
- 1Java实现微信小程序相关接口_内网java代码调用微信小程序接口
- 2单目测距_csdn单目测距原理
- 3EditPlus使用正则表达式替换删除空白行_editplus 删除空行
- 4【Python探索之旅】运算符
- 5大数据-计算引擎-Spark(三):RDD编程【离线分析;替代MapReduce编程,使用RDD(弹性分布式数据集)编程;处理非结构化数据;RDD操作算子:transformation、Action】_spark离线分析
- 6超融合与云有哪些不同,全在这里
- 7等保测评是什么意思?分为几个等级?_等保一共分为几个等级
- 8解决 git push Failed to connect to 127.0.0.1 port 45463: 拒绝连接_gitstack网站拒绝链接csdn
- 9小红书接口加密参数X-sign
- 10Java 实际开发中,实现微信小程序/微信公众号的微信注册登录_java 微信注册
Deep learning + SLAM小综述_deep-learn-slam可以有效解决场景退化问题吗?
赞
踩
两个月前写的DL+SLAM研究现状综述,刚想起放到博客上。
随着近几年深度学习技术的火热,越来越多的研究工作尝试将深度学习引入到SLAM中去,有些工作也取得了较为不错的效果。本文尝试对相关工作进行简单梳理,并探讨深度学习+SLAM的可行性和发展方向。当然个人学识有限,如有疏漏之处望大家不吝指正。
首先上个人观点:长期来讲,深度学习有极大可能会去替代目前SLAM技术中的某些模块,但彻底端到端取代SLAM可能性不大。短期来讲(三到五年),深度学习不会对传统SLAM技术产生很大冲击。
下面结合具体工作谈谈这么说的理由。目前深度学习+SLAM有几个主要的研究方向:1)单目SLAM学习尺度/深度;2)相机重定位;3)前端提取特征和匹配4)端到端学习相机位姿;5)语义SLAM;
- 单目SLAM学习尺度/深度
单目纯视觉SLAM最大的问题是缺乏尺度信息,于是最直观的思路就是引入深度学习来脑补图像的尺度/深度信息。
代表工作其实有很多,但很大一部分是端到端架构,两个网络分别计算pose+depth直接出绝对轨迹,这类工作我放在后面端到端学习位姿部分中介绍,这里仅例举估计深度而不计算pose的工作。如TUM发表在CVPR17上的CNN-SLAM: Real-time dense monocular SLAM with learned depth prediction,将LSD-SLAM里的深度估计和图像匹配都替换成基于CNN的方法,取得了较为鲁棒的结果。
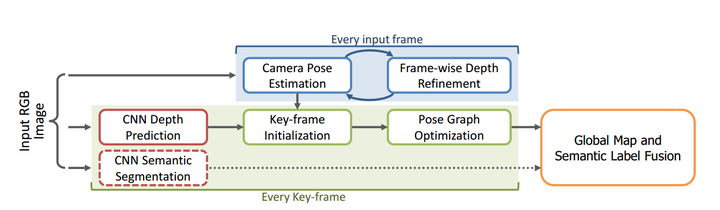
但个人认为用DL估算深度在原理上不是很站得住,DL擅长去做一些高层理解类的任务如特征估计图像匹配等,但深度估计太偏计算几何了。人眼去看一张图像也只能获得大概定性的深度远近,而无法得到精确定量的深度大小,这种任务对于DL来说实在有些强人所难了。而传统的深度计算方法,不考虑误差理论上是可以得到精确数学解的,深度学习无论如何也无法达到这样的解析精度。
实际上,相关工作的精度确实不高,CNN-SLAM在室内每个像素的平均误差约50cm,在室外则高达7米,相比传统三角化计算深度在精度上有一定差距。但优势在于鲁棒性较强,传统三角化所面临的视差太大太小问题在DL这里都不存在。
- 相机重定位/闭环检测
相机重定位/闭环检测通常需要对当前时刻各类传感器的信息进行特征提取,并与之前得到的历史数据进行搜索匹配,以便在跟丢后重新获取一个初始位置/判断是否到达了某个历史位置。
这一过程与传统的图像匹配有一定相似性,是比较适合用深度学习去完成的一类任务。
代表工作如DL+SLAM的开山之作——剑桥的论文:ICCV15的PoseNet,使用GoogleNet去做6-dof相机位姿的回归模型,并利用得到的pose进行重定位。

其结果在当时(15年)非常具有开创性,但其主要意义还是在于开创了一种新的思路,其实用性及精确度并不如传统重定位方案来的可靠。
- 前端提取特征和匹配
目前DL在图像领域最成功的应用即是feature en

