【学习】深度强化学习
赞
踩
一、深度强化学习Deep Reinforcement Learning (RL)
什么是RL?(三步骤)
在一些任务中给数据加标签是很有挑战性的。没有标签的数据可以使用RL。
在RL里面有两个东西:actor和环境。环境会给observation作为输入,actor获取观测会输出action,环境会不断给出reward作为反馈,判断actor的动作是否好。
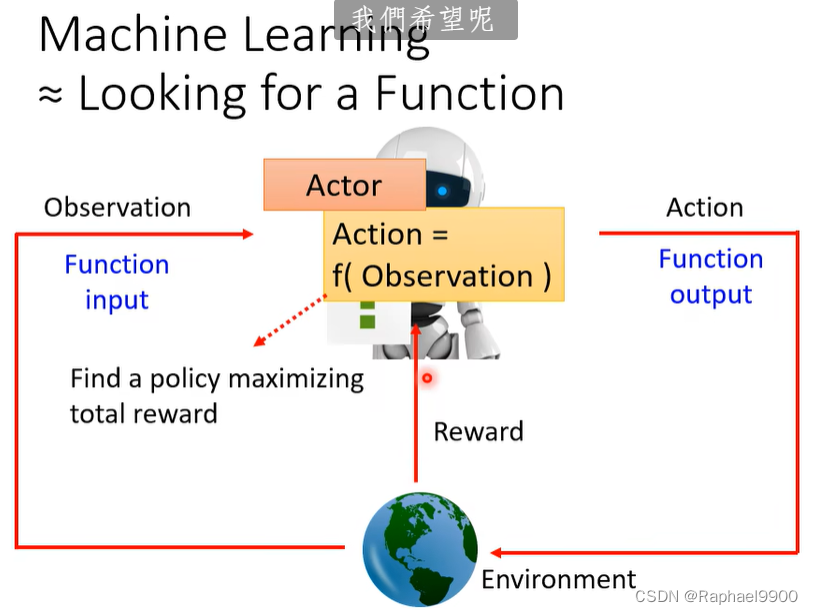
找到一个最大化总reward的政策
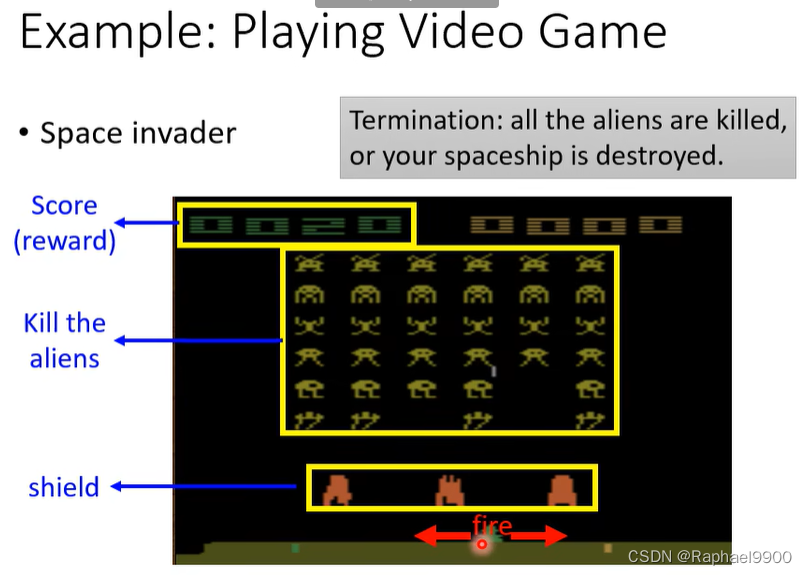
