
- 1Linux基础命令- echo_echo替换文件内容
- 2Vue中 ,vue-resource 设置请求超时(timeout)后,做出对应响应_vue-resource.esm.超时
- 3csdn专用必杀技----谷歌浏览器插件_csdn谷歌插件
- 4SASS的介绍和应用示例入门_sass应用实例
- 5天池龙珠SQL训练营日常 task3 打卡_10-1 创建视图,包含拥有属性值个数大于1的商品信息 分数 10 作者 冰冰 单位 广东
- 6前端进阶 | 如何写好JS(含实例+完整代码)_前端代码编写方法
- 7JSON parse error: Cannot deserialize value of type `java.time.LocalDateTime` from String异常的正确处理方法,嘿嘿
- 8测试老鸟6年面试心得:四种公司、四种问题_陕六建入职测评过不了
- 9js如何实现整除_auto js 怎么表示整除
- 10面试题收集(五)_一万个人抢 100 个红包,如何实现(不用队列),如何保证 2 个人不能抢 到同一个红包,
【视频异常检测】Text Prompt with Normality Guidance for Weakly Supervised Video Anomaly 论文阅读
赞
踩
Text Prompt with Normality Guidance for Weakly Supervised Video Anomaly 论文阅读
文章信息:

原文链接:https://arxiv.org/pdf/2404.08531v1.pdf
无源码
发表于:CVPR 2024
Abstract
弱监督视频异常检测(WSVAD)是一项具有挑战性的任务。基于弱标签生成细粒度伪标签,然后进行自我训练分类器是目前一个有前景的解决方案。然而,由于现有方法仅使用RGB视觉模态,忽略了类别文本信息的利用,从而限制了更准确伪标签的生成,并影响了自我训练的性能。受基于事件描述的手动标注过程的启发,在本文中,我们提出了一种基于文本提示与正常性引导(TPWNG)的弱监督视频异常检测伪标签生成和自我训练框架。我们的想法是利用对比语言-图像预训练(CLIP)模型的丰富语言-视觉知识,对齐视频事件描述文本和相应的视频帧以生成伪标签。具体来说,我们首先通过设计两个排序损失和一个分布不一致性损失对CLIP进行领域自适应微调。此外,我们提出了一个可学习的文本提示机制,辅以正常性视觉提示,进一步提高了视频事件描述文本和视频帧的匹配精度。然后,我们设计了一个基于正常性引导的伪标签生成模块,以推断可靠的帧级伪标签。最后,我们引入了一个时间上下文自适应学习模块,更灵活、更准确地学习不同视频事件的时间依赖关系。大量实验证明,我们的方法在两个基准数据集UCF-Crime和XD-Violence上实现了最先进的性能,证明了我们提出的方法的有效性。
1. Introduction

图1.说明了手动视频帧标记过程
异常检测已经被广泛研究和应用于各个领域,如计算机视觉[23, 35, 40, 43, 49]、自然语言处理[1]和智能优化[29]等。其中,视频异常检测(VAD)是最重要的研究问题之一。VAD的主要目的是自动识别视频中与我们期望不一致的事件或行为。
由于异常事件的稀缺性以及帧级标记的困难,当前的视频异常检测(VAD)方法主要集中在半监督[14, 16, 18]和弱监督[11, 26, 52]范式上。半监督VAD方法旨在从正常数据中学习正常模式,而与此模式不符的偏差被视为异常。然而,由于在训练阶段缺乏具有鉴别性的异常信息,这些模型往往容易过拟合,在复杂场景中表现不佳。随后,弱监督视频异常检测(WSVAD)方法开始受到关注。WSVAD在训练阶段涉及具有视频级标签的正常和异常视频,但异常帧的确切位置是未知的。当前的WSVAD方法主要包括基于多实例学习(MIL)[17, 26, 27]的单阶段方法和基于伪标签自训练的两阶段方法[6, 11, 51, 53]。虽然基于MIL的单阶段方法显示出有希望的结果,但这种范式倾向于关注具有突出异常特征的视频片段,并对次要异常关注不足,从而限制了进一步的性能提升。
