
- 1华为盒子EC6110-T_悦me高安版_线刷固件(通刷版)_ec6110t刷机教程
- 2香橙派AIpro(OrangePi AIPro)开发板初测评
- 32021爱分析·中国人工智能应用趋势报告——新基建助推,人工智能应用迈入新阶段_ocr拉新
- 4CVPR 2022 | 北大&腾讯开源:文字Logo生成模型!脑洞大开堪比设计师
- 5单向链表ArrayList跟LinkedList的实现代码_arraylist转换成链表
- 6VMware虚拟机下载安装教程【详细步骤 - 图文结合】
- 7上线即碾压Github榜首!十大互联网Docker实战案例手册(大厂版)_docker除了github
- 8初识Hadoop_vwjle
- 9大数据开发教程——构建Hadoop开发环境
- 10ChatGPT技术演进简介
transformer的一些理解以及逐层架构剖析与pytorch代码实现_transformer和pytorch
赞
踩
文章目录
前言
transformer模型是一个将注意力机制发挥到极致的模型,有两个显著的优势:1.能够进行分布式计算,使得训练效率大大提高。2.能够对长文本语义有更好的捕获效果。
transformer模型还是比较复杂的,我这篇文章是参考b站的一个教程https://www.bilibili.com/video/BV1Wr4y1n7JM?p=1
写下来的,感觉他讲的很不错,看一遍下来也基本懂transformer是如何架构的了。
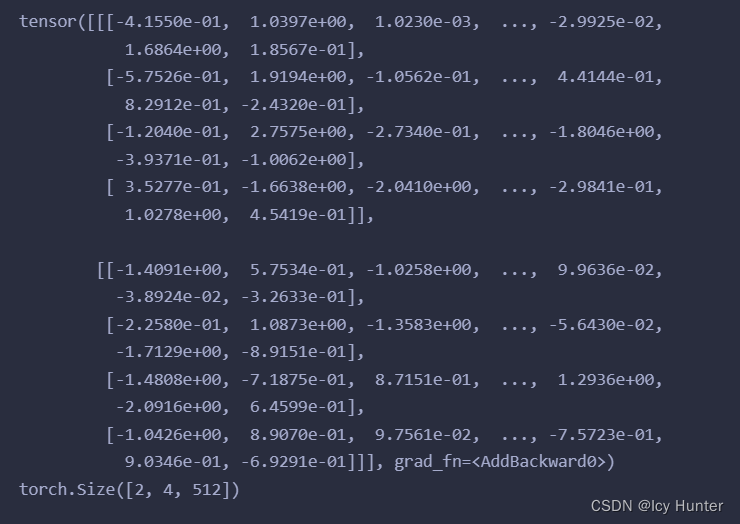
一、transformer的架构
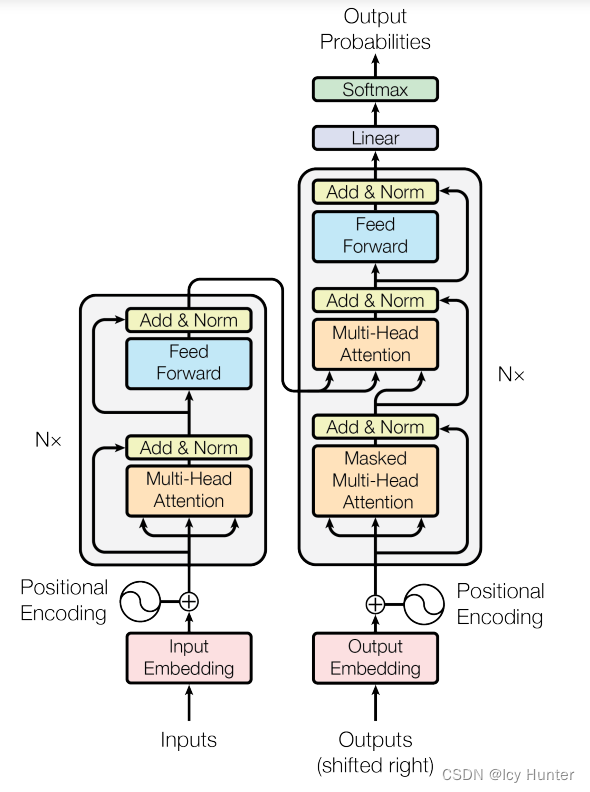
transformer的架构这张流程图就已经表达的很清晰明了了,但是对于我们这样的初学者来说,一些细节以及代码实现还是十分有困难的。
但不管怎么说,transformer最初诞生是用于机器翻译的,因此拥有标准的编码器和解码器架构,只不过是编码器和解码器稍微复杂了点。接下来将逐步讲解transformer的架构和代码实现。
二、transformer需要用到的三级部件
需要用到的相关库如下:
import torch
import torch.nn as nn
import math
from torch.autograd import Variable
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as F
import copy
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
(建议使用jupyter格式.ipynb来允许比较好,方便运行)
1.词嵌入层(Embedding)

论文中提到编码器、解码器、softmax前都需要有个embedding层,这三个层的参数是共享的,值得注意的是,这里embedding层需要乘 √dmodel,即embedding_size,一般取512。
class Embeddings(nn.Module):
def __init__(self, d_model, vocab):
# d_model:词嵌入维度
# vocab:字典大小
super(Embeddings, self).__init__()
self.lut = nn.Embedding(vocab, d_model)
self.d_model = d_model
def forward(self, x):
return self.lut(x) * math.sqrt(self.d_model)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
可以测试一下embedding层:
d_model = 512 # embedding_size
vocab = 1000 # 词典大小
x = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
emb = Embeddings(d_model, vocab)
embr = emb(x)
print(embr.shape)
- 1
- 2
- 3
- 4
- 5
- 6
这里对八个词进行编码,得出结果:

2.位置编码器(PositionalEncoding)
由于transformer抛弃了原始RNN的序列计算结构,能够进行并行计算,这样也就失去了原本重要的序列信息,而对于NLP序列信息十分重要,因此使用transformer中使用位置编码器来记录各个词的序列信息。
