
- 1《数据结构》学习笔记-第八章 高级搜索树(ABST)_第8章 高级搜索树
- 2SensorService启动-Android12_android重启sensor
- 3无头单向链表_无头链表
- 4Python中的异常处理:try, except, else, finally详解_python try if else
- 5信创=国产化?一文带你快速了解信创和国产化_信创国产化
- 6Docker - Windows 11 下 Docker Desktop 的 下载 安装 配置 使用_dockerdesktop
- 7Vite+Vue3+Ts配置ESllint_vite+vue3+ts 配置eslint
- 8javaScript中String中配合正则匹配的一些方法_string正则匹配
- 9git的基本理解_git的解释
- 10Prometheus(六):Blackbox监控安装配置_prometheus blackbox
大语言模型的预训练[4]:指示学习Instruction Learning:Entailment-oriented、PLM oriented、human-oriented以及和Prompt工程区别_大模型中 text 和instruct 是什么差别
赞
踩
大语言模型的预训练[4]:指示学习Instruction Learning:Entailment-oriented、PLM oriented、human-oriented以及和Prompt Learning,In-content Learning区别
1.指示学习的定义
Instruction Learning 让模型对题目 / 描述式的指令进行学习。针对每个任务,单独生成指示,通过在若干个 full-shot 任务上进行微调,然后在具体的任务上进行评估泛化能力,其中预训练模型参数是可更新的。
指示学习和提示学习的目的都是去挖掘语言模型本身具备的知识。不同的是 Prompt 是激发语言模型的补全能力,例如根据上半句生成下半句,或是完形填空等。Instruct 是激发语言模型的理解能力,它通过给出更明显的指令,让模型去做出正确的行动。通过下面的例子来理解这两个不同的学习方式:
- 提示学习:老师讲解的通俗易懂,学生很喜欢,这门课太____了。
- 指示学习:这句话的情感是非常正向的:老师讲解的通俗易懂,学生很喜欢。选项:A = 好;B = 一般;C = 差。
对于任务指令学习,目标是通过遵循指令来驱动系统在给定输入的情况下达到输出。因此,数据集由三个项目组成:
- 输入 (X):一个实例的输入;它可以是单个文本片段(例如,情感分类)或一组文本片段(例如,文本蕴涵、问题回答等)。
- 输出(Y):一个实例的输出;在分类问题中,它可以是一个或多个预定义的标签;在文本生成任务中,它可以是任何开放式文本。
- 模板 (T):一个文本模板,试图单独表达任务意义或充当 X 和 Y 之间的桥梁。T 可能还不是一种组件结构。
三种不同类别的文本说明,如图所示:
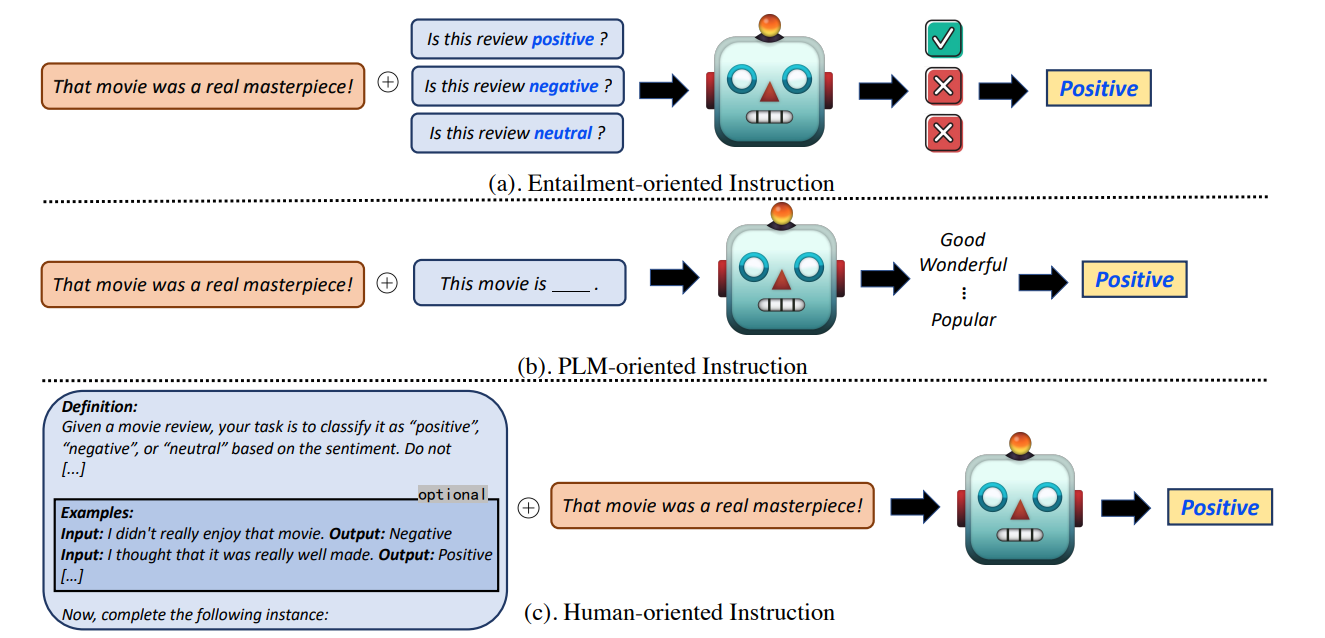
-
Entailment-oriented:将原始输入作为前提,将每个预定义的标签转换为假设(即指令)。
-
PLM oriented:使用模板将原始任务输入构建成完形填空题。
-
human-oriented:利用足够的任务信息作为指导,例如定义和可选的小样本演示等
2. 指示学习的指令种类
2.1 任务指令
