
- 1Spring源码分析-BeanDefinition_spring源码系列之beandefinition
- 2Mac 解决配置 zsh 后,nvm不见的问题
- 3苹果微信分身双开怎么弄?2024最新苹果微信分身下载教程!
- 4AI代码生成助手Cursor、TabNine 、Cosy使用体验_cursor是基于chargbt的吗
- 5四、Hybrid_astar.py文件中Hybrid A * 算法程序的详细介绍
- 6微信小程序电子签名及图片生成_电子签名小程序
- 7腾讯云认证FAQ | 热门考试方向、考试报名流程、模拟试题等_腾讯云运维工程师认证
- 8Sublime text3 Version 3.22下载安装及注册_sublime 322 注册
- 9详解Python对Excel处理_python能处理xls文件吗
- 10《Flink原理、实战与性能优化》(Flink知识梳理一)
Hadoop3:HDFS中NameNode和SecondaryNameNode的工作机制(较复杂)
赞
踩
一、HDFS存储数据的机制简介
HDFS存储元数据(meta data)的时候
结果,记录在fsImage文件里
过程,记录在Edits文件里
同时fsImage+Edits=最终结果,这个最终结果(fsImage+Edits)会保存一份在内存中,为了提升性能
大家都知道,内存计算是最快的!
就有点像Redis的RDB和AOF持久化。
RDB是将某个时间点上Redis中的数据以快照的形式保存在硬盘中,它是以完整的数据角度进行持久化;
AOF是通过记录每一个写操作并追加到文件中进行持久化,它是以日志的形式记录完整的写入操作。
- 1
- 2
问题来了,我们在启动Hadoop的时候,会把结果加载到内存中,用于后面的计算。
用Edits来记录操作过程,那么,在关停服务的时候,合并Edits结果到fsImage中,
消耗的时间就非常多!!!
这样肯定不行。
这时候,就需要SecondaryNameNode来帮忙处理,当Edits达到一定界限时,就进行一次fsImage合并
二、服务器查看
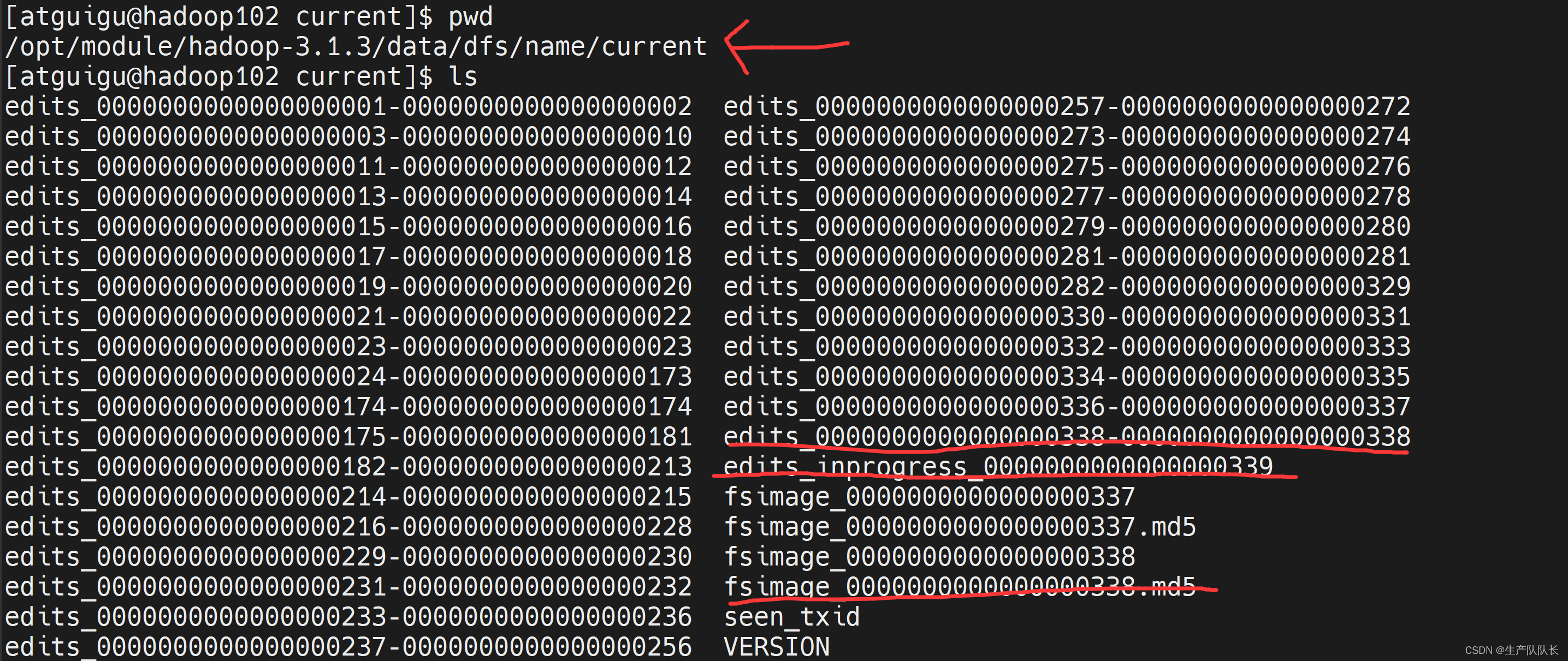
102上查看NameNode文件情况
104上查看SecondaryNameNode文件情况
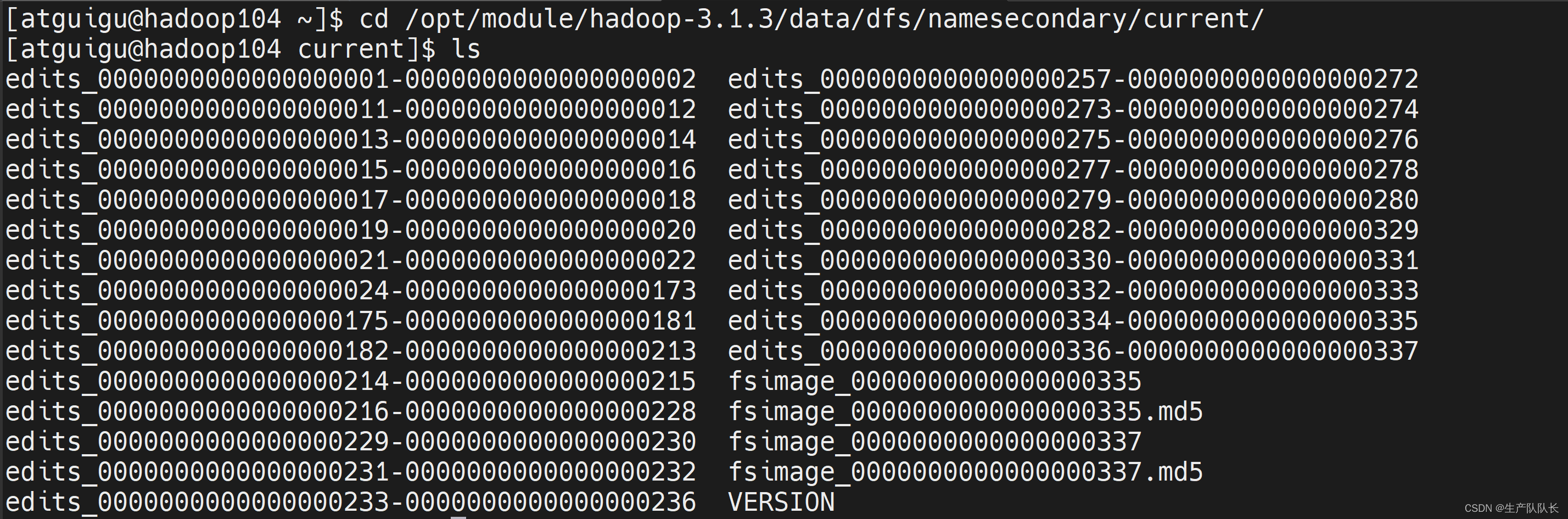
