- 1一个RtspServer的设计与实现和RTSP2.0简介_rtsp server
- 2SystemVerilog(一)-RTL和门级建模
- 32019第十二届“认证杯”数学建模(第一阶段)_2019年认证杯数学建模比赛第一阶段
- 4Navicat 导入数据时报Incorrect datetime value: '0000-00-00 00:00:00.000000' 错误
- 5基于HTML+CSS+JavaScript制作学生网页——外卖服务平台10页带js 带购物车_外卖网站制作
- 6提升编程效率的神器-百度Comate AI编程助手_百度编程助手 私有化部署
- 7电子烟单片机方案开发,32位单片机PY32F030电子烟解决方案
- 8单片机设计_液晶滚动显示(AT89C51、LCD1602)_设计单片机空间控制led1602字符液晶滚动,三个按键按钮分别实现液晶垂直或水平滚动
- 9运维系列(亲测有效):Docker pull拉取镜像报错“Error response from daemon: Get “https://registry-1.docker.io/v2”解决办法_docker pull error response
- 10Layer2之争:短期看Optimism 长期看zkSync?_layer2之争:短期看optimism 长期看zksync?
Mamba解读(FlashAttention,SSM,LSSL,S4,S5,Mamba)_mamba算法
赞
踩
Sequence model
seq2seq任务将 输入序列
x
(
t
)
x(t)
x(t) 映射为 输出序列
y
(
t
)
y(t)
y(t),其中序列可以是离散的(如文本),也可以是连续的(如音频)。在大多数情况下我们使用离散的(连续序列可以经过采样得到离散序列):
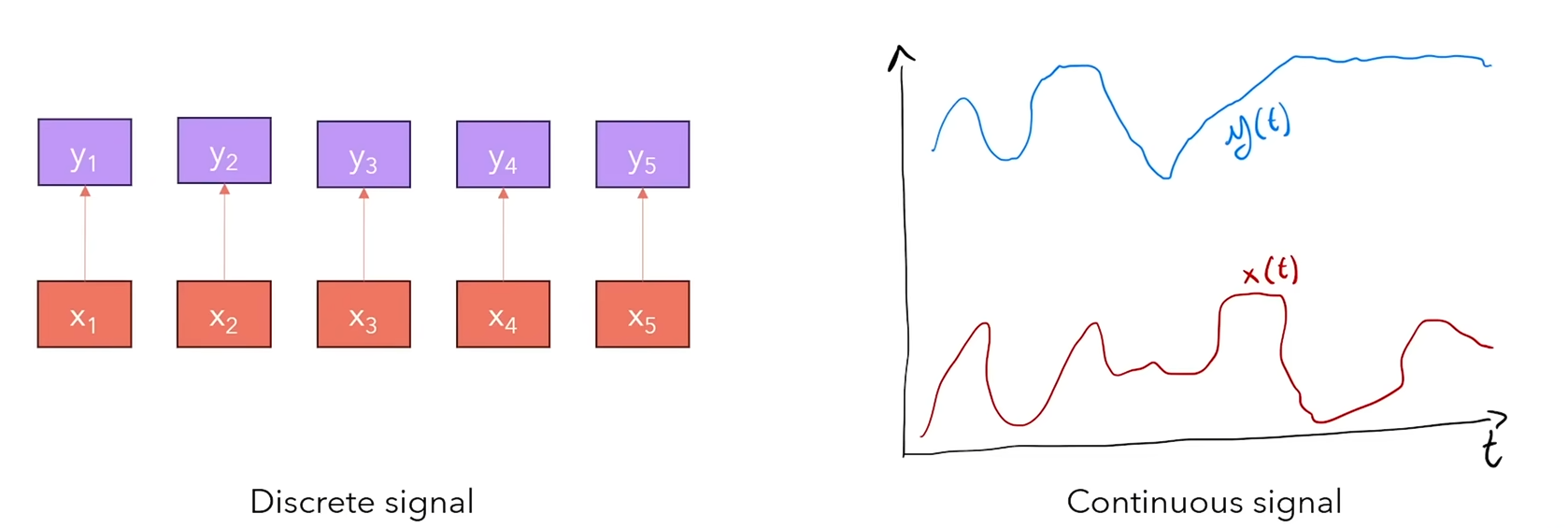
常见序列建模任务seq2seq架构:
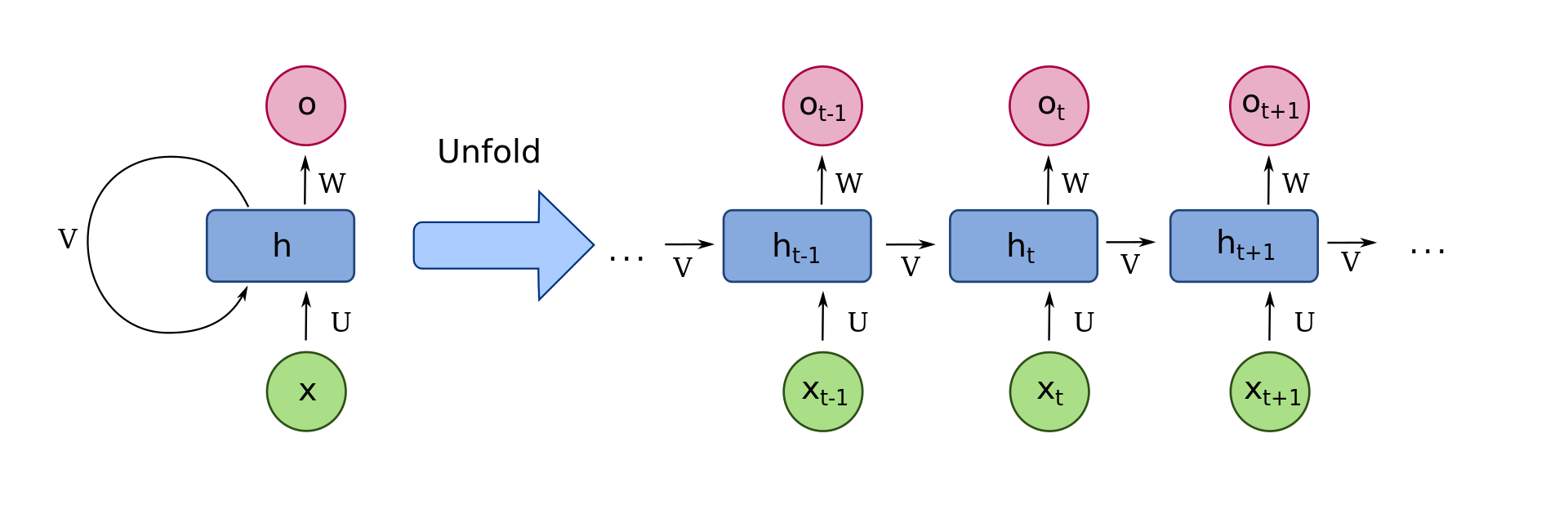
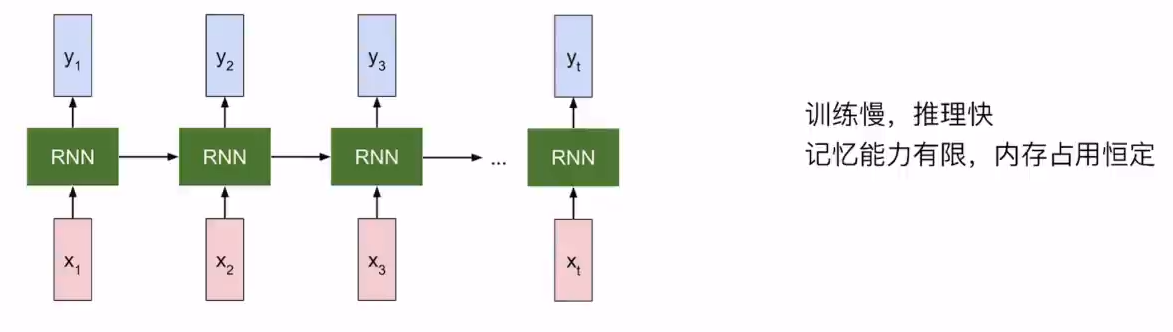
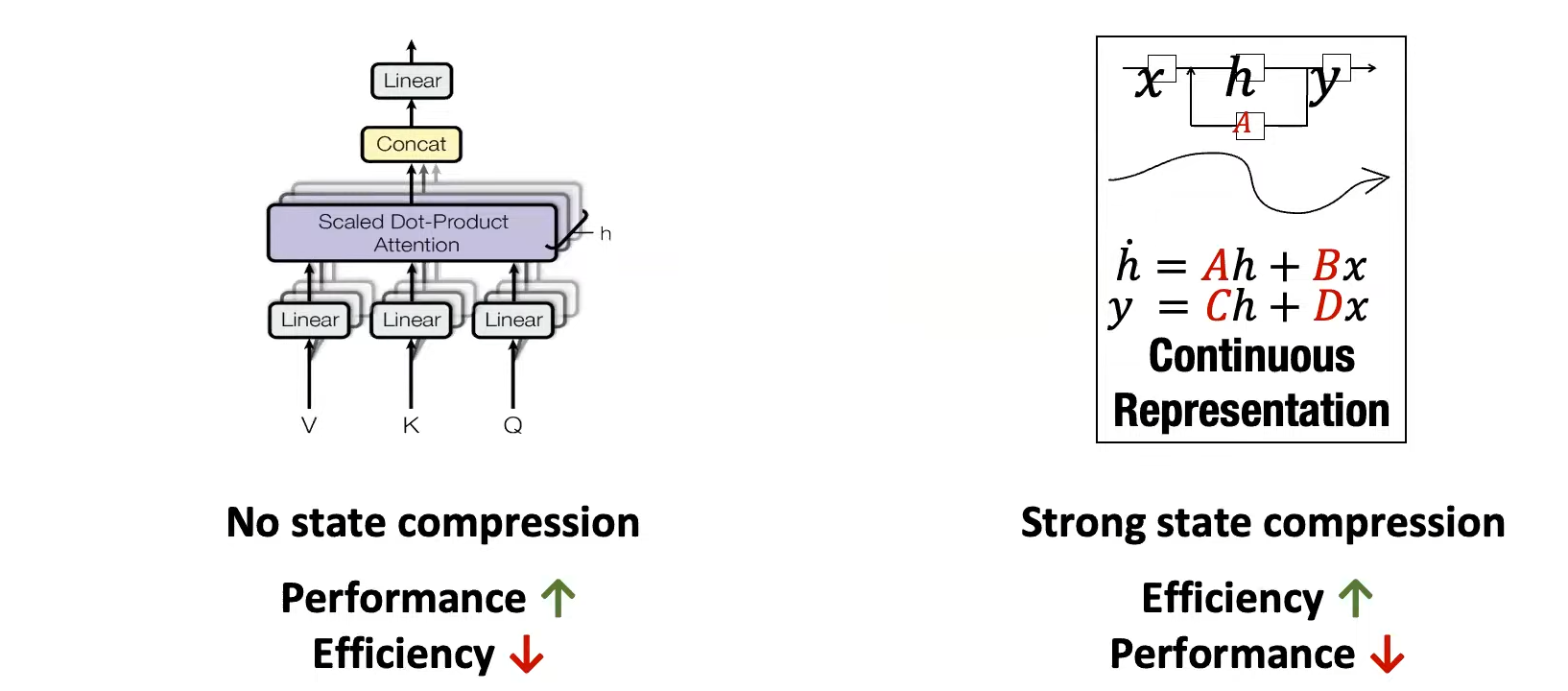
RNN:无限的context window,输入seq长度为N,内存占用 d ( d < < N ) d(d<<N) d(d<<N)
- Training: O ( N ) O(N) O(N),不可并行训练。
- Inference:对每个增加的token的推理时间恒定。
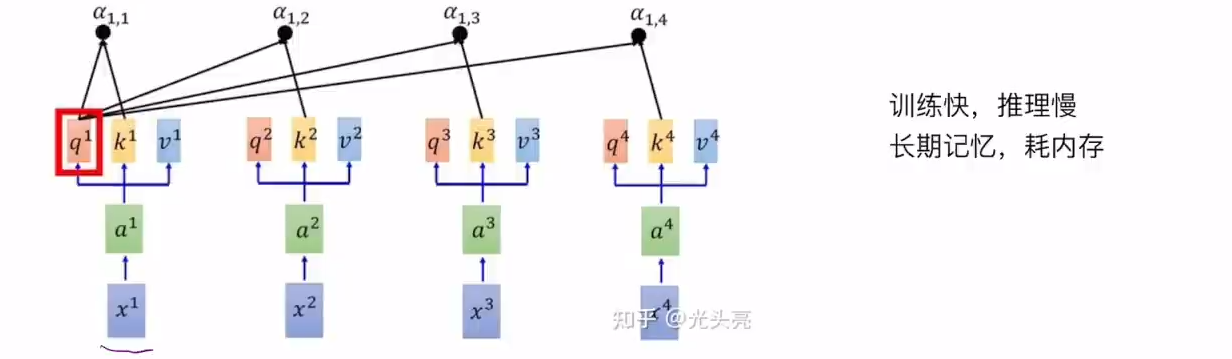
Transmformer:有限的context window,输入seq长度为N,内存占用 N 2 N^2 N2
- Training: O ( N 2 ) O(N^2) O(N2),可并行训练,使用self-attention。
- Inference: O ( N ) O(N) O(N),对每个增加的token的推理时间会平方增加(如增加第N个token,需要将其和前N-1个token进行计算)。
因此我们希望构造一个Model可以实现:
- 像Transformer一样可并行训练,又可以像RNN一样线性缩放到长序列。
- 同时在推理时,像RNN一样,对每个增加的token,增加的推理时间恒定。
这就引出了State Space Model (SSM)!