终结:所有的外星人都被杀死,或者你的飞船被摧毁。
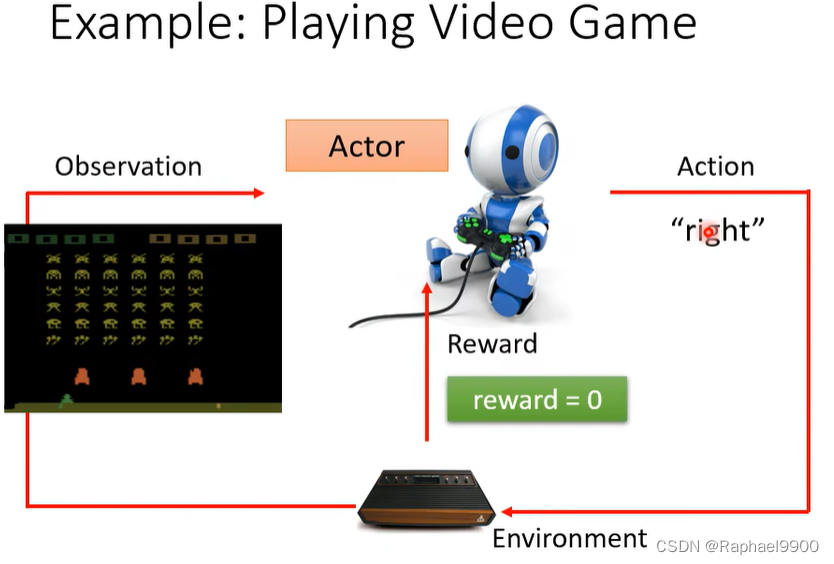
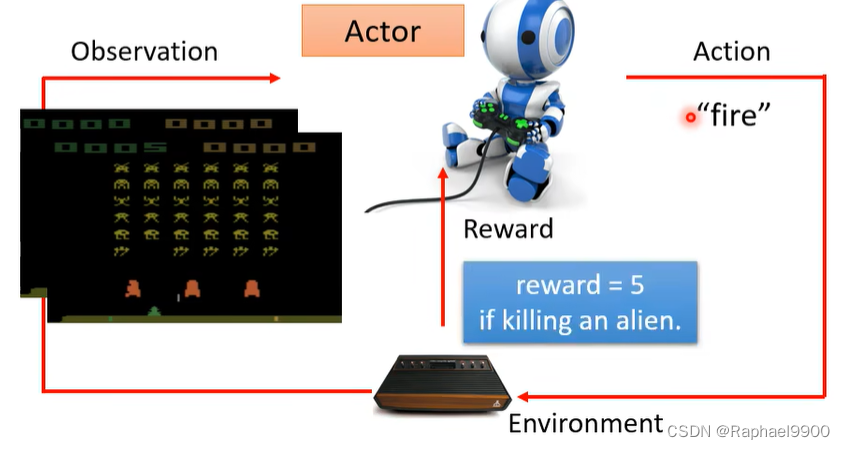

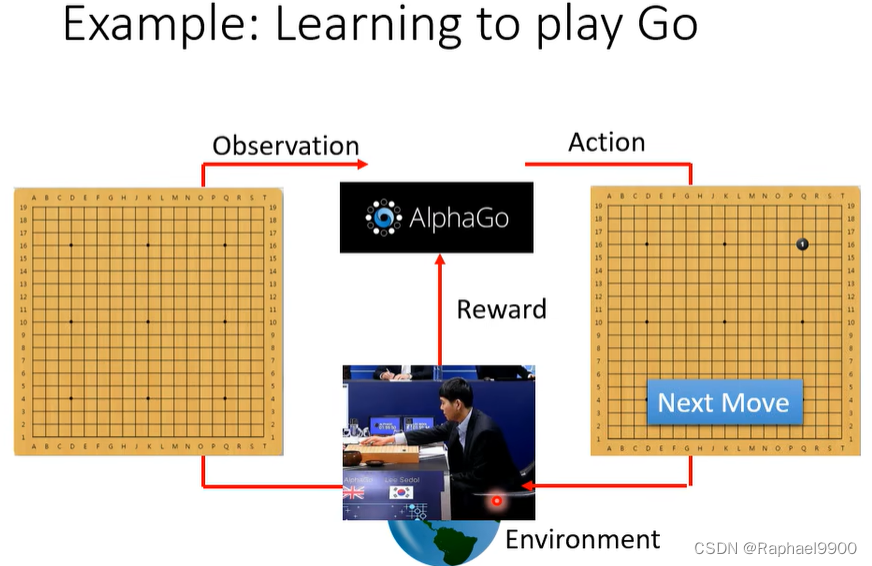
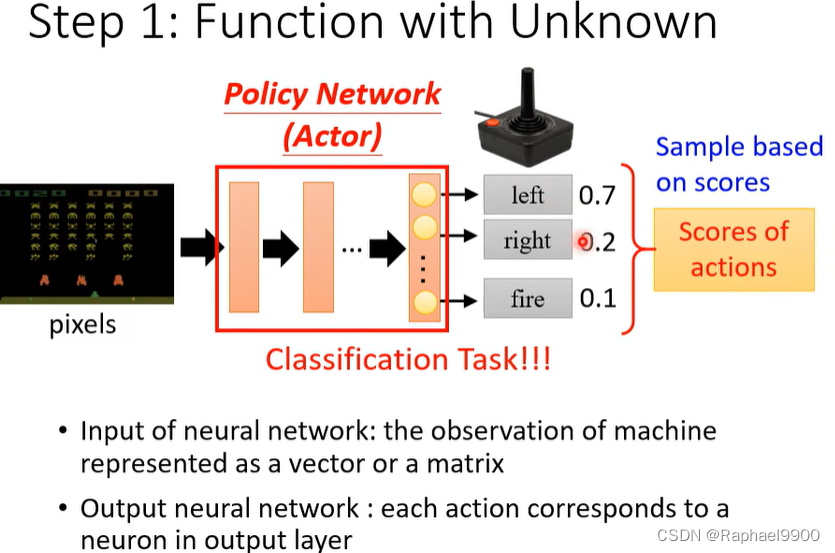
神经网络的输入:用向量或矩阵表示的机器的观测值
输出神经网络:每个动作对应输出层的一个神经元
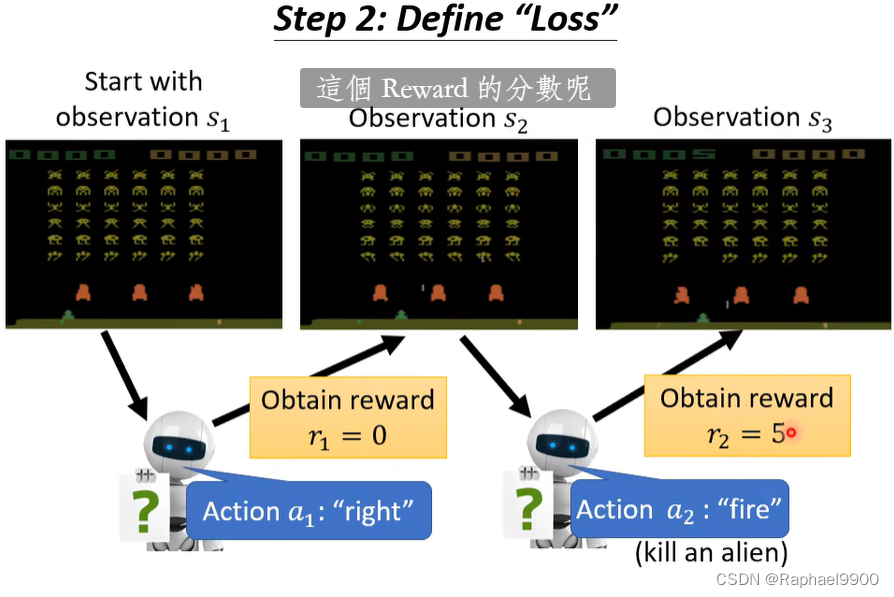
