
- 1js中push(),pop(),unshift(),shift()的用法小结_tablearr.shift()
- 22020.3IDEA配置git教程_idea2020配置git插件
- 3netbios 网上基本输入输出系统 简介_netbios-ns
- 4服务网格技术:为微服务架构提供基础设施
- 5计算机软件职称聘用,关于做好2017年“以聘代评”系列职称聘任工作的通知
- 6【大数据入门核心技术-DolphinScheduler】(二)DolphinScheduler安装部署-集群模式_dolphinscheduler 配合git使用
- 7sql having是什么意思_SQL-计算、汇总和分组
- 8centos执行mpd&遇到bash:mpd:command not found错误
- 9电商技术揭秘十五:数据挖掘与用户行为分析
- 10【解决】Invalid hash given_fatal: invalid hash
Redis 布隆过滤器总结_java 使用redisbloom过滤去重海量数据
赞
踩
前言: 开发中,经常有让我们判断一个集合中是否存在某个数的case;大多数情况下,只需要用map或是list这样简单的数据结构。但是在高并发环境下,所有的case都会极端化,如果这是一个十分庞大的集合(给这个庞大一个具体的值吧,一个亿),简单的一个HashMap,不考虑链表所需的指针内存空间,一亿个int类型的整数,就需要380多M(4byte × 10 ^8),十亿的话就是4个G,不考虑性能,光算算这内存开销,即使现在满地都是128G的服务器,也不好吃下这一壶。
在海量数据面前,需要高效的去重数据结构布隆过滤器。布隆过滤器有着很棒的性能,也有着很广泛的应用场景,比如垃圾邮件的过滤,缓存击穿等。
一、为什么会出现布隆过滤器?
1.1、抖音推送去重
(1)问题描述
抖音你有刷到过重复的推荐内容吗?这么多的推荐内容要推荐给这么多的用户,它是怎么保证每个 用户在看推荐内容时,保证不会出现之前已经看过的推荐视频呢?也就是说,抖音是如何实现 推送去重 的呢?
(2)解决方案
你会想到服务器记录了用户看过的所有历史记录,当推荐系统推荐短视频时会从每个用户的历史记录里进行筛选,过滤掉那些已经存在的记录。问题是当用户量很大,每个用户看过的短视频又很多的情况下,这种方式,推荐系统的去重工作在性能上跟的上么?
实际上,如果历史记录存储在关系数据库里,去重就需要频繁地对数据库进行 exists 查询,当系统并发量很高时,数据库是很难抗住压力的。你可能又想到了Redis缓存,但是这么多用户这么多的历史记录,如果全部缓存起来,那得需要浪费多大的内存空间啊,并且这个存储空间会随着时间呈线性增长,服务器撑不住啊?不缓存性能又跟不上,咋办呢?
布隆过滤器(Bloom Filter) 就是这样一种专门用来判断是否存在或解决去重问题的高级数据结构。它能在解决去重的同时,在空间上能节省 90% 以上。
1.2、用户登录和签到
在移动应用的业务场景中,我们需要保存这样的信息:一个 key 关联了一个数据集合。
常见的场景如下:
-
给一个 userId ,判断用户登陆状态;
-
显示用户某个月的签到次数和首次签到时间;
-
两亿用户最近 7 天的签到情况,统计 7 天内连续签到的用户总数;
通常情况下,我们面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息。所以,我们必须要选择能够非常高效地统计大量数据(例如亿级)的集合类型。
如何选择合适的数据集合,我们首先要了解常用的统计模式,并运用合理的数据类型来解决实际问题。
四种统计类型:
-
二值状态统计;
-
聚合统计;
-
排序统计;
-
基数统计。
本文将介绍二值状态统计类型,会用到 String、Set、Zset、List、hash 以外的拓展数据类型 Bitmap 和布隆过滤器来实现。
也就是集合中的元素的值只有 0 和 1 两种,在签到打卡和用户是否登陆的场景中,只需记录签到(1)或 未签到(0),已登录(1)或未登陆(0)。
假如我们在判断用户是否登陆的场景中使用 Redis 的 String 类型实现(key -> userId,value -> 0 表示下线,1 - 登陆),假如存储 100 万个用户的登陆状态,如果以字符串的形式存储,就需要存储 100 万个字符串了,内存开销太大。可以使用高级数据结构bitmap或者布隆过滤器实现。
二、布隆过滤器简介
2.1、布隆过滤器是什么?
