
- 1rasterio介绍以及代码
- 2篇三:让OAuth2 server支持密码模式_oauth2authorizationgrantauthenticationtoken
- 3Django 自定义权限管理系统(通过中间件认证)_中间件对指定的文件配置权限认证
- 4Confluent kafka rest实战
- 5关于Gitee的安装与概述_gitee安装
- 6SF相关1111
- 7补: Codeforces Round #698 (Div. 2)_codeforces round #698 (div. 2) c
- 8基于微信小程序+SpringBoot的私家车位共享系统小程序(源码+文档+部署+讲解)
- 9Codeforces Round #828 (Div. 3) 题解(A-E2)_828 codeforces
- 10Mac 系统安装 PyCharm 并使用_mac安装pycharm
【CNN】深入浅出讲解卷积神经网络(介绍、结构、原理)
赞
踩
 本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅!
本文收录于《深入浅出讲解自然语言处理》专栏,此专栏聚焦于自然语言处理领域的各大经典算法,将持续更新,欢迎大家订阅! 个人主页:有梦想的程序星空
个人主页:有梦想的程序星空 个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。
个人介绍:小编是人工智能领域硕士,全栈工程师,深耕Flask后端开发、数据挖掘、NLP、Android开发、自动化等领域,有较丰富的软件系统、人工智能算法服务的研究和开发经验。 如果文章对你有帮助,欢迎
如果文章对你有帮助,欢迎
关注、
点赞、收藏、订阅。
1、卷积神经网络的背景介绍
卷积神经网络(Convolutional Neural Networks,简称CNN)是一种具有局部连接、权值共享等特点的深层前馈神经网络(Feedforward Neural Networks),是深度学习(deep learning)的代表算法之一,擅长处理图像特别是图像识别等相关机器学习问题,比如图像分类、目标检测、图像分割等各种视觉任务中都有显著的提升效果,是目前应用最广泛的模型之一。
卷积神经网络具有表征学习(representation learning)能力,能够按其阶层结构对输入信息进行平移不变分类(shift-invariant classification),可以进行监督学习和非监督学习,其隐含层内的卷积核参数共享和层间连接的稀疏性使得卷积神经网络能够以较小的计算量对格点化(grid-like topology)特征,例如像素和音频进行学习、有稳定的效果且对数据没有额外的特征工程(feature engineering)要求,并被大量应用于计算机视觉、自然语言处理等领域。
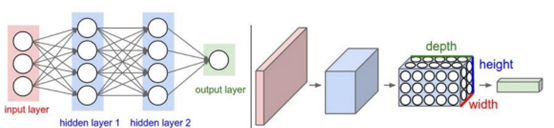
图1 左为神经网络(全连接结构),右为卷积神经网络。
2、CNN的网络结构
