
- 1汽车电子相关术语_ivi和domain controller
- 2iOS技术之Xcode 15打包报错:Command PhaseScriptExecution failed with a nonzero exit code_xcode15.3 真机 command phasescriptexecution failed w
- 3socket编程一:socket是什么?套接字是什么?_socket编程 为什么是socket
- 4关于前端技术文章_前端写一个关于技术方面的文章
- 5C-Pack论文解读
- 6mysql忘记密码怎么解决_mysql 忘记密码,通宵都要看完这个大数据开发关键技术点_进入mysql 密码
- 7vscode配置c++11_vscode c++11
- 8YOLOv8算法改进【NO.100】引入最新发布AKConv_改进yolov8
- 9Flink 内容分享(六):Fink原理、实战与性能优化(六)_flinkvalue.f0
- 10uniapp导入导出Excel_uniapp 导出导入
Selenium自动化测试工具使用教程_selenium使用教程
赞
踩
目录
1 为什么使用
1.1 selenium简介
Selenium 是支持 web 浏览器自动化的一系列工具和库的综合项目。
Selenium 有很多功能, 但其核心是 web 浏览器自动化的一个工具集, 它使用最好的技术来远程控制浏览器实例, 并模拟用户与浏览器的交互。
它允许用户模拟终端用户执行的常见活动;将文本输入到字段中,选择下拉值和复选框,并单击文档中的链接。 它还提供许多其他控件,比如鼠标移动、任意 JavaScript 执行等等。
它提供了扩展来模拟用户与浏览器的交互,用于扩展浏览器分配的分发服务器, 以及用于实现 W3C WebDriver 规范 的基础结构, 该规范允许您为所有主要 Web 浏览器编写可互换的代码。
Selenium,作为测试自动化工具,支持将简单测试扩展为 在大型分布式环境,以及不同操作系统环境上运行的多个浏览器的测试。
1.2 Selenium 不同版本的区别
项目始于2004年,至今已经发展到selenium 4。不同版本的区别,参见文章Selenium 不同版本的区别https://blog.csdn.net/seagal890/article/details/114493064
1.3 支持的浏览器
| 图标 | 浏览器 | 备注 |
|---|---|---|
 | 火狐浏览器(Firefox) | GeckoDriver 由 Mozilla 实现和支持,请参阅他们的 文档 以了解支持的版本。 |
 | 谷歌浏览器(Chrome) | ChromeDriver 由 Chromium 项目支持,请参阅他们的 文档 以获取任何兼容性信息。 |
 | 苹果浏览器(Safari) | SafariDriver 由 Apple 直接支持,有关更多信息,请查看他们的 文档 |
 | IE浏览器(IE) | 仅支持版本11,并且需要额外 配置。 |
 | Edge浏览器(Edge) | Microsoft 正在实施和维护 Microsoft Edge WebDriver,请参阅其 文档 以获取任何兼容性信息。 |
 | 欧朋浏览器(Opera) | OperaDriver 由 Opera Software 支持,请参阅其 文档 以了解支持的版本。 |
经测试,使用谷歌内核的国产浏览器,均可支持。例如360浏览器的极速模式,红莲花安全浏览器等。
1.4 支持的操作系统
| 图标 | 浏览器 | 备注 |
|---|---|---|
 | Windows | 目前 Microsoft 仍支持的大多数 MS Windows 版本都应可与 Selenium 配合使用。尽管我们使用最新的 MS Windows 来解决问题,但这并不意味着 Selenium 不会尝试支持不同版本的 Windows。这仅意味着我们不会持续在其他特定版本的 Windows 上运行测试。 |
 | macOS | 目前,在针对 Selenium 项目的自动化测试中不使用任何版本的 macOS。然而,该项目的大多数开发人员都使用最新版本的 macOS,我们将继续支持当前的稳定版本,以及常用的以前的版本。 |
 | Linux | 主要在 Ubuntu 上进行测试,但其他版本的 Linux 在浏览器制造商支持的情况下也应该可以工作。 |
经测试验证,centos7可以使用,银河麒麟可以使用。
1.5 selenium的常用工具
1.5.1 WebDriver
如果您开始使用桌面或移动网站测试自动化,那么您将使用 WebDriver APIs。 WebDriver 使用浏览器供应商提供的浏览器自动化 API 来控制浏览器和运行测试,这就像真正的用户正在操作浏览器一样。2018 年 6 月,WebDriver 成为 W3C 推荐标准。这是什么意思?主要浏览器供应商(Mozilla、Google、Apple、Microsoft)都支持 WebDriver,并不断努力改进浏览器和浏览器控制代码,这会导致不同浏览器之间的行为更加统一,从而使您的自动化脚本更加稳定。通过WebDriver的api,调用浏览器的驱动程序与浏览器进行交互。
1.5.2 Selenium IDE
Selenium IDE (Integrated Development Environment 集成开发环境) 是用来开发 Selenium 测试用例的工具.。这是一个易于使用的 Chrome 和 Firefox 浏览器扩展,通常是开发测试用例最有效率的方式。它使用现有的 Selenium 命令记录用户在浏览器中的操作,参数由元素的上下文确定。这不仅节省了开发时间,而且是学习 Selenium 脚本语法的一种很好的方法。
1.5.3 Grid
Selenium Grid允许您在不同平台的不同机器上运行测试用例。可以本地控制测试用例的操作,当测试用例被触发时,它们由远端自动执行。Selenium Grid可帮助您跨浏览器、版本和操作系统的多种组合运行自动化脚本,加快执行速度并减少自动化脚本的总体运行时间。
简而言之,Selenium IDE是为了方便录制脚本,前期可以辅助编写脚本;Selenium Grid是为了跨平台提升测试效率;WebDriver是脚本编写的核心。
1.5.4 selenium集合功能组成图
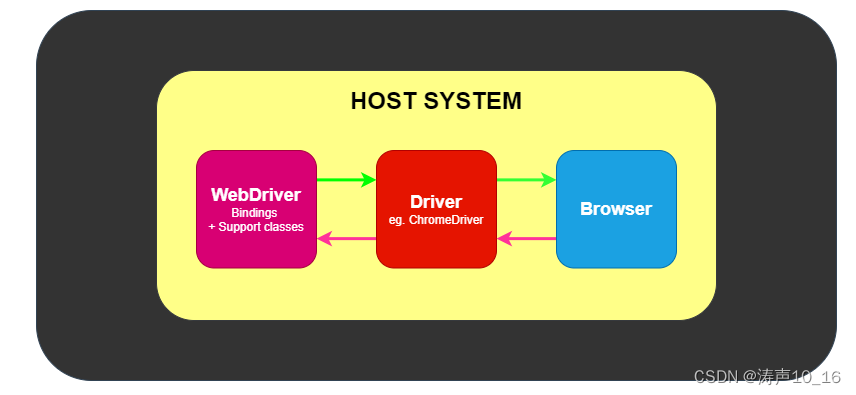
1.5.4.1 本地模式
测试框架和浏览器驱动、浏览器在相同的系统上运行。测试框架使用WebDriver 通过一个驱动程序与浏览器对话。WebDriver 通过驱动程序向浏览器传递命令, 然后通过相同的路径接收信息。
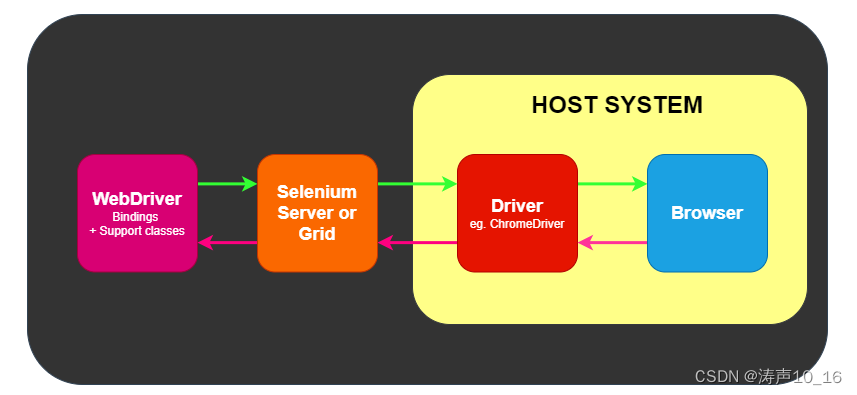
1.5.4.2 远程模式
