
- 1智能反射面论文1_irs位置跟踪
- 2“开源与闭源大模型:数据隐私、商业应用与社区参与的多维比较“
- 3数据结构课设 根据后序和中序遍历输出先序遍历_给定一棵二叉树的后序遍历和中序遍历,请你输出其层序遍历的序列。这里假设键值都
- 4php怎么登录路由器,如何通过php实现SSO单点登录系统接入功能?
- 5用C#使用EF框架编写window应用程序进行可视化增删改查_c#做界面可视化
- 6Pandas 工具包实战(6)merge 操作:series, dataframe,合并操作_dataframe series merge
- 7springboot+二手车交易系统 毕业设计-附源码131456_二手车交易系统活动图
- 8CMake中添加Qt模块的合理方法
- 9GIT使用指南_gitfiend
- 10【ESP32接入语言大模型之通义千问】_esp32接入大模型
3天快速入门python机器学习(黑马xxx)_黑马人工智能笔记
赞
踩
目录
一、 机器学习概述
1.1 人工智能概述
1.1.1介绍
让机器下棋(1950年人工智能),过滤垃圾邮件(1980年机器学习),图像识别(2010年深度学习)
达特茅斯会议-人工智能的起点
机器学习是人工智能的一个实现途径
深度学习是机器学习的一个方法发展而来
用机器来模仿人类学习以及其他方面的智能
1.1.2 机器学习、深度学习能做些什么
传统预测:量化投资、广告推荐、销量预测
图像识别:人脸识别、街道交通标志检测
自然语言处理:文本分类、情感分析、自动聊天、文本检测
1.1.3 人工智能阶段课程安排
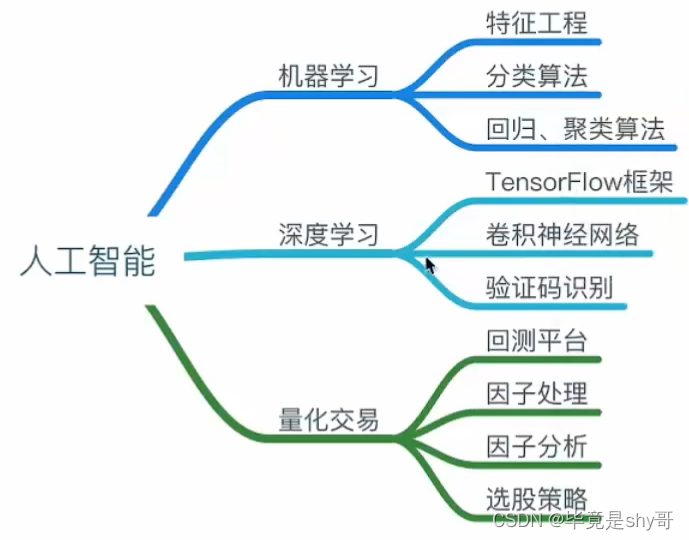
1.2 什么是机器学习
定义:从数据中自动分析获得模型,并利用模型对未知数据进行预测
数据、 模型、预测
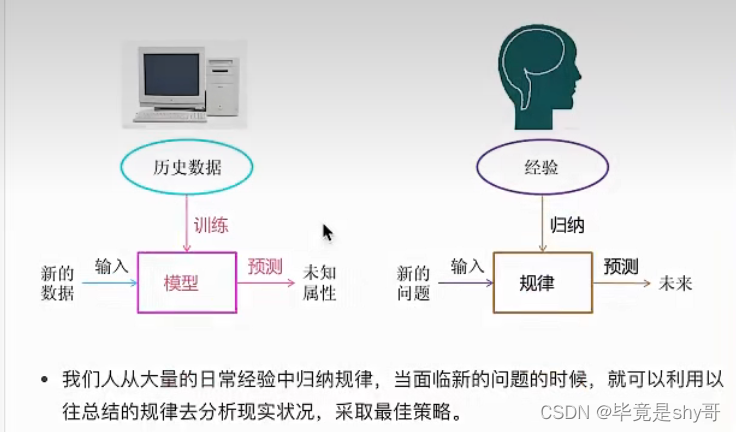
从历史数据当中获得规律?这些历史数据是怎么的格式?
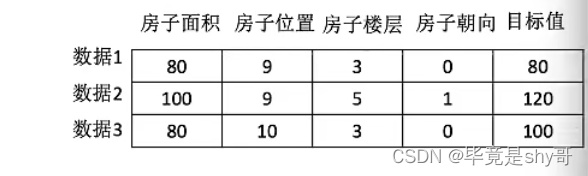
1.2.3 数据集构成
结构:特征值 + 目标值

1.3 机器学习算法分类
1.3.1 分类
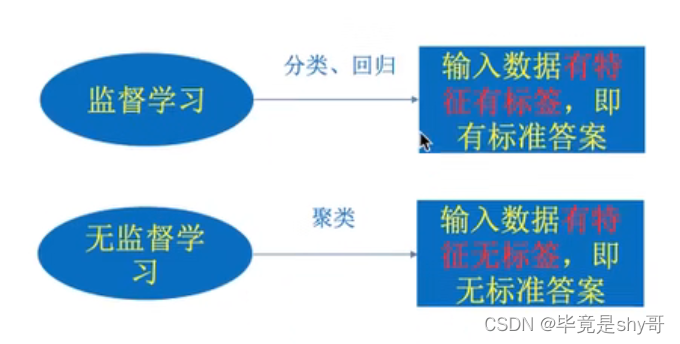
有目标值是监督学习
- 目标值:类别 (猫狗分类)----- 分类问题
k-近邻算法、贝叶斯分类、决策树与随机森林 - 目标值:连续型的数据 (房屋价格预测)-------回归问题
线性回归、岭回归 - 无目标值---------- 无监督学习
聚类 k-means
1.3.2 小练习
1、预测明天的气温是多少度? 回归
2、预测明天是阴、晴还是雨? 分类
3、人脸年龄预测? 回归(多少岁)/分类(老的小的)
4、人脸识别? 分类
1.3.3 机器学习算法分类

1.4 机器学习开发流程

1)获取数据
2)数据处理(缺失值什么的)
3)特征工程(处理为能使用的数据)
4)机器学习算法训练 - 模型
5)模型评估(模型好不好)
6)应用(不好的话返回2、3)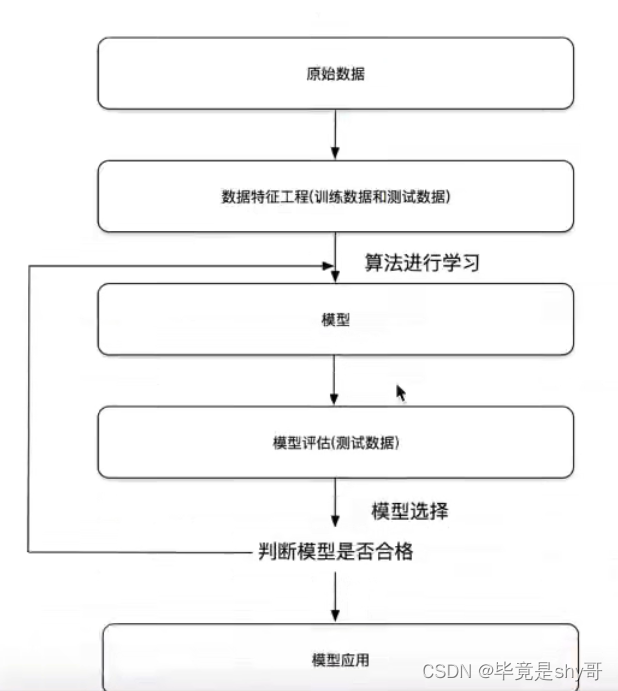
1.5 学习框架和资料介绍
1)算法是核心,数据与计算是基础
2)找准定位

3)怎么做?
1、入门
2、实战类书籍
3、机器学习 -”西瓜书”- 周志华
统计学习方法 - 李航
深度学习 - “花书”
4)1.5.1 机器学习库与框架

1.5.1 机器学习库和框架

sklearn、tensorflow、caffe、pytorch、theano、Chainer
研究算法底层,研究框架
1.5.2 书籍资料

提升:

二、特征工程
2.1 数据集
- 分为训练集和测试集
- 会使用sklearn的数据集
2.1.1 可用数据集(针对本次三天学习而言)
公司内部 百度
数据接口 花钱
数据集
学习阶段可以用的数据集:
1)sklearn
数据量小、方便学习
2)kaggle
大数据竞赛平台、80万科学家、真实数据、数据量巨大
3)UCI
目前600多数据集、领域广、数据量几十万
- Scikit-learn工具介绍

- 安装
pip3 install Scikit-learn==0.19.1
- 1

- Scikit-learn包含的内容

2.1.2 sklearn数据集
- scikit-learn数据集API介绍

- sklearn小数据集

- sklearn大数据集

- sklearn数据集的使用

- 数据集的返回值

datasets.base.Bunch(继承自字典)
dict[“key”] = values
bunch.key = values 思考:拿到的数据是否全部都用来训练一个模型?
思考:拿到的数据是否全部都用来训练一个模型?
no,测试集
2.1.3 数据集的划分
- 训练数据:用于训练,构建模型
- 测试数据:在模型检验时使用,用于评估模型是否有效
测试集 20%~30%

sklearn.model_selection.train_test_split(arrays, *options)
训练集特征值,测试集特征值,训练集目标值,测试集目标值
x_train, x_test, y_train, y_test