Scale and Efficiency
Model的Scale Law在最近几年展现出巨大的涌现能力,随之而来的挑战就是Efficiency效率问题。两个解决方案是,FlashAttention和Mamba:
FlashAttention
Motivation
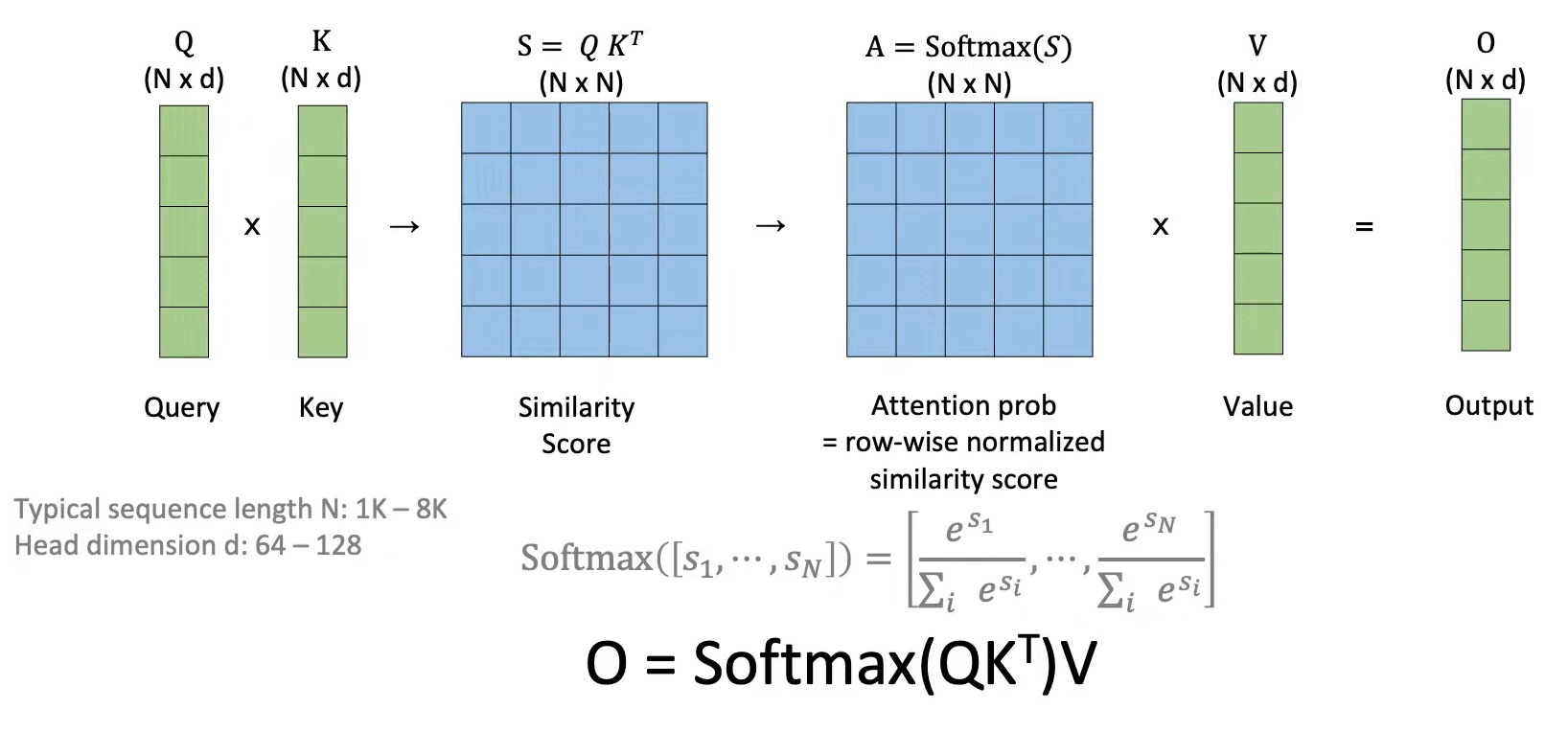
Transformer由Endoer组成(Attention+MLP),根据Attention的原理,Attention scales是sequence length
N
N
N的平方
O
(
N
2
)
O(N^2)
O(N2),加倍sequence length意味着4倍的推理时间和内存占用。
对于Modeling long sequence context,GPU内存读写是制约Attention计算效率的瓶颈,FlashAttention可以减少GPU内存读写,同时支持更长的sequence tokens交互:可以实现更快、更长上下文的Transformer。现在已经广泛应用于各大深度学习库,如Torch、Hggingface等。

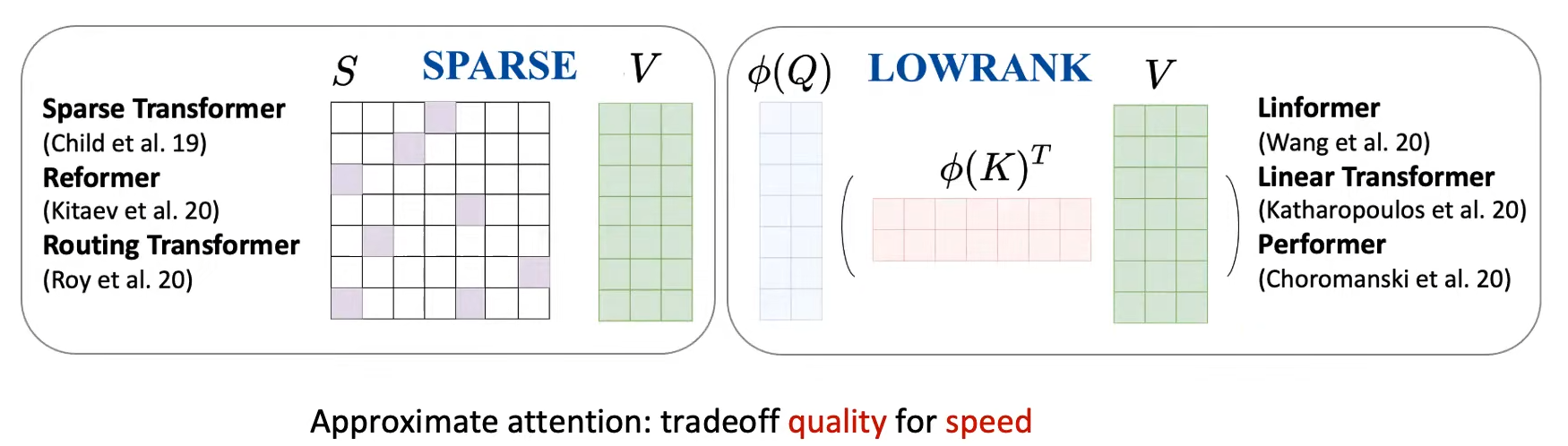
在FlashAttention之前,已经有很多算法,尝试解决Modeling long sequence问题:核心思路都是提出近似N^2的Attention操作,损失一些Attention的质量,来提升计算速度。但工业界训练LLM时,并不认可这些花哨的近似方法,原因如下:(1)这些理论上的加速Attention的方法使得模型质量更差;(2)这些方法,只是在理论上减少了浮点数运算,但不减少GPU的IO,真正的瓶颈是Attention中large matrix的IO速度,并不会真正的加速计算和节省GPU内存!
