下来启动 Spring Boot 项目,然后运行单元测试方法发送消息,最终的控制台打印日志如下:

从日志中可以看到消息延迟已经实现了。
6.2 DLX 实现延迟队列
6.2.1 延迟队列实现思路
延迟队列实现的思路也很简单,就是上篇文章我们所说的 DLX(死信交换机)+TTL(消息超时时间)。
我们可以把死信队列就当成延迟队列。
具体来说是这样:
假如一条消息需要延迟 30 分钟执行,我们就设置这条消息的有效期为 30 分钟,同时为这条消息配置死信交换机和死信 routing_key,并且不为这个消息队列设置消费者,那么 30 分钟后,这条消息由于没有被消费者消费而进入死信队列,此时我们有一个消费者就在 “蹲点” 这个死信队列,消息一进入死信队列,就立马被消费了。
这就是延迟队列的实现思路,是不是很简单?
6.2.2 案例
接下来松哥通过一个简单的案例,来和大家演示一下延迟队列的具体实现。
首先准备好一个启动的 RabbitMQ。
然后我们创建一个 Spring Boot 项目,引入 RabbitMQ 依赖:
然后在 application.properties 中配置一下 RabbitMQ 的基本连接信息:
spring.rabbitmq.host=localhost
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
spring.rabbitmq.port=5672
- 1
- 2
- 3
- 4
接下来我们来配置两个消息队列:一个普通队列,一个死信队列:
@Configuration public class QueueConfig { public static final String JAVABOY_QUEUE_NAME = "javaboy_queue_name"; public static final String JAVABOY_EXCHANGE_NAME = "javaboy_exchange_name"; public static final String JAVABOY_ROUTING_KEY = "javaboy_routing_key"; public static final String DLX_QUEUE_NAME = "dlx_queue_name"; public static final String DLX_EXCHANGE_NAME = "dlx_exchange_name"; public static final String DLX_ROUTING_KEY = "dlx_routing_key"; /** * 死信队列 * @return */ @Bean Queue dlxQueue() { return new Queue(DLX_QUEUE_NAME, true, false, false); } /** * 死信交换机 * @return */ @Bean DirectExchange dlxExchange() { return new DirectExchange(DLX_EXCHANGE_NAME, true, false); } /** * 绑定死信队列和死信交换机 * @return */ @Bean Binding dlxBinding() { return BindingBuilder.bind(dlxQueue()).to(dlxExchange()) .with(DLX_ROUTING_KEY); } /** * 普通消息队列 * @return */ @Bean Queue javaboyQueue() { Map<String, Object> args = new HashMap<>(); //设置消息过期时间 args.put("x-message-ttl", 1000*10); //设置死信交换机 args.put("x-dead-letter-exchange", DLX_EXCHANGE_NAME); //设置死信 routing_key args.put("x-dead-letter-routing-key", DLX_ROUTING_KEY); return new Queue(JAVABOY_QUEUE_NAME, true, false, false, args); } /** * 普通交换机 * @return */ @Bean DirectExchange javaboyExchange() { return new DirectExchange(JAVABOY_EXCHANGE_NAME, true, false); } /** * 绑定普通队列和与之对应的交换机 * @return */ @Bean Binding javaboyBinding() { return BindingBuilder.bind(javaboyQueue()) .to(javaboyExchange()) .with(JAVABOY_ROUTING_KEY); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
这段配置代码虽然略长,不过原理其实简单。
- 配置可以分为两组,第一组配置死信队列,第二组配置普通队列。每一组都由消息队列、消息交换机以及 Binding 三者组成。
- 配置消息队列时,为消息队列指定死信队列,不熟悉的小伙伴可以翻一下上篇文章,传送门:RabbitMQ 中的消息会过期吗?。
- 配置队列中的消息过期时间时,默认的时间单位时毫秒。
接下来我们为死信队列配置一个消费者,如下:
@Component
public class DlxConsumer {
private static final Logger logger = LoggerFactory.getLogger(DlxConsumer.class);
@RabbitListener(queues = QueueConfig.DLX_QUEUE_NAME)
public void handle(String msg) {
logger.info(msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
收到消息后就将之打印出来。
这就完事了。
启动项目。
最后我们在单元测试中发送一条消息:
@SpringBootTest
class DelayQueueApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
System.out.println(new Date());/
rabbitTemplate.convertAndSend(QueueConfig.JAVABOY_EXCHANGE_NAME, QueueConfig.JAVABOY_ROUTING_KEY, "hello javaboy!");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
这个就没啥好说的了,就是普通的消息发送,10 秒之后这条消息会在死信队列的消费者中被打印出来。
好啦,这就是我们用 RabbitMQ 做延迟队列的两种思路~感兴趣的小伙伴可以试试哦~
7. RabbitMQ 发送可靠性
微服务可以设计成消息驱动的微服务,响应式系统也可以基于消息中间件来做,从这个角度来说,在互联网应用开发中,消息中间件真的是太重要了。
以 RabbitMQ 为例,松哥来和大家聊一聊消息中间消息发送可靠性的问题。
注意,以下内容我主要和大家讨论如何确保消息生产者将消息发送成功,并不涉及消息消费的问题。
7.1 RabbitMQ 消息发送机制
大家知道,RabbitMQ 中的消息发送引入了 Exchange(交换机)的概念,消息的发送首先到达交换机上,然后再根据既定的路由规则,由交换机将消息路由到不同的 Queue(队列)中,再由不同的消费者去消费。

大致的流程就是这样,所以要确保消息发送的可靠性,主要从两方面去确认:
- 消息成功到达 Exchange
- 消息成功到达 Queue
如果能确认这两步,那么我们就可以认为消息发送成功了。
如果这两步中任一步骤出现问题,那么消息就没有成功送达,此时我们可能要通过重试等方式去重新发送消息,多次重试之后,如果消息还是不能到达,则可能就需要人工介入了。
经过上面的分析,我们可以确认,要确保消息成功发送,我们只需要做好三件事就可以了:
- 确认消息到达 Exchange。
- 确认消息到达 Queue。
- 开启定时任务,定时投递那些发送失败的消息。
7.2 RabbitMQ 的努力
上面提出的三个步骤,第三步需要我们自己实现,前两步 RabbitMQ 则有现成的解决方案。
如何确保消息成功到达 RabbitMQ?RabbitMQ 给出了两种方案:
- 开启事务机制
- 发送方确认机制
这是两种不同的方案,不可以同时开启,只能选择其中之一,如果两者同时开启,则会报如下错误:

我们分别来看。以下所有案例都在 Spring Boot 中展开,文末可以下载相关源码。
7.2.1 开启事务机制
Spring Boot 中开启 RabbitMQ 事务机制的方式如下:
首先需要先提供一个事务管理器,如下:
@Bean
RabbitTransactionManager transactionManager(ConnectionFactory connectionFactory) {
return new RabbitTransactionManager(connectionFactory);
}
- 1
- 2
- 3
- 4
接下来,在消息生产者上面做两件事:添加事务注解并设置通信信道为事务模式:
@Service
public class MsgService {
@Autowired
RabbitTemplate rabbitTemplate;
@Transactional
public void send() {
// 开启事务模式
rabbitTemplate.setChannelTransacted(true);
abbitTemplate.convertAndSend(RabbitConfig.JAVABOY_EXCHANGE_NAME,RabbitConfig.JAVABOY_QUEUE_NAME,
"hello rabbitmq!".getBytes());
int i = 1 / 0;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
这里注意两点:
- 发送消息的方法上添加
@Transactional注解标记事务。 - 调用 setChannelTransacted 方法设置为 true 开启事务模式。
这就 OK 了。
在上面的案例中,我们在结尾来了个 1/0 ,这在运行时必然抛出异常,我们可以尝试运行该方法,发现消息并未发送成功。
当我们开启事务模式之后,RabbitMQ 生产者发送消息会多出四个步骤:
- 客户端发出请求,将信道设置为事务模式。
- 服务端给出回复,同意将信道设置为事务模式。
- 客户端发送消息。
- 客户端提交事务。
- 服务端给出响应,确认事务提交。
上面的步骤,除了第三步是本来就有的,其他几个步骤都是平白无故多出来的。所以大家看到,事务模式其实效率有点低,这并非一个最佳解决方案。我们可以想想,什么项目会用到消息中间件?一般来说都是一些高并发的项目,这个时候并发性能尤为重要。
所以,RabbitMQ 还提供了发送方确认机制(publisher confirm)来确保消息发送成功,这种方式,性能要远远高于事务模式,一起来看下。
7.2.2 发送方确认机制
7.2.2.1 单条消息处理
首先我们移除刚刚关于事务的代码,然后在 application.properties 中配置开启消息发送方确认机制,如下:
spring.rabbitmq.publisher-confirm-type=correlated
spring.rabbitmq.publisher-returns=true
- 1
- 2
第一行是配置消息到达交换器的确认回调,第二行则是配置消息到达队列的回调。
第一行属性的配置有三个取值:
- none:表示禁用发布确认模式,默认即此。
- correlated:表示成功发布消息到交换器后会触发的回调方法。
- simple:类似 correlated,并且支持
waitForConfirms()和waitForConfirmsOrDie()方法的调用。
接下来我们要开启两个监听,具体配置如下:
@Configuration public class RabbitConfig implements RabbitTemplate.ConfirmCallback, RabbitTemplate.ReturnsCallback { public static final String JAVABOY_EXCHANGE_NAME = "javaboy_exchange_name"; public static final String JAVABOY_QUEUE_NAME = "javaboy_queue_name"; private static final Logger logger = LoggerFactory.getLogger(RabbitConfig.class); @Autowired RabbitTemplate rabbitTemplate; @Bean Queue queue() { return new Queue(JAVABOY_QUEUE_NAME); } @Bean DirectExchange directExchange() { return new DirectExchange(JAVABOY_EXCHANGE_NAME); } @Bean Binding binding() { return BindingBuilder.bind(queue()) .to(directExchange()) .with(JAVABOY_QUEUE_NAME); } @PostConstruct public void initRabbitTemplate() { rabbitTemplate.setConfirmCallback(this); rabbitTemplate.setReturnsCallback(this); } @Override public void confirm(CorrelationData correlationData, boolean ack, String cause) { if (ack) { logger.info("{}:消息成功到达交换器",correlationData.getId()); }else{ logger.error("{}:消息发送失败", correlationData.getId()); } } @Override public void returnedMessage(ReturnedMessage returned) { logger.error("{}:消息未成功路由到队列",returned.getMessage().getMessageProperties().getMessageId()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
关于这个配置类,我说如下几点:
- 定义配置类,实现
RabbitTemplate.ConfirmCallback和RabbitTemplate.ReturnsCallback两个接口,这两个接口,前者的回调用来确定消息到达交换器,后者则会在消息路由到队列失败时被调用。 - 定义 initRabbitTemplate 方法并添加 @PostConstruct 注解,在该方法中为 rabbitTemplate 分别配置这两个 Callback。
这就可以了。
接下来我们对消息发送进行测试。
首先我们尝试将消息发送到一个不存在的交换机中,像下面这样:
rabbitTemplate.convertAndSend("RabbitConfig.JAVABOY_EXCHANGE_NAME",RabbitConfig.JAVABOY_QUEUE_NAME,
"hello rabbitmq!".getBytes(),new CorrelationData(UUID.randomUUID().toString()));
- 1
- 2
注意第一个参数是一个字符串,不是变量,这个交换器并不存在,此时控制台会报如下错误:

接下来我们给定一个真实存在的交换器,但是给一个不存在的队列,像下面这样:
rabbitTemplate.convertAndSend(RabbitConfig.JAVABOY_EXCHANGE_NAME,"RabbitConfig.JAVABOY_QUEUE_NAME","hello rabbitmq!".getBytes(),new CorrelationData(UUID.randomUUID().toString()));
- 1
注意此时第二个参数是一个字符串,不是变量。

可以看到,消息虽然成功达到交换器了,但是没有成功路由到队列(因为队列不存在)。
这是一条消息的发送,我们再来看看消息的批量发送。
7.2.2.2 消息批量处理
如果是消息批量处理,那么发送成功的回调监听是一样的,这里不再赘述。
这就是 publisher-confirm 模式。
相比于事务,这种模式下的消息吞吐量会得到极大的提升。
7.3 失败重试
失败重试分两种情况,一种是压根没找到 MQ 导致的失败重试,另一种是找到 MQ 了,但是消息发送失败了。
两种重试我们分别来看。
7.3.1 自带重试机制
前面所说的事务机制和发送方确认机制,都是发送方确认消息发送成功的办法。如果发送方一开始就连不上 MQ,那么 Spring Boot 中也有相应的重试机制,但是这个重试机制就和 MQ 本身没有关系了,这是利用 Spring 中的 retry 机制来完成的,具体配置如下:
spring.rabbitmq.template.retry.enabled=true
spring.rabbitmq.template.retry.initial-interval=1000ms
spring.rabbitmq.template.retry.max-attempts=10
spring.rabbitmq.template.retry.max-interval=10000ms
spring.rabbitmq.template.retry.multiplier=2
- 1
- 2
- 3
- 4
- 5
从上往下配置含义依次是:
- 开启重试机制。
- 重试起始间隔时间。
- 最大重试次数。
- 最大重试间隔时间。
- 间隔时间乘数。(这里配置间隔时间乘数为 2,则第一次间隔时间 1 秒,第二次重试间隔时间 2 秒,第三次 4 秒,以此类推)
配置完成后,再次启动 Spring Boot 项目,然后关掉 MQ,此时尝试发送消息,就会发送失败,进而导致自动重试。

7.3.2 业务重试
业务重试主要是针对消息没有到达交换器的情况。
如果消息没有成功到达交换器,根据我们第二小节的讲解,此时就会触发消息发送失败回调,在这个回调中,我们就可以做文章了!
整体思路是这样:
- 首先创建一张表,用来记录发送到中间件上的消息,像下面这样:

每次发送消息的时候,就往数据库中添加一条记录。这里的字段都很好理解,有三个我额外说下:
- status:表示消息的状态,有三个取值,0,1,2 分别表示消息发送中、消息发送成功以及消息发送失败。
- tryTime:表示消息的第一次重试时间(消息发出去之后,在 tryTime 这个时间点还未显示发送成功,此时就可以开始重试了)。
- count:表示消息重试次数。
其他字段都很好理解,我就不一一啰嗦了。
- 在消息发送的时候,我们就往该表中保存一条消息发送记录,并设置状态 status 为 0,tryTime 为 1 分钟之后。
- 在 confirm 回调方法中,如果收到消息发送成功的回调,就将该条消息的 status 设置为 1(在消息发送时为消息设置 msgId,在消息发送成功回调时,通过 msgId 来唯一锁定该条消息)。
- 另外开启一个定时任务,定时任务每隔 10s 就去数据库中捞一次消息,专门去捞那些 status 为 0 并且已经过了 tryTime 时间记录,把这些消息拎出来后,首先判断其重试次数是否已超过 3 次,如果超过 3 次,则修改该条消息的 status 为 2,表示这条消息发送失败,并且不再重试。对于重试次数没有超过 3 次的记录,则重新去发送消息,并且为其 count 的值 + 1。
大致的思路就是上面这样,松哥这里就不给出代码了,松哥的 vhr 里边邮件发送就是这样的思路来处理的,完整代码大家可以参考 vhr 项目(github.com/lenve/vhr)。
当然这种思路有两个弊端:
- 去数据库走一遭,可能拖慢 MQ 的 Qos,不过有的时候我们并不需要 MQ 有很高的 Qos,所以这个应用时要看具体情况。
- 按照上面的思路,可能会出现同一条消息重复发送的情况,不过这都不是事,我们在消息消费时,解决好幂等性问题就行了。
当然,大家也要注意,消息是否要确保 100% 发送成功,也要看具体情况。
好啦,这就是关于消息生产者的一些常见问题以及对应的解决方案,下一小节松哥和大家探讨如果保证消息消费成功并解决幂等性问题。
8. RabbitMQ 消费可靠性
上一小节松哥和大家聊了 MQ 高可用之如何确保消息成功发送,各种配置齐上阵,最终确保了消息的成功发送,甚至在一些极端情况下还可能发生同一条消息重复发送的情况,不管怎么样,消息总算发送出去了,如果小伙伴们还没看过上篇文章,建议先看看,再来学习本文:
今天我们就来聊一聊消息消费的问题,看看如何确保消息消费成功,并且确保幂等性。
8.1 两种消费思路
RabbitMQ 的消息消费,整体上来说有两种不同的思路:
- 推(push):MQ 主动将消息推送给消费者,这种方式需要消费者设置一个缓冲区去缓存消息,对于消费者而言,内存中总是有一堆需要处理的消息,所以这种方式的效率比较高,这也是目前大多数应用采用的消费方式。
- 拉(pull):消费者主动从 MQ 拉取消息,这种方式效率并不是很高,不过有的时候如果服务端需要批量拉取消息,倒是可以采用这种方式。
两种方式我都举个例子看下。
先来看推(push):
这种方式大家比较常见,就是通过 @RabbitListener 注解去标记消费者,如下:
@Component
public class ConsumerDemo {
@RabbitListener(queues = RabbitConfig.JAVABOY_QUEUE_NAME)
public void handle(String msg) {
System.out.println("msg = " + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
当监听的队列中有消息时,就会触发该方法。
再来看拉(pull):
@Test
public void test01() throws UnsupportedEncodingException {
Object o = rabbitTemplate.receiveAndConvert(RabbitConfig.JAVABOY_QUEUE_NAME);
System.out.println("o = " + new String(((byte[]) o),"UTF-8"));
}
- 1
- 2
- 3
- 4
- 5
调用 receiveAndConvert 方法,方法参数为队列名称,方法执行完成后,会从 MQ 上拉取一条消息下来,如果该方法返回值为 null,表示该队列上没有消息了。receiveAndConvert 方法有一个重载方法,可以在重载方法中传入一个等待超时时间,例如 3 秒。此时,假设队列中没有消息了,则 receiveAndConvert 方法会阻塞 3 秒,3 秒内如果队列中有了新消息就返回,3 秒后如果队列中还是没有新消息,就返回 null,这个等待超时时间要是不设置的话,默认为 0。
这是消息两种不同的消费模式。
如果需要从消息队列中持续获得消息,就可以使用推模式;如果只是单纯的消费一条消息,则使用拉模式即可。切忌将拉模式放到一个死循环中,变相的订阅消息,这会严重影响 RabbitMQ 的性能。
8.2 确保消费成功两种思路
在上篇文章中,我们想尽办法确保消息能够发送成功,对于消息消费成功,其实官方提供了相关的机制,我们一起来看下。
为了保证消息能够可靠的到达消息消费者,RabbitMQ 中提供了消息消费确认机制。当消费者去消费消息的时候,可以通过指定 autoAck 参数来表示消息消费的确认方式。
- 当 autoAck 为 false 的时候,此时即使消费者已经收到消息了,RabbitMQ 也不会立马将消息移除,而是等待消费者显式的回复确认信号后,才会将消息打上删除标记,然后再删除。
- 当 autoAck 为 true 的时候,此时消息消费者就会自动把发送出去的消息设置为确认,然后将消息移除(从内存或者磁盘中),即使这些消息并没有到达消费者。
我们来看一张图:

如上图所示,在 RabbitMQ 的 web 管理页面:
- Ready 表示待消费的消息数量。
- Unacked 表示已经发送给消费者但是还没收到消费者 ack 的消息数量。
这是我们可以从 UI 层面观察消息的消费情况确认情况。
当我们将 autoAck 设置为 false 的时候,对于 RabbitMQ 而言,消费分成了两个部分:
- 待消费的消息
- 已经投递给消费者,但是还没有被消费者确认的消息
换句话说,当设置 autoAck 为 false 的时候,消费者就变得非常从容了,它将有足够的时间去处理这条消息,当消息正常处理完成后,再手动 ack,此时 RabbitMQ 才会认为这条消息消费成功了。如果 RabbitMQ 一直没有收到客户端的反馈,并且此时客户端也已经断开连接了,那么 RabbitMQ 就会将刚刚的消息重新放回队列中,等待下一次被消费。
综上所述,确保消息被成功消费,无非就是手动 Ack 或者自动 Ack,无他。当然,无论这两种中的哪一种,最终都有可能导致消息被重复消费,所以一般来说我们还需要在处理消息时,解决幂等性问题。
8.3 消息拒绝
当客户端收到消息时,可以选择消费这条消息,也可以选择拒绝这条消息。我们来看下拒绝的方式:
@Component
public class ConsumerDemo {
@RabbitListener(queues = RabbitConfig.JAVABOY_QUEUE_NAME)
public void handle(Channel channel, Message message) {
//获取消息编号
long deliveryTag = message.getMessageProperties().getDeliveryTag();
try {
//拒绝消息
channel.basicReject(deliveryTag, true);
} catch (IOException e) {
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
消费者收到消息之后,可以选择拒绝消费该条消息,拒绝的步骤分两步:
- 获取消息编号 deliveryTag。
- 调用 basicReject 方法拒绝消息。
调用 basicReject 方法时,第二个参数是 requeue,即是否重新入队。如果第二个参数为 true,则这条被拒绝的消息会重新进入到消息队列中,等待下一次被消费;如果第二个参数为 false,则这条被拒绝的消息就会被丢掉,不会有新的消费者去消费它了。
需要注意的是,basicReject 方法一次只能拒绝一条消息。
8.4 消息确认
消息确认分为自动确认和手动确认,我们分别来看。
8.4.1 自动确认
先来看看自动确认,在 Spring Boot 中,默认情况下,消息消费就是自动确认的。
我们来看如下一个消息消费方法:
@Component
public class ConsumerDemo {
@RabbitListener(queues = RabbitConfig.JAVABOY_QUEUE_NAME)
public void handle2(String msg) {
System.out.println("msg = " + msg);
int i = 1 / 0;
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
通过 @Componet 注解将当前类注入到 Spring 容器中,然后通过 @RabbitListener 注解来标记一个消息消费方法,默认情况下,消息消费方法自带事务,即如果该方法在执行过程中抛出异常,那么被消费的消息会重新回到队列中等待下一次被消费,如果该方法正常执行完没有抛出异常,则这条消息就算是被消费了。
8.4.2 手动确认
手动确认我又把它分为两种:推模式手动确认与拉模式手动确认。
8.4.2.1 推模式手动确认
要开启手动确认,需要我们首先关闭自动确认,关闭方式如下:
spring.rabbitmq.listener.simple.acknowledge-mode=manual
- 1
这个配置表示将消息的确认模式改为手动确认。
接下来我们来看下消费者中的代码:
@RabbitListener(queues = RabbitConfig.JAVABOY_QUEUE_NAME) public void handle3(Message message,Channel channel) { long deliveryTag = message.getMessageProperties().getDeliveryTag(); try { //消息消费的代码写到这里 String s = new String(message.getBody()); System.out.println("s = " + s); //消费完成后,手动 ack channel.basicAck(deliveryTag, false); } catch (Exception e) { //手动 nack try { channel.basicNack(deliveryTag, false, true); } catch (IOException ex) { ex.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
将消费者要做的事情放到一个 try..catch 代码块中。
如果消息正常消费成功,则执行 basicAck 完成确认。
如果消息消费失败,则执行 basicNack 方法,告诉 RabbitMQ 消息消费失败。
这里涉及到两个方法:
- basicAck:这个是手动确认消息已经成功消费,该方法有两个参数:第一个参数表示消息的 id;第二个参数 multiple 如果为 false,表示仅确认当前消息消费成功,如果为 true,则表示当前消息之前所有未被当前消费者确认的消息都消费成功。
- basicNack:这个是告诉 RabbitMQ 当前消息未被成功消费,该方法有三个参数:第一个参数表示消息的 id;第二个参数 multiple 如果为 false,表示仅拒绝当前消息的消费,如果为 true,则表示拒绝当前消息之前所有未被当前消费者确认的消息;第三个参数 requeue 含义和前面所说的一样,被拒绝的消息是否重新入队。
当 basicNack 中最后一个参数设置为 false 的时候,还涉及到一个死信队列的问题,这个松哥以后再专门写文章和大家细聊。
8.4.2.2 拉模式手动确认
拉模式手动 ack 比较麻烦一些,在 Spring 中封装的 RabbitTemplate 中并未找到对应的方法,所以我们得用原生的办法,如下:
public void receive2() { Channel channel = rabbitTemplate.getConnectionFactory().createConnection().createChannel(false); long deliveryTag = 0L; try { GetResponse getResponse = channel.basicGet(RabbitConfig.JAVABOY_QUEUE_NAME, false); deliveryTag = getResponse.getEnvelope().getDeliveryTag(); System.out.println("o = " + new String((getResponse.getBody()), "UTF-8")); channel.basicAck(deliveryTag, false); } catch (IOException e) { try { channel.basicNack(deliveryTag, false, true); } catch (IOException ex) { ex.printStackTrace(); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
这里涉及到的 basicAck 和 basicNack 方法跟前面的一样,我就不再赘述。
8.5 幂等性问题
最后我们再来说说消息的幂等性问题。
大家设想下面一个场景:
消费者在消费完一条消息后,向 RabbitMQ 发送一个 ack 确认,此时由于网络断开或者其他原因导致 RabbitMQ 并没有收到这个 ack,那么此时 RabbitMQ 并不会将该条消息删除,当重新建立起连接后,消费者还是会再次收到该条消息,这就造成了消息的重复消费。同时,由于类似的原因,消息在发送的时候,同一条消息也可能会发送两次(参见四种策略确保 RabbitMQ 消息发送可靠性!你用哪种?)。种种原因导致我们在消费消息时,一定要处理好幂等性问题。
幂等性问题的处理倒也不难,基本上都是从业务上来处理,我来大概说说思路。
采用 Redis,在消费者消费消息之前,现将消息的 id 放到 Redis 中,存储方式如下:
- id-0(正在执行业务)
- id-1(执行业务成功)
如果 ack 失败,在 RabbitMQ 将消息交给其他的消费者时,先执行 setnx,如果 key 已经存在(说明之前有人消费过该消息),获取他的值,如果是 0,当前消费者就什么都不做,如果是 1,直接 ack。
极端情况:第一个消费者在执行业务时,出现了死锁,在 setnx 的基础上,再给 key 设置一个生存时间。生产者,发送消息时,指定 messageId。
当然这只是一个简单思路供大家参考。
松哥在 vhr 项目中也处理了消息幂等性问题,感兴趣的小伙伴可以查看 vhr 源码(github.com/lenve/vhr),代码在 mailserver 中。
9. 理解 VirtualHost
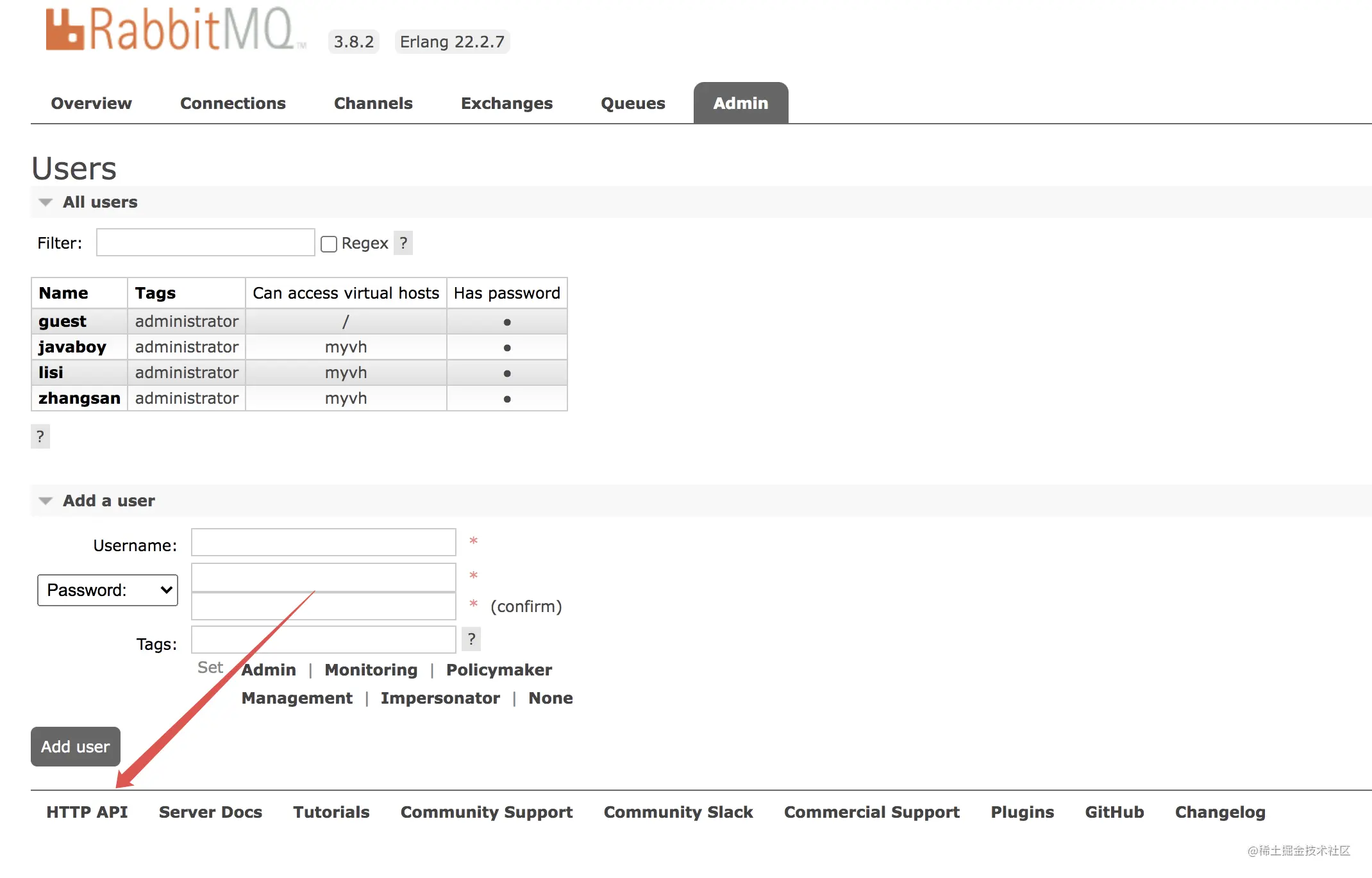
当我们第一次安装好一个 RabbitMQ 之后,我们可能都会通过 Web 页面去管理这个 RabbitMQ,默认情况下,我们第一次使用的默认用户是 guest。
登录成功后,在 admin 选项卡可以查看所有用户:

可以看到,每个用户都有一个 Can access virtual hosts 属性,这个属性是啥意思呢?
今天松哥来和大家稍微捋一捋。
9.1 多租户
RabbitMQ 中有一个概念叫做多租户,怎么理解呢?
我们安装一个 RabbitMQ 服务器,每一个 RabbitMQ 服务器都能创建出许多虚拟的消息服务器,这些虚拟的消息服务器就是我们所说的虚拟主机(virtual host),一般简称为 vhost。
本质上,每一个 vhost 都是一个独立的小型 RabbitMQ 服务器,这个 vhost 中会有自己的消息队列、消息交换机以及相应的绑定关系等等,并且拥有自己独立的权限,不同的 vhost 中的队列和交换机不能互相绑定,这样技能保证运行安全又能避免命名冲突。
我们并不需要特别的去看待 vhost,他就跟普通的物理 RabbitMQ 一样,不同的 vhost 能够提供逻辑上的分离,确保不同的应用消息队列能够安全独立运行。
要我来说,我们该怎么看待 vhost 和 RabbitMQ 的关系呢?RabbitMQ 相当于一个 Excel 文件,而 vhost 则是 Excel 文件中的一个个 sheet,我们所有的操作都是在某一个 sheet 上进行操作。
本质上来说,vhost 算是 AMQP 协议中的概念。
9.2 命令行创建 vhost
先来看看如何通过命令行创建 vhost。
因为松哥这里的 RabbitMQ 是用 docker 安装的,所以我们首先进入到 docker 容器中:
docker exec -it some-rabbit /bin/bash
- 1
然后执行如下命令创建一个名为 /myvh 的 vhost:
rabbitmqctl add_vhost myvh
- 1
最终执行结果如下:

然后通过如下命令可以查看已有的 vhost:
rabbitmqctl list_vhosts
- 1
当然这个命令也可以添加两个选项 name 和 tracing,name 表示 vhost 的名称,tracing 则表示是否使用了 tracing 功能(tracing 可以帮助追踪 RabbitMQ 中消息的流入流出情况),如下图:
可以通过如下命令删除一个 vhost:
rabbitmqctl delete_vhost myvh
- 1

当删除一个 vhost 的时候,与这个 vhost 相关的消息队列、交换机以及绑定关系等,统统都会被删除。
给一个用户设置 vhost:
rabbitmqctl set_permissions -p myvh guest ".*" ".*" ".*"
- 1

前面参数都好说,最后面三个 ".*" 含义分别如下:
- 用户在所有资源上都拥有可配置权限(创建 / 删除消息队列、创建 / 删除交换机等)。
- 用户在所有资源上都拥有写权限(发消息)。
- 用户在所有资源上都拥有读权限(消息消费,清空队列等)。
禁止一个用户访问某个 vhost:
rabbitmqctl clear_permissions -p myvh guest
- 1

9.3 管理页面创建 vhost
当然我们也可以在网页端管理 vhost:
在 admin 选项卡中,点击右边的 Virtual Hosts,如下:

然后点击下边的 Add a new virtual host ,可以添加一个新的 vhost:
进入到某一个 vhost 之后,可以修改其权限以及删除一个 vhost,如下图:
9.4 用户管理
因为 vhost 通常跟用户一起出现,所以这里我也顺便说下 user 的相关操作。
添加一个用户名为 javaboy,密码为 123 的用户,方式如下:
rabbitmqctl add_user javaboy 123
- 1

通过如下命令可以修改用户密码(将 javaboy 的密码改为 123456):
rabbitmqctl change_password javaboy 123456
- 1

通过如下命令可以验证用户密码:
rabbitmqctl authenticate_user javaboy 123456
- 1
验证成功和验证失败的情况分别如下:

通过如下命令可以查看当前的所有用户:
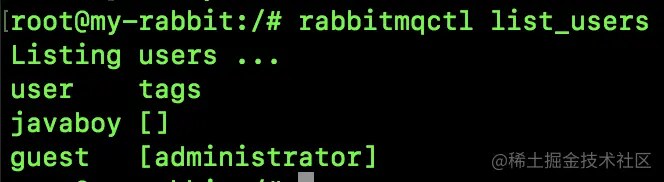
第一列是用户名,第二列是用户角色。
关于用户角色,我在上篇文章中已经聊过了,这里就不再赘述。传送门:RabbitMQ 管理页面该如何使用。
给用户设置角色的命令如下(给 javaboy 设置 administrator 角色):
rabbitmqctl set_user_tags javaboy administrator
- 1

最后,删除一个用户的命令如下:
rabbitmqctl delete_user javaboy
- 1

10. REST API
关于 RabbitMQ 的管理,我们可以通过网页来进行,在松哥前面的文章中也和小伙伴们做了相关的介绍了:
不过呢,如果我们安装了 rabbitmq_management 插件,即安装了 RabbitMQ 中的 Web 管理客户端,那么我们就可以通过 REST API 来进行 RabbitMQ 的管理。
可能有小伙伴会问,这有什么用?
如果我们的项目使用了如 Granglia 或者 Graphite 之类的图形工具,我们想抓取当前 RabbitMQ 上消息消费 / 累积的情况,就可以使用使用 REST API 去查询这些信息并将查询结果传输到新的图形工具上,同时,由于 REST API 就是 HTTP 请求,所以支持的客户端也是多样化,只要能发送 HTTP 请求,就能用,是不是特别方便?
10.1 REST API
可能有小伙伴还不懂什么是 REST API,这里就先简单科普下:
REST(Representational State Transfer)是一种 Web 软件架构风格,它是一种风格,而不是标准,匹配或兼容这种架构风格的的网络服务称为 REST 服务。
REST 服务简洁并且有层次,它通常基于 HTTP、URI、XML 以及 HTML 这些现有的广泛流行的协议和标准。在 REST 中,资源是由 URI 来指定,对资源的增删改查操作可以通过 HTTP 协议提供的 GET、POST、PUT、DELETE 等方法实现。
使用 REST 可以更高效的利用缓存来提高响应速度,同时 REST 中的通信会话状态由客户端来维护,这可以让不同的服务器处理一系列请求中的不同请求,进而提高服务器的扩展性。
在前后端分离项目中,一个设计良好的 Web 软件架构必然要满足 REST 风格。
10.2 开启 Web 管理页面
再来说说如何开启 Web 管理页面,整体上来说,我们有两种方式开启 Web 管理页面:
- 安装 RabbitMQ 的时候,直接选择
rabbitmq:3-management镜像,安装命令如下:
docker run -d --rm --hostname my-rabbit --name some-rabbit -p 15672:15672 -p 5672:5672 rabbitmq:3-management
- 1
这样安装好的 RabbitMQ 就可以直接使用 Web 管理页面了。
- 安装的时候就选择正常的普通镜像
rabbitmq:3,安装命令如下:
docker run -d --hostname my-rabbit --name some-rabbit2 -p 5673:5672 -p 25672:15672 rabbitmq:3
- 1
这个安装好之后,需要我们进入到容器中,然后手动开启 Web 管理插件,命令如下:
docker exec -it some-rabbit2 /bin/bash
rabbitmq-plugins enable rabbitmq_management
- 1
- 2
第一条命令是进入到容器中,第二条命令开启 Web 管理插件,执行结果如下:
通过以上两种方式任意一种把 Web 管理页面打开,然后我们就可以使用 REST API 了。
10.3 实践
接下来我们就来体验几个常见的 REST API 操作。
我们可以通过 CURL 工具来发送请求,也可以通过 POSTMAN 来发送请求,两者皆可,选择自己喜欢的即可。松哥这里两种方式都和大家演示一下。
10.3.1 查看队列统计数据
例如我们想查看虚拟主机 myvh 下 hello-queue 队列的数据统计,我们可以通过如下方式来查看:
curl -i -u javaboy:123 http://localhost:15672/api/queues/myvh/hello-queue
- 1
-i 表示显示响应头信息。
最终执行结果如下:

可以看到,返回的信息有响应头,也有 JSON,不过返回的 JSON 没有格式化,看起来有点难受,如果返回的数据只有 JSON 而不包含响应头,那么我们可以使用 python 来完成数据的格式化,如下:
可以看到,此时返回的数据就格式化了。
当然我们也可以使用 POSTMAN 来发送这个请求,方式如下:

注意选择认证方式为 Basic Auth,同时设置正确的用户名密码。
POSTMAN 请求还是方便很多。
10.3.2 创建队列
在 /myvh 虚拟主机下创建一个名为 javaboy-queue 的队列,使用 CURL 请求方式如下:
curl -i -u javaboy:123 -XPUT -H "Content-Type:application/json" -d '{"auto_delete":false,"durable":true}' http://localhost:15672/api/queues/myvh/javaboy-queue
- 1
注意请求方式是 PUT 请求,请求参数是 JSON 形式,JSON 里边有两个东西,一个 auto_delete 是说如果该队列没有任何消费者订阅的话,该队列是否会被自动删除(如果是一些临时队列,则该属性可以设置为 true);另外一个 durable 则是说队列是否持久化(持久化的队列,在 RabbitMQ 重启之后,队列依然存在),如果大家用 Java 代码创建过队列,这两个参数很好理解,因为我们用 Java 代码创建队列的时候这两个参数也会经常用到。
当然,我们也可以用 POSTMAN 来发送请求:

返回 201 Created 表示队列创建成功。
不过要注意在 Authorization 选项卡中设置用户名 / 密码:
10.3.3 查看当前连接信息
我们可以通过如下请求查看当前连接信息:
请求如下:
curl -i -u javaboy:123 http://localhost:15672/api/connections
- 1
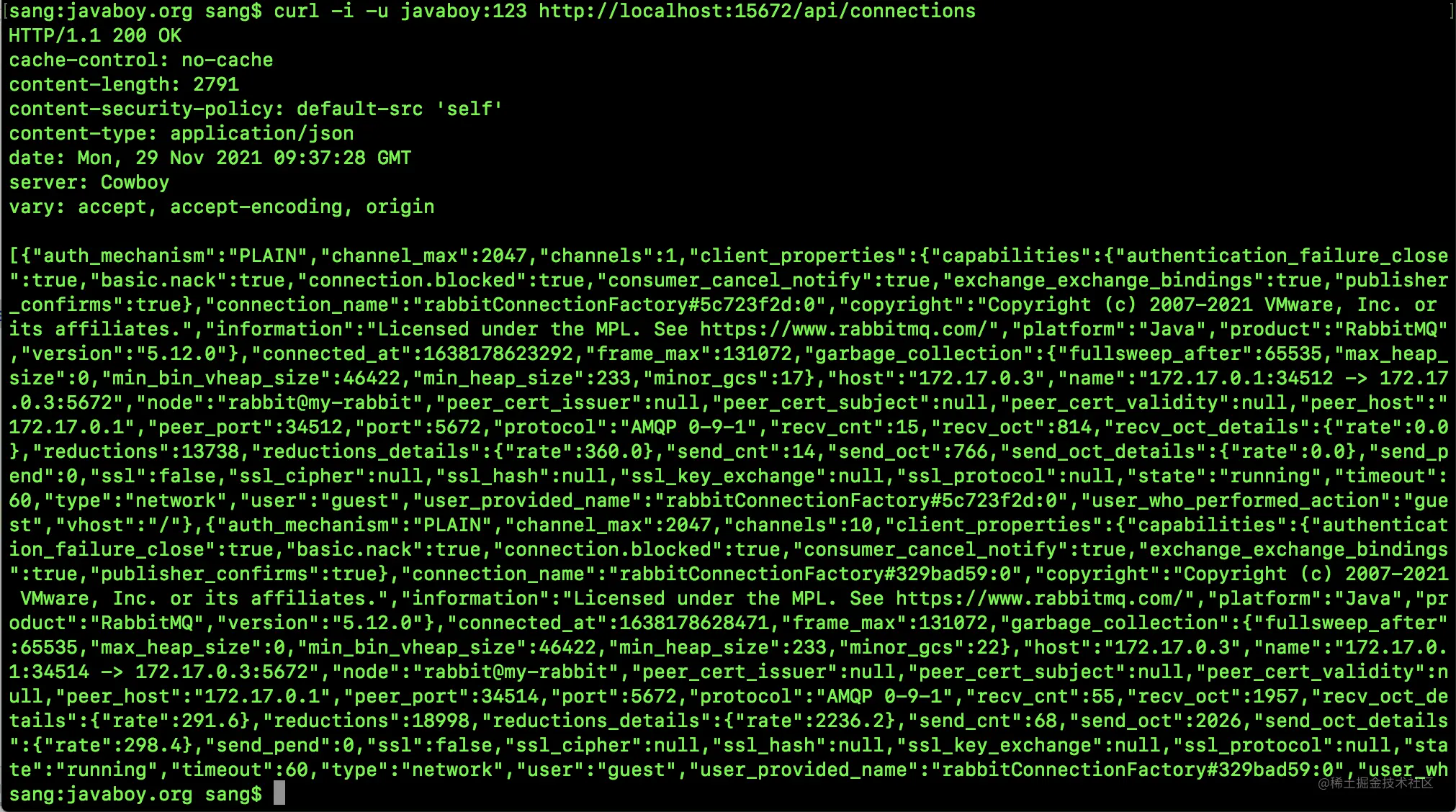
POSTMAN 查看方式如下:
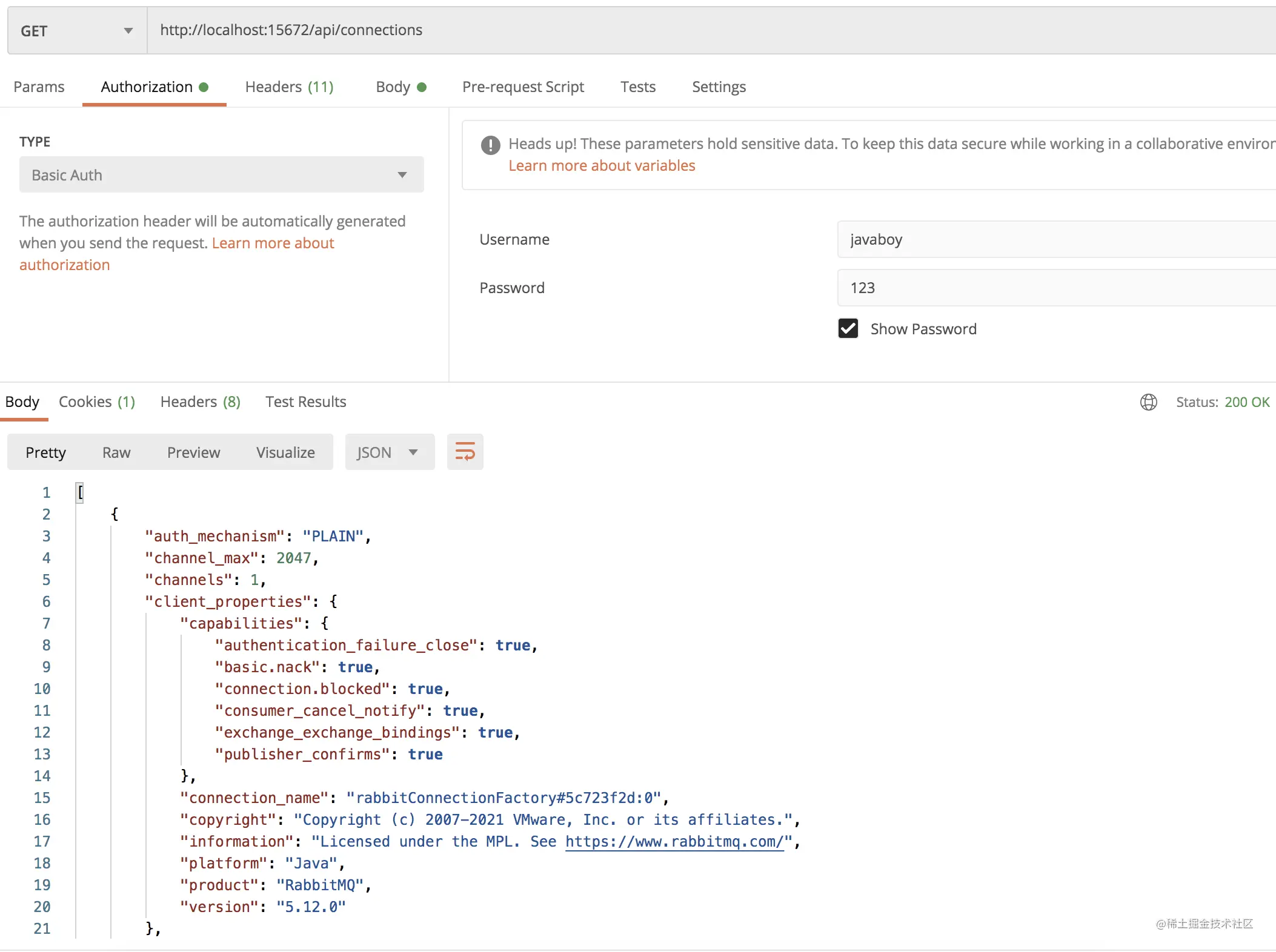
10.3.4 查看当前用户信息
curl -i -u javaboy:123 http://localhost:15672/api/users
- 1
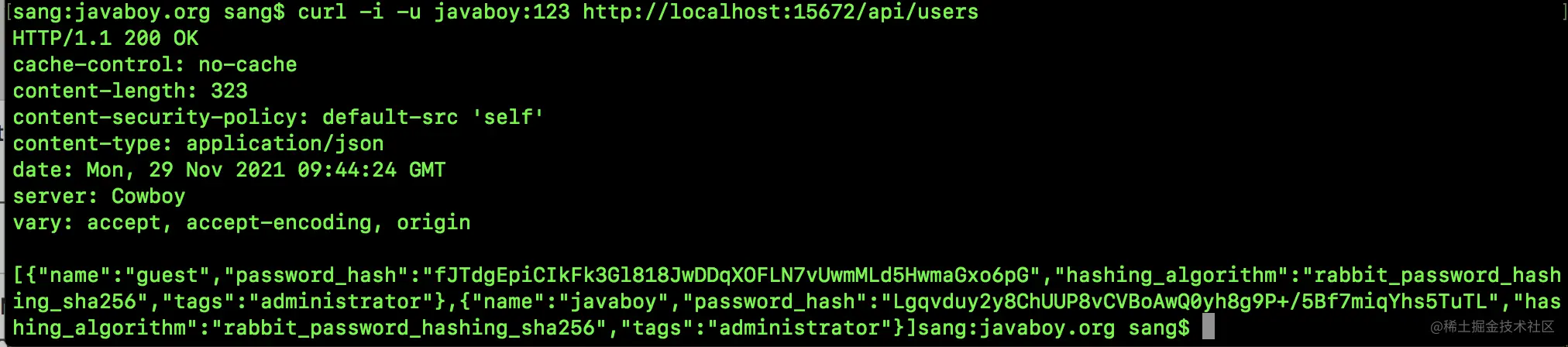
POSTMAN 查看信息如下:

10.3.5 创建一个用户
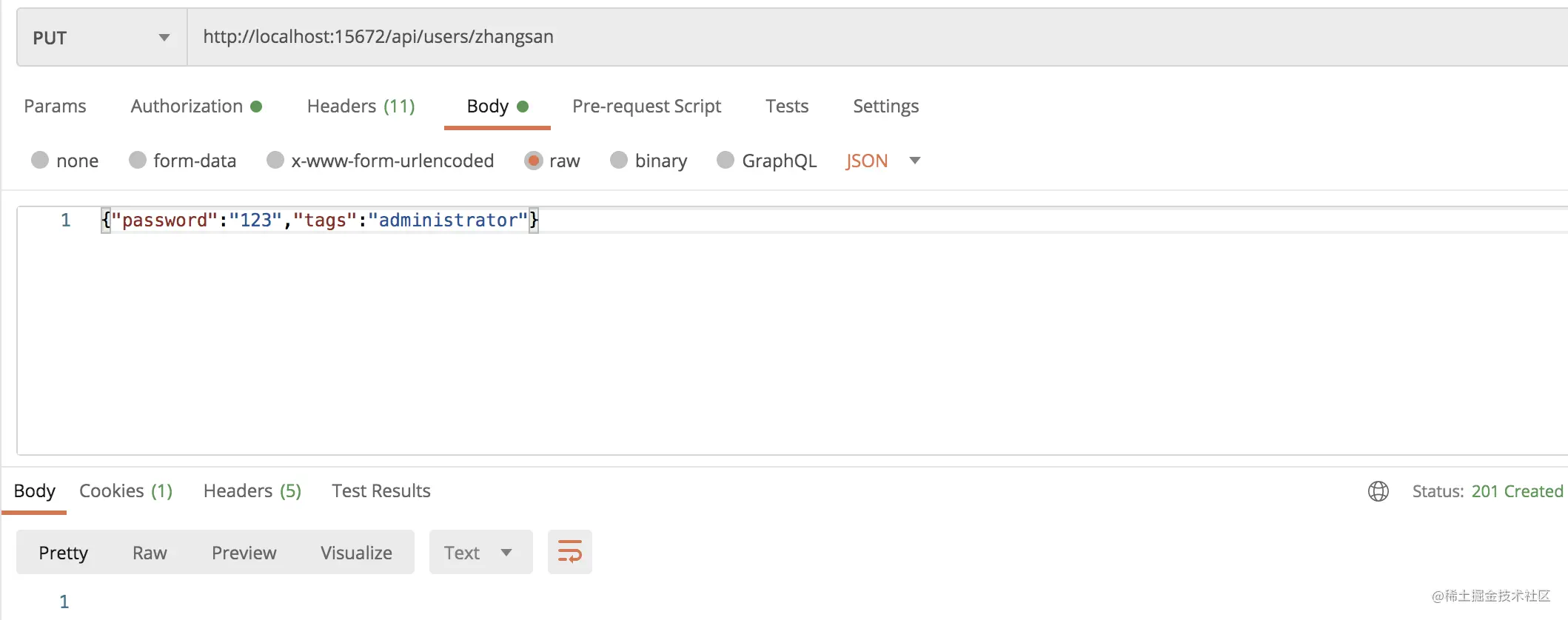
创建一个名为 zhangsan,密码是 123 ,角色是 administrator 的用户。
CURL:
curl -i -u javaboy:123 -H "{Content-Type:application/json}" -d '{"password":"123","tags":"administrator"}' -XPUT http://localhost:15672/api/users/zhangsan
- 1
POSTMAN:
10.3.6 为新用户设置 vhost
将名为 zhangsan 的用户设置到名为 myvh 的 vhost 下:
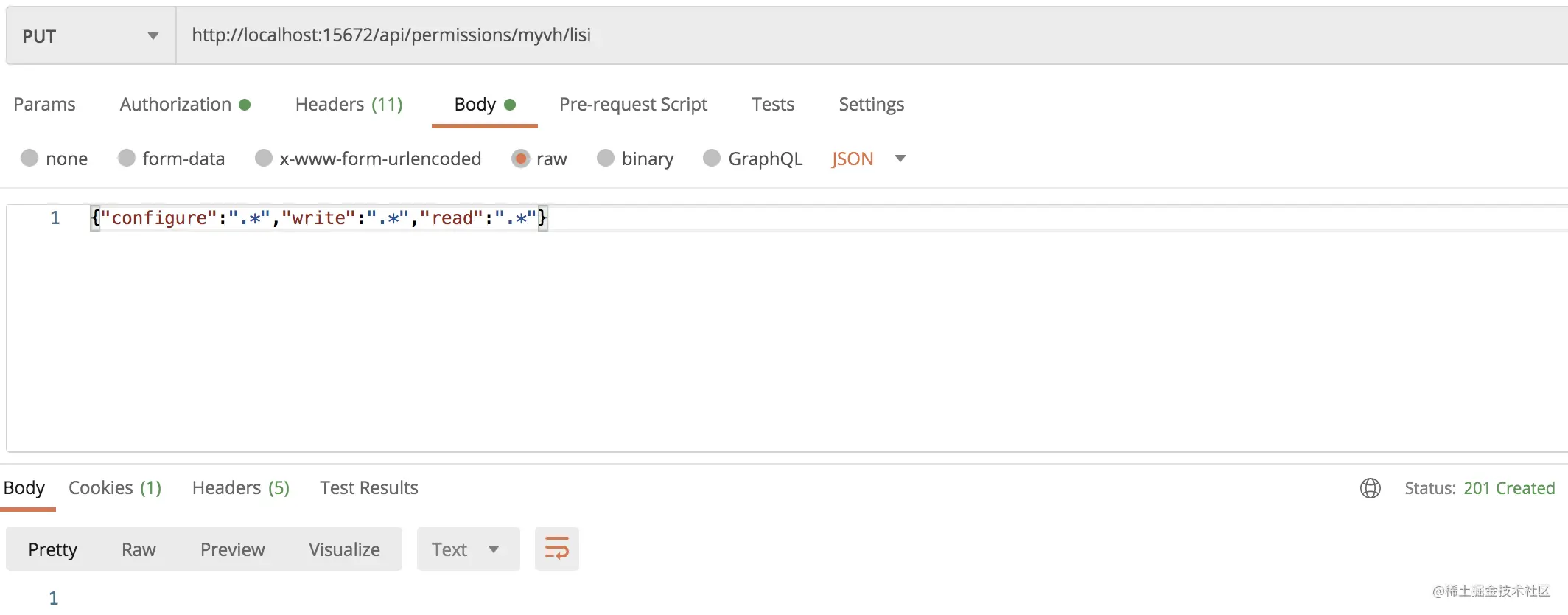
curl -i -u javaboy:123 -H "{Content-Type:application/json}" -d '{"configure":".*","write":".*","read":".*"}' -XPUT http://localhost:15672/api/permissions/myvh/zhangsan
- 1
参数是具体的权限信息:

POSTMAN 请求方式如下:
好啦,松哥这里随便给大家举几个例子,其他 API 的用法,小伙伴们可以打开 RabbitMQ 的管理页面,点击下方的 HTTP API 按钮,里边有一个完整的文档:
11. 常见操作命令
前面我们介绍了一些 REST API,在方便发送 HTTP 请求的地方调用这些 REST API,还是非常方便的。但是,在一些不方便发送 HTTP 请求的地方,这些 REST API 用着并不太方便,那么今天松哥就给大家再来介绍 RabbitMQ 的另一种玩法 —rabbitmqadmin。
11.1 rabbitmqadmin
我们自己平时做练习,一般都会开启 RabbitMQ 的 Web 管理页面,然而在生产环境下,经常是没有 Web 管理页面的,只能通过 CLI 命令去管理 MQ。
其实呀,Web 管理页面虽然友好,但是很多时候没有 CLI 快捷,而且通过 CLI 命令行的操作,我们可以做更多的定制,例如将关键信息查出来后提供给集中的监控系统以触发报警。
直接操作 CLI 命令行有点麻烦,RabbitMQ 提供了 CLI 管理工具 rabbitmqadmin ,其实就是基于 RabbitMQ 的 HTTP API,用 Python 写的一个脚本。因为 REST API 手动写请求还是挺麻烦的,这些脚本刚好替我们简化了这个操作,让这个事情变得更加简单了。
使用 rabbitmqadmin 要先会安装它。
如果我们创建 RabbitMQ 容器的时候使用的是 rabbitmq:3-management 镜像,那么默认情况下,rabbitmqadmin 就是安装好的。
否则可能需要我们自己安装 rabbitmqadmin,安装方式很简单,
首先确认你的设备上安装了 Python,这是最基本的,因为 rabbitmqadmin 这个工具就是 Python 脚本。
然后开启 RabbitMQ 的 Web 管理页面,然后输入如下地址(我的管理页面度那口映射为 25672):
http://localhost:25672/cli/index.html
- 1

