- 1笔记 GWAS 操作流程2-4:哈温平衡检验
- 2自动化测试脚本 Selenium WebDriver(Java)常用 API 汇总
- 3记录一下Termux的配置过程_termux github
- 4Hadoop3.1.3安装教程_单机/伪分布式配置
- 5【数据库系统工程师】1.1计算机硬件基础知识_系统工程师硬件知识
- 6Android studio开发的App闪退问题解决方法之一
- 7python音乐管理系统 计算机专业毕业设计源码83260_数据库音乐管理系统
- 8安装、破解Navicat Premium 12.0.18
- 9谷粒商城学习笔记(17.秒杀系统)_谷粒商城 优惠营销系统
- 102022年甘肃省职业院校技能大赛“网络搭建与应用”赛项_网络搭建技能大赛
RabbitMQ常见问题解决方案——消息丢失、重复消费、消费乱序、消息积压_rabbitmq的消息异常(丢失、重复、顺序、堆积)如何处理?
赞
踩
背景
本篇文章首发于个人博客平台:https://duktig.cn/archives/79/,如果觉得感兴趣/对您有帮助,欢迎来访:Duktig的个人博客。
RabbitMQ常见问题解决方案
消息中间件在业务开发当中具有举足轻重的地位,很多场景/问题下都可以依托于消息中间件来实现,所以消息中间件的很多问题也是在面试的高频点。
1. RabbitMQ的可靠性(消息丢失问题)
消息可靠性问题举例:
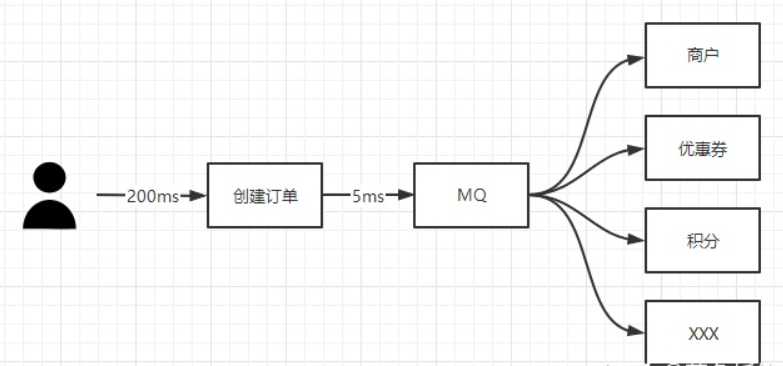
以创建订单为例,可能会出现这样的业务场景
- MQ 挂了,消息没发出去。创建订单后面几个优惠券、积分的下游系统全都没有执行业务结算怎么办?
- MQ 是高可用的,消息发出去了,但是优惠券结算业务报错了怎么办?因为这个是异步的,也不好去回滚
- 消息正常发出去,消费者也接收到了,商户系统、优惠券系统都正常执行完了,积分业务报错了导致积分没结算,那这个订单的数据就不一致了
要解决上述问题,就是要保证消息一定要可靠的被消费,那么我们可以来分析下消息有哪些步骤会出问题

RabbitMQ出现消息可靠性问题的常见情况:
- 生产者消息没到交换机,相当于生产者弄丢消息
- 交换机没有把消息路由到队列,相当于生产者弄丢消息
- RabbitMQ 宕机导致队列、队列中的消息丢失,相当于 RabbitMQ 弄丢消息
- 消费者消费出现异常,业务没执行,相当于消费者弄丢消息
1.1 生产者丢失消息
异步监听机制:
①成功/未成功发送到交换机可以触发一个confirm-type监听
②交换机发送到队列会有一个publisher-returns监听
具体操作:
以 SpringBoot 整合 RabbitMQ 为例
引入依赖 starter
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-amqp</artifactId>
</dependency>
- 1
- 2
- 3
- 4
配置文件
rabbitmq:
publisher-returns: true
publisher-confirm-type: correlated #新版本 publisher-confirms: true 已过时
- 1
- 2
- 3
然后编写监听回调
@Configuration
@Slf4j
public class RabbitMQConfig {
@Autowired
private RabbitTemplate rabbitTemplate;
@PostConstruct
public void enableConfirmCallback() {
//confirm 监听,当消息成功发到交换机 ack = true,没有发送到交换机 ack = false
//correlationData 可在发送时指定消息唯一 id
rabbitTemplate.setConfirmCallback((correlationData, ack, cause) -> {
if(!ack){
//记录日志、发送邮件通知、落库定时任务扫描重发
}
});
//当消息成功发送到交换机没有路由到队列触发此监听
rabbitTemplate.setReturnsCallback(returned -> {
//记录日志、发送邮件通知、落库定时任务扫描重发
});
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
测试的时候可以在发送消息时故意写错交换机、路由键的名称,然后就会回调到我们刚刚写的监听方法, cause 会给我们展示具体没有发到交换机的原因;returned 对象中包含了消息相关信息。
但是一般不这样用,成本太高丢失概率很低。一般采用日志/邮件记录,手动维护。
即RabbitMQ 本身丢失的可能性就非常低,其次如果这里需要落库再用定时任务扫描重发还要开发一堆代码,分布式定时任务…再其次定时任务扫描肯定会增加消息延迟,不是很有必要。真实业务场景是记录一下日志就行了,方便问题回溯,顺便发个邮件给相关人员,如果真的极其罕见的是生产者弄丢消息,那么开发往数据库补数据就行了。
1.2 RabbitMQ弄丢消息
设置持久化将消息写出磁盘(重启后消息仍然存在),否则RabbitMQ重启后所有队列和消息都会丢失。
持久化操作:
持久化分为三种
- 交换机持久化
- 队列持久化
- 消息持久化
1.2.1 交换机持久化
