
热门标签
当前位置: article > 正文
推荐系统经典模型YouTubeDNN
作者:weixin_40725706 | 2024-04-27 03:30:29
赞
踩
推荐系统经典模型YouTubeDNN
YouTubeDNN概念
- YouTubeDNN是YouTube用于做视频推荐的落地模型,其大体思路就是召回阶段使用多个简单的模型来进行筛选,这样可以大量地筛除相关度较低的内容,而排序阶段则是使用相对复杂的模型来获得精准的推荐结果。YouTubeDNN模型主要分为两个阶段:召回阶段和排序阶段。
- YouTubeDNN模型的召回主要是完成候选视频的快速筛选(在论文中被称为 Candidate Generation Model),也就是候选集的生成模型。在这一部分中,模型要做的就是将整个YouTube数据库中的视频数量由百万级别降到数百级别。
- 为什么要使用YouTubeDNN模型?
- 答:传统的协同过滤算法处理百万级数据量,很明显是不够的,因为CF算法的本质就是计算两两内容之间的关系矩阵,然后将结果保存在内存当中,当然随着数据量的增大,就会很容易地出现OOM的现象。假设有个无限大的内存的分布式计算系统(Spark等),对于百万级矩阵计算处理时所耗费的时间,也不是我们想看到的结果。而YouTubeDNN则利用了Embedding向量加上对负样本的特殊采样处理,巧妙地解决了这一问题。
YouTubeDNN模型架构图
- YouTube推荐系统架构图
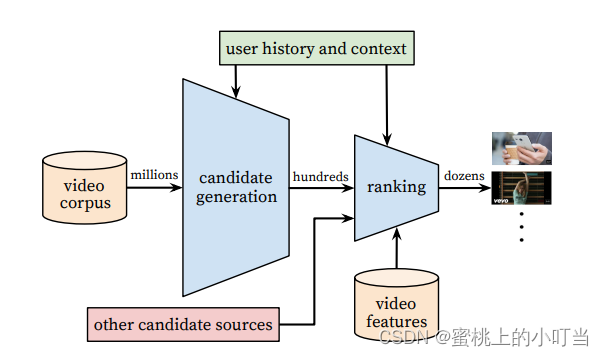
- 从论文的解释中我们可以得知这个架构就像是一个沙漏(funnel)一样,从最初的百万级→数百级→十级别。
YouTubeDNN召回阶段
- YouTubeDNN召回模型架构图
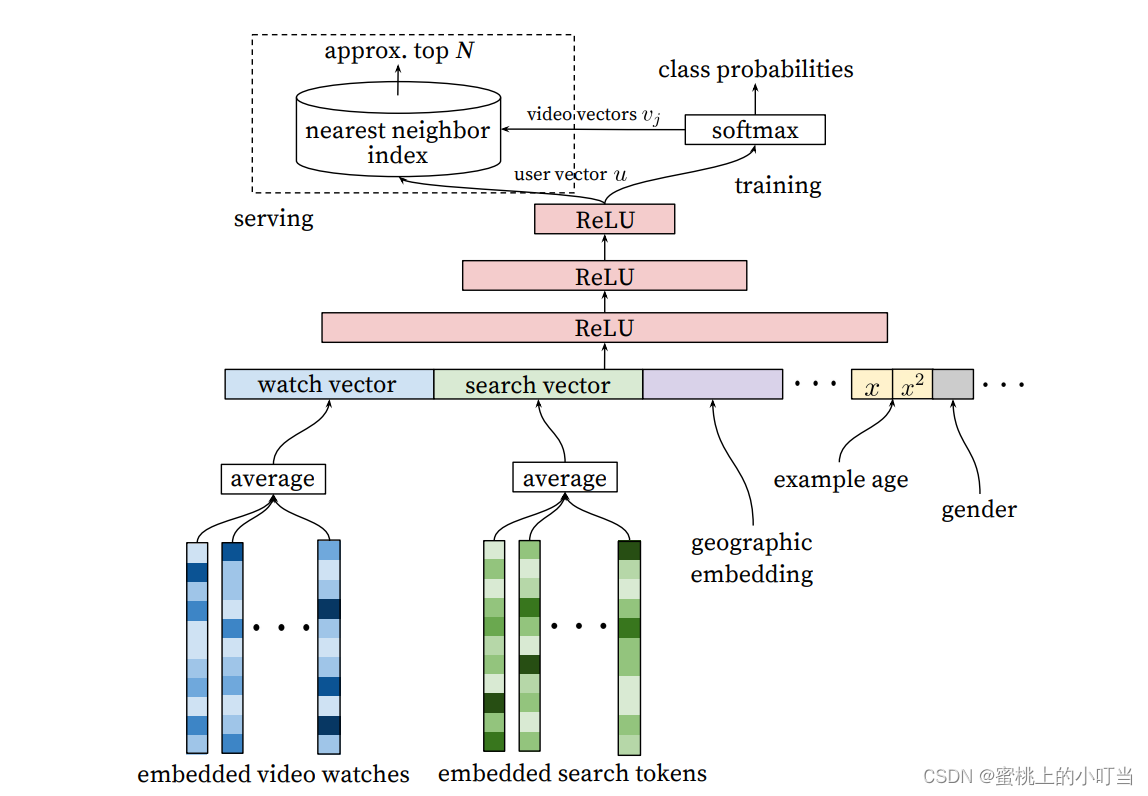
YouTubeDNN层级介绍
- 我们可以把召回模型的结构分为三层。
-
