
- 1FPGA拨码开关控制流水灯(VHDL)_vhdl开关控制led灯程序
- 2毕业设计:基于java的保险业务管理系统设计与实现_保险业务系统表设计
- 3团员分享_AI产品脑洞系列001:Google Duplex分析
- 4Eureka 服务注册与消费(超详细)_eureka 收费吗
- 5运维学网络安全还是云计算好?哪个更有前景?_云计算和网络安全哪个难学_网络运维和云计算
- 6Hive的基本操作_hive 如何插入boolean
- 7密码学一:哈希函数 散列函数是什么 SHA-256原理 哈希碰撞
- 8vscode 执行npm命令错误,node:internal/modules/cjs/loader:1148 throw err; ^Error: Cannot find module
- 9【随笔】Git 实战篇 -- Git Rebase出错?手把手教你如何优雅地解决常见问题 (四十二)_git rebase 怎么解决
- 10人工智能辅导程序 Mr. Ranedeer AI Tutor_mr. ranedeer ai tutor 怎么使用
Redis入门详解(一)—Redis数据类型及命令、SpringBoot整合Redis_redis关系型数据库
赞
踩
1、关系型数据库与非关系型数据库
redis是一款典型的开源的、支持网络交互的、可基于内存也可持久化的Key-Value非关系型数据库,在探讨接下来的内容之前,我们需要对非关系型数据库与它的"好兄弟"关系型数据库(这里使用MySQL数据库为例)这两个概念做个了解:
1、结构方面:
关系型数据库是结构化数据,每一张表都有严格的约束信息:字段名、字段数据类型、字段约束信息等等,插入的数据必须通过SQL语句遵守这些约束;非关系型数据库则对数据库的格式没有严格约束,形式松散,自由,并且不同的非关系型数据库存储的信息的格式也会有所不同,可以是以Json的文档形式储存,也可以是使用键值对的形式储存
2、关联性:
关系型数据库的表与表之间往往存在关联,比如外键;而非关系型数据库不存在关联关系,要维护关系要么靠代码中的业务逻辑,要么靠数据之间的耦合
3、查询方式:
关系型数据库会基于SQL语句做查询,语法标准统一;非关系型数据库查询有语法差异较大,五花八门的,例如:redis使用的方式是通过get key来获取value,而ES(elaticsearch,也是非关系型数据库的一种)则通过http请求来获取value
4、是否能够满足ACID原则:
关系型数据库能满足事务ACID的原则;非关系数据库往往不支持事务,或者不能严格保证ACID的特性
2、Redis特性:
1、键值型,使用方便,功能丰富
2、单线程,能保证线程安全
3、基于内存,低延迟,速度快
4、支持数据持久化
5、支持主从集群和分片集群,在安全和扩容上提供支撑
6、支持多语言客户端,java、C都可以使用
3、Redis的安装:
redis下载官网:Download | Redis
博主资源:https://download.csdn.net/download/m0_68772878/88740366
这里对Redis的安装步骤不错过多介绍,mac可以通过官网下载安装包,也可以通过Homebrew的方式安装,如果是Linux也可以使用docker安装redis,如果是mac本m1系统可以直接拿取作者已经安装配置好的资源即可。
4、Redis通用命令了解及使用
部分数据类型,都可以使用的命令,常见的有:
KEYS:查询所有符合模板的key,*匹配多个字段,?匹配一个
DEL:删除一个指定的key
EXISTS:判断key是否存在
EXPIRE:给一个key设置有效期,有效期到达自动删除该key
TTL:查看一个key剩余的有效期
TYPE:查看指定key类型
SELECT: 切换数据库,默认有16个,下标为0~15
CONFIG:配置参数设置(set)以及查看(get)
FLUSHDB: 清空当前数据库中的key
FLUSHALL:清空所有数据库中的key
MULTI:开启事务
EXEC:执行事务,相当于提交事务
DISCARD:回滚事务
示例代码如下:
- 127.0.0.1:6379[1]> select 2 //切换到第二个数据库
- OK
- 127.0.0.1:6379[2]> select 1
- OK
- 127.0.0.1:6379[1]> keys *
- 1) "id"
- 2) "float"
- 3) "height"
- 4) "name"
- 5) "age"
- 127.0.0.1:6379[1]> keys *t //查询以t结尾的key
- 1) "float"
- 2) "height"
- 127.0.0.1:6379[1]> keys a* //查询以a开头的key
- 1) "age"
- 127.0.0.1:6379[1]> del height
- (integer) 1
- 127.0.0.1:6379[1]> type name
- string
- 127.0.0.1:6379[1]> exists id
- (integer) 1
- 127.0.0.1:6379[1]> exists ID
- (integer) 0
- 127.0.0.1:6379[1]> expire id 10
- (integer) 1
- 127.0.0.1:6379[1]> ttl id
- (integer) 6
- 127.0.0.1:6379[1]> ttl id
- (integer) 3
- 127.0.0.1:6379[1]> ttl id //此时key为id已经不存在
- (integer) -2
- 127.0.0.1:6379[1]> get id
- (nil)
- 127.0.0.1:6379[1]> keys *
- 1) "float"
- 2) "name"
- 3) "age"
- 127.0.0.1:6379[1]> config get * //查询redis所有配置
- 127.0.0.1:6379[1]> config get port
- 1) "port"
- 2) "6379"
- 127.0.0.1:6379[1]> multi //开启事务
- OK
- 127.0.0.1:6379[1](TX)> set name cola //开启事务后所有命令将不会马上执行,而是保存到队列里
- QUEUED
- 127.0.0.1:6379[1](TX)> set age 27
- QUEUED
- 127.0.0.1:6379[1](TX)> exec //提交,则之前的所有命令都会生效,并且该命令执行后事务关闭
- 1) OK
- 2) OK
- 127.0.0.1:6379[1]> get name //可以get到
- "cola"
- 127.0.0.1:6379[1]> multi //开启事务
- OK
- 127.0.0.1:6379[1](TX)> set num1 123
- QUEUED
- 127.0.0.1:6379[1](TX)> set num2 456
- QUEUED
- 127.0.0.1:6379[1](TX)> discard //事务回滚,之前的命令搜不会生效
- OK
- 127.0.0.1:6379[1]> get num2 //不可以get到
- (nil)

5、Redis五大普通数据类型的了解及命令的使用
Redis五大数据类型分别有:String、Hash、List、Set、SortedSet(ZSet)
①String常见命令的使用
在redis中,字符串有三种格式,分别是我们了解的String常规字符串,还有int和float,这三种格式在底层都是以字节数组形式储存,所以在redis中int和float也属于String,并且这两者可以进行自增自减操作。
String常用命令汇总:
SET:添加或修改已经存在的一个String类型的键值对
GET:根据key获取String类型的value
MSET:批量添加多个String类型的键值对
MGET:根据多个key获取多个String类型的value
INCR:让整型的key自增1
INCRBY:让一个整型的key自增指定的步长