布隆过滤器(Boolm Filter)是1970年由布隆提出的一种算法。实际上是一个很长的二进制向量和一系列随机映射哈希函数。其实就是一种数据结构,类似于Hash、Set,主要用于检索一个元素是否在一个集合中。当布隆过滤器说某个值存在时,这个值 可能不存在;当它说不存在时,那么一定不存在。你也可以把它简单理解为一个不怎么精确的 set 结构,当你使用它的
contains方法判断某个对象是否存在时,它可能会误判。但是布隆过滤器也不是特别不精确,只要参数设置的合理,它的精确度可以控制的相对足够精确,只会有小小的误判概率。
在编程中,我们想要判断一个元素是不是在一个集合中,一般会想到将所有元素保存起来,然后比较确定。链表、树等数据结构都是这种思路。但是,随着集合中元素的增加,需要的存储空间越来越大,检索的速度也就越来越慢了。
布隆过滤器相对于Hash、Set等数据结构不同的时,它无需存储key,对于每个key,只需要k个比特位,每个存储一个标志,用来判断key是否在集合中。所以,它可以实现高效的插入和查询,并且在时间和空间方面都具有巨大的优势,都是常数。
2.2、布隆过滤器的使用场景
基于上述的功能,我们大致可以把布隆过滤器用于以下的场景之中:
-
大数据判断是否存在来实现去重:这就可以实现出上述的去重功能,如果你的服务器内存足够大的话,那么使用 HashMap 可能是一个不错的解决方案,理论上时间复杂度可以达到 O(1) 的级别,但是当数据量起来之后,还是只能考虑布隆过滤器。
-
判断用户是否访问过:判断用户是否阅读过某视频或文章,比如抖音或头条,当然会导致一定的误判,但不会让用户看到重复的内容。
-
解决缓存穿透:我们经常会把一些热点数据放在 Redis 中当作缓存,例如产品详情。通常一个请求过来之后我们会先查询缓存,而不用直接读取数据库,这是提升性能最简单也是最普遍的做法,但是 如果一直请求一个不存在的缓存,那么此时一定不存在缓存,那就会有大量请求直接打到数据库上,造成 缓存穿透,布隆过滤器也可以用来解决此类问题。
-
爬虫/ 邮箱等系统的过滤:平时不知道你有没有注意到有一些正常的邮件也会被放进垃圾邮件目录中,这就是使用布隆过滤器误判导致的。
2.3、布隆过滤器的原理
当一个元素被加入集合时,通过N个Hash函数将这个元素进行Hash,算出一个整数索引值,然后对数组长度进行取模运算,从而得到一个位置,每个Hash函数都会得到一个不同的位置,然后再把位数组中的几个位置点都置为1。

检索时,也会把哈希的几个位置算出来,然后看看位数组中对应的几个位置是否都为1,只要有一个位为0,那么就说明布隆过滤器里不存在这个元素。
但是,这几个位置都为1,并不能完全说明这个元素就一定存在其中,有可能这些位置为1是因为其他元素的存在,这就是布隆过滤器会出现误判的原因。
简而言之就是,布隆过滤器可以判断某个元素一定不存在,但是无法判断一定存在。
所以,我们可以得出布隆过滤器的优缺点如下:
优点
1)占用空间极小,插入和查询速度极快;
2)布隆过滤器可以表示全集,其它任何数据结构都不能;
缺点
1)误算率随着元素的增加而增加;
2)一般情况下无法删除元素;
三、bitmap和布隆过滤器关系
在Redis4.0之前,只能通过bitmap来实现,在Redis4.0之后,官方提供了module能力,这时候,官方提供的RedisBloom才算正式出道。
3.1、海量整数中是否存在某个值:bitmap
bitmap使用位数代表数的大小,bit中存储的0或者1来标识该整数是否存在。计算一下bitmap的内存开销,如果是1亿以内的数据查找,我们只需要1亿个bit = 12MB左右的内存空间,就可以完成海量数据查找了,这是极其诱人的一个内存缩减。
(1)bitmap概述
我们知道,计算机是以二进制为底层的存储单位,一个字节等于8位。比如“big”字符串是由三个字符组成,这三个字符对应的ASCII码分别为98,105,103,对应的二进制存储如下:

基本命令如下:
- # 设置字节值
- setbit key offset value
- # 获取字节值
- gitbit key offset
- # 获取指定范围内为1的元素个数
- bitcount key [start end]
(2)bitmap原理
这是一个能标识0-9的“bitmap”,其中4321这四个数存在,具体模型如下:
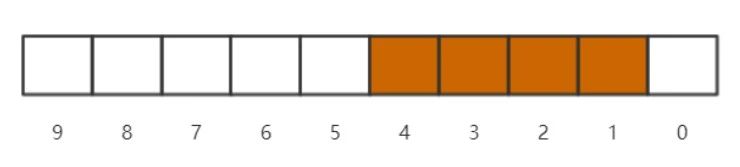
例如说往bitmap里面存储一个数字11,那么首先需要通过向右移位(因为一个byte相当于8个bit),计算出所存储的byte[]数组的索引定位,这里计算出index是1。由于一个byte里面存储了八个bit位,所以通过求余的运算来计算postion,算出来为3。
这里假设原有的bitmap里面存储了4和12这2个数字,那么它的结构如下所示:

这个时候,我们需要存储11进来,那么就需要进行或运算了:

同理,当我们判断数字是否存在的时候,也需要进行相应的判断,代码如下:
- public boolean contain(int number) {
- int index = number >> 3;
- int position = number & 0x07;
- return (bytes[index] & (1<<position)) !=0;
- }

(3)整合一下,简单版的bitmap代码如下:
- public class MyBitMap {
-
- private byte[] bytes;
- private int initSize;
-
- public MyBitMap(int size) {
- if (size <= 0) {
- return;
- }
- initSize = size / (8) + 1;
