
- 1《ClickHouse入门、实战与进阶》的创作之路_clickhouse入门实战与进阶 pdf
- 2别当工具人了,手把手教会你 Jenkins_jenkins text publisher
- 3KAFKA学习_kafka多个消费者消费一个topic
- 4使用easypoi模板方法导出excel_easypoi导出excel模板
- 5Python & 机器学习之项目实践_正态化数据之后再评估算法还是
- 61.入门matlab数理统计随机数的产生(matlab程序)_生成二项分布随机数的命令
- 7Docker安装kkfileview_基于ubuntu构建kkfileview的dockerfile
- 8Linux Mysql5.7版本安装以及配置 (图文详细)_linux 安装mysql5.7
- 9【原】android模拟器 adb不能正常使用 报错:ADB server didn't ACK * failed to start daemon *...
- 10GPT每日面试题-Typescript中type和interface的区别
NER数据集标注工具——Label Studio
赞
踩
在自然语言处理(NLP)领域,命名实体识别(NER)是一项重要的任务,它涉及识别文本中具有特定意义的实体,如人名、地名、组织机构名等。为了训练和评估NER模型,需要大量标注好的数据。而Label-Studio作为一款开源且免费的数据标注工具,为我们提供了便利。
Label-Studio简介
Label-Studio 是一款开源和免费的数据标注工具,能够完成文本分类、图像分类等多种机器学习及深度学习的数据标注任务.它具有用户友好的界面和丰富的功能,可以帮助用户高效地进行数据标注工作。。本文主要讲解一下NER任务的数据标注以及数据如何转化为BIO格式。
安装LabelStudio
pip install label-studio安装成功后在终端运行一下命令,即可打开
label-studio
之后填写邮箱和密码进行注册账号,即可使用。
NER任务的数据标注
NER任务的数据标注主要涉及标注文本中的实体,并为每个实体标注所属的实体类别。在Label-Studio中,我们可以通过创建项目并定义任务模板来进行NER任务的数据标注。
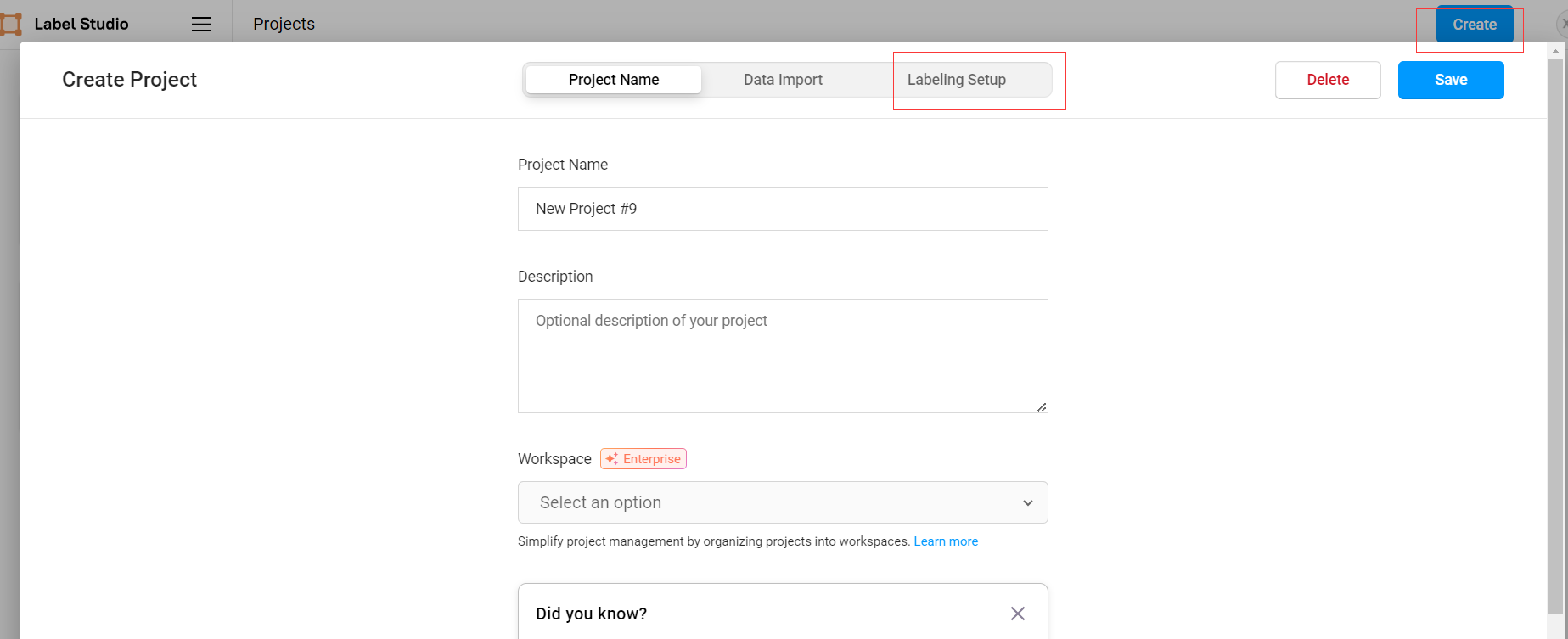
1.创建项目: 首先,在Label-Studio中创建一个新项目,并选择NER任务类型。
点击create,并在Labeling Setup中选择任务类型。
