
【极验黑科技】文生图大模型在极验人机对抗领域的应用_文生图模型的应用场景
赞
踩
自极验于2013年开创性地提出新一代的智能验证码概念开始,就始终在人机对抗领域不停地升级迭代。极验全球首创的“行为式验证”在十多年来,为全球近40万的开发者使用。如小米、新浪微博、东方航空、国家工商局等企业携手极验验证码进行升级,使得现在传统的字符验证码逐步退出了历史舞台,每日极验的API调用量高达数10亿次,每一次API的响应,都是对机器黑产的对抗和用户体验的升级。
随着人机对抗的升级,极验也在不停地利用新技术创造更安全的验证服务和更极致的用户体验。早在16年,极验便将Neural style transfer 技术运用到人机对抗的实践中去,这是典型的将安全与体验兼得的验证方式,并取得令客户赞赏的效果。

Neural style transfer 原理图

将“语意理解”与“Neural style transfer”相结合而得出的新的验证过程
专利号:ZL 201830130077.X
随着大规模文生图模型已经成熟,极验也在技术前沿探索,并将新技术进一步应用到人机对抗领域,今天我们主要分享一下这方面的相关过程和进展,以及一些实验数据。
文生图模型原理
文生图模型是一种多模态深度学习模型,它可以从文本描述生成与描述相匹配的图像。其核心原理是将自然语言文本转换为图像空间,同时将视觉特征与语言信息相互联系起来,以实现自然语言文本与图像之间的映射。
文生图模型通过大量成对的文本描述和相应图像的数据集进行训练。在训练过程中,模型学习从文本中提取相关特征,并将它们映射到图像中相应的视觉特征。这个过程涉及到语义理解和图像合成。
一旦模型训练完成,它就可以用于从它以前没有见过的新文本描述中生成图像。为此,模型首先将文本描述编码为一个特征向量,然后使用生成器网络合成与该特征向量相对应的图像。
文生图模型可用于各种应用,例如为电子商务网站生成真实的产品图像,为残障人士创建视觉辅助工具,为虚拟和增强现实应用程序生成图像以及验证码图片素材的制作。
图片生成过程中存在的一些问题和解决办法
图片的生成过程,主要面临着图片的准确性、可控性、规模性三方面。
2.1 准确性
大部分开源预训练模型是基于英文构建的,翻译的过程中会产生歧义,从而产生图文不匹配的情况。
第一张图为某文生图模型demo展示的效果,原因是“起重机”被翻译成了“Crane”,而这个单词的另一个含义是“仙鹤”。

下面两张图是基于现有的提示词库生成九宫格图片遇到的一种特殊情况,第一张图的prompt为(electric, mouse)。这里的第一个问题是“鼠标”被翻译成了“老鼠”,而另一个问题是坐标为[1, 2]的图片出现了明显的图文不匹配,这个问题在第二张图(提示词为罐头)中同样存在。由此可见,在借助文生图模型生成素材的过程中仍然需要引入一定程度的人工校验,而这个问题在大规模应用中可能会被放大。


