
- 1大数据与财会行业未来机遇与挑战下的领域——大数据资产的估值_与会计专业有关的数据图片
- 2【全开源】JAVA同城搬家系统源码小程序APP源码
- 3mysql 锁表确认及解除锁表_mysql锁表如何解锁
- 4CDH | Spark升级_cdh spark2和3 区别 cdh spark升级
- 5AI编程篇-python基础篇_python ai编程
- 6java学习资源分享_javaweb学习资源百度云
- 7清华大学范玉顺互联网与大数据_清华大学范玉顺:大数据、人工智能与工业互联网...
- 8vue router 参数_让构建单页面应用变得易如反掌 Vue3中的router
- 9安卓程序的开机动画详解(Animation 一)_app的开机动画
- 10Vue2+Echarts+koa2+websocket电商平台数据可视化实时检测系统(一)_vue 调佣echarts 和 websocket 时需要分开写js文件吗
CVPR 2022 | 北大&腾讯开源:文字Logo生成模型!脑洞大开堪比设计师
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
转载自:机器之心
下图的每对 logo 中,一个是设计师设计的 logo,另一个是 AI 模型生成的,顺序不确定,你能分辨出哪些是 AI 模型生成的吗?(答案在文末揭晓)

文字标志(text logo)的设计非常依赖于设计师的创意和经验,其中,如何安排每个文字元素的布局是一个核心问题。布局设计需要考虑到很多因素,如字形、文字语义、主题等。例如,不同的文字之间通常不能有形状重叠;对于要强调语义的文字,通常使用较大的尺寸;斜切和旋转等几何变换可以分别体现力量感和欢乐感等主题。业内现有的方案大多是设计一套易于执行的规则,按照一些预先设定好的模板来设计布局,但是生成的结果往往会比较单调且缺乏创意和美感。
最近,北京大学王选计算机所和腾讯针对这个问题,提出了一种内容感知的文字标志图像生成模型,从大量现有的文字 logo 中隐式地学习布局设计规则,从而能够对任意输入的字形生成新的 logo。
该工作已经被 CVPR2022 接收,相关数据集和代码已经开源。

论文: https://arxiv.org/abs/2204.02701
数据集和代码: https://github.com/yizhiwang96/TextLogoLayout
一、数据集
训练 AI 模型通常需要大量的数据,然而业内尚不存在针对该任务的数据集。为了解决该问题,本文提出了 TextLogo3K 数据集,借助腾讯视频平台,收集、标注了 3,470 张精心挑选的文字 logo 图,这些 logo 来源于电影、电视剧和动漫的封面图。该数据集对字形进行了像素级别的精准标注,也标注了字形包围框、字符类别。

图 1 TextLogo3K 中 Logo 图像的标注
同时,它们在原海报图片中的位置和分割信息也一并提供:

图 2 TextLogo3K 中海报图像的标注
该数据集免费提供给用户做学术研究使用(禁止任何商业用途)。除了文字 logo 生成,该数据集同样可以应用于文本检测和识别、艺术字体生成、纹理特效迁移、场景文字编辑等任务。
二、模型设计
2.1 流程框图
本模型的流程框图如下图所示:
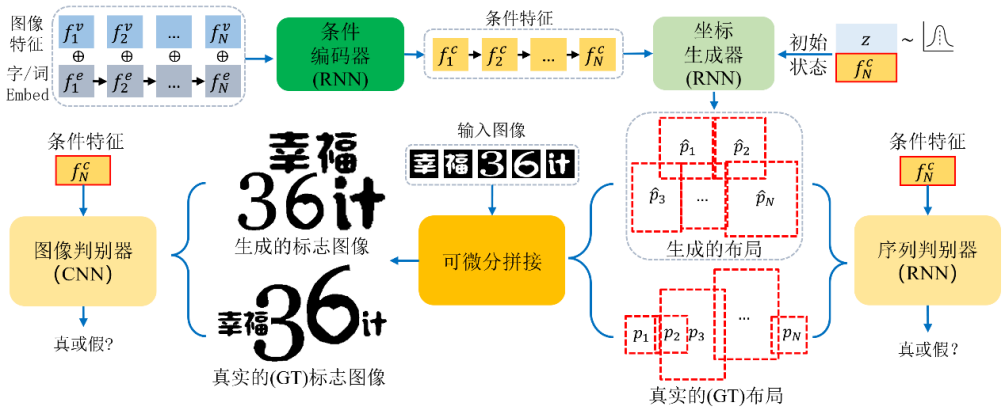
图 3 本文模型流程框图
本模型基于 Conditional GAN 来生成文字 logo,创新性地使用双判别器结构(序列判别器和图像判别器),对字形的轨迹序列和整体 logo 图像分别做判别;同时借助可微分拼接(Differentiable Composition),构建位置坐标到 logo 图像的可微分渲染过程。其主要的流程包括:
首先利用输入元素的双模态的特征(即字形视觉特征和文本语义特征),将其编码成条件特征。
坐标生成器采用条件特征和一个随机噪声作为输入, 为每个字符预测位置坐标,即字形外接框的中心点坐标,宽和高。
每个字符的位置坐标形成一条轨迹序列,故采用一个序列判别器去根据条件对序列和做真假判别。注意到本任务中坐标值是连续的,保证了序列判别器可以传播梯度。
通过可微分拼接, 合并每个字形得到的 logo 图像。
引入图像判别器,作为序列判别器的补充,目的是进一步捕捉到标志图像的细节信息,保证不同的字形之间不会有较大的重叠,字形间距合理等。
网络的整体优化目标函数如下:
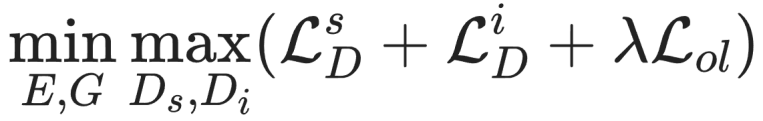
其中,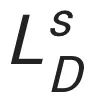 是序列判别器损失,
是序列判别器损失,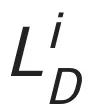 是图像判别器损失,
是图像判别器损失,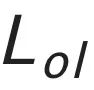 是显式的字形重叠损失(详情见论文)。E 代表条件编码器,G 代表坐标生成器,
是显式的字形重叠损失(详情见论文)。E 代表条件编码器,G 代表坐标生成器, 和
和 分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
分别代码表序列判别器和图像判别器。其中,可微分拼接和双判别器的具体技术细节在后续小节进一步介绍。
2.2 可微分拼接
在获得预测的几何参数之后,需要进一步将每个字形图像按照这些几何参数拼接成一个文字 logo。更重要的是,这个拼接过程必须是可微分的,以让整个模型可以端到端地被优化。为了达成这个目的,本文设计了一个基于 STN(Spatial Transform Networks)变种的可微分拼接方法。在原始的 STN 中,仿射变换参数是使用神经网络直接直接预测。本文方法先预测得到了目标字形位置坐标,于是先建立原坐标到目标坐标的映射关系(下图左),手动解出仿射变换的参数(下图右)。通过这种方式,既可以保证目标字形的位置坐标在画布的范围之内,又可以利用 STN 的可微分采样算法。

图 4 显式求解仿射变换参数
通常来说,在文字 logo 中不同字形之间不会有重叠(有一些故意的设计除外),因此不需要考虑每个字形之间的图层关系。将每个字形变换的图像直接进行加法操作,即可得到 logo 图像,结合上述步骤,可微分拼接的整体过程都是可微分的。
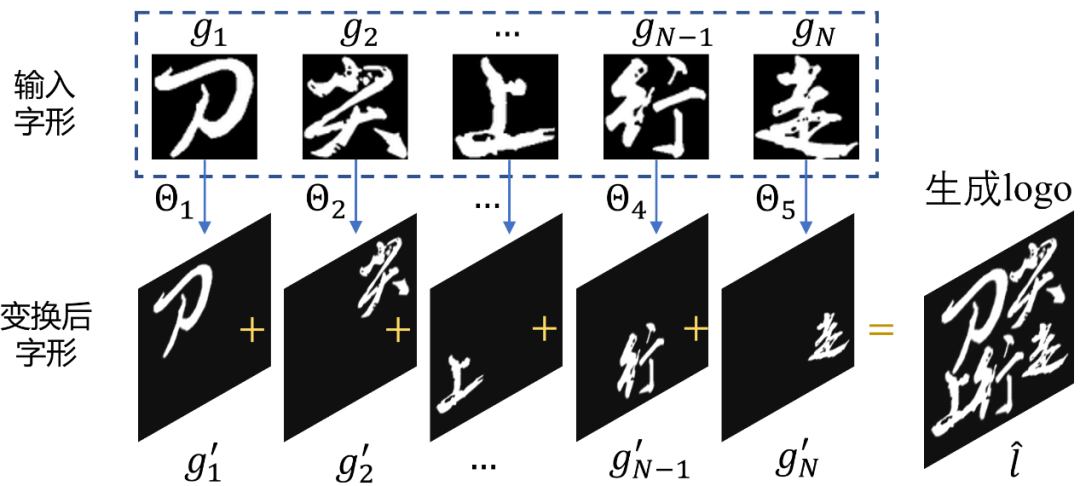
图 5 根据求解参数合成 logo 图像
2.3 双判别器结构
字符的放置轨迹应该既符合人们的阅读习惯,又呈现出多样的风格。然而,这两个特性不容易被图像生成模型中常用的卷积神经网络(CNNs)所捕获到。为了解决这个问题,本文设计了一个双判别器的模块,包括一个序列判别器和一个图像判别器。序列判别器以条件特征作为初始状态,将几何参数的序列作为输入,去分析这个放置轨迹的合理性。
序列判别器并不能够捕捉到细粒度的信息(如笔画等),因为它仅仅接收几何参数作为输入。于是,本模型引入图像判别器去进一步探究 logo 图像(人工设计的或者本模型生成的)的合理性,并预测它们的真假。根据业内的常见做法,将条件特征进行堆叠再放置到的第一个卷积层之后,用作判别条件。
三、实验
3.1 布局生成结果展示
如图 6 和图 7 所示,本模型可以生成英文 logo 图,也可以生成中文 logo。