在打开的页面中就可以看到 rabbitmqadmin 的下载链接。将 rabbitmqadmin 下载下来后,然后赋予其可执行权限即可:
chmod +x rabbitmqadmin
- 1
下载后的 rabbitmqadmin 我们可以直接用记事本打开,里边其实就是一堆 Python 脚本。
这套流程操作下来还是挺麻烦的,所以,我建议大家直接使用 rabbitmq:3-management 镜像,一步到位。
11.2 rabbitmqadmin 的功能
- 列出 exchanges, queues, bindings, vhosts, users, permissions, connections and channels。
- 创建和删除 exchanges, queues, bindings, vhosts, users and permissions。
- 发布和获取消息,以及消息详情。
- 关闭连接和清空队列。
- 导入导出配置。
接下来松哥就这些功能逐一和小伙伴们进行介绍。
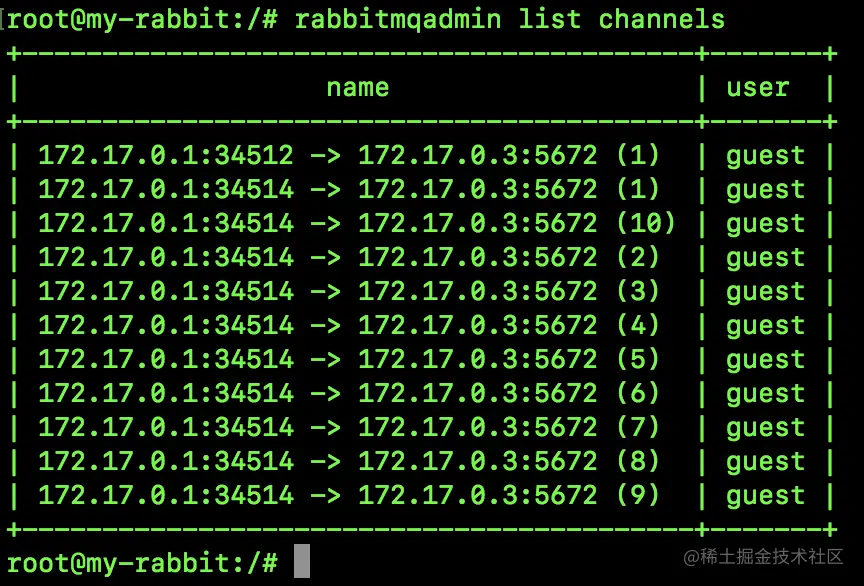
11.3 列出各种信息
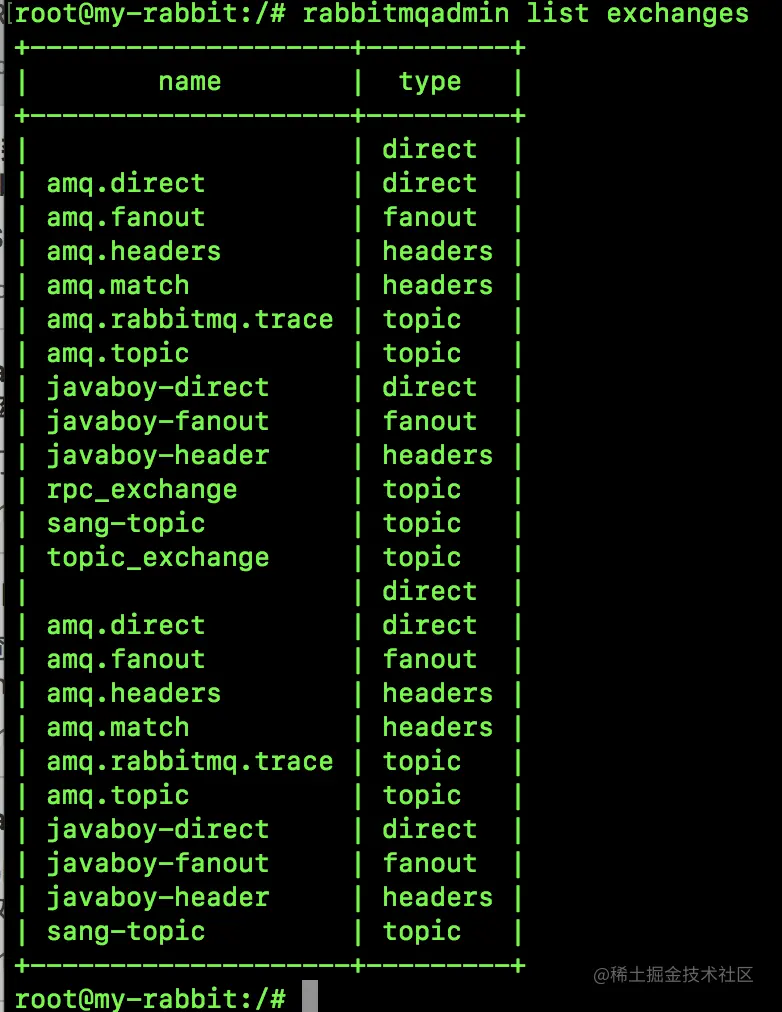
查看所有交换机:
rabbitmqadmin list exchanges
- 1
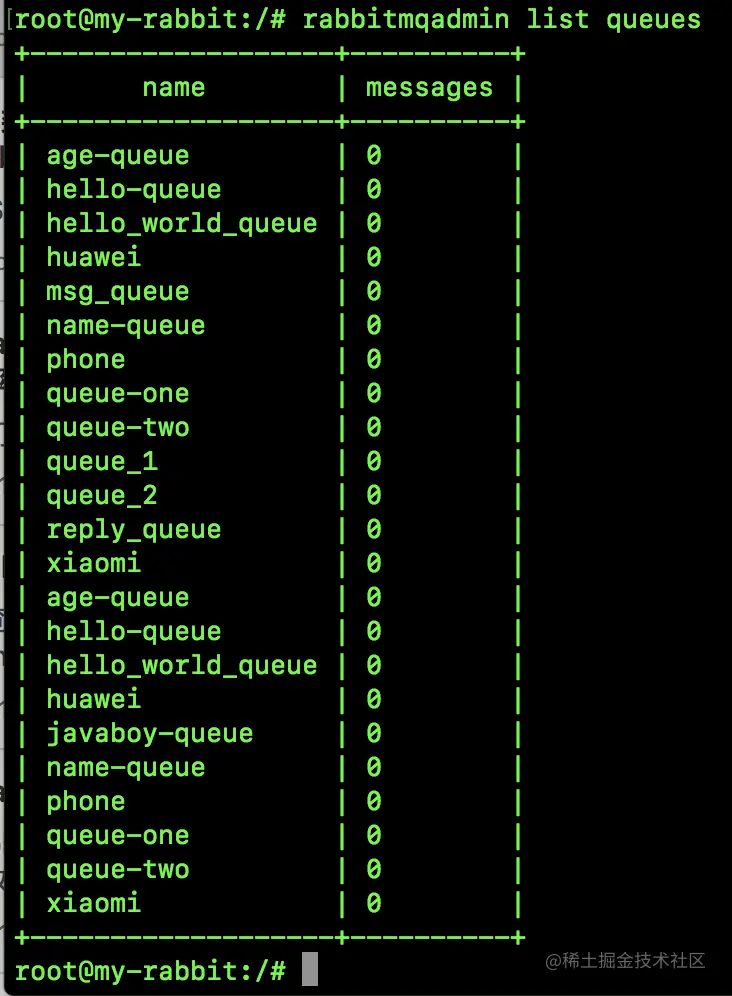
查看所有队列:
rabbitmqadmin list queues
- 1
查看所有 Binding:
rabbitmqadmin list bindings
- 1
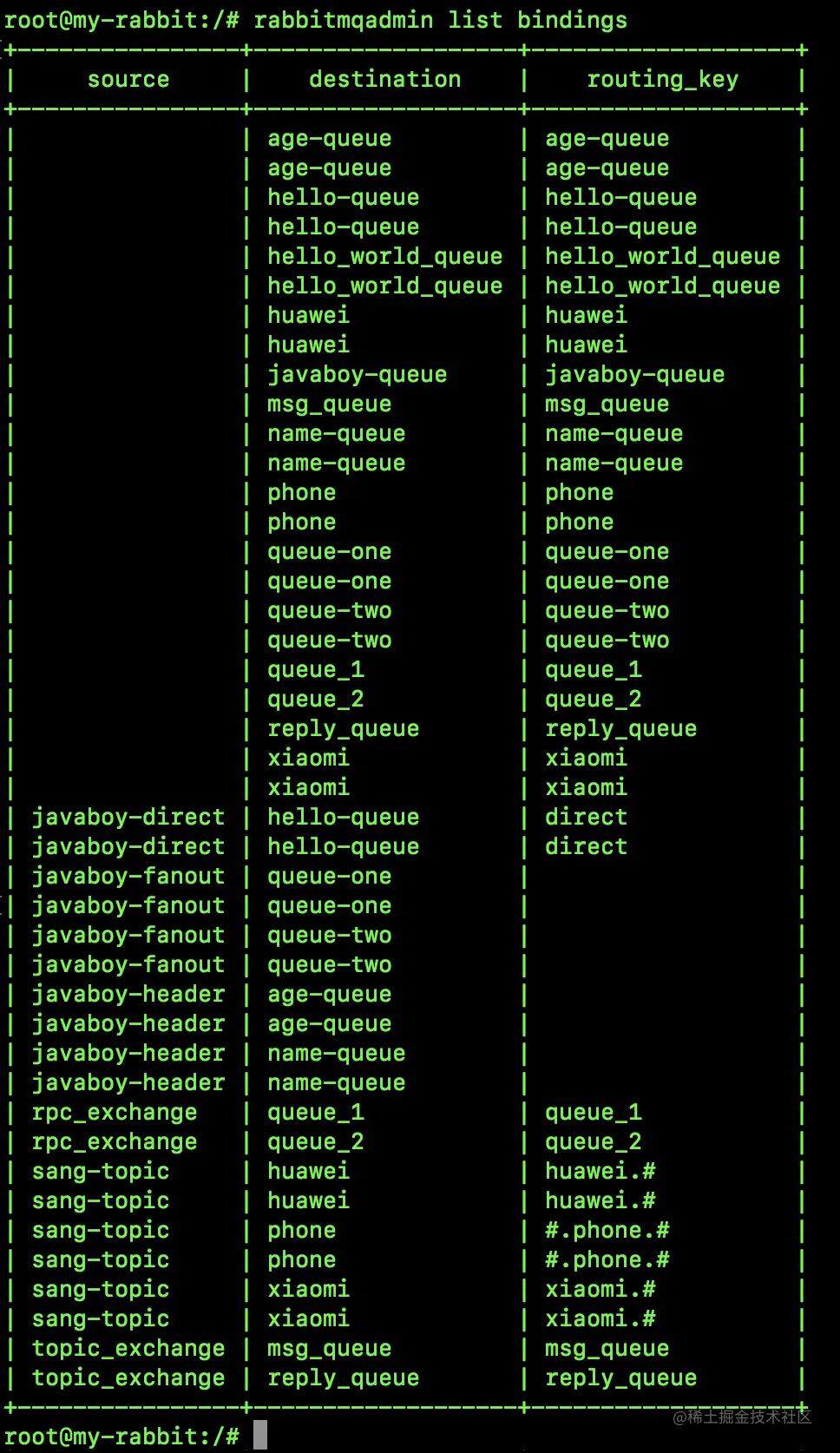
查看所有虚拟主机:
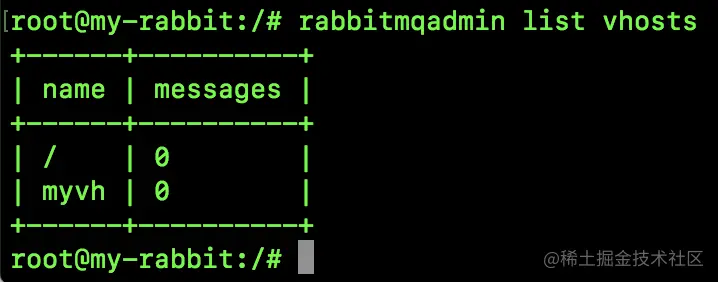
rabbitmqadmin list vhosts
- 1
查看所有用户信息:
rabbitmqadmin list users
- 1

查看所有权限信息:
rabbitmqadmin list permissions
- 1
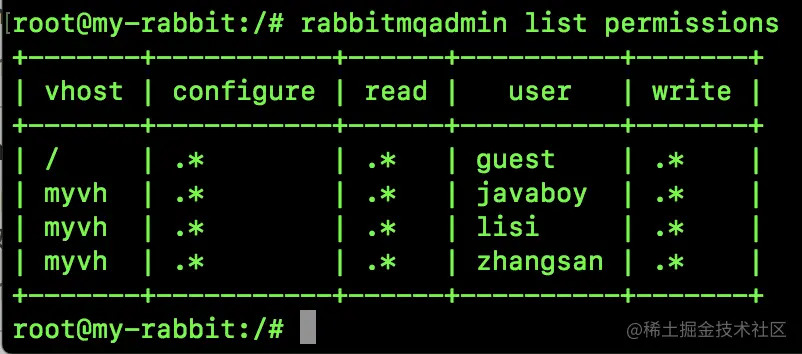
查看所有连接信息:
rabbitmqadmin list connections
- 1
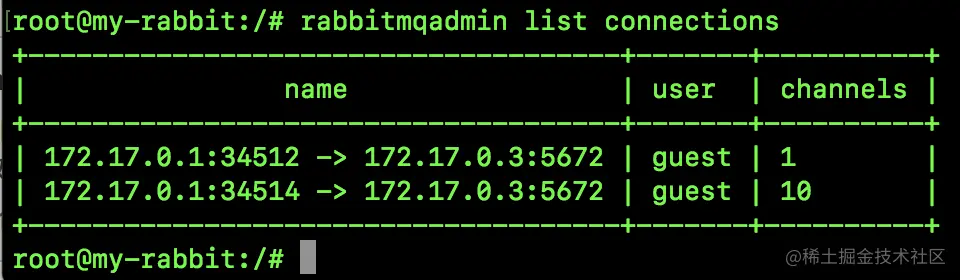
查看所有通道信息:
rabbitmqadmin list channels
- 1
11.4 一个完整的例子
接下来我们用 rabbitmqadmin 来写一个完整的消息收发例子看看。
首先创建一个名为 javaboy-exchange 的交换机:
rabbitmqadmin declare exchange name=javaboy-exchange durable=true auto_delete=false type=direct
- 1

这里各种参数都好理解,我就不多说了。
接下来创建一个名为 javaboy-queue 的队列:
rabbitmqadmin declare queue name=javaboy-queue durable=true auto_delete=false
- 1

接下来再创建一个 Binding,将交换机和消息队列绑定起来:
rabbitmqadmin declare binding source=javaboy-exchange destination=javaboy-queue routing_key=javaboy-routing
- 1

这里涉及到到三个概念:
- source:源,其实就是指交换机。
- destination:目标,其实就是指消息队列。
- routing_key:这个就是路由的 key。
接下来发布一条消息:
rabbitmqadmin publish routing_key=javaboy-queue payload="hello javaboy"
- 1