远程目标系统上有浏览器驱动和浏览器,测试框架通过WebDriver调用Selenium Server 或 Selenium Grid,Selenium Server 或 Selenium Grid再调用远程目标系统上的浏览器驱动程序进行通信。
2 Selenium的简单使用
2.1 安装Python开发环境
参考 python3详细安装教程https://blog.csdn.net/qq_59636442/article/details/123079968
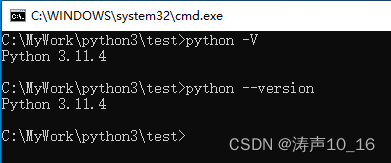
安装成功后,在命令行执行python -V 或者 python --version 查看安装的python版本信息
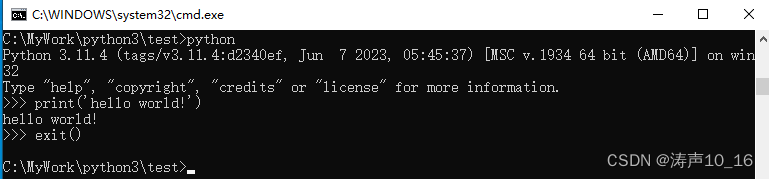
在命令行执行python,进入到python的开发交互工具中,执行exit()方法,退出交互工具。
2.2 安装Python3的selenium工具
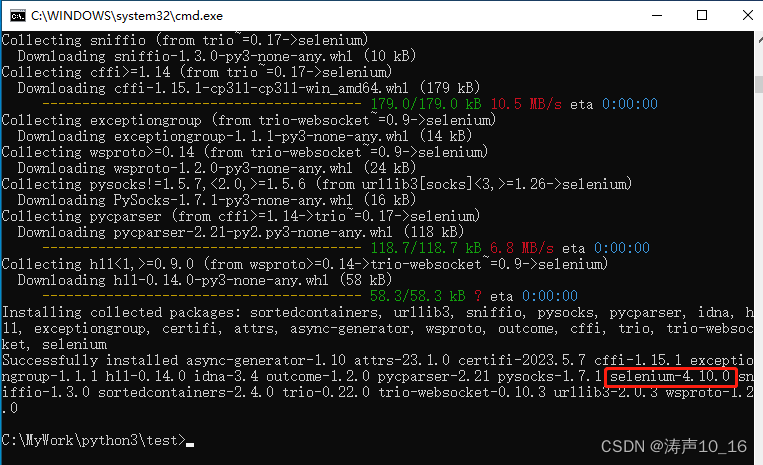
在命令行执行安装命令,可以看到成功安装了selenium-4.10.0等工具包
pip3 install selenium
- 1

2.3 浏览器驱动下载
要使用selenium进行web自动化测试,测试环境需要安装浏览器和对应版本的驱动程序。驱动程序由各浏览器厂商提供。
点击浏览器驱动下载
https://www.selenium.dev/zh-cn/documentation/webdriver/troubleshooting/errors/driver_location/#download-the-driver

selenium诞生于2004年,因此对浏览器各个旧版本基本都支持。以谷歌浏览器为例,可以支持到其远古的2.0版本。
2.4 驱动与浏览器版本对应关系
2.4.1 谷歌浏览器驱动与浏览器版本对应
新版的版本号都是对应的,大版本还一致即可。

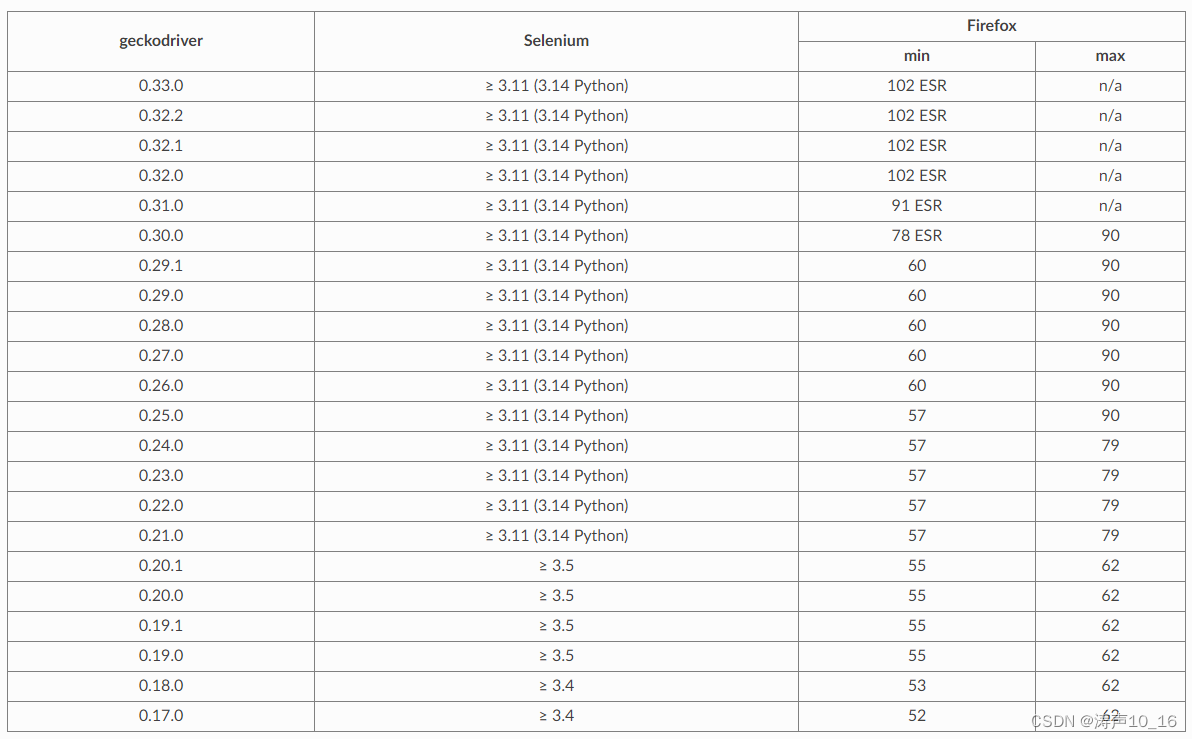
2.4.2 火狐浏览器驱动与浏览器版本对应
官方建议使用selenium3.11以上版本,Firefox 57 及更高版本的支持最好。
2.5 重点基础
编写selenium测试脚本,重点难点在
2.5.1 定位元素
定位策略是在DOM中标识一个或多个特定元素的方法。
定位器是在页面上标识元素的一种方法。它是传送给 查找元素 方法的参数。
在 WebDriver 中有 8 种不同的内置元素定位策略:
| 定位器 | 描述 |
|---|---|
| class name | 定位class属性与搜索值匹配的元素(不允许使用复合类名) |
| css selector | 定位 CSS 选择器匹配的元素 |
| id | 定位 id 属性与搜索值匹配的元素 |
| name | 定位 name 属性与搜索值匹配的元素 |
| link text | 定位link text可视文本与搜索值完全匹配的锚元素 |
| partial link text | 定位link text可视文本部分与搜索值部分匹配的锚点元素。如果匹配多个元素,则只选择第一个元素。 |
| tag name | 定位标签名称与搜索值匹配的元素 |
| xpath | 定位与 XPath 表达式匹配的元素 |
selenium-ide 生成的脚本,默认以
我们以下面的HTML片段为例,介绍8种定位策略的使用:
<html>
<body>
<style>
.information {
background-color: white;
color: black;
padding: 10px;
}
</style>
<h2>Contact Selenium</h2>
<form action="/action_page.php">
<input type="radio" name="gender" value="m" />Male
<input type="radio" name="gender" value="f" />Female <br>
<br>
<label for="fname">First name:</label><br>
<input class="information" type="text" id="fname" name="fname" value="Jane"><br><br>
<label for="lname">Last name:</label><br>
<input class="information" type="text" id="lname" name="lname" value="Doe"><br><br>
<label for="newsletter">Newsletter:</label>
<input type="checkbox" name="newsletter" value="1" /><br><br>
<input type="submit" value="Submit">
</form>
<p>To know more about Selenium, visit the official page
<a href ="www.selenium.dev">Selenium Official Page</a>
</p>
</body>
</html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2.5.1.1 class属性名称
HTML 页面 Web 元素可以具有属性类。我们可以在上面显示的 HTML 片段中看到一个示例。我们可以使用 Selenium 中提供的类名定位器来识别这些元素。
WebDriver driver = new ChromeDriver();
driver.findElement(By.className("information"));
- 1
- 2
2.5.1.2 css选择器
CSS 是用于设计 HTML 页面样式的语言。我们可以使用CSS选择器定位器策略来识别页面上的元素。如果元素有 id,我们将创建定位器 css = #id。否则,我们遵循的格式是 css =[attribute=value] 。让我们看一下上面 HTML 片段中的示例。我们将使用 css 创建fname文本框的定位器。
WebDriver driver = new ChromeDriver();
driver.findElement(By.cssSelector("#fname"));
- 1
- 2
2.5.1.3 元素的id属性
我们可以使用网页中元素的 ID 属性来定位它。通常,网页上的元素的 ID 属性应该是唯一的。我们将使用它来识别lname字段。
WebDriver driver = new ChromeDriver();
driver.findElement(By.id("lname"));
- 1
- 2
2.5.1.4 元素的name属性