代码如下:
class PositionalEncoding(nn.Module): def __init__(self, d_model, dropout, max_len=5000): # d_model:词嵌入维度 # dropout:置零比率 # max_len:每个句子最大的长度 super(PositionalEncoding, self).__init__() self.dropout = nn.Dropout(p=dropout) pe = torch.zeros(max_len, d_model) position = torch.arange(0, max_len).unsqueeze(1) div_term = torch.exp(torch.arange(0, d_model, 2) * -(math.log(1000.0) / d_model)) pe[:, 0::2] = torch.sin(position * div_term) pe[:, 1::2] = torch.cos(position * div_term) pe = pe.unsqueeze(0) self.register_buffer("pe", pe) def forward(self, x): x = x + Variable(self.pe[:, :x.size(1)], requires_grad=False) return self.dropout(x)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
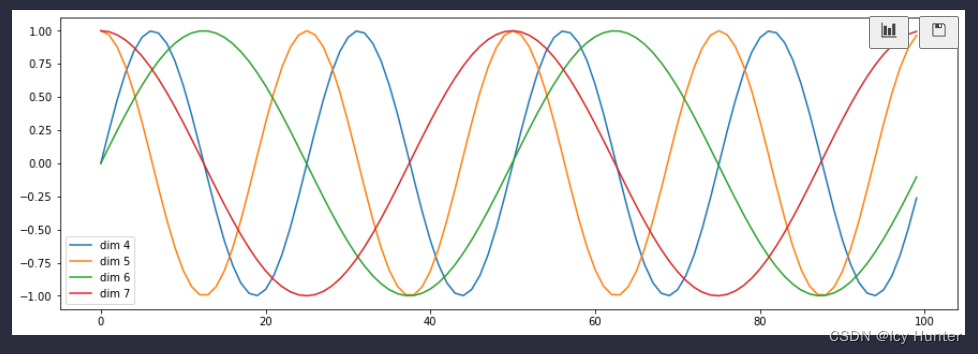
transformer是使用sin和cos来分别对偶数位置词和奇数位置词进行位置编码,将位置信息直接加入embedding层中就是使用了位置编码了。
下面可以测试一下位置编码器:
dropout = 0.1
max_len = 60
pe = PositionalEncoding(d_model, dropout, max_len)
pe_result = pe(embr)
print(pe_result.shape)
plt.figure(figsize=(15, 5))
pe = PositionalEncoding(20, 0)
# 传入全0参数,相当于展示位置编码
y = pe(Variable(torch.zeros(1, 100, 20)))
plt.plot(np.arange(100), y[0, :, 4:8].data.numpy())
plt.legend(["dim %d" %p for p in [4, 5, 6, 7]])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
输出结果:

3.掩码张量生成器(subsequent_mask)
在transformer中, 掩码张量的主要作用在应用attention,有一些生成的attention张量中的值计算有可能已知了未来信息而得到的,未来信息被看到是因为训练时会把整个输出结果都一次性进行Embedding,但是理论上解码器的的输出却不是一次就能产生最终结果的,而是一次次通过上一次结果综合得出的,因此,未来的信息可能被提前利用. 所以,需要进行遮掩
def subsequent_mask(size):
attn_shape = (1, size, size)
subsequent_mask = np.triu(np.ones(attn_shape), k=1).astype("uint8")
return torch.from_numpy(1 - subsequent_mask)
- 1
- 2
- 3
- 4
测试一下:
sm = subsequent_mask(5)
print(sm)
plt.figure(figsize=(5, 5))
plt.imshow(subsequent_mask(20)[0])
- 1
- 2
- 3
- 4
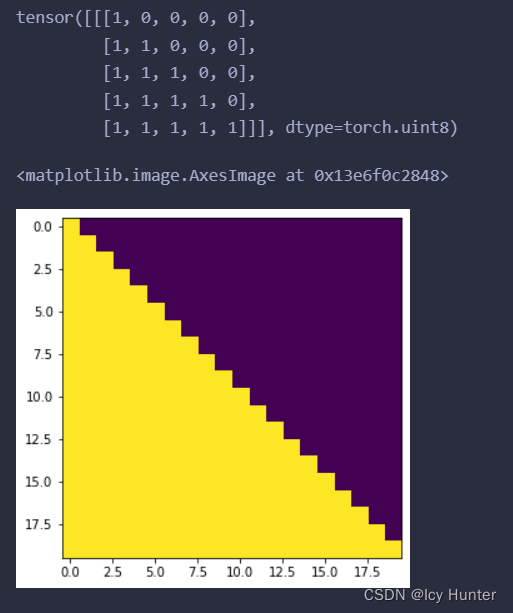
输出如上,例如在第0列看不到任何一个词,第一列能够看到第一个词…以此类推,就使得注意力机制能够只看到该看的东西。
4.注意力机制层(Attention)
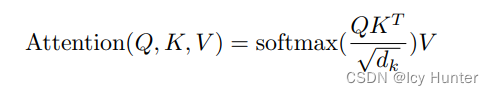
