
- 1城市桥梁健康监测系统,高精度自动识别病害
- 2MySQL遍历select语句的查询结果_sql遍历查询结果
- 3uniapp——授权报错,选择合适的基础库
- 4java中String对+的重载_java +号重载
- 5网络安全之反弹Shell_反弹shell事件上报
- 6爱课程第四周c语言测试答案,c语言习题含答案 爱课程mooc.pdf
- 7TCP常见的一些面试题目小结_同意连接请求(syn-ack)并建立物理连接的函数是
- 8机器学习基础:六种方法帮你解决模型过拟合问题_在大模型训练中,哪些方法通常用于过拟合
- 9Android六大网络框架_安卓密集上传大量数据的网络框架都有哪些
- 10软件行业工作一年的感悟_加入软件团队一年感想
Mobile Video Object Detection with Temporally-Aware Feature Maps 论文笔记+代码阅读_bottleneck-lstmlayer: 将 lstm 串联到图像检测框架中,实现作为级信息的视频
赞
踩
论文连接:https://arxiv.org/abs/1711.06368
代码连接:https://github.com/vikrant7/mobile-vod-bottleneck-lstm
论文笔记
1 Summary
本文介绍了一种在GPU上实时运行的视频对象检测online model。我们的方法将快速的单图像目标检测与卷积长短时记忆(LSTM)层相结合,创建一个 recurrent-convolutional 架构。此外,我们提出了一个有效的bottleneck-LSTM层,与常规的LSTM相比,它显著降低了计算成本。我们的网络通过使用bottleneck-LSTM来改进和传播跨帧的特征图,从而实现时间感知。
总结
- recurrent-convolutional 架构:将LSTM 与SSD结合,利用时间上下文。
- bottleneck-LSTM层:基于卷积LSTM层进行改进,在计算门之前减少输入feature map的Channel,从而减少计算
- CPU上运行:将卷积换为深度可分离卷积,来减少计算。
2 Model
2.1 Joint LSTM-SSD Model
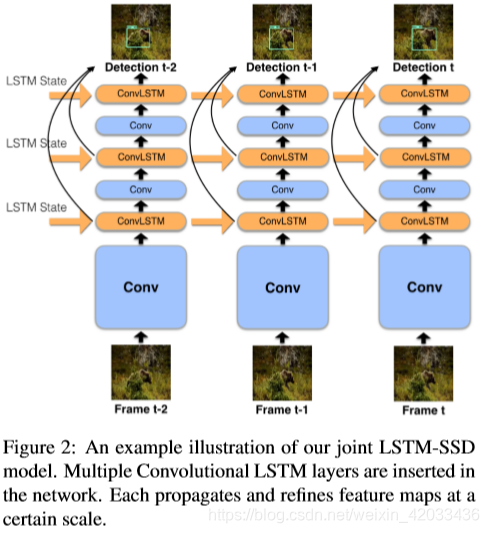
上图描述了我们的完整模型在处理视频时的输入和输出。在实践中,LSTM层的输入和输出可以有不同的维数,但是只要每个子网络的第一卷积层的输入维数修改了,就可以执行相同的计算。
在网络中插入多个卷积LSTM层。每个都在一定的尺度上传播和细化feature map。
LSTMs需要在一个前向通道中计算多个门,这在以效率为中心的网络中是一个问题。为了解决这个问题,对LSTMs进行改变,使其更适合实时移动对象检测的任务。
2.2 Width Multiplier
MobileNet V1中除了使用了深度可分离卷积之外,还引入了宽度乘数和分辨率乘数。本文把 Width Multiplier 引入网络里。
宽度乘数 α \alpha α:即将输出channel M M M 与宽度乘数相乘,变成 α M \alpha M αM
分辨率乘数 ρ \rho ρ:通过改变分辨率的大小,隐式的设置 ρ \rho ρ
首先,我们讨论LSTM的Channel维数。我们可以通过Channel宽度乘数α,更好的控制网络体系结构。原始的宽度乘法器是一个超参数,用于缩放每一层的通道尺寸。我们引入三个新参数 α b a s e \alpha_{base} αbase、 α s s d \alpha_{ssd} αssd、 α l s t m \alpha_{lstm} αlstm控制网络的不同部分的通道尺寸。
本文网络,使用 α b a s e = α \alpha_{base}=\alpha αbase=α、 α s s d = 0.5 α \alpha_{ssd}=0.5\alpha αssd=0.5α、 α l s t m = 0.25 α \alpha_{lstm}=0.25\alpha αlstm=0.25α。每个LSTM的输出是输入大小的四分之一,这大大减少了所需的计算
2.3 Efficient Bottleneck-LSTM Layers
论文根据标准卷积 LSTM 提出 Bottleneck-LSTM
b
t
=
ϕ
(
(
M
+
N
)
W
b
M
⋆
[
x
t
,
h
t
−
1
]
)
f
t
=
σ
(
(
M
+
N
)
W
f
N
⋆
[
x
t
,
h
t
−
1
]
)
i
t
=
σ
(
(
M
+
N
)
W
i
N
⋆
[
x
t
,
h
t
−
1
]
)
o
t
=
σ
(
(
M
+
N
)
W
o
N
⋆
[
x
t
,
h
t
−
1
]
)
c
t
=
f
t
∘
c
t
−
1
+
i
t
∘
ϕ
(
(
M
+
N
)
W
c
N
⋆
[
x
t
,
h
t
−
1
]
)
h
t
=
o
t
∘
ϕ
(
c
t
)
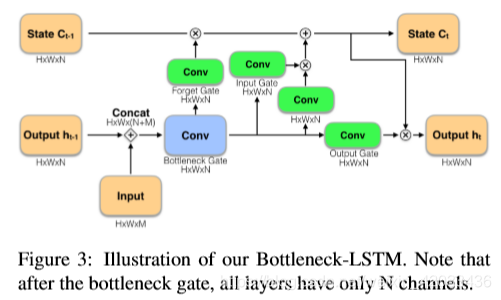
对于Bottleneck-LSTM层, x t x_t xt和 h t − 1 h_{t-1} ht−1作为输入,并按通道连接它们。它输出一个特征映射 h t h_{t} ht和细胞状态 c t c_{t} ct。
j W k ⋆ X ^{j} W^{k} \star X jWk⋆X表示一个深度可分离卷积,权值参数为 W W W,输入Channel为 k k k,输出Channel为 j j j。 ⋆ \star ⋆表示卷积, ∘ \circ ∘表示 Hadamard product (点乘), ϕ \phi ϕ表示激活函数。
b t b_{t} bt是 Bottleneck Gate,它的输出 feature map 是所有门的输入,经过该门后 Channel 由 M + N M+N M+N变为 N N N。