我们可以使用网页中元素的 NAME 属性来定位它。一般来说,NAME 属性对于网页上的元素应该是唯一的。我们将使用它来识别newsletter复选框。
WebDriver driver = new ChromeDriver();
driver.findElement(By.name("newsletter"));
- 1
- 2
2.5.1.5 链接文本
如果我们要定位的元素是链接,我们可以使用链接文本定位器在网页上识别它。链接文本是链接显示的文本。在共享的 HTML 片段中,我们有一个可用的链接,让我们看看如何找到它。
WebDriver driver = new ChromeDriver();
driver.findElement(By.linkText("Selenium Official Page"));
- 1
- 2
2.5.1.6 部分链接文本
如果我们要定位的元素是链接,我们可以使用部分链接文本定位器在网页上识别它。链接文本是链接显示的文本。我们可以将部分文本作为值传递。在共享的 HTML 片段中,我们有一个可用的链接,让我们看看如何找到它。
WebDriver driver = new ChromeDriver();
driver.findElement(By.partialLinkText("Official Page"));
- 1
- 2
2.5.1.7 标签名
我们可以使用 HTML TAG 本身作为定位器来识别页面上的 Web 元素。从上面共享的 HTML 片段中,让我们使用其 html 标签“a”来识别链接。
WebDriver driver = new ChromeDriver();
driver.findElement(By.tagName("a"));
- 1
- 2
2.5.1.8 xpath路径
一个HTML文档可以被认为是一个XML文档,然后我们可以使用xpath,它是到达感兴趣的元素所遍历的路径来定位该元素。XPath 可以是绝对 xpath,它是从文档的根目录创建的。示例 - /html/form/input[1]。这将返回男性单选按钮。或者 xpath 可能是相对的。示例 - //input[@name=‘fname’]。这将返回名字文本框。让我们使用 xpath 为女性单选按钮创建定位器。
WebDriver driver = new ChromeDriver();
driver.findElement(By.xpath("//input[@value='f']"));
- 1
- 2
2.5.1.9 相对定位符
相对定位器方法可以将先前定位的元素引用或另一个定位器作为原点的参数。根据目标元素与原点元素的相对位置,来定位与原点元素相邻的目标元素。以下图中的元素为例:
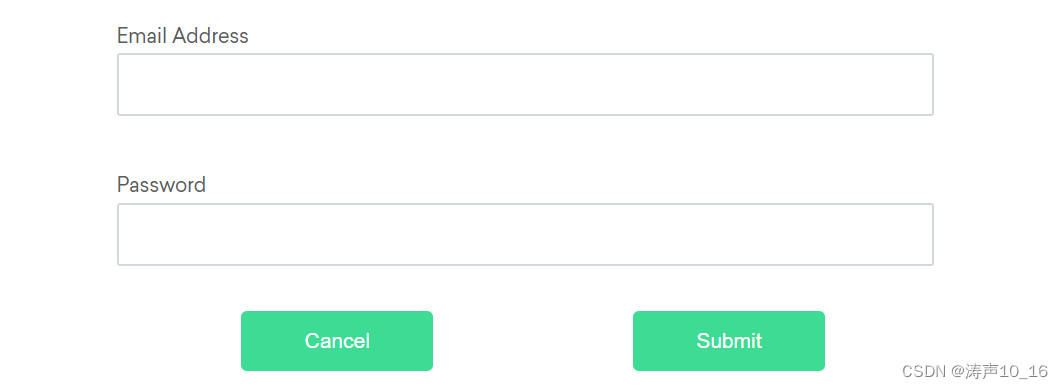
above(上方)
如果电子邮件文本字段元素由于某种原因不易识别,但密码文本字段元素可以,我们可以利用文本字段元素是密码元素“上方”的“输入”元素这一事实来定位文本字段元素。
By emailLocator = RelativeLocator.with(By.tagName("input")).above(By.id("password"));
- 1
below(下方)
如果密码文本字段元素由于某种原因不易识别,但电子邮件文本字段元素可以,我们可以利用文本字段元素是电子邮件元素“下方”的“输入”元素这一事实来定位文本字段元素。
By passwordLocator = RelativeLocator.with(By.tagName("input")).below(By.id("email"));
- 1
Left of (左侧)
如果取消按钮由于某种原因不容易识别,但提交按钮元素可以,我们可以利用取消按钮元素是提交元素“左侧”的“按钮”元素这一事实来定位取消按钮元素。
By cancelLocator = RelativeLocator.with(By.tagName("button")).toLeftOf(By.id("submit"));
- 1
Right of (右侧)
如果由于某种原因提交按钮不易识别,但取消按钮元素却很容易识别,那么我们可以利用提交按钮元素是取消元素“右侧”的“按钮”元素这一事实来定位提交按钮元素。
By submitLocator = RelativeLocator.with(By.tagName("button")).toRightOf(By.id("cancel"));
- 1
Near (附近)
如果相对定位不明显,或者根据窗口大小而变化,您可以使用near方法来识别距离50px所提供的定位器最远的元素。
By emailLocator = RelativeLocator.with(By.tagName("input")).near(By.id("lbl-email"));
- 1
链接多个相对定位符
如果需要,您还可以链接定位器。有时,该元素最容易被识别为位于一个元素的上方/下方以及另一元素的右侧/左侧。
By submitLocator = RelativeLocator.with(By.tagName("button")).below(By.id("email")).toRightOf(By.id("cancel"));
- 1
2.5.2 元素交互
Web元素交互是用于操纵表单的高级指令集。
仅有五种基本命令可用于元素的操作:
- 点击 (适用于任何元素)
- 发送键位 (仅适用于文本字段和内容可编辑元素)
- 清除 (仅适用于文本字段和内容可编辑元素)
- 提交 (仅适用于表单元素)
- 选择 (参见 选择列表元素)
其他还有鼠标、键盘的交互操作,参考文档
2.5.2.1 点击
元素单击命令在元素的中心执行。如果元素的中心由于某种原因被遮挡,Selenium 将返回元素点击拦截错误。
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html");
// Click on the element
driver.findElement(By.name("color_input")).click();
- 1
- 2
- 3
- 4
2.5.2.2 发送键位
元素发送键位命令 将录入提供的键位到 可编辑的 元素。通常,这意味着元素是具有 文本 类型的表单的输入元素或具有 内容可编辑 属性的元素。如果不可编辑,则返回 无效元素状态 错误。
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html");
// Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear();
//Enter Text
driver.findElement(By.name("email_input")).sendKeys("admin@localhost.dev");
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