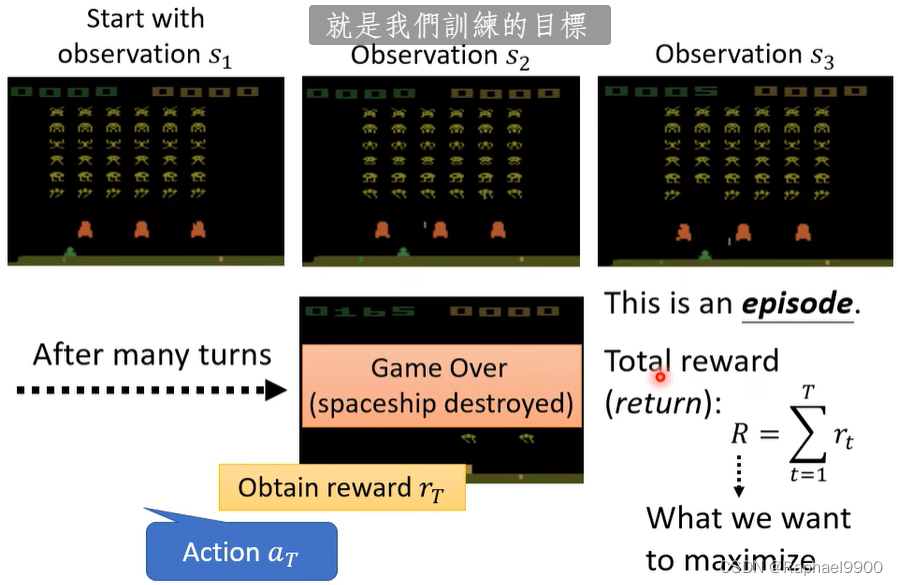
reward不仅要看a还要看s。
第三步要找到一组参数,让R越大越好。
因为a是取样的,结果带有随机性,所以每次的结果不一定是一样的。
环境和reward是黑盒子,不知道结果和过程。
环境也是有随机性的,一般的方法不能用。如何在这里进行优化是RL的主要挑战。
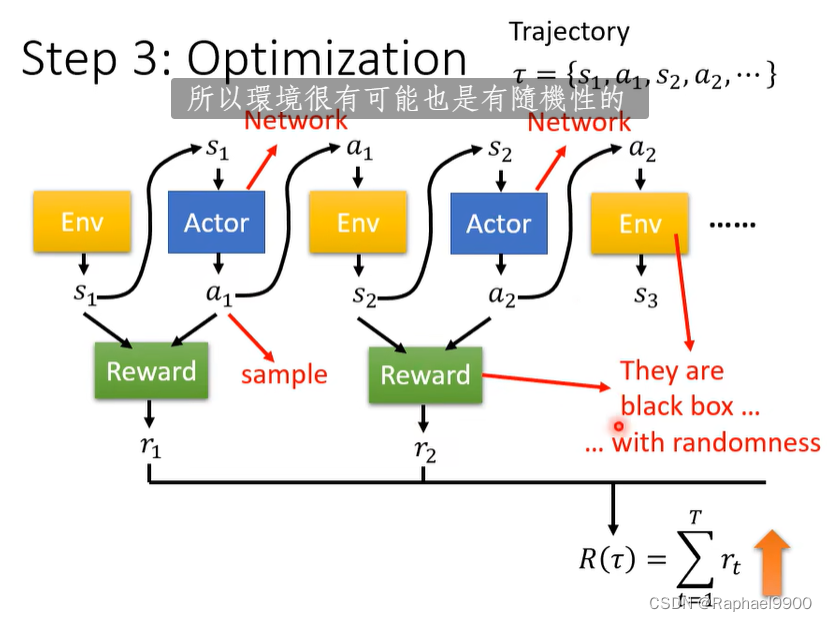
RL的随机性很大,测试的时候结果有很大的不一样。
计算loss
控制actor:让它采取(或不采取)特定的行动——给出特定的观察结果。

