
- 1huaggingface模型国内网络下载_huggfaceing
- 2pyqt5 python3.7教程_Python3.7安装PyQt5的方法
- 3c语言仿ce内存搜索工 源代码_CE的AOB_scan功能源码内存搜索特征码
- 4创建一个完整的购物商城系统是一个复杂的项目,涉及到前端、后端、数据库和支付接口等多个方面。
- 5【数据结构初阶】线性表——单链表(手撕单链表)
- 6AIGC - 大模型:InternLM 模型部署_ubuntu internlm
- 7计算机毕业/课程设计系列基于SpringBoot+Vue的高校图书管理和座位预约系统_基于springboot、vue高校图书管理系统
- 8Qt 文件操作_qt 读取单个单词
- 9【毕业设计】大数据住房数据分析可视化系统 - python_租房数据分析论文
- 10自动化使用 ChatGPT 生成 PPT 大纲 - 基于 Python 和 PyAutoGUI
计算机毕业设计Hadoop+Spark+Hive知识图谱租房推荐系统 租房数据分析 租房爬虫 租房可视化 租房大数据 大数据毕业设计 大数据毕设 机器学习
赞
踩
毕 业 设 计(论 文)
| 基于大数据的租房数据爬虫与推荐分析系统 |
| 姓 名 | |
| 学 院 | |
| 专 业 | |
| 班 级 | |
| 指导教师 |
摘 要
本设计是一个基于爬虫技术的房地产数据采集与可视化分析应用程序。该程序首先通过爬虫采集网上所有房地产的房源数据,并对采集到的数据进行清洗;将这些房源大致分类,以对所有数据的概括总结。通过上述分析,可以了解到目前市面上房地产各项基本特征及房源分布情况,为众多的购房者进行购房决策提供了参考。
本系统主要是由大数据系统、可视化前端系统、web后台管理系统、租房推荐系统、租房小程序/APP端组成。大屏统计端使用hadoop+spark完成,数据采集使用java离线分析端、网页用户端以及后台管理使用Springboot+mybatis框架开发,在可视化阶段采用Echarts来提供可交互的直观数据可视化图表。本系统采用的数据库是MySQL数据库,其目的是用来存储利用爬虫爬取到的大量租房信息数据集和数据处理之后的分析结果,在通过Spark并行计算进行数据抽取,多维分析,查询统计等操作来完成数据分析部分。完整基于大数据的租房数据分析推荐可视化与管理一体的系统开发。
关键词: 租房数据分析、大数据开发、java开发
Abstract
This design is a real estate data acquisition and visualization analysis application based on crawler technology. Firstly, the program collects all the housing data of real estate on the Internet through crawler, and cleans the collected data. These listings are roughly categorized to provide a summary of all the data. Through the above analysis, we can understand the basic characteristics of real estate on the market and the distribution of housing supply, which provides a reference for many home buyers to make purchase decisions.
The system is mainly composed of big data system, visual front-end system, Web background management system, rental recommendation system, rental small program /APP end. The large-screen statistical end is completed by Hadoop + Spark, data collection is developed by Java offline analysis end, web client end and background management using Springboot+ Mybatis framework. In the visualization stage, Echarts is used to provide interactive intuitive data visualization charts. The database used in this system is MySQL database, which is used to store a large number of rental information data sets obtained by crawler and the analysis results after data processing. Data analysis is completed through Spark parallel computing for data extraction, multidimensional analysis, query statistics and other operations. The development of a system integrating the analysis, recommendation, visualization and management of rental data based on big data.
Keywords: rental data analysis, big data development, Java development
目录