Method
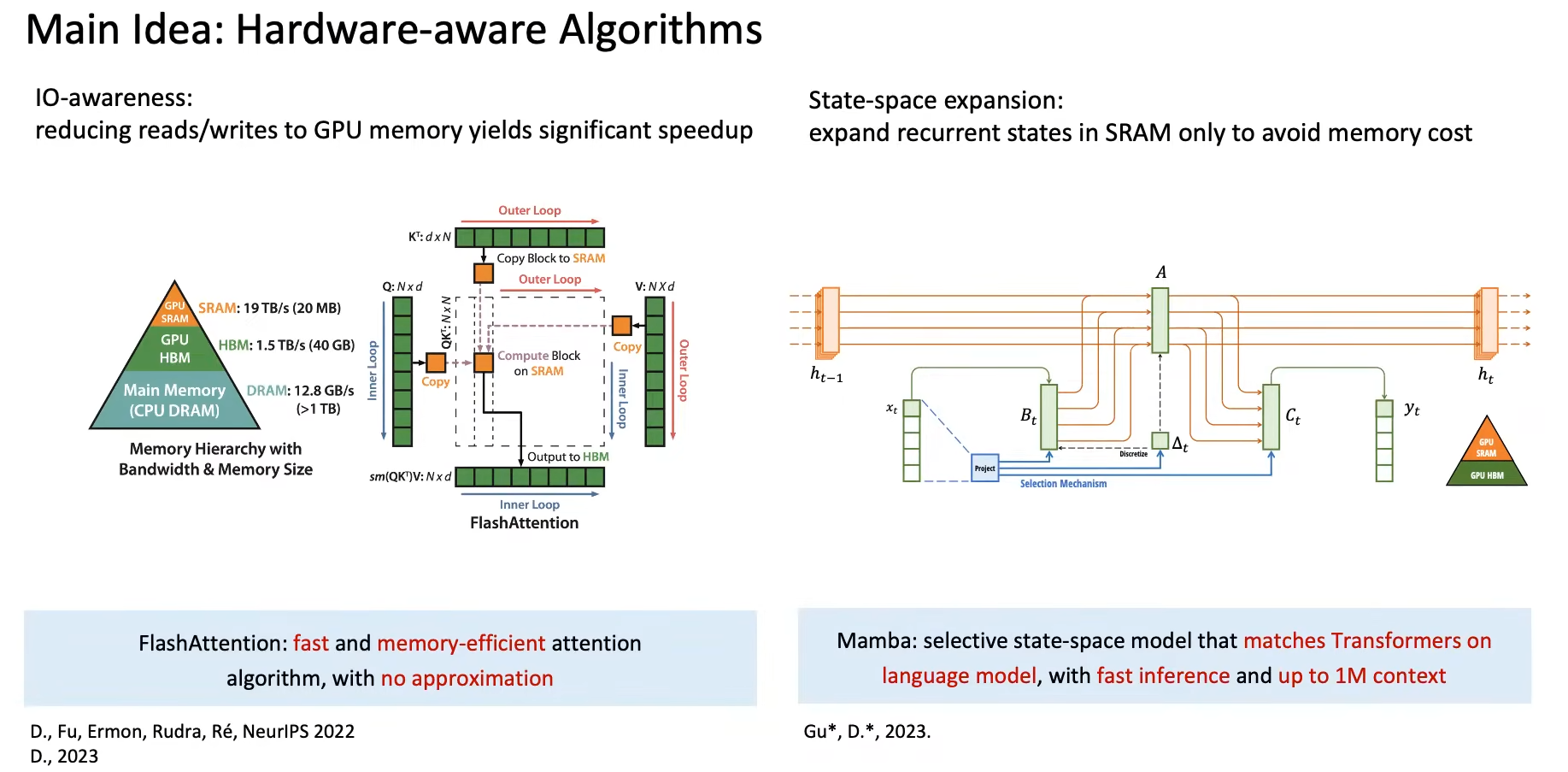
为了解决GPU内存读写引发的Attention效率问题,我们必须了解硬件:(下图是GPU的成千上万个SM计算单元中的一个)
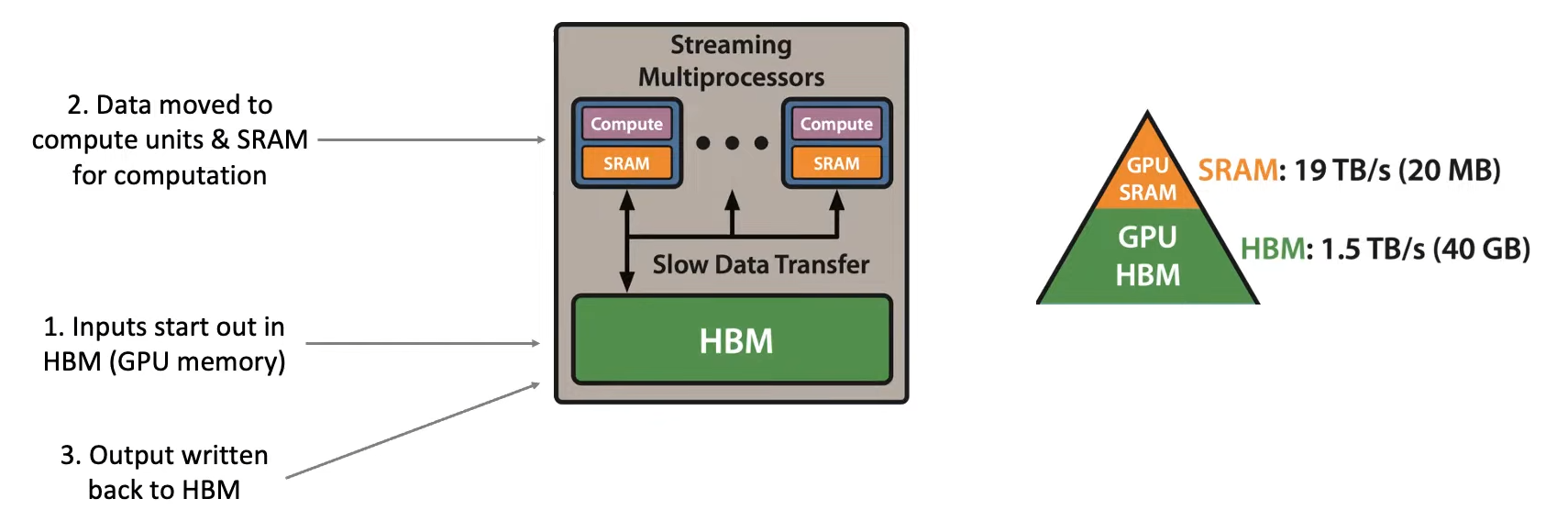
HBM是高带宽存储器,即GPU的内存(GPU Memory)。数据处理速度慢,但存储空间大。Compute是GPU的计算组件,用于执行矩阵乘法/加法等。SRAM是GPU的Cache,用于HBM和Compute之间的数据缓存。数据处理速度快,但存储空间小。
GPU工作时:①data传入HBM,②data从HBM传入SRAM和Compute进行运算,③result再写回HBM。问题在于HBM和SRAM的传输速度很慢!

FlashAttention的核心思想 是 减少GPU中HBM和SRAM之间的内存读写(Tiling 和 Recomputation):
-
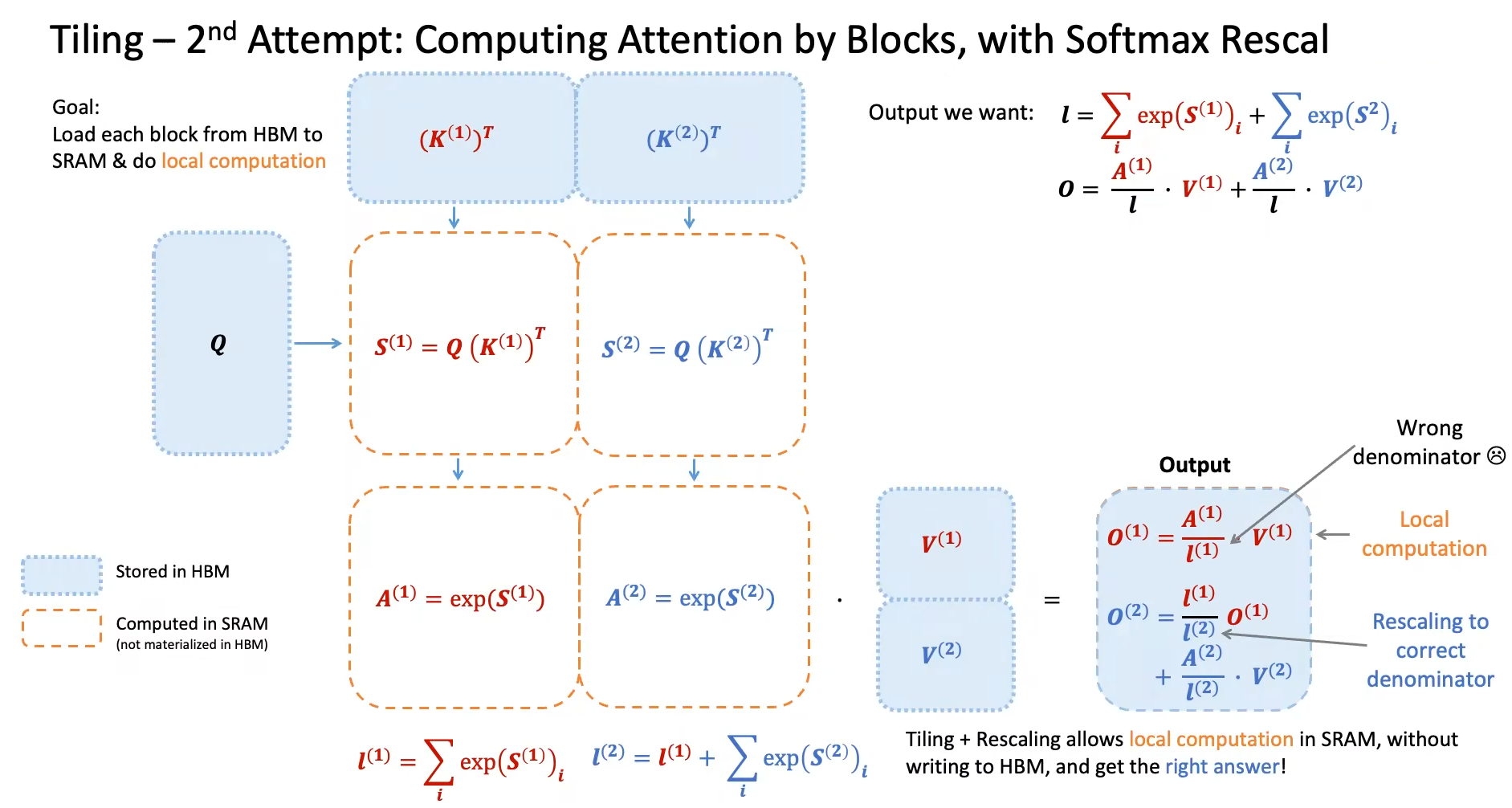
Softmax Tiling:将
Q K V分块,从HBM送入SRAM计算Attention(使用ReScaling技巧得到Local分块计算的正确Attention结果,否则Softmax除的那个系数将是错误的)。
-
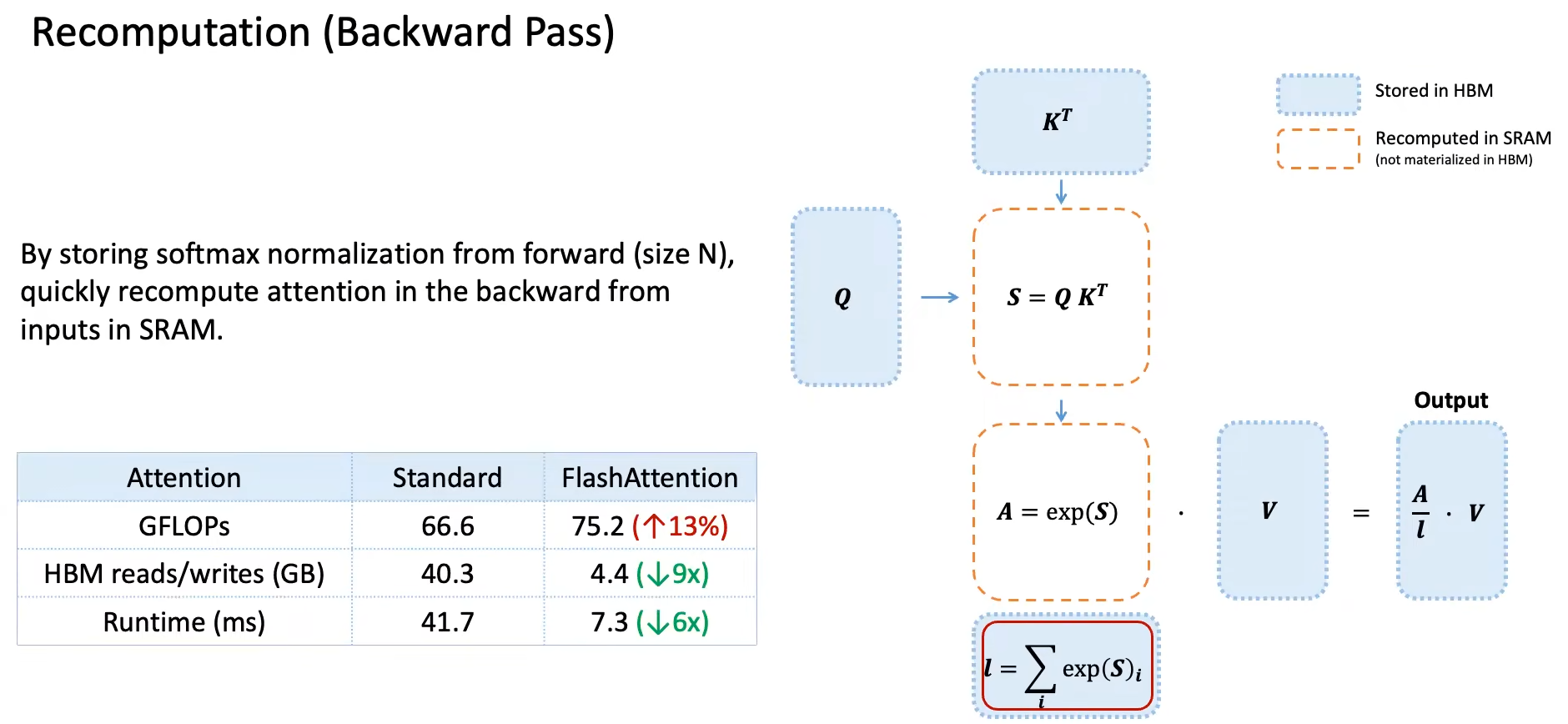