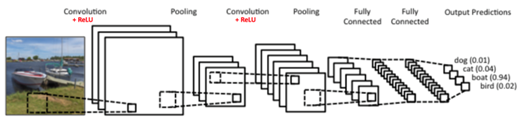
图2 CNN的网络结构图
卷积神经网络的基本结构大致包括:卷积层、激活函数、池化层、全连接层、输出层等。
(1)卷积层(Convolutional layer),这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。卷积神经网路中每层卷积层由若干卷积单元组成,每个卷积单元的参数都是通过反向传播算法优化得到的。
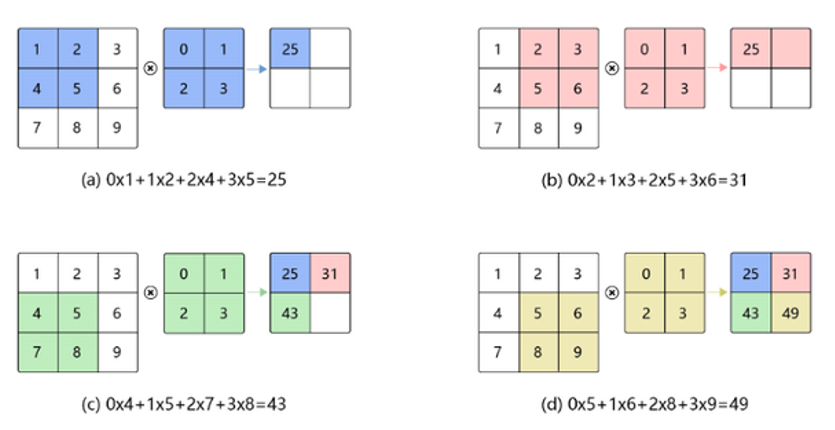
图3 卷积操作图解
在这个卷积层,有两个关键操作:
- 局部关联。每个神经元看做一个滤波器(filter)。
- 窗口(receptive field)滑动, filter对局部数据计算。
卷积运算的目的是提取输入的不同特征,某些卷积层可能只能提取一些低级的特征如边缘、线条和角等层级,更多层的网路能从低级特征中迭代提取更复杂的特征。
卷积层的作用是对输入数据进行卷积操作,也可以理解为滤波过程,一个卷积核就是一个窗口滤波器,在网络训练过程中,使用自定义大小的卷积核作为一个滑动窗口对输入数据进行卷积。
卷积过程实质上就是两个矩阵做乘法,在卷积过程后,原始输入矩阵会有一定程度的缩小,比如自定义卷积核大小为3*3,步长为1时,矩阵长宽会缩小2,所以在一些应用场合下,为了保持输入矩阵的大小,我们在卷积操作前需要对数据进行扩充,常见的扩充方法为0填充方式。
卷积层中还有两个重要的参数,分别是偏置和激活(独立层,但一般将激活层和卷积层放在一块)。
偏置向量的作用是对卷积后的数据进行简单线性的加法,就是卷积后的数据加上偏置向量中的数据,然后为了增加网络的一个非线性能力,需要对数据进行激活操作,在神经元中,就是将没有的数据率除掉,而有用的数据则可以输入神经元,让人做出反应。
(2)激活函数,最常用的激活函数目前有Relu、tanh、sigmoid,着重介绍一下Relu函数(即线性整流层(Rectified Linear Units layer, 简称ReLU layer)),Relu函数是一个线性函数,它对负数取0,正数则为y=x(即输入等于输出),即f(x)=max(0,x),它的特点是收敛快,求梯度简单,但较脆弱。
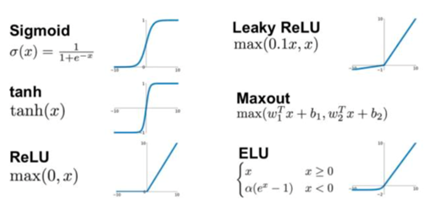
图4 常用激活函数
由于经过Relu函数激活后的数据0值一下都变成0,而这部分数据难免有一些我们需要的数据被强制取消,所以为了尽可能的降低损失,我们就在激活层的前面,卷积层的后面加上一个偏置向量,对数据进行一次简单的线性加法,使得数据的值产生一个横向的偏移,避免被激活函数过滤掉更多的信息。
(3)池化层(Pooling layer),通常在卷积层之后会得到维度很大的特征,将特征切成几个区域,取其最大值或平均值,得到新的、维度较小的特征。
池化方式一般有两种,一种为取最大值,另一种为取均值,池化的过程也是一个移动窗口在输入矩阵上滑动,滑动过程中去这个窗口中数据矩阵上最大值或均值作为输出,池化层的大小一般为2*2,步长为1。