INCRBYFLOAT:让一个浮点型的数字自增并指定步长
SETNX:添加一个String类型的键值对,前提是这个key不存在,否则不执行
SETEX:添加一个String类型的键值对,并且指定有限期
示例代码如下:
- 127.0.0.1:6379[1]> set name cola
- OK
- 127.0.0.1:6379[1]> get name
- "cola"
- 127.0.0.1:6379[1]> mset name zoey age 24 height 168
- OK
- 127.0.0.1:6379[1]> mget name age height
- 1) "zoey"
- 2) "24"
- 3) "168"
- 127.0.0.1:6379[1]> set id 1
- OK
- 127.0.0.1:6379[1]> incr id
- (integer) 2
- 127.0.0.1:6379[1]> incrby id 5
- (integer) 7
- 127.0.0.1:6379[1]> set float 2.5 //设置浮点型数据value必须为浮点型,否则默认还是整形
- OK
- 127.0.0.1:6379[1]> incrbyfloat float 5
- "7.5"
- 127.0.0.1:6379[1]> setnx hobby ball
- (integer) 1
- 127.0.0.1:6379[1]> setnx name lily
- (integer) 0
- 127.0.0.1:6379[1]> setex hobby 10 swing //有效期以秒为单位,有效期截止后该key会自动被删除
- OK
- 127.0.0.1:6379[1]> get hobby
- (nil)
②Hash类型常见命令的使用
Hash类型在Redis中存储的数据可以把他理解为一个对象,是对象就会包含对象的属性和值
HSET key filed value:添加或修改已经存在的一个hash类型的filed的值
HGET key field:根据key中的field获取到value
HMSET key filed:批量添加多个hash类型key的filed的值
HMGET key filed:批量获取多个hash类型key的filed的值
HGETALL key:获取一个hash类型的key中所有的filed和值
HKEYS key:获取一个hash类型的key中的所有的filed
HINCRBY:让一个hash类型key的字段值自增并指定步长
HSETNX:添加一个hash类型key的filed值,前提是这个key不存在,否则不执行
示例代码:
- 127.0.0.1:6379[2]> hset user name cola //定义对象为user 属性有name 值为cola
- (integer) 1
- 127.0.0.1:6379[2]> hset user age 27 //在对象为user中插入 属性有age 值为27的数据
- (integer) 1
- 127.0.0.1:6379[2]> hmset user sex women height 167
- OK
- 127.0.0.1:6379[2]> hget user name
- "cola"
- 127.0.0.1:6379[2]> hget user height
- "167"
- 127.0.0.1:6379[2]> hmget user name age sex
- 1) "cola"
- 2) "27"
- 3) "women"
- 127.0.0.1:6379[2]> hgetall user
- 1) "name"
- 2) "cola"
- 3) "age"
- 4) "27"
- 5) "sex"
- 6) "women"
- 7) "height"
- 8) "167"
- 127.0.0.1:6379[2]> hkeys user
- 1) "name"
- 2) "age"
- 3) "sex"
- 4) "height"
- 127.0.0.1:6379[2]> hset user id 1
