
- 1Understanding Large Language Models-TianQi Chen_self-diagnosis and self-debiasing: a proposal for
- 2arm架构,django4.2.7适配达梦8数据库
- 3动态规划之数字三角形模型
- 4【Package】RosBridge——打通Ros与非Ros环境的数据壁垒_rosbridge roswiki
- 5中华有为,进入华为华为上班是一种什么样的体验,附上华为大佬的面试经验!_为什么想去华为工作
- 6【设计原则】迪米特法则_迪米特法则的优点和缺点
- 7探索Open Interpreter:一个创新的代码解释器项目
- 8Android修改包名的办法_安卓修改包名
- 9使用格式工厂将H264文件转成mp4文件_h264转mp4
- 10多年收集的一些稀有软件3
机器学习实战(十一)FP-growth算法_fpgrowth算法
赞
踩
前言
频繁项集挖掘算法用于挖掘经常一起出现的item集合(称为频繁项集),通过挖掘出这些频繁项集,当在一个事务中出现频繁项集的其中一个item,则可以把该频繁项集的其他item作为推荐。比如经典的购物篮分析中啤酒、尿布故事,啤酒和尿布经常在用户的购物篮中一起出现,通过挖掘出啤酒、尿布这个啤酒项集,则当一个用户买了啤酒的时候可以为他推荐尿布,这样用户购买的可能性会比较大,从而达到组合营销的目的。
常见的频繁项集挖掘算法有两类,一类是Apriori算法,另一类是FP-growth算法。
一、FP-growth算法简介
Apriori通过不断的构造候选集、筛选候选集挖掘出频繁项集,需要多次扫描原始数据,当原始数据较大时,磁盘I/O次数太多,效率比较低下。这毫无疑问会成为Apriori算法最大的缺点一频繁项集发现的速度太慢。 FP-growth算法其实是在Apriori算法基础上进行了优化得到的算法,FPGrowth算法则只需扫描原始数据两遍,通过FP-tree数据结构对原始数据进行压缩,效率较高。
FP-growth算法只需要对数据库进行了两次扫描,而Apriori算法对于每个潜在的频繁项集都会扫描数据集判定给定模式是否频繁,因此FP-growth算法的速度要比Apriori算法快。在小规模数据集上,这不是什么问题,但是当处理大规模数据集时,就会产生很大的区别。
关于FP-growth算法需要注意的两点是:
- 该算法采用了与Apriori完全不同的方法来发现频繁项集
