- 1Hadoop之MapReduce基础
- 2比阿里EMO抢先开源!蔡徐坤“复出”唱RAP,腾讯AniPortrait让照片变视频,鬼畜区UP狂喜!看看哪家效果好_audio2video大模型
- 3数据库系统概论(第五版)课后习题一
- 4基于Spark的用户分析系统_基于spark分布式计算框架的用户行为分析
- 5安全测试-django防御安全策略_django 开发的网站提高安全性
- 6前端工程师的岗位职责(合集)_前端设计分工
- 7vant 组件【PullRefresh 下拉刷新】页面没划到最顶部依然触发刷新_vant2list未下拉到头就刷新了
- 8Android 项目必备(三十六)-->设备连接管理及常用 ADB 命令行_adb连接是否成功
- 9Mybatis框架学习笔记(04)_实验04 mybatis框架:注解方法
- 10PMP证书:考PMP的人真的很厉害吗?_考pmp的人都很厉害吗
实验三、SPARK RDD基础编程方法二_ubuntu的spark实验rdd
赞
踩
一、实验目的
理解 SPARK 工作流程;
掌握 SPARK RDD 基础编程方法;
二、实验平台
操作系统:Linux(建议Ubuntu16.04);
Hadoop版本:2.7.1;
JDK版本:1.7或以上版本;
Java IDE:IDEA
spark版本:3.1.2
scala版本:2.12.10
三、实验内容
(一) 分析用户行为数据: 现在有一份用户行为数据,包括用户ID、时间戳、事件类型和事件内容。请使用大数据计算工具(如 Spark)进行分析,以解决以下问题.
UserActivityData.txt
UserID, Timestamp, EventType, EventContent 1, 2023-04-15 08:30:00, Click, Product A 2, 2023-04-15 08:35:00, View, Product B 1, 2023-04-15 08:40:00, Add to Cart, Product A 3, 2023-04-15 08:42:00, Click, Product C 2, 2023-04-15 08:50:00, Purchase, Product B 1, 2023-04-15 08:55:00, Click, Product D 4, 2023-04-15 08:57:00, View, Product E 2, 2023-04-15 09:00:00, Click, Product F 3, 2023-04-15 09:05:00, Add to Cart, Product C 5, 2023-04-15 09:10:00, Click, Product G 1, 2023-04-15 08:30:00, Click, Product A 2, 2023-04-15 08:35:00, View, Product B 1, 2023-04-15 08:40:00, Add to Cart, Product A 3, 2023-04-15 08:42:00, Click, Product C 2, 2023-04-15 08:50:00, Purchase, Product B 1, 2023-04-15 08:55:00, Click, Product D 4, 2023-04-15 08:57:00, View, Product E 2, 2023-04-15 09:00:00, Click, Product F 3, 2023-04-15 09:05:00, Add to Cart, Product C 5, 2023-04-15 09:10:00, Click, Product G 1, 2023-04-15 09:20:00, Purchase, Product D 2, 2023-04-15 09:25:00, Click, Product F 3, 2023-04-15 09:30:00, View, Product C 1, 2023-04-15 09:35:00, Click, Product A 2, 2023-04-15 09:40:00, Add to Cart, Product F 4, 2023-04-15 09:45:00, Click, Product E 1, 2023-04-15 09:50:00, View, Product D 2, 2023-04-15 09:55:00, Click, Product B 3, 2023-04-15 10:00:00, Purchase, Product C 5, 2023-04-15 10:05:00, Click, Product G

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
UserInfoData.txt
UserID, UserName
1, Alice
2, Bob
3, Carol
4, Dave
5, Eve
- 1
- 2
- 3
- 4
- 5
- 6
通过分布式计算平台Spark,使用Scala及Java编程语言进行求解。代码质量有限,仅供参考!