2.5.2.3 清除
元素清除命令 重置元素的内容。这要求元素 可编辑, 且 可重置。 通常, 这意味着元素是具有 文本 类型的表单的输入元素或具有 内容可编辑 属性的元素。如果不满足这些条件,将返回 无效元素状态 错误。
// Navigate to Url
driver.get("https://www.selenium.dev/selenium/web/inputs.html");
// Clear field to empty it from any previous data
driver.findElement(By.name("email_input")).clear();
- 1
- 2
- 3
- 4
- 5
2.5.2.4 提交
在Selenium 4中, 不再通过单独的端点以及脚本执行的方法来实现。因此,建议不要使用此方法,而是单击相应的表单提交按钮。
2.5.2.5 选择
与其他元素相比,选择列表具有特殊的行为。Select对象现在将为您提供一系列命令,用于允许您与 元素进行交互。选择 (参见 选择列表元素)
请注意,此类仅适用于 HTML 元素 select 和 option。这个类将不适用于那些通过 div 或 li 并使用JavaScript遮罩层设计的下拉列表。
2.5.3 同步浏览器状态(等待)
WebDriver通常可以说有一个阻塞API。因为它是一个指示浏览器做什么的进程外库,而且web平台本质上是异步的,所以WebDriver不跟踪DOM的实时活动状态。根据经验,大多数由于使用Selenium和WebDriver而产生的间歇性问题都与浏览器和用户指令之间的 竞争条件 有关。例如,用户指示浏览器导航到一个页面,然后在试图查找元素时得到一个 no such element 的错误。
selenium提供显示等待,隐式等待和流畅等待三种等待方式,也可以使用编程语言的强制等待。
参考文章 JavaSelenium中几种等待方式
2.5.3.1 强制等待
强制等待,就是硬等待,使用方法Thread.sleep(int sleeptime),使用该方法会让当前执行进程暂停指定的时间。弊端就是,你不能确定元素多久能加载完全,如果两秒元素加载出来了,你用了30秒,造成脚本执行时间上的浪费。
try {
Thread.sleep(5);
}catch (InterruptedException e){
e.printStackTrace();
}
- 1
- 2
- 3
- 4
- 5
2.5.3.2 显示等待
显示等待,就是明确的要等到某个元素的出现或者是某个元素的可点击等条件等到为止,才会继续执行后续操作,等不到,就一直等,除非在规定的时间之内都没找到,那么就抛出异常了。
// 当页面中存在我的已办的链接文字时,点击我的已办,等待10秒依然不存在该元素时抛出异常
{
WebDriverWait wait = new WebDriverWait(driver, 10);
wait.until(ExpectedConditions.visibilityOfElementLocated(By.linkText("我的已办")));
}
driver.findElement(By.linkText("我的已办")).click();
- 1
- 2
- 3
- 4
- 5
- 6
显式等待使用ExpectedConditions类中自带方法, 可以进行显式等待的判断,常用的判断条件如下表:
| 等待的条件方法名称 | 描述 |
|---|---|
| elementToBeClickable(By locator) | 页面元素是否在页面上可用和可被单击 |
| elementToBeSelected(WebElement element) | 页面元素处于被选中状态 |
| presenceOfElementLocated(By locator) | 页面元素在页面中存在 |
| textToBePresentInElement(By locator) | 在页面元素中是否包含特定的文本 |
| textToBePresentInElementValue(By locator, java.lang.String text) | 页面元素值 |
| titleContains(java.lang.String title) | 标题 (title) |
显式等待常跟以下三种方法一起使用,用来判断元素
| 方法 | 作用 |
|---|---|
| isEnable() | 检查元素是否被启用 |
| isSelected() | 检查元素是否被选中 |
| isDisplay() | 检查元素是否可见 |
2.5.3.3 隐式等待
全局设置,对整个driver都有作用,如在设定时间内,元素没有加载完成,则抛出异常,如果元素加载完成,剩下的时间将不再等待。
默认情况下隐式等待元素出现是禁用的,它需要在单个会话的基础上手动启用。将显式等待和隐式等待混合在一起会导致意想不到的结果,就是说即使元素可用或条件为真也要等待睡眠的最长时间。
警告: 不要混合使用隐式和显式等待。这样做会导致不可预测的等待时间。例如,将隐式等待设置为10秒,将显式等待设置为15秒,可能会导致在20秒后发生超时。
隐式等待是告诉WebDriver如果在查找一个或多个不是立即可用的元素时轮询DOM一段时间。默认设置为0,表示禁用。一旦设置好,隐式等待就被设置为会话的生命周期。
// 识别对象时的超时时间。过了这个时间如果对象还没找到的话就会抛出NoSuchElement 异常。
driver.manage().timeouts().implicitlyWait(5,TimeUnit.SECONDS);
// 异步脚本的超时时间。WebDriver 可以异步执行脚本,这个是设置异步执行脚本,脚本返回结果的超时时间
driver.manage().timeouts().setScriptTimeout(5,TimeUnit.SECONDS);
// 页面加载时的超时时间。因为 WebDriver 会等页面加载完毕再进行后面的操作,所以如果页面超过设置时间依然没有加载完成,那么 WebDriver 就会抛出异常。
driver.manage().timeouts().pageLoadTimeout(5, TimeUnit.SECONDS);
- 1
- 2
- 3
- 4
- 5
- 6
2.5.3.4 流畅等待
流畅等待实例定义了等待条件的最大时间量,以及检查条件的频率。
用户可以配置等待来忽略等待时出现的特定类型的异常,例如在页面上搜索元素时出现的NoSuchElementException。
实际上显示等待就是一种默认配置的流畅等待,默认设置检查频率为500毫秒。
// Waiting 30 seconds for an element to be present on the page, checking
// for its presence once every 5 seconds.