输入层:输入层总共有四种特征。
- 用户看过视频的 Embedding(embedded video watches)
- 用户搜索的关键词的 Embedding 向量(embedded search tokens)
- 用户所在的地理位置的特征(geographic embedding)适用于冷启动
- 用户基本特征(example age, gender)
- 在处理观看的视频序列和搜索词时需要格外注意,每一个人所观看的内容的数量、长度一定不同、所搜索的关键词也一定不同,所产生出来的Embedding也会千差万别,所以就需要用多值特征和平均池化进行处理。由于每个人的序列长度不同,我们在进行训练时就需要将多值特征中的每一个视频ID经过Embedding Lookup(通过矩阵相乘类似于一个全连接层)操作后,得到其对应的Embedding向量,然后再经过平均池化处理,最后得到这个多值特征所对应的Embedding特征。
- 最后将处理完的特征拼接成一个大的Embedding输入给模型。
-
三层神经网络(训练层):这一层也就是模型训练层,这里采用了三层ReLU结构,实际上在YouTubeDNN中,这三层ReLU的作用就是接收输入层特征的CONCAT,然后使用常见的塔形设计,对自底向上的每一层神经元数目作减半处理,直到得到的输出维度与Softmax所要求的输入维度相同(256维)。也就是1024→512→256。
-
Softmax层(输出层):在经过三层ReLU之后,召回层使用Softmax作为输出层。我们知道,传入Softmax层的参数是用户的Embedding向量,而这里的用户的 Embedding并不是在输入层里面的用户Embedding,而是经过实时计算得到的,也就是最后一层ReLU的输出。
- Softmax层最终的输出并不是点击率的预估,而是预测用户最终会点击哪个视频。首先看右侧的Softmax部分,这一部分实际上是把上一步ReLU输出的user u接到了Softmax 层,得到其概率分布。