为了方便后续数据处理操作,首先将两份txt文件中第一行(字段名)删除。
1、二次排序和筛选:
a. 从给定的数据集中,使用二次排序的方法,首先按照用户ID升序排序,然后按照时间戳降序排序。输出按照排序条件筛选后的前 10 条记录。
(1)按照Ordered和Serializable接口重写方法,实现自定义排序的key
class SecondarySortKey (val first:Int,val second:String) extends Ordered [SecondarySortKey] with Serializable { override def compare(other: SecondarySortKey): Int = { if(this.first-other.first!=0){ this.first-other.first }else{ if(this.second>other.second){ -1 } else if(this.second.equals(other.second)) { 0 } else{ 1 } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(2)主程序代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object task_one_1a {
def main(args :Array[String]): Unit = {
val conf=new SparkConf().setAppName("task_one_1a").setMaster("local")
val sc=new SparkContext(conf)
val lines=sc.textFile("file:///home/XXX/Desktop/UserActivityData.txt",1)
val sortkey=lines.map(line=>(new SecondarySortKey(line.split(", ")(0).toInt,line.split(", ")(1)),line))
val sorted=sortkey.sortByKey(true)
val result=sorted.map(sortline=>sortline._2)
result.take(10).foreach(println) #输出前10记录
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)查看运行结果,如下图所示:
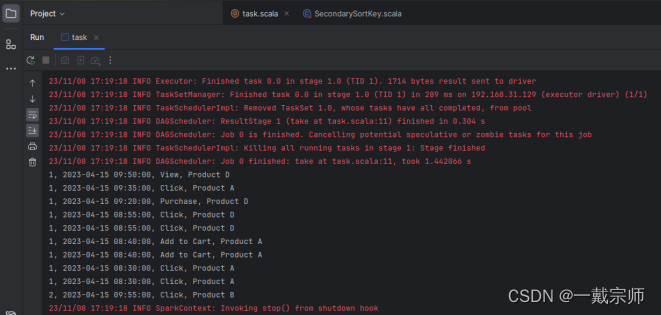
b. 从给定的数据集中,使用二次排序的方法,首先按照用户ID降序排序,然后按照事件类型升序排序。输出按照排序条件筛选后的前 10 条记录。
(1)按照Ordered和Serializable接口重写方法,实现自定义排序的key(同上)
class SecondarySortKey (val first:Int,val second:String) extends Ordered [SecondarySortKey] with Serializable { override def compare(other: SecondarySortKey): Int = { if(this.first-other.first!=0){ this.first-other.first }else{ if(this.second>other.second){ -1 } else if(this.second.equals(other.second)) { 0 } else{ 1 } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
(2)主程序代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object task_one_1b {
def main(args :Array[String]): Unit = {
val conf=new SparkConf().setAppName("task_one_1b").setMaster("local")
val sc=new SparkContext(conf)
val lines=sc.textFile("file:///home/XXX/Desktop/UserActivityData.txt",1)
val sortkey=lines.map(line=>(new SecondarySortKey(line.split(", ")(0).toInt,line.split(", ")(2)),line))
val sorted=sortkey.sortByKey(false) #修改sortByKey参数为false
val result=sorted.map(sortline=>sortline._2)
result.take(10).foreach(println)#输出前10记录
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
(3)查看运行结果,如下图所示:
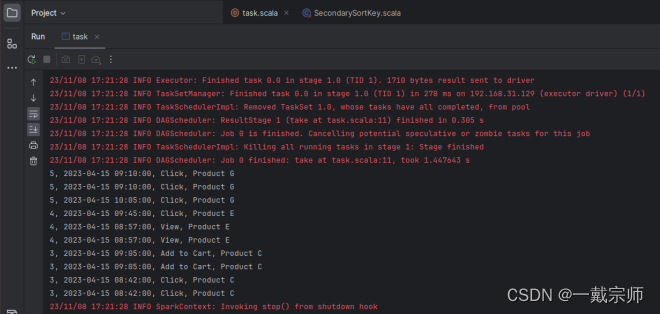