与标准卷积LSTM相比,Bottleneck LSTM进行了两处改变:一、增加了Bottleneck Gate。二、把激活函数改成ReLU
增加了Bottleneck Gate 的好处有两点:
对于Bottleneck-LSTM层,
x
t
x_t
xt和
h
t
−
1
h_{t-1}
ht−1作为输入,并按通道连接它们。它输出一个特征映射
h
t
h_{t}
ht和细胞状态
c
t
c_{t}
ct。
j W k ⋆ X ^{j} W^{k} \star X jWk⋆X表示一个深度可分离卷积,权值参数为 W W W,输入Channel为 k k k,输出Channel为 j j j。 ⋆ \star ⋆表示卷积, ∘ \circ ∘表示 Hadamard product (点乘), ϕ \phi ϕ表示激活函数。
b t b_{t} bt是 Bottleneck Gate,它的输出 feature map 是所有门的输入,经过该门后 Channel 由 M + N M+N M+N变为 N N N。
与标准卷积LSTM相比,Bottleneck LSTM进行了两处改变:一、增加了Bottleneck Gate。二、把激活函数改成ReLU
增加了Bottleneck Gate 的好处有两点:
首先减少了门的计算量,性能优于在所有实际的场景中标准的LSTMs。
其次,瓶颈 - LSTM比标准LSTM更深,这是基于经验证据得出的结论,即更深层次的模型优于宽层次和浅层次的模型。
使用ReLU激活函数的原因:
不改变feature map的边界是很重要的,因为我们的LSTMs分布在卷积层中。
2.3 带有single-LSTM的LSTM-SSD

在我们的一个LSTM- SSD架构中使用一个具有256通道状态的LSTM的卷积层。“dw”表示深度卷积。最后的bounding boxes是通过对瓶颈- LSTM和Feature Map层应用额外的卷积得到的。
放置LSTM有几个方案:
- 在Conv13层之后放置一个LSTM。
- 在Conv13层之后堆叠多个LSTMs。
- 在每个Feature Map之后放置一个LSTM
3 实验
我们在Imagenet VID 2015数据集上进行训练和评估。对于训练,我们使用了Imagenet VID trainingset中的全部3862个视频。我们将LSTM展开为10步,并按10帧的顺序进行训练。在训练中,我们使用RMSprop和异步梯度下降。
我们呈现的结果模型宽度乘数分别为
α
=
1
\alpha=1
α=1和
α
=
0.5
\alpha=0.5
α=0.5。
α
=
1
\alpha=1
α=1模型中,我们使用一个输入分辨率为
320
×
320
320\times320
320×320,学习率为0.003。对于
α
=
0.5
\alpha=0.5
α=0.5模型,设置分辨路为
256
×
256
256\times256
256×256和学习速率为0.002。
我们调整了原来的hard negative挖掘方法,允许每10个negative例子对应一个positive,同时将每个negative loss乘以0.3。通过这种修改,我们获得了明显更好的准确性,这可能是因为原来的方法严厉地惩罚了groundtruth标签中的 false negative。
为了解决过拟合问题,我们使用一个两阶段的过程来训练网络。首先,我们对没有LSTMs的SSD网络进行了优化,然后我们冻结了Conv 13及其之前的权重参数,在剩下的训练中注入LSTM层。
对于评估,在Imagenet VID评估集中从每个视频中选择连续20帧,总共11080帧。我们把这些帧称为 minival set。对于所有结果,我们采用标准的 Imagenet VID 精度度量,即平均精度@0.5 IOU。我们还对效率进行比较,通过计算参数数量和 MAC (multiply-adds,即一次乘法和一次加法 )
3.1 消融实验
1、首先讨论单个LSTM的放置位置 
我们在模型的各个层之后放置一个LSTM。表2证实了在特征映射之后放置LSTM可以获得更好的性能,而Conv13层提供了最大的改进,从而验证了我们的观点,即在特征空间中添加时间感知是有益的。
2、接下来,我们将我们提出的LSTM瓶颈与其他递归层类型(包括averaing、LSTM层和GRUs层)进行比较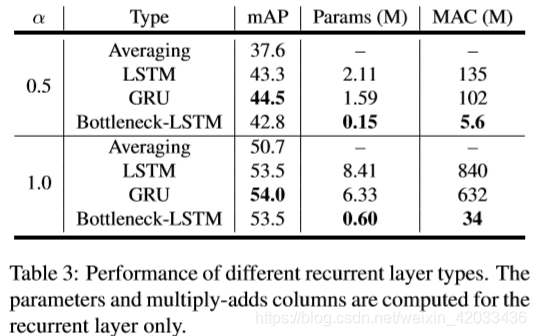
对于这个实验,我们把一个RNN Layer放在Conv13层后并评估我们的α= 1和α= 0.5模型。对于 baseline,我们在连续帧中使用特征的加权平均,当前帧权重为0.75,前一帧权重为0.25。LSTM的输出 Channel 根据扩展的 width 乘法器进行了缩减,但其他所有递归层类型的输入和输出维数都是相同的,因为它们不是为瓶颈而设计的。结果如表3所示。我们的瓶颈- lstm比其他递归层的效率要高一个数量级,同时达到了可比较的性能。
3、Bottleneck 输出通道
我们进一步分析了LSTM输出通道尺寸对精度的影响,如图4所示。在每个实验中,Conv13层之后都有一个单一的瓶颈—lstm。精度仍然接近常数
α
l
s
t
m
=
0.25
α
\alpha_{lstm}=0.25\alpha
αlstm=0.25α,然后下降。这支持我们使用的扩展宽度乘数。
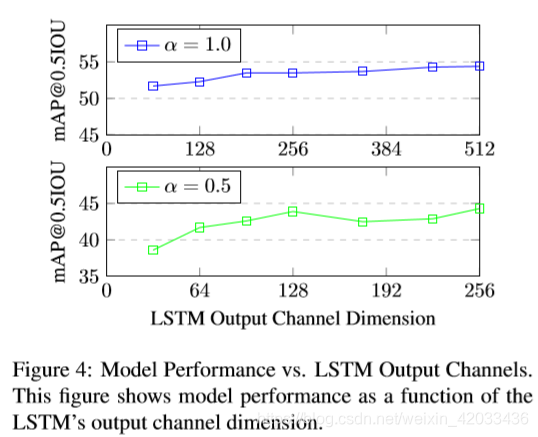
4、多个LSTM放置策略
我们的框架可以自然地扩展到多个LSTM。在ssd中,每个feature map代表一定范围内的特征。我们研究了合并多个LSTMs以在不同尺度上细化特征映射的好处。在下表中我们评估了合并多个LSTMs的不同策略。
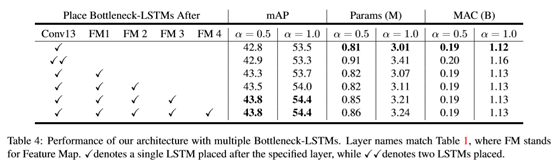