Backward Recomputation:backward计算梯度时需要forward时Attention输出的计算结果。但我们forward后不存储
attn_matrix,只存储softmax除的系数,而是在backward时重新计算attn_matrix。因为重新计算is cheap,GPU读写is expensive!因此即使计算量增加了,但总体速度还是提升了。
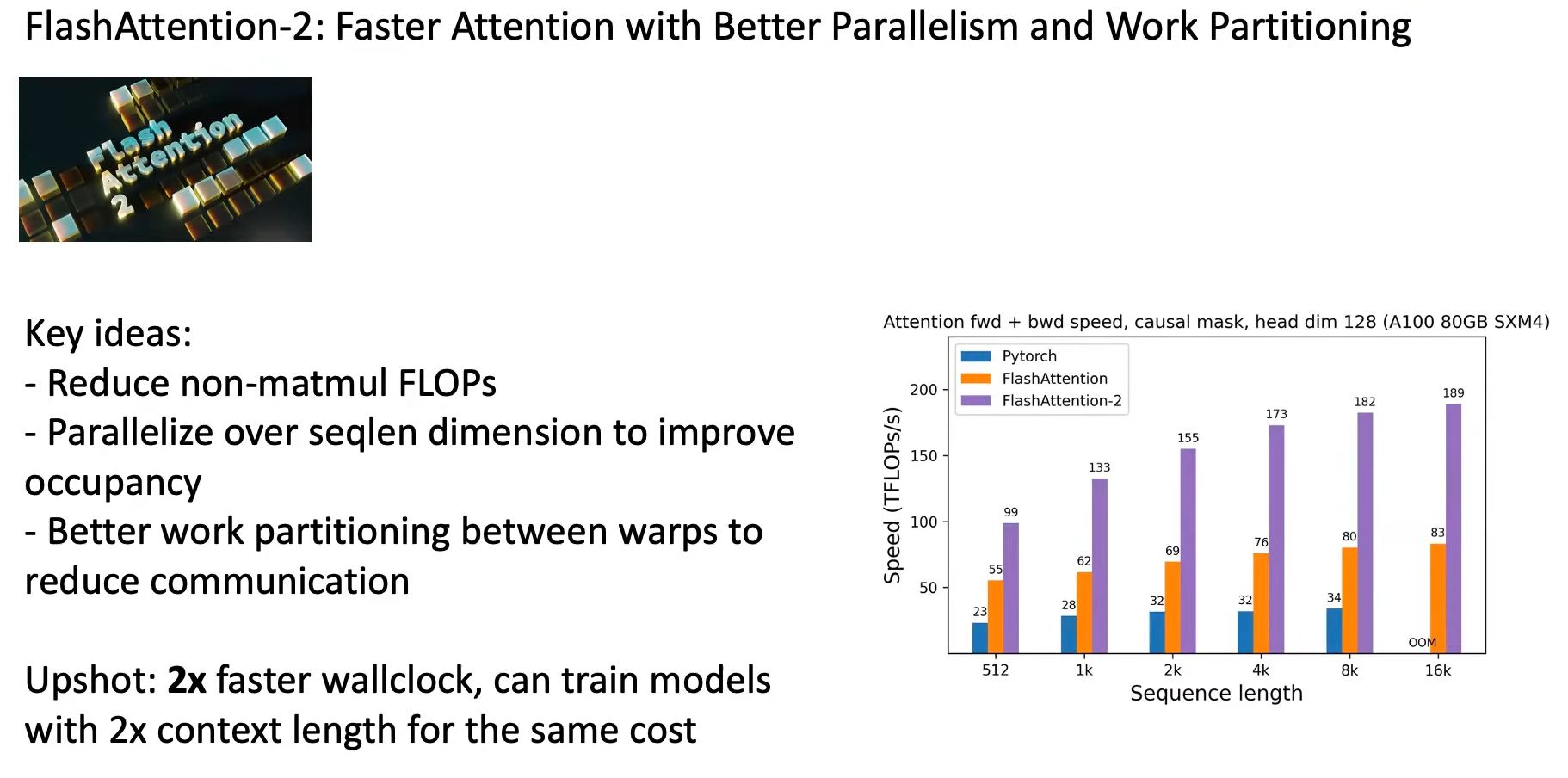
FlashAttention-2 在 FlashAttention-1 的基础上进行了并行优化,将speed和sequence length都提升了2倍。
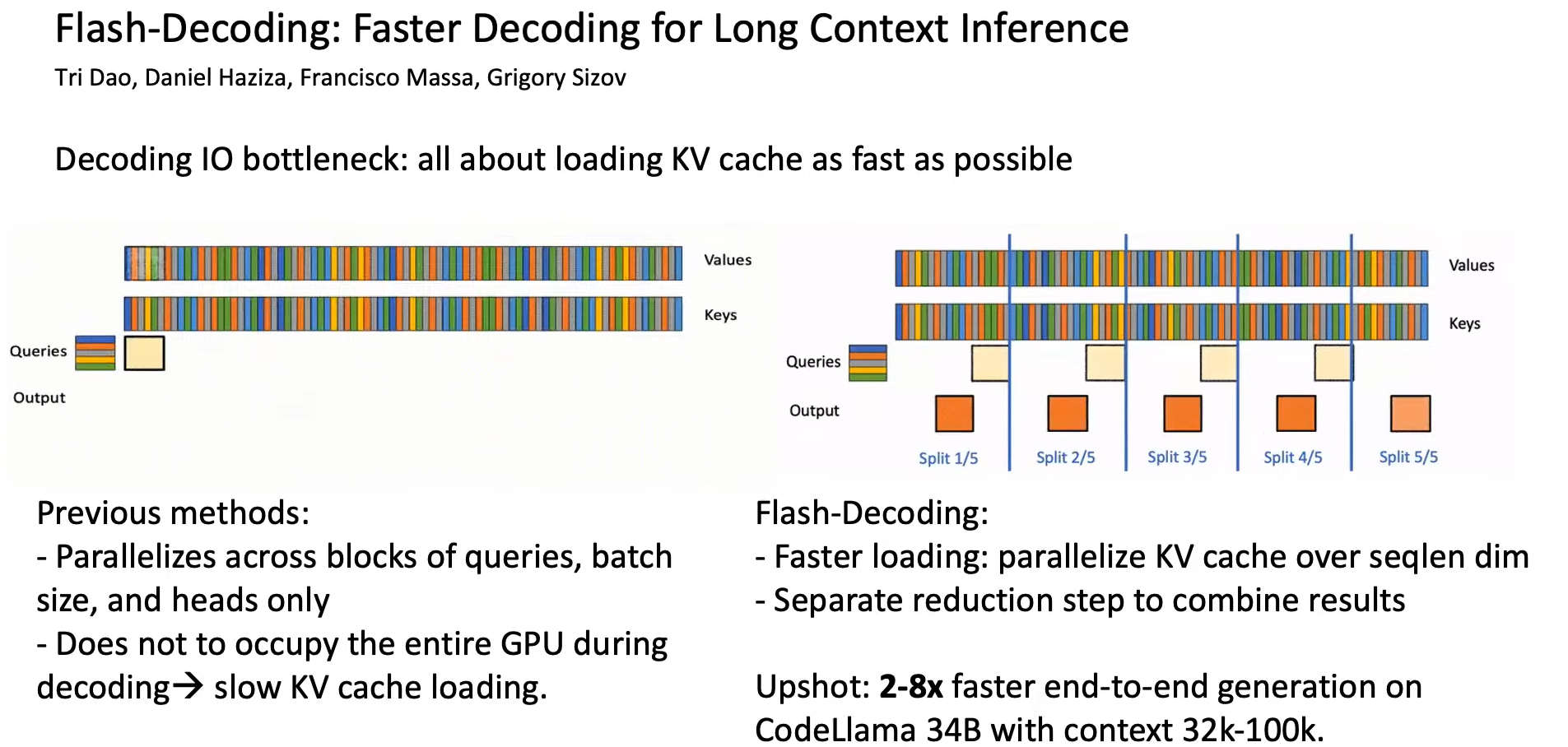
FlashDecoding
当我们做Long squence的Attention时,仅仅用FlashAttention分块计算,KV Cache可能依然非常的长(包含history context),而Q非常的短(只有几个tokens)。因此我们使用FlashDecoding按照seq_len维度进行划分KV,和FlashAttention一样分块计算,只是分的块更加细粒度了,这样可以进一步提升GPU的并行处理能力。
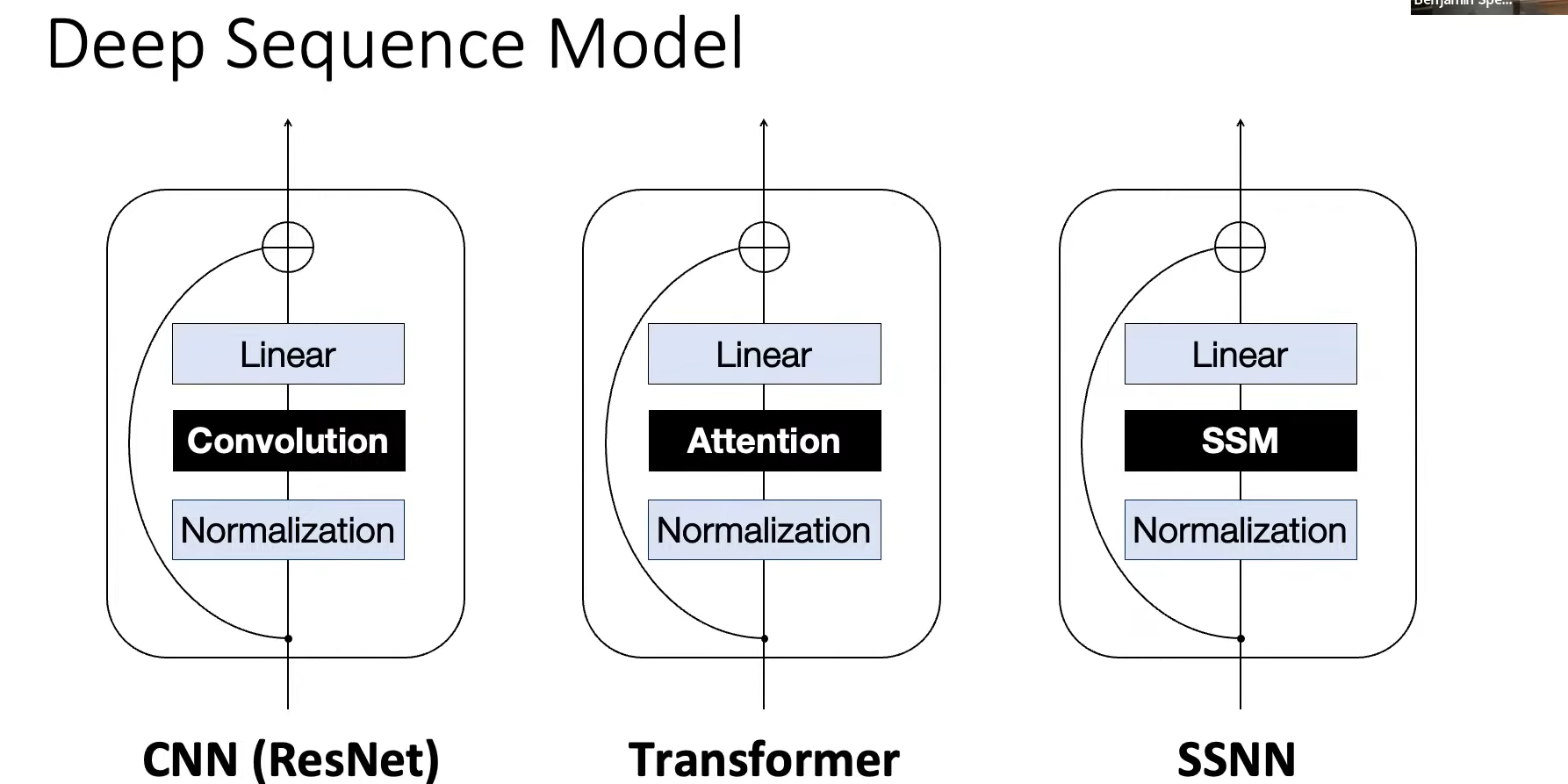