交换机持久化描述的是当这个交换机上没有注册队列时,这个交换机是否删除。如果要打开持久化的话也很简单
@Bean
public DirectExchange testDirectExchange(){
//第二个参数就是是否持久化,第三个参数就是是否自动删除
return new DirectExchange("direct.Exchange",true,false);
}
- 1
- 2
- 3
- 4
- 5
- 6
消费者类上的注解:
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(value = "direct.Queue",autoDelete = "true"),
exchange = @Exchange(value = "direct.Exchange", type = ExchangeTypes.DIRECT,durable = "true"),
key = "direct.Rout"
)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
@Exchange注解的durable属性设置为true(默认也是true,不设置也可以)。这样,即使这个交换机没有队列,也不会被删除
1.2.2 队列持久化
队列持久化描述的是当这个队列没有消费者在监听时,是否进行删除。持久化做法:
@Bean
public Queue txQueue(){
//第二个参数就是durable,是否持久化
return new Queue("txQueue",true);
}
- 1
- 2
- 3
- 4
- 5
消费者类的注解:
@RabbitListener(
bindings = @QueueBinding(
value = @Queue(value = "direct.Queue",autoDelete = "false",durable = "true"),
exchange = @Exchange(value = "direct.Exchange", type = ExchangeTypes.DIRECT,durable = "true"),
key = "direct.Rout"
)
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到,@Queue注解上,加上了durable="true"的注解。这样队列在重启的时候就不会被删除了
1.2.3 消息持久化
消息持久化和前面两个稍微有点不同。消息持久化实际上就是基于确认机制去做的。默认情况下,只要消费者接收到这个消息,这个消息就从队列上被删除了。、
但考虑这样一种场景,接口层接受到一个请求,然后推送一个消息,异步地去更新数据库。此时对于消费者端来说,一拿到消息,消息就从队列上被删除,然后开始执行数据库更新,但此时数据库更新失败了,方法直接返回。但队列上已经没有这条消息了,这个更新操作不就没有完成了吗?这肯定是有问题的。
所以RabbitMQ就有了消费者确认机制,只有消费者手动确认,消息才会被删除,否则该消息将一直存在队列中,开启的方法很简单:
application.properties上加上:
spring.rabbitmq.listener.simple.acknowledge-mode=manual
意为改为手动确认。
- 1
- 2
对于消费者端:
@RabbitHandler
public void onMessage(String str,Channel channel,Message message) throws IOException {
channel.basicAck(message.getMessageProperties().getDeliveryTag(),false); //手动调用
System.out.println(str);
}
- 1
- 2
- 3
- 4
- 5
手动调用下确认即可,消息就会被删除。这一步可以放在业务逻辑的执行之后
1.3 消费者弄丢消息
消费者丢数据一般是因为采用了自动确认消息模式。MQ收到确认消息后会删除消息,如果这时消费者异常了,那消息就没了。
即消费端执行业务代码报错,导致业务未执行,比较常见,属于业务代码异常,一定要解决。如:创建订单成功了,优惠券结算报错了,默认情况下 RabbitMQ 只要把消息推送到消费者就会认为消息已经被消费,就从队列中删除了,但是优惠券还没有结算,这样就相当于消息变相丢失了。
可以使用ack机制,默认情况下自动应答,可以使用手动ack,然后再删除消息。
具体操作:
首先在配置文件中开启手动 ack
spring:
rabbitmq:
listener:
simple:
acknowledge-mode: manual #手动应答
- 1
- 2
- 3
- 4
- 5
然后在消费端代码中手动应答签收消息
@RabbitListener(queues = "queue")
public void listen(String object, Message message, Channel channel) {
long deliveryTag = message.getMessageProperties().getDeliveryTag();
log.info("消费成功:{},消息内容:{}", deliveryTag, object);
try {
/**
* 执行业务代码...
