
- 1.net 怎么使用github_如何正确的使用ncnn的Extractor
- 2MongoDB【部署 03】Windows系统安装mongodb并设置用户名密码(无需安装mongosh)及SpringBoot集成报错 Command failed with error 18_command failed with error 18 (authenticationfailed
- 3GitHub与Git命令使用笔记_github的quick setup在哪里
- 4Sql常用查询操作_sql server查询信息
- 5小米 10 年再创业,高端 5G 手机和 AIoT 有多少机会?
- 6ubuntu-git使用(远程分支)_ubuntu git拉取远程代码到本地
- 7git 合并指定文件_程序员必备基础:Git 命令全方位学习
- 8python智能硬件开发好吗_智能硬件不止树莓派,八款优秀智能硬件开源项目推荐...
- 9关于实习经历_csdn产品实习
- 10怎样计算两个文本的Rougel,Bleu评价指标
KNN问题回顾_knn 算法的三要素是距离度量、k值选择和分类决策规则
赞
踩
1. KNN算法的三个基本要素
(1)k值的选取。(在应用中,k值一般选择一个比较小的值,一般选用交叉验证来取最优的k值)
(2)距离度量。(Lp距离:误差绝对值p次方求和再求p次根。欧式距离:p=2的Lp距离。曼哈顿距离:p=1的Lp距离。p为无穷大时,Lp距离为各个维度上距离的最大值)
(3)分类决策规则。(也就是如何根据k个最近邻决定待测对象的分类。k最近邻的分类决策规则一般选用多数表决)
2. KD树
当我们的数据量很小的时候,我们可以使用线性扫描,计算输入实例和每一个训练实例的距离,但是当数据集很大时,这种方法就不太可行了。下面我们来介绍一下当数据量很大情况下,对于快速寻找k最近邻的算法——kd树。
kd树(K-dimension tree)是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构。kd树是是一种二叉树,表示对k维空间的一个划分,构造kd树相当于不断地用垂直于坐标轴的超平面将K维空间切分,构成一系列的K维超矩形区域。kd树的每个结点对应于一个k维超矩形区域。利用kd树可以省去对大部分数据点的搜索,从而减少搜索的计算量。
比如我们的数据集如左下图所示,经过构造Kd树后,我们呢就可以对数据空间进行如下右图所示的划分:

推广到三维空间,kd树按照一定的划分规则把这个三维空间划分了多个空间,如下图所示

下面我们看一下如何根据给定的数据集构造一个Kd树。构造kd树的方法如下:构造根结点,使根结点对应于K维空间中包含所有实例点的超矩形区域;通过下面的递归的方法,不断地对k维空间进行切分,生成子结点。在超矩形区域上选择一个坐标轴和在此坐标轴上的一个切分点,确定一个超平面,这个超平面通过选定的切分点并垂直于选定的坐标轴,将当前超矩形区域切分为左右两个子区域(子结点);这时,实例被分到两个子区域,这个过程直到子区域内没有实例时终止(终止时的结点为叶结点)。
在此过程中,将实例保存在相应的结点上。通常,循环的择坐标轴对空间切分,选择训练实例点在坐标轴上的中位数为切分点,这样得到的kd树是平衡的(平衡二叉树:它是一棵空树,或其左子树和右子树的深度之差的绝对值不超过1,且它的左子树和右子树都是平衡二叉树)。
KD树中每个节点是一个向量,和二叉树按照数的大小划分不同的是,KD树每层需要选定向量中的某一维,然后根据这一维按左小右大的方式划分数据。在构建KD树时,关键需要解决2个问题:
(1)选择向量的哪一维进行划分;
(2)如何划分数据。
第一个问题简单的解决方法可以是选择随机选择某一维或按顺序选择,但是更好的方法应该是在数据比较分散的那一维进行划分(分散的程度可以根据方差来衡量)。好的划分方法可以使构建的树比较平衡,可以每次选择中位数来进行划分,这样问题2也得到了解决。
下面给出构造平衡kd树的算法描述