2、去重和统计:
a. 从给定的数据集中,找出重复的事件记录(完全相同的记录),并将它们去重。输出去重后的数据集。输出的数据格式:用户ID 事件类型 事件内容
(1)核心代码:lines.filter(_.trim.length>0).map(line=>(line.trim,“”)).groupByKey().sortByKey().keys找出数据集中重复记录并去除。
(2)程序代码
import org.apache.spark.SparkContext
import org.apache.spark.SparkConf
object task_one_2a {
def main(args :Array[String]): Unit = {
val conf = new SparkConf().setAppName("task_one_2a").setMaster("local")
val sc = new SparkContext(conf)
val lines = sc.textFile("file:///home/XXX/Desktop/UserActivityData.txt", 1)
val sortkey = lines.filter(_.trim.length>0).map(line=>(line.trim,"")).groupByKey().sortByKey().keys
sortkey.saveAsTextFile("file:///home/XXX/Desktop/output") #这里保存结果,为后续使用
for (elem <- sortkey) {
val s = elem.split(", ")
println(s(0)+", "+s(2)+", "+s(3))#按格式要求打印输出
}
}
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
(3)查看运行结果,如下图所示:
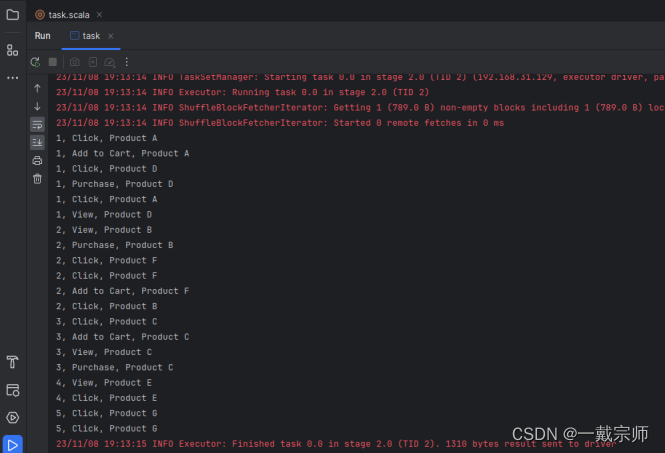
b. 对去重后的数据集,统计每种事件类型的数量,并输出事件类型和对应的数量。
时间能力有限,选择使用Java for循环连接打印简单粗暴解决问题,时间空间复杂度较高,对大量数据不友好,代码质量有限,仅供参考!
(1)通过JavaRDD data=sc.textFile(file,1);将文件内容转化为SPARKRDD
(2)通过List collect=data.collect();将data转化为列表,并设置一个集合变量及map变量,计算事件类型对应数量,并映射存储。
(3)程序代码:
import org.apache.spark.api.java.*; import org.apache.spark.SparkConf; import java.util.*; public class task_one_2b { public static void main(String[] args) { String file="file:///home/XXX/Desktop/output/part-00000";#此前2a输出的结果文件 SparkConf conf=new SparkConf().setAppName("task").setMaster("local"); JavaSparkContext sc=new JavaSparkContext(conf); JavaRDD<String> data=sc.textFile(file,1); List<String> collect=data.collect(); Set<String> set=new HashSet<>(); for (int i = 0; i < collect.size(); i++) { String s=collect.get(i); String[] ss=s.split(", "); set.add(ss[2]); } Map<String,Integer> map=new HashMap<>(); for (String elem :set){ int number=0; for (int i = 0; i < collect.size(); i++) { String s=collect.get(i); String[] ss=s.split(", "); if (ss[2].equals(elem)){ number=number+1; } } map.put(elem,number); } for (String key: map.keySet()){ System.out.println((key + ": " + map.get(key).toString())); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
(4)查看运行结果,如下图所示:
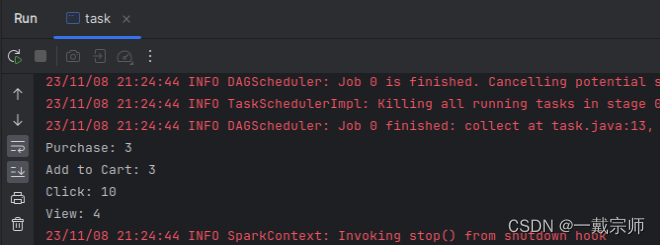
3、数据连接和格式化:
从用户信息数据集中读取用户ID和用户名称。将两个数据集根据用户ID进行连接,得到一个新的数据集,其中包含用户信息和相关用户行为记录。
时间能力有限,选择使用Java for循环连接打印简单粗暴解决问题,时间空间复杂度较高,对大量数据不友好,代码质量有限,仅供参考!