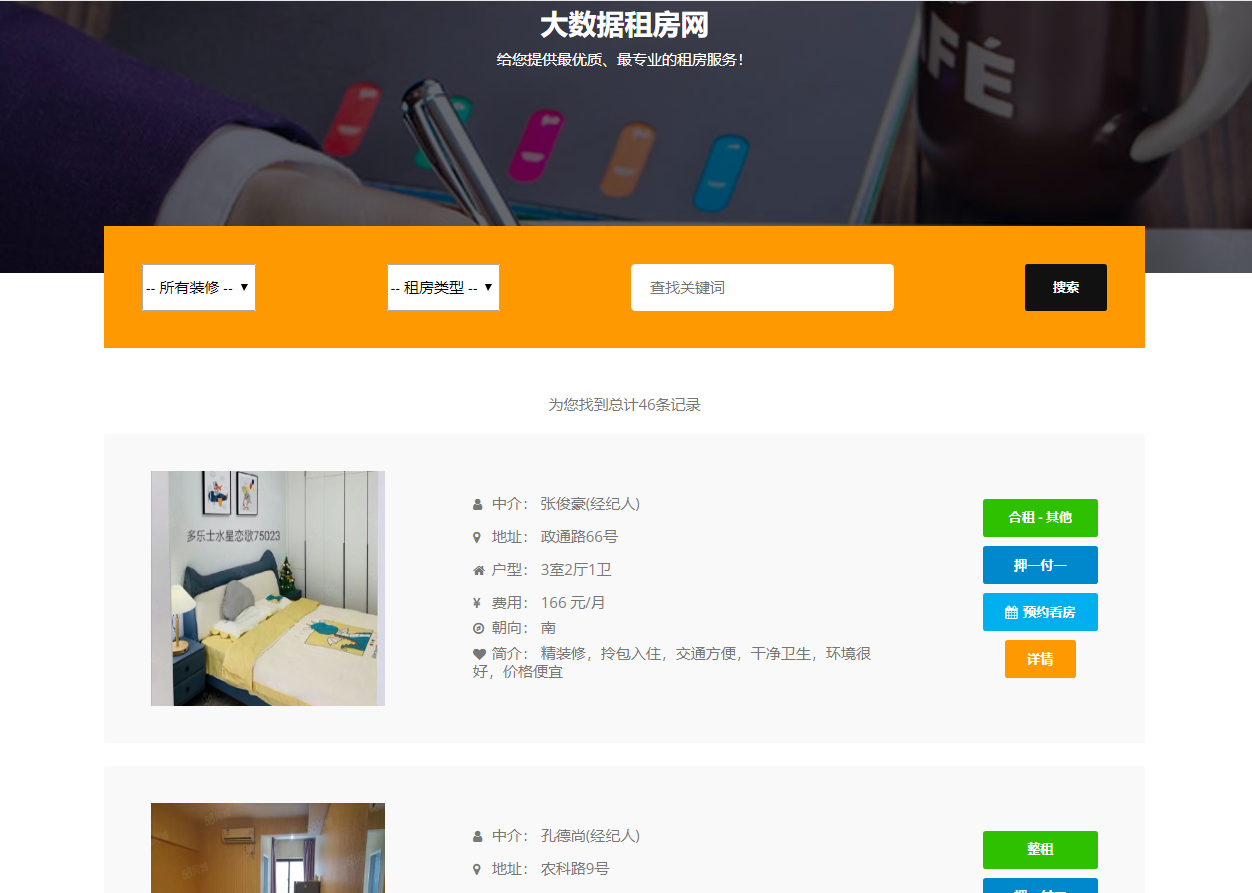

核心算法代码分享如下:
- from flask import Flask, request
- import json
- from flask_mysqldb import MySQL
-
- # 创建应用对象
- app = Flask(__name__)
- app.config['MYSQL_HOST'] = 'bigdata'
- app.config['MYSQL_USER'] = 'root'
- app.config['MYSQL_PASSWORD'] = '123456'
- app.config['MYSQL_DB'] = 'beike_hive'
- mysql = MySQL(app) # this is the instantiation
-
-
- @app.route('/tables01')
- def tables01():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table01''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['area','bads','goods'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables02')
- def tables02():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table02''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['area','avg_pay'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables03')
- def tables03():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table03 order by num desc''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['house_estate','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables04')
- def tables04():
- cur = mysql.connection.cursor()
- cur.execute('''
- select * from (
- SELECT ctime,num,CAST(replace(ctime,'小时前','') AS UNSIGNED) ctime2 FROM table04 where ctime like '%小时前%'
- union all
- SELECT ctime,num,CAST(replace(ctime,'天前','')*24 AS UNSIGNED) ctime2 FROM table04 where ctime like '%天前%'
- )t order by t.ctime2 desc;
- ''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['ctime','num','ctime2'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- # @app.route("/getmapcountryshowdata")
- # def getmapcountryshowdata():
- # filepath = r"D:\\hadoop_spark_hive_mooc2024\\server\\data\\maps\\china.json"
- # with open(filepath, "r", encoding='utf-8') as f:
- # data = json.load(f)
- # return json.dumps(data, ensure_ascii=False)
-
-
- @app.route('/tables05')
- def tables05():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table05''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['agent_name','hot'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables06')
- def tables06():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table06''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['house_type','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables07')
- def tables07():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table07''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['house_decora','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables08')
- def tables08():
- cur = mysql.connection.cursor()
- cur.execute('''SELECT * FROM table08''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['house_pay_way','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
- @app.route('/tables09')
- def tables09():
- cur = mysql.connection.cursor()
- #cur.execute('''SELECT SUBSTRING(address) address,num FROM table09''')
- cur.execute('''SELECT SUBSTRING(address,-5) address,num FROM table09''')
- #row_headers = [x[0] for x in cur.description] # this will extract row headers
- row_headers = ['address','num'] # this will extract row headers
- rv = cur.fetchall()
- json_data = []
- #print(json_data)
- for result in rv:
- json_data.append(dict(zip(row_headers, result)))
- return json.dumps(json_data, ensure_ascii=False)
-
-
- if __name__ == "__main__":
- app.run(debug=False)

- 序单片机拍照 序 ...
赞
踩