在这个实验中,我们逐步地向网络中添加更多的LSTM层。由于同时训练多个LSTMs存在困难,我们从以前的检查点进行微调,同时逐步增加层。在不同尺度的特征映射之后放置LSTMs,由于后续的特征映射的维数很小,并且我们的LSTMs layers的效率很高,所以在性能上有了轻微的改进,并且在计算成本上几乎没有变化。
然而,在同一个feature map后堆叠两个LSTM是没有好处的。在FM3和FM4这两种feature map中,我们没有进一步限制LSTM输出通道,因为通道尺寸已经非常小了。
我们使用在所有特征映射之后放置LSTMs的模型作为最终模型。
3.2 与其他框架比较
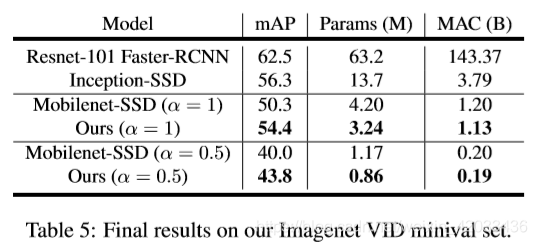
所有Baseline都使用开源的Tensorflow对象检测API[18]进行训练。在这些方法中,只有Mobilenet SSD变体和我们的方法可以在移动设备上实时运行,我们的方法在所有指标上都优于Mobilenet-SSD。
3.3 鲁棒性实验
我们通过在每个视频中创建人工遮挡来测试我们的方法对输入噪声的鲁棒性。我们生成这些遮挡如下:对于每个groundtruth bounding box,我们分配一个遮挡bounding box的概率
p
p
p。
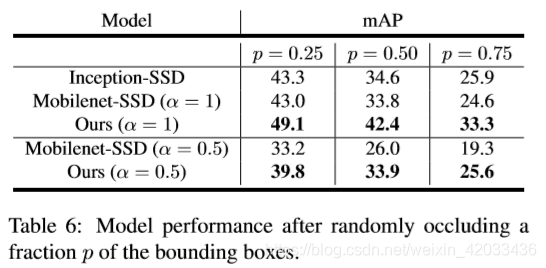
对于尺寸为
H
×
W
H\times W
H×W的每个被遮挡的bounding box,我们清除了一个随机选择的大小在
H
2
×
W
2
\frac{H}{2} \times \frac{W}{2}
2H×2W和
3
H
4
×
3
W
4
\frac{3H}{4} \times \frac{3W}{4}
43H×43W内的矩形区域所有像素包围框。本实验结果见表6。所有的方法都在相同的遮挡上进行评估,而在测试前没有对这些遮挡进行任何方法的训练。我们的方法在噪声数据上的表现优于所有单帧SSD方法,表明我们的网络学习了视频的时间连续性,并利用时间线索实现了对噪声的鲁棒性。
3.4 Mobile Runtime

我们用高通骁龙835在最新的Pixel2手机上对我们的模型进行基线评估。运行时在Snapdragon 835大核和小核上测量,使用Tensorflow[1]的自定义设备实现进行单线程推理。表7显示了我们的模型优于所有基线。值得注意的是,我们的α= 0.5模型在大核上实现实时的速度15 FPS(每秒传输帧数(Frames Per Second))。
代码阅读
本文展现的是带有single-LSTM的LSTM-SSD网络代码
基本卷积
def SeperableConv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0): """Replace Conv2d with a depthwise Conv2d and Pointwise Conv2d. Arguments: in_channels : number of channels of input out_channels : number of channels of output kernel_size : kernel size for depthwise convolution stride : stride for depthwise convolution padding : padding for depthwise convolution Returns: object of class torch.nn.Sequential """ return nn.Sequential( nn.Conv2d(in_channels=int(in_channels), out_channels=int(in_channels), kernel_size=kernel_size, groups=int(in_channels), stride=stride, padding=padding), nn.ReLU6(), nn.Conv2d(in_channels=int(in_channels), out_channels=int(out_channels), kernel_size=1), )

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
def conv_bn(inp, oup, stride):
"""3x3 conv with batchnorm and relu
Arguments:
inp : number of channels of input
oup : number of channels of output
stride : stride for depthwise convolution
Returns:
object of class torch.nn.Sequential
"""
return nn.Sequential(
nn.Conv2d(int(inp), int(oup), 3, stride, 1, bias=False),
nn.BatchNorm2d(int(oup)),
nn.ReLU6(inplace=True)
)- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