与上述单阶段方法相比,基于伪标签自训练的两阶段方法通常使用现成的分类器或MIL方法获取初始伪标签,然后使用进一步细化的伪标签对分类器进行训练。由于这些方法直接使用生成的细粒度伪标签对分类器进行训练,它们在性能上显示出巨大的潜力。然而,这些方法仍然存在两个方面尚未考虑的问题:首先,伪标签的生成仅基于视觉模态,缺乏对文本模态的利用,这限制了生成的伪标签的准确性和完整性。其次,对视频帧之间的时间依赖性的挖掘不足。
为了进一步挖掘基于伪标签的自我训练在WSVAD上的潜力,我们在本文中专注于研究上述两个问题。对于第一个问题,我们的动机是探索如何有效利用文本模态信息来辅助生成伪标签。回顾我们手动标记视频帧的过程,我们主要依靠异常事件的文本定义,即关于异常事件的先验知识,来准确定位视频帧。如图1所示,假设我们需要标记包含“打斗”事件的异常视频帧,我们将首先关联“打斗”的文本定义,然后寻找匹配的视频帧,实际上这是一个基于先验知识的文本-图像匹配过程。受此过程启发,我们将一个非常流行和强大的对比语言-图像预训练(CLIP)模型用于辅助我们实现这一目标。一方面,CLIP在网络上学习了大量的图像-文本对,因此具有丰富的先验知识;另一方面,CLIP通过比较学习进行训练,赋予了它出色的图像-文本对齐能力。对于第二个动机,由于不同的视频事件具有不同的持续时间,这导致了不同范围的时间依赖性。现有方法要么不考虑时间依赖性,要么仅考虑固定时间范围内的依赖性,导致对时间依赖性的建模不足。因此,为了实现对不同长度的时间依赖性的更灵活和充分的建模,我们应该研究可以自适应地学习不同长度时间依赖性的方法。
基于以上两个动机,我们提出了一种基于文本提示和正常性引导(TPWNG)的新型伪标签生成和自我训练框架,用于WSVAD。我们的主要想法是利用CLIP模型将视频事件的文本描述与相应的视频帧进行匹配,然后根据匹配相似性推断出伪标签。然而,由于CLIP模型是在图像-文本级别上进行训练的,它可能会受到域偏差的影响,并且缺乏学习视频中时间依赖性的能力。为了更好地将CLIP的先验知识转移到WSVAD任务中,我们首先构建了一个对比学习框架,通过设计两个排名损失和一个分布不一致性损失来对CLIP模型进行微调,以适应弱监督设置下的域适应。为了进一步提高视频事件的描述文本与视频帧对齐的准确性,我们采用可学习的文本提示来促进CLIP的文本编码器生成更广义的文本嵌入特征。在此基础上,我们提出了一种正常性视觉提示(NVP)机制来辅助这一过程。此外,由于异常视频也包含正常视频帧,我们设计了一个基于正常性引导的伪标签生成(PLG)模块,可以减少单个正常视频帧对异常视频帧对齐的干扰,从而便于获取更准确的帧级标签。
此外,为了弥补CLIP中缺乏时间关系建模的不足,并更灵活、充分地挖掘视频帧之间的时间依赖关系,我们引入了一种基于时间上下文自适应学习(TCSAL)模块的时间依赖建模,受到文献[25]的启发。TCSAL允许Transformer中的注意力模块通过设计时间跨度自适应学习机制,根据输入自适应调整注意力跨度。这可以促使模型更准确、更灵活地捕获不同持续时间视频事件的时间依赖关系。
总的来说,我们的主要贡献总结如下:
- 我们提出了一种新颖的框架,即TPWNG,用于执行WSVAD的伪标签生成和自我训练。TPWNG使用设计的排序损失和分布不一致性损失对CLIP进行微调,以将其强大的文本-图像对齐能力转移到通过PLG模块辅助生成伪标签。