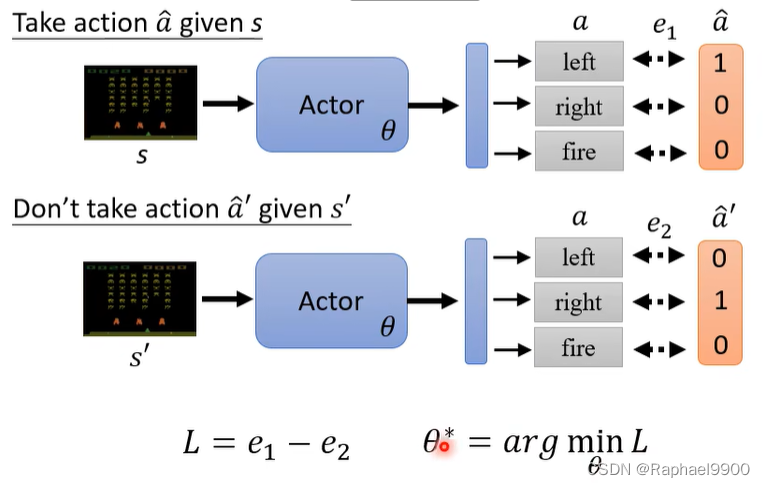
这跟监督学习训练分类器是一样的!
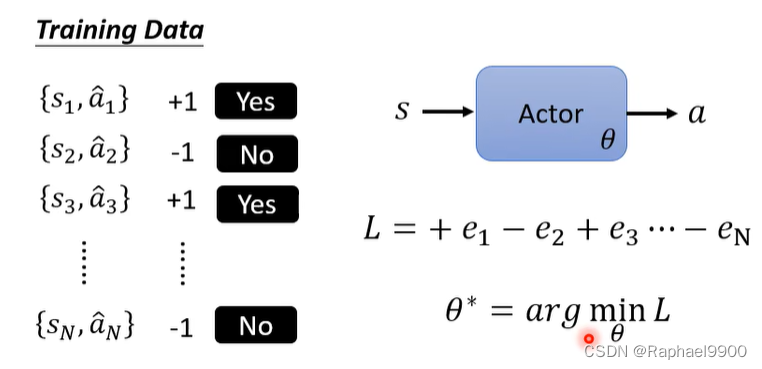
计算A
改变二元分类问题,加上权重:难点是怎么得到这些对和A
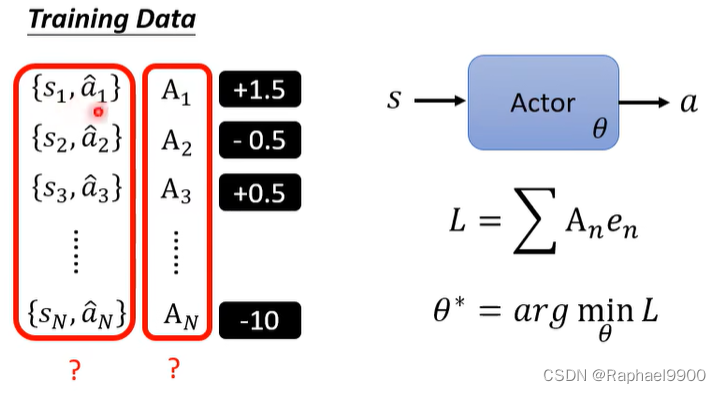
版本0
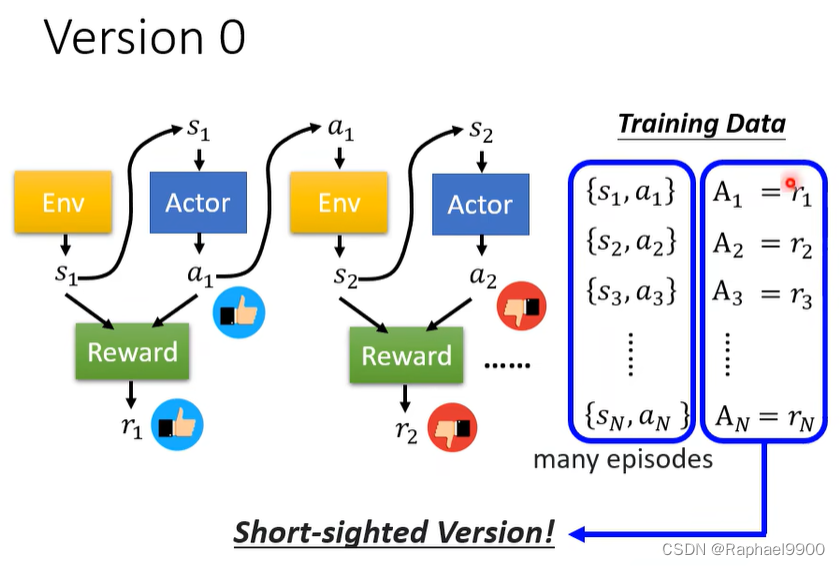
不是一个好的版本,只看近不看远。一项行动会影响后续观察,进而影响后续reward。a1可能会影响r2.