2.2 特征工程介绍
影响训练效果的原因:算法、特征工程
2.2.1 为什么需要特征工程(Feature Engineering)

2.2.2 什么是特征工程

2.2.3 特征工程的位置与数据处理的比较

sklearn 特征工程
pandas 数据清洗、数据处理直接
特征抽取/特征提取(有些数据不能处理,需要转换)
机器学习算法 - 统计方法 - 数学公式
文本类型 -》 数值
类型 -》 数值
2.3 特征提取


2.3.1 特征提取
sklearn.feature_extraction
2.3.2 字典特征提取
类别 -> one-hot编码

sklearn.feature_extraction.DictVectorizer(sparse=True,…)
vector 数学:向量 物理:矢量
矩阵 matrix 二维数组
向量 vector 一维数组
父类:转换器类
返回sparse矩阵
sparse稀疏
将非零值 按位置表示出来
节省内存 - 提高加载效率
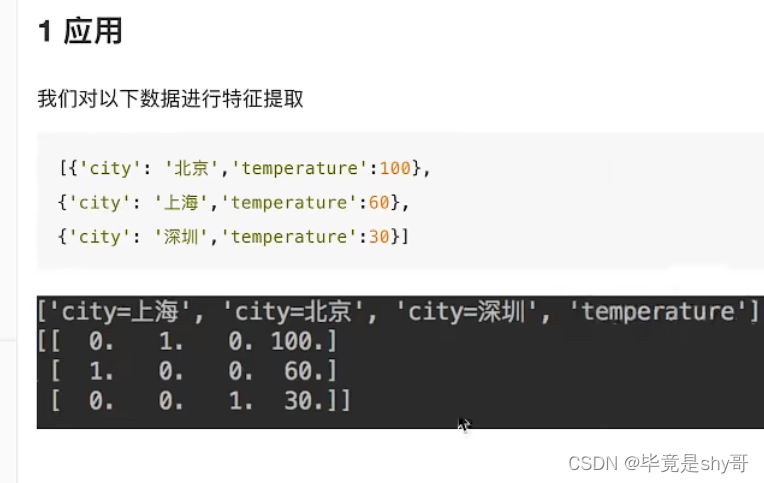
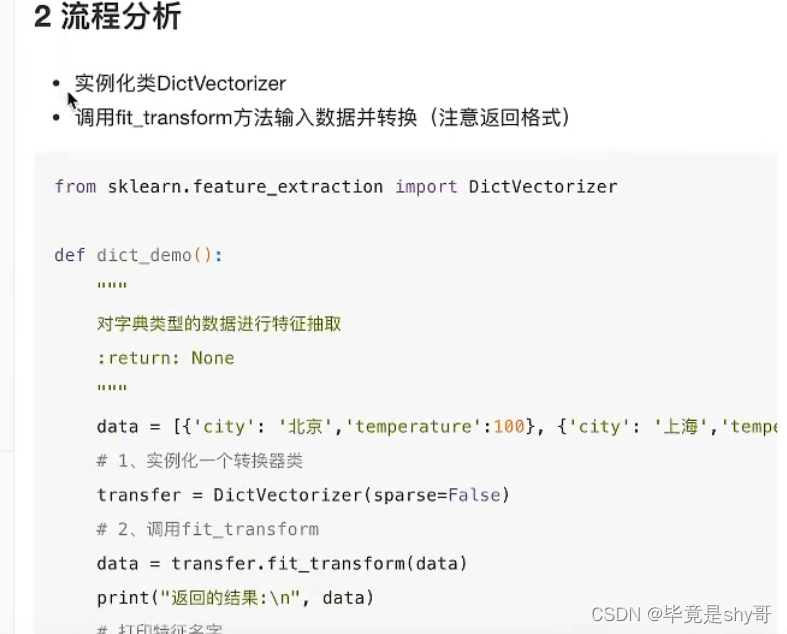
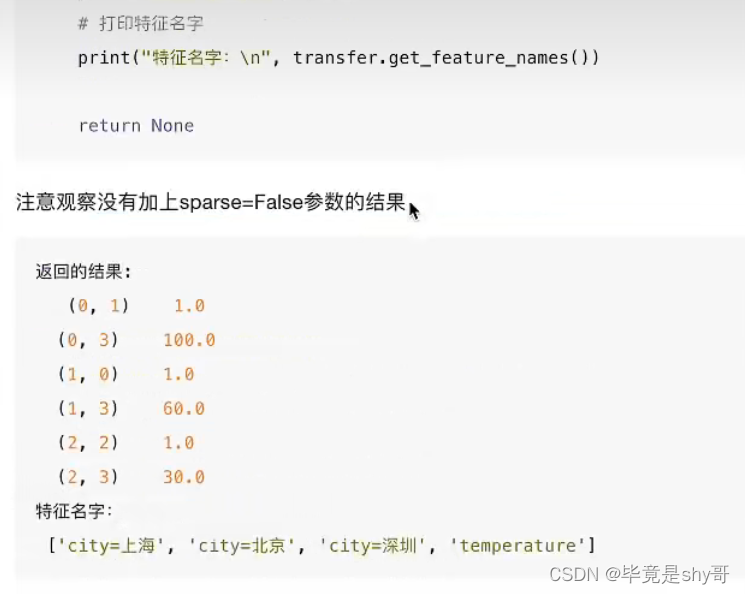

转化为: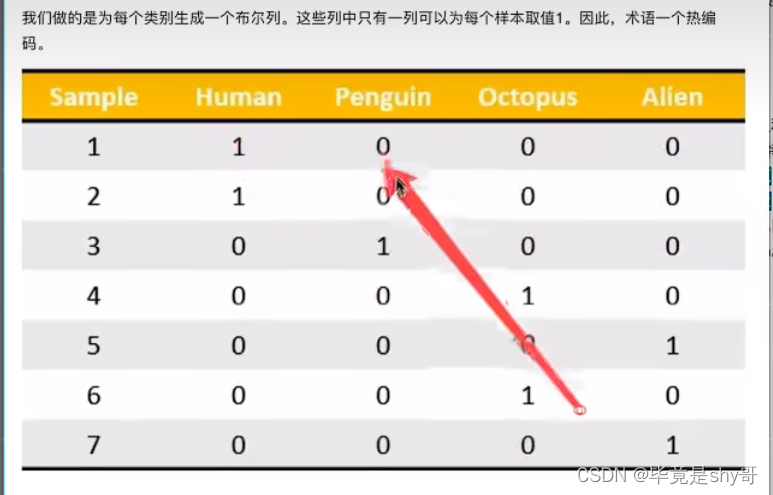
2.3.3 上述总结
对于特征当中存在类别信息的我们都会做one-hot编码处理
应用场景:
1)pclass, sex 数据集当中类别特征比较多
1、将数据集的特征-》字典类型
2、DictVectorizer转换
2)本身拿到的数据就是字典类型
2.3.3文本特征提取
作用:对文本数据进行特征值化
单词 作为 特征
句子、短语、单词、字母
特征:特征词

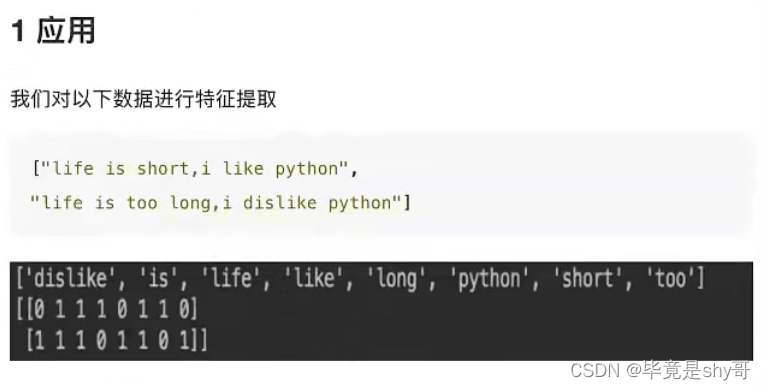





- 方法1:CountVectorizer
统计每个样本特征词出现的个数
stop_words停用的
停用词表
关键词:在某一个类别的文章中,出现的次数很多,但是在其他类别的文章当中出现很少
- 方法2:TfidfVectorizer


TF-IDF - 重要程度
两个词 “经济”,“非常”
1000篇文章-语料库
100篇文章 - “非常”
10篇文章 - “经济”
两篇文章
文章A(100词) : 10次“经济” TF-IDF:0.2
tf:10/100 = 0.1
idf:lg 1000/10 = 2
文章B(100词) : 10次“非常” TF-IDF:0.1
tf:10/100 = 0.1
idf: log 10 1000/100 = 1
TF - 词频(term frequency,tf)
IDF - 逆向文档频率

2.3.5 总结
对字典的类别转换为onehot编码
对文本:1. 统计特征值出现的个数 2. 计算词的重要性程度
2.4 特征预处理
2.4.1 什么是特征预处理