- 我们设计了可学习的文本提示和正常性视觉提示机制,进一步提高视频事件描述文本和视频帧之间的对齐精度。
- 我们引入了一个TCSAL模块,以更加灵活和准确地学习不同视频事件之间的时间依赖关系。据我们所知,我们是首次提出了自适应学习时间上下文依赖关系的想法,用于视频异常检测。
- 我们在两个基准数据集UCF-Crime和XD-Violence上进行了大量实验,优秀的性能表现证明了我们方法的有效性。
2. Related Work
2.1. Video Anomaly Detection
视频异常检测(VAD)任务受到了广泛的关注和研究,并提出了许多解决此问题的方法。根据不同的监督模式,这些方法主要可以分为基于半监督和基于弱监督的VAD方法。
Semi-supervised VAD.早期的研究者主要使用半监督方法来解决VAD问题。在半监督设置中,只能在训练阶段获取正常数据,旨在通过学习正常数据来建立能够表征正常行为模式的模型。在测试阶段,与正常模式相矛盾的数据被视为异常。常见的半监督VAD方法主要包括基于单类分类器的方法和基于重建或预测误差的方法。例如,Xu等人使用多个单类分类器基于外观和动态特征预测异常分数。Hasan等人构建了一个完全卷积自动编码器来学习视频中的正常模式。Liu等人提出了一种利用U-Net架构预测未来帧的新型视频异常检测方法,其中预测误差较大的帧被视为异常。
Weakly Supervised VAD.与半监督VAD方法相比,WSVAD可以在训练阶段利用正常和异常数据,并且具有视频级别的标签,但确切的异常事件发生位置是未知的。在这种设置下,基于多实例学习(MIL)的一阶方法和基于伪标签自训练的二阶方法是两种主要方法。例如,Sultani等人首先提出了一种用于VAD的深度MIL排名框架,其中将异常和正常视频分别视为正袋和负袋,并且视频中的片段被视为实例。然后,使用排名损失来约束正袋和负袋中具有最高异常分数的片段彼此远离。后来,基于这个方法提出了许多变种。例如,Tian等人提出了一种基于前k个MIL的VAD方法,具有强大的时间特征幅度学习。
然而,这些一阶方法通常使用MIL框架,导致模型倾向于仅关注最显著的异常片段,而忽略了非常规的异常片段。基于伪标签自训练的两阶段方法提供了一个相对更有前景的解决方案。这种两阶段方法首先使用MIL或一个现成的分类器生成初始伪标签,然后在将它们用于对分类器进行监督训练之前对标签进行细化。例如,钟等人在[53]中将WSVAD问题重新表述为一个在通过现成视频分类器获得的噪声标签下的监督学习任务。冯等人在[6]中引入了一个多实例伪标签生成器,该生成器使用自训练机制为微调任务特定的特征编码器生成更可靠的伪标签。张等人在[51]中利用完整性和不确定性属性增强伪标签以进行有效的自训练。然而,所有这些现有方法都只基于视觉单模态信息生成伪标签,缺乏对文本模态的利用。因此,在本文中,我们致力于结合视觉和文本模态信息,以生成更准确和完整的伪标签,用于对分类器进行自训练。
2.2. Large Vision-Language Models
最近,出现了一系列大型视觉-语言模型,通过在大规模数据集上进行预训练来学习视觉和文本模态之间的相互关系。在这些方法中,CLIP在许多视觉-语言下游任务中表现出前所未有的性能,例如图像分类[55]、目标检测[56]、语义分割[12]等。CLIP模型最近还成功地扩展到了视频领域。VideoCLIP [39] 提出通过对比时间重叠的视频-文本对和挖掘的困难负样本来对齐视频和文本表示。ActionCLIP [30] 将动作识别任务构建为一个多模态学习问题,而不是传统的单模态分类任务。然而,利用CLIP模型解决VAD任务的尝试较少。Joo等人在[9]中简单地利用CLIP的图像编码器提取更具辨别性的视觉特征,并不使用文本信息。Wu等人[36],Zanella等人[48]主要利用CLIP的文本特征来增强整体特征的表达能力,然后采用基于MIL的异常分类器学习。与上述工作的主要区别在于,我们的方法首次利用了由CLIP文本编码器编码的文本特征与视觉特征相结合来生成伪标签,然后采用监督方法训练异常分类器。