这里参数都很简单,没啥好说的。
查看队列中的消息(只查看,不消费,看完之后消息还在):
rabbitmqadmin get queue=javaboy-queue
- 1

清空一个队列中的消息:
rabbitmqadmin purge queue name=javaboy-queue
- 1

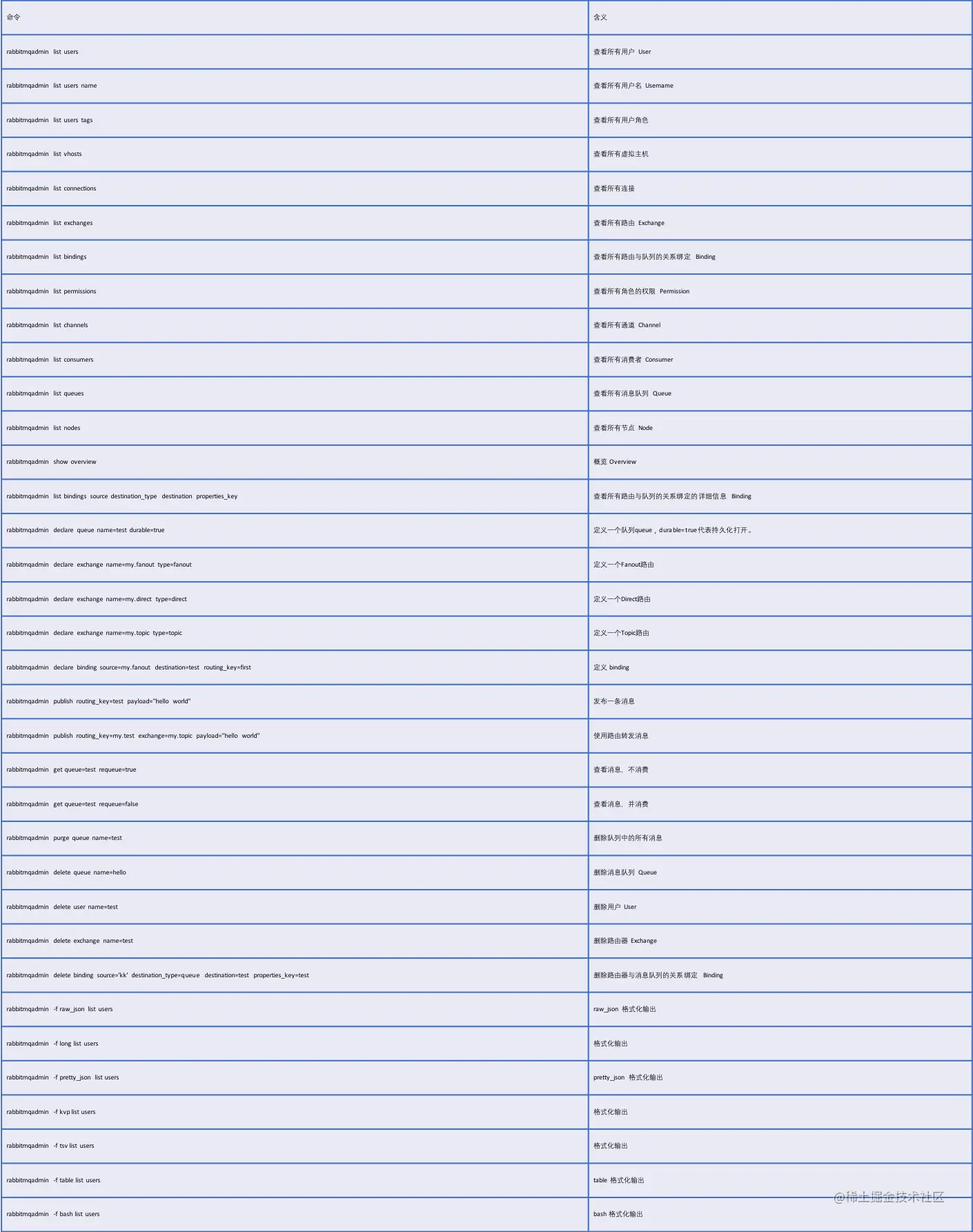
11.5 命令一览
表格字体有点小,大家在公众号【江南一点雨】后台回复 rabbitmqadmin 获取 Excel 文档链接。
12. RabbitMQ 权限系统
不管我们是通过网页还是通过命令行工具创建用户对象,刚创建好的用户对象都是没法直接使用的,需要我们首先把这个用户置于某一个 vhost 之下,然后再赋予其权限,有了权限,这个用户才可以正常使用。
那么今天我们就来了解一下 RabbitMQ 中的权限系统,看下这个权限系统是什么样子的。
12.1 RabbitMQ 权限系统介绍
RabbitMQ 是从 1.6 这个版本开始实现了一套 ACL 风格的权限系统,可能有小伙伴还不知道什么是 ACL 风格的权限系统,可以看看松哥之前发的这两篇文章:
在这套 ACL 风格的权限管理系统中,允许非常多细粒度的权限控制,可以为不同用户分别设置读、写以及配置等权限。
这里涉及到三种不同的权限:
- 读:和消息消费有关的所有操作,包括清除整个队列的消息。
- 写:发布消息。
- 配置:消息队列、交换机等的创建和删除。
这是 RabbitMQ 权限系统的一个简单介绍。
12.2 操作和权限的对应关系
接下来,下图展示了操作和权限的对应关系:
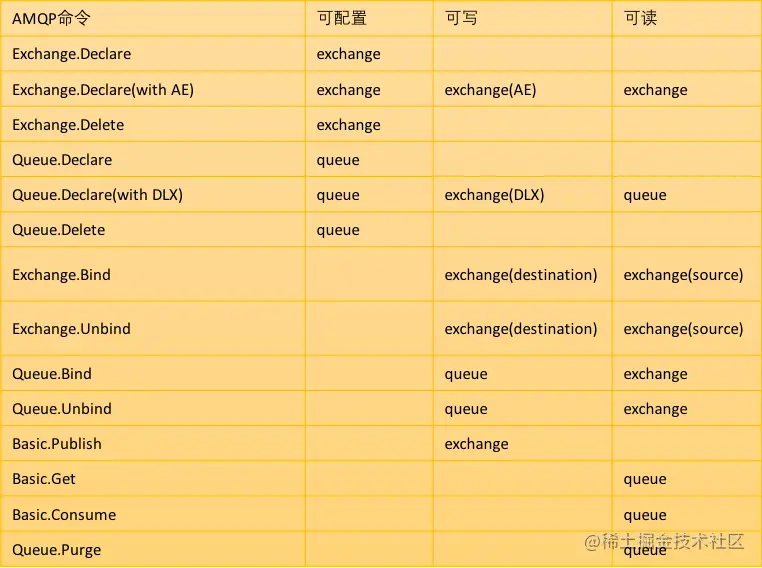
公众号后台回复 rabbitmq_permission 可以获取这张图的 Excel 表格。
执行什么命令,需要什么权限,这张图描述的一清二楚了。
12.3 权限操作命令
RabbitMQ 中权限操作命令格式如下:
rabbitmqctl set_permissions [-p vhosts] {user} {conf} {write} {read}
- 1
这里有几个参数:
- [-p vhost]:授予用户访问权限的 vhost 名称,如果不写默认为
/。 - user:用户名。
- conf:用户在哪些资源上拥有可配置权限(支持正则表达式)。
- write:用户在哪些资源上拥有写权限(支持正则表达式)。
- read:用户在哪些资源上拥有读权限(支持正则表达式)。
至于可配置权限能干嘛,写权限能干嘛,读权限能干嘛,大家可以参考第二小节,这里不再赘述。
松哥来举一个简单的例子。
假设我们有一个名为 zhangsan 的用户,我们希望该用户在 myvh 虚拟主机下具备所有权限,那么我们的操作命令如下:
rabbitmqctl set_permissions -p myvh zhangsan ".*" ".*" ".*"
- 1
执行结果如下:

接下来执行如下命令可以验证授权是否成功:
rabbitmqctl -p myvh list_permissions
- 1
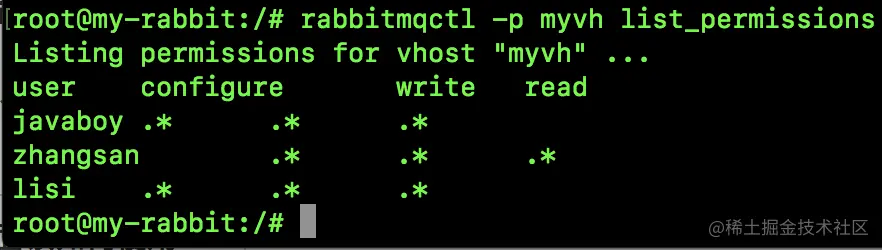
可以看到,张三的权限已经赋值到位。
在上面的授权命令中,我们用的都是 ".*",松哥再额外说下这个通配符:
".*":这个表示匹配所有的交换机和队列。"javaboy-.*":这个表示匹配名字以javaboy-开头的交换机和队列。"":这个表示不匹配任何队列与交换机(如果想撤销用户的权限可以使用这个)。
我们可以使用如下命令来移除某一个用户在某一个 vhost 上的权限,例如移除 zhangsan 在 myvh 上的所有权限,如下:
rabbitmqctl clear_permissions -p myvh zhangsan
- 1
执行完成后,我们可以通过 rabbitmqctl -p myvh list_permissions 命令来查看执行结果是否生效,最终执行效果如下:

如果一个用户在多个 vhost 上都有对应的权限,按照上面的 rabbitmqctl -p myvh list_permissions 命令只能查看一个 vhost 上的权限,此时我们可以通过如下命令来查看 lisi 在所有 vhost 上的权限:
rabbitmqctl list_user_permissions lisi
- 1

12.4 Web 管理页面操作
当然,如果你不想敲命令,也可以通过 Web 管理端去操作权限。
在 Admin 选项卡,点击用户名称,就可以给用户设置权限了,如下:
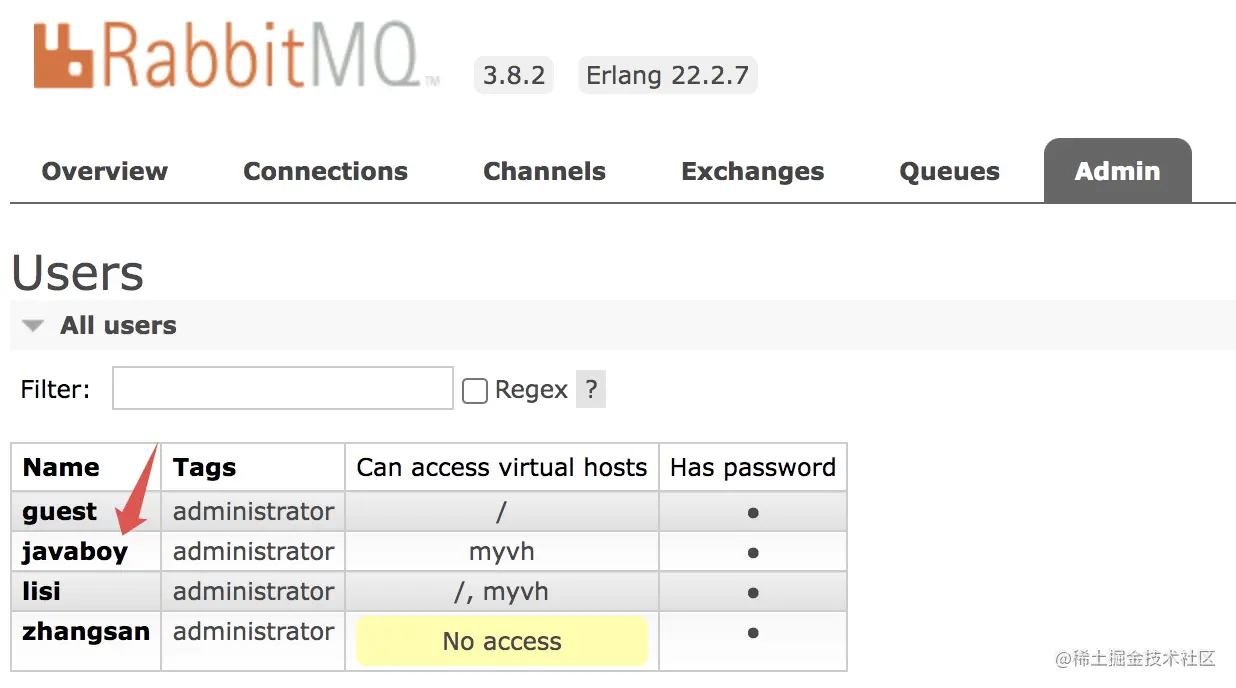
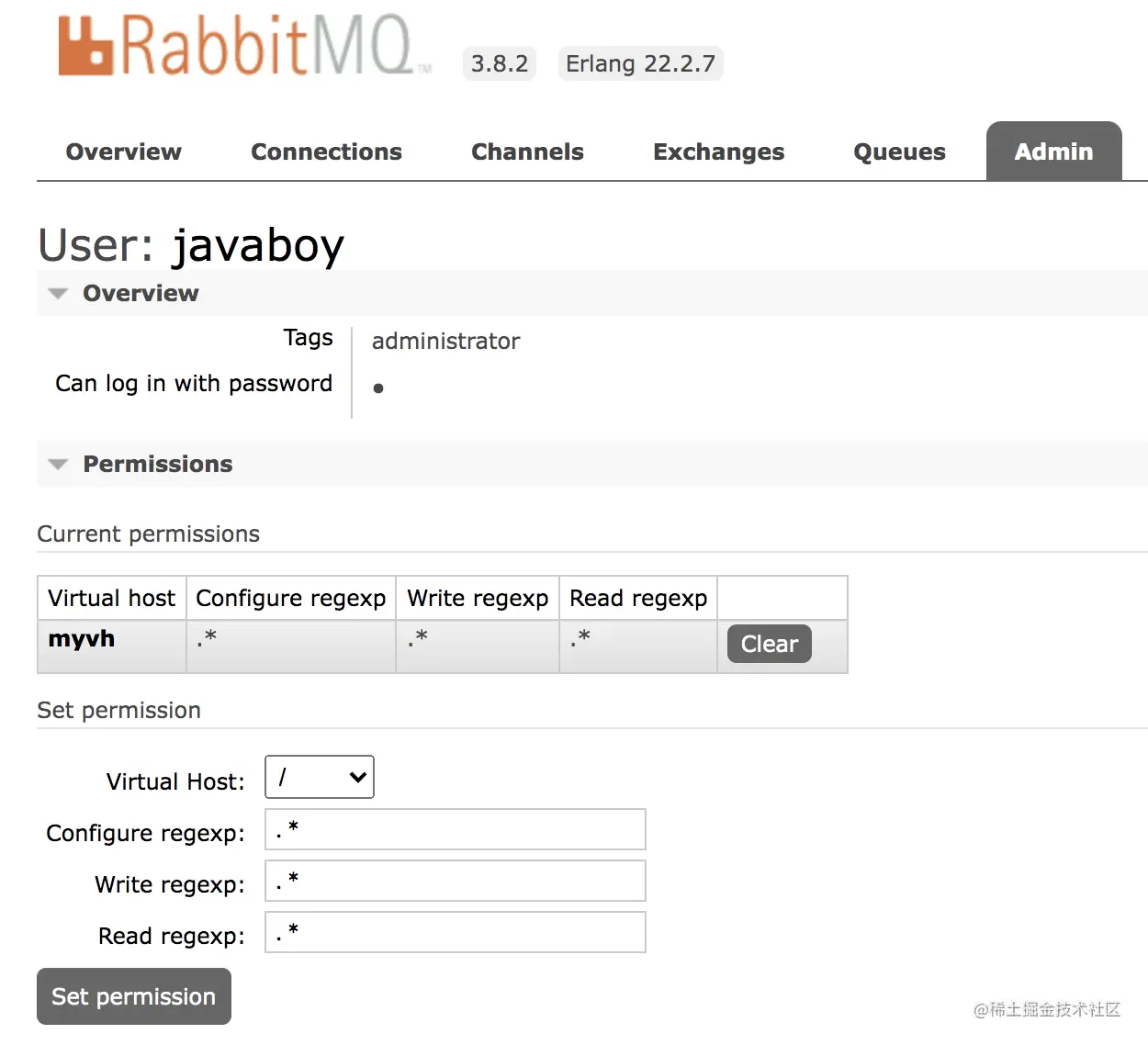
可以设置权限,也可以清除权限。
当然,在网页上还有一个 Topic Permissions,这是 RabbitMQ3.7 开始的一个新功能,可以针对某一个 topic exchange 设置权限,主要针对 STOMP 或者 MQTT 协议,我们日常 Java 开发用上这个配置的机会很少。如果用户不设置的话,相应的 topic exchange 也总是有权限的。
13. RabbitMQ 集群搭建
单个的 RabbitMQ 肯定无法实现高可用,要想高可用,还得上集群。
今天松哥就来和大家聊一聊 RabbitMQ 集群的搭建。
13.1 两种模式
说到集群,小伙伴们可能第一个问题是,如果我有一个 RabbitMQ 集群,那么是不是我的消息集群中的每一个实例都保存一份呢?
这其实就涉及到 RabbitMQ 集群的两种模式:
- 普通集群
- 镜像集群
13.1.1 普通集群
普通集群模式,就是将 RabbitMQ 部署到多台服务器上,每个服务器启动一个 RabbitMQ 实例,多个实例之间进行消息通信。
此时我们创建的队列 Queue,它的元数据(主要就是 Queue 的一些配置信息)会在所有的 RabbitMQ 实例中进行同步,但是队列中的消息只会存在于一个 RabbitMQ 实例上,而不会同步到其他队列。
当我们消费消息的时候,如果连接到了另外一个实例,那么那个实例会通过元数据定位到 Queue 所在的位置,然后访问 Queue 所在的实例,拉取数据过来发送给消费者。
这种集群可以提高 RabbitMQ 的消息吞吐能力,但是无法保证高可用,因为一旦一个 RabbitMQ 实例挂了,消息就没法访问了,如果消息队列做了持久化,那么等 RabbitMQ 实例恢复后,就可以继续访问了;如果消息队列没做持久化,那么消息就丢了。
大致的流程图如下图:

13.1.2 镜像集群
它和普通集群最大的区别在于 Queue 数据和原数据不再是单独存储在一台机器上,而是同时存储在多台机器上。也就是说每个 RabbitMQ 实例都有一份镜像数据(副本数据)。每次写入消息的时候都会自动把数据同步到多台实例上去,这样一旦其中一台机器发生故障,其他机器还有一份副本数据可以继续提供服务,也就实现了高可用。
大致流程图如下图:

13.1.3 节点类型
RabbitMQ 中的节点类型有两种:
- RAM node:内存节点将所有的队列、交换机、绑定、用户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得交换机和队列声明等操作速度更快。
- Disk node:将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启 RabbitMQ 的时候,丢失系统的配置信息
RabbitMQ 要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。为了确保集群信息的可靠性,或者在不确定使用磁盘节点还是内存节点的时候,建议直接用磁盘节点。
13.2 搭建普通集群
13.2.1 预备知识
大致的结构了解了,接下来我们就把集群给搭建起来。先从普通集群开始,我们就使用 docker 来搭建。
搭建之前,有两个预备知识需要大家了解:
- 搭建集群时,节点中的 Erlang Cookie 值要一致,默认情况下,文件在 /var/lib/rabbitmq/.erlang.cookie,我们在用 docker 创建 RabbitMQ 容器时,可以为之设置相应的 Cookie 值。
- RabbitMQ 是通过主机名来连接服务,必须保证各个主机名之间可以 ping 通。可以通过编辑 /etc/hosts 来手工添加主机名和 IP 对应关系。如果主机名 ping 不通,RabbitMQ 服务启动会失败(如果我们是在不同的服务器上搭建 RabbitMQ 集群,大家需要注意这一点,接下来的 2.2 小结,我们将通过 Docker 的容器连接 link 来实现容器之间的访问,略有不同)。
13.2.2 开始搭建
执行如下命令创建三个 RabbitMQ 容器:
docker run -d --hostname rabbit01 --name mq01 -p 5671:5672 -p 15671:15672 -e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
docker run -d --hostname rabbit02 --name mq02 --link mq01:mylink01 -p 5672:5672 -p 15672:15672 -e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
docker run -d --hostname rabbit03 --name mq03 --link mq01:mylink02 --link mq02:mylink03 -p 5673:5672 -p 15673:15672 -e RABBITMQ_ERLANG_COOKIE="javaboy_rabbitmq_cookie" rabbitmq:3-management
- 1
- 2
- 3
运行结果如下:

三个节点现在就启动好了,注意在 mq02 和 mq03 中,分别使用了 --link 参数来实现容器连接,关于这个参数,如果大家不懂,可以在公众号江南一点雨后台回复 docker,由松哥写的 docker 入门教程,里边有讲这个。这里我就不啰嗦了。另外还需要注意,mq03 容器中要既能够连接 mq01 也能够连接 mq02。
接下来进入到 mq02 容器中,首先查看一下 hosts 文件,可以看到我们配置的容器连接已经生效了:
将来在 mq02 容器中,就可以通过 mylink01 或者 rabbit01 访问到 mq01 容器了。
接下来我们开始集群的配置。
分别执行如下命令将 mq02 容器加入集群中:
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit01
rabbitmqctl start_app
- 1
- 2
- 3
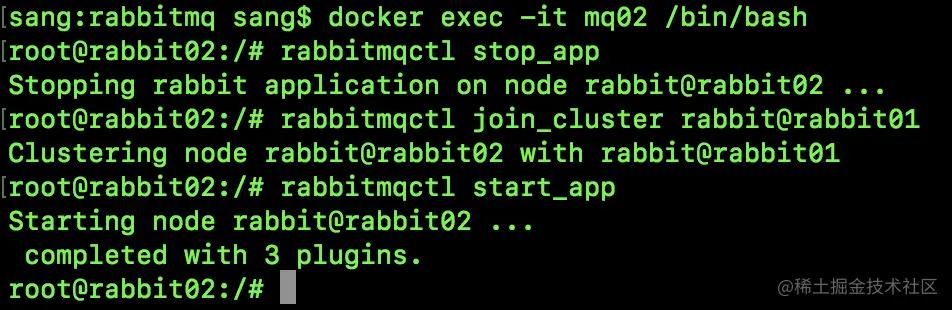
接下来输入如下命令我们可以查看集群的状态:
rabbitmqctl cluster_status
- 1
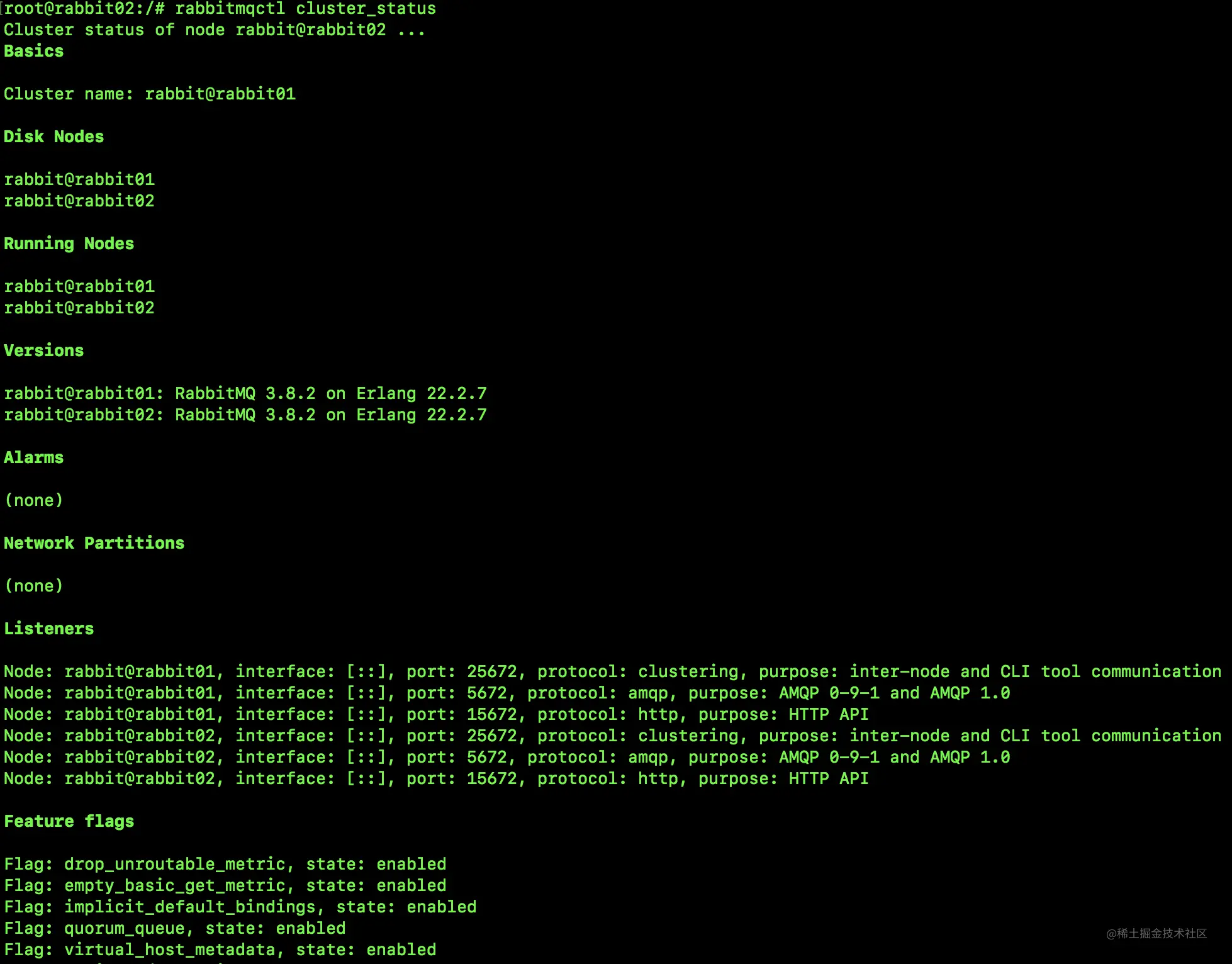
可以看到,集群中已经有两个节点了。
接下来通过相同的方式将 mq03 也加入到集群中:
rabbitmqctl stop_app
rabbitmqctl join_cluster rabbit@rabbit01
rabbitmqctl start_app
- 1
- 2
- 3
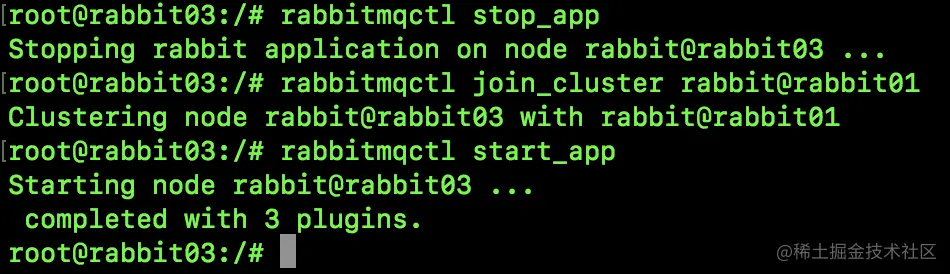
接下来,我们可以查看集群信息:
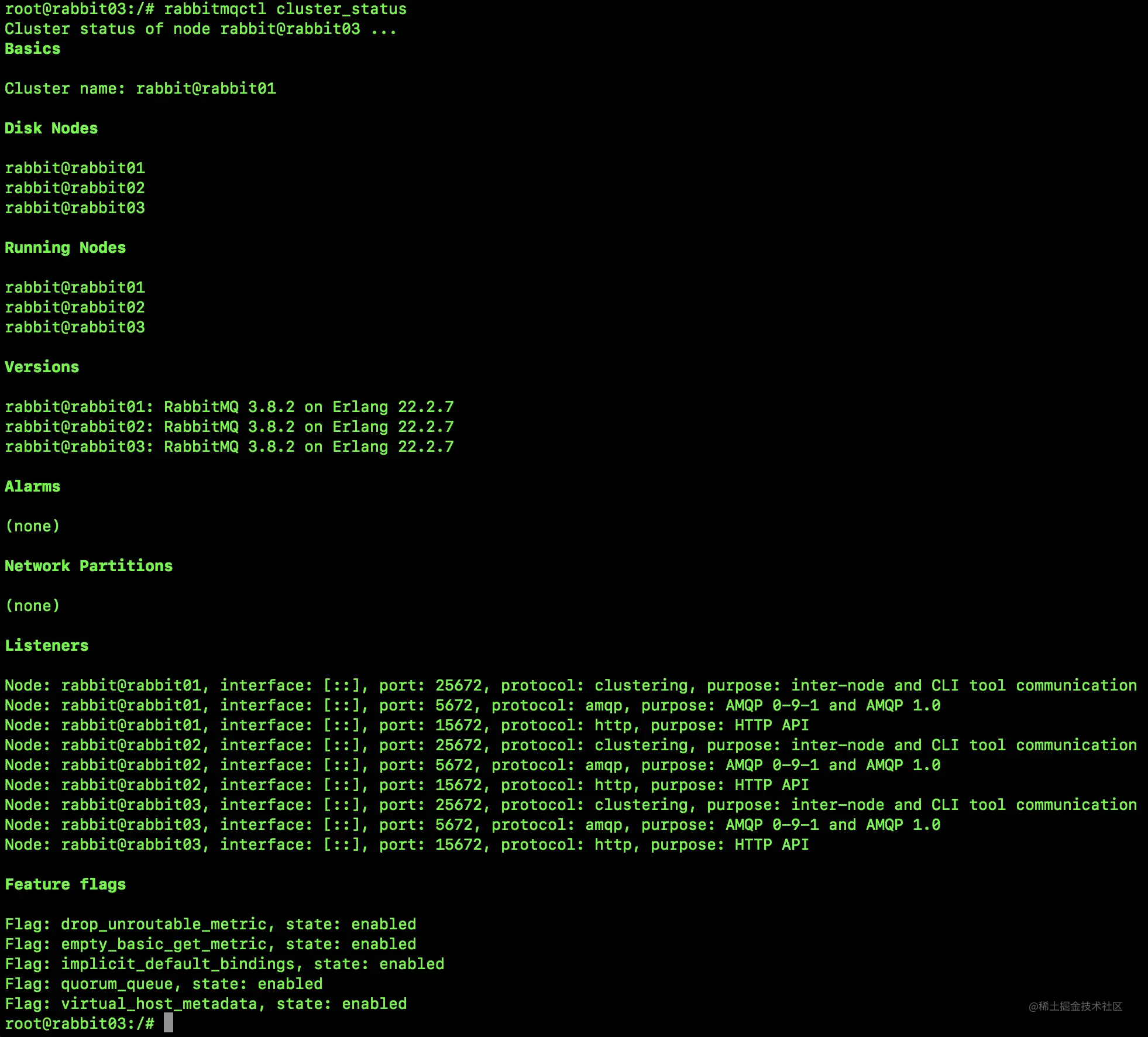
可以看到,此时集群中已经有三个节点了。
其实,这个时候,我们也可以通过网页来查看集群信息,在三个 RabbitMQ 实例的 Web 端首页,都可以看到如下内容:

13.2.3 代码测试
接下来我们来简单测试一下这个集群。
我们创建一个名为 mq_cluster_demo 的父工程,然后在其中创建两个子工程。
第一个子工程名为 provider,是一个消息生产者,创建时引入 Web 和 RabbitMQ 依赖,如下:

然后配置 applicaiton.properties,内容如下(注意集群配置):
spring.rabbitmq.addresses=localhost:5671,localhost:5672,localhost:5673
spring.rabbitmq.username=guest
spring.rabbitmq.password=guest
- 1
- 2
- 3
接下来提供一个简单的队列,如下:
@Configuration public class RabbitConfig { public static final String MY_QUEUE_NAME = "my_queue_name"; public static final String MY_EXCHANGE_NAME = "my_exchange_name"; public static final String MY_ROUTING_KEY = "my_queue_name"; @Bean Queue queue() { return new Queue(MY_QUEUE_NAME, true, false, false); } @Bean DirectExchange directExchange() { return new DirectExchange(MY_EXCHANGE_NAME, true, false); } @Bean Binding binding() { return BindingBuilder.bind(queue()) .to(directExchange()) .with(MY_ROUTING_KEY); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
这个没啥好说的,都是基本内容,接下来我们在单元测试中进行消息发送测试:
@SpringBootTest
class ProviderApplicationTests {
@Autowired
RabbitTemplate rabbitTemplate;
@Test
void contextLoads() {
rabbitTemplate.convertAndSend(null, RabbitConfig.MY_QUEUE_NAME, "hello 江南一点雨");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
这条消息发送成功之后,在 RabbitMQ 的 Web 管理端,我们会看到三个 RabbitMQ 实例上都会显示有一条消息,但是实际上消息本身只存在于一个 RabbitMQ 实例。
接下来我们再创建一个消息消费者,消息消费者的依赖以及配置和消息生产者都是一模一样,我就不重复了,消息消费者中增加一个消息接收器:
@Component
public class MsgReceiver {
@RabbitListener(queues = RabbitConfig.MY_QUEUE_NAME)
public void handleMsg(String msg) {
System.out.println("msg = " + msg);
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
当消息消费者启动成功后,这个方法中只收到一条消息,进一步验证了我们搭建的 RabbitMQ 集群是没问题的。
13.2.4 反向测试
接下来松哥再举两个反例,以证明消息并没有同步到其他 RabbitMQ 实例。
确保三个 RabbitMQ 实例都是启动状态,关闭掉 Consumer,然后通过 provider 发送一条消息,发送成功之后,关闭 mq01 实例,然后启动 Consumer 实例,此时 Consumer 实例并不会消费消息,反而会报错说 mq01 实例连接不上,这个例子就可以说明消息在 mq01 上,并没有同步到另外两个 MQ 上。相反,如果 provider 发送消息成功之后,我们没有关闭 mq01 实例而是关闭了 mq02 实例,那么你就会发现消息的消费不受影响。
13.3 搭建镜像集群
所谓的镜像集群模式并不需要额外搭建,只需要我们将队列配置为镜像队列即可。
这个配置可以通过网页配置,也可以通过命令行配置,我们分别来看。
13.3.1 网页配置镜像队列
先来看看网页上如何配置镜像队列。
点击 Admin 选项卡,然后点击右边的 Policies,再点击 Add/update a policy,如下图:

接下来添加一个策略,如下图:
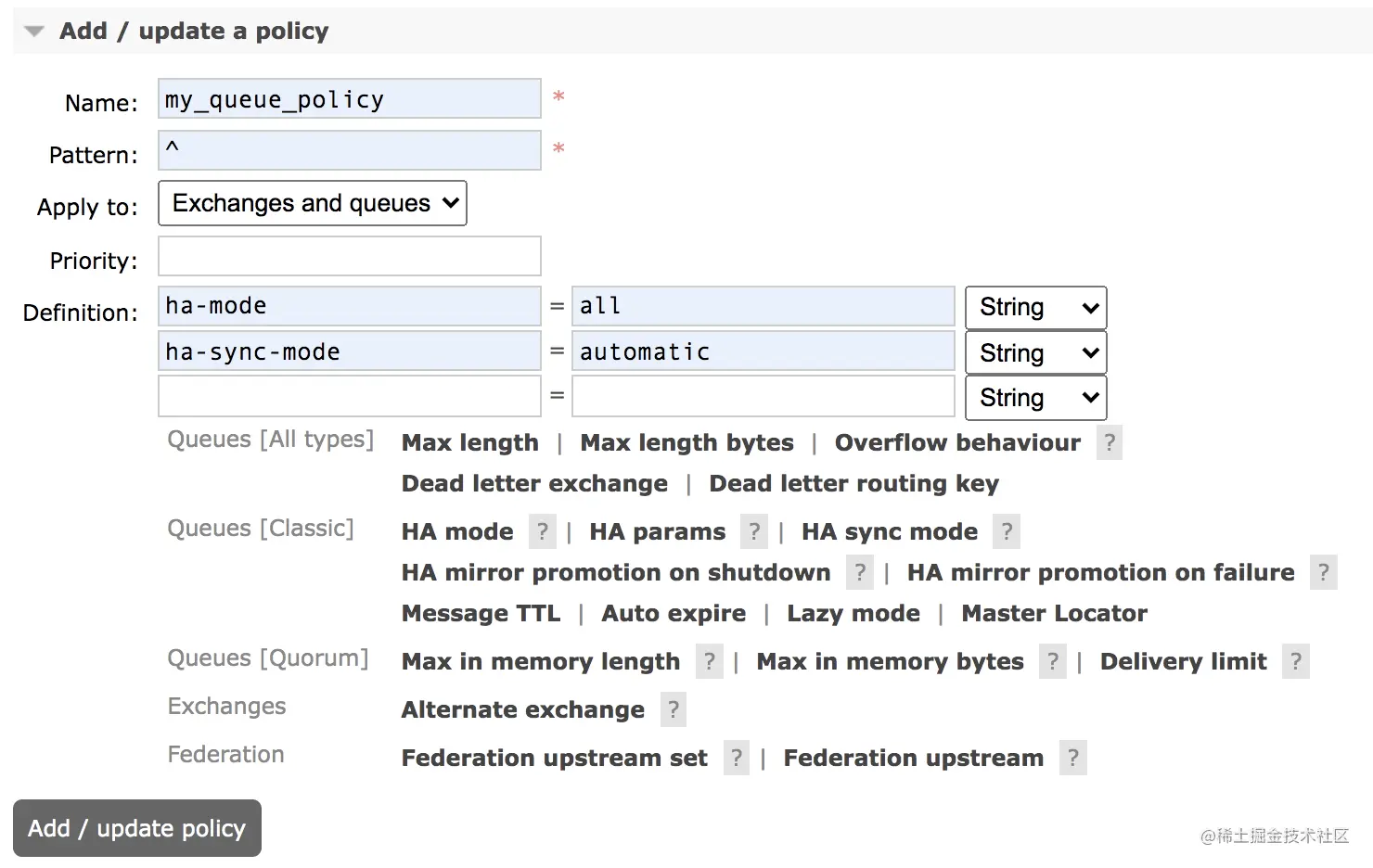
各参数含义如下:
- Name: policy 的名称。
- Pattern: queue 的匹配模式 (正则表达式)。
- Definition:镜像定义,主要有三个参数:ha-mode, ha-params, ha-sync-mode。
- ha-mode:指明镜像队列的模式,有效值为 all、exactly、nodes。其中 all 表示在集群中所有的节点上进行镜像(默认即此);exactly 表示在指定个数的节点上进行镜像,节点的个数由 ha-params 指定;nodes 表示在指定的节点上进行镜像,节点名称通过 ha-params 指定。
- ha-params:ha-mode 模式需要用到的参数。
- ha-sync-mode:进行队列中消息的同步方式,有效值为 automatic 和 manual。
- priority 为可选参数,表示 policy 的优先级。
配置完成后,点击下面的 add/update policy 按钮,完成策略的添加,如下:
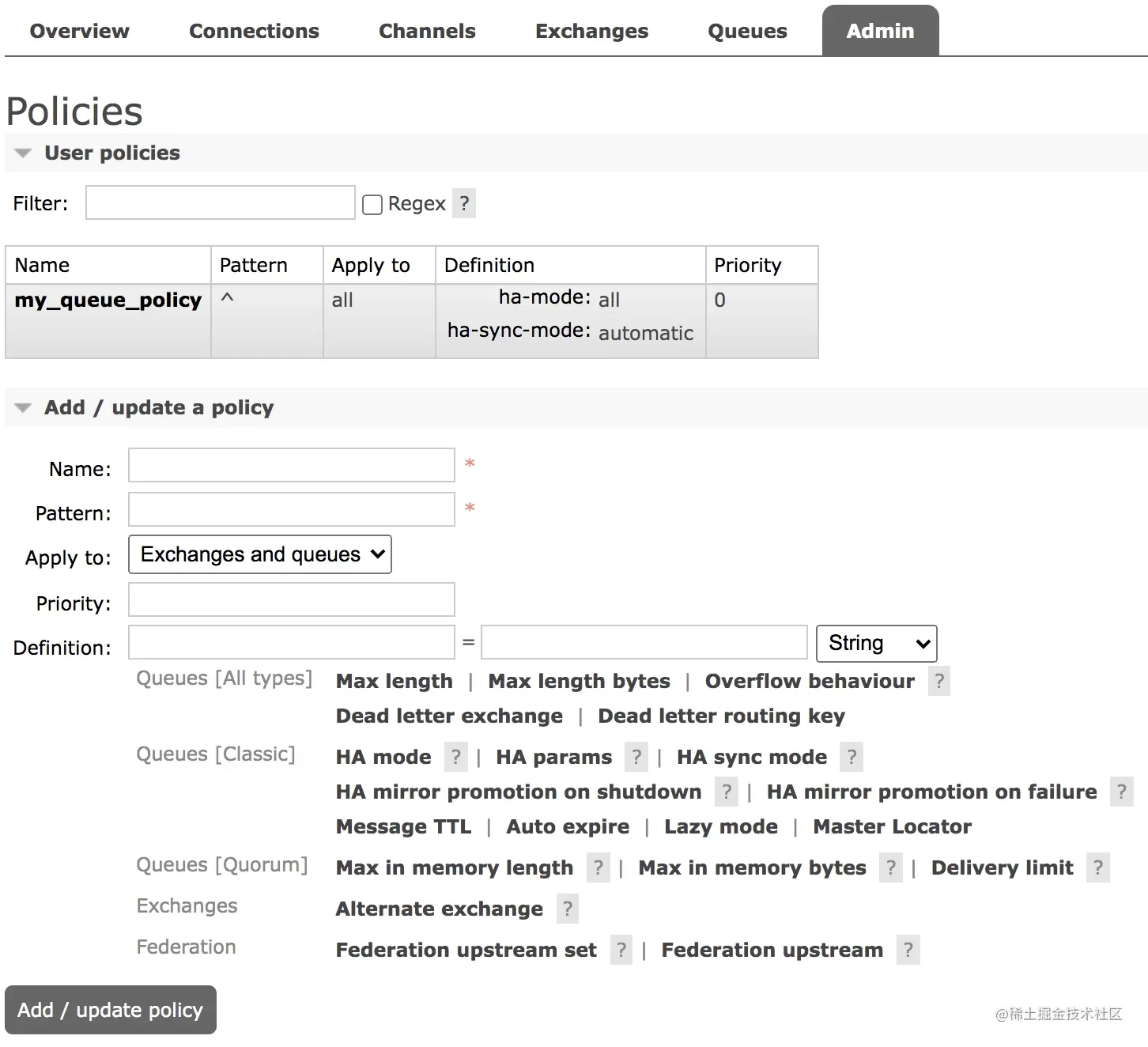
添加完成后,我们可以进行一个简单的测试。
首先确认三个 RabbitMQ 都启动了,然后用上面的 provider 向消息队列发送一条消息。
发完之后关闭 mq01 实例。
接下来启动 consumer,此时发现 consumer 可以完成消息的消费(注意和前面的反向测试区分),这就说明镜像队列已经搭建成功了。
13.3.2 命令行配置镜像队列
命令行的配置格式如下:
rabbitmqctl set_policy [-p vhost] [--priority priority] [--apply-to apply-to] {name} {pattern} {definition}
- 1
举一个简单的配置案例:
rabbitmqctl set_policy -p / --apply-to queues my_queue_mirror "^" '{"ha-mode":"all","ha-sync-mode":"automatic"}'
- 1

- 完结撒花~
作者:江南一点雨
原文链接:https://juejin.cn/post/7051469607806173221