* */
channel.basicAck(deliveryTag, false);
} catch (IOException e) {
log.error("签收失败", e);
try {
channel.basicNack(deliveryTag, false, true);
} catch (IOException exception) {
log.error("拒签失败", exception);
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
实际场景的应用
但是在实际场景中,设置ack后,让消息重回队列会回到队列顶端,继续推送到服务端,通常的代码报错并不能因为重试而解决,可能会造成死循环。所以这样的场景一般有三个选择:
- 当消费失败后将此消息存到 Redis,记录消费次数,如果消费了三次还是失败,就丢弃掉消息,记录日志落库保存
- 直接填 false ,不重回队列,记录日志、发送邮件等待开发手动处理
- 不启用手动 ack ,使用 SpringBoot 提供的消息重试
SpringBoot 提供的消息重试:
其实很多场景并不是一定要启用消费者应答模式,因为 SpringBoot 给我们提供了一种重试机制,当消费者执行的业务方法报错时会重试执行消费者业务方法。
启用 SpringBoot 提供的重试机制
spring:
rabbitmq:
listener:
simple:
retry:
enabled: true
max-attempts: 3 #重试次数
- 1
- 2
- 3
- 4
- 5
- 6
- 7
消费者代码
@RabbitListener(queues = "queue")
public void listen(String object, Message message, Channel channel) throws IOException {
try {
/**
* 执行业务代码...
* */
int i = 1 / 0; //故意报错测试
} catch (Exception e) {
log.error("签收失败", e);
/**
* 记录日志、发送邮件、保存消息到数据库,落库之前判断如果消息已经落库就不保存
* */
throw new RuntimeException("消息消费失败");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
注意一定要手动 throw 一个异常,因为 SpringBoot 触发重试是根据方法中发生未捕捉的异常来决定的。值得注意的是这个重试是 SpringBoot 提供的,重新执行消费者方法,而不是让 RabbitMQ 重新推送消息。
小结
其实认真研究下来你会发现所谓的消息可靠性本身就是无法保证的…所谓的各种可靠性机制只是为了以后消息丢失提供可查询的日志而已,不过通过这些机制耗费一些(巨大)成本的确是能够缩小消息丢失的可能性。
2. 重复消费问题(消息幂等性)
为了防止消息在消费者端丢失,会采用手动回复MQ的方式来解决,同时也引出了一个问题,消费者处理消息成功,手动回复MQ时由于网络不稳定,连接断开,导致MQ没有收到消费者回复的消息,那么该条消息还会保存在MQ的消息队列,由于MQ的消息重发机制,会重新把该条消息发给和该队列绑定的消息者处理,这样就会导致消息重复消费。而有些操作是不允许重复消费的,比如下单,减库存,扣款等操作。
2.1 生产时消息重复
由于生产者发送消息给MQ,在MQ确认的时候出现了网络波动,生产者没有收到确认,实际上MQ已经接收到了消息。这时候生产者就会重新发送一遍这条消息。
生产者中如果消息未被确认,或确认失败,我们可以使用定时任务+(redis/db)来进行消息重试。
@Component
@Slf4J
public class SendMessage {
@Autowired
private MessageService messageService;
@Autowired
private RabbitTemplate rabbitTemplate;
// 最大投递次数
private static final int MAX_TRY_COUNT = 3;
/**
* 每30s拉取投递失败的消息, 重新投递
*/
@Scheduled(cron = "0/30 * * * * ?")