Q、K、V分别表示query、key、value。有个比喻解释:有一段文本,为了提示方便更好的获取正确答案,给出的提示就是key,文本的原文就是query,value就是当你看到这段文本和提示后,脑子里所想到的答案。transformer中使用的是自注意力机制,即Q、K、V的输入都是相同的。
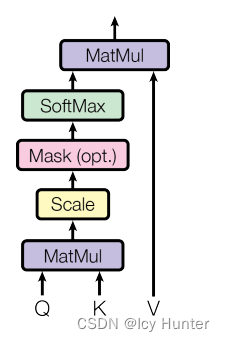
def attention(query, key, value, mask=None, dropout=None):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
if dropout is not None:
p_attn = dropout(p_attn)
return torch.matmul(p_attn, value), p_attn
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
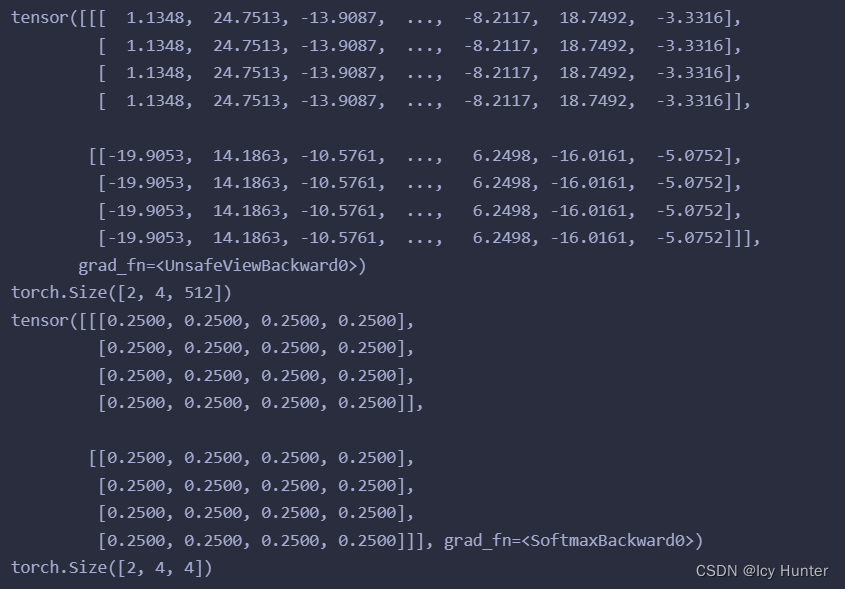
测试一下:
query = key = value = pe_result
mask = Variable(torch.zeros(2, 4, 4))
attn, p_attn = attention(query, key, value, mask=mask)
print(attn)
print(attn.shape)
print(p_attn)
print(p_attn.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
输出:
5.多头注意力机制层(MultiHeadedAttention)
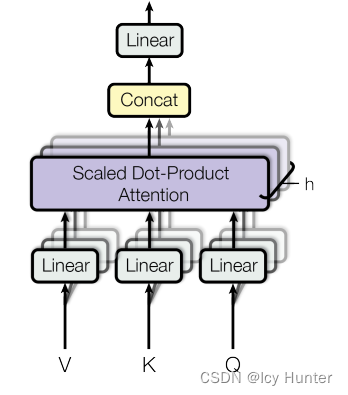
多头注意力机制的基本思路就是,将原本的Q、K、V分别通过线性层投影成若干个小的Q、K、V,然后各自计算attention最后将结果拼接再经过线性层得到最终多头注意力机制的结果,这样一来,注意力机制部分能够学习的东西变多了,使得能够更好更多的注意不同的方面,从而提示效果。
# 深层拷贝 def clones(module, N): return nn.ModuleList([copy.deepcopy(module) for _ in range(N)]) class MultiHeadedAttention(nn.Module): def __init__(self, head, embedding_dim, dropout=0.1): # head:代表几个头 # embedding_dim:词嵌入维度 # dropout:置0比率 super(MultiHeadedAttention, self).__init__() # 确认embedding_dim能够被head整除 assert embedding_dim % head == 0 self.head = head self.d_k = embedding_dim // head # 获得4个线性层, 分别是Q、K、V、以及最终的输出的线形层 self.linears = clones(nn.Linear(embedding_dim, embedding_dim), 4) self.attn = None self.dropout = nn.Dropout(p=dropout) def forward(self, query, key, value, mask=None): if mask is not None: mask = mask.unsqueeze(0) batch_size = query.size(0) # 经过线性层投影后分成head个注意力头 query, key, value = [model(x).view(batch_size, -1, self.head, self.d_k).transpose(1, 2) for model, x in zip(self.linears, (query, key, value))] # 各自计算每个头的注意力 x, self.attn = attention(query, key, value, mask=mask, dropout=self.dropout) # 转换回来 x = x.transpose(1, 2).contiguous().view(batch_size, -1, self.head * self.d_k) # 经过最后一个线性层得到最终多头注意力机制的结果 return self.linears[-1](x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
测试一下:
head = 8
embedding_dim = 512
dropout = 0.2
query = key = value = pe_result
mask = Variable(torch.zeros(8, 4, 4))
mha = MultiHeadedAttention(head, embedding_dim, dropout)
mha_result = mha(query, key, value, mask)
print(mha_result)
print(mha_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9

6.前馈全连接层(PositionwiseFeedForward)
考虑注意力机制可能对复杂的情况拟合程度不够,因此增加两层网络来增强模型的能力。
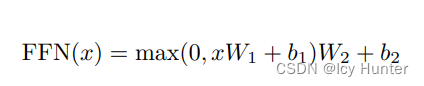
前馈全连接层就是两次线性层+Relu激活
class PositionwiseFeedForward(nn.Module):
def __init__(self, d_model, d_ff, dropout=0.1):
super(PositionwiseFeedForward, self).__init__()
self.w1 = nn.Linear(d_model, d_ff)
self.w2 = nn.Linear(d_ff, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x):
return self.w2(self.dropout(F.relu(self.w1(x))))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试一下:
d_model = 512
d_ff = 64
dropout = 0.2
x = mha_result
ff = PositionwiseFeedForward(d_model, d_ff, dropout=dropout)
ff_result = ff(x)
print(ff_result)
print(ff_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
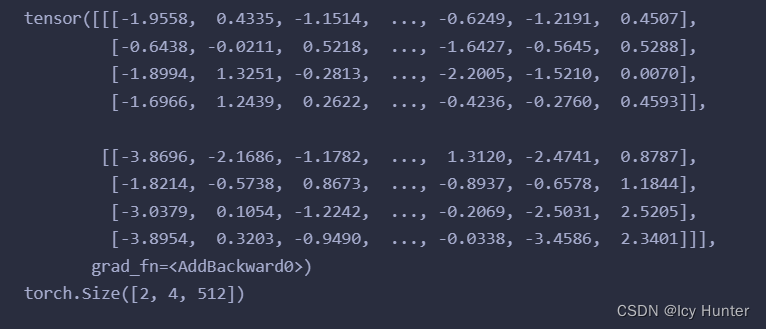
7.规范化层(LayerNorm)
规范化层是深层神经网络的标配,因为经过多层网络的计算,可能导致参数过大或者过小,影响模型收敛,因此需要规范化,使数值处于一个合理的区间。
class LayerNorm(nn.Module):
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a2 = nn.Parameter(torch.ones(features))
self.b2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
mean = x.mean(-1, keepdim = True)
std = x.std(-1, keepdim = True)
return self.a2 * (x - mean) / (std + self.eps) + self.b2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
torch中其实也自带规范化层
测试一下:
ln = LayerNorm(features)
lnn = nn.LayerNorm(features)
ln_result = ln(x)
lnn_result = lnn(x)
print(ln_result)
print(ln_result.shape)
print(lnn_result)
print(lnn_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8

两个结果差不多
8.子层连接结构(SublayerConnection)
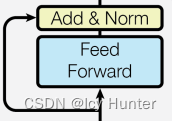
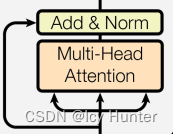
残差连接多头注意力结果的这一层就是子层连接结构,就是Add&Norm这一层。
class SublayerConnection(nn.Module):