def conv_dw(inp, oup, stride): """Replace Conv2d with a depthwise Conv2d and Pointwise Conv2d having batchnorm and relu layers in between. Here kernel size is fixed at 3. Arguments: inp : number of channels of input oup : number of channels of output stride : stride for depthwise convolution Returns: object of class torch.nn.Sequential """ return nn.Sequential( nn.Conv2d(int(inp), int(inp), 3, stride, 1, groups=int(inp), bias=False), nn.BatchNorm2d(int(inp)), nn.ReLU6(inplace=True), nn.Conv2d(int(inp), int(oup), 1, 1, 0, bias=False), nn.BatchNorm2d(int(oup)), nn.ReLU6(inplace=True), )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
Bottleneck LSTM层
class BottleneckLSTMCell(nn.Module): """ Creates a LSTM layer cell Arguments: input_channels : variable used to contain value of number of channels in input hidden_channels : variable used to contain value of number of channels in the hidden state of LSTM cell """ def __init__(self, input_channels, hidden_channels): super(BottleneckLSTMCell, self).__init__() assert hidden_channels % 2 == 0 self.input_channels = int(input_channels) self.hidden_channels = int(hidden_channels) self.num_features = 4 self.W = nn.Conv2d(in_channels=self.input_channels, out_channels=self.input_channels, kernel_size=3, groups=self.input_channels, stride=1, padding=1) self.Wy = nn.Conv2d(int(self.input_channels+self.hidden_channels), self.hidden_channels, kernel_size=1) self.Wi = nn.Conv2d(self.hidden_channels, self.hidden_channels, 3, 1, 1, groups=self.hidden_channels, bias=False) self.Wbi = nn.Conv2d(self.hidden_channels, self.hidden_channels, 1, 1, 0, bias=False) self.Wbf = nn.Conv2d(self.hidden_channels, self.hidden_channels, 1, 1, 0, bias=False) self.Wbc = nn.Conv2d(self.hidden_channels, self.hidden_channels, 1, 1, 0, bias=False) self.Wbo = nn.Conv2d(self.hidden_channels, self.hidden_channels, 1, 1, 0, bias=False) self.relu = nn.ReLU6() # self.Wci = None # self.Wcf = None # self.Wco = None logging.info("Initializing weights of lstm") self._initialize_weights() def _initialize_weights(self): """ Returns: initialized weights of the model """ for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.xavier_uniform_(m.weight) if m.bias is not None: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def forward(self, x, h, c): #implemented as mentioned in paper here the only difference is Wbi, Wbf, Wbc & Wbo are commuted all together in paper """ Arguments: x : input tensor h : hidden state tensor c : cell state tensor Returns: output tensor after LSTM cell """ x = self.W(x) y = torch.cat((x, h),1) #concatenate input and hidden layers i = self.Wy(y) #reduce to hidden layer size b = self.Wi(i) #depth wise 3*3 ci = torch.sigmoid(self.Wbi(b)) cf = torch.sigmoid(self.Wbf(b)) cc = cf * c + ci * self.relu(self.Wbc(b)) co = torch.sigmoid(self.Wbo(b)) ch = co * self.relu(cc) return ch, cc def init_hidden(self, batch_size, hidden, shape): """ Arguments: batch_size : an int variable having value of batch size while training hidden : an int variable having value of number of channels in hidden state shape : an array containing shape of the hidden and cell state Returns: cell state and hidden state """ # if self.Wci is None: # self.Wci = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda() # self.Wcf = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda() # self.Wco = Variable(torch.zeros(1, hidden, shape[0], shape[1])).cuda() # else: # assert shape[0] == self.Wci.size()[2], 'Input Height Mismatched!' # assert shape[1] == self.Wci.size()[3], 'Input Width Mismatched!' return (Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda(), Variable(torch.zeros(batch_size, hidden, shape[0], shape[1])).cuda() )
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
class BottleneckLSTM(nn.Module): def __init__(self, input_channels, hidden_channels, height, width, batch_size): """ Creates Bottleneck LSTM layer Arguments: input_channels : variable having value of number of channels of input to this layer hidden_channels : variable having value of number of channels of hidden state of this layer height : an int variable having value of height of the input width : an int variable having value of width of the input batch_size : an int variable having value of batch_size of the input Returns: Output tensor of LSTM layer """ super(BottleneckLSTM, self).__init__() self.input_channels = int(input_channels) self.hidden_channels = int(hidden_channels) self.cell = BottleneckLSTMCell(self.input_channels, self.hidden_channels) (h, c) = self.cell.init_hidden(batch_size, hidden=self.hidden_channels, shape=(height, width)) self.hidden_state = h self.cell_state = c def forward(self, input): new_h, new_c = self.cell(input, self.hidden_state, self.cell_state) self.hidden_state = new_h self.cell_state = new_c return self.hidden_state
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
整体框架
MobileNetV1
class MobileNetV1(nn.Module): def __init__(self, num_classes=1024, alpha=1): """torch.nn.module for mobilenetv1 upto conv12 Arguments: num_classes : an int variable having value of total number of classes alpha : a float used as width multiplier for channels of model """ super(MobileNetV1, self).