例如:在《统计学习方法》中给定一个数据集T=(2,3),(5,4),(9,6),(4,7),(8,1),(7,2),对它构造平衡的Kd树,使用上面的算法,我们就可以对数据集空间进行如下的划分,以及生成对应的Kd树:

下面给出了使用简单的坐标轮换的方法递归的构造Kd树,也可以跟合理的计算所有数据点在每个维度上的数值的方差,然后选择方差最大的维度作为当前节点的划分维度。方差越大,说明这个维度上的数据越不集中(稀疏、分散),也就说明了它们就越不可能属于同一个空间,因此需要在这个维度上进行划分。
# kd-tree每个结点中主要包含的数据结构如下 class KdNode(object): def __init__(self, dom_elt, split, left, right): self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点) self.split = split # 整数(进行分割维度的序号) self.left = left # 该结点分割超平面左子空间构成的kd-tree self.right = right # 该结点分割超平面右子空间构成的kd-tree # 构建kd树 class KdTree(object): def __init__(self, data): k = len(data[0]) # 数据维度 def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode if not data_set: # 数据集为空 return None # key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较 # operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号 # data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序 data_set.sort(key=lambda x: x[split]) split_pos = len(data_set) // 2 # //为Python中的整数除法 median = data_set[split_pos] # 中位数分割点 split_next = (split + 1) % k # cycle coordinates # 递归的创建kd树 return KdNode(median, split, CreateNode(split_next, data_set[:split_pos]), # 创建左子树 CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树 self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点 # KDTree的前序遍历 def preorder(root): print(root.dom_elt) if root.left: # 节点不为空 preorder(root.left) if root.right: preorder(root.right) if __name__ == "__main__": data = [[2, 3], [5, 4], [9, 6], [4, 7], [8, 1], [7, 2]] kd = KdTree(data) preorder(kd.root)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
输出:

在构建好kd树后,我们对kd树进行搜索可以省去大部分数据点的搜索,减少搜索量。下面给出用kd树的最近邻搜索算法的描述。
Kd树的搜索:


例如我们看先前构建好的kd树,查找目标点(3,4.5)的最近邻点。同样先进行二叉查找,先从(7,2)查找到(5,4)节点,在进行查找时是由y = 4为分割超平面的,由于查找点为y值为4.5,因此进入右子空间查找到(4,7),形成搜索路径:(7,2)→(5,4)→(4,7),取(4,7)为当前最近邻点。以目标查找点为圆心,目标查找点到当前最近点的距离2.69为半径确定一个红色的圆。然后回溯到(5,4),计算其与查找点之间的距离为2.06,则该结点比当前最近点距目标点更近,以(5,4)为当前最近点。用同样的方法再次确定一个绿色的圆,可见该圆和y = 4超平面相交,所以需要进入(5,4)结点的另一个子空间进行查找。(2,3)结点与目标点距离为1.8,比当前最近点要更近,所以最近邻点更新为(2,3),最近距离更新为1.8,同样可以确定一个蓝色的圆。接着根据规则回退到根结点(7,2),蓝色圆与x=7的超平面不相交,因此不用进入(7,2)的右子空间进行查找。至此,搜索路径回溯完,返回最近邻点(2,3),最近距离1.8。