def __init__(self, size, dropout=0.1):
super(SublayerConnection, self).__init__()
self.norm = LayerNorm(size)
self.dropout = nn.Dropout(p=dropout)
self.size = size
def forward(self, x, sublayer):
return x + self.dropout(sublayer(self.norm(x)))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
测试一下:
size = 512
dropout = 0.2
head = 8
d_model = 512
x = pe_result
mask = Variable(torch.zeros(8, 4, 4))
self_attn = MultiHeadedAttention(head, d_model)
sublayer = lambda x: self_attn(x, x, x, mask)
sc = SublayerConnection(size, dropout)
sc_result = sc(x, sublayer)
print(sc_result)
print(sc_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12

三、transformer的二级部件
1.编码器层(EncoderLayer)
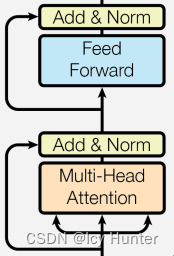
编码器层就是由一个多头注意力机制层、一个前馈全连接层和两个子层连接结构组成。
class EncoderLayer(nn.Module):
def __init__(self, size, self_attn, feed_forward, dropout):
# size:词嵌入的维度
# self_attn:代表输入的多头子注意力层的实例化对象
# feed_forward:代表前馈全连接层的实例化对象
# dropout:置0比例
super(EncoderLayer, self).__init__()
self.self_attn = self_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 2)
self.size = size
def forward(self, x, mask):
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, mask))
return self.sublayer[1](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
测试一下:
size = 512
head = 8
d_model = 512
d_ff = 64
x = pe_result
dropout = 0.2
self_attn = MultiHeadedAttention(head, d_model)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
mask = Variable(torch.zeros(8, 4, 4))
el = EncoderLayer(size, self_attn, ff, dropout)
el_result = el(x, mask)
print(el_result)
print(el_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果:
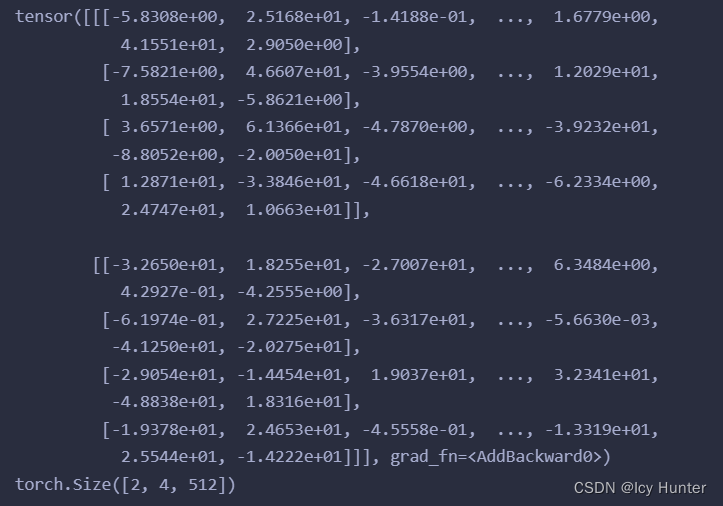
2.编码器(Encoder)
就是将编码器层复制N份就可以了。
# 编码器
class Encoder(nn.Module):
def __init__(self, layer, N):
super(Encoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, mask):
for layer in self.layers:
x = layer(x, mask)
return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
测试一下:
size = 512 head = 8 d_model = 512 d_ff = 64 c = copy.deepcopy dropout = 0.2 attn = MultiHeadedAttention(head, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) mask = Variable(torch.zeros(8, 4, 4)) layer = EncoderLayer(size, c(attn), c(ff), dropout) N = 8 mask = Variable(torch.zeros(8, 4, 4)) en = Encoder(layer, N) en_result = en(x, mask) print(en_result) print(en_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
结果
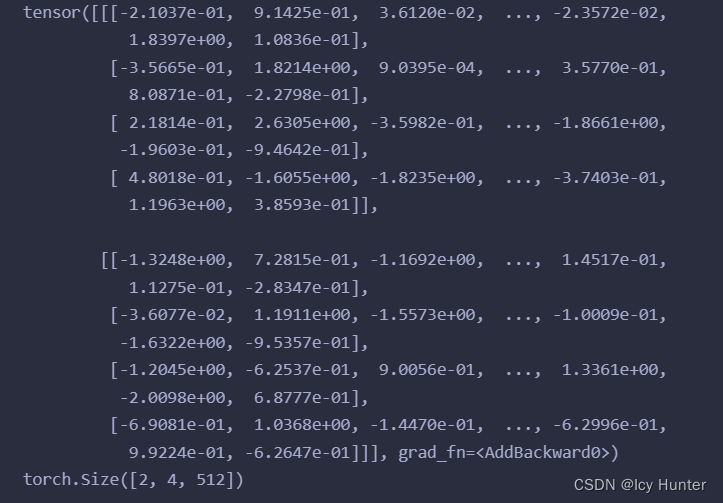
3.解码器层(DecoderLayer)
解码器层由两个多头注意力层、三个子层连接结构和一个前馈全连接层组成。
class DecoderLayer(nn.Module):
def __init__(self, size, self_attn, src_attn, feed_forward, dropout):
super(DecoderLayer, self).__init__()
self.size = size
self.self_attn = self_attn
self.src_attn = src_attn
self.feed_forward = feed_forward
self.sublayer = clones(SublayerConnection(size, dropout), 3)
def forward(self, x, memory, source_mask, target_mask):
m = memory
x = self.sublayer[0](x, lambda x: self.self_attn(x, x, x, target_mask))
x = self.sublayer[1](x, lambda x: self.src_attn(x, m, m, source_mask))
return self.sublayer[2](x, self.feed_forward)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
测试一下:
(对原数据进行mask和对目标数据进行mask目的不同。对原数据进行mask是为了让注意力更加关注相对有用的信息,对目标数据进行遮掩,是为了让解码的时候不让其获取当前词之后信息,使得解码过程符合实际)
head = 8
size = d_model = 512
d_ff = 64
dropout = 0.2
self_attn = src_attn = MultiHeadedAttention(head, d_model, dropout)
ff = PositionwiseFeedForward(d_model, d_ff, dropout)
x = pe_result
memory = en_result
mask = Variable(torch.zeros(8, 4, 4))
source_mask = target_mask = mask # 这里为了方便演示就直接设置一样了
dl = DecoderLayer(size, self_attn, src_attn, ff, dropout)
dl_result = dl(x, memory, source_mask, target_mask)
print(dl_result)
print(dl_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
结果:
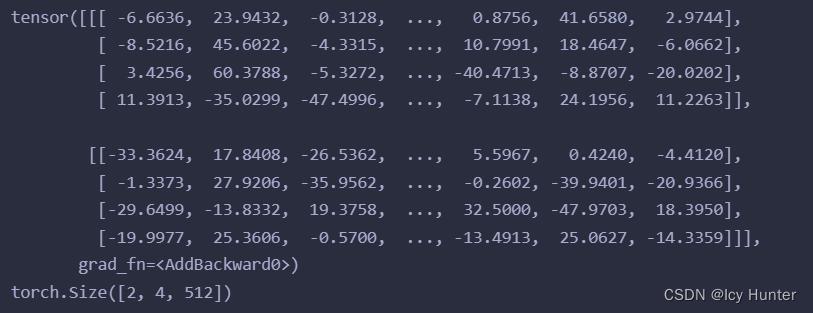
4.解码器(Decoder)
解码器就是解码器层复制N份
class Decoder(nn.Module):
def __init__(self, layer, N):
super(Decoder, self).__init__()
self.layers = clones(layer, N)
self.norm = LayerNorm(layer.size)
