
- 1Java实现excel导出功能的几种方法——poi、easyExcel、easypoi、jxl_java导出excel的三种方法
- 2ChatGPT AIGC人工智能助力职场,办公人员的福音来了 WPS AI
- 3flutter vscode+第三方安卓模拟器
- 4【数据结构】排序:插入排序与希尔排序详解_数据结构输入一组数据使用直接插入算法进行排序,输出排序结果
- 5计算机科学与技术万金油专业,盘点工学大类里的“万金油”专业
- 6LSS 和 BEVDepth算法解读_bev自底向上和自顶向下
- 7深入解析 JWT(JSON Web Tokens):原理、应用场景与安全实践_jwt 适用场景
- 8mysql 数据丢失更新的解决方法
- 9python爬虫获取的网页数据为什么要加[0-python3爬虫爬取网页思路及常见问题(原创)...
- 10HBase无法启动HRegionServer_hbase没有hquorumpeer进程
darknet框架下yolov3实战(一)_yolov3 darknet
赞
踩
目录
参考文章:YOLO-V3实战(darknet) - chiemon - 博客园
1. 运行demo
1. 安装darknet很简单,YOLO: Real-Time Object Detection,直接按照该网站的步骤配置就行。
其中,需要安装cuda与opencv直接在makefile文件里修改对应的值就行,1是安装,0是不安装,默认都是不安装的。

2. 下载预训练模型,运行命令:
./darknet detect cfg/yolov3.cfg yolov3.weights data/dog.jpg如果出现如下图的结果,则说明已正确运行了;

如果你在安装是OPENCV设置为1了,那么会直接显示运行的结果图像并保存;如果没有安装opencv,则图像保存在同级目录下的predictions.jpg。
因为我的opencv之前已经安装好的,如果之前没有安装好,我不知道在编译darknet时候是也编译了opencv还是说编译的时候只配置了opencv,但我感觉应该是只负责配置opencv,因为darknet的编译过程我没有看到编译opencv,而且编译opencv耗时很长,而编译darknet的时候一会儿就编译完了,所以我感觉应该只是配置opencv。
2. 使用VOC数据训练自己的模型
darknet是在VOC格式的数据集上训练yolov3
2.1 标注数据
darknet框架下的训练数据是两个txt文本,一个记录路径,以及记录标注目标的位置。生成这两个txt文件首先需要有标注好的voc数据,voc2007或voc2012均可,我用的是voc2007数据格式,生成标注数据和生成voc2007数据格式可见我的博文《将标注的数据集转化为VOC2007格式》
2.2 生成训练用的txt文件
由于我的数据结构是voc2007的,自己修改了官网的scripts\voc_label.py文件,添加了一些注释。自己修改文件里面还是有很多坑的,要特别注意,在文章后面我也列出了一些。修改后程序如下:
- import xml.etree.ElementTree as ET
- import pickle
- import os
- from os import listdir, getcwd
- from os.path import join
-
- classes = ["myobject"]
-
-
- def convert(size, box):
- dw = 1./(size[0])
- dh = 1./(size[1])
- x = (box[0] + box[1])/2.0 - 1
- y = (box[2] + box[3])/2.0 - 1
- w = box[1] - box[0]
- h = box[3] - box[2]
- x = x*dw
- w = w*dw
- y = y*dh
- h = h*dh
- return (x,y,w,h)
-
- def convert_annotation(image_id):
- in_file = open('E:\dataset\myobject\VOC2007\Annotations/%s.xml'%(image_id))#读取标注数据
- out_file = open('E:\dataset\myobject\VOC2007/labels/%s.txt'%(image_id), 'w')#输出的标注训练数据文本文件
- tree=ET.parse(in_file)
- root = tree.getroot()
- size = root.find('size')
- w = int(size.find('width').text)
- h = int(size.find('height').text)
-
- for obj in root.iter('object'):
- difficult = obj.find('difficult').text
- cls = obj.find('name').text
- if cls not in classes or int(difficult)==1:
- continue
- cls_id = classes.index(cls)
- xmlbox = obj.find('bndbox')
- b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
- bb = convert((w,h), b)
- out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
-
- wd = getcwd()#获取当前执行文件夹的路径
-
- if not os.path.exists('E:\dataset\myobject\VOC2007/labels'):#判断是否存在输出文件夹
- os.makedirs('E:\dataset\myobject\VOC2007/labels')#不存在则创建输出文件夹
- image_ids = open('E:\dataset\myobject\VOC2007\ImageSets\Main/train.txt').read().strip().split()#分离文本中的imageID