a.对连接后的数据集进行进一步处理,将用户信息和活动详情合并成一个格式化的字符串,例如:“用户名称 - 事件类型 - 事件内容”。
(1)通过如下操作将两份文件内容转化为SPARKRDD
JavaRDDdata_one=sc.textFile(file_one,1);
JavaRDDdata_two=sc.textFile(file_two,1);
(2)通过List将两份data转化为列表,并设置一个map变量映射两文件内容。然后设置一个总列表变量,存储连接替换后的文件内容。
(3)程序代码:
import org.apache.spark.api.java.*; import org.apache.spark.SparkConf; import java.util.*; public class task_one_3a { public static void main(String[] args) { String file_one="file:///home/XXX/Desktop/UserActivityData.txt"; String file_two="file:///home/XXX/Desktop/UserInfoData.txt"; SparkConf conf=new SparkConf().setAppName("task").setMaster("local"); JavaSparkContext sc=new JavaSparkContext(conf); JavaRDD<String> data_one=sc.textFile(file_one,1); JavaRDD<String> data_two=sc.textFile(file_two,1); List<String> collect_sum=new LinkedList<>(); List<String> collect_one=data_one.collect(); List<String> collect_two=data_two.collect(); Map<String,String> map_two=new HashMap<>(); for (int i = 0; i < collect_two.size(); i++) { String str_two=collect_two.get(i); String[] str=str_two.split(", "); map_two.put(str[0],str[1]); } for (int i = 0; i < collect_one.size(); i++) { String str_one=collect_one.get(i); String[] str=str_one.split(", "); String str_sum=""; String value=map_two.get(str[0]); str[0]=value; for (int j = 0; j < str.length; j++) { if (j==str.length-1){ str_sum=str_sum+str[j]; } else { str_sum=str_sum+str[j]+", "; } } collect_sum.add(str_sum); } for (int i = 0; i < collect_sum.size(); i++) { String str_sum=collect_sum.get(i); String[] s=str_sum.split(", "); System.out.println((s[0] + " - " + s[2] + " - " + s[3])); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
(4)查看运行结果,如下图所示:
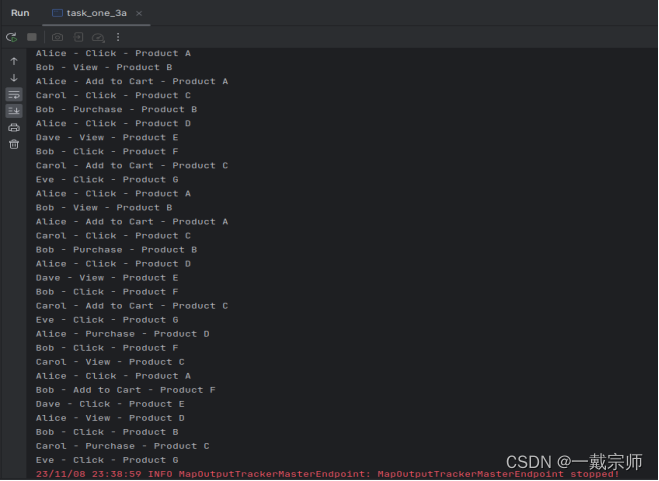
b. 输出格式化后的报告,包括每个用户的用户名称、事件类型和事件数量。
输出格式为:用户名称–事件类型–事件数量
(1)通过如下操作将两份文件内容转化为SPARKRDD
JavaRDDdata_one=sc.textFile(file_one,1);
JavaRDDdata_two=sc.textFile(file_two,1);
(2)通过List将两份data转化为列表,并设置一个map变量映射两文件内容。然后设置一个总列表变量,存储连接替换后的文件内容。
(3)设置一个集合变量,去除重复元素,后续对照集合内容计算相应事件数量。设置一个总列表,存储最终结果并输出。
(4)程序代码:
import org.apache.spark.api.java.*; import org.apache.spark.SparkConf; import java.util.*; public class task_one_3b { public static void main(String[] args) { String file_one="file:///home/XXX/Desktop/UserActivityData.txt"; String file_two="file:///home/XXX/Desktop/UserInfoData.txt"; SparkConf conf=new SparkConf().setAppName("task").setMaster("local"); JavaSparkContext sc=new JavaSparkContext(conf); JavaRDD<String> data_one=sc.textFile(file_one,1); JavaRDD<String> data_two=sc.textFile(file_two,1); List<String> collect_sum=new LinkedList<>(); List<String> collect_one=data_one.collect(); List<String> collect_two=data_two.collect(); Map<String,String> map_two=new HashMap<>(); for (int i = 0; i < collect_two.size(); i++) { String str_two=collect_two.get(i); String[] str=str_two.split(", "); map_two.put(str[0],str[1]); } for (int i = 0; i < collect_one.size(); i++) { String str_one=collect_one.get(i); String[] str=str_one.split(", "); String str_sum=""; String value=map_two.get(str[0]); str[0]=value; for (int j = 0; j < str.length; j++) { if (j==str.length-1){ str_sum=str_sum+str[j]; } else { str_sum=str_sum+str[j]+", "; } } collect_sum.add(str_sum); } Set<String> set=new HashSet<>(); Map<String,Integer> map=new HashMap<>(); for (int i = 0; i < collect_sum.size(); i++) { String s=collect_sum.get(i); String[] ss=s.split(", "); String ans=ss[0]+"--"+ss[2]; set.add(ans); } for(String elem:set){ int number=0; for (int i = 0; i < collect_sum.size(); i++) { String s=collect_sum.get(i); String[] ss=s.split(", "); String answer=ss[0]+"--"+ss[2]; if (answer.equals(elem)){ number=number+1; } } map.put(elem,number); } for (String key: map.keySet()){ System.out.println((key + "--" + map.get(key).toString())); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
(5)查看运行结果,如下图所示:
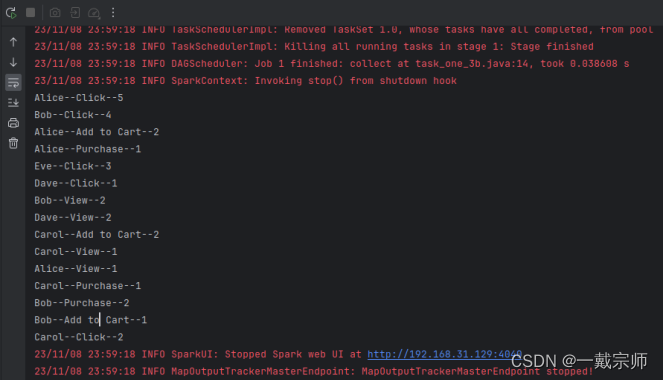
(二)分析校运动会数据。有一份运动会竞赛结果的数据集,其中包括比赛项目、班级、运动员、成绩和名次。使用 Spark SQL 进行分析。
运动会数据.txt
比赛项目, 班级, 运动员, 成绩, 名次 100米短跑, A班, 张三, 12.45, 1 100米短跑, B班, 李四, 12.62, 2 100米短跑, C班, 王五, 12.75, 3 100米短跑, A班, 李华, 12.82, 4 100米短跑, C班, 王明, 13.05, 5 200米短跑, A班, 张三, 21.81, 2 200米短跑, A班, 刘强, 21.10, 1 200米短跑, C班, 王五, 22.35, 3 200米短跑, C班, 王明, 22.45, 4 200米短跑, B班, 李四, 22.60, 5 跳高, A班, 张三, 1.85, 2 跳高, B班, 李四, 1.90, 1 跳高, C班, 王五, 1.75, 3 铅球, A班, 张三, 12.34, 1 铅球, C班, 王明, 11.92, 2 铅球, C班, 王五, 11.50, 3 跳远, A班, 张三, 7.05, 2 跳远, B班, 李四, 6.95, 1 跳远, B班, 李华, 6.80, 3
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
可通过spark编程实现,这里仅选择简单RDD交互式求解。代码质量有限,仅供参考!