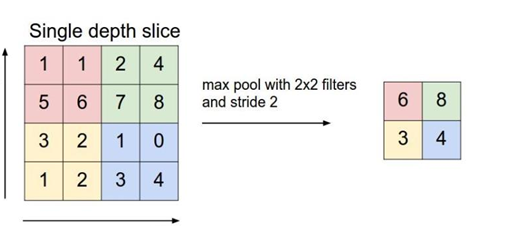
图5 max pool图解

图6 池化方式比较
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。
池化层的作用是对数据进行降维处理,对于所有神经网络来说,随着网络深度增加,网络中权值参数的数量也会越来越大,这也是导致我们在训练一个大型网络时必须使用大型服务站和GPU加速了,但是卷积神经网络出了它本身权值共享和局部连接方式可以有效的降低网络压力外,池化层也作为一个减低网络压力的重要组成部分,经过卷积层后的数据做为池化层的输入进行池化操作。
池化层的具体作用:
- 特征不变性,也就是我们在图像处理中经常提到的特征的尺度不变性,池化操作就是图像的resize,平时一张狗的图像被缩小了一倍我们还能认出这是一张狗的照片,这说明这张图像中仍保留着狗最重要的特征,我们一看就能判断图像中画的是一只狗,图像压缩时去掉的信息只是一些无关紧要的信息,而留下的信息则是具有尺度不变性的特征,是最能表达图像的特征。
- 特征降维,我们知道一幅图像含有的信息是很大的,特征也很多,但是有些信息对于我们做图像任务时没有太多用途或者有重复,我们可以把这类冗余信息去除,把最重要的特征抽取出来,这也是池化操作的一大作用。
- 在一定程度上防止过拟合,更方便优化。
(4)全连接层( Fully-Connected layer), 把所有局部特征结合变成全局特征,用来计算最后每一类的得分。
全连接层往往在分类问题中用作网络的最后层,作用主要为将数据矩阵进行全连接,然后按照分类数量输出数据,在回归问题中,全连接层则可以省略,但是我们需要增加卷积层来对数据进行逆卷积操作。
3、CNN的训练过程图解
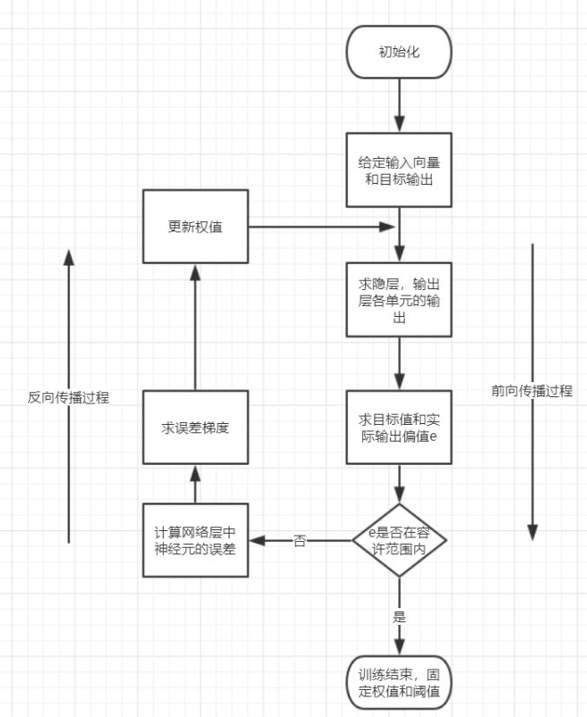
图7 CNN的训练过程图解
前向传播阶段:
选取训练样本(x,y),将x输入网络中。随机初始化权值(一般情况下选取小数),信息从输入层经过一层一层的特征提取和转换,最后到达输出层,得到输出结果。
反向传播阶段:
输出结果与理想结果对比,计算全局性误差(即Loss)。得到的误差反向传递给不同层的神经元,按照“迭代法”调整权值和偏重,寻找全局性最优的结果。
4、CNN的基本特征
(1)局部感知(Local Connectivity)
卷积层解决这类问题的一种简单方法是对隐含单元和输入单元间的连接加以限制:每个隐含单元仅仅只能连接输入单元的一部分。例如,每个隐含单元仅仅连接输入图像的一小片相邻区域。
(2)参数共享(Parameter Sharing)
在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
权值共享使得我们能更有效的进行特征抽取,因为它极大的减少了需要学习的自由变量的个数。通过控制模型的规模,卷积网络对视觉问题可以具有很好的泛化能力。
关注微信公众号【有梦想的程序星空】,了解软件系统和人工智能算法领域的前沿知识,让我们一起学习、一起进步吧!