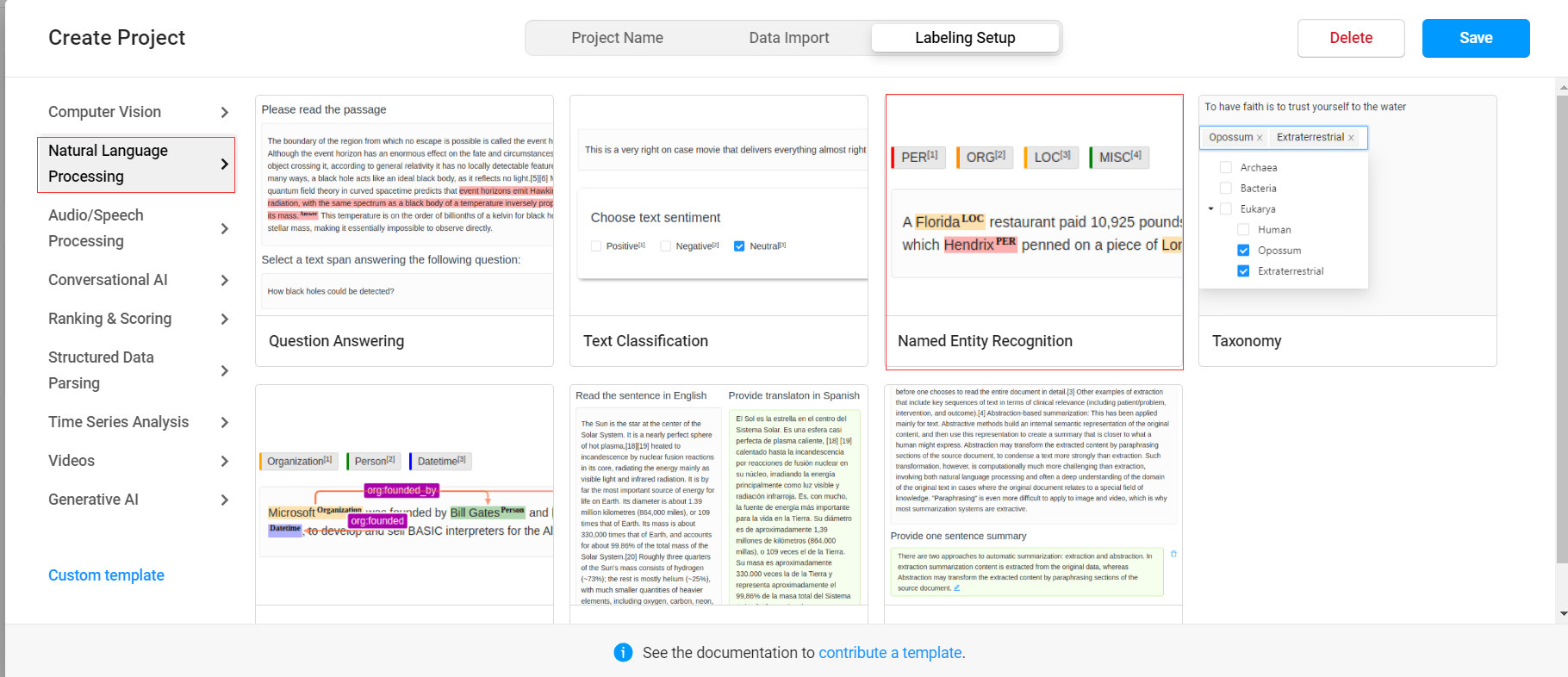
定义任务模板: 在项目中定义任务模板,包括实体类别的定义和标注界面的设置。可以根据具体需求自定义实体类别,如人名、地名、组织机构名等。
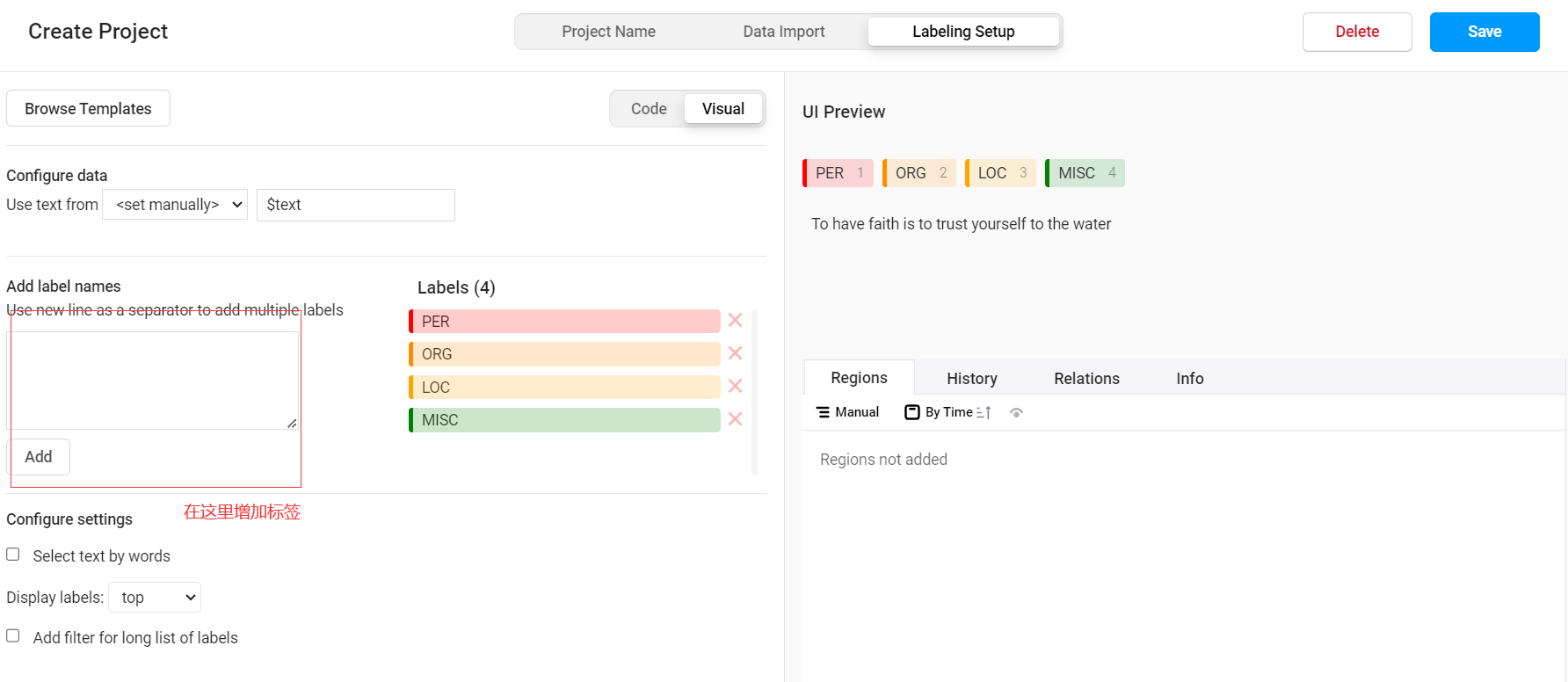
标注数据: 将需要标注的文本导入Label-Studio中,并在标注界面中标注文本中的实体,并为每个实体选择相应的实体类别。
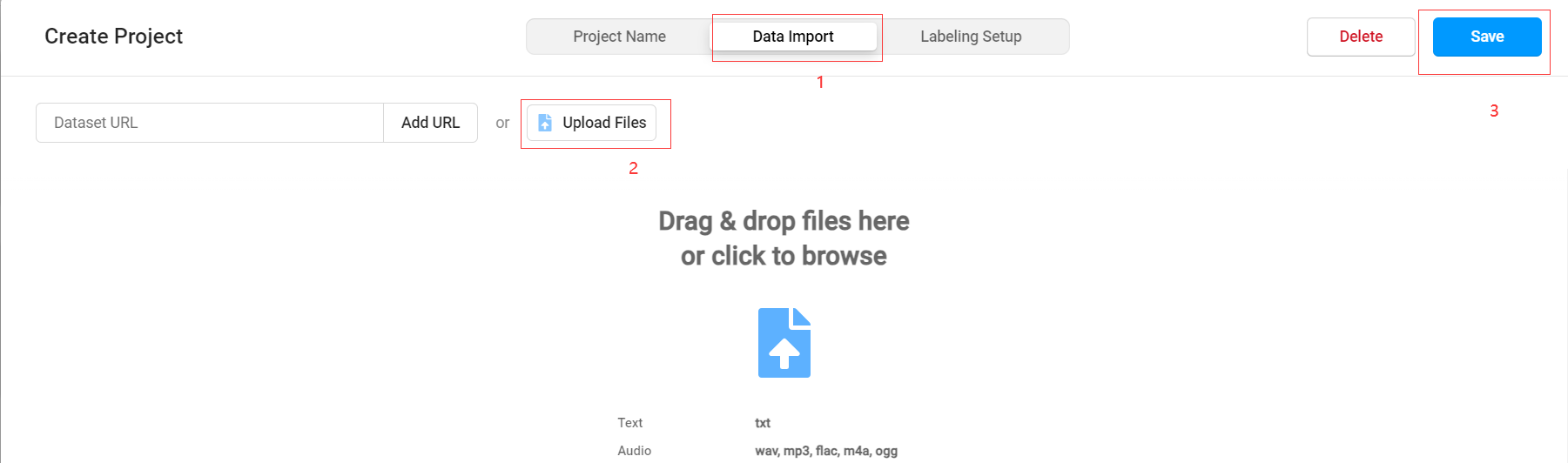
选择Data Import导入需要标注的文件
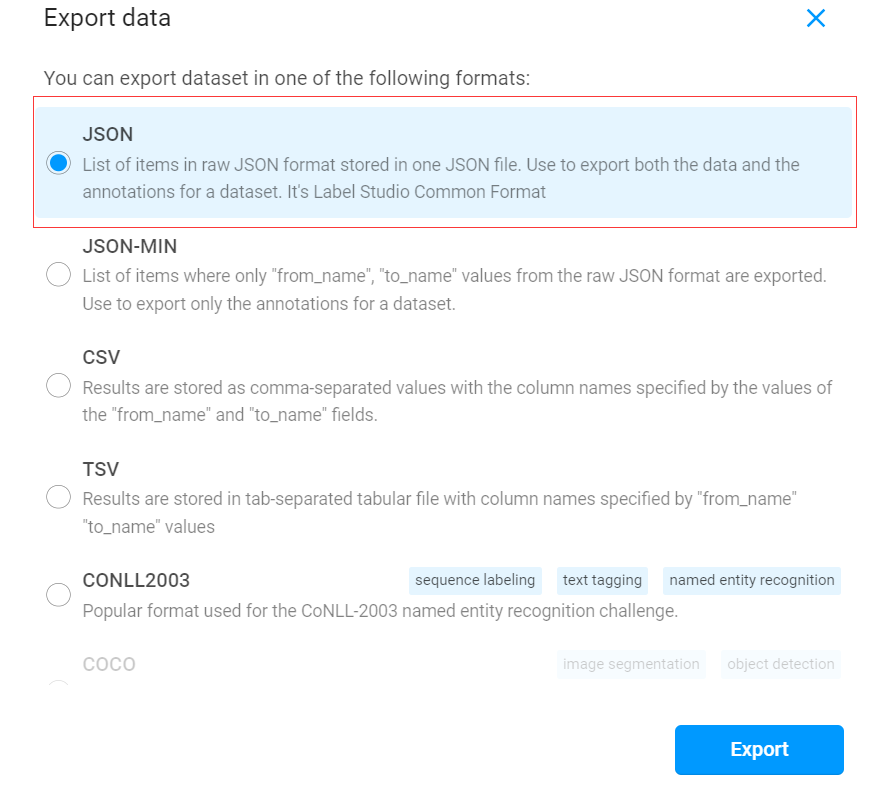
标注完毕后,可导出为json格式的文件,以便用于转化为BIO格式。
在进行NER任务时,通常会将标注好的数据转化为BIO(Begin-Inside-Outside)格式,以便于训练NER模型。BIO格式将每个词标注为实体的起始位置(B-实体类型)、实体内部(I-实体类型)、或不属于任何实体(O)。
代码转换
在Label-Studio中,可以通过一些脚本或工具将标注好的数据转化为BIO格式。以下是一个简单的示例Python脚本,用于将标注好的数据转化为BIO格式:
- # -*- coding: utf-8 -*-
- import json
-
- def json_to_bio(json_file, bio_file):
- with open(json_file, 'r' , encoding='utf-8') as f:
- data = json.load(f)
-
- with open(bio_file, 'w' , encoding='utf-8') as f:
- for item in data:
- text = item['data']['text']
- entities = item['annotations'][0]['result']
- bio_tags = get_bio_tags(text, entities)
- for token, tag in bio_tags:
- f.write(token + ' ' + tag + '\n')
- f.write('\n')
-
- def get_bio_tags(text, entities):
- bio_tags = ['O'] * len(text)
- for entity in entities:
- start = entity['value']['start']
- end = entity['value']['end']
- entity_type = entity['value']['labels'][0]
- for i in range(start, end):
- prefix = 'B' if i == start else 'I' if i > start else 'O'
- bio_tags[i] = prefix + '-' + entity_type
- return zip(text, bio_tags)
-
- if __name__ == '__main__':
- json_to_bio('project-7-at-2023-05-12-15-39-f5bc0cfc.json', 'work_project.txt')

这个脚本会将输入的数据转化为BIO格式,并输出结果,方便后续的模型训练和评估。
通过Label-Studio进行NER任务的数据标注,并将标注好的数据转化为BIO格式,可以为NER模型的训练提供高质量的标注数据,从而提升模型的性能和效果。
在实际应用中,结合Label-Studio和BIO格式,可以更高效地完成NER任务,并为NLP应用的开发和部署提供可靠的支持。