- bytes = new byte[initSize];
- }
-
- public void set(int number) {
- //相当于对一个数字进行右移动3位,相当于除以8
- int index = number >> 3;
- //相当于 number % 8 获取到byte[index]的位置
- int position = number & 0x07;
- //进行|或运算 参加运算的两个对象只要有一个为1,其值为1。
- bytes[index] |= 1 << position;
- }
-
-
- public boolean contain(int number) {
- int index = number >> 3;
- int position = number & 0x07;
- return (bytes[index] & (1 << position)) != 0;
- }
-
- public static void main(String[] args) {
- MyBitMap myBitMap = new MyBitMap(32);
- myBitMap.set(30);
- myBitMap.set(13);
- myBitMap.set(24);
- System.out.println(myBitMap.contain(2));
- }
-
- }

(4)bitmap缺陷
使用简单的byte数组和位运算,就能做到时间与空间的完美均衡,但是bitmap还存在问题!
试想一下,如果我们明确这是一个一亿以内,但是数量级只有10的集合,我们使用bitmap,同样需要开销12M的数据,如果是10亿以内的数据,开销就会涨到120M,bitmap的空间开销永远是和他的数据取值范围挂钩的,只有在海量数据下,他才能够大显身手。
再说说刚刚提到的那个极端case,假设这个数据量在一千万,但是取值范围好死不死就在十个亿以内,那我们不可避免还是要面对120M的开销,有方法应对么?
3.2、布隆过滤器
(1)布隆过滤器简介
如果面对笔者说的以上问题,我们结合一下常规的解决方案,譬如说hash一下,我将十亿以内的某个数据,hash成一亿内的某个值,再去bitmap中查怎么样,如下图,布隆过滤器就是这么干的:
利用多个hash算法得到的值,减小hash碰撞的概率,但只要存在碰撞,就一定会有错误判断,我们无法百分百确定一个值是否真的存在,但是hash算法的魅力在于,我不能确定你是否存在,但是我可以确定你是否真的不存在,这也就是以上的实现为什么称之“过滤器”的原因了。
在Redis4.0之后。我们可以将RedisBloom作为一个模块加载到Redis Server中,从而获取强大的布隆过滤器能力。
在RedisBloom中,布隆过滤器有两个基本命令,分别是:
1)bf.add:添加元素到布隆过滤器中,类似于集合的sadd命令,不过bf.add命令只能一次添加一个元素,如果想一次添加多个元素,可以使用bf.madd命令。
2)bf.exists:判断某个元素是否在过滤器中,类似于集合的sismember命令,不过bf.exists命令只能一次查询一个元素,如果想一次查询多个元素,可以使用bf.mexists命令。
布隆过滤器提供默认参数的布隆过滤器,它在我们第一次使用bf.add命令时自动创建的。
(2)Redis自定义参数的布隆过滤器
Redis还提供了自定义参数的布隆过滤器,想要尽量减少布隆过滤器的误判,就要设置合理的参数。
在使用bf.add命令添加元素之前,使用bf.reserve命令创建一个自定义的布隆过滤器。
bf.reserve命令有三个参数,分别是:
key:键
error_rate:期望错误率,期望错误率越低,需要的空间就越大。
capacity:初始容量,当实际元素的数量超过这个初始化容量时,误判率上升。
示例如下:
- 127.0.0.1:6379> BF.RESERVE customFilter 0.0001 600000
- OK
如果对应的key已经存在时,在执行bf.reserve命令就会报错。如果不使用bf.reserve命令创建,而是使用Redis自动创建的布隆过滤器,默认的error_rate是 0.0001,capacity是 60。
布隆过滤器的error_rate越小,需要的存储空间就越大,对于不需要过于精确的场景,error_rate设置稍大一点也可以。
布隆过滤器的capacity设置的过大,会浪费存储空间,设置的过小,就会影响准确率,所以在使用之前一定要尽可能地精确估计好元素数量,还需要加上一定的冗余空间以避免实际元素可能会意外高出设置值很多。
总之,error_rate和 capacity都需要设置一个合适的数值。
四、Redis布隆过滤器的使用
Redis 官方提供的布隆过滤器到了 Redis 4.0 提供了插件功能之后才正式登场。布隆过滤器作为一个插件加载到 Redis Server 中,给 Redis 提供了强大的布隆去重功能。而在Java开发中,可以使用各种现成的布隆过滤器客户端,包括Google出品的Guava BloomFilter类和Redisson的RBloomFilter接口访问布隆过滤器。
4.1、使用 Google 开源的 Guava 中自带的布隆过滤器
Guava 中布隆过滤器的实现算是比较权威的,所以实际项目中我们不需要手动实现一个布隆过滤器。
首先我们需要在项目中引入 Guava 的依赖:
- <dependency>
- <groupId>com.google.guava</groupId>
- <artifactId>guava</artifactId>
- <version>28.0-jre</version>
- </dependency>
实际使用如下:
我们创建了一个最多存放 最多 1500 个整数的布隆过滤器,并且我们可以容忍误判的概率为百分之一(0.01)
- // 创建布隆过滤器对象
- BloomFilter<Integer> filter = BloomFilter.create(
- Funnels.integerFunnel(),
- 1500,
- 0.01);
- // 判断指定元素是否存在
- System.out.println(filter.mightContain(1));
- System.out.println(filter.mightContain(2));
- // 将元素添加进布隆过滤器
- filter.put(1);
- filter.put(2);
- System.out.println(filter.mightContain(1));
- System.out.println(filter.mightContain(2));
在我们的示例中,当 mightContain() 方法返回 true 时,我们可以 99% 确定该元素在过滤器中,当过滤器返回 false 时,我们可以 100% 确定该元素不存在于过滤器中。
Guava 提供的布隆过滤器的实现还是很不错的 ,但是它有一个重大的缺陷就是只能单机使用 (另外,容量扩展也不容易),而现在互联网一般都是分布式的场景。为了解决这个问题,我们就需要用到 Redis 中的布隆过滤器了。
4.2、通过Redisson使用布隆过滤器
Redisson是一款超快速轻量级Redis Java客户端,提供了许多常用的Java对象和功能,包括布隆过滤器。
- public interface RBloomFilter<T> extends RExpirable {
-
- boolean tryInit(long var1, double var3); //初始化布隆过滤器,var1表示大小,var3表示容错率
-
- boolean add(T var1); //添加对象
- boolean contains(T var1); //判断对象是否存在
-
- long getExpectedInsertions(); //返回预计插入数量
- double getFalseProbability(); //返回容错率
- int getHashIterations(); //返回hash函数个数
-
- long count(); //对象插入后,估计插入数量
- long getSize(); //布隆过滤器位数组的大小
-
- }
下面的示例代码演示了如何用Redisson的RBloomFilter接口使用布隆过滤器:
- RBloomFilter<SomeObject> bloomFilter = redisson.getBloomFilter("sample");
- // 初始化布隆过滤器
- // expectedInsertions = 55000000
- // falseProbability = 0.03
- bloomFilter.tryInit(55000000L, 0.03);
-
- bloomFilter.add(new SomeObject("field1Value", "field2Value"));
-
- bloomFilter.add(new SomeObject("field5Value", "field8Value"));
-
-
- bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
-
- bloomFilter.count();
布隆过滤器是一种概率数据结构:能确认元素不存在于集合中,但只能提供元素出现在集合中的概率。
-
falseProbability参数定义了使用给定RBloomFilter发生误报的概率。
-
expectedInsertions参数定义了每个元素的预期插入次数。RBloomFilter对象最多支持2 ^32 bit。
Redisson还能通过RClusteredBloomFilter接口在Redis中支持分布式布隆过滤器。RClusteredBloomFilter的内存效率更高,可以缩小所有Redis节点使用的内存。RClusteredBloomFilter对象最多支持2^64 bit。请注意,RClusteredBloomFilter只支持Redisson集群模式使用。
以下示例代码演示了如何使用RClusteredBloomFilter接口:
- RClusteredBloomFilter<SomeObject> bloomFilter = redisson.getClusteredBloomFilter("sample");
- // 初始化布隆过滤器
- // expectedInsertions = 255000000
- // falseProbability = 0.03
- bloomFilter.tryInit(255000000L, 0.03);
- bloomFilter.add(new SomeObject("field1Value", "field2Value"));
- bloomFilter.add(new SomeObject("field5Value", "field8Value"));
- bloomFilter.contains(new SomeObject("field1Value", "field8Value"));
Redis布隆过滤器总结:
Redis中大名鼎鼎的布隆过滤器,在一些大数据场景下,判断是否存在来实现去重,布隆过滤器有着极为出色的性能,在大厂中应用范围是极其广的,只要你想在大厂搬砖,一定会在面试敲门的时候被问到的。
参考链接:
Redis 实战篇:巧用 Bitmap 实现亿级海量数据统计