Mamba
虽然FlashAttention可以优化Transformer的速度和内存占用,但Transformer本质仍然是
O
(
N
2
)
O(N^2)
O(N2)的模型(N是sequence length),FlashAttention没有从本质降低计算量,在推理时依然需要保持KV Cache,这是令人头疼的。因此我们希望从本质出发,去寻找一个更加优秀的结构,去替代Attention:
- RNN:可以处理无限的
sequence length(sequence length就是timestep大小),训练慢(需要沿着sequence length逐个计算,每个token计算都进行一次backword),推理快(每个timestep的隐藏状态可以重用,可并行)。
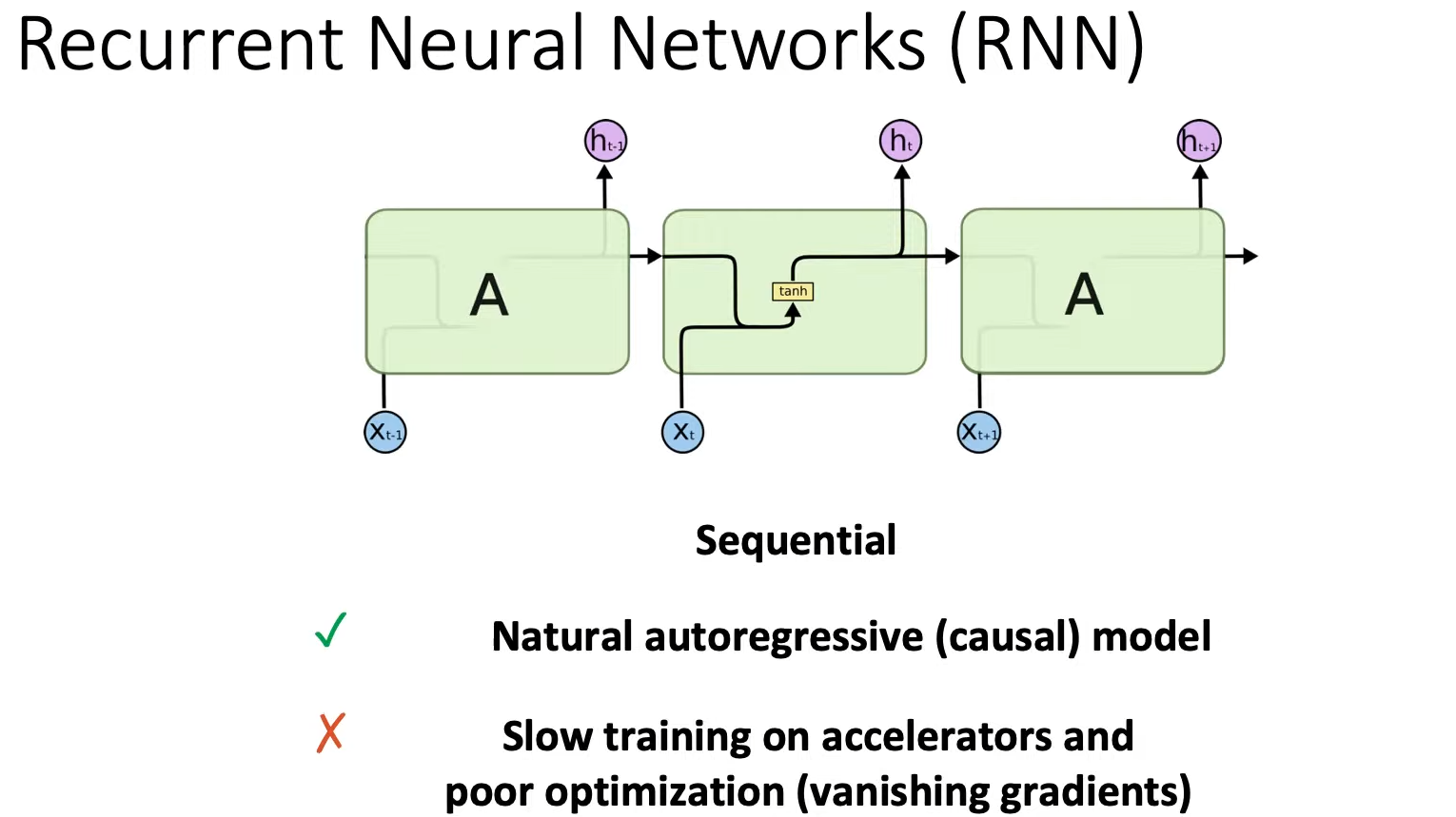
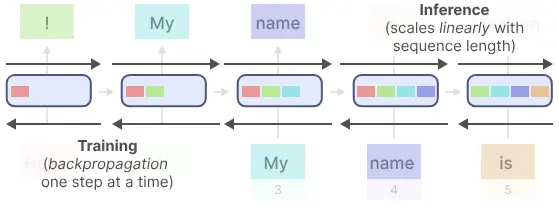
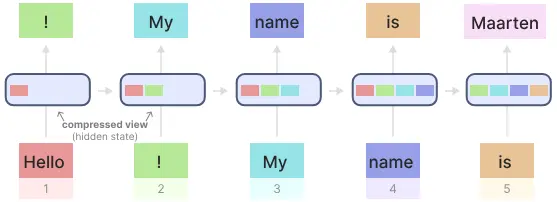
相较于Attention,RNN的优点是在推理生成每个token输出时,只需要考虑之前的隐藏状态和当前的输入。 它可以防止重新计算所有先前的隐藏状态,而这正是 Attention 所做的。缺点:快速遗忘。如最后一个隐藏状态在生成名称“Maarten”时,可能不再包含有关单词“Hello”的信息。 随着时间的推移,RNN 往往会忘记信息,因为它们只考虑先前的一个状态。