3. Method
在本节中,我们首先介绍WSVAD任务的定义,然后介绍我们提出的方法的总体体系结构,随后详细说明每个模块和执行过程的细节。
3.1. Overall Architecture
形式上,我们首先定义了包含 M M M个异常视频和正常视频的数据集 D a = { ( v i a , y i ) } i = 1 M D^a= \{ ( v_i^a, y_i) \} _{i= 1}^M Da={(via,yi)}i=1M和 D n = { ( v i n , y i ) } i = 1 M D^n\:=\:\{(v_i^n,y_i)\}_{i=1}^M Dn={(vin,yi)}i=1M,其中 y i y_i yi是视频的真实标签。对于每个 v i a v_i^a via,其标签 y i = 1 y_i=1 yi=1,表示该视频至少包含一个异常帧,但异常帧的确切位置未知。对于每个 v i n v_i^n vin,其标签 y i = 0 y_i= 0 yi=0,表示该视频完全由正常帧组成。在这种设置下,WSVAD任务是利用粗粒度的视频级标签,使分类器学习预测细粒度的帧级异常分数。
图2展示了我们方法的整体流程。正常和异常视频以及可学习的类别提示文本被分别由CLIP的图像编码器和文本编码器编码为特征嵌入。然后,通过对CLIP的文本编码器进行微调,鼓励其产生准确匹配异常或正常视频帧的视频事件类别的文本特征嵌入,并且NVP在此过程中起到辅助作用。与此同时,图像特征输入TCSAL模块以执行对时间依赖关系的自适应学习。最后,通过由PLG模块获得的伪标签的监督,训练视频帧分类器以预测异常分数。
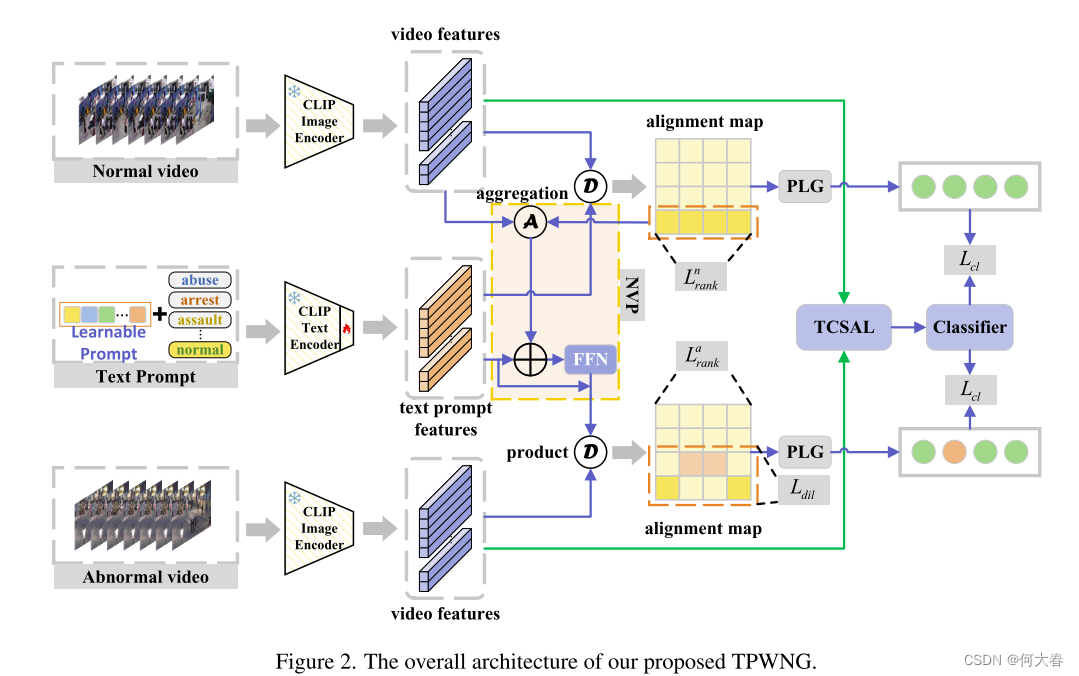
3.2. Text and Normality Visual Prompt
Learnable Text Prompt.构建能够准确描述各种视频事件类别的文本提示是实现文本与相应视频帧对齐的先决条件。然而,手动定义能够完全描述所有不同场景中异常事件的描述文本是不现实的。因此,受 CoOp [55] 启发,我们采用了可学习的文本提示机制,自适应地学习代表性的视频事件文本提示以对齐相应的视频帧。具体来说,我们构建了一个可学习的提示模板,该模板在标记化的类别名称前面添加了
l
l
l 个可学习的提示向量,如下所示:
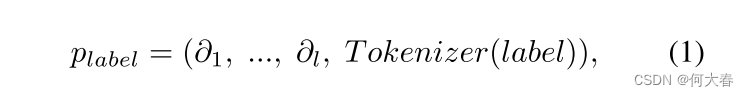
其中,
∂
l
∂l
∂l 表示第
l
l
l 个提示向量。Tokenizer 通过 CLIP tokenizer 将原始的类别标签,例如“fighting”、“accident”等,转换为类别标记。然后,我们将相应的位置信息
p
o
s
pos
pos 添加到可学习的提示中,然后将其输入 CLIP 文本编码器
ζ
t
e
x
t
ζ_{text}
ζtext,得到视频事件描述文本的特征嵌入
T
l
a
b
e
l
∈
R
D
T_{label} ∈ \mathbb{R}^D
Tlabel∈RD,如下所示:
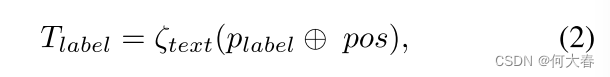
最后,根据公式(1)和(2)计算所有视频事件类别,得到视频事件描述文本嵌入集合
E
=
{
T
1
a
,
T
2
a
,
.
.
.