将这些指令概括为执行 T,X 和 Y 的不同组合的三类(ENTAILMENT-ORIENTED、 PLM-ORIENTED 和 HUMAN-ORIENTED)
2.1.1 I=T+Y:Entailment-oriented Instruction
-
处理分类任务的一个传统方案是将目标标签转换为索引,并让模型决定输入属于哪个索引。这种范式侧重于对输入语义进行编码,同时丢失标签语义。为了让系统识别新标签而不依赖于大量标记的示例,为每个标签建立一个假设——然后,推导标签的真值被转换为确定假设的真值。这种方法内置在指令 I 中,指令(I)结合模板 (Y) 和标签 (Y) 来解释每个目标标签(Y)。由于这种范式自然满足文本蕴涵(TE,其中任务输入和指令可以分别被视为前提和假设)的格式,因此这类指令被称为“面向蕴涵的指令”。优点有以下四个方面:
-
保留了标签语义,使得输入编码和输出编码在输入输出关系建模中得到同等重视;
-
产生了一个统一的推理过程文本蕴涵来处理各种 NLP 问题;
-
创造了利用现有 TE 数据集的间接监督的机会,因此预训练的 TE 模型有望在没有特定任务微调的情况下处理这些目标任务;
-
将原始的封闭集标签分类问题扩展为具有很少甚至零标签特定示例的开放域开放形式标签的识别问题。
因此,它被广泛应用于各种少样本 / 零样本分类任务,如主题分类、情感分类、实体类型和实体关系。
-
2.1.2 I=T+X:PLM-oriented Instruction
-
Prompt 是 PLM-oriented instructions 的代表,通常是一个简短的话语,前面加上任务输入(前缀提示),或者一个完形填空题模板(完形填空)
-
基本上是为从预训练的 LM (PLM) 查询中间响应而设计的。由于提示输入符合 PLM 的预训练目标(例如,完形填空式输入满足屏蔽语言建模目标(Kenton 和 Toutanova,2019)),因此有助于摆脱对传统监督微调的依赖大大减轻了人工标注的成本。因此,快速学习在许多先前的少量 / 零样本 NLP 任务中取得了令人印象深刻的结果。
-
尽管提示技术具有出色的性能,但在实际应用中,面向 PLM 的指令仍然存在两个明显的问题:
- 不是用户友好的。由于提示是为服务 PLM 设计的,因此鼓励使用 “模型的语言”(例如,模型首选的不连贯的词或内部嵌入)设计提示。然而,这种面向 PLM 的指令很难理解,并且经常违反人类的直觉。同时,提示的性能在很大程度上取决于费力的提示工程(Bach 等人,2022 年),而大多数最终用户都不是 PLM 专家,通常缺乏足够的知识来调整有效的提示。
- 应用限制。提示通常简短而简单,而许多任务不能仅仅通过简短的提示来有效地制定,这使得提示难以处理现实世界 NLP 任务的不同格式。
-
2.1.3 Human-oriented Instruction
-
面向人的指令基本上是指用于在人工标注平台上进行众包工作的指令(例如,Amazon MTurk 指令)。与面向 PLM 的指令不同,面向人的指令通常是一些人类可读的、描述性的、段落式的任务特定的文本信息,包括任务标题、类别、定义、应避免的事情等。因此,Human-oriented Instruction 说明更加用户友好,可以理想地应用于几乎任何复杂的 NLP 任务。
- 面向人的指令类似于面向 PLM 的指令,它也利用模板将原始输入(红色)转换为完形填空题。然而,任务模板本身包含信息任务语义,即正式的任务定义。同时,还提供了 few-shot 备选任务演示.