- 该算法虽然能更为高效地发现频繁项集,但不能用于发现关联规则。
二、FP-growth算法步骤
FP-growth算法主要分为两个步骤
- 基于数据集构建FP树
- 从FP树种递归挖掘频繁项集
FP-tree构建通过两次数据扫描,将原始数据中的事务压缩到一个FP-tree树,该FP-tree类似于前缀树,相同前缀的路径可以共用,从而达到压缩数据的目的。
接着通过FP-tree找出每个item的条件模式基、条件FP-tree,递归的挖掘条件FP-tree得到所有的频繁项集。
算法的主要计算瓶颈在FP-tree的递归挖掘上。
三、FP-growth算法数据结构

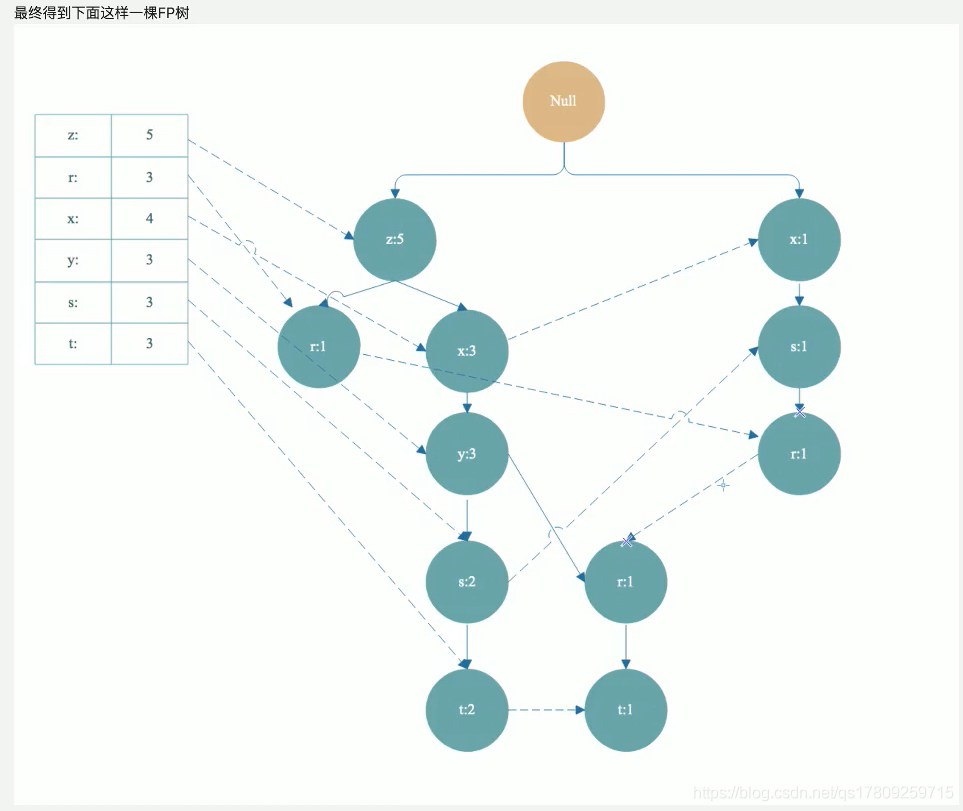
由这样的树节点构造出来的树,就是FP树。
四、FP-growth算法原理
1.基于数据集构建FP树
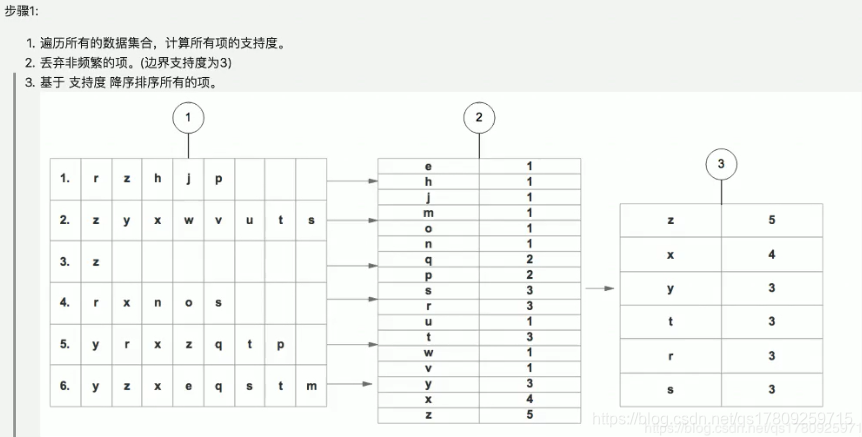
- 支持度:某一项类别出现的次数,可以理解为出现的频率
- 非频繁项:某一项出现的次数小于一定次数,我们称之为非频繁项。
(1)FP树的特点

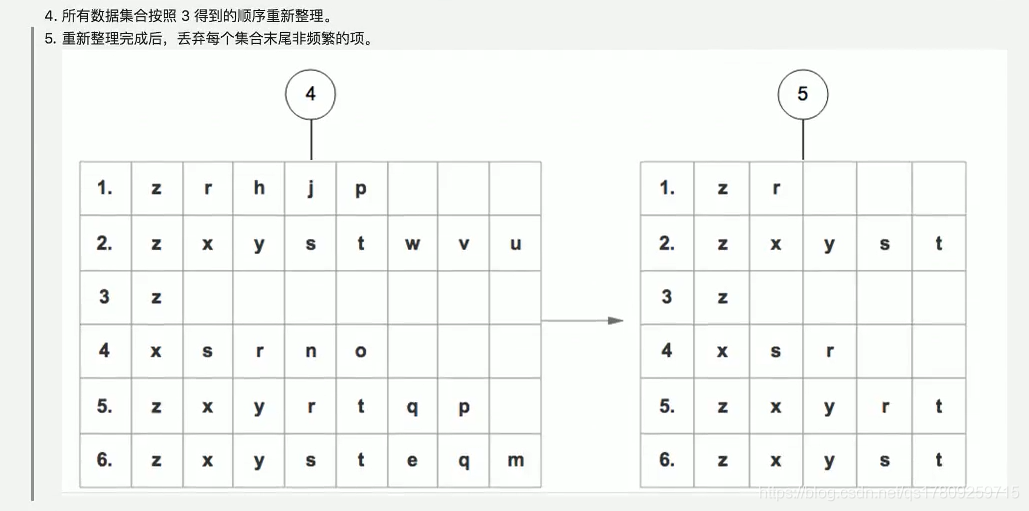