,
T
k
−
1
a
,
T
k
n
}
E= \{ T_1^a, T_2^a, ..., T_{k- 1}^a, T_k^n\}
E={T1a,T2a,...,Tk−1a,Tkn},其中
{
T
i
a
}
i
=
1
k
−
1
\{T_i^a\}_{i=1}^{k-1}
{Tia}i=1k−1 表示前
k
−
1
k-1
k−1 个异常事件的描述文本嵌入,
T
k
n
T_k^n
Tkn 表示正常事件的描述文本嵌入。
Normality Visual Prompt.对于一个包含异常帧和正常帧的异常视频,我们的核心任务是根据异常事件的描述文本与视频帧之间的匹配相似度推断伪标签。然而,这个过程容易受到异常视频中正常帧的干扰,因为它们与异常帧有相似的背景。为了最小化这种干扰,我们提出了一种NVP机制。NVP用于辅助正常事件的描述文本更准确地对齐异常视频中的正常帧,从而通过分布不一致性损失(将在第3.5节介绍)间接地帮助异常事件的描述文本对齐异常视频中的异常帧。具体地,我们首先计算正常事件描述文本与正常视频帧特征之间的匹配相似度
S
i
,
k
n
n
∈
R
F
S_{
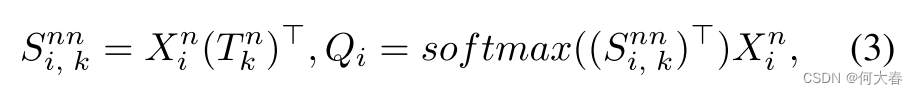
其中,
X
i
n
∈
R
F
×
D
X_i^n\in\mathbb{R}^{F\times D}
Xin∈RF×D表示由CLIP图像编码器获得的正常视频
v
i
n
v_i^n
vin的视觉特征,其中
F
F
F和
D
D
D分别表示视频帧数和特征维度。然后,我们在特征维度上将
Q
i
Q_i
Qi和
T
k
n
T_k^n
Tkn进行拼接,并通过具有跳跃连接的FFN层进行处理,以获得增强的正常事件描述文本嵌入
T
˙
k
n
\dot{T}_k^n
T˙kn。公式表示如下:
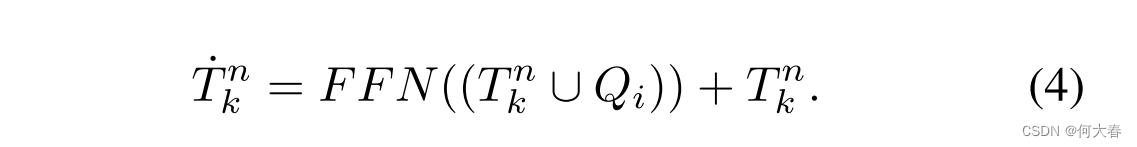
3.3. Pseudo Label Generation Module
在本小节中,我们详细介绍如何生成帧级伪标签。对于一个正常视频,我们可以直接得到帧级伪标签,即对于包含 F F F个正常帧的 v i n = { I j } j = 1 F v_i^n~=~\{I_j\}_{j=1}^{F} vin = {Ij}j=1F,它对应着一个标签集合 { γ i , j n = 0 } j = 1 F . \{\gamma_{i,\:j}^{n}=0\}_{j=1}^{F}. {γi,jn=0}j=1F. 我们的主要目标是推断包含异常帧和正常帧的异常视频的伪标签。为此,我们提出了一个基于正常性指导的PLG模块,用于根据正常性指导推断准确的帧级伪标签。PLG模块通过将正常事件的描述文本与异常视频的匹配相似性作为指导,将对应异常事件的描述文本与异常视频的匹配相似性相结合,推断帧级伪标签。
具体来说,我们首先计算正常事件描述文本增强的NVP与异常视频特征之间的匹配相似性 S i , k a n = X i a ( T ˙ k n ) ⊤ S_{i,\:k}^{an}\:=\:X_{i}^{a}(\dot{T}_{k}^{n})^{\top} Si,kan=Xia(T˙kn)⊤,其中 X i a ∈ R F × D X_i^a\in\mathbb{R}^{F\times D} Xia∈RF×D表示由CLIP图像编码器获得的异常视频 v i a v_i^a via的视觉特征。类似地,我们计算对应的第 τ \tau τ个 ( 1 ⩽ τ ⩽ k − 1 ) (1\leqslant\tau\leqslant k-1) (1⩽τ⩽k−1)真实异常类别描述文本嵌入 T τ a T_\tau^a Tτa与异常视频特征 X i a X_i^a Xia之间的匹配相似性 S i , τ a a = S_{i,\:\tau}^{aa}= Si,τaa= X i a ( T τ a ) ⊤ X_i^a(T_\tau^a)^\top Xia(Tτa)⊤。
理论上,对于
S
i