为什么我们要进行归一化/标准化?
无量纲化
2.4.2 归一化



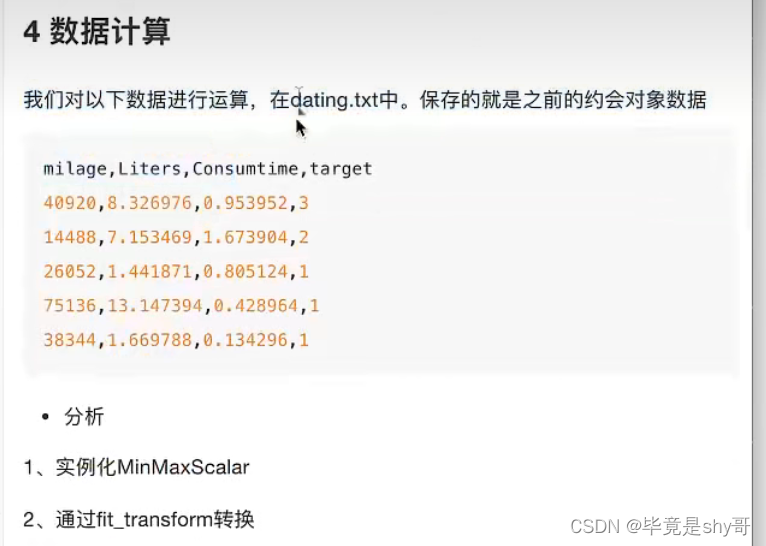
异常值:最大值、最小值

2.4.3 标准化

(x - mean) / std
均值变化不会太大
标准差:集中程度
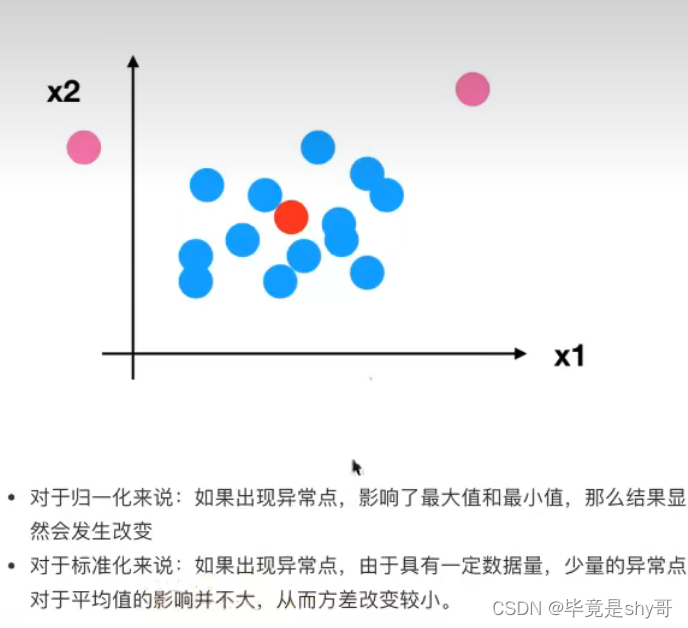

应用场景:
在已有样本足够多的情况下比较稳定,适合现代嘈杂大数据场景。
2.5 特征降维
2.5.1 降维 - 降低维度
ndarray
维数:嵌套的层数
0维 标量
1维 向量
2维 矩阵
3维
n维
二维数组
此处的降维:降低特征的个数(列数)
效果:
特征与特征之间不相关
2.5.2 降维的两种方式
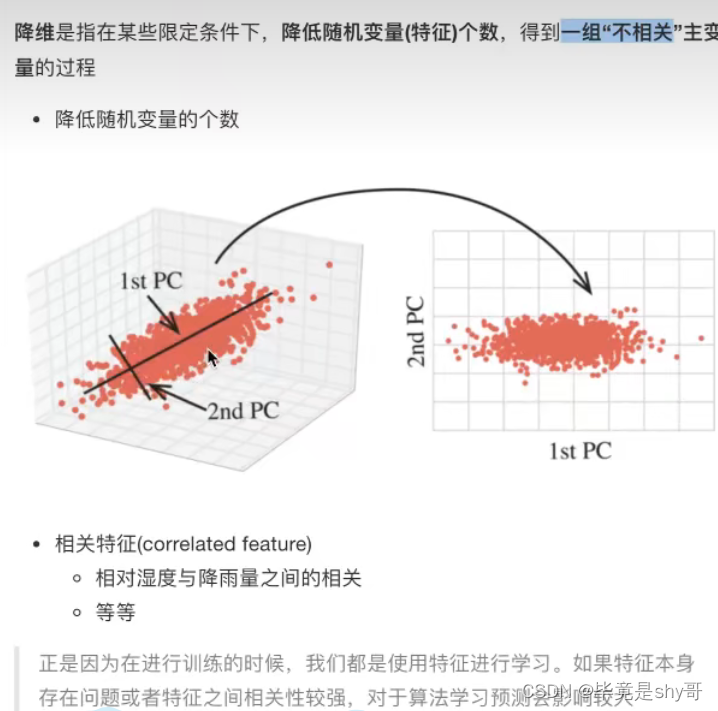
- 特征选择
- 主成分分析(理解为一种特征提取的方式)
2.5.3 特征选择


特征选择
- Filter过滤式
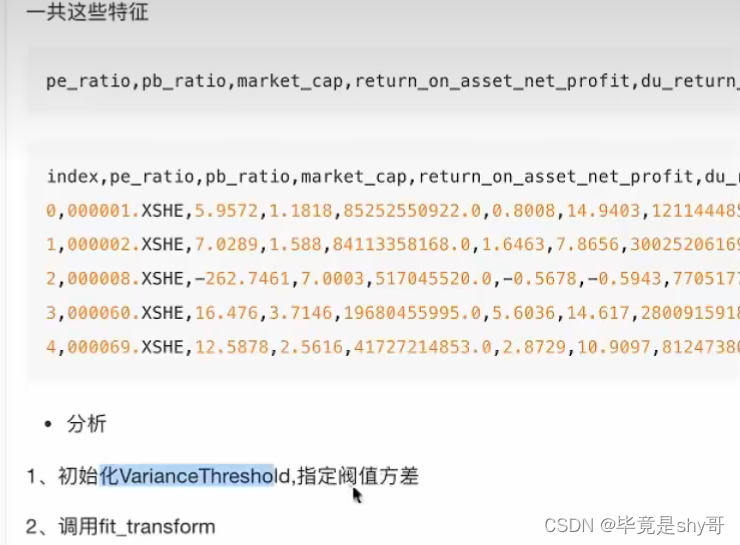
方差选择法:低方差特征过滤
相关系数 - 特征与特征之间的相关程度
取值范围:–1≤ r ≤+1
皮尔逊相关系数
0.9942
特征与特征之间相关性很高:
1)选取其中一个
2)加权求和
3)主成分分析 - Embeded嵌入式
决策树 第二天
正则化 第三天
深度学习 第五天
2.5.4 低方差特征过滤




2.6 主成分分析
2.6.1 什么是主成分分析(PCA)


sklearn.decomposition.PCA(n_components=None)
n_components
小数 表示保留百分之多少的信息
整数 减少到多少特征
2.6.2 案例:探究用户对物品类别的喜好细分
用户 物品类别
user_id aisle
1)需要将user_id和aisle放在同一个表中 - 合并
2)找到user_id和aisle - 交叉表和透视表
3)特征冗余过多 -> PCA降维
三、分类算法
目标值:类别
1、sklearn转换器和预估器
2、KNN算法
3、模型选择与调优
4、朴素贝叶斯算法
5、决策树
6、随机森林
3.1 sklearn转换器和估计器
转换器
估计器(estimator)
3.1.1 转换器 - 特征工程的父类
1 实例化 (实例化的是一个转换器类(Transformer))
2 调用fit_transform(对于文档建立分类词频矩阵,不能同时调用)
标准化:
(x - mean) / std
fit_transform()
fit() 计算 每一列的平均值、标准差
transform() (x - mean) / std进行最终的转换
3.1.2 估计器(sklearn机器学习算法的实现)
估计器工作流程:
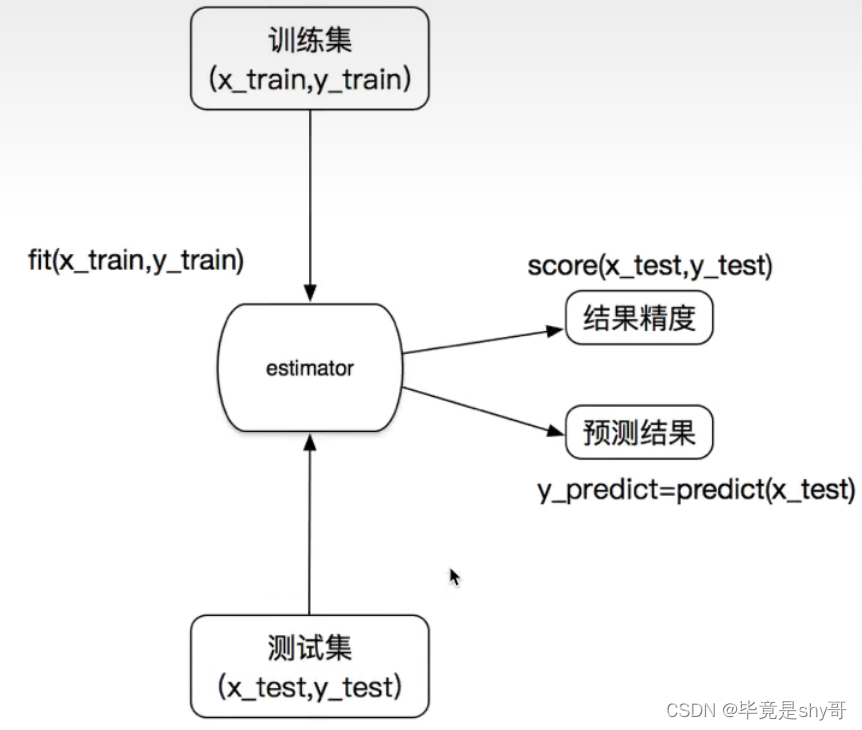 估计器(estimator)
估计器(estimator)
1 实例化一个estimator
2 estimator.fit(x_train, y_train) 计算 —— 调用完毕,模型生成
3 模型评估:
1)直接比对真实值和预测值
y_predict = estimator.predict(x_test)
y_test == y_predict
2)计算准确率
accuracy = estimator.score(x_test, y_test)
3.2 K-近邻算法(KNN)
3.2.1 什么是K-近邻算法
KNN核心思想:
你的“邻居”来推断出你的类别
- K-近邻算法(KNN)原理