- (integer) 1
- 127.0.0.1:6379[2]> hincrby user id 5
- (integer) 6
- 127.0.0.1:6379[2]> hsetnx user name zoey //key为user已经存在,插入失败
- (integer) 0
- 127.0.0.1:6379[2]> hsetnx socure chinesr 78
- (integer) 1
- 127.0.0.1:6379[2]>
hash类型数据在可视化工具中呈现出来的对象结果
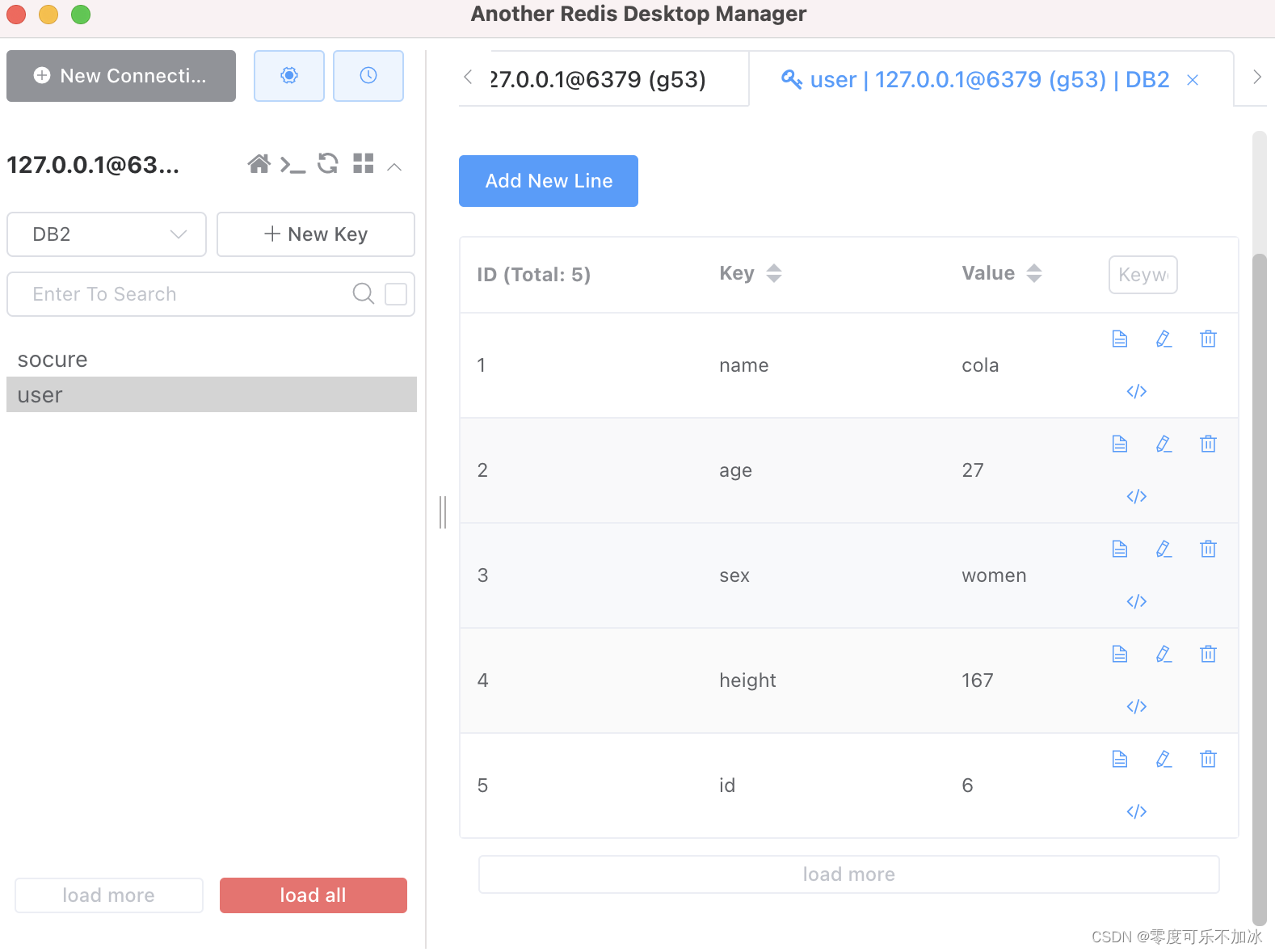
③List类型常见命令的使用
和Java中的LinkedList相似,可以看做是一个双向链表结构。既可以正向检索也可以反向检索,其特征也和LinkedList类似,具有元素有序、可重复、删改速度快的特点
————————————————
对于List而言,它的底层引用的是栈的概念,所以其命令具有入栈和出栈的命令,入栈为PUSH,出栈为POP
————————————————
LPUSH key element:向列表左侧插入一个或多个元素
LPOP key count:移除并返回列表左侧的第count个元素,没有返回nil
RPUSH:向列表右侧插入一个或多个元素
RPOP:移除并返回列表右侧的第一个元素,没有返回nil
LRANGE key start stop:返回指定范围内所有元素,开区间
BLPOP和BRPOP:与LPOP和RPOP类似,只不过在没有元素时等待指定时间,而不是直接返回nil
示例代码:
- 127.0.0.1:6379[3]> lpush user cola zoey lily betty hermon mike
- (integer) 6
- 127.0.0.1:6379[3]> lpop user 1
- 1) "mike"
- 127.0.0.1:6379[3]> lpop user 2
- 1) "hermon"
- 2) "betty"
- 127.0.0.1:6379[3]> rpush user kitty andrew jetty
- (integer) 6
- 127.0.0.1:6379[3]> rpop user 2
- 1) "jetty"
- 2) "andrew"
- 127.0.0.1:6379[3]> lrange user 1 5
- 1) "zoey"
- 2) "cola"
- 3) "kitty"
- 127.0.0.1:6379[3]> lrange user 0 5
- 1) "lily"
- 2) "zoey"
- 3) "cola"
- 4) "kitty"
- 127.0.0.1:6379[3]> lrange user 0 6
- 1) "lily"
- 2) "zoey"
- 3) "cola"
- 4) "kitty"
- 127.0.0.1:6379[3]>
-
④Set类型常见命令
和Java中的HashSet类似,可以看做是一个value为空的hashMap,它有无序、元素不能重复、查找快的特性,并且支持交集、并集、差集等功能
SADD key :向set中添加一个或多个元素
SREM ket :移除set中的指定元素
SCARD key:返回set中元素的个数
SISMEMBER key member:判断 一个元素是否存在与set中,0表示不在,1表示在
SMEMBERS key:获取set中的所有元素
SINTER key1 key2:求key1和key2的交集
SDIFF key1 key2:求key1和key2的差集
SUNION key1 key2:求key1和key2的并集
示例代码:
- 127.0.0.1:6379[4]> sadd user mike cola zoey betty kitty
- (integer) 5
- 127.0.0.1:6379[4]> scard user
- (integer) 5
- 127.0.0.1:6379[4]> srem user zoey