对比两者区别,会发现,NN节点比2NN节点多了一个edits_inprogress_xxxxxxx文件。
三、NameNode和SecondaryNameNode的工作机制
1、工作流程图
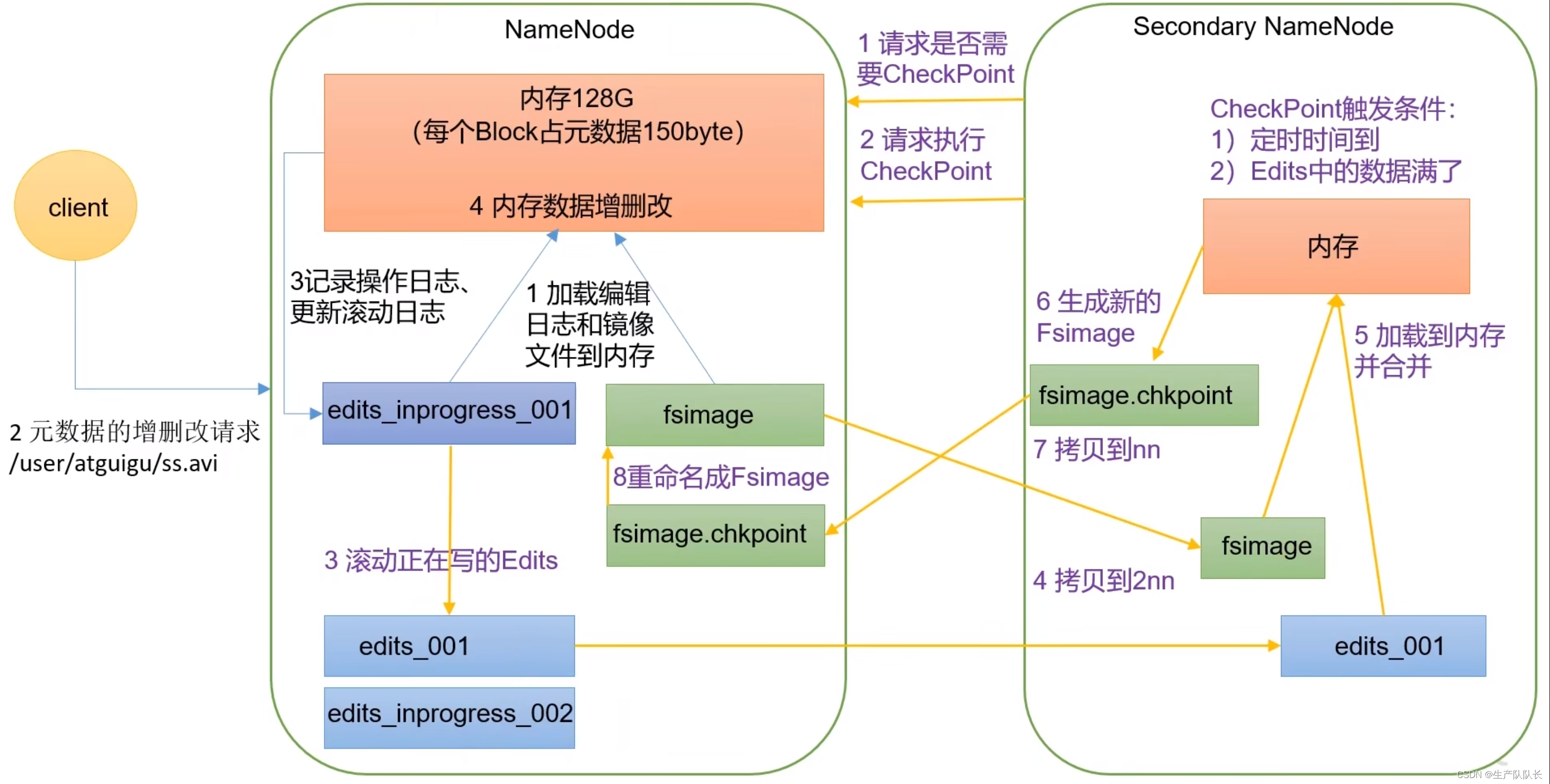
2、流程讲解
2.1、NameNode工作时机
1、第一次启动NameNode格式化后,创建Fsimage 和Edits 文件。如果不是第一次启动,直接加载已有的Fsimage和Edits到内存。
2、客户端发起对元数据进行增删改的请求。
3、NameNode记录操作日志,更新edits_inprogress_xxxxxxx文件。
4、NameNode更新内存中的元数据。
2.3、SecondaryNameNode工作时机
1、SecondaryNameNode发起询问请求,是否需要CheckPoint,NameNode直接返回是否CheckPoint的需求。
这个请求触发条件有两个
触发时间到了,默认是60min一次,进行一次CheckPoint。
edits操作次数达到100万次时,进行一次CheckPoint。(这个是1分钟2NN去检查一次NN的edits)
2、如果,返回需要执行CheckPoint,则SecondaryNameNode在次请求执行CheckPoint。
3、NameNode滚动正在编辑的edits_inprogress_xxxxxxx文件,更新为edits_001,并生成一个新的edits_inprogress_002文件。
4、SecondaryNameNode拷贝edits_001和Fsimage到自己所在节点机器上。
5、SecondaryNameNode加载edits_001和Fsimage到内存,进行合并操作,计算出最终结果。
6、SecondaryNameNode上,生成新的镜像文件fsimage.chkpoint文件。
7、拷贝fsimage.chkpoint文件到NameNode节点上。
8、NameNode将fsimage.chkpoint重新命名为fsimage文件,覆盖原有的fsimage文件。
四、总结
通过上面的流程讲解,我们可以知道,SecondaryNameNode上永远没有edits_inprogress_xxxxxxx文件,所以,当NameNode宕机时,SecondaryNameNode是无法代替NameNode进行工作的。
只能辅助帮助恢复元数据,但是可以修复大量的元数据。
补充:
1、CheckPoint检查时间配置
hdfs-default.xml文件,默认是3600s一次。
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
<description>
The number of seconds between two periodic checkpoints.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.
</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2、2NN检查edits中的操作次数
hdfs-default.xml文件
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>The Secondary NameNode or CheckpointNode will create a checkpoint
of the namespace every 'dfs.namenode.checkpoint.txns' transactions, regardless
of whether 'dfs.namenode.checkpoint.period' has expired.
</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description>The SecondaryNameNode and CheckpointNode will poll the NameNode
every 'dfs.namenode.checkpoint.check.period' seconds to query the number
of uncheckpointed transactions. Support multiple time unit suffix(case insensitive),
as described in dfs.heartbeat.interval.
</description>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
注意:
另外,这个作为了解知识,因为在实际的企业中,保证集群的高可用,不用2NN来实现。一句话,时机生产中,2NN不适用!!!