k = 1
容易受到异常点的影响
如何确定谁是邻居?
计算距离:
距离公式
欧氏距离
曼哈顿距离 绝对值距离
明可夫斯基距离 - 电影类型分析
k = 1 爱情片
k = 2 爱情片
……
k = 6 无法确定
k = 7 动作片
如果取的最近的电影数量不一样?会是什么结果?
k 值取得过小,容易受到异常点的影响
k 值取得过大,样本不均衡的影响
结合前面的约会对象数据,分析K-近邻算法需要做什么样的处理
无量纲化的处理
标准化
3.2.2 k-邻近算法API

sklearn.neighbors.KNeighborsClassifier(n_neighbors=5,algorithm=‘auto’)
n_neighbors:k值
3.2.3 案例1:鸢尾花种类预测
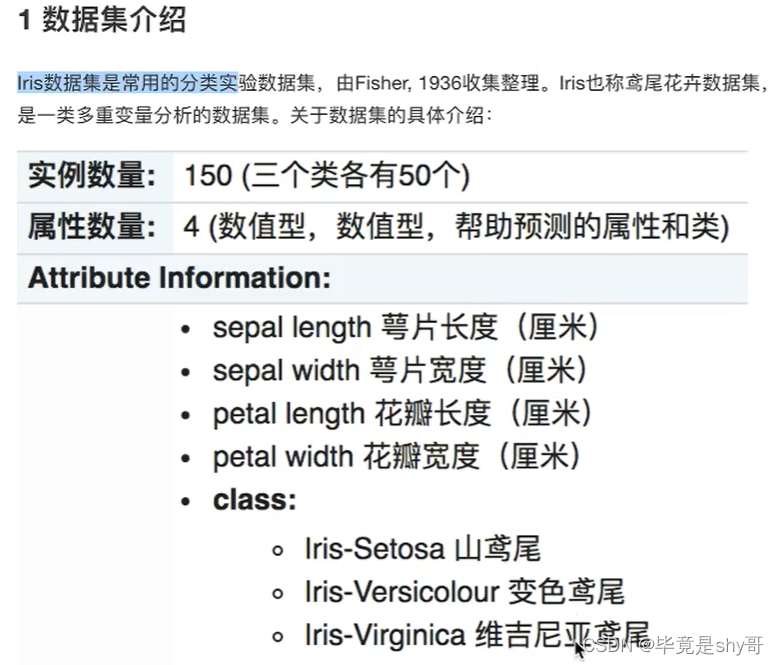
1)获取数据
2)数据集划分
3)特征工程
标准化
4)KNN预估器流程
5)模型评估

3.2.4 K-近邻总结
优点:简单,易于理解,易于实现,无需训练
缺点:
1)必须指定K值,K值选择不当则分类精度不能保证
2)懒惰算法,对测试样本分类时的计算量大,内存开销大
使用场景:小数据场景,几千~几万样本,具体场景具体业务去测试
3.3 模型选择与调优
3.3.1 什么是交叉验证(cross validation)


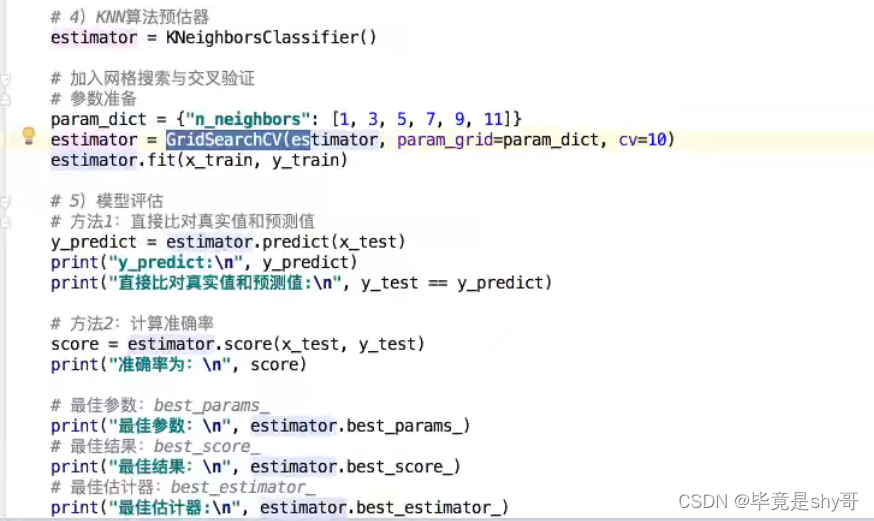
3.3.2 超参数搜索-网格搜索(Grid Search)
k的取值
[1, 3, 5, 7, 9, 11]
暴力破解
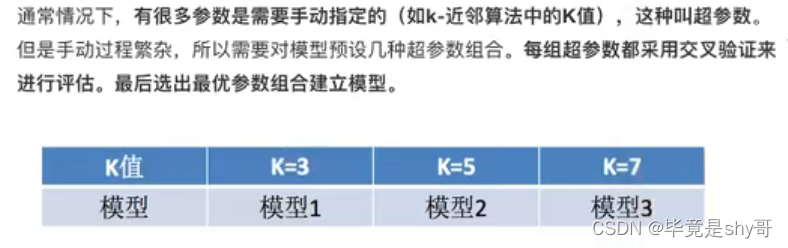

3.3.3 鸢尾花案例增加K值调优
3.2.4 案例:预测facebook签到位置
流程分析:
1)获取数据
2)数据处理
目的:
特征值 x
目标值 y
a.缩小数据范围
2 < x < 2.5
1.0 < y < 1.5
b.time -> 年月日时分秒
c.过滤签到次数少的地点
数据集划分
3)特征工程:标准化
4)KNN算法预估流程
5)模型选择与调优
6)模型评估
3.4 朴素贝叶斯算法
3.4.1 什么是朴素贝叶斯分类方法
分完之后出现概率值
3.4.2 概率基础
1 概率(Probability)定义

3.4.3 联合概率、条件概率与相互独立
- 联合概率:包含多个条件,且所有条件同时成立的概率
P(程序员, 匀称) P(程序员, 超重|喜欢)
P(A, B) - 条件概率:就是事件A在另外一个事件B已经发生条件下的发生概率
P(程序员|喜欢) P(程序员, 超重|喜欢)
P(A|B) - 相互独立:
P(A, B) = P(A)P(B) <=> 事件A与事件B相互独立
3.4.4 贝叶斯公式

朴素?
假设:特征与特征之间是相互独立
朴素贝叶斯算法:
朴素 + 贝叶斯
应用场景:
文本分类

单词作为特征


拉普拉斯平滑系数
3.4.6 案例:20类新闻分类
1)获取数据
2)划分数据集
3)特征工程
文本特征抽取
4)朴素贝叶斯预估器流程
5)模型评估

3.4.7 朴素贝叶斯算法总结

3.5 决策树
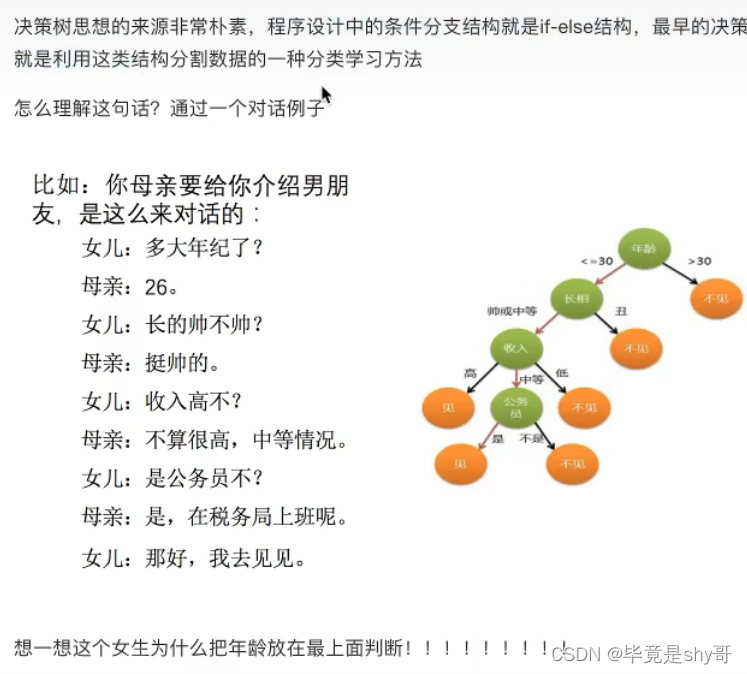
3.5.1 认识决策树
如何高效的进行决策?
特征的先后顺序
3.5.2 决策树分类原理详解
已知 四个特征值 预测 是否贷款给某个人
先看房子,再工作 -> 是否贷款 只看了两个特征
年龄,信贷情况,工作 看了三个特征





