- 1linux清理内存
- 22024年【危险化学品经营单位安全管理人员】新版试题及危险化学品经营单位安全管理人员模拟考试题_如果用人单位没有统一购买劳动防护用品,应该按照
- 3vue3+vite+ts 使用webrtc-streamer播放海康rtsp监控视频_vue3 webrtc 播放
- 4【裂缝识别】基于matlab GUI路面裂缝识别(带面板)【含Matlab源码 1648期】
- 5ESP32+VSCODE环境搭建(ESP32S模块为例)_vscode esp32环境搭建
- 6使用VitePress搭建vue组件库文档_vitepress中文文档
- 7kafka session.timeout.ms 是指消费一条数据的时间?_阿里工程师分享:浅谈分布式发布订阅消息系统Kafka...
- 8八股文之linux中redis常用命令_linux redis 命令
- 9web 原型设计工具_适用于Web设计人员的13+种原型设计工具
- 10Python_Game之开心消消乐_python开心消消乐。
【OCR】paddle的OCR学习笔记_ocr csdn
赞
踩
1.OCR概念
OCR(Optical Character Recognition,光学字符识别)是计算机视觉重要方向之一。传统定义的OCR一般面向
扫描文档类对象,现在我们常说的OCR一般指场景文字识别(Scene Text Recognition,STR),主要面向自然
场景,如下图中所示的牌匾等各种自然场景可见的文字。
2.OCR技术挑战
OCR的技术难点可以分为算法层和应用层两方面。
2.1 算法层

2.2 应用层
1. 海量数据要求OCR能够实时处理。OCR应用常对接海量数据,我们要求或希望数据能够得到实时处理,模型的速度做到实时是一个不小的挑战。
2. 端侧应用要求OCR模型足够轻量,识别速度足够快。 OCR应用常部署在移动端或嵌入式硬件,端侧OCR应用一般有两种模式:上传到服务器 vs. 端侧直接识别,考虑到上传到服务器的方式对网络有要求,实时性较低,并且请求量过大时服务器压力大,以及数据传输的安全性问题,我们希望能够直接在端侧完成OCR识别,而端侧的存储空间和计算能力有限,因此对OCR模型的大小和预测速度有很高的要求
3 文本检测
文本检测的任务是定位出输入图像中的文字区域。