- list_file = open('2007_train.txt','w')
- for image_id in image_ids:
- list_file.write('E:\dataset\myobject\VOC2007\JPEGImages/%s.jpg\n'%(image_id))#将路径写入到文本文件中
- convert_annotation(image_id)
- list_file.close()
运行以下命令生成训练缩需的txt文件。
python voc_label.py2.3 修改配置文件
(1) 修改cfg/yolov3-voc.cfg,建议在Windows下修改,用文本工具打开文件后查找"yolo"字段,文件中共有3处yolo节点,在yolo节点下面的类别数改成你的类别数,yolo节点上面的卷积层的滤波数改成类别数对应的滤波数,具体计算如下:
- [convolutional]
- size=1
- stride=1
- pad=1
- filters=18 #filters = 3 * ( classes + 5 ) here,filters=3*(1+5)
- activation=linear
-
- [yolo]
- mask = 0,1,2
- anchors = 10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326
- classes=1 #修改为自己的类别数
- num=9
- jitter=.3
- ignore_thresh = .5
- truth_thresh = 1
- random=1
此处我只例举了一个,配置文件中共有3处要修改。
(2)修改data\voc.names文件,改成你自己的类别名,记住一行一个,千万别多出空行,空行程序也会识别为类别数。
(3)修改数据格式:
- data load_data_detection(int n, char **paths, int m, int w, int h, int boxes, int classes, float jitter, float hue, float saturation, float exposure)
- {
- char **random_paths = get_random_paths(paths, n, m);
- int i;
- data d = {0};
- d.shallow = 0;
-
- d.X.rows = n;
- d.X.vals = calloc(d.X.rows, sizeof(float*));
- d.X.cols = h*w; //灰阶图
- //d.X.cols = h*w*3; //RGB图
-
- ...
(4)修改cfg\voc.data文件,该文件内容如下图,classes修改成你的类别数,train.txt修改成标注数据时候的2007_train.txt文件的路径(train.txt文件中记录的是训练图片的路径列表),valid是测试数据路径,可以改成和train一样的路径,names路径就是voc.names的路径,backup为输出的权重信息文件夹路径

(5)下载预训练权重:https://pjreddie.com/media/files/darknet53.conv.74,也可以下载官方的预训练权重,YOLO: Real-Time Object Detection,但下载后需手动提取骨架网络。
darknet/partial.cmd at 57e878b4f9512cf9995ff6b5cd6e0d7dc1da9eaf · AlexeyAB/darknet · GitHub
对于yolov3-tiny.weights权重,骨架网络提取命令为:
./darknet partial cfg/yolov3-tiny.cfg yolov3-tiny.weights yolov3-tiny.conv.15 15yolov3.weights权重,提取命令为:
sudo ./darknet partial cfg/yolov3.cfg yolov3.weights yolov3.conv.81 81后面的数字代表了卷积层的层数。提取命令如下:
./darknet partial cfg文件 权重文件 输出名字 层数(6)训练自己的模型:
./darknet -i <gpu_id> detector train <data_cfg> <train_cfg> <weights>其中:"-i" 是GPU标签号,如果你只有一个GPU,那么就是"-i 0",<data_cfg>是数据配置文件,即voc.data的路径,<train_cfg> 为网络结构的配置文件路径,即yolov3-voc.cfg的路径,<weights>为预训练权重的路径。
我的命令是:
./darknet -i 0 detector train cfg/voc.data cfg/yolov3-voc.cfg darknet53.conv.74对于yolov3-tiny.weights
./darknet -i 0 detector train cfg/voc.data cfg/yolov3-tiny.cfg yolov3-tiny.conv.15训练过程如下:
- Loaded: 4.533954 seconds
- Region Avg IOU: 0.262313, Class: 1.000000, Obj: 0.542580, No Obj: 0.514735, Avg Recall: 0.162162, count: 37
- Region Avg IOU: 0.175988, Class: 1.000000, Obj: 0.499655, No Obj: 0.517558, Avg Recall: 0.070423, count: 71
- Region Avg IOU: 0.200012, Class: 1.000000, Obj: 0.483404, No Obj: 0.514622, Avg Recall: 0.075758, count: 66
- Region Avg IOU: 0.279284, Class: 1.000000, Obj: 0.447059, No Obj: 0.515849, Avg Recall: 0.134615, count: 52