3.5.3 据册数API

信息论基础
1)信息
香农:消除随机不定性的东西
小明 年龄 “我今年18岁” - 信息
小华 ”小明明年19岁” - 不是信息
2)信息的衡量 - 信息量 - 信息熵
bit
g(D,A) = H(D) - 条件熵H(D|A)
4 决策树的划分依据之一------信息增益
没有免费的午餐
3.5.4 决策树对鸢尾花分类
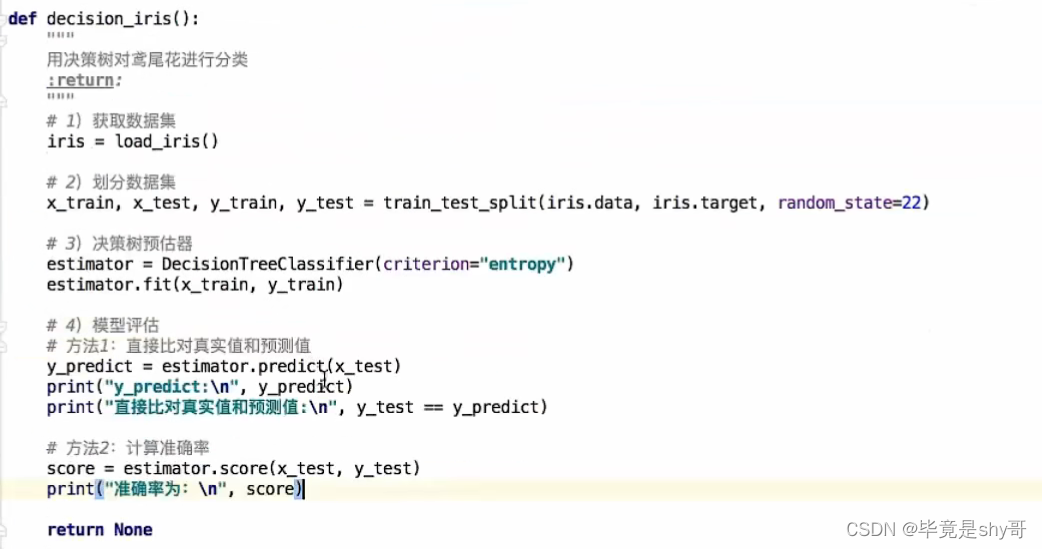
3.5.5 决策树可视化

3.5.6 决策树总结

优点:
可视化 - 可解释能力强
缺点:
容易产生过拟合
3.5.7 案例:泰坦尼克号乘客生存预测
流程分析:
特征值 目标值
1)获取数据
2)数据处理
缺失值处理
特征值 -> 字典类型
3)准备好特征值 目标值
4)划分数据集
5)特征工程:字典特征抽取
6)决策树预估器流程
7)模型评估
3.6 集成学习方法之随机森林
3.6.1 什么是集成学习方法

3.6.2 什么是随机森林
随机
森林:包含多个决策树的分类器

3.6.3 随机森林原理过程

训练集:
N个样本
特征值 目标值
M个特征
随机
两个随机
- 训练集随机 - N个样本中随机有放回的抽样N个
bootstrap 随机有放回抽样
[1, 2, 3, 4, 5]
新的树的训练集
[2, 2, 3, 1, 5] - 特征随机 - 从M个特征中随机抽取m个特征
M >> m
降维

3.6.4 API

3.6.6 总结
能够有效地运行在大数据集上,
处理具有高维特征的输入样本,而且不需要降维

四、回归和聚类
线性回归
欠拟合与过拟合
岭回归
分类算法:逻辑回归
模型保存与加载
无监督学习 K-means算法
4.1 线性回归
回归问题:
目标值 - 连续型的数据
4.1.1 线性回归的原理

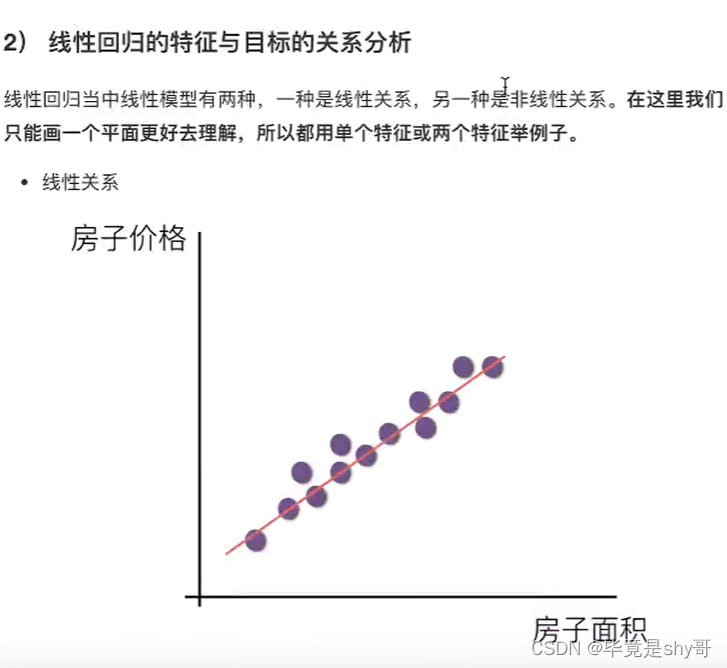
4.1.2 什么是线性回归

函数关系 :特征值和目标值
线型模型
线性关系
y = w1x1 + w2x2 + w3x3 + …… + wnxn + b
= wTx + b
数据挖掘基础
y = kx + b
y=w1x1+w2x2+b
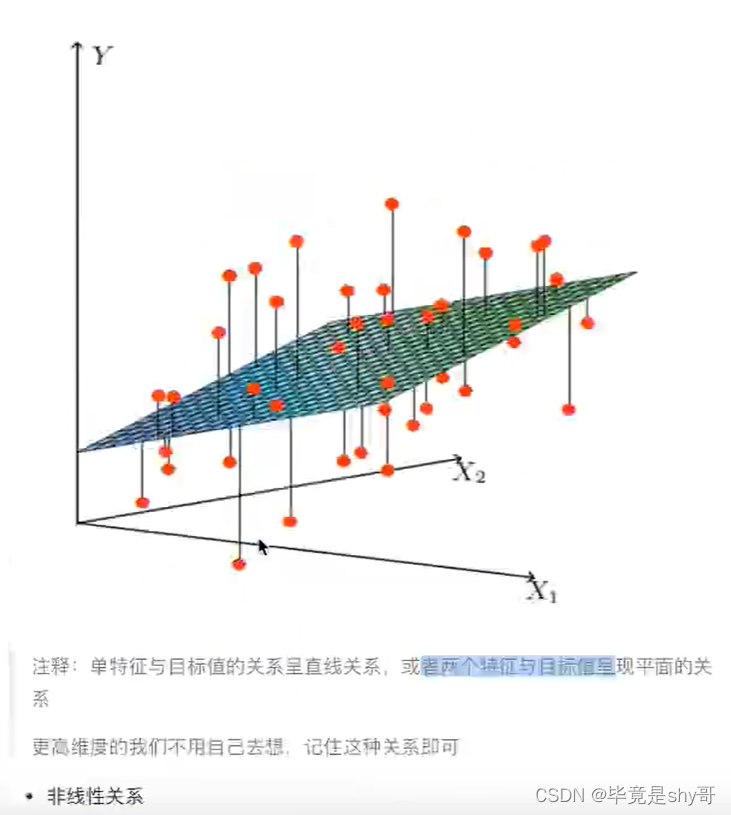
广义线性模型
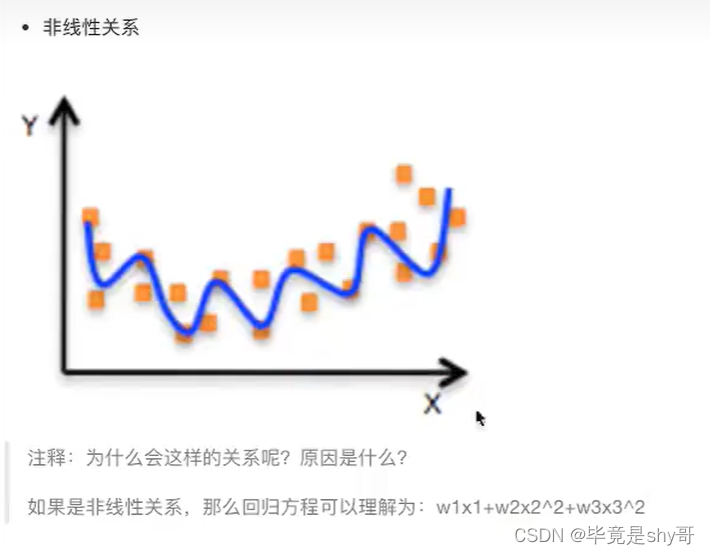
也有非线性关系
线性模型
自变量一次(线性关系)
y = w1x1 + w2x2 + w3x3 + …… + wnxn + b
参数一次
y = w1x1 + w2x1^2 + w3x1^3 + w4x2^3 + …… + b(w1,w2,w3是一次的)
线性关系&线性模型
线性关系一定是线性模型
线性模型不一定是线性关系
4.1.2 线性回归的损失和优化原理(理解记忆)
目标:求模型参数
模型参数能够使得预测准确
真实关系:真实房子价格 = 0.02×中心区域的距离 + 0.04×城市一氧化氮浓度 + (-0.12×自住房平均房价) + 0.254×城镇犯罪率
随意假定:预测房子价格 = 0.25×中心区域的距离 + 0.14×城市一氧化氮浓度 + 0.42×自住房平均房价 + 0.34×城镇犯罪率
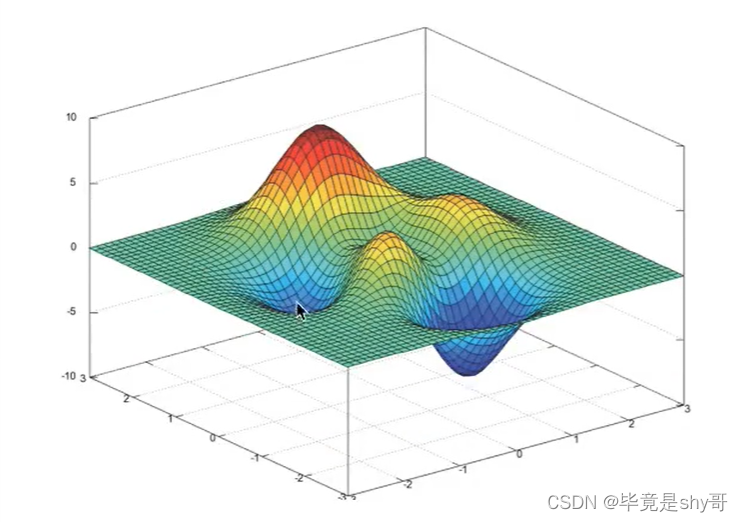
损失函数/cost/成本函数/目标函数:


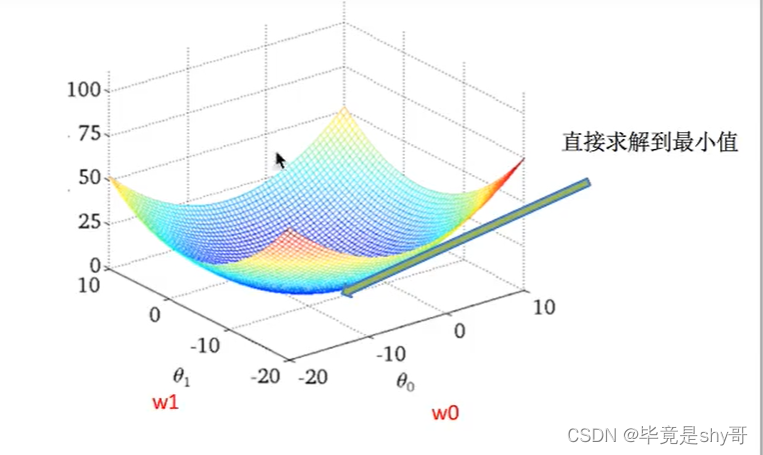
-
正规方程
天才 - 直接求解W -
梯度下降
勤奋努力的普通人
试错、改进

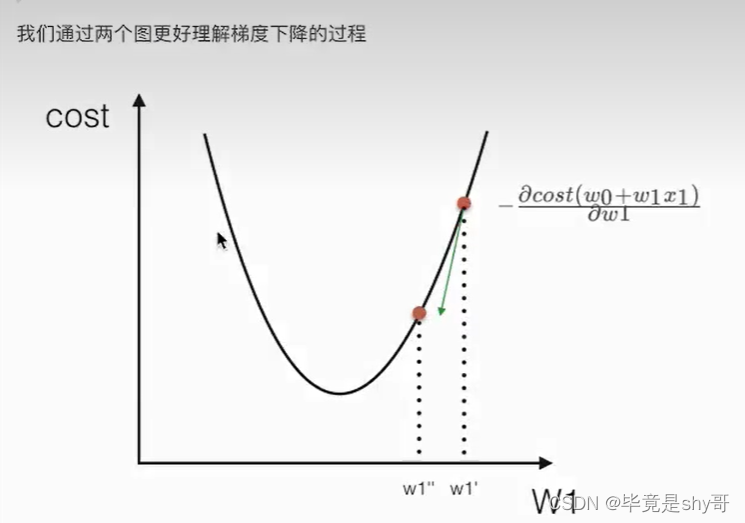
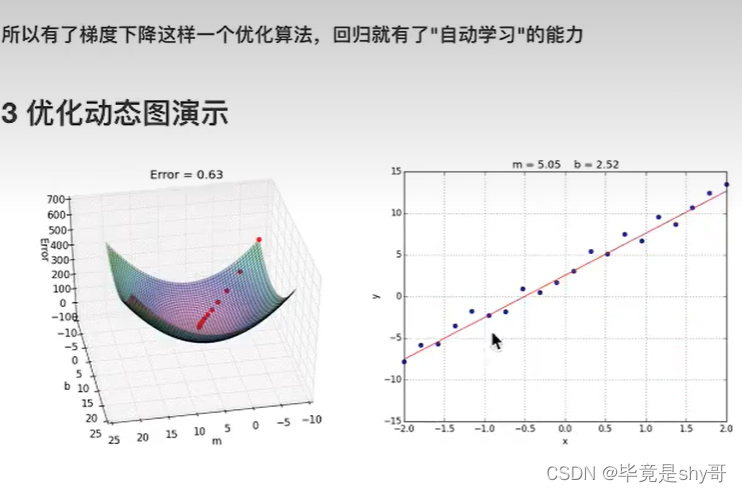
4.1.3 线性回归API

4.1.4 波士顿房价预测
流程:
1)获取数据集
2)划分数据集
3)特征工程:
无量纲化 - 标准化
4)预估器流程
fit() --> 模型
coef_ intercept_
5)模型评估
4.1.5 回归的性能评估
均方误差

4.1.6 正规方程和梯度下降对比
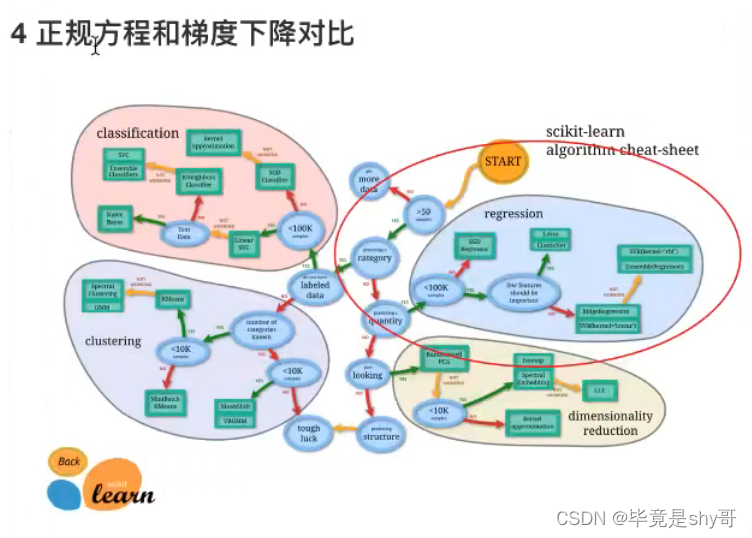
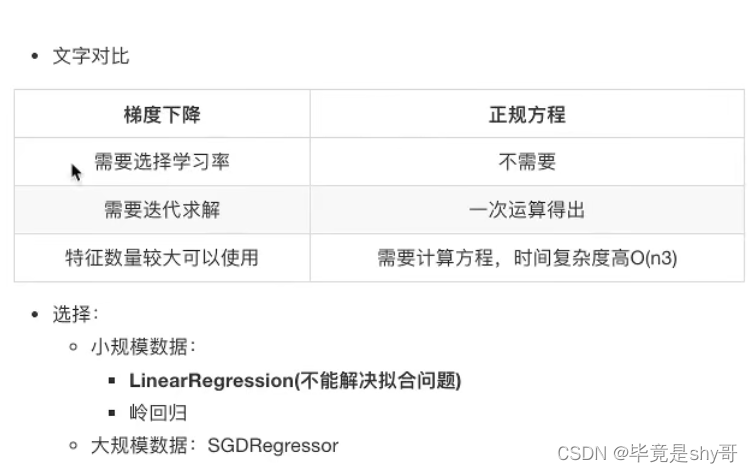