图 6 本模型在英文数据集上结果

图 7 本模型在中文数据集上结果
其中,“ours”所在列表示本模型生成结果,“GT”表示设计师设计的结果。本模型生成的布局具有丰富的多样性:如(1)根据具体字形安排布局,如 “B + 侦探” 中,将 “+” 号巧妙地安排到 “B” 右下角和 “侦” 左下角之间;(2)根据语义进行换行,如 “神探包青天” 和“春风十里不如你”。
3.2 与其他方法对比
本文与 2D 图形布局生成工作 LayoutGAN(Li et al, ICLR 2018)和 layoutNet(Zheng et al, TOG 2019)进行了对比,这两种方法没有考虑到空间布局上的序列信息,以及输入元素的自身本文语义信息,所以不能处理该任务。如图 8 所示,本模型生成了更好的结果。

图 8 与现有方法对比
3.3 布局风格分析
通过主成分分析方法(PCA),对隐空间噪声 z 进行了可视化实验,结果展示在图 9 中。结果发现,(1)垂直的布局(B2, C2, H2, E3)倾向于落在平面的左边;(2)水平的布局(A1-E1, H1, G2)倾向于落在平面的中间和上方;(3)多行的布局(A2, D2, E2, F2)倾向于落在平面的右下方;(4)不规则的布局(F1,G1)倾向落在平面的边缘。隐空间噪声 z 和输入文本的长度变量是正交的。该可视化方法可以引导设计师探索布局风格的隐空间,帮助他们挑选喜欢的风格。
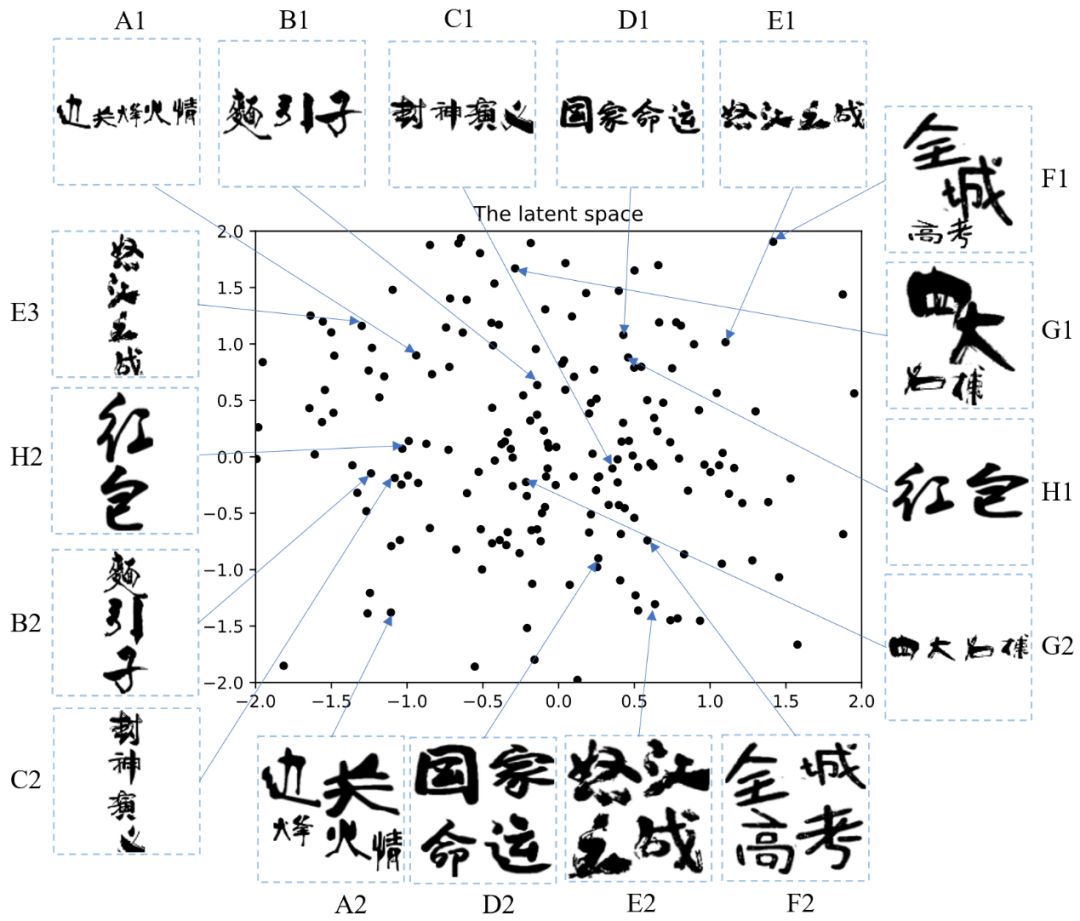
图 9 隐空间噪声 z 的可视化结果
3.4 主观评价
本文开展了一项用户调查,用于收集用户对于本模型生成结果的主观评价,用户群体包括 27 个专业设计师和 52 个其他职业者。使用了 20 对测试图片(模型生成和人工设计的),让用户(1)选择哪个是 AI 生成的:下表中的 “准确率” 表示用户挑出本模型结果的概率,越低越好;(2)选择自己更倾向于哪个:下表中的 “选择率” 表示用户选择本模型结果的概率,越高越好;(3)给 AI 生成的质量打分(1-5):体现为下表中的“生成质量”,越高越好。从结果可以看出本模型取得了不错的效果,平均准确率接近 50%,平均选择率 40%。我们也观察到设计师群体更容易鉴别出 AI 结果,对质量要求也更苛刻,说明本工作还有进一步提升的空间。