- 1: 629.763611, 629.763611 avg, 0.001000 rate, 6.098687 seconds, 64 images
- Loaded: 2.957771 seconds
- Region Avg IOU: 0.145857, Class: 1.000000, Obj: 0.051285, No Obj: 0.031538, Avg Recall: 0.069767, count: 43
- Region Avg IOU: 0.257284, Class: 1.000000, Obj: 0.048616, No Obj: 0.027511, Avg Recall: 0.078947, count: 38
- Region Avg IOU: 0.174994, Class: 1.000000, Obj: 0.030197, No Obj: 0.029943, Avg Recall: 0.088889, count: 45
- Region Avg IOU: 0.196278, Class: 1.000000, Obj: 0.076030, No Obj: 0.030472, Avg Recall: 0.087719, count: 57
- 2: 84.804230, 575.267700 avg, 0.001000 rate, 5.959159 seconds, 128 imagesiter
- 迭代次数 总损失 平均损失 学习率 花费时间 参与训练的图片总数
| Region | cfg文件中yolo-layer的索引 |
| Avg IOU | 当前迭代中,预测的box与标注的box的平均交并比,越大越好,期望数值为1 |
| Class | 标注物体的分类准确率,越大越好,期望数值为1 |
| obj | 越大越好,期望数值为1 |
| No obj | 越小越好,但不为零 |
| .5R | 以IOU=0.5为阈值时候的recall; recall = 检出的正样本/实际的正样本 |
| .75R | 以IOU=0.75为阈值时候的recall |
| count | 正样本数 |
3. 运行训练后的模型
模型训练完后,按照voc.data的配置,保存在backup文件夹下,在该文件夹下,有许多训练的中间文件,中间文件名中的数值代表了迭代次数。但都加了锁,需要先解锁才能进行预测,使用以下命令对文件进行解锁:
sudo chown $USER 文件路径测试单张图片命令:
./darknet detector test <data_cfg> <test_cfg> <weights> <image_file> 实例:
./darknet detector test cfg/voc.data cfg/yolov3-voc.cfg backup/yolov3-voc_10000.weights test.jpg附上darknet程序使用方式:
- ./darknet detector test <data_cfg> <models_cfg> <weights> <test_file> [-thresh] [-out]
- ./darknet detector train <data_cfg> <models_cfg> <weights> [-thresh] [-gpu] [-gpus] [-clear]
- ./darknet detector valid <data_cfg> <models_cfg> <weights> [-out] [-thresh]
- ./darknet detector recall <data_cfg> <models_cfg> <weights> [-thresh]
-
- '<>'必选项,’[ ]‘可选项
输出:保存./darknet目录下的predict.png
| data_cfg | 数据配置文件,eg:cfg/voc.data |
| models_cfg | 模型配置文件,eg:cfg/yolov3-voc.cfg |
| weights | 权重配置文件,eg:weights/yolov3.weights |
| test_file | 测试文件,eg:*/*/*/test.txt |
| -thresh | 显示被检测物体中confidence大于等于 [-thresh] 的bounding-box,默认0.005 |
| -out | 输出文件名称,默认路径为results文件夹下,eg:-out "" //输出class_num个文件,文件名为class_name.txt;若不选择此选项,则默认输出文件名为comp4_det_test_"class_name".txt |
| -i/-gpu | 指定单个gpu,默认为0,eg:-gpu 2 |
| -gpus | 指定多个gpu,默认为0,eg:-gpus 0,1,2 |
4. 遇到的坑
1. 我一开始运行程序是在ubuntu虚拟机下运行的,运行demo直接报错,程序killed。如下图:
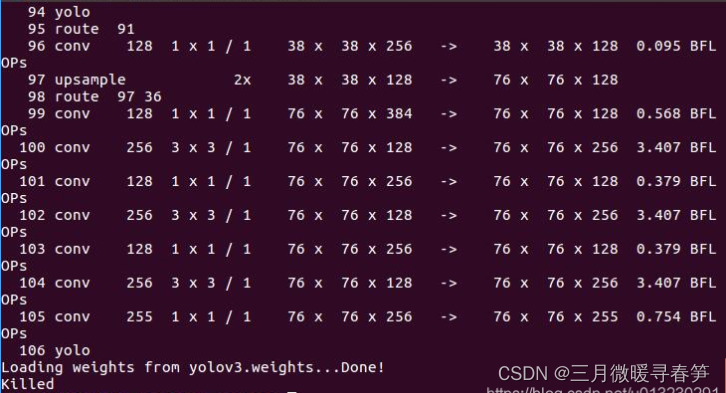
网上查了很多资料,没有找到,后来在纯ubuntu环境下运行,居然可以了,灵感突现,可能是内存太小的原因,因为错误发生是loading预训练模型的时候,而预训练模型文件较大,进而修改了分配的内存,问题顺利解决。
2. 训练之前路径设置,python中路径设置时路径字符串中不是正斜杠"\",都是反斜杠"/",如果使用了正斜杠,则会报如下图错误:
![]()
3. 在linux下生成训练的txt文件时,一般系统里有两个python版本,需要注意使用python2还是python3版本,在运行py脚本文件时,由于系统默认是python2的,要改成python3的,所以运行命令如下:
python3 xxx.py4. 从checkpoint继续训练,测试训练后的模型,报错如下:
segmentation fault但从预训练模型开始训练却没有报错,不知道是什么原因。因此尽量不要从模型保存文件夹backup下的yolov3-backup.weights开始训练。
5. 训练过程中loss出现"Inf",这种情况可能是训练过拟合了,可以适当调整下训练的batch和subdivision的值,如将batch调大一点,但要保证batch/subdivision的值是4的倍数。