为了方便使用交互式RDD及Spark SQL进行数据处理操作,首先将txt文件转化为csv文件,并将首行中文字段名修改为对应英文字段名。
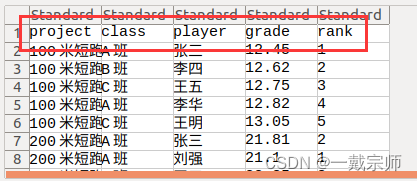
注意:查看csv文件时可能会出现中文乱码,可以通过选择不同编码方式找到合适的编码方式并记住该编码方式
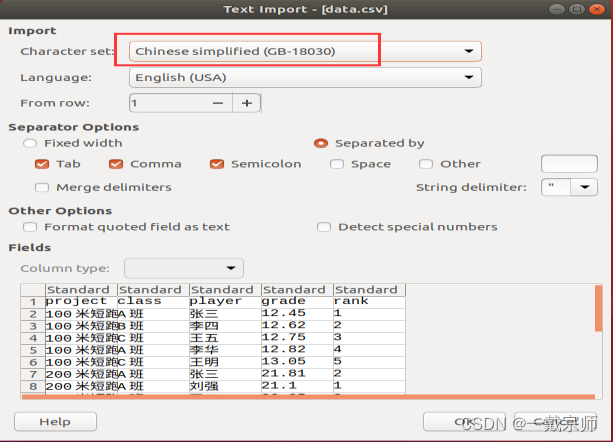
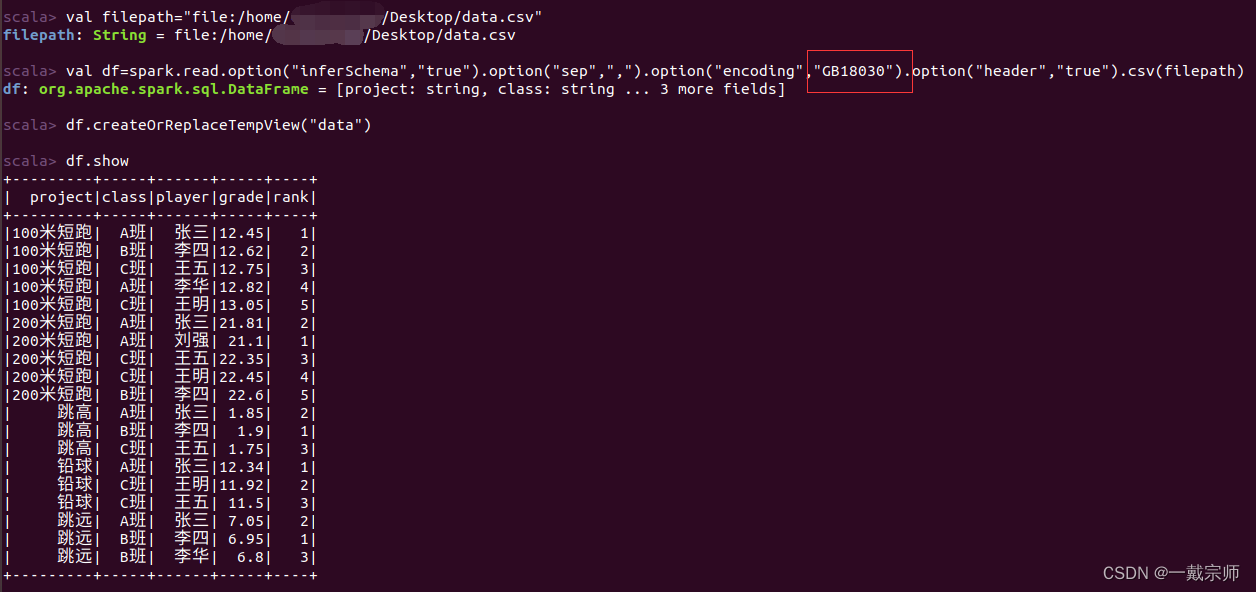
实验前提准备:
注意:需设置合适编码方式,否则可能会出现中文乱码
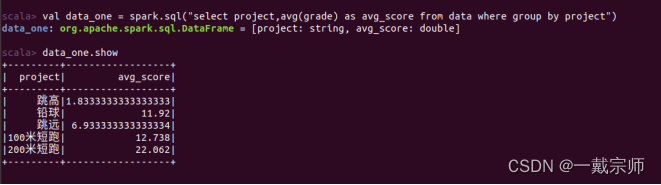
(1) 计算所有比赛项目的平均成绩。
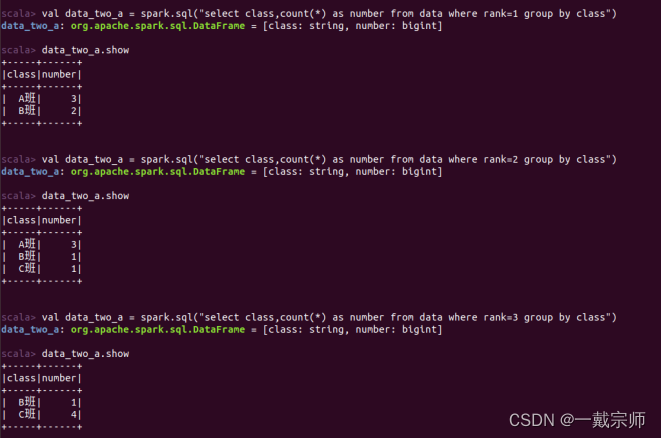