def forward(self, x, memory, source_mask, target_mask):
# x:词嵌入维度
# memory:代表编码器的输出张量
# source_mask:原数据的掩码张量
# target_mask:目标数据的掩码张量
for layer in self.layers:
x = layer(x, memory, source_mask, target_mask)
return self.norm(x)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
测试一下:
size = 512 head = 8 d_model = 512 d_ff = 64 c = copy.deepcopy dropout = 0.2 attn = MultiHeadedAttention(head, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) layer = DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout) memory = en_result mask = Variable(torch.zeros(8, 4, 4)) source_mask = target_mask = mask N = 8 x = pe_result de = Decoder(layer, N) de_result = de(x, memory, source_mask, target_mask) print(de_result) print(de_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
结果
5.输出层(Generator)
最后输出就是经过一个线性层然后取softmax就可以了。
class Generator(nn.Module):
def __init__(self, d_model, vocab_size):
super(Generator, self).__init__()
self.project = nn.Linear(d_model, vocab_size)
def forward(self, x):
return F.softmax(self.project(x), dim=-1)
- 1
- 2
- 3
- 4
- 5
- 6
测试一下:
vocab_size = 1000
gen = Generator(d_model, vocab_size)
x = de_result
gen_result = gen(x)
print(gen_result)
print(gen_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
结果
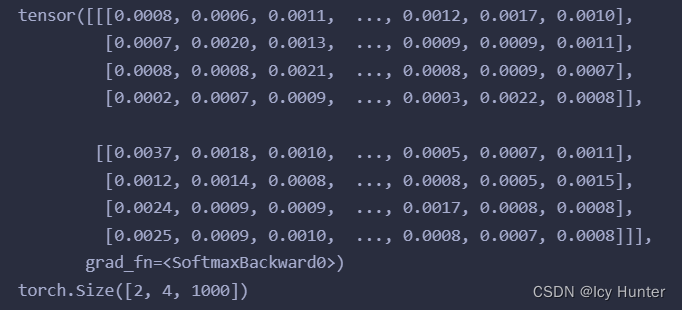
6.输入层
就是embedding层+位置编码,其实已经嵌入了之前编码器和解码器里了。
三、transformer的一级部件
1.编码器-解码器
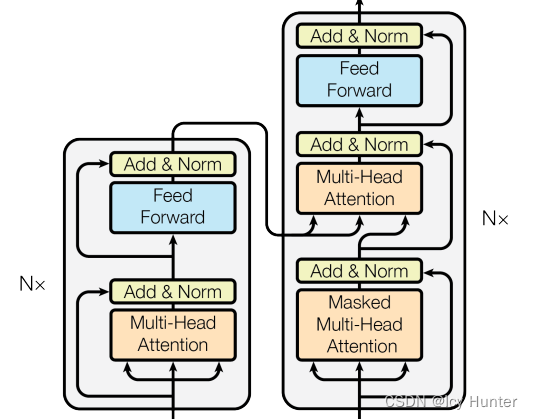
就是将之前的编码器和解码器拼接起来。
class EncoderDecoder(nn.Module): def __init__(self, encoder, decoder, source_embed, target_embed, generator): # encoder:编码器对象 # decoder:解码器对象 # source_embed:原数据词嵌入 # target_embed:目标数据词嵌入 # generator:输出部分类别生成器 super(EncoderDecoder, self).__init__() self.encoder = encoder self.decoder = decoder self.src_embed = source_embed self.tgt_embed = target_embed self.generator = generator def forward(self, source, target, source_mask, target_mask): return self.decode(self.encode(source, source_mask), source_mask, target, target_mask) def encode(self, source, source_mask): return self.encoder(self.src_embed(source), source_mask) def decode(self, memory, source_mask, target, target_mask): return self.decoder(self.tgt_embed(target), memory, source_mask, target_mask)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