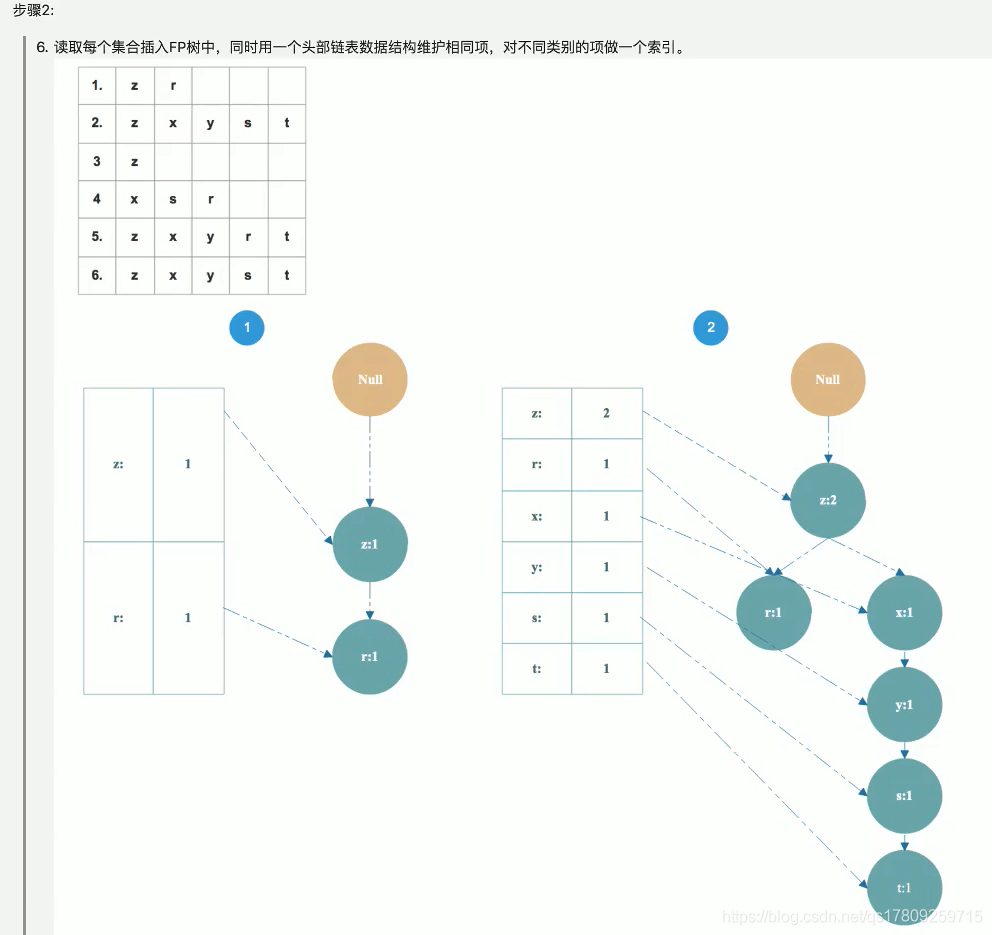
(2)FP树的构建步骤:
2.从FP树中挖掘频繁项集
有了FP树之后,我们就可以来挖掘频繁项集了。这里的思路和Apriori算法大致类似,首先从单元素项集合开始,然后在此基础上逐步构建更大的集合。当然,这里使用的是FP树而不是原始数据集。
条件模式基: 头部链表中的某一点的前缀路径组合就是条件模式基,条件模式基的值取决于末尾节点的值。
(1)从FP树中挖掘频繁项集的步骤:
- 1)从FP树中获得条件模式基;
- 2)利用条件模式基,构建一个条件FP树;
- 3)迭代:重复上述两个步骤,知道树包含一个元素项为止。
(2)挖掘频繁项集的过程如下:
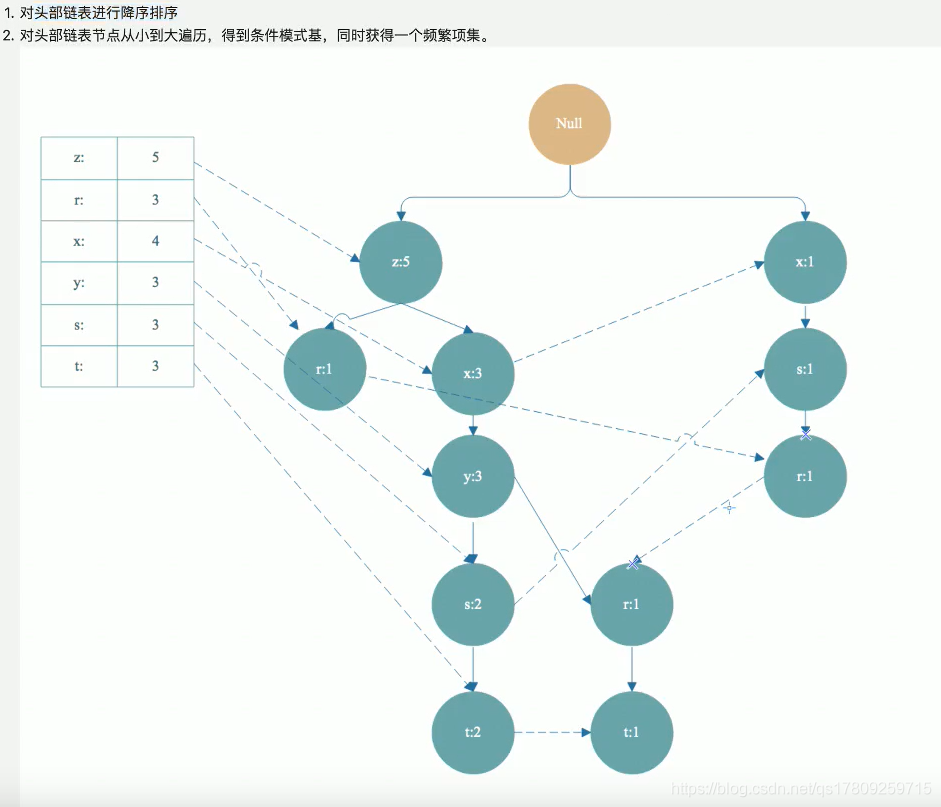
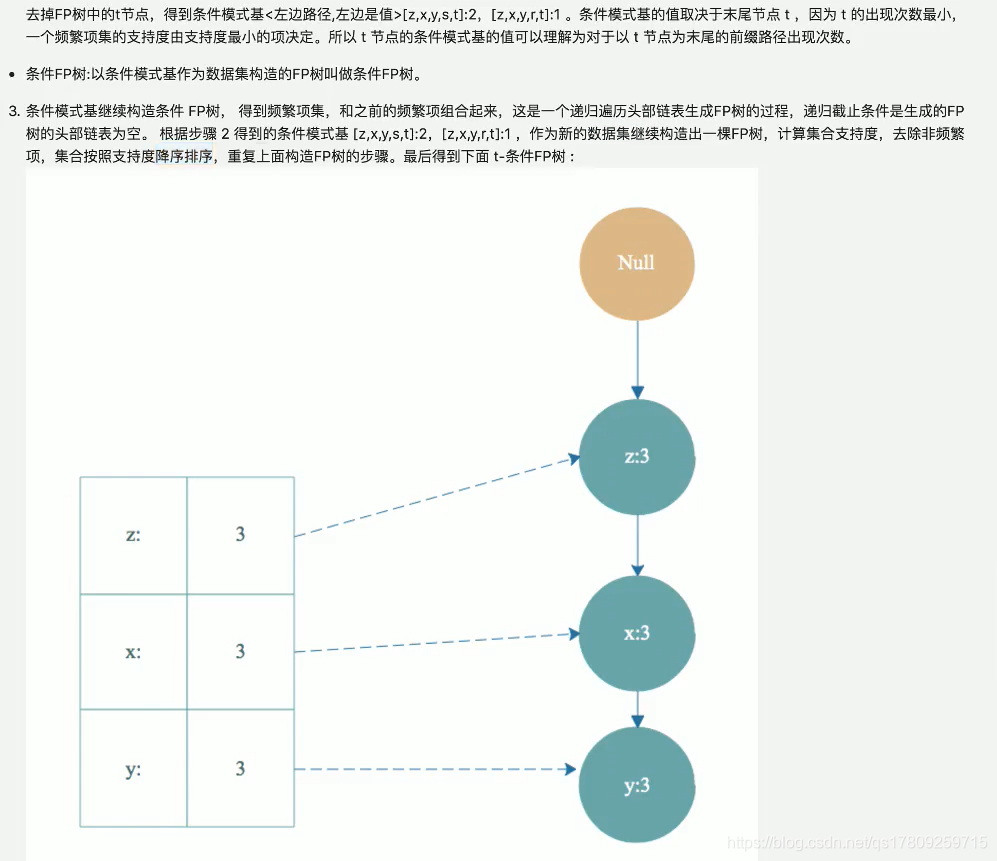
然后根据t-条件FP树的头部链表进行遍历,从y开始。得到频繁项集ty。然后又得到y的条件模式基,构造出ty的条件FP树,即ty-条件FP树。继续遍历ty-条件FP树的头部链表,得到频繁项集tyx,然后又得到频繁项集tyxz. 最后得到构造tyxz条件FP树的头部链表是空的,终止遍历。我们得到的频繁项集有t->ty->tyz->tyzx,这只是-小部分。
五、FP-growth算法总结:
优点:
1.因为FP-growth 算法只需要对数据集遍历两次,所以速度更快。
2. FP树将集合按照支持度降序排序,不同路径如果有相同前缀路径共用存储空间,使得数据得到了压缩。
3.不同于Apriori算法,不需要生成候选集。比Apriori更快。
缺点:
1.FP-Tree第二次遍历会存储很多中间过程的值,会占用很多内存。
2.构建FP-Tree是比较昂贵的。
适用数据类型:标称型数据(离散型数据)。
参考文档:
[1]《机器学习实战》Peter Harrington著
[2] https://blog.csdn.net/huagong_adu/article/details/17739247
[3] https://www.bilibili.com/video/av14852677?from=search&seid=7705461350718549274
[4] https://www.bilibili.com/video/av40754697?from=search&seid=7705461350718549274