,
τ
a
a
S_{i,\tau}^{aa}
Si,τaa,它应该在异常帧对应的匹配相似性较高,而在正常帧对应的匹配相似性较低。但是,它可能会受到来自具有相同背景的同一视频的正常帧的干扰。为了减少正常帧的干扰,我们通过将与正常事件描述文本对应的匹配相似性作为指导并赋予一定的权重,将其纳入到对应真实异常事件的描述文本匹配相似性中,从而推断出伪标签。具体来说,我们首先对
S
i
,
τ
a
a
S_{i,\tau}^{aa}
Si,τaa和
S
i
,
k
a
a
S_{i,k}^{aa}
Si,kaa进行归一化和融合操作,如下所示:
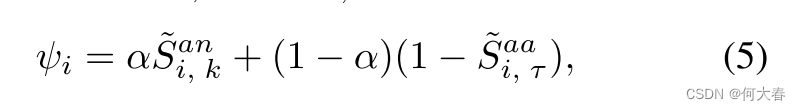
在这里,
∗
~
\tilde{*}
∗~表示归一化操作,
α
\alpha
α表示引导权重。在获得
ψ
i
\psi_i
ψi后,我们类似地对其进行归一化操作,得到
ψ
~
i
\tilde{\psi}_i
ψ~i。然后,我们在
ψ
i
\psi_i
ψi 上设置一个阈值
θ
\theta
θ,以获得异常视频的帧级伪标签,具体如下所示:
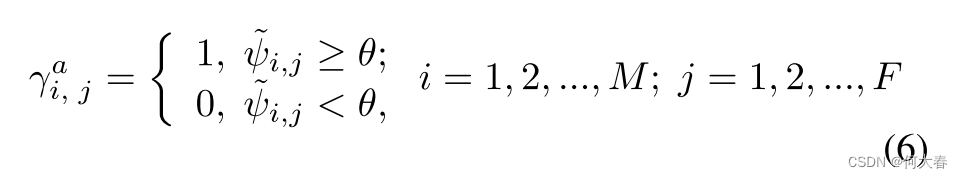
其中,
γ
i
,
j
a
\gamma_{i,j}^a
γi,ja 表示第
i
i
i 个异常视频中第
j
j
j 帧的伪标签。最后,我们将正常和异常视频的帧级伪标签
γ
i
,
j
n
\gamma_{i,j}^n
γi,jn 和
γ
i
,
j
a
\gamma_{i,j}^a
γi,ja 结合起来,得到总的伪标签集合
{
γ
i
,
j
}
j
=
1
F
\{\gamma_{i,\:j}\}_{j=1}^F
{γi,j}j=1F。
3.4. Temporal Context Self-adaptive Learning
为了根据输入视频数据自适应调整时间关系的学习范围,我们受到 [25] 中的工作的启发,引入了一个 TCSAL 模块。TCSAL 的主干是 transformer 编码器,但与原始 transformer 不同,每个自注意力头在每一层的跨度范围由一个软掩码函数 χ z \chi_z χz 控制。 χ z \chi_z χz 是一个分段函数,将距离映射到 [0,1] 之间的值,如下所示:
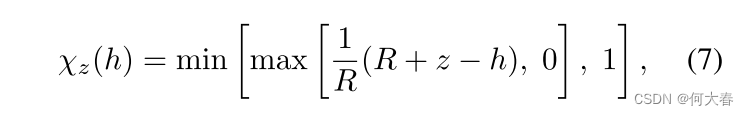
其中,
h
h
h代表视频中当前第
t
t
t帧与过去时间范围内第
r
r
r帧(
r
∈
[
1
,
t
−
1
]
r\in [ 1, t- 1]
r∈[1,t−1])之间的距离。
R
R
R是一个用于控制软性的超参数。
z
z
z是一个可学习参数,其根据输入自适应调整如下:
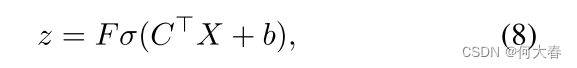
这里, σ \sigma σ表示 sigmoid 运算, C C C 和 b b b 是模型训练过程中可学习的参数。利用软掩码函数 χ z \chi_z χz,在该掩码内计算相应的注意力权重 ω t , r \omega_{t,r} ωt,r,即
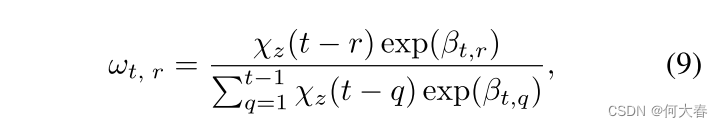
这里, β t , r \beta_{t,r} βt,r 表示视频中第 t t t 帧对应的查询项与过去第 r r r 帧对应的键项的点积输出。在 χ z \chi_z χz 的控制下,自注意力头将能够根据输入自适应调整自注意力跨度范围。
最后,经过时间上下文自适应学习的视频特征被馈送到分类器中,以预测帧级别的异常分数 { η i , j } j = 1 F \{\eta_{i,\:j}\}_{j=1}^{F} {ηi,j}j=1F。
3.5. Objective Function
首先,我们对CLIP文本编码器进行微调。对于正常视频,我们进一步计算匹配相似性集合
φ
i
n
a
=
{
S
i
,
τ
n
a
=
X
i
n
(
T
τ
a
)
⊤