- YouTubeDNN把每一个视频当做一个类别,这里的Softmax可以理解为每一个视频进行了一个概率上的打分。从论文的角度来说,就是将user u和video v进行内积(这个内积实际上就是求其相似度然后再进行 Softmax),这样就可以得到用户观看每个视频的概率,也就是上面这张图中所展示的class probabilities。Softmax右侧部分也就是一个离线的Training(主要是加快线上预测效率)当得到右侧最终的用户向量之后,为了与离线的训练保持一致,需要对每个video进行内积计算,然后得到概率Top N个结果作为输出。
- Softmax最左边是一个nearest neighbor index,这个部分就是核心所在。这里YouTubeDNN采用最临近搜索的方法去完成topN的推荐,通过召回模型得到user u和video v做内积,然后再用最临近搜索来得到最后的 topN,这样的效率实际上是最高的。
- Softmax层概率公式:基于用户U与上下文C,在t时刻,将视频库V中指定的视频wt划分为第i类的概率
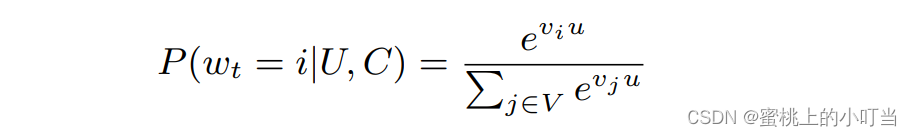
-
YouTubeDNN排序阶段
- YouTubeDNN排序模型架构图
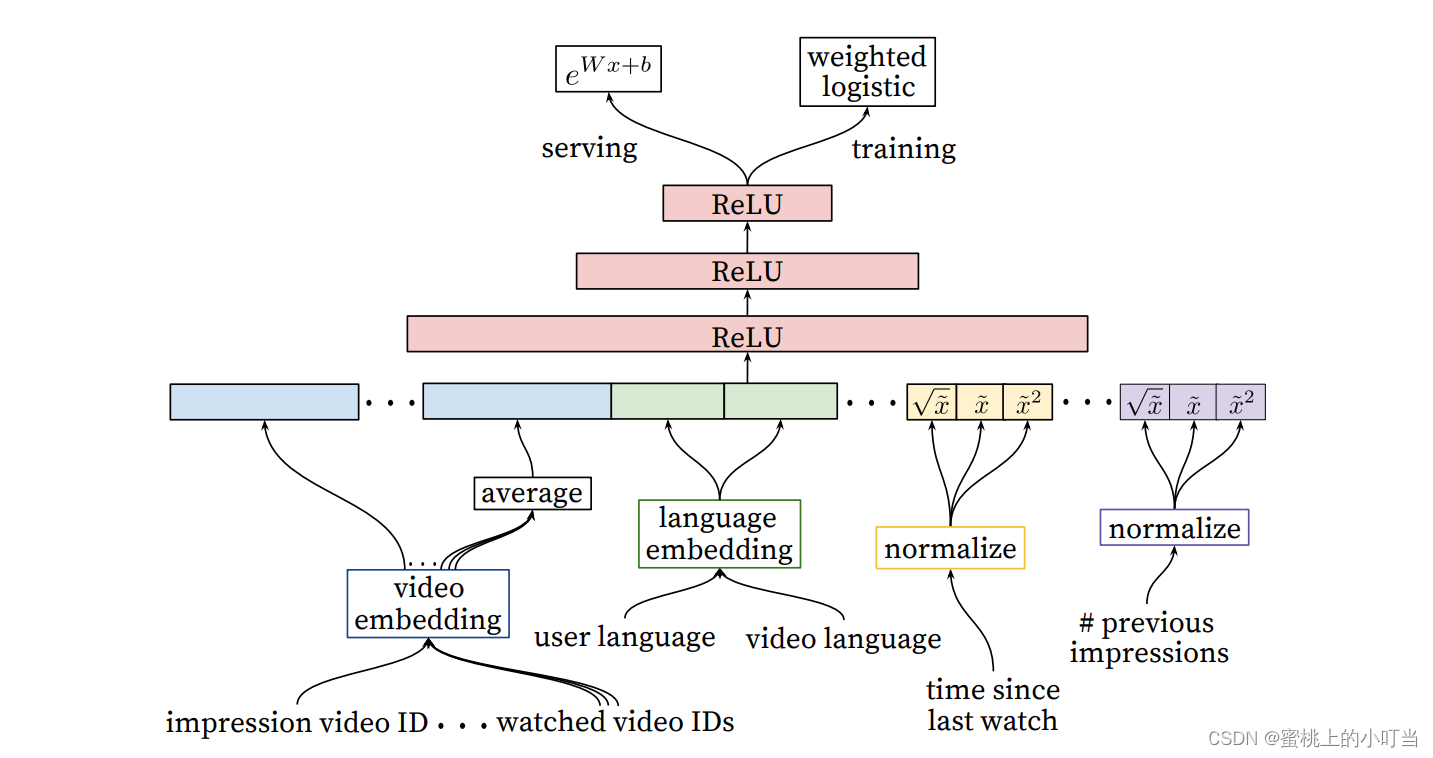
- YouTubeDNN排序阶段模型图与召回层模型相似,排序模型面对的只是来自检索的数百候选视频,所以可以使用更多精细的特征,重点是精准预测。论文中已特征工程的角度对各个视视频特征进行了embedding处理,然后再进行ReLU层,最终通过加权LR进行Training,在线上Serving部分使用了e^(wx+b)进行预测。
- 论文中将特征分成了两类一类是impression一类是query。
- video embedding包含impression video ID(展示视频)、watched video ID(用户已观看视频后续还需要进行avg-pooling处理)。