reward delay:actor不得不牺牲眼前的奖励来获得更多的长期奖励。
在《太空入侵者》中,只有“开火”能产生积极的回报,所以vision 0将学习一个总是“开火”的actor。
版本1
a1有多好由后面的r决定。
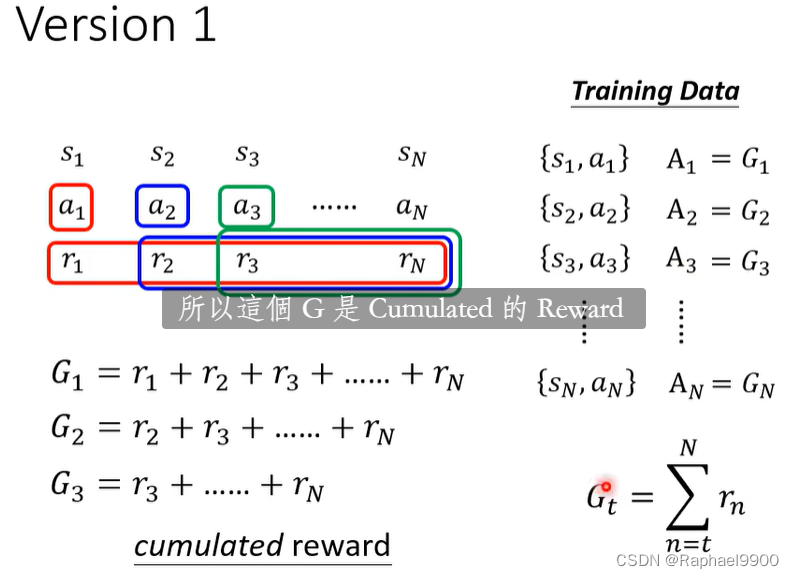
问题:如果游戏很久,那很远之后的r归功于很前的动作吗?
版本2
加入γ,影响力削减

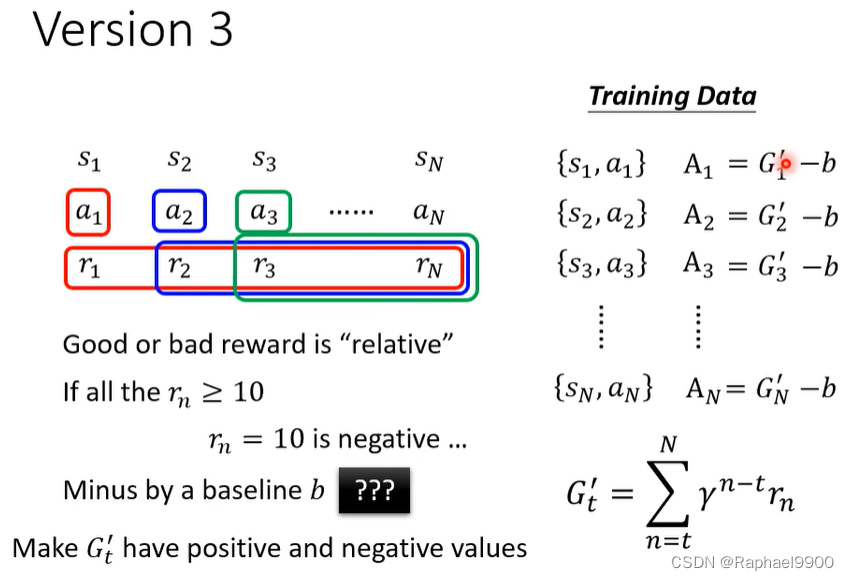
版本3
越早的动作的分数会累积很多。