public void resend() {
log.info("开始执行定时任务(重新投递消息)");
List<MsgLog> msgLogs = messageService.selectTimeoutMsg();
msgLogs.forEach(msgLog -> {
String msgId = msgLog.getMsgId();
if (msgLog.getTryCount() >= MAX_TRY_COUNT) {
messageService.updateStatus(msgId, Constant.MsgLogStatus.DELIVER_FAIL);
log.info("超过最大重试次数, 消息投递失败, msgId: {}", msgId);
} else {
messageService.updateTryCount(msgId, msgLog.getNextTryTime());// 投递次数+1
CorrelationData correlationData = new CorrelationData(msgId);
rabbitTemplate.convertAndSend(msgLog.getExchange(), msgLog.getRoutingKey(), MessageHelper.objToMsg(msgLog.getMsg()), correlationData);// 重新投递
log.info("第 " + (msgLog.getTryCount() + 1) + " 次重新投递消息");
}
});
log.info("定时任务执行结束(重新投递消息)");
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
也可以生产消息时,具备唯一ID,消费时通过消费端进行处理(参看消费重复的解决方案)。
2.2 消费时消息重复
两个思路:
- 不让消费端执行两次
- 让它重复消费了,但是不让其对业务数据造成影响
2.2.1 确保消费端只执行一次
一般来说消息重复消费都是在短暂的一瞬间消费多次,我们可以使用 redis 将消费过的消息唯一标识存储起来,然后在消费端业务执行之前判断 redis 中是否已经存在这个标识。
举个例子,订单使用优惠券后,要通知优惠券系统,增加使用流水。这里可以用订单号 + 优惠券 id 做唯一标识。业务开始先判断 redis 是否已经存在这个标识,如果已经存在代表处理过了。不存在就放进 redis 设置过期时间,执行业务。
Boolean flag = stringRedisTemplate.opsForValue().setIfAbsent("orderNo+couponId");
//先检查这条消息是不是已经消费过了
if (!Boolean.TRUE.equals(flag)) {
return;
}
//执行业务...
//消费过的标识存储到 Redis,10 秒过期
stringRedisTemplate.opsForValue().set("orderNo+couponId","1", Duration.ofSeconds(10L));
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.2.2 允许消费端执行多次,保证数据不受影响
- 数据库唯一键约束
如果消费端业务是新增操作,我们可以利用数据库的唯一键约束,比如优惠券流水表的优惠券编号,如果重复消费将会插入两条相同的优惠券编号记录,数据库会给我们报错,可以保证数据库数据不会插入两条。
- 数据库乐观锁思想
如果消费端业务是更新操作,可以给业务表加一个 version 字段,每次更新把 version 作为条件,更新之后 version + 1。由于 MySQL 的 innoDB 是行锁,当其中一个请求成功更新之后,另一个请求才能进来,由于版本号 version 已经变成 2,必定更新的 SQL 语句影响行数为 0,不会影响数据库数据。
3. 消息消费顺序性问题
举例:
-
比如一个电商的下单操作,下单后先减库存然后生成订单,这个操作就需要顺序执行的 那怎么保证顺序呢?