测试一下:
vocab_size = 1000
d_model = 512
encoder = en
decoder = de
source_embed = nn.Embedding(vocab_size, d_model)
target_embed = nn.Embedding(vocab_size, d_model)
generator = gen
source = target = Variable(torch.LongTensor([[100, 2, 421, 508], [491, 998, 1, 221]]))
source_mask = target_mask = Variable(torch.zeros(8, 4, 4))
ed = EncoderDecoder(encoder, decoder, source_embed, target_embed, generator)
ed_result = ed(source, target, source_mask, target_mask)
print(ed_result)
print(ed_result.shape)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
结果:

四、transformer的实现
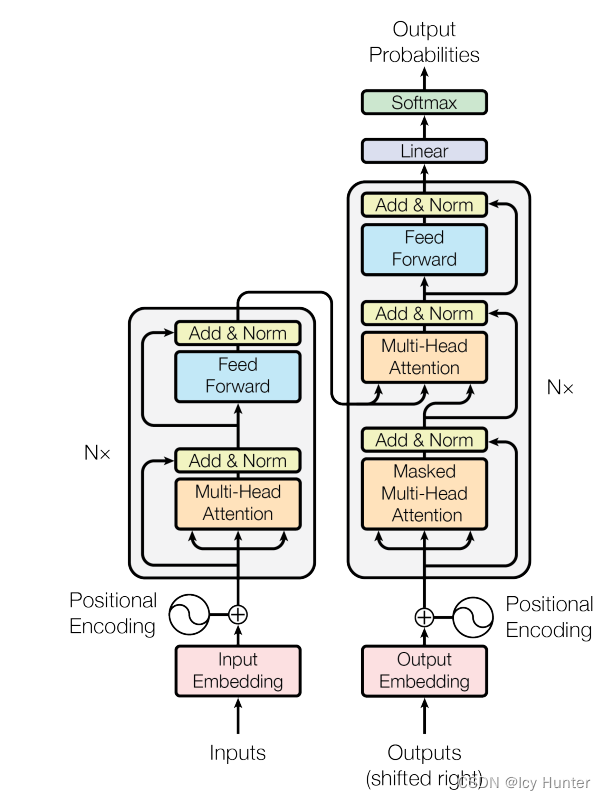
又回到了最初的流程图,那么此时可以将transformer模型构建出来了。
def make_transformer_model(source_vocab, target_vocab, N=6, d_model=512, d_ff=64, head=8, dropout=0.1): c = copy.deepcopy attn = MultiHeadedAttention(head, d_model) ff = PositionwiseFeedForward(d_model, d_ff, dropout) position = PositionalEncoding(d_model, dropout) model = EncoderDecoder( Encoder(EncoderLayer(d_model, c(attn), c(ff), dropout), N), Decoder(DecoderLayer(d_model, c(attn), c(attn), c(ff), dropout), N), nn.Sequential(Embeddings(d_model, source_vocab), c(position)), nn.Sequential(Embeddings(d_model, target_vocab), c(position)), Generator(d_model, target_vocab)) for p in model.parameters(): if p.dim()>1: nn.init.xavier_uniform(p) return model
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
测试一下:
source_vocab = 11
target_vocab = 11
N = 6
res = make_transformer_model(source_vocab, target_vocab, N)
print(res)
- 1
- 2
- 3
- 4
- 5
结果
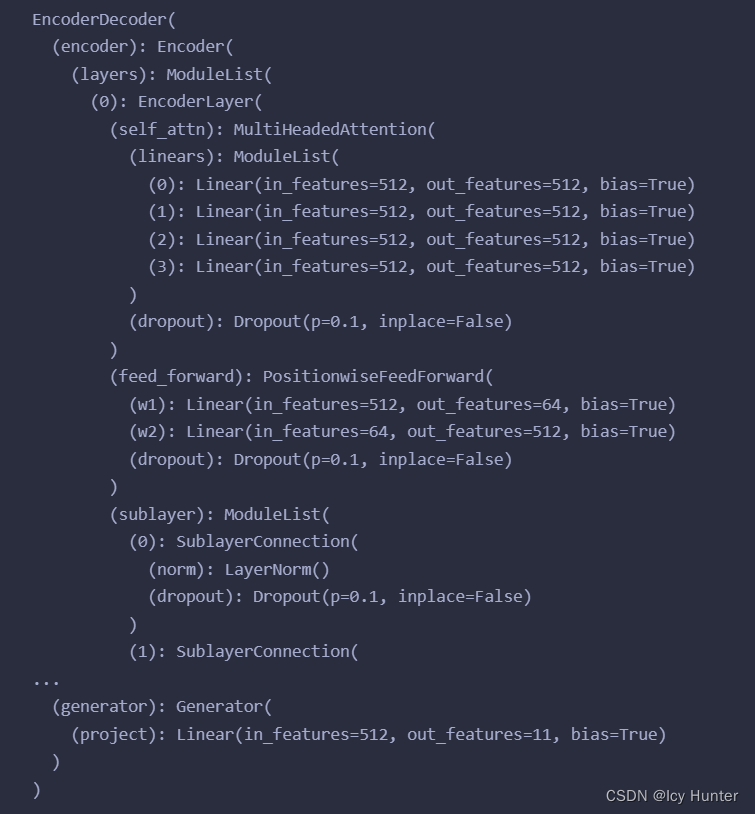
至此,终于,transformer模型以及构建完成。
总结
个人感觉transformer模型确实比较复杂,在看了b站等一些大佬的讲解之后,发现确实复杂,而且论文原文其实讲解的很糙,对我们这种新手不是很友好,但是好在在b站找到一个十分好的教程,一遍看下来,跟着代码敲下来,感觉大概懂这个模型是怎么架构的。