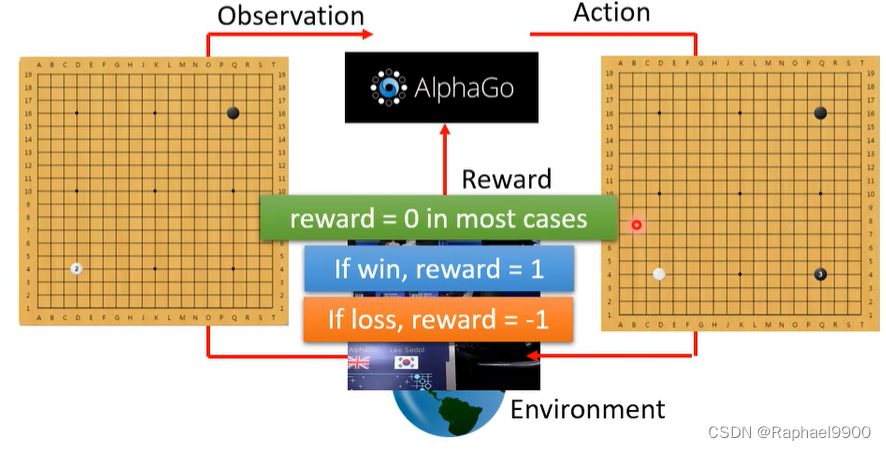
G要做标准化吗?reward是相对的!
奖励的好坏是“相对的”,如果所有rn ≥ 10,Tn = 10是负数…减去基线b使G’有正值和负值。
2、梯度方法
可以看到,收集资料{s,a}需要训练很多次

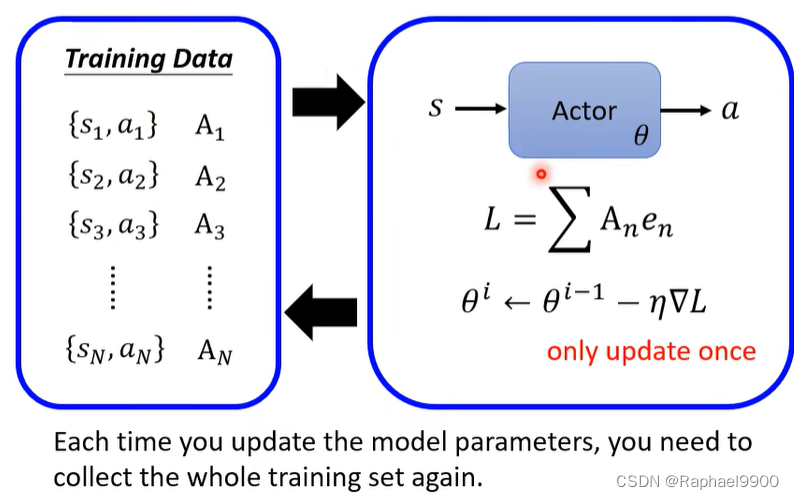
每次更新模型参数时,都需要再次收集整个训练集。一次循环只更新一次参数。
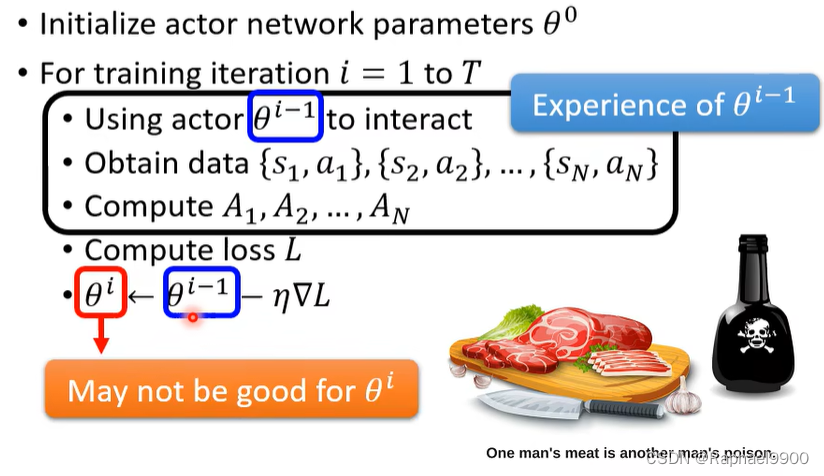
事实上我们获取的这些资料只适合当前的参数,不一定适合后面 的参数!