- language embedding包含:user language(用户语言)和video language(视频语言)。
- time since last watch(自上次观看同channel视频的时间)进行归一化处理,刚看过这个channel的视频,还会继续曝光该channel的其他视频
- previous impressions(该视频已经被曝光给该用户的次数)进行归一化处理,主要是防止无效曝光。
- 这里就简单介绍一下排序模型的架构,因为排序模型更改迭代速度实在是太快了。本章主要是还是从召回模型做思考。
YoutubeDNN模型中的一些Trick
负采样问题
- YouTubeDNN采用了负采样,训练样本来自全部观看记录,观看记录包括用户被推荐的内容,再加上用户自己搜索或者在其他地方点击的内容,这样做的好处是可以使新的视频也能够有比较好的曝光。
- 把用户看完的内容作为正样本,再从视频库里随机选取一些样本作为负样本。没有曝光过的内容理论上有可能被点击过,但是这里把它们全都变成了负样本,这样就有了一定的随机性。
- 在采样时,训练数据中对每个用户选取相同的样本数。这样做的目的是保证用户在损失函数的权重是相等的,这样可以尽可能地减少高度活跃的用户对整个推荐结果的Loss的影响。
- 为什么加入负采样的目的是提高训练的速度?
- 对于每一个样本来说,所有视频来说都有可能是正样本,YouTubeDNN Softmax实际上对每个视频都计算出一个概率,如果不做负采样,则会形成一个数以万计的分类,显然增加了训练难度,所以作者这里正常提取正样本,把负样本从视频库中根据重要性进行抽样,这样可以缓解训练压力,提升整体效率。
特征构造
-
对于一些简单的特征(用户性别、年龄)没有经过特殊的处理,直接输入,然后做一层归一化后,把最终的结果压缩到[0, 1]范围内。
-