-
有些业务场景会需要让消息顺序消费,比如使用 canal 订阅 MySQL 的 binary 日志来更新 Redis,通常我们会把 canal 订阅到的数据变化发送到消息队列。
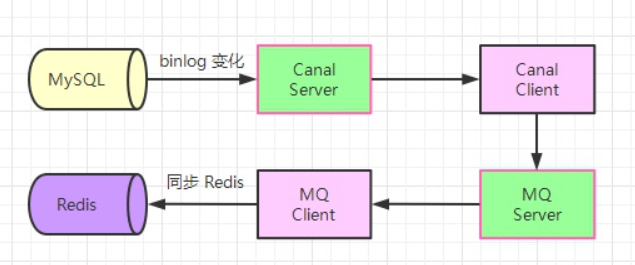
如果不保证 RabbitMQ 的顺序消费, Redis 中就有可能会出现脏数据。
原因:
其实队列本身是有顺序的,但是生产环境服务实例一般都是集群,当消费者是多个实例时,队列中的消息会分发到所有实例进行消费(同一个消息只能发给一个消费者实例),这样就不能保证消息顺序的消费,因为你不能确保哪台机器执行消费端业务代码的速度快。
解决消费顺序问题的思路:
- 多个消费实例并发竞争时,不能保证消费顺序,那么每次RabbitMQ只投递一个消息,待收到ack确认时再投递下一个,即可解决问题。在并发和性能要求高的情况下不适用:
- 每次只有一个消费者可消费,其他消费者被阻塞,降低了消费端的性能和并发能力。
- 大大提高了消息积压的风险。
- 根据一定的策略,多个消费者按序消费。
3.1 保证每次只有单个消费实例消费
所以对于需要保证顺序消费的业务,我们可以只部署一个消费者实例,然后设置 RabbitMQ 每次只推送一个消息,再开启手动 ack 即可。这样 RabbitMQ 每次只会从队列推送一个消息过来,处理完成之后我们 ack 回应,再消费下一个,就能确保消息顺序性。
spring:
rabbitmq:
listener:
simple:
prefetch: 1 #每次只推送一个消息
acknowledge-mode: manual
- 1
- 2
- 3
- 4
- 5
- 6