∣
1
⩽
τ
⩽
k
−
1
}
\varphi_i^{na}=\{S_{i,\:\tau}^{na}=X_{i}^{n}(T_{\tau}^{a})^{\top}\:|1\leqslant\tau\leqslant k-1\}
φina={Si,τna=Xin(Tτa)⊤∣1⩽τ⩽k−1},其中包括其他
k
−
1
k-1
k−1 个异常事件描述文本与正常帧之间的匹配相似性。我们希望
φ
i
n
a
\varphi_i^{na}
φina 中的最大值尽可能小,同时
S
i
,
k
n
n
S_{i,k}^{nn}
Si,knn 中的最大值尽可能大。因此,我们设计了以下约束的排序损失函数:
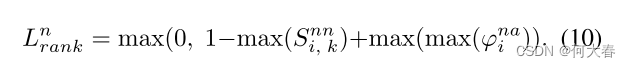
对于异常视频,我们首先计算正常事件描述文本与异常视频特征之间的相似性
S
i
,
k
a
n
=
X
i
a
(
T
˙
k
n
)
⊤
S_{i,\:k}^{an}=X_{i}^{a}(\dot{T}_{k}^{n})^{\top}
Si,kan=Xia(T˙kn)⊤,以及第
τ
\tau
τ 个
(
1
⩽
τ
⩽
k
−
1
)
(1\leqslant\tau\leqslant k-1)
(1⩽τ⩽k−1) 真实异常事件类别的描述文本与异常视频特征之间的相似性
S
i
,
τ
a
a
=
X
i
a
(
T
τ
a
)
+
S_{i,\tau}^{aa}=X_{i}^{a}(T_{\tau}^{a})^{+}
Si,τaa=Xia(Tτa)+,以及其他
k
−
2
k-2
k−2 个异常事件类别的描述文本与异常视频特征之间的相似性集合
φ
i
a
a
=
{
S
i
,
g
a
a
=
X
i
a
(
T
g
a
)
⊤
∣
1
⩽
g
⩽
k
−
1
,
g
≠
τ
}
\varphi_i^{aa}=\{S_{i,g}^{aa}=X_i^a(T_g^a)^\top\mid1\leqslant g\leqslant k-1,\:g\neq\tau\}
φiaa={Si,gaa=Xia(Tga)⊤∣1⩽g⩽k−1,g=τ}。我们期望
S
i
,
k
a
n
S_{i,k}^{an}
Si,kan 中的最大值大于
φ
i
a
a
\varphi_i^{aa}
φiaa 中的最大值。类似地,我们期望
S
i
,
τ
a
a
S_{i,\tau}^{aa}
Si,τaa 中的最大值大于
φ
i
a
a
\varphi_i^{aa}
φiaa 中的最大值。简而言之,我们期望真实异常和正常事件的描述文本与异常视频中的异常和正常帧的匹配相似性尽可能高。因此,异常视频的排序损失设计如下:
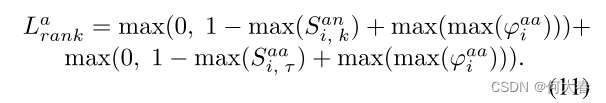
此外,为了进一步确保真实异常事件和正常事件的描述文本能够准确地分别与异常视频中的异常帧和正常帧对齐,我们设计了一个分布不一致性损失(DIL)。DIL 用于限制真实异常事件的描述文本与视频帧之间的相似性与正常事件的描述文本与视频帧之间的相似性分布不一致。我们使用余弦相似度来执行此损失:
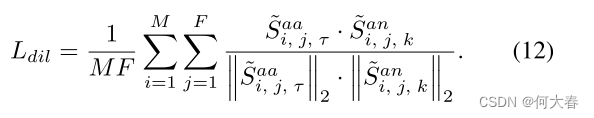
然后,为了确保生成的伪标签在时间顺序上满足稀疏性和平滑性,我们施加了稀疏性和平滑性约束,
L
s
p
=
∑
j
=
1
F
(
S
~
i
,
j
,
τ
a
a
−
S
~
i
,
j
+
1
,
τ
a
a
)
2
,
L
s
m
=
∑
j
=
1
F
S
~
i
,
j
,
τ
a
a
,
L_{sp}=\sum_{j=1}^{F}\left(\tilde{S}_{i,\:j,\:\tau}^{aa}-\tilde{S}_{i,\:j+1,\:\tau}^{aa}\right)^{2},L_{sm}=\sum_{j=1}^{F}\tilde{S}_{i,\:j,\:\tau}^{aa},
Lsp=j=1∑F(S~i,j,τaa−S~i,j+1,τaa)2,Lsm=j=1∑FS~i,j,τaa,