对于用户观看的视频(video)在模型中并没有取视频的特征,只是简单将视频ID 作为特征传入进来,然后利用DNN来自动学习商品的Embedding特征。
-
因为用户更偏向于喜欢观看最新的视频,而随着时间的增长喜爱程度会下降,为了修复此问题,引入了召回模型中的example age特征。
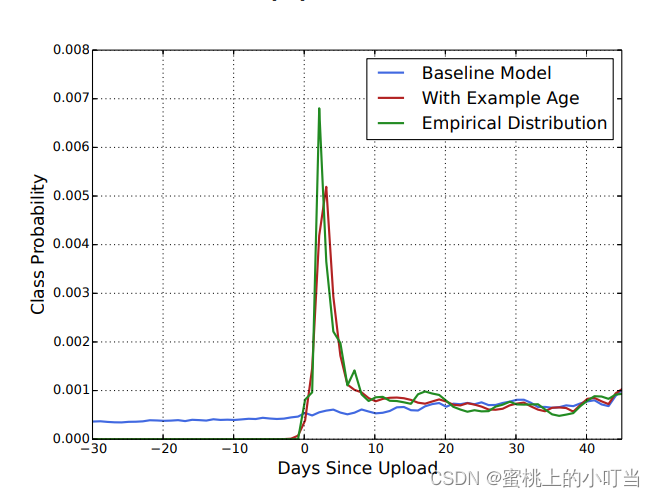
-
历史信息是一个边长的视频ID序列,根据ID序列和Embedding视频矩阵来获取用户历史观看的Embedding向量序列,通过weighted、avg、attention等方法,将这个 Embedding序列映射成一个定长的Watch Vector,作为输入层的一部分。
上下文选择
- 在上下文和标签的选择中,主要利用了序列的方法。用户每次进入YouTube一直到退出都有一定的序列,而这个序列一开始会选择范围比较广的视频进行浏览,然后再慢慢地专注到一个比较小的范围内。类似于冷启动里的EE问题,先探索再开采。这种浏览行为实际上就是一种不对称的浏览行为。因此,作者从观看序列中随机抽取一个视频作为Label,这样就忽略了这种不对称性所产生的影响,如下图所示:
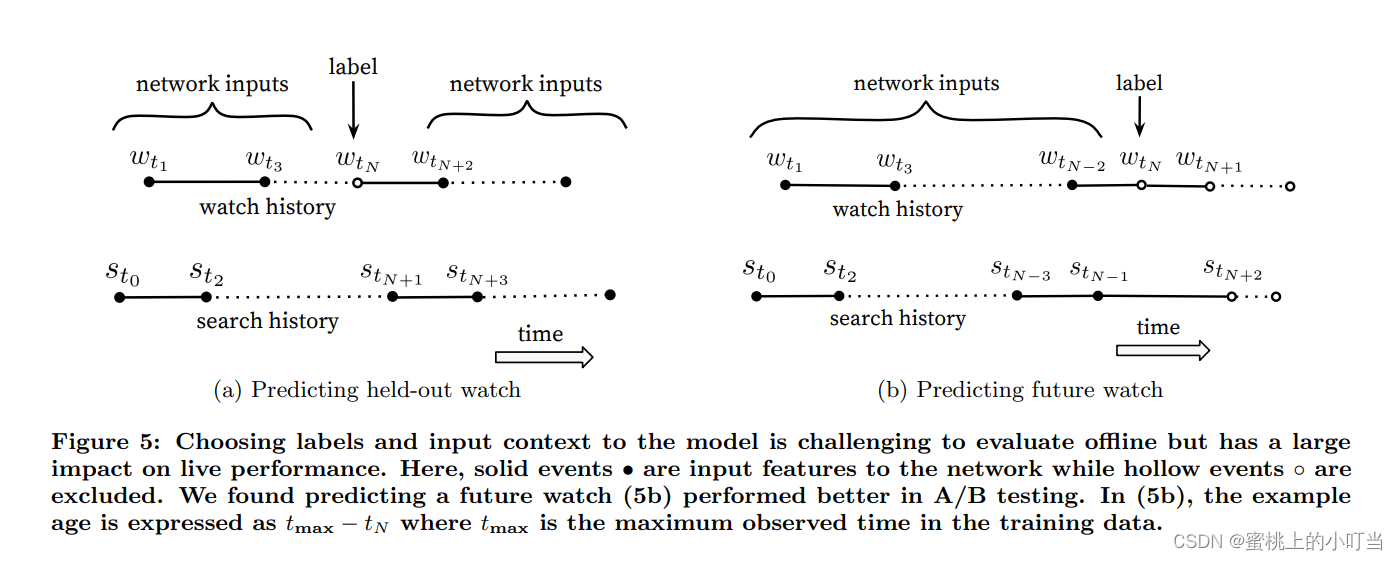
- 上图是一个对比实验,很多算法都是采用左边的方法,利用全局观看的信息作为输入,这样就忽略了观看序列的不对称性。而YouTubeDNN则是使用右边的方法,就是把历史信息当做输入,用历史来预测未来。这样做的优点就是模型的测试集往往也是用户最近一次的观看行为,后面可以把用户最后一次的点击放到测试集中,防止信息穿越的问题,在线上AB测试方面表现更佳。
总结
- 这些内容对于初学推荐系统的小伙伴还是比较有帮助的,具体一些细节还是得在论文中查看,这里老规矩放上论文链接,关于代码方面,会在后面更新。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/494544
推荐阅读
相关标签