2.2 如何建模指令
-
Semantic Parser-based(基于语义解析器):在机器学习的早期阶段,为了帮助系统理解自然语言指令,大量工作采用语义解析将指令转换为形式语言(逻辑公式),以便于系统执行。
-
Prompting Template-based(基于提示模板):对于基于神经网络的系统可以直接将自然语言指令编码到模型的嵌入中,而无需语义解析器的帮助。基于提示模板的方法的本质是使用模板将任务输入转换为提示格式(即完形填空)。
-
Prefix Instruction-based(基于前缀指令):与基于前缀指令的方法主要用于为 human-oriented 的指令建模,其中提供了足够的特定于任务的信息。
-
HyperNetwork-based:使用基于前缀指令的建模策略有两个明显的问题。首先,它将任务级指令与每个实例级输入连接起来,重复过程显着减慢了处理 / 推理速度,冗长的输入也增加了计算成本的负担。其次,它可能会影响优化,因为模型无法明确区分任务输入 x 和前缀指令 I,因此模型可以简单地学习完成任务并忽略指令。为了解决上述问题,使用超网络对任务指令进行编码。使用基于超网络的方法的本质是:
-
分别对任务指令 I 和任务输入 x 进行编码。
-
将指令转换为特定于任务的模型参数。
-
2.3 优点
指令通常包含比单独标记的示例更抽象和更全面的目标任务知识。随着任务指令的可用性,可以快速构建系统来处理新任务,尤其是在特定于任务的标注稀缺的情况,举例说明,例如,一个小孩可以通过从指导和一些例子中学习来很好地解决一个新的数学任务。
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做 zero-shot,而提示学习都是针对一个任务的。泛化能力不如指示学习。
3.与其他大语言模型技术对比
3.1.Instruction Learning 与 Prompt Learning
相同之处:
- 核心一样,就是去发掘语言模型本身具备的知识
不同之处:
- 不同点就在于,Prompt 是去激发语言模型的补全能力,比如给出上半句生成下半句、或者做完形填空,都还是像在做 language model 任务;而 Instruction Learning 则是激发语言模型的理解能力,通过给出更明显的指令 / 指示,让模型去理解并做出正确的 action。比如 NLI / 分类任务
- Prompt 在没精调的模型上也能有一定效果,而 Instruction Learning 则必须对模型精调,让模型知道这种指令模式;Prompt Learning 都是针对一个任务的,比如做个情感分析任务的 prompt tuning,精调完的模型只能用于情感分析任务,而经过 Instruction Learning 多任务精调后,可以用于其他任务的 zero-shot!
3.2.In-content Learning 和 Instruction Learning
-
In-context Learning :给出范例,让机器回答其它问题;以 GPT3 为代表,将检索后的每个文档(标题 + 提炼后的语句)作为一个样本输入到 GPT3 里,最后写 “标题:xxx \n 内容:_______”,让模型去补全。
-
**Instruction Learning:**给出题目的叙述,让机器进行回答;以 ChatGPT 为代表,将检索后的信息输入给 ChatGPT 并后面补上一句 “请根据以上内容,回答问题 xxx”。
4.关键知识点
-
Instruction Learning建模指令有:基于语义解析器、基于提示模板、基于前缀指令
-
Instruction Learning任务指令类型有:Entailment-oriented Instruction、PLM-oriented Instruction 、Human-oriented Instruction
-
通过Instruction Learning给【题目叙述】回答问题以及In-context Learning给【范例】回答问题可以让语言模型变成一个通才。
-
指示学习的优点是它经过多任务的微调后,也能够在其他任务上做zero-shot,而提示学习都是针对一个任务的,泛化能力不如指示学习。
-
指示学习和提示学习的相同之处是:核心一样,就是去发掘语言模型本身具备的知识。