- (integer) 1
- 127.0.0.1:6379[4]> sismember user zoey
- (integer) 0
- 127.0.0.1:6379[4]> sismember user mike
- (integer) 1
- 127.0.0.1:6379[4]> smembers user
- 1) "mike"
- 2) "cola"
- 3) "betty"
- 4) "kitty"
- 127.0.0.1:6379[4]> sadd num1 1 3 5 7 9 0
- (integer) 6
- 127.0.0.1:6379[4]> sadd num2 2 4 6 7 8 0
- (integer) 6
- 127.0.0.1:6379[4]> sinter num1 num2
- 1) "0"
- 2) "7"
- 127.0.0.1:6379[4]> sdiff num1 num2
- 1) "1"
- 2) "3"
- 3) "5"
- 4) "9"
- 127.0.0.1:6379[4]> sunion num1 num2
- 1) "0"
- 2) "1"
- 3) "2"
- 4) "3"
- 5) "4"
- 6) "5"
- 7) "6"
- 8) "7"
- 9) "8"
- 10) "9"
- 127.0.0.1:6379[4]>
⑤SortedSet类型常见命令:
这个类型的结构可以用于排序,他有查询速度快、可排序、元素不重复的特点,可用于实现排行榜的业务
ZADD key score member:添加一个或多个元素,存在就更新
ZREM key:删除元素
ZSCORE :获取指定元素的score值
ZRANK:获取指定元素的排名
ZCARD:获取元素个数
ZCOUNT key min max:获取指定范围内所有元素的个数
(这里的min 和max是score的值)
ZINCRBY :指定元素自增
ZRANGE key start stop:按照score排名后,获取指定排名范围内的member
(这里的start和stop是排名,不是score,并且结果为升序排序)
ZDIFF、ZINTER、ZUNION:求差集、交集、并集
注:所有排名默认是升序,且第一位为0,如果要降序,在命令Z后面添加REV
- 升序:ZRANK
- 降序:ZREVRANK
示例代码:
- 127.0.0.1:6379[5]> zadd english 90.0 cola
- (integer) 1
- 127.0.0.1:6379[5]> zadd english 87.5 zoey
- (integer) 1
- 127.0.0.1:6379[5]> zadd english 70.0 kitty 69.0 jetty
- (integer) 2
- 127.0.0.1:6379[5]> zscore english zoey
- "87.5"
- 127.0.0.1:6379[5]> zrank english zoey
- (integer) 2
- 127.0.0.1:6379[5]> zcard english
- (integer) 4
- 127.0.0.1:6379[5]> zcount english 60 85
- (integer) 2
- 127.0.0.1:6379[5]> zrange english 0 3
- 1) "jetty"
- 2) "kitty"
- 3) "zoey"
- 4) "cola"
- 127.0.0.1:6379[5]> zrevrank english cola
- (integer) 0
- 127.0.0.1:6379[5]>
以上五大常见数据类型使我们最常使用的,其中String数据类型使我们使用最多的;另外Redis还提供了三种特殊数据类型,在某些特殊的业务场景中,这些特殊的类型或许能够给我们多一种解决思路,但在这里不做重点分享(因为博主也不会哈哈哈哈哈

Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