如果实例点是随机分布的,kd树搜索的平均计算复杂度是O(logN),这里N是训练实例数。kd树更适用于训练实例数远大于空间维数时的k近邻搜索。当空间维数接近训练实例数时,它的效率会迅速下降,几乎接近线性扫描。
下面给出kd树搜索的代码:
# kd-tree每个结点中主要包含的数据结构如下 class KdNode(object): def __init__(self, dom_elt, split, left, right): self.dom_elt = dom_elt # k维向量节点(k维空间中的一个样本点) self.split = split # 整数(进行分割维度的序号) self.left = left # 该结点分割超平面左子空间构成的kd-tree self.right = right # 该结点分割超平面右子空间构成的kd-tree # 构建kd树 class KdTree(object): def __init__(self, data): k = len(data[0]) # 数据维度 def CreateNode(split, data_set): # 按第split维划分数据集exset创建KdNode if not data_set: # 数据集为空 return None # key参数的值为一个函数,此函数只有一个参数且返回一个值用来进行比较 # operator模块提供的itemgetter函数用于获取对象的哪些维的数据,参数为需要获取的数据在对象中的序号 # data_set.sort(key=itemgetter(split)) # 按要进行分割的那一维数据排序 data_set.sort(key=lambda x: x[split]) split_pos = len(data_set) // 2 # //为Python中的整数除法 median = data_set[split_pos] # 中位数分割点 split_next = (split + 1) % k # cycle coordinates # 递归的创建kd树 return KdNode(median, split, CreateNode(split_next, data_set[:split_pos]), # 创建左子树 CreateNode(split_next, data_set[split_pos + 1:])) # 创建右子树 self.root = CreateNode(0, data) # 从第0维分量开始构建kd树,返回根节点 # KDTree的前序遍历 def preorder(root): print(root.dom_elt) if root.left: # 节点不为空 preorder(root.left) if root.right: preorder(root.right) from math import sqrt from collections import namedtuple # 定义一个namedtuple,分别存放最近坐标点、最近距离和访问过的节点数 result = namedtuple("Result_tuple", "nearest_point nearest_dist nodes_visited") def find_nearest(tree, point): k = len(point) # 数据维度 def travel(kd_node, target, max_dist): if kd_node is None: return result([0] * k, float("inf"), 0) # python中用float("inf")和float("-inf")表示正负无穷 nodes_visited = 1 s = kd_node.split # 进行分割的维度 pivot = kd_node.dom_elt # 进行分割的“轴” if target[s] <= pivot[s]: # 如果目标点第s维小于分割轴的对应值(目标离左子树更近) nearer_node = kd_node.left # 下一个访问节点为左子树根节点 further_node = kd_node.right # 同时记录下右子树 else: # 目标离右子树更近 nearer_node = kd_node.right # 下一个访问节点为右子树根节点 further_node = kd_node.left temp1 = travel(nearer_node, target, max_dist) # 进行遍历找到包含目标点的区域 nearest = temp1.nearest_point # 以此叶结点作为“当前最近点” dist = temp1.nearest_dist # 更新最近距离 nodes_visited += temp1.nodes_visited if dist < max_dist: max_dist = dist # 最近点将在以目标点为球心,max_dist为半径的超球体内 temp_dist = abs(pivot[s] - target[s]) # 第s维上目标点与分割超平面的距离 if max_dist < temp_dist: # 判断超球体是否与超平面相交 return result(nearest, dist, nodes_visited) # 不相交则可以直接返回,不用继续判断 # ---------------------------------------------------------------------- # 计算目标点与分割点的欧氏距离 temp_dist = sqrt(sum((p1 - p2) ** 2 for p1, p2 in zip(pivot, target))) if temp_dist < dist: # 如果“更近” nearest = pivot # 更新最近点 dist = temp_dist # 更新最近距离 max_dist = dist # 更新超球体半径 # 检查另一个子结点对应的区域是否有更近的点 temp2 = travel(further_node, target, max_dist) nodes_visited += temp2.nodes_visited if temp2.nearest_dist < dist: # 如果另一个子结点内存在更近距离 nearest = temp2.nearest_point # 更新最近点 dist = temp2.nearest_dist # 更新最近距离 return result(nearest, dist, nodes_visited) return travel(tree.root, point, float("inf")) # 从根节点开始递归 from time import clock from random import random # 产生一个k维随机向量,每维分量值在0~1之间 def random_point(k): return [random() for _ in range(k)] # 产生n个k维随机向量 def random_points(k, n): return [random_point(k) for _ in range(n)] if __name__ == "__main__": data = [[2, 3], [5, 4], [9, 6], [4, 7], [8, 1], [7, 2]] kd = KdTree(data) preorder(kd.root) ret = find_nearest(kd, [3, 4.5]) print(ret) N = 400000 t0 = clock() kd2 = KdTree(random_points(3, N)) # 构建包含四十万个3维空间样本点的kd树 ret2 = find_nearest(kd2, [0.1, 0.5, 0.8]) # 四十万个样本点中寻找离目标最近的点 t1 = clock() print("time: ", t1 - t0, "s") print(ret2)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
输出:

3. sklearn中的KNN算法
3.1 无监督最近邻
NearestNeighbors (最近邻)实现了 unsupervised nearest neighbors learning(无监督的最近邻学习)。 它为三种不同的最近邻算法提供统一的接口:BallTree, KDTree, 还有基于 sklearn.metrics.pairwise 的 brute-force 算法。算法的选择可通过关键字 ‘algorithm’ 来控制, 并必须是 [‘auto’, ‘ball_tree’, ‘kd_tree’, ‘brute’] 其中的一个。当默认值设置为 ‘auto’ 时,算法会尝试从训练数据中确定最佳方法。
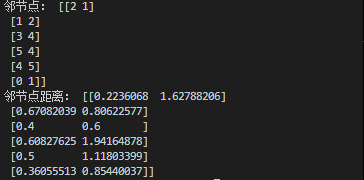
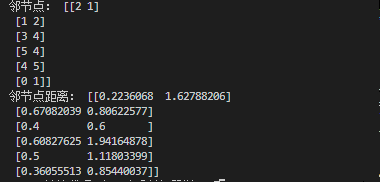
# ========无监督查找最近邻(常在聚类中使用,例如变色龙聚类算法)========== from sklearn.neighbors import NearestNeighbors import numpy as np # 快速操作结构数组的工具 X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) # 样本数据 test_x = np.array([[-3.2, -2.1], [-2.6, -1.3], [1.4, 1.0], [3.1, 2.6], [2.5, 1.0], [-1.2, -1.3]]) # 设置测试数据 # test_x=X # 测试数据等于样本数据。这样就相当于在样本数据内部查找每个样本的邻节点了。 nbrs = NearestNeighbors(n_neighbors=2, algorithm='ball_tree').fit(X) # 为X生成knn模型 distances, indices = nbrs.kneighbors(test_x) # 为test_x中的数据寻找模型中的邻节点 print('邻节点:',indices) print('邻节点距离:',distances) # ==============================使用kd树和Ball树实现无监督查找最近邻======================== from sklearn.neighbors import KDTree,BallTree import numpy as np # 快速操作结构数组的工具 X = np.array([[-1, -1], [-2, -1], [-3, -2], [1, 1], [2, 1], [3, 2]]) # test_x = np.array([[-3.2, -2.1], [-2.6, -1.3], [1.4, 1.0], [3.1, 2.6], [2.5, 1.0], [-1.2, -1.3]]) # 设置测试数据 test_x=X # 测试数据等于样本数据。这样就相当于在样本数据内部查找每个样本的邻节点了。 kdt = KDTree(X, leaf_size=30, metric='euclidean') distances,indices = kdt.query(test_x, k=2, return_distance=True) print('邻节点:',indices) print('邻节点距离:',distances)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3.2 最近邻分类
scikit-learn 实现了两种不同的最近邻分类器:KNeighborsClassifier 基于每个查询点的 k 个最近邻实现,其中 k 是用户指定的整数值。RadiusNeighborsClassifier 基于每个查询点的固定半径 r 内的邻居数量实现, 其中 r 是用户指定的浮点数值。
k -邻居分类是 KNeighborsClassifier 下的两种技术中比较常用的一种。k 值的最佳选择是高度依赖数据的:通常较大的 k 是会抑制噪声的影响,但是使得分类界限不明显。如果数据是不均匀采样的,那么 RadiusNeighborsClassifier 中的基于半径的近邻分类可能是更好的选择。
RadiusNeighborsClassifier 中用户指定一个固定半径 r,使得稀疏邻居中的点使用较少的最近邻来分类。
对于高维参数空间,这个方法会由于所谓的 “维度灾难” 而变得不那么有效。
在两种k最近邻分类中,基本的最近邻分类使用统一的权重:分配给查询点的值是从最近邻的简单多数投票中计算出来的。 在某些环境下,最好对邻居进行加权,使得更近邻更有利于拟合。可以通过 weights 关键字来实现。
默认值 weights = ‘uniform’ 为每个近邻分配统一的权重。而 weights = ‘distance’ 分配权重与查询点的距离成反比。 或者,用户可以自定义一个距离函数用来计算权重。