其中
S
~
i
,
τ
a
a
\tilde{S}_{i,\:\tau}^{aa}
S~i,τaa 是相似性向量。
然后,我们计算分类损失,即分类器预测的异常分数 η i , j \eta_{i,j} ηi,j 与伪标签 γ i , j \gamma_{i,\:j} γi,j 之间的二元交叉熵:
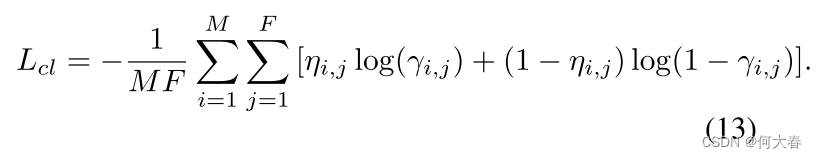
最终的整体目标函数由
λ
1
\lambda_{1}
λ1 和
λ
2
\lambda_{2}
λ2 平衡设计如下:
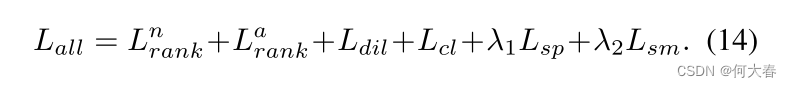
4. Experiments
4.1. Datasets and Evaluation Metrics
- UCF-Crime
- XD-Violence
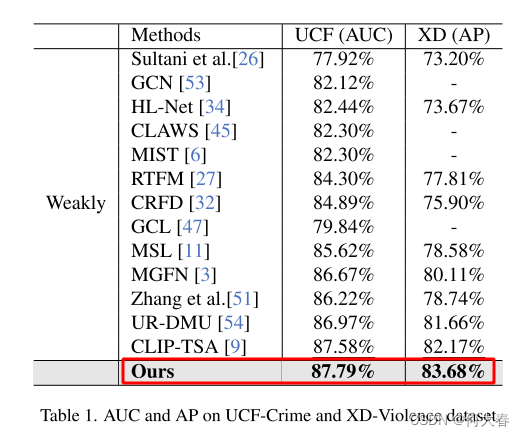
Evaluation Metrics.根据之前的方法[6,26],对于UCF-Crime数据集,我们使用帧级接收者工作特征(ROC)的曲线下面积(AUC)来衡量我们的方法的性能。同样,对于XD-Violence数据集,我们遵循工作[34]提出的平均精度(AP)评估标准来衡量我们方法的有效性。
4.2. Implementation Details
我们方法中的图像和文本编码器使用了预训练的 CLIP(VIT-B/16),其中图像和文本编码器都保持冻结状态,除了文本编码器的最终投影层被解冻以进行微调。特征维度 D D D 设置为 512。FFN 是来自 Transformer 的标准块。文本提示中可学习序列的长度 l l l 设置为 8。用于正常性引导权重 α \alpha α 对于 UCF-Crime 和 XDViolence 数据集均设置为 0.2。用于生成伪标签的阈值 θ \theta θ 分别设置为 UCF-Crime 和 XD-Violence 数据集的 0.55 和 0.35。用于控制软掩模函数软度的参数 R R R 设置为 256。稀疏损失和平滑损失权重分别设置为 λ 1 = 0.1 \lambda_{1}=0.1 λ1=0.1 和 λ 2 = 0.01 \lambda_{2}=0.01 λ2=0.01。更多实现细节请参阅补充材料。
4.3. Comparison with State-of-the-art Methods
5. Conclusions
在本文中,我们提出了一个新颖的框架,TPWNG,用于执行WSVAD的伪标签生成和自我训练。TPWNG通过设计的排序损失和分布不一致性损失对CLIP进行微调,以将其文本-图像对齐能力转移到PLG模块中,从而帮助生成伪标签。此外,我们设计了可学习的文本提示和正常性视觉提示机制,进一步提高了视频事件描述文本和视频帧的对齐精度。最后,我们引入了一个TCSAL模块,以更灵活和准确地学习不同视频事件的时间依赖关系。我们在UCF-Crime和XD-Violence数据集上进行了大量实验,与现有方法相比,我们的方法表现出了更优越的性能,证明了我们方法的有效性。
阅读总结
西瓜大的又一篇用clip做弱监督视频异常检测的文章,和VadCLIP: Adapting Vision-Language Models for Weakly Supervised Video Anomaly Detection这篇也是他们实验室的工作很类似。
Prompt这里变了一个花样,多做了一个变换。
这个地方描述的感觉是不是有问题:

既然是其他k-2个异常种类,那g不应该是
1
⩽
g
⩽
k
−
2
1\leqslant g\leqslant k-2
1⩽g⩽k−2吗
还有几个地方可能是我没看懂,不过总感觉有点问题。
本篇也没开源,我感觉代码结构和上一篇应该是很类似的,做法有点不同,期待作者能开源代码。
我看的也不一定完全正确,如果有说的不正确的地方,欢迎大家一起讨论。