__init__() # upto conv 12 self.model = nn.Sequential( conv_bn(3, 32*alpha, 2), conv_dw(32*alpha, 64*alpha, 1), conv_dw(64*alpha, 128*alpha, 2), conv_dw(128*alpha, 128*alpha, 1), conv_dw(128*alpha, 256*alpha, 2), conv_dw(256*alpha, 256*alpha, 1), conv_dw(256*alpha, 512*alpha, 2), conv_dw(512*alpha, 512*alpha, 1), conv_dw(512*alpha, 512*alpha, 1), conv_dw(512*alpha, 512*alpha, 1), conv_dw(512*alpha, 512*alpha, 1), conv_dw(512*alpha, 512*alpha, 1), ) logging.info("Initializing weights of base net") self._initialize_weights() #self.fc = nn.Linear(1024, num_classes) def _initialize_weights(self): """ Returns: initialized weights of the model """ for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.xavier_uniform_(m.weight) if m.bias is not None: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def forward(self, x): """ Arguments: x : a tensor which is used as input for the model Returns: a tensor which is output of the model """ x = self.model(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
SSD
class SSD(nn.Module): def __init__(self,num_classes, batch_size, alpha = 1, is_test=False, config = None, device = None): """ Arguments: num_classes : an int variable having value of total number of classes batch_size : an int variable having value of batch size alpha : a float used as width multiplier for channels of model is_Test : a bool used to make model ready for testing config : a dict containing all the configuration parameters """ super(SSD, self).__init__() # Decoder self.is_test = is_test self.config = config self.num_classes = num_classes if device: self.device = device else: self.device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu") if is_test: self.config = config self.priors = config.priors.to(self.device) self.conv13 = conv_dw(512*alpha, 1024*alpha, 2) #not using conv14 as mentioned in paper self.bottleneck_lstm1 = BottleneckLSTM(input_channels=1024*alpha, hidden_channels=256*alpha, height=10, width=10, batch_size=batch_size) self.fmaps_1 = nn.Sequential( nn.Conv2d(in_channels=int(256*alpha), out_channels=int(128*alpha), kernel_size=1), nn.ReLU6(inplace=True), SeperableConv2d(in_channels=128*alpha, out_channels=256*alpha, kernel_size=3, stride=2, padding=1), ) self.fmaps_2 = nn.Sequential( nn.Conv2d(in_channels=int(256*alpha), out_channels=int(64*alpha), kernel_size=1), nn.ReLU6(inplace=True), SeperableConv2d(in_channels=64*alpha, out_channels=128*alpha, kernel_size=3, stride=2, padding=1), ) self.fmaps_3 = nn.Sequential( nn.Conv2d(in_channels=int(128*alpha), out_channels=int(64*alpha), kernel_size=1), nn.ReLU6(inplace=True), SeperableConv2d(in_channels=64*alpha, out_channels=128*alpha, kernel_size=3, stride=2, padding=1), ) self.fmaps_4 = nn.Sequential( nn.Conv2d(in_channels=int(128*alpha), out_channels=int(32*alpha), kernel_size=1), nn.ReLU6(inplace=True), SeperableConv2d(in_channels=32*alpha, out_channels=64*alpha, kernel_size=3, stride=2, padding=1), ) self.regression_headers = nn.ModuleList([ SeperableConv2d(in_channels=512*alpha, out_channels=6 * 4, kernel_size=3, padding=1), SeperableConv2d(in_channels=256*alpha, out_channels=6 * 4, kernel_size=3, padding=1), SeperableConv2d(in_channels=256*alpha, out_channels=6 * 4, kernel_size=3, padding=1), SeperableConv2d(in_channels=128*alpha, out_channels=6 * 4, kernel_size=3, padding=1), SeperableConv2d(in_channels=128*alpha, out_channels=6 * 4, kernel_size=3, padding=1), nn.Conv2d(in_channels=int(64*alpha), out_channels=6 * 4, kernel_size=1), ]) def _initialize_weights(self): """ Returns: initialized weights of the model """ for m in self.modules(): if isinstance(m, nn.Conv2d): nn.init.xavier_uniform_(m.weight) if m.bias is not None: m.bias.data.zero_() elif isinstance(m, nn.BatchNorm2d): m.weight.data.fill_(1) m.bias.data.zero_() def compute_header(self, i, x): #ssd method to calculate headers """ Arguments: i : an int used to use particular classification and regression layer x : a tensor used as input to layers Returns: locations and confidences of the predictions """ confidence = self.classification_headers[i](x) confidence = confidence.permute(0, 2, 3, 1).contiguous() confidence = confidence.view(confidence.size(0), -1, self.num_classes) location = self.regression_headers[i](x) location = location.permute(0, 2, 3, 1).contiguous() location = location.view(location.size(0), -1, 4) return confidence, location def forward(self, x): """ Arguments: x : a tensor which is used as input for the model Returns: confidences and locations of predictions made by model during training or confidences and boxes of predictions made by model during testing """ confidences = [] locations = [] header_index=0 confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) x = self.conv13(x) x = self.bottleneck_lstm1(x) confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) x = self.fmaps_1(x) confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) x = self.fmaps_2(x) confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) x = self.fmaps_3(x) confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) x = self.fmaps_4(x) confidence, location = self.compute_header(header_index, x) header_index += 1 confidences.append(confidence) locations.append(location) confidences = torch.cat(confidences, 1) locations = torch.cat(locations, 1) if self.is_test: #while testing convert locations to boxes confidences = F.softmax(confidences, dim=2) boxes = box_utils.convert_locations_to_boxes( locations, self.priors, self.config.center_variance, self.config.size_variance ) boxes = box_utils.center_form_to_corner_form(boxes) return confidences, boxes else: return confidences, locations