Wait<WebDriver> wait = new FluentWait<WebDriver>(driver)
.withTimeout(Duration.ofSeconds(30))
.pollingEvery(Duration.ofSeconds(5))
.ignoring(NoSuchElementException.class);
WebElement foo = wait.until(driver -> {
return driver.findElement(By.id("foo"));
});
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
2.6 编写示例
3 Selenium-IED使用
3.1 安装插件
最简单的方法是直接在浏览器的插件市场搜索安装插件。如果浏览器官方插件市场无法访问,也可以搜索,下载相应浏览器的插件,手动安装。
xpi文件是Firefox浏览器(火狐浏览器)的扩展包文件
CRX文件是谷歌浏览器Chrome的插件文件
3.2 修改插件
由于官方插件是英文版的,我们可以下载源码进行汉化修改。当前最新的浏览器插件源码版本是3.17.2。
https://github.com/SeleniumHQ/selenium-ide/archive/refs/tags/v3.17.2.zip
修改完源码后,在谷歌浏览器中,访问chrome://extensions/,进入扩展程序管理页面,打开右上角的开发者模式之后,可以点击左上角的加载已解压的扩展程序,直接选择源码所在路径,即可添加插件。(注意,如果使用打包扩展程序,将插件打包成.crx文件后,拖入到浏览器插件管理中,可能会因为该扩展程序未列在 Chrome 应用商店中,并可能是在您不知情的情况下添加的原因,插件无法使用。)
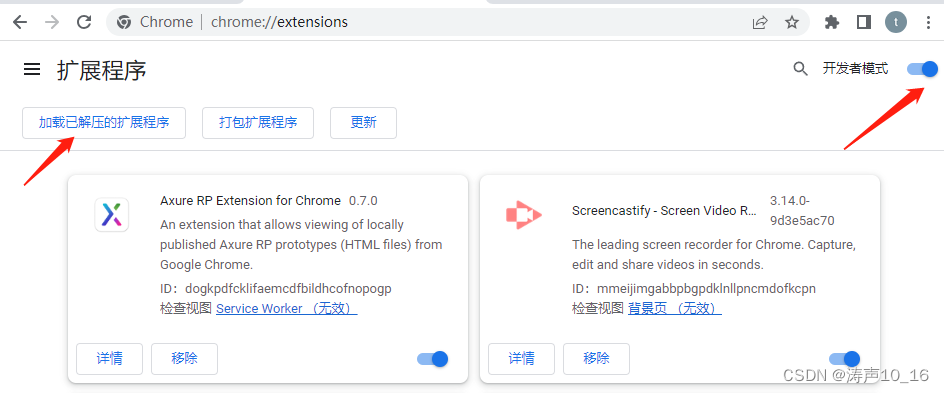
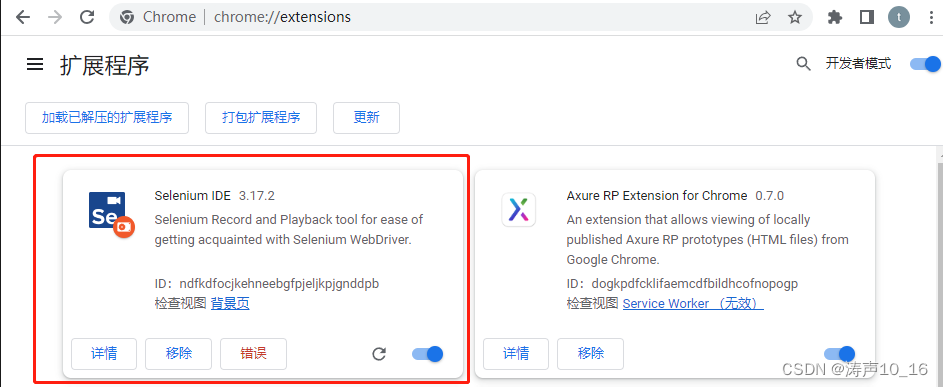
3.3 录制测试用例
在浏览器的插件管理中打开Selenium IDE插件
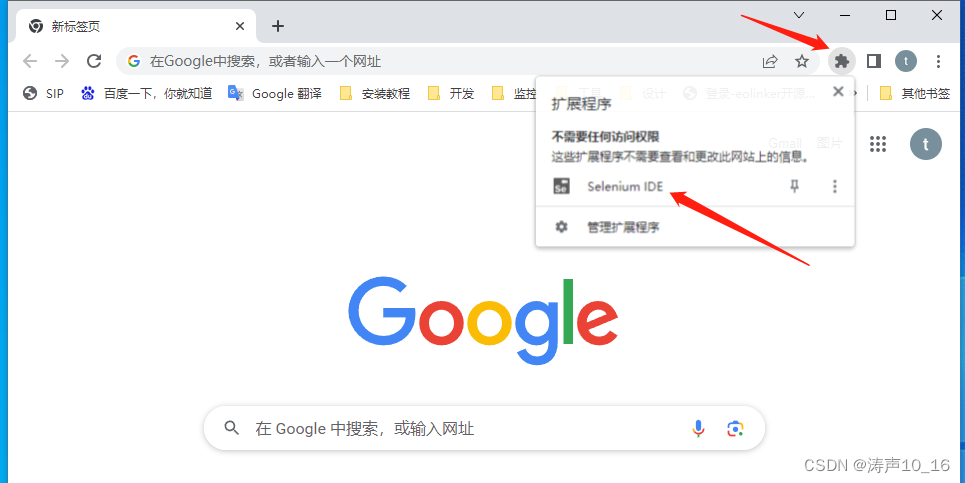
点击在一个新的工程中录制一个新的测试
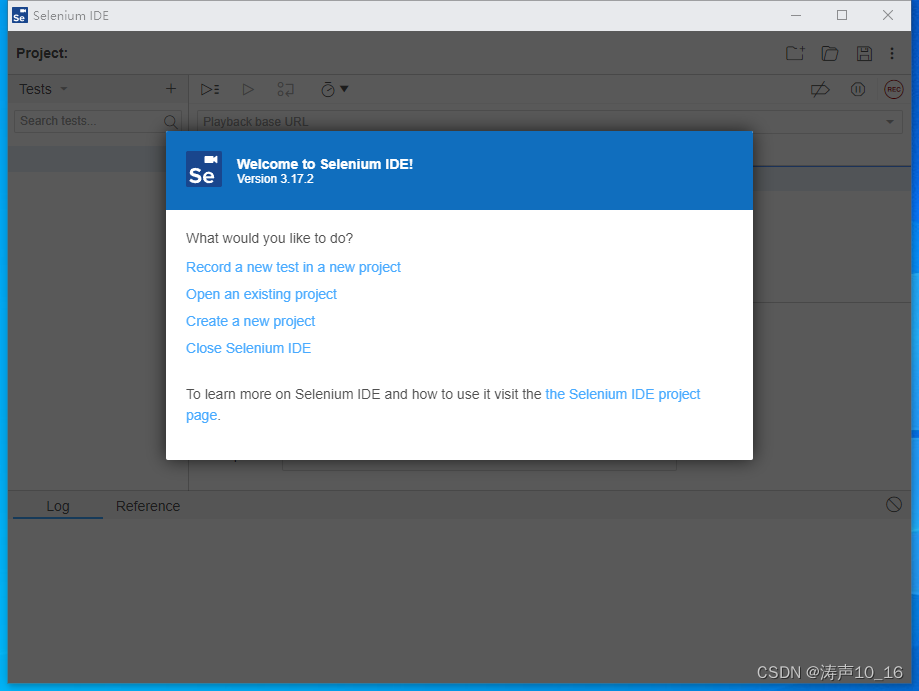
输入工程名,访问地址,即自动开始录制。在浏览器中访问测试的应用,测试完成后,关闭浏览器,停止录制。
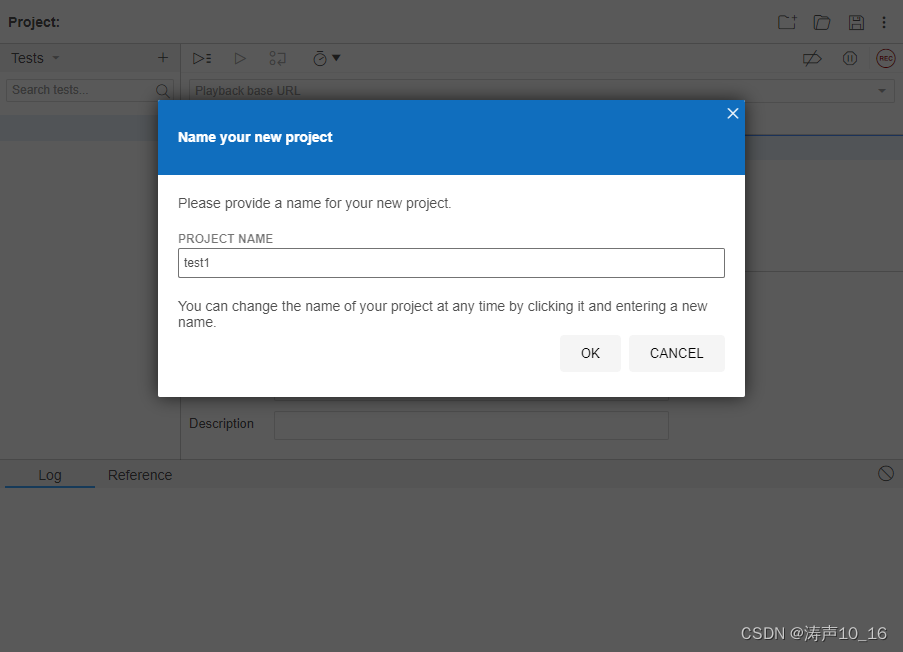
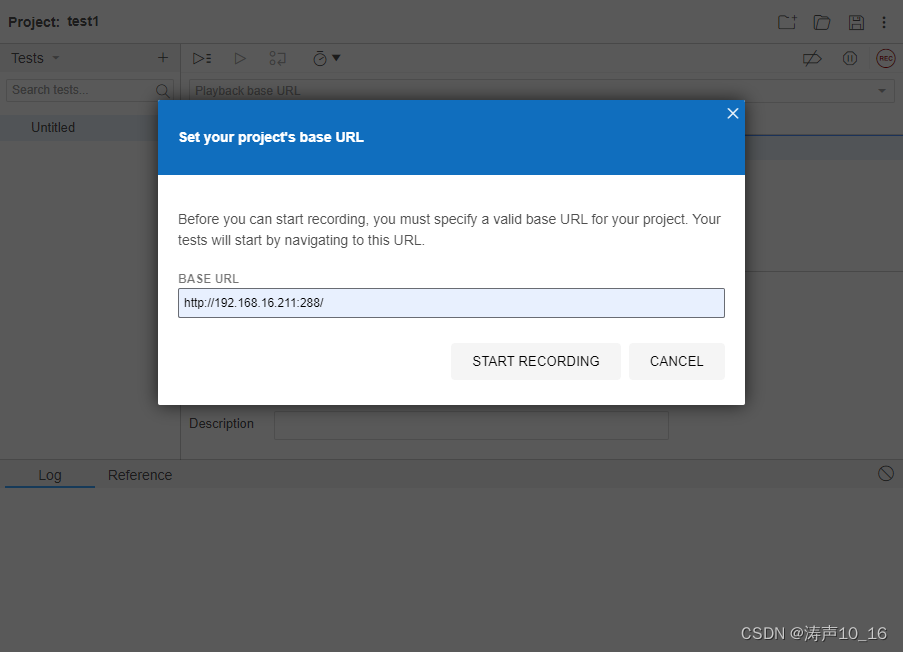
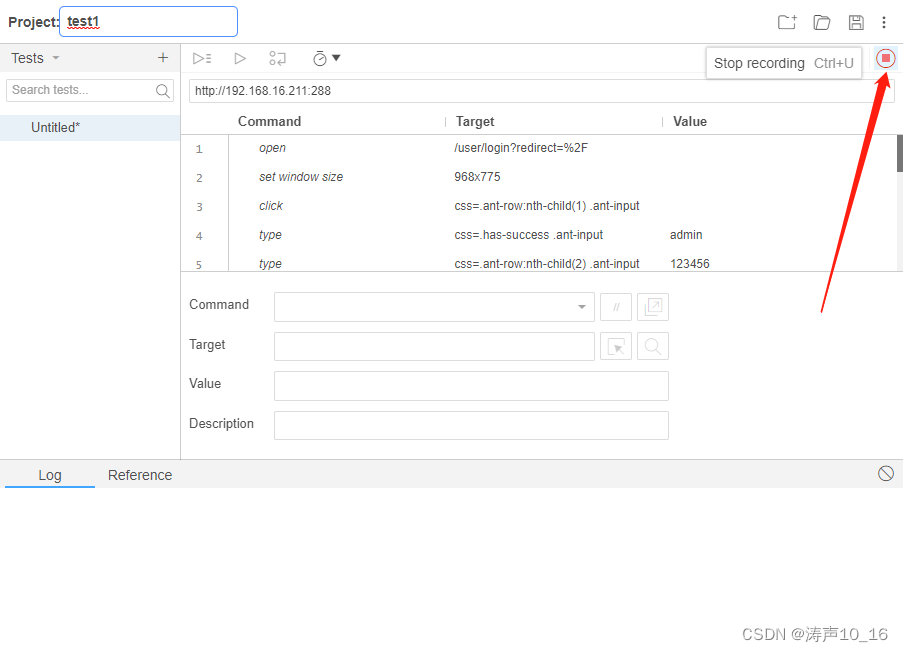
停止录制后,自动提示输入测试用例的名称。一个工程里可以创建多个测试用例。
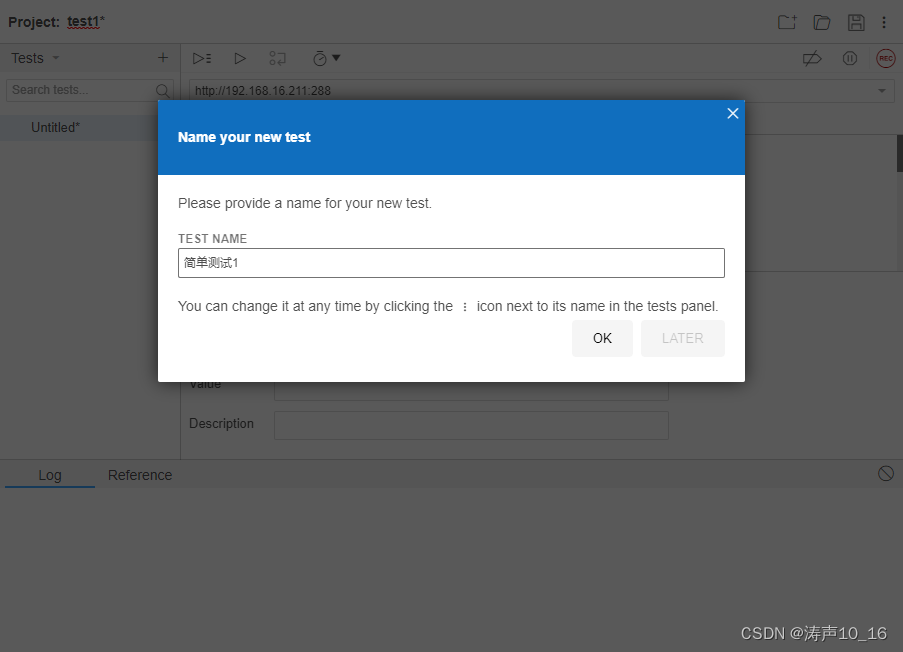
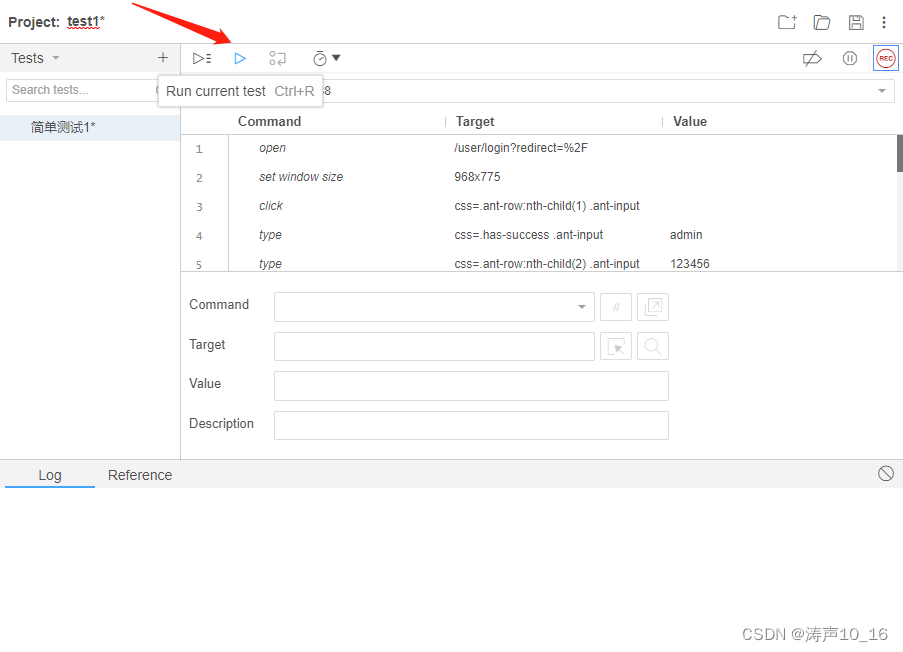
可以运行指定的测试用例,验证录制的测试过程是否正常运行。有些步骤生成的元素定位target不一定正确,可以手动选择其他定位方式,直到所有测试步骤能够正常运行。