4.1.7 总结

4.2 欠拟合与过拟合
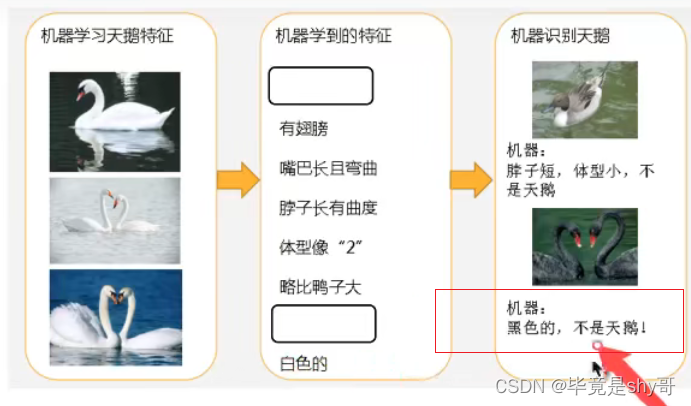
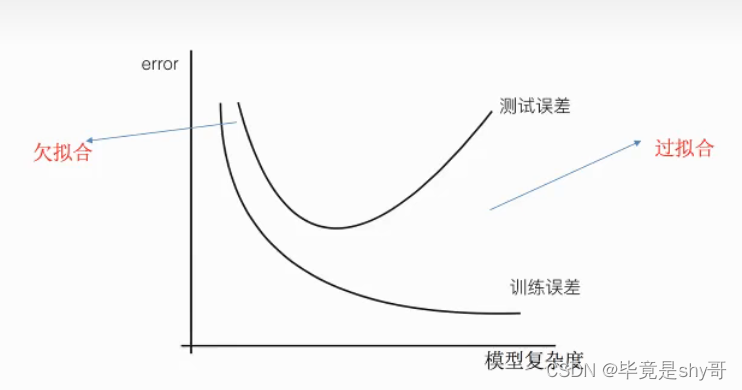
训练集上表现得好,测试集上不好 - 过拟合
4.2.1 什么是过拟合与欠拟合
- 欠拟合(学习的少,偷懒)
学习到数据的特征过少
解决:
增加数据的特征数量
- 过拟合(想面面俱到,想太多)
原始特征过多,存在一些嘈杂特征, 模型过于复杂是因为模型尝试去兼顾各个测试数据点
解决:
正则化

4.2.2 原因及解决方法



L1
损失函数 + λ惩罚项
LASSO
L2 更常用
损失函数 + λ惩罚项
Ridge - 岭回归
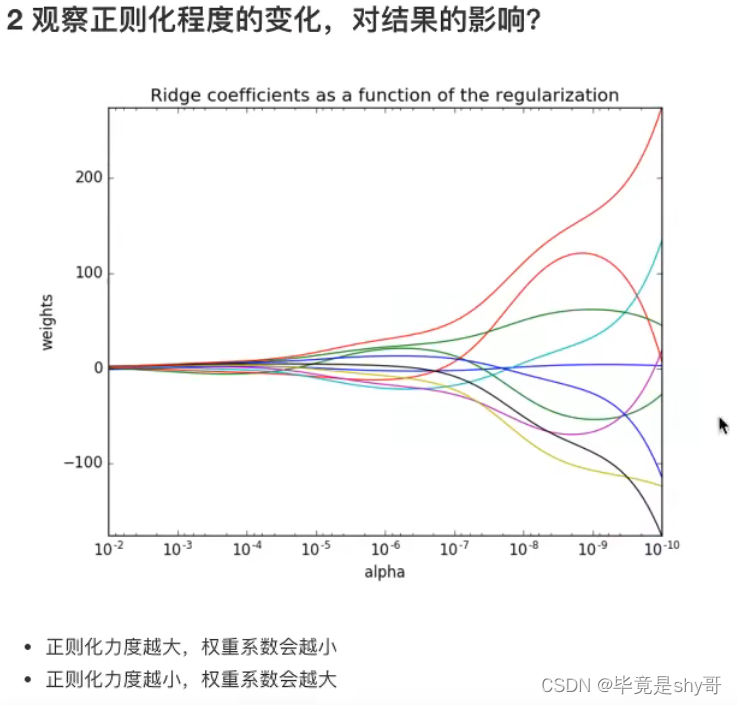
4.3 线性回归的改进-岭回归
4.3.1 带有L2正则化的线性回归-岭回归

- API


alpha 正则化力度=惩罚项系数
4.4 分类算法-逻辑回归与二分类
4.4.1 逻辑回归的应用场景
广告点击率 是否会被点击
是否为垃圾邮件
是否患病
是否为金融诈骗
是否为虚假账号
正例 / 反例

4.4.2 逻辑回归的原理


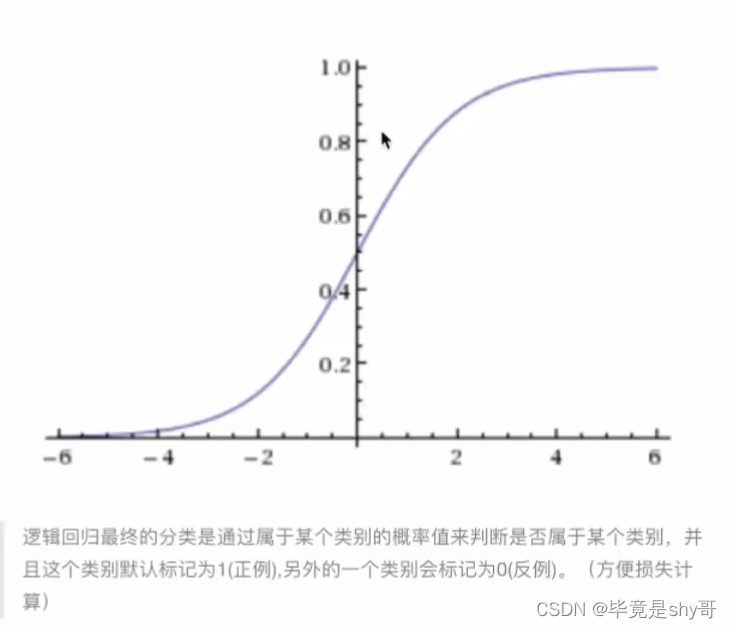
线型回归的输出 就是 逻辑回归 的 输入
-
激活函数
sigmoid函数 [0, 1]
1/(1 + e^(-x))
假设函数/线性模型
1/(1 + e^(-(w1x1 + w2x2 + w3x3 + …… + wnxn + b))) -
损失函数
(y_predict - y_true)平方和/总数
逻辑回归的真实值/预测值 是否属于某个类别 -
对数似然损失
log 2 x


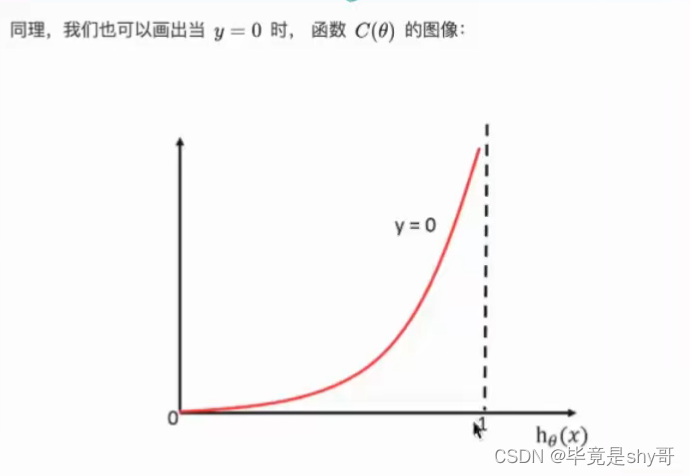
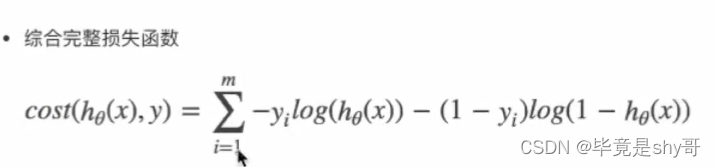
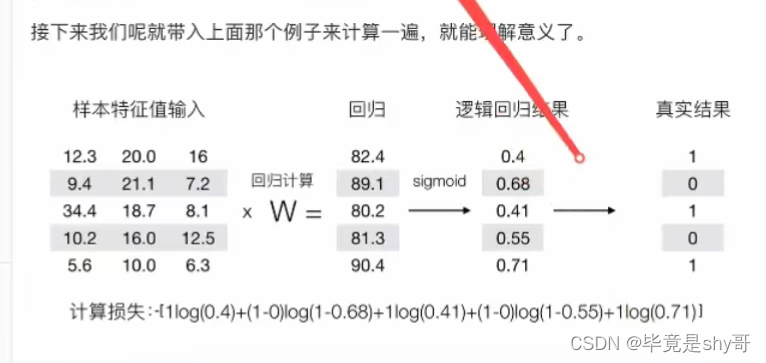

-
优化损失
 梯度下降
梯度下降

4.4.4 案例:癌症分类预测-良/恶性乳腺癌肿瘤预测
恶性 - 正例
流程分析:
1)获取数据
读取的时候加上names
2)数据处理
处理缺失值
3)数据集划分
4)特征工程:
无量纲化处理-标准化
5)逻辑回归预估器
6)模型评估
真的患癌症的,能够被检查出来的概率 - 召回率
4.4.5 分类的评估方法
- 精确率与召回率




1 混淆矩阵
TP = True Possitive
FN = False Negative
2 精确率(Precision)与召回率(Recall)
精确率
召回率 查得全不全
工厂 质量检测 次品 召回率
3 F1-score 模型的稳健型
总共有100个人,如果99个样本癌症,1个样本非癌症 - 样本不均衡
不管怎样我全都预测正例(默认癌症为正例) - 不负责任的模型
准确率:99%
召回率:99/99 = 100%
精确率:99%
F1-score: 2*99%/ 199% = 99.497%
AUC:0.5
TPR = 100%
FPR = 1 / 1 = 100%