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
完整网络
class MobileVOD(nn.Module): """ Module to join encoder and decoder of predictor model """ def __init__(self, pred_enc, pred_dec): """ Arguments: pred_enc : an object of MobilenetV1 class pred_dec : an object of SSD class """ super(MobileVOD, self).__init__() self.pred_encoder = pred_enc self.pred_decoder = pred_dec def forward(self, seq): """ Arguments: seq : a tensor used as input to the model Returns: confidences and locations of predictions made by model """ x = self.pred_encoder(seq) confidences, locations = self.pred_decoder(x) return confidences , locations def detach_hidden(self): """ Detaches hidden state and cell state of all the LSTM layers from the graph """ self.pred_decoder.bottleneck_lstm1.hidden_state.detach_() self.pred_decoder.bottleneck_lstm1.cell_state.detach_()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
补充
SSD参考笔记
https://blog.csdn.net/thisiszdy/article/details/89576389
LSTM笔记
通俗理解:https://www.jianshu.com/p/95d5c461924c
Conv LSTM:https://zhuanlan.zhihu.com/p/63254556
循环神经网络(Recurrent Neural Networks)
在对序列信息(如语音)进行预测时,传统的神经网络很难通过利用前面的事件信息来对后面事件进行分类。而循环神经网络(下面简称RNNs)可以通过不停的将信息循环操作,保证信息持续存在,从而解决上述问题。
RNNs理论上是可以将以前的信息与当前的任务进行连接,例如使用以前的视频帧来帮助网络理解当前帧。如果RNNs能做到这一点,那将会是非常的有用。但是他们能做到这点吗?答案是不一定。
当有用信息与需要进行处理信息的地方之间的距离较远,这样容易导致RNNs不能学习到有用的信息,最终推导的任务可能失败。
理论上RNNs是能够处理这种“长依赖”问题的。通过调参来解决这种问题。但是在实践过程中RNNs无法学习到这种特征。Hochreiter (1991) [German] 和Bengio, et al. (1994)深入研究过为什么RNNs没法学习到这种特征。
Lukily,这种"长依赖"问题可以通过LSTM——一种特殊的RNNs解决。
Long Short Term Memory networks(简称LSTMs)
LSTMs的核心是细胞状态 C t C_t Ct,用贯穿细胞的水平线表示。细胞状态像传送带一样。它贯穿整个细胞却只有很少的分支,这样能保证信息不变的流过整个RNNs。
LSTM网络能通过一种被称为门的结构对细胞状态进行删除或者添加信息。
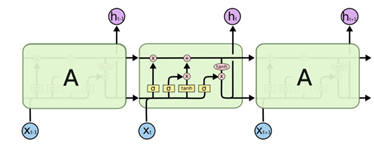
实际上
C
t
C_t
Ct的更新是通过:
C
~
t
=
tanh
(
W
C
⋅
[
h
t
−
1
,
x
t
]
+
b
C
)
\tilde{C}_{t}=\tanh \left(W_{C} \cdot\left[h_{t-1}, x_{t}\right]+b_{C}\right)
C~t=tanh(WC⋅[ht−1,xt]+bC)
C
t
=
f
t
∗
C
t
−
1
+
i
t
∗
C
~
t
C_{t}=f_{t} * C_{t-1}+i_{t} * \tilde{C}_{t}
Ct=ft∗Ct−1+it∗C~t
直观上来看,
C
t
C_t
Ct包含当前输入的信息,之前输入的信息,以及之前输出的信息。
总结
- RNNs经常用来处理序列数据。LSTMs适用于大部分的序列场景应用。
- LSTM的提出是用来解决“长依赖”问题的。
- 其实,attention思想也很有用,attention的思想是让RNN在每一步挑选信息的时候都能从更大的信息集里面挑选出有用信息。
问题
- 对 online model 的训练过程不太了解
- 对正负样本的形成不太了解