# ==========k最近邻分类========= import numpy as np # 快速操作结构数组的工具 from sklearn.neighbors import KNeighborsClassifier,KDTree # 导入knn分类器 # 数据集。4种属性,3种类别 data=[ [ 5.1, 3.5, 1.4, 0.2, 0], [ 4.9, 3.0, 1.4, 0.2, 0], [ 4.7, 3.2, 1.3, 0.2, 0], [ 4.6, 3.1, 1.5, 0.2, 0], [ 5.0, 3.6, 1.4, 0.2, 0], [ 7.0, 3.2, 4.7, 1.4, 1], [ 6.4, 3.2, 4.5, 1.5, 1], [ 6.9, 3.1, 4.9, 1.5, 1], [ 5.5, 2.3, 4.0, 1.3, 1], [ 6.5, 2.8, 4.6, 1.5, 1], [ 6.3, 3.3, 6.0, 2.5, 2], [ 5.8, 2.7, 5.1, 1.9, 2], [ 7.1, 3.0, 5.9, 2.1, 2], [ 6.3, 2.9, 5.6, 1.8, 2], [ 6.5, 3.0, 5.8, 2.2, 2], ] # 构造数据集 dataMat = np.array(data) X = dataMat[:,0:4] y = dataMat[:,4] knn = KNeighborsClassifier(n_neighbors=2,weights='distance') # 初始化一个knn模型,设置k=2。weights='distance'样本权重等于距离的倒数。'uniform'为统一权重 knn.fit(X, y) #根据样本集、结果集,对knn进行建模 result = knn.predict([[3, 2, 2, 5]]) #使用knn对新对象进行预测 print(result)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
3.3 最近邻回归
最近邻回归是用在数据标签为连续变量,而不是离散变量的情况下。分配给查询点的标签是由它的最近邻标签的均值计算而来的。
scikit-learn 实现了两种不同的最近邻回归:KNeighborsRegressor 基于每个查询点的 k 个最近邻实现, 其中 k 是用户指定的整数值。RadiusNeighborsRegressor 基于每个查询点的固定半径 r 内的邻点数量实现, 其中 r 是用户指定的浮点数值。
基本的最近邻回归使用统一的权重:即,本地邻域内的每个邻点对查询点的分类贡献一致。 在某些环境下,对邻点加权可能是有利的,使得附近点对于回归所作出的贡献多于远处点。 这可以通过 weights 关键字来实现。默认值 weights = ‘uniform’ 为所有点分配同等权重。 而 weights = ‘distance’ 分配的权重与查询点距离呈反比。 或者,用户可以自定义一个距离函数用来计算权重。
# ==============================k最近邻回归======================== import numpy as np import matplotlib.pyplot as plt from sklearn import neighbors np.random.seed(0) X = np.sort(5 * np.random.rand(40, 1), axis=0) T = np.linspace(0, 5, 500)[:, np.newaxis] y = np.sin(X).ravel() # 为输出值添加噪声 y[::5] += 1 * (0.5 - np.random.rand(8)) # 训练回归模型 n_neighbors = 5 for i, weights in enumerate(['uniform', 'distance']): knn = neighbors.KNeighborsRegressor(n_neighbors, weights=weights) y_ = knn.fit(X, y).predict(T) plt.subplot(2, 1, i + 1) plt.scatter(X, y, c='k', label='data') plt.plot(T, y_, c='g', label='prediction') plt.axis('tight') plt.legend() plt.title("KNeighborsRegressor (k = %i, weights = '%s')" % (n_neighbors,weights)) plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
输出结果

参见:
KNN算法的介绍
李航《统计学习方法》第三章