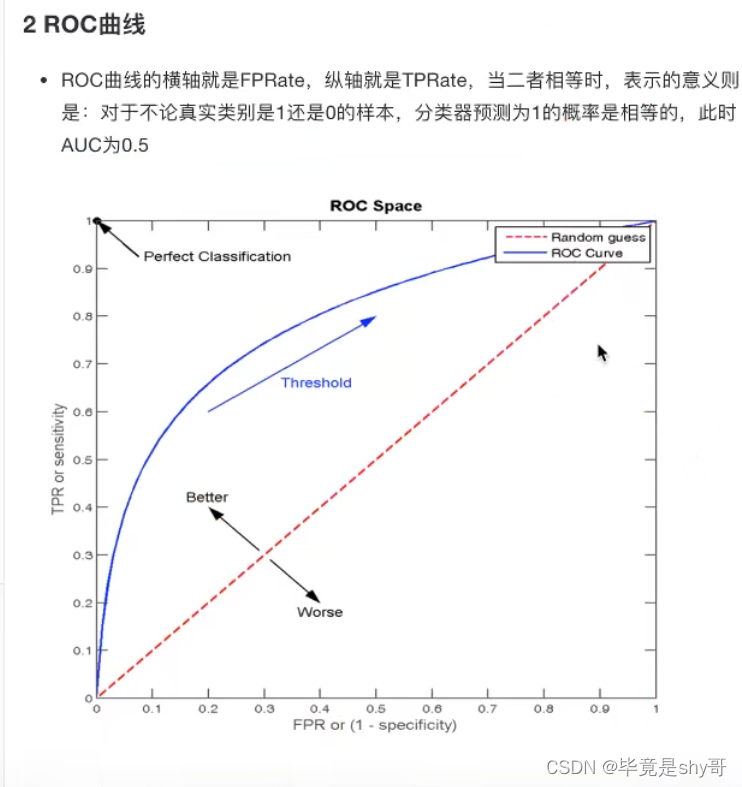



2 ROC曲线与AUC指标
1 知道TPR与FPR
TPR = TP / (TP + FN) - 召回率
所有真实类别为1的样本中,预测类别为1的比例
FPR = FP / (FP + TN)
所有真实类别为0的样本中,预测类别为1的比例
4.5 模型保存和加载
4.5.1 sklearn模型的保存和加载API

4.6 无监督学习-K-means算法
4.6.1 什么是无监督学习
没有目标值 - 无监督学习

4.6.2 无监督学习包含算法
- 聚类
K-means(K均值聚类) - 降维
PCA
4.6.3 K-means原理
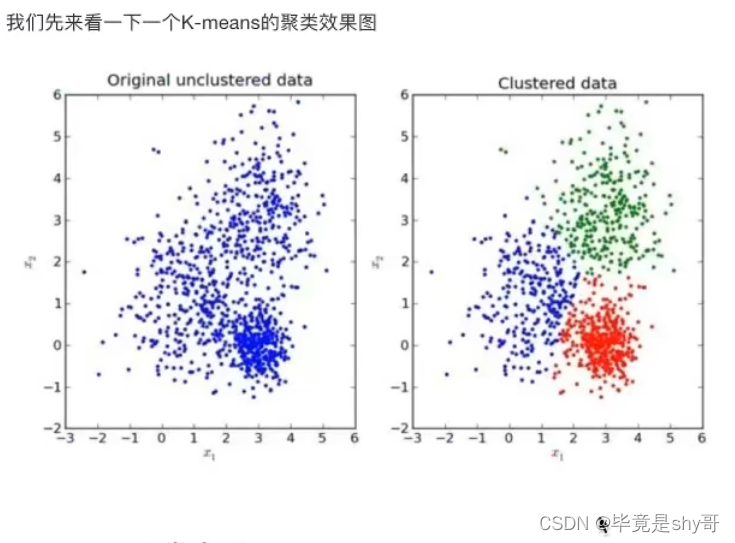

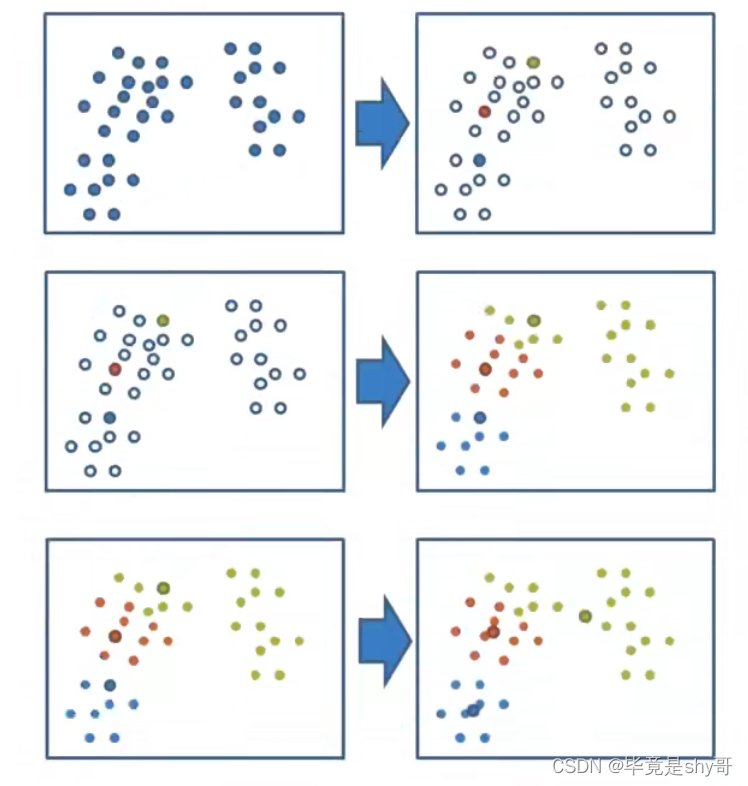
K-超参数
1看需求
2调节参数
4.6.4 API

4.6.5 案例:k-means对Instacart Market用户聚类
k = 3
流程分析:
降维之后的数据
1)预估器流程
2)看结果
3)模型评估

4.6.6 Kmeans性能评估指标
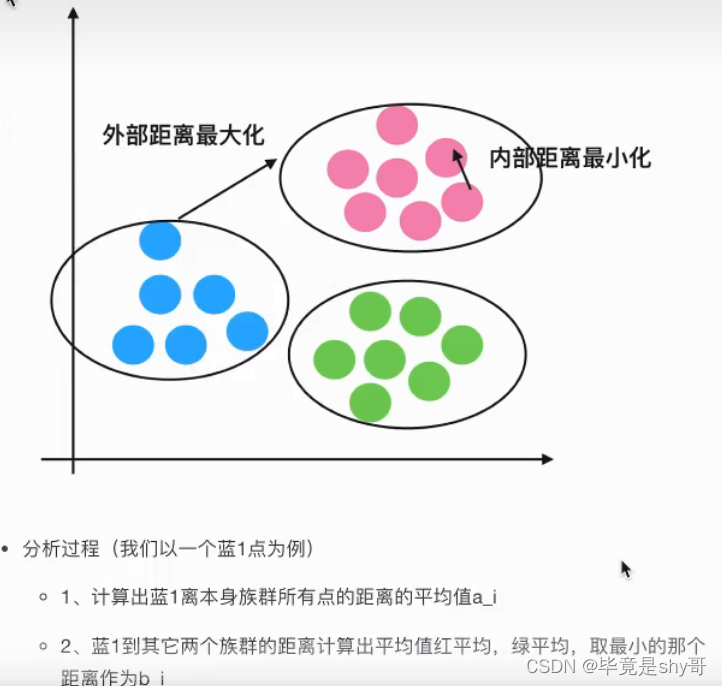
轮廓系数
如果b_i>>a_i:趋近于1效果越好,
b_i<<a_i:趋近于-1,效果不好。
轮廓系数的值是介于 [-1,1] ,
越趋近于1代表内聚度和分离度都相对较优。
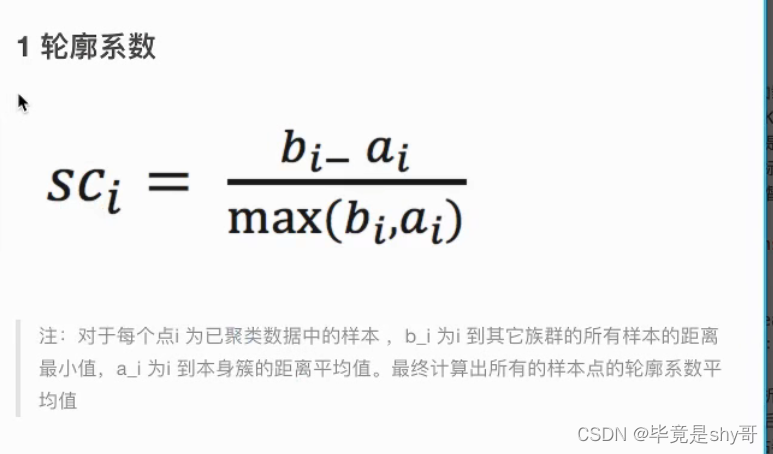


4.6.7 K-means总结
应用场景:
没有目标值
分类


