
- 1力扣138 - 复制带随机指针的链表【复杂链表的终极试炼】
- 2探索Franka Emika机器人 | 操作面板使用教程_franka mianban操作
- 3轻松获奖五一数学建模和蓝桥杯_五一建模三等奖好得吗
- 4扫雷(第一次不会炸死,点到不是雷的区域能延展开一片)_扫雷可能第一下就死吗
- 5三分钟了解什么是时序数据库
- 6jeecg快速启动(附带本地运行可用版本下载)
- 7windows 安装本地服务器 gitblit_gitblit-1.8.0.zip
- 8前端启动本地服务的四种方法,看完不会你锤我_前端启动命令
- 9Java-红黑树的实现_java 实现红黑树
- 10使用Cheat Engine(CE)来对植物大战僵尸进行逆向分析_ce植物大战僵尸冷却基址
大数据之Spark:Spark 基础_spark发展史
赞
踩
1、Spark 发展史
2009 年诞生于美国加州大学伯克利分校 AMP 实验室;
2014 年 2 月,Spark 成为 Apache 的顶级项目;
Spark 成功构建起了一体化、多元化的大数据处理体系。在任何规模的数据计算中, Spark 在性能和扩展性上都更具优势;
在 FullStack 理想的指引下,Spark 中的 Spark SQL 、SparkStreaming 、MLLib 、GraphX 、R 五大子框架和库之间可以无缝地共享数据和操作, 这不仅打造了 Spark 在当今大数据计算领域其他计算框架都无可匹敌的优势, 而且使得 Spark 正在加速成为大数据处理中心首选通用计算平台。
2、Spark 为什么会流行
原因 1:优秀的数据模型和丰富计算抽象;
Spark 产生之前,已经有 MapReduce 这类非常成熟的计算系统存在了,并提供了高层次的 API(map/reduce),把计算运行在集群中并提供容错能力,从而实现分布式计算。
虽然 MapReduce 提供了对数据访问和计算的抽象,但是对于数据的复用就是简单的将中间数据写到一个稳定的文件系统中(例如 HDFS),所以会产生数据的复制备份,磁盘的 I/O 以及数据的序列化,所以在遇到需要在多个计算之间复用中间结果的操作时效率就会非常的低。而这类操作是非常常见的,例如迭代式计算,交互式数据挖掘,图计算等。
认识到这个问题后,学术界的 AMPLab 提出了一个新的模型,叫做 RDD。RDD 是一个可以容错且并行的数据结构(其实可以理解成分布式的集合,操作起来和操作本地集合一样简单),它可以让用户显式的将中间结果数据集保存在内存中,并且通过控制数据集的分区来达到数据存放处理最优化.同时 RDD 也提供了丰富的 API (map、reduce、filter、foreach、redeceByKey…)来操作数据集。后来 RDD 被 AMPLab 在一个叫做 Spark 的框架中提供并开源。
简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的 API 提高了开发速度。
原因 2:完善的生态圈-fullstack
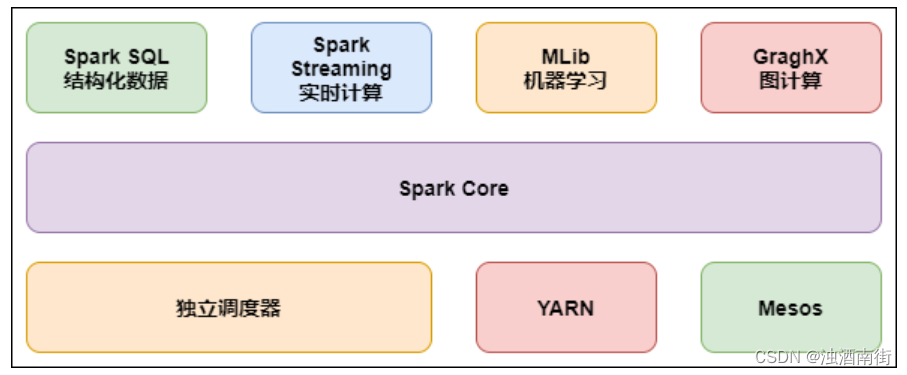
目前,Spark 已经发展成为一个包含多个子项目的集合,其中包含 SparkSQL、Spark Streaming、GraphX、MLlib 等子项目。
Spark Core:实现了 Spark 的基本功能,包含 RDD、任务调度、内存管理、错误恢复、与存储系统交互等模块。
Spark SQL:Spark 用来操作结构化数据的程序包。通过 Spark SQL,我们可以使用 SQL 操作数据。
Spark Streaming:Spark 提供的对实时数据进行流式计算的组件。提供了用来操作数据流的 API。
Spark MLlib:提供常见的机器学习(ML)功能的程序库。包括分类、回归、聚类、协同过滤等,还提供了模型评估、数据导入等额外的支持功能。
GraphX(图计算):Spark 中用于图计算的 API,性能良好,拥有丰富的功能和运算符,能在海量数据上自如地运行复杂的图算法。
集群管理器:Spark 设计为可以高效地在一个计算节点到数千个计算节点之间伸缩计算。
Structured Streaming:处理结构化流,统一了离线和实时的 API。
原因 3:Spark VS Hadoop
| Hadoop | Spark | |
|---|---|---|
| 类型 | 分布式基础平台, 包含计算, 存储, 调度 | 分布式计算工具 |
| 场景 | 大规模数据集上的批处理 | 迭代计算, 交互式计算, 流计算 |
| 价格 | 对机器要求低, 便宜 | 对内存有要求, 相对较贵 |
| 编程范式 | Map+Reduce, API 较为底层, 算法适应性差 | RDD 组成 DAG 有向无环图, API 较为顶层, 方便使用 |
| 数据存储结构 | MapReduce 中间计算结果存在 HDFS 磁盘上, 延迟大 | RDD 中间运算结果存在内存中 , 延迟小 |
| 运行方式 | Task 以进程方式维护, 任务启动慢 | Task 以线程方式维护, 任务启动快 |
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