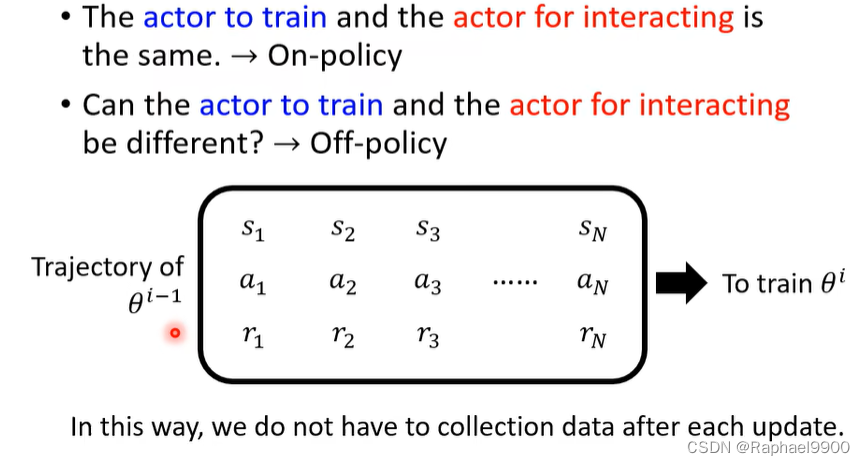
off-policy:这样,我们不必在每次更新后收集数据。

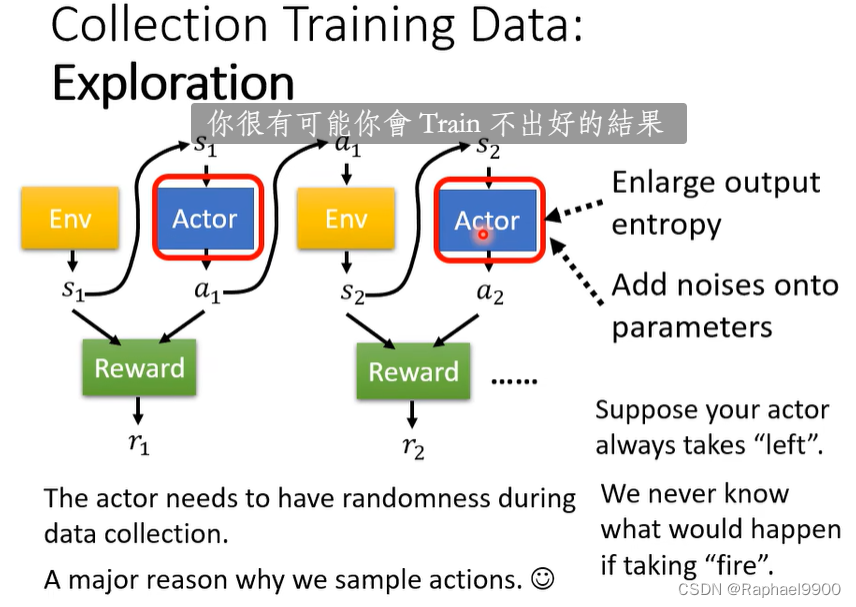
收集训练数据:探索
actor需要在数据收集过程中具有随机性。我们采样动作的主要原因。
扩大输出熵
在参数上添加噪声
假设你的actor总是走“左”,我们永远不知道如果“开火”会发生什么。
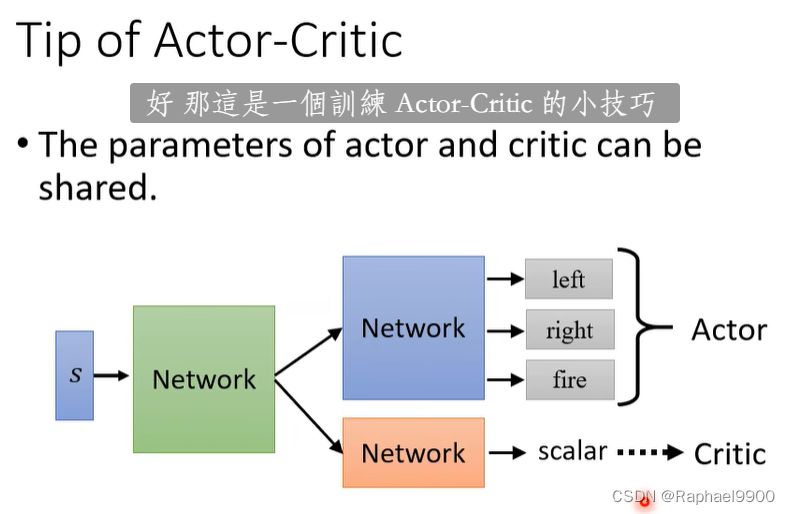
3、actor critic