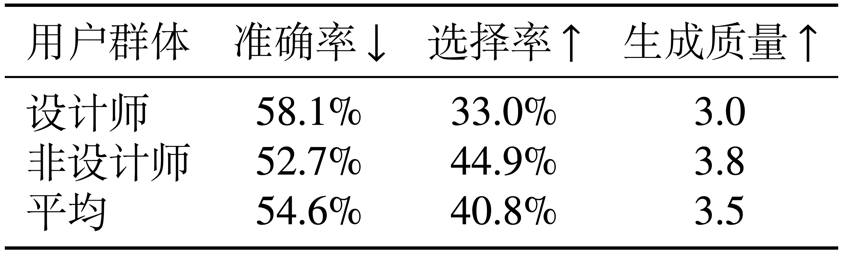
表 1 主观调查结果
3.5 logo 图生成系统
受字体生成模型和纹理迁移模型的启发,本文也建立了一个全自动的文字 logo 图生成系统。该系统首先根据用户输入的文本和主题生成对应的字体,接着,将合成的字形图像和文本送到本文提出的布局生成网络中,得到字形摆放的布局,最后使用纹理迁移模型得到修饰后的 logo 图像。图 10 展示了一些合成的样例, 证明了本系统的有效性。

图 10 logo 图像生成系统
四、结论
本文提出了一种用于合成文字 logo 图的布局生成模型。该模型创新性地提出了一个双判别器的模块,用于同时评估字符的放置轨迹和渲染后文字 logo 图的细节信息。同时,本文提出一种可微分拼接的方法,构建了布局参数到文字 logo 的可微分渲染过程。本文构建了一个大规模的数据集 TextLogo3K,并实施大量实验来验证模型的有效性,该数据同样可以应用于其他任务。引言部分中每对 logo 图像,左边是 AI 生成的,右边是人工设计的,你猜对了吗?
ICCV和CVPR 2021论文和代码下载
后台回复:CVPR2021,即可下载CVPR 2021论文和代码开源的论文合集
后台回复:ICCV2021,即可下载ICCV 2021论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
- 目标检测和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
-
- ▲扫码或加微信: CVer6666,进交流群
- CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
-
- ▲扫码进群
- ▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看![]()