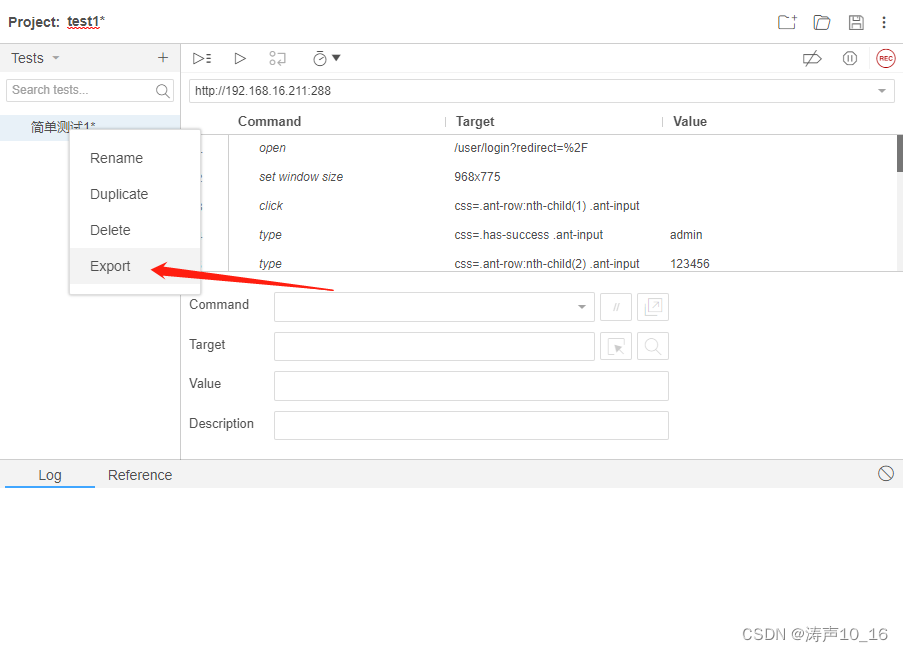
3.4 导出脚本
在测试用例上右键,选择导出脚本
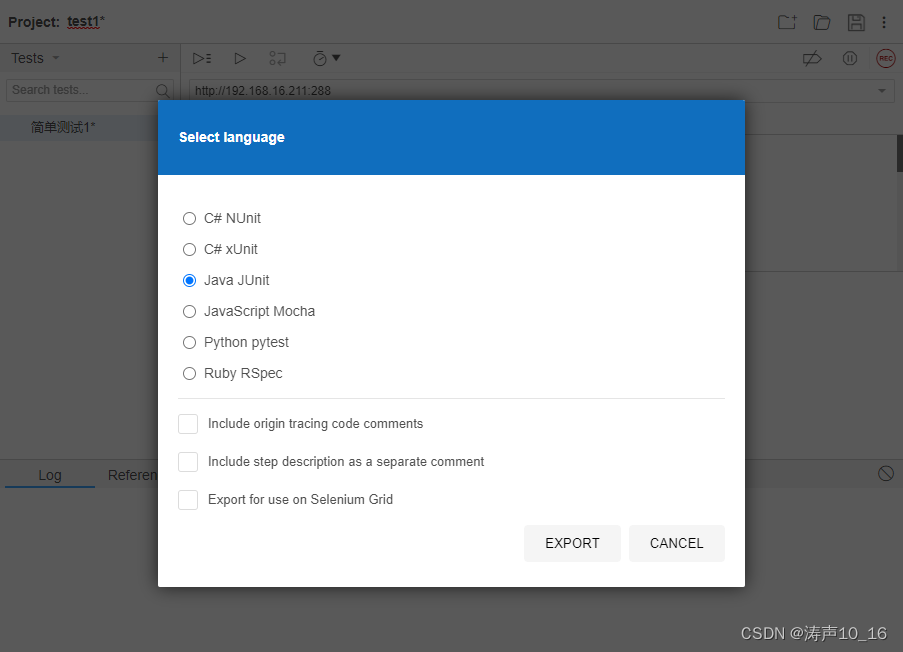
选择要导出的脚本语言,这里以java脚本为例
4 selenium java中使用
以谷歌浏览器为例,测试环境的谷歌浏览器版本为114.0.5735.199
4.1 在Maven项目中引入selenium依赖
在pom文件中引入依赖
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.10.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
4.2 通过反射动态加载测试脚本
Class.forName()是Java中的一个反射方法,用于根据类的完整限定名(fully qualified name)加载类并返回对应的Class对象。它的作用是在运行时动态地加载类,可以在编写通用代码时动态地加载不同的类,从而实现更高的灵活性和可扩展性。
Class.forName()方法通常用于以下场景:
- 在运行时动态加载类,实现更高的灵活性和可扩展性;
- 加载JDBC驱动程序;
- 加载一些第三方库或插件等。
4.3 错误解决
错误一
报错
Selenium java Only local connections are allowed.