下面这张图,我们将模型更换为卡通风格,提示词依然是(electric, mouse)。这次很“幸运”,同时集齐了歧义和敏感两个要素。

2.2 可控性
敏感素材以及公平和偏见的问题,这类问题可以通过safety-checker解决一部分,但无法杜绝,可以考虑通过如下方式进行规避:
1)数据采集:在训练模型之前,需要使用多样化的数据集来确保生成的图像不具有偏见或歧视。数据集应包括各种背景、文化和种族的人物和场景,以确保生成的图像不会出现偏见或歧视。
2)模型训练:训练文本到图像的模型时,需要确保使用公正和公平的方法来训练模型。例如,可以使用一种叫做"公平性约束"的技术来确保生成的图像不包含歧视性特征。该方法通过约束模型在生成图像时不能出现歧视性特征,如年龄、种族、性别等,从而消除歧视。
3)监督和审核:在模型训练和图像生成过程中,需要进行人工审核和监督,以确保生成的图像符合伦理和道德标准。审核人员应该接受适当的培训,以了解文化敏感性和歧视问题,并对可能引起争议的图像进行审查。
4)避免敏感主题:为了避免潜在的歧视问题,可以避免生成与种族、性别、宗教、政治或其他敏感主题相关的图像。
5)公开透明:需要公开透明地展示如何训练模型、使用数据集和进行审核,以便公众和业内人士能够了解这些技术的使用和潜在影响。
2.3 规模性
大批量素材生成涉及到计算资源投入产出比问题,以及后续gpu资源的调度和扩展。这里我们有三个诉求:
1)模型服务化,尤其是涉及到大模型,必然会存在gpu的调用,这部分资源在云上成本比较高。
2)在初期,为了把控一次性投入,希望既能使用到gpu资源又能按量付费,避免昂贵的月租,提高资源利用率。
3)模型服务代码量尽可能小,且便于横向扩展。
为此我们基于Ray和K8s构建了如下的模型服务:
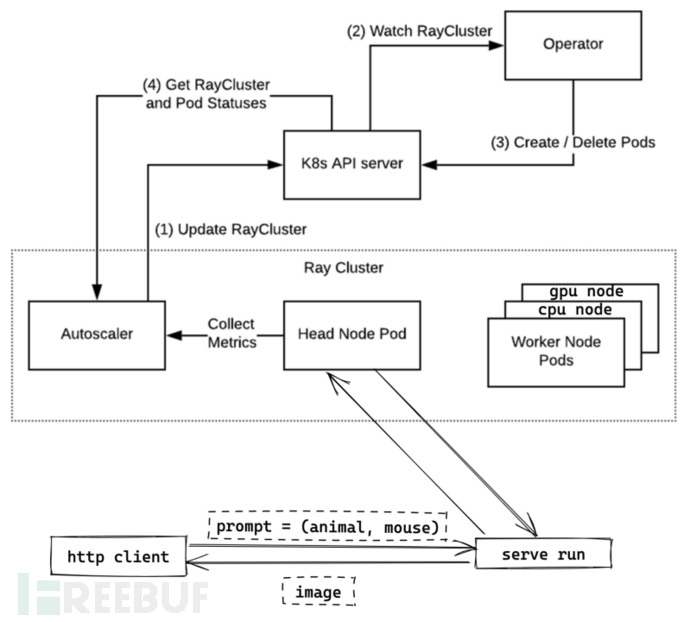
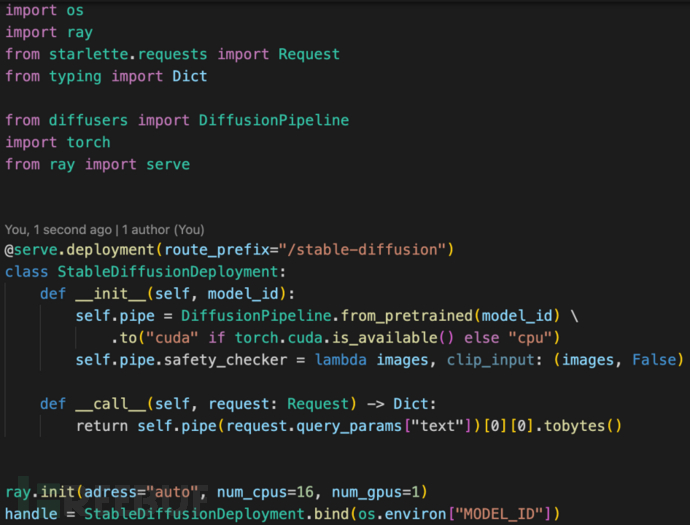
通过上图所示架构,我们可以以最小的代码量来部署一个模型服务,这部分以后有机会可以展开说明。
文生图大模型的人机对抗的实践应用
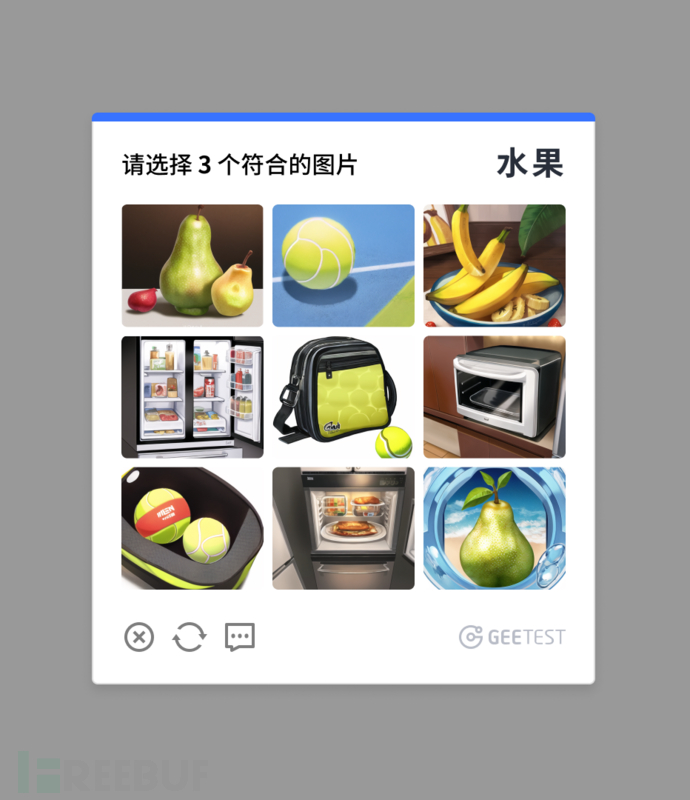
以上图片均为文生图大模型AI自动化生成,并在线上得到应用的场景
结语
人机验证码领域的图片生成的投入,主要解决的是“模型破解”和“人工打码”,这两种破解方式往往又不是独立进行,在特定情况下会产生人工标记训练后进行模型训练后进行自动对抗。所以,对于线上图片的更新,最后落脚之处还是在于图片的更新速度、图片的抗模型训练能力。
目前,极验每日API调用量高达数10亿次,在图片对抗的积累上,已经形成高标准的服务方案。极验按照线上所有图库资源进行每小时5万张、200个类别的自动更新的速率进行自动化更新,同时针对于瞬时要求比较高的客户,可以单独进行10分钟1万张、50个类别的速率自动化更新。现在,文生图大模型的进度,将会进一步加快更新速率,真正做到“世界上没有两片相同的树叶”,让黑产对抗的成本得到指数级的提升,从而放弃针对极验客户的攻击。
那么,前面介绍了我们在文生图大模型的投入,效果如何呢?我们将在下一期的文章中介绍:
1、文生图大模型的实际对抗数据分享2、文生图大模型的验证防破解优势
我们下期再见~