- Attention:不能处理无限长度(存储/时间和
sequence length成平方关系 O ( N 2 ) O(N^2) O(N2)),训练快(只需要一次矩阵乘法,可并行),推理慢(需要计算每个注意力权重)。
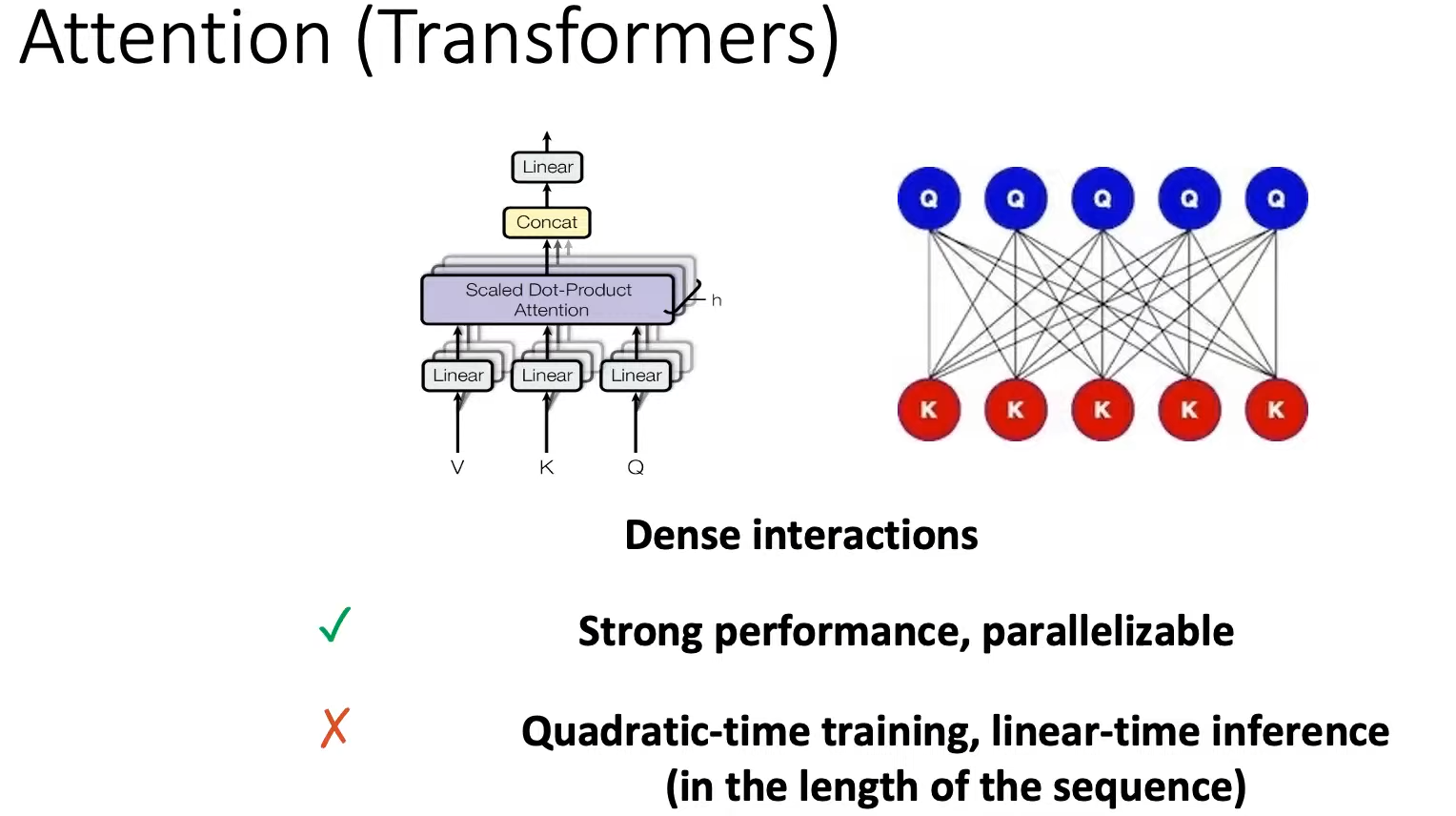
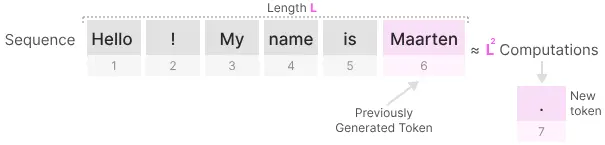
缺点: 当生成下一个标记时,即使我们已经生成了一些前面的标记,我们也需要重新计算整个序列的Attention。
- SSM:可以处理无限长度(
O
(
N
)
O(N)
O(N)),训练快,推理快。由
state equation状态方程和output equation输出方程组成。
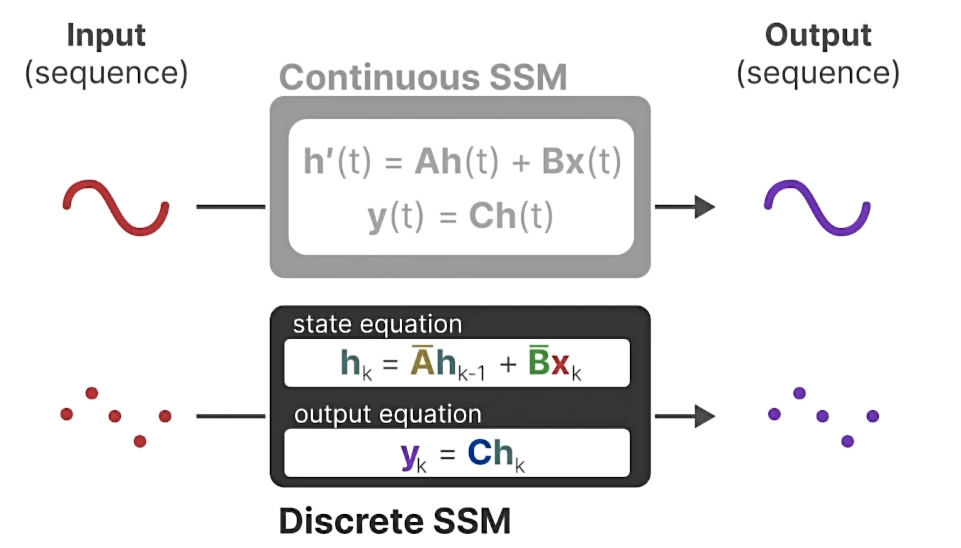
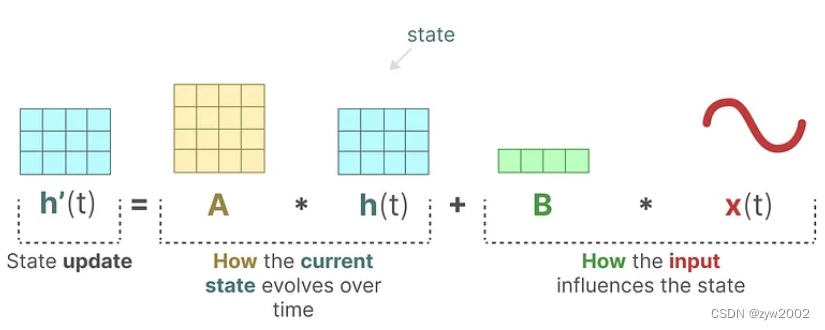
State-Space Models(SSM)
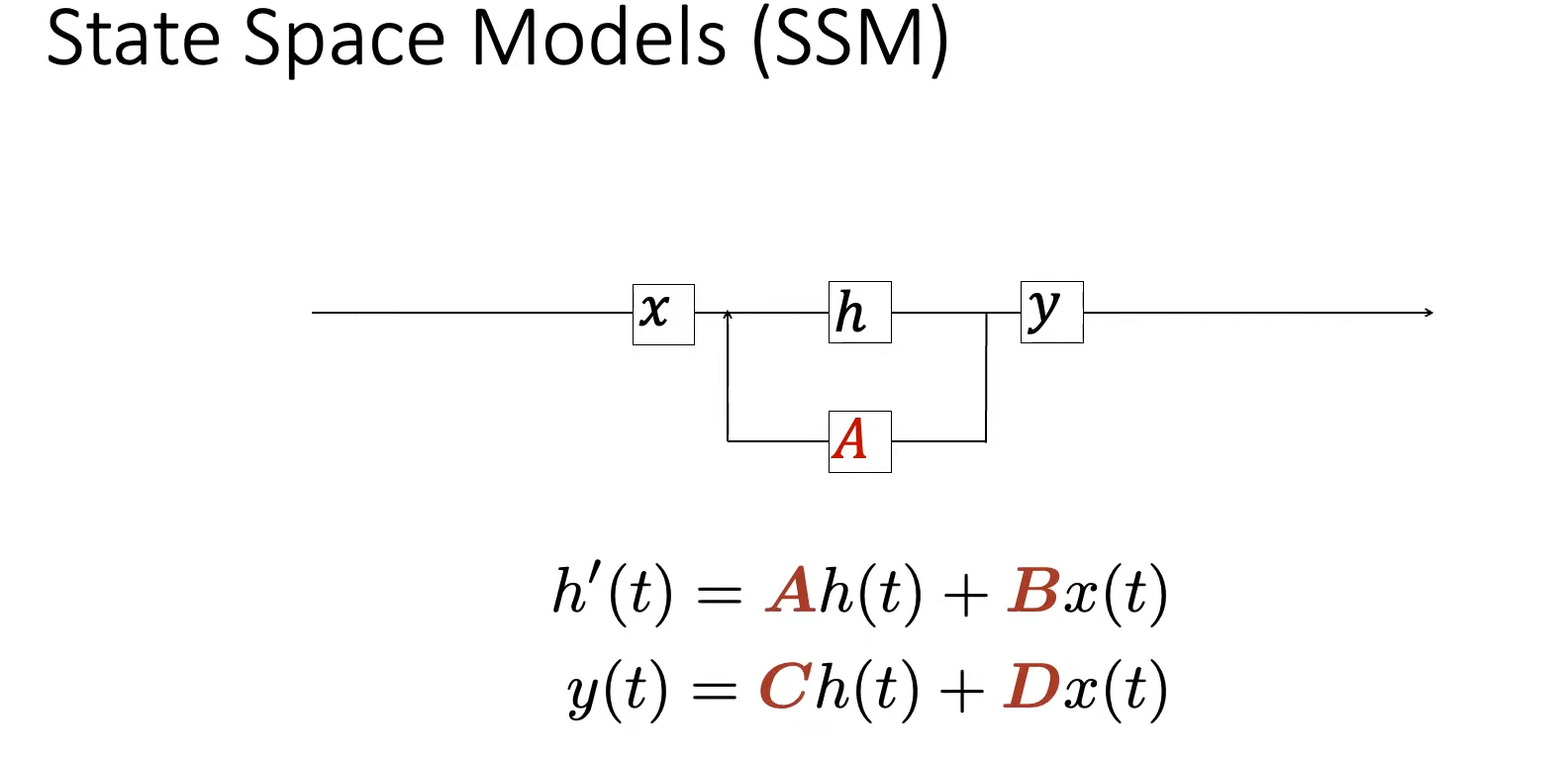
state equation状态方程:矩阵A和矩阵B分别控制着 当前状态
h
(
t
)
h(t)
h(t) 和 输入
x
(
t
)
x(t)
x(t) 如何影响状态的变化到
