
热门标签
热门文章
- 1【北邮鲁鹏老师计算机视觉课程笔记】05 Hough 霍夫变换
- 2python多进程(multiprocessing)(map)_multiprocessing map
- 3图解朴素贝叶斯
- 4Sublime Text3配置node.js环境_sublime text3配置node环境
- 5设置linux开机自动运行Python脚本_linux开机自启时使用普通用户的python环境
- 6Resx 文件无效。未能加载 .RESX 文件中使用的类型 System.Collections.Generic.List`1请确保已在项目中添加了必需的引用。
- 7MAC系统Python环境搭建_mac python环境搭建
- 8Codeforces Round #700 (Div. 2)_codeforces round 700 (div. 2)
- 9蓝桥杯java技巧总结_蓝桥杯 技能升级——java
- 10文心大模型3.5勇夺三个冠军领跑,中文完爆GPT-4!国际权威报告7项满分「全班第一」...
当前位置: article > 正文
Kafka系列之:Kafka生产者和消费者
作者:weixin_40725706 | 2024-02-12 20:46:53
赞
踩
kafka生产者和消费者
Kafka系列之:Kafka生产者和消费者
一、Kafka生产者发送流程
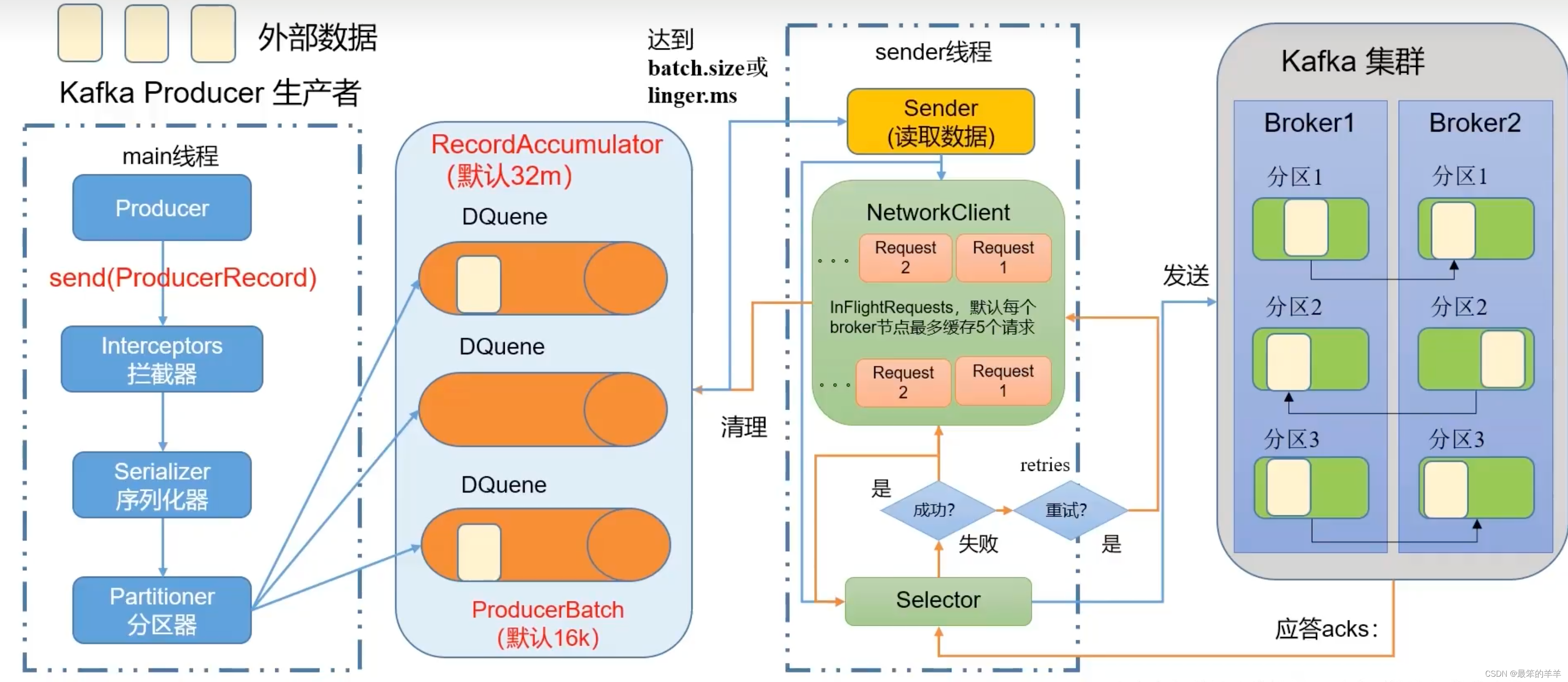
- batch.size:只有数据积累到batch.size之后,sender才会发送数据,默认16K。
- linger.ms:如果数据迟迟未达到batch.size,sender等待linger.ms设置的时间到了之后就会发送数据。单位ms,默认值是0ms,表示没有延迟。
- 0:生产者发送过来的数据,不需要等数据罗盘应答。
- 1:生产者发送过来的数据,Leader收到数据后应答。
- -1:生产者发送过来的数据,Leader和ISR队列里面的所有节点收齐数据后应答,-1和all等价。
二、提高生产者吞吐量
- batch.size&#
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/weixin_40725706/article/detail/78503
推荐阅读
- swagger:swagger 引入
[详细] 赞
踩
相关标签