文本检测算法可以大致分为基于回归和基于分割的两大类文本检测算法。
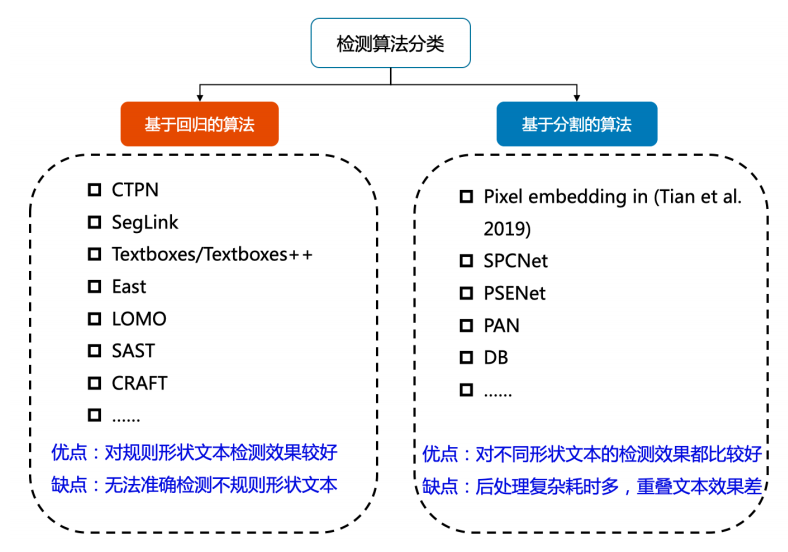
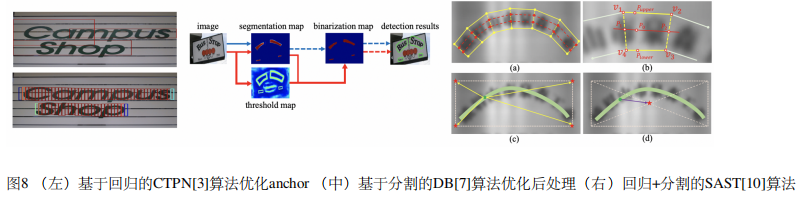
3.1 文本检测难点
1. 自然场景中文本具有多样性:文本检测受到文字颜色、大小、字体、形状、方向、语言、以及文本长度
的影响;
2. 复杂的背景和干扰;文本检测受到图像失真,模糊,低分辨率,阴影,亮度等因素的影响;
3. 文本密集甚至重叠会影响文字的检测;
4. 文字存在局部一致性,文本行的一小部分,也可视为是独立的文本;
3.2 文本检测方法
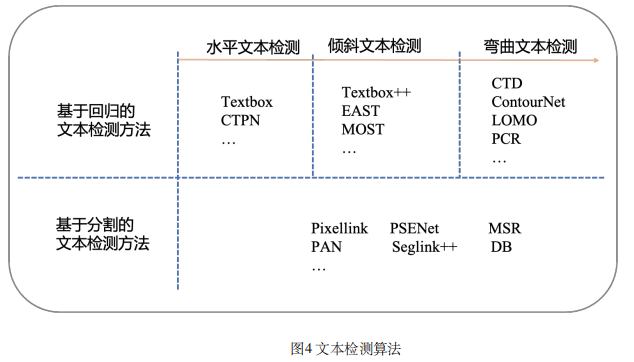
3.2.1 基于回归的文本检测
4. 文本识别
文本识别的任务是识别出图像中的文字内容,一般输入来自于文本检测得到的文本框截取出的图像文字区域。文本识别一般可以根据待识别文本形状分为规则文本识别和不规则文本识别两大类。规则文本主要指印刷字体、扫描文本等,文本大致处在水平线位置;不规则文本往往不在水平位置,存在弯曲、遮挡、模糊等问题。不规则文本场景具有很大的挑战性,也是目前文本识别领域的主要研究方向。
规则文本识别的算法根据解码方式的不同可以大致分为基于CTC和Sequence2Sequence两种,将网络学习到的序列特征转化为最终的识别结果的处理方式不同。基于CTC的算法以经典的CRNN[11] 为代表。
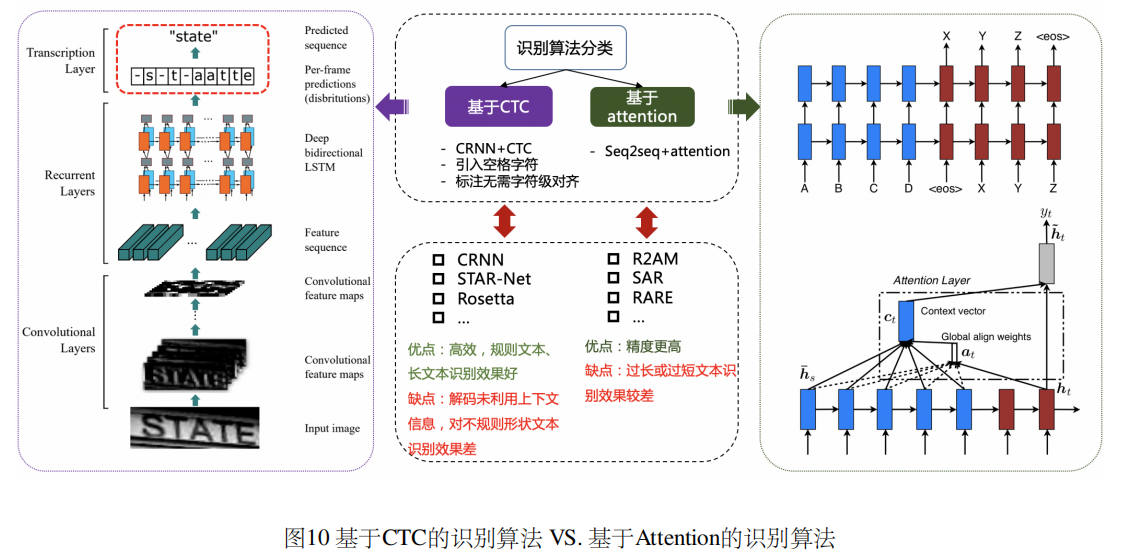
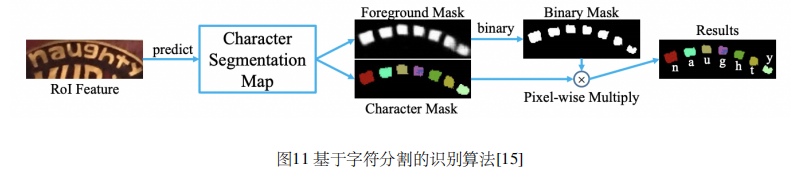
不规则文本的识别算法:STAR-Net,RARE,Transfomer。
5. 文档结构化识别
5.1 版面分析

5.2 表格识别
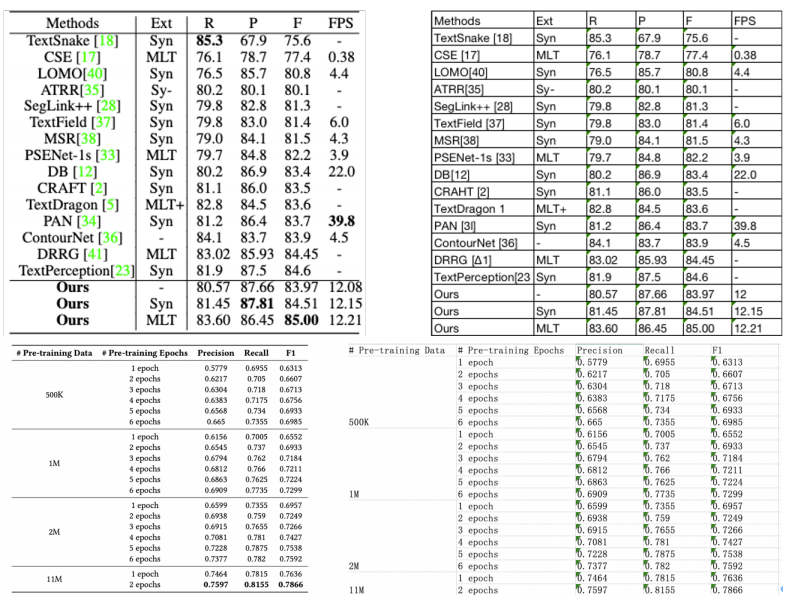
5.3关键信息提取
关键信息提取(Key Information Extraction,KIE)是Document VQA中的一个重要任务

KIE通常分为两个子任务进行研究:
• SER: 语义实体识别 (Semantic Entity Recognition),对每一个检测到的文本进行分类,如将其分为姓名,身份证。如下图中的黑色框和红色框。
• RE: 关系抽取 (Relation Extraction),对每一个检测到的文本进行分类,如将其分为问题和的答案。然后对每一个问题找到对应的答案。如下图中的红色框和黑色框分别代表问题和答案,黄色线代表问题和答案之间的对应关系。

6.产业实践难点