这样 RabbitMQ 每次只会从队列推送一个消息过来,处理完成之后我们 ack 回应,再消费下一个,就能确保消息顺序性。
但是这样的操作也会降低消费者的性能,一个消费者消费消息时,其他消费者会阻塞,所以很多场景下可能并不会采用这样的方案。
所以一般会根据场景,制定一定的策略来解决消费顺序问题。
3.2 简单队列场景
当RabbitMQ采用简单队列模式的时候,如果消费者采用多线程的方式来加速消息的处理,此时也会出现消息乱序的问题。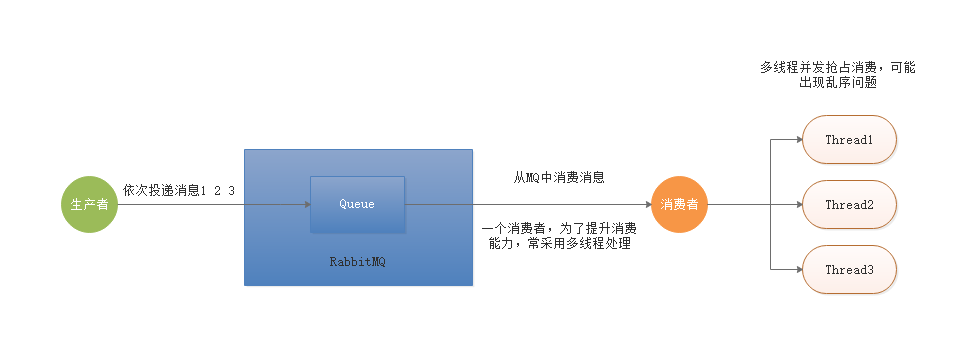
多线程并发抢占出现消费乱序问题,将消息ID进行hash计算,将相同值放入同一个内存队列,让指定线程执行,即可解决顺序消费问题。
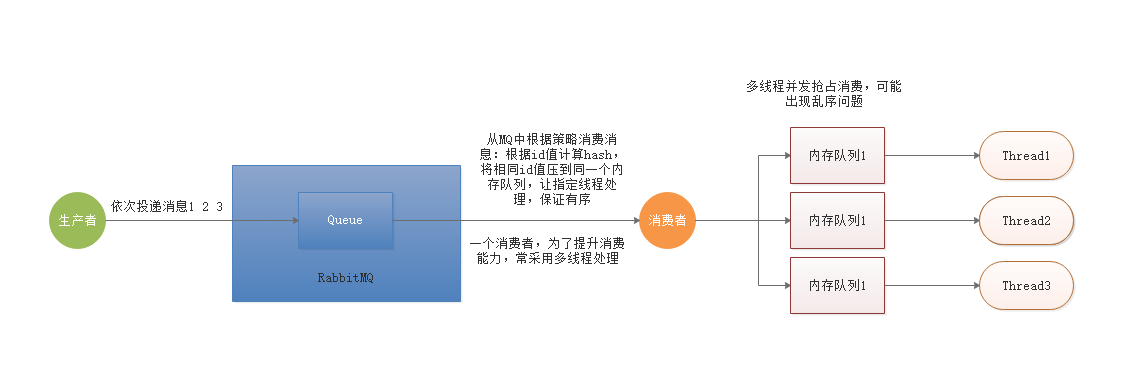
3.3 工作队列场景
当RabbitMQ采用work Queue模式,此时只会有一个Queue但是会有多个Consumer,同时多个Consumer直接是竞争关系,此时就会出现MQ消息乱序的问题。
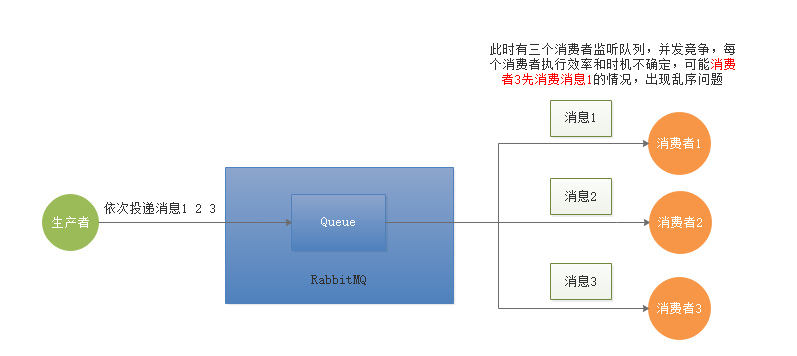
生产者根据商品id计算hash值,对队列取余,将相同id的操作压入同一个队列。每个队列一个消费者就不会出现乱序情况。
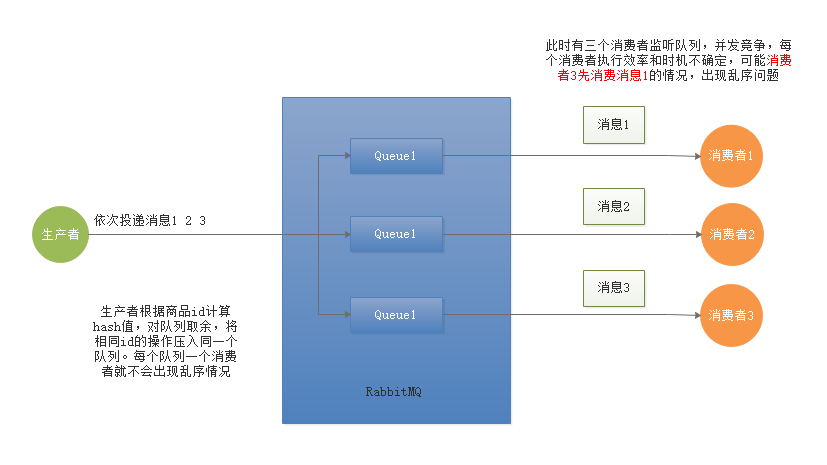
3.4小结
解决消费顺序问题,最根源的思路还是根据一定的策略,实现一个消费者按序处理一个队列中的消息。
4. 消息积压问题
所谓消息积压一般是由于消息生产的速度长时间,远远大于消费的速度时,导致大量消息在 RabbitMQ 的队列中无法消费。
4.1 消息积压的影响