h
′
(
t
)
h'(t)
h′(t)
output equation输出方程:描述了状态
h
(
t
)
h(t)
h(t) 如何转换为输出
y
(
t
)
y(t)
y(t)的一部分 (通过矩阵C),以及输入
x
(
t
)
x(t)
x(t)如何影响输出
y
(
t
)
y(t)
y(t)(通过矩阵D)
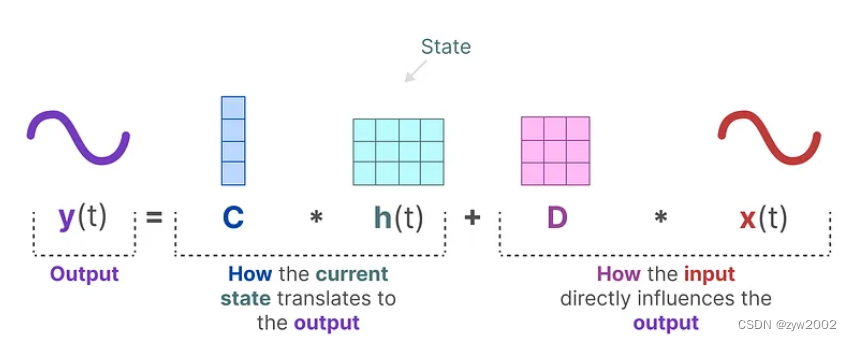
上述的A,B,C,D都是可学习的参数
将上述的两个方程整合在一起,得到了如下的结构:
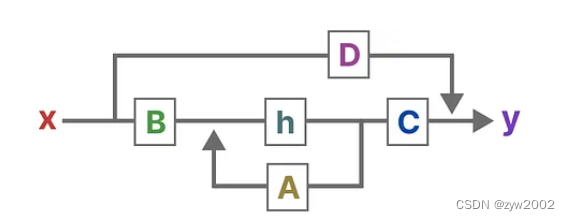
让我们逐步了解一般技术,以了解这些矩阵如何影响学习过程:
step1:假设我们有一些输入信号 x(t),该信号首先乘以矩阵 B,该矩阵描述了输入如何影响系统。

step2:更新后的状态(类似于神经网络的隐藏状态)是一个包含环境核心“知识”的潜在空间。 我们将状态与矩阵 A 相乘,矩阵 A 描述了所有内部状态如何连接,因为它们代表了系统的底层动态。(您可能已经注意到,矩阵 A 在创建状态表示之前应用,并在状态表示更新后更新)
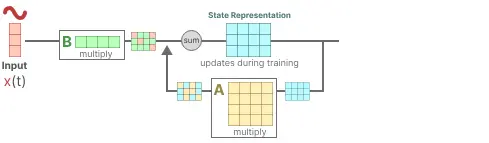
step3:然后,我们使用矩阵 C 来描述如何将状态转换为输出。
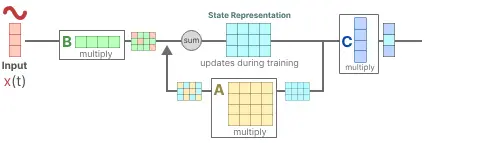