(2)统计每个班级的名次总数:
a. 统计每个班级获得的第一名、第二名和第三名的次数。
分别找出获得第一名、第二名和第三名的班级及次数。
或者按要求顺序依次分别求每个班获得第几名的次数。
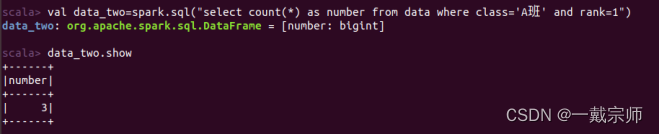
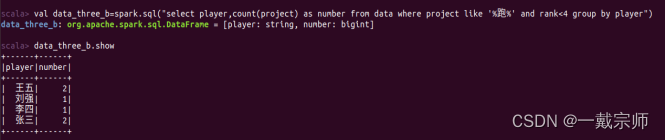
b. 列出获得第一名次数超过 2 次的班级。

(3)筛选并统计特定项目的成绩:
a. 筛选出所有田径项目(如100米短跑、200米短跑)的比赛结果。
田径项目种类很多,按照题意筛选出100米短跑、200米短跑的比赛结果。
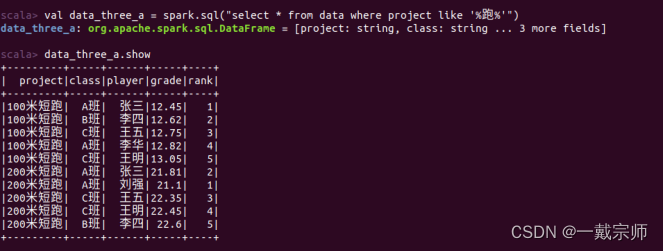
b. 统计在这些田径项目中获得前三名的个人数量。
先按照个人进行分组,然后找出在这些田径项目中有获得前三名的人及相应数量。