- 可能导致新消息无法进入队列
- 可能导致l旧消息无法丢失
- 消息等待消费的时间过长,超出了业务容忍范围。
4.2 产生堆积的情况
- 生产者突然大量发布消息
- 消费者消费失败
- 消费者出现性能瓶颈
- 消费者挂掉
4.3场景重现
- 生产者发送大量消息:利用Jmeter开多线程,循环发送大量消息进入队列。
- 消费者消费失败:自动ack情况下,抛出异常进行模拟。
- 设置消费者性能瓶颈:在消费方法中设置休眠时间,模拟性能瓶颈。
- 关闭消费者:停掉消费者,模拟消费者挂掉。
消费者端示例核心代码:
public class LoginIntegralComsumer implements MessageListener{
public void onMessage(Message message){
String jsonString = null;
try{
jsonString = new String(message.getBody(),"UTF-8");
}catch (UnsupportedEncodingException e){
e.printStackTrace();
}
if(new Random().nextInt(5)==2){
//模拟发生异常
throw new RuntimeException("模拟处理异常");
}
try{
//模拟耗时的处理过程
TimeUnit.MILLISECONDS.sleep(1000);
System.out.println(Thread.currentThread().getName()+"处理消息:"+jsonString);
}catch(InterruptedException e){
e.printStackTrace();
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
4.4 解决办法
- 对生产者发消息接口进行适当限流(不太推荐,影响用户体验)
- 多部署几台消费者实例(推荐)
- 适当增加 prefetch 的数量,让消费端一次多接受一些消息(推荐,可以和第二种方案一起用)
- 增加消费者的多线程处理
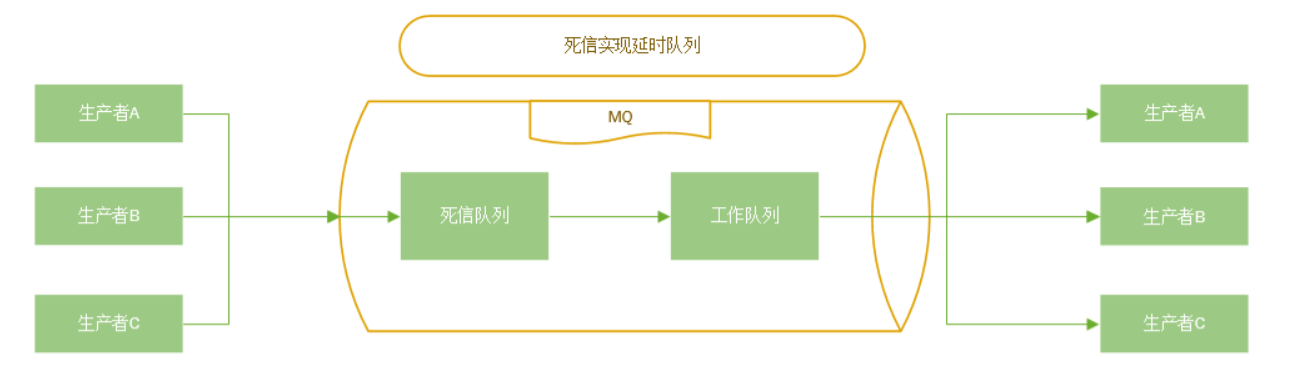
- 死信队列
常见处理思路
- 拆分MQ,生产者一个MQ,消费者一个MQ,写一个程序监听生产者的MQ模拟消费速度(譬如线程休眠),然后发送到消费者的MQ,如果消息积压则只需要处理生产者的MQ的积压消息,不影响消费者MQ
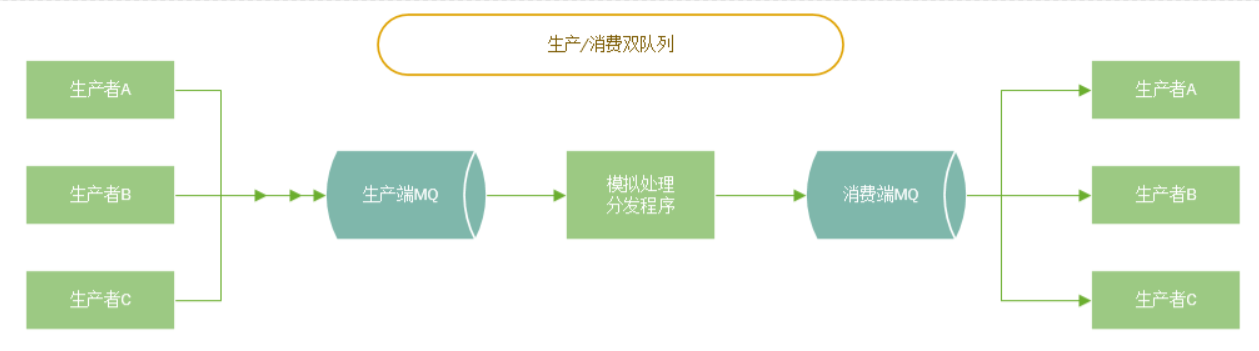
-
拆分MQ,生产者一个MQ,消费者一个MQ,写一个程序监听生产者的MQ,定义一个全局静态变量记录上一次消费的时间,如果上一次时间和当前时间只差小于消费者的处理时间,则发送到一个延迟队列(可以使用死信队列实现)发送到消费者的MQ,如果消息积压则只需要处理生产者的MQ的积压消息,不影响消费者MQ。
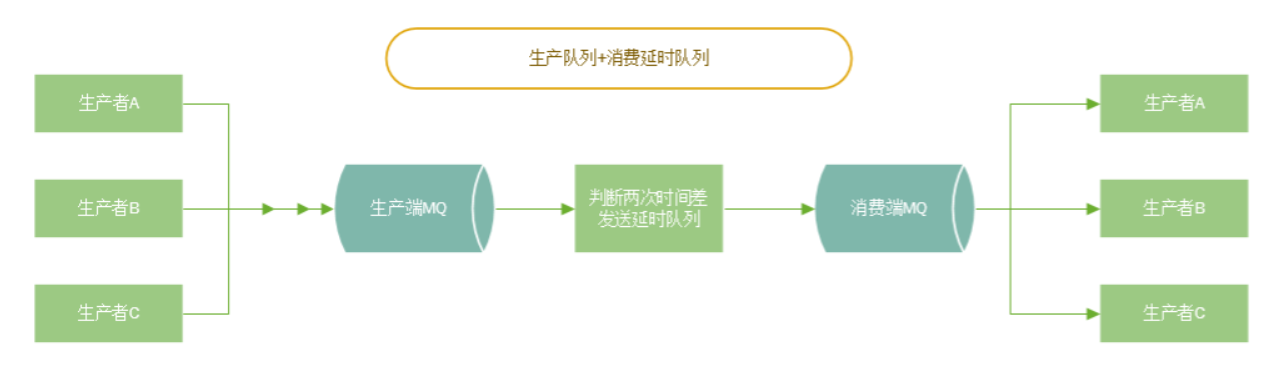
-
使用Redis的List或ZSET做接收消息缓存,写一个程序按照消费者处理时间定时从Redis取消息发送到MQ
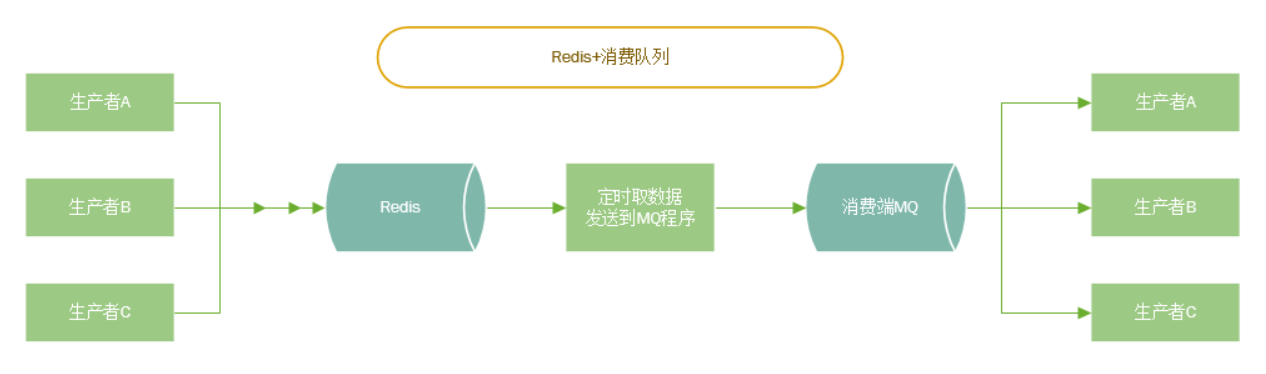
-
设置消息过期时间,过期后转入死信队列,写一个程序处理死信消息(重新如队列或者即使处理或记录到数据库延后处理)