解决方法
只允许本地连接,需要将要连接的IP加入白名单。
System.setProperty("webdriver.chrome.whitelistedIps", ""); //将所有IP加入白名单
- 1
错误二
报错
java.io.IOException。Invalid Status code=403 text=Forbidden and websocket handler
解决方法
options.addArguments("--remote-allow-origins=*")
错误三
报错
Element is not clickable at point(xxx,xxx),Other element would receive the click
解决方法
因为其他元素覆盖,导致无法点击指定位置的元素(一般是按钮)。
可以使用脚本点击事件,也可以等待覆盖的消息框消失后再点击,也可以录制关闭提示框的操作。
错误四
报错
Caused by: java.lang.NoSuchFieldError: Companion
at okhttp3.internal.Util.<clinit>(Util.kt:69)
at okhttp3.internal.concurrent.TaskRunner.<clinit>(TaskRunner.kt:309)
at okhttp3.ConnectionPool.<init>(ConnectionPool.kt:41)
at okhttp3.ConnectionPool.<init>(ConnectionPool.kt:47)
at org.openqa.selenium.remote.internal.OkHttpClient$Factory.<init>(OkHttpClient.java:116)
at org.openqa.selenium.remote.http.HttpClient$Factory.createDefault(HttpClient.java:66)
at org.openqa.selenium.remote.HttpCommandExecutor.<clinit>(HttpCommandExecutor.java:47)
at org.openqa.selenium.chrome.ChromeDriver.<init>(ChromeDriver.java:181)
at org.openqa.selenium.chrome.ChromeDriver.<init>(ChromeDriver.java:168)
at org.openqa.selenium.chrome.ChromeDriver.<init>(ChromeDriver.java:157)
at org.jeecg.modules.autotest.script.AppTestScriptForYqsm.runTest(AppTestScriptForYqsm.java:35)
... 110 more
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
解决方法
当出现如上问题时,一般是底层依赖 okhttp 与 okio 的版本不兼容导致,例如下图中 okhttp 是 v4.4.1,而 okio 有2.4.3和v1.14.0
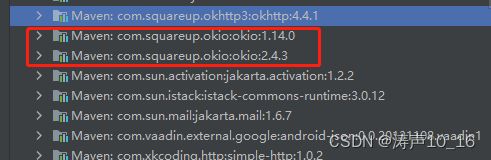
原因是selenium-java依赖的okio 版本较老,与框架中其他依赖产生冲突,在selenium-java依赖中排除okio依赖即可,将依赖改为:
<dependency>
<groupId>org.seleniumhq.selenium</groupId>
<artifactId>selenium-java</artifactId>
<version>4.10.0</version>
<!-- 与其他高版本依赖冲突,排除此处的低版本okio依赖 -->
<exclusions>
<exclusion>
<groupId>com.squareup.okio</groupId>
<artifactId>okio</artifactId>
</exclusion>
</exclusions>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
5其他参考信息
5.1浏览器参数
谷歌浏览器
启动谷歌浏览器时,要使用的命令行参数,可参考下面两个网站:
常用的参数配置如下:
无浏览器模式
--headless,在没有桌面的服务器上配置该属性,运行测试时,不展示浏览器图形界面。
无沙盒模式
--no-sandbox,让Chrome在root权限下跑。在Linux服务器上进行测试时,浏览器、驱动配置正确,而且启用--headless无浏览器模式时,依然会报错unknown error: DevToolsActivePort file doesn't exist时,需要添加该配置。
设置浏览器分辨率
--window-size=1366,768
最大化运行
--start-maximized,最大化运行(全屏窗口)。
禁用gpu
--disable-gpu,禁用gpu。
不显示浏览器正在被自动化程序控制的提示
--disable-infobars,不显示浏览器正在被自动化程序控制的提示。
在较老的chrome V76版本以前使用这个参数配置。
在chrome V76版本及以上,需要使用排除的配置
//禁用浏览器正在被自动化程序控制的提示(chromeV76及以上版本)
options.setExperimentalOption("excludeSwitches", ImmutableList.of("--enable-automation"));
- 1
- 2
禁用gpu加速
--disable-gpu,禁用gpu加速。
忽略证书错误
--ignore-certificate-errors,用于忽略证书错误。当访问某些HTTPS网站时,浏览器会根据证书的颁发机构来验证网站的真实性。如果不可信,就会出现证书错误。而使用–ignore-certificate-errors参数可以忽略这个错误,直接显示该网站的内容。
6 不鼓励的测试
以下内容均翻译自官网教程。
验证码
验证码 (CAPTCHA),是 全自动区分计算机和人类的图灵测试 (Completely Automated Public Turing test to tell Computers and Humans Apart) 的简称,是被明确地设计用于阻止自动化的,所以不要尝试!
规避验证码的检查,主要有两个策略:
- 在测试环境中禁用验证码
- 添加钩子以允许测试绕过验证码
文件下载
虽然可以通过在Selenium的控制下单击浏览器的链接来开始下载, 但是API并不会暴露下载进度, 因此这是一种不理想的测试下载文件的方式。 因为下载文件并非模拟用户与Web平台交互的重要方面。取而代之的是,应使用Selenium(以及任何必要的cookie)查找链接,并将其传递给例如libcurl这样的HTTP请求库。
HtmlUnit driver 可以通过实现AttachmentHandler 接口将附件作为输入流进行访问来下载附件。可以将AttachmentHandler添加到 HtmlUnit WebClient。
HTTP响应码
对于Selenium RC中的某些浏览器配置, Selenium充当了浏览器和自动化站点之间的代理。这意味着可以捕获或操纵通过Selenium传递的所有浏览器流量。captureNetworkTraffic() 方法旨在捕获浏览器和自动化站点之间的所有网络流量,包括HTTP响应码。
Selenium WebDriver是一种完全不同的浏览器自动化实现, 它更喜欢表现得像用户一样,这种方式来自于基于WebDriver编写测试的方式。在自动化功能测试中,检查状态码并不是测试失败的特别重要的细节,之前的步骤更重要。
浏览器将始终呈现HTTP状态代码,例如404或500错误页面。遇到这些错误页面时,一种“快速失败”的简单方法是 在每次加载页面后检查页面标题或可信赖点的内容(例如 <h1> 标签)。 如果使用的是页面对象模型,则可以将此检查置于类构造函数中或类似于期望的页面加载的位置。有时,HTTP代码甚至可能出现在浏览器的错误页面中, 您可以使用WebDriver读取此信息并改善调试输出。
检查网页本身的一种理想实践是符合WebDriver的呈现以及用户的视角。
如果您坚持,捕获HTTP状态代码的高级解决方案是复刻Selenium RC的行为去使用代理。WebDriver API提供了为浏览器设置代理的功能, 并且有许多代理可以通过编程方式来操纵发送到Web服务器和从Web服务器接收的请求的内容。使用代理可以决定如何响应重定向响应代码。此外,并非每个浏览器都将响应代码提供给WebDriver, 因此选择使用代理可以使您拥有适用于每个浏览器的解决方案。
测试依赖
关于自动化测试的一个常见想法和误解是关于特定的测试顺序. 您的测试应该能够以任何顺序运行,而不是依赖于完成其他测试才能成功。
性能测试
通常不建议使用Selenium和WebDriver进行性能测试。并非因为不能做,只是缺乏针对此类工作的优化,因而难以得到乐观的结果。
对于用户而言, 在用户上下文中执行性能测试似乎是自然而然的选择, 但是WebDriver的测试会受到许多外部和内部的影响而变得脆弱,这是您无法控制的。例如, 浏览器的启动速度, HTTP服务器的速度,托管JavaScript或CSS的第三方服务器的响应 以及WebDriver实现本身检测的损失。这些因素的变化会影响结果。很难区分网站自身与外部资源之间的性能差异,并且也很难明确浏览器中使用WebDriver对性能的影响,尤其是在注入脚本时。
另一个潜在的吸引点是"节省时间"-同时执行功能和性能测试。但是,功能和性能测试分别具有截然不同的目标。要测试功能, 测试人员可能需要耐心等待加载,但这会使性能测试结果蒙上阴影,反之亦然。
为了提高网站的性能,您需要不依赖于环境的差异来分析整体性能,识别不良代码的实践,对单个资源 (即CSS或JavaScript) 的性能进行细分 以了解需要改进的地方。有很多性能测试工具已经可以完成这项工作,并且提供了报告和分析结果, 甚至可以提出改进建议。
例如一种易于使用的 (开源) 软件包是: JMeter。
爬取链接
建议您不要使用WebDriver来通过链接进行爬网, 并非因为无法完成,而是因为它绝对不是最理想的工具。 WebDriver需要一些时间来启动,并且可能要花几秒钟到一分钟的时间, 具体取决于测试的编写方式,仅仅是为了获取页面并遍历DOM。
除了使用WebDriver之外,您还可以通过执行 curl 命令或 使用诸如BeautifulSoup之类的库来节省大量时间, 因为这些方法不依赖于创建浏览器和导航至页面。通过不使用WebDriver可以节省大量时间。
双因素认证
双因素认证通常简写成 2FA 是一种一次性密码(OTP)通常用在移动应用上例如“谷歌认证器”, “微软认证器”等等,或者通过短信或者邮件来认证。在Selenium自动化中这些都是影响有效自动化 的极大挑战。虽然也有一些方法可以自动化这些过程,但是同样对于Selenium自动化也引入了很多不安全因素。 所以你应该要避免对2FA自动化。
这里有一些对于如何绕过2FA校验的建议:
- 在测试环境中对特定用户禁止2FA校验,这样对于这些特定用户可以直接进行自动化测试。
- 禁止2FA校验在测试环境中。
- 对于特定IP区域禁止2FA校验,这样我们可以配置测试机器的IP在这些白名单区域中。