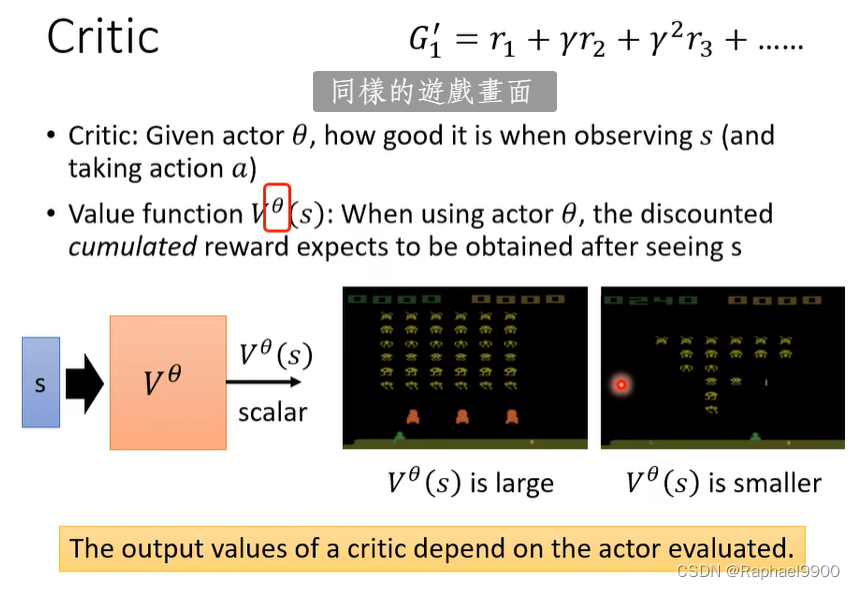
critic:给定actore,观察s(并采取行动a)时有多好
价值函数Vθ(s):当使用actor e时,期望在看到s之后获得折扣的累积报酬discounted cumulated reward
MC
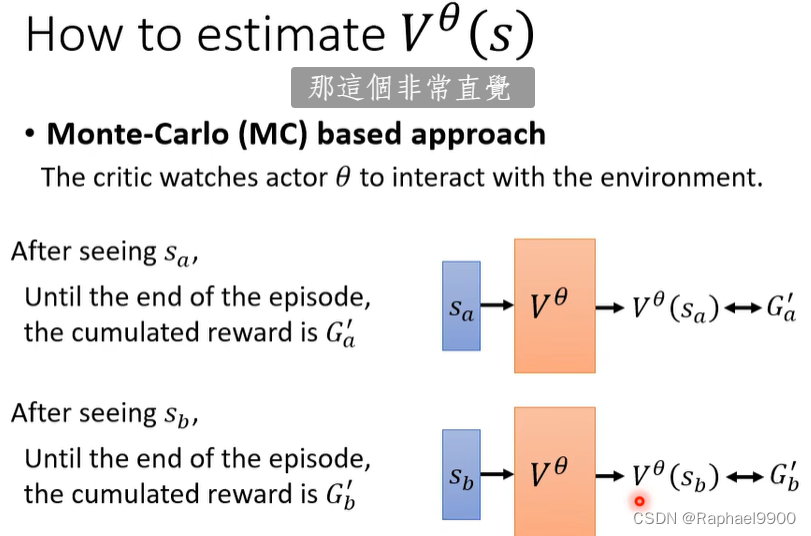
玩完整场游戏之后进行预测
TD
玩了一会就更新参数


版本3.5

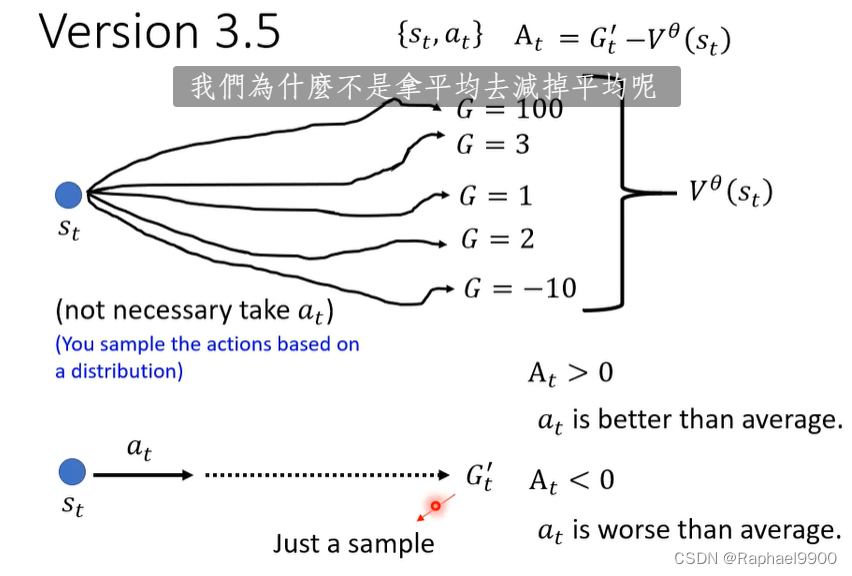
上面是根据一个分布随便取样的
下面是执行 了一个at之后得到的