step4:最后,我们可以利用矩阵 D 提供从输入到输出的直接信号。 这通常也称为跳跃连接。
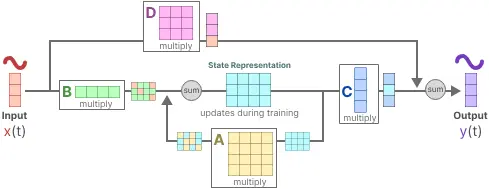 这两个方程共同旨在根据观测数据预测系统的状态。 由于输入预计是连续的,因此 SSM 的主要表示是连续时间表示。
这两个方程共同旨在根据观测数据预测系统的状态。 由于输入预计是连续的,因此 SSM 的主要表示是连续时间表示。

Mamba 基础讲解【SSM,LSSL,S4,S5,Mamba】
Mamba复现与代码解读
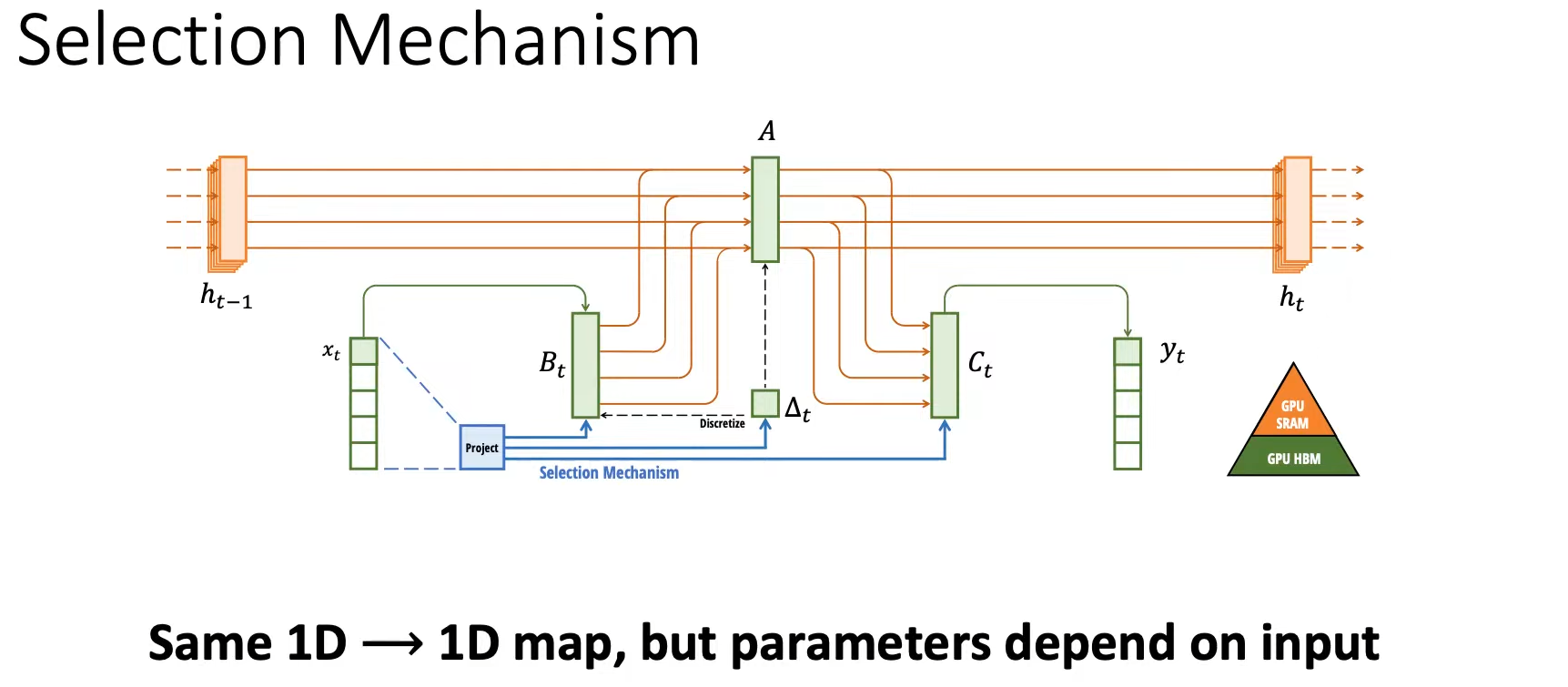
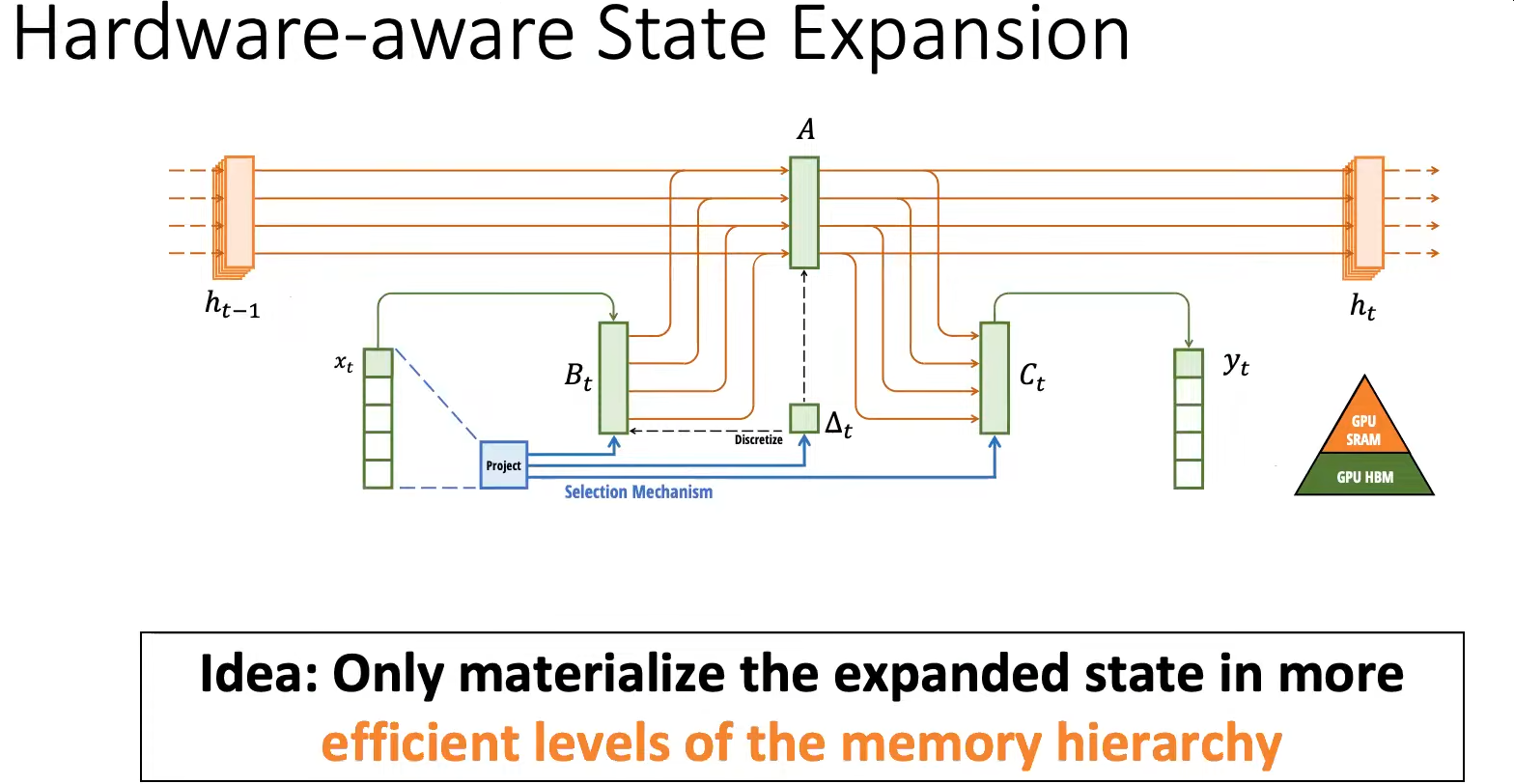
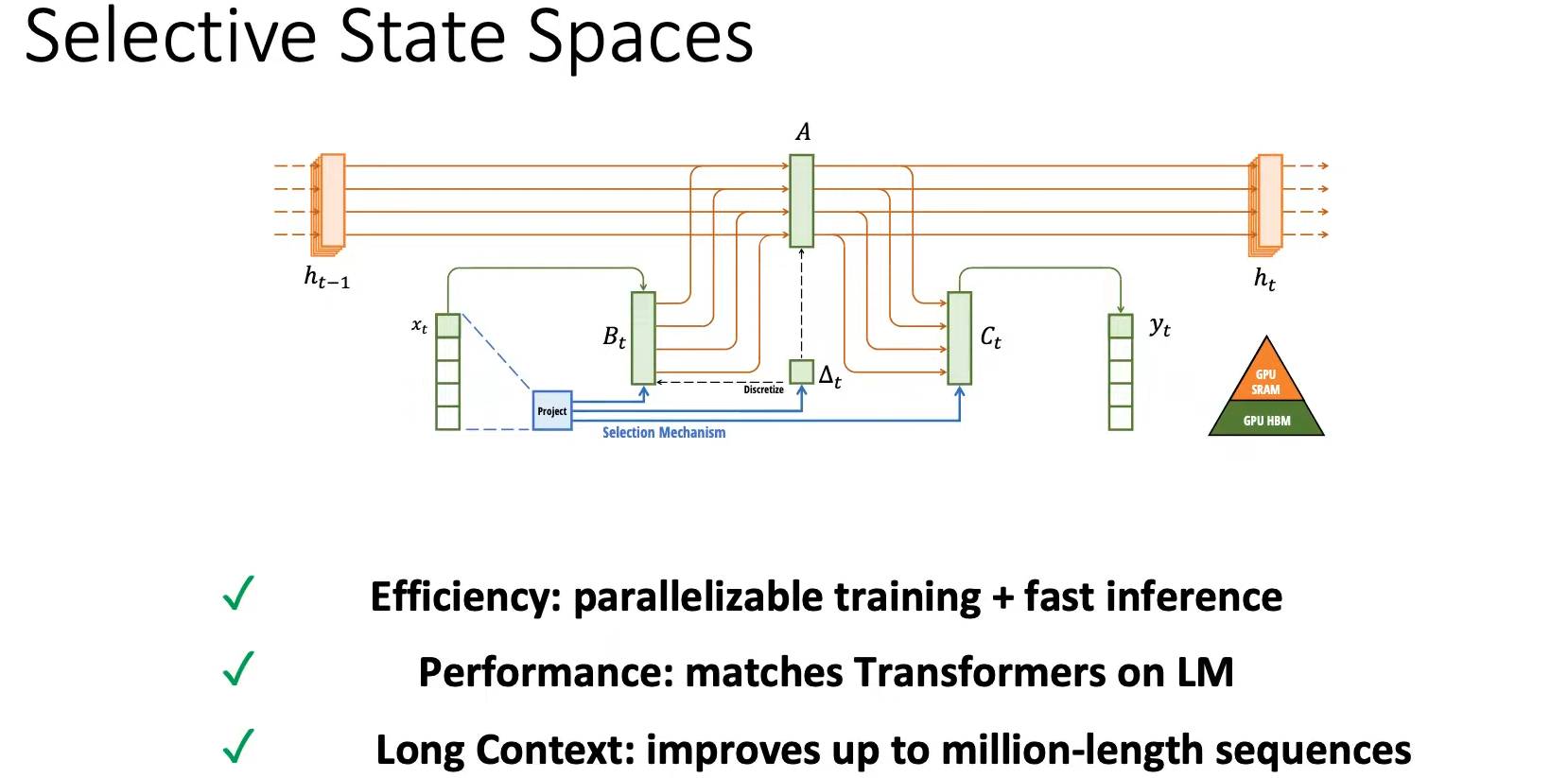
Selective State Space Models(Mamba)
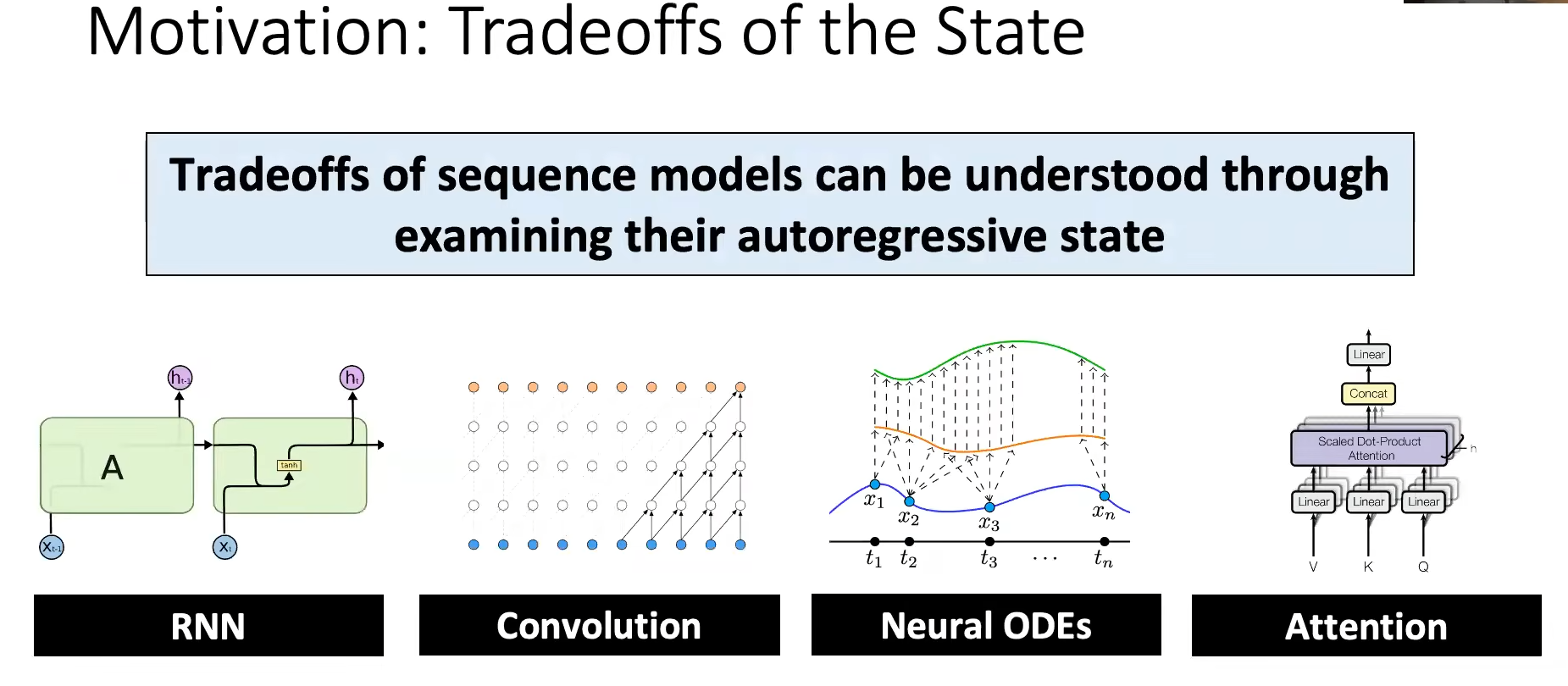
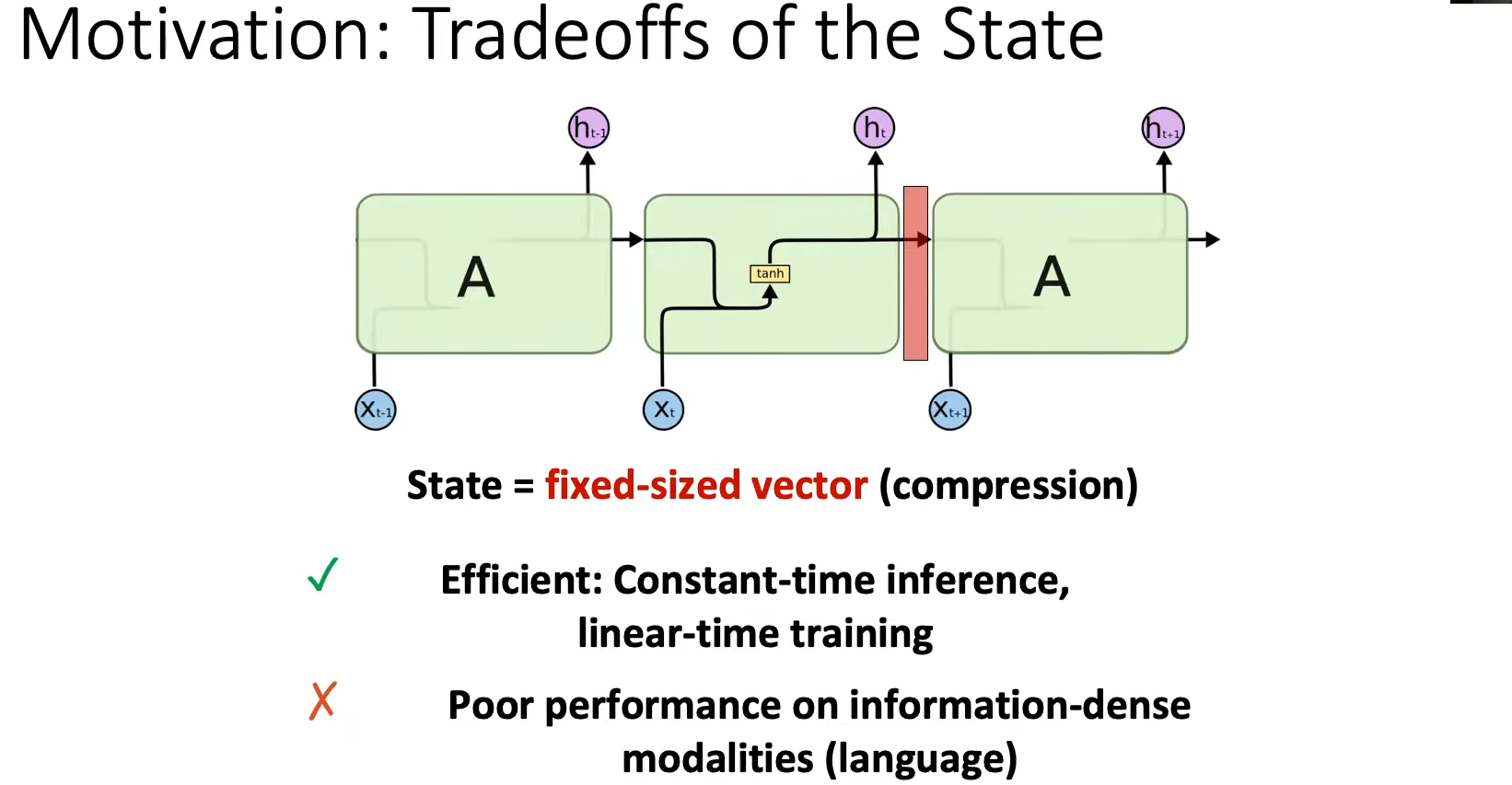

S4将整个history_context总结为一个fixed_context,而Mamba提出的Selective机制,依然存储整个history_context,但选择将部分history_context总结为一个fixed_context。