
- 1爬虫实战--人民网_://jhsjk.people.cn/testnew/result
- 22023新春祝福html代码,包你学会_怎么做新年祝福网址
- 3基于Java+SpringBoot制作一个论坛小程序_spingboot论坛小程序
- 4sklearn中的聚类算法K-Means_sklearn kmeans
- 5leetcode 315. 计算右侧小于当前元素的个数—(每日一难day7)_r程序请按要求返回一个新数组 counts。数组 counts 有该性质: counts[i]的值
- 6MySQL如何导出建表语句及如何建表_mysql批量导出建表语句
- 7搜索引擎工作过程_搜索引擎的工作过程有哪些
- 8react项目中使用sass总结_react sass
- 9Java 内存分析工具 Arthas 介绍与示例讲解_内存监控 arthus
- 10python——分治策略求最大值和最小值_分治算法最小值问题 算法分析ph
Kafka单节点安装部署_单节点kafka
赞
踩
本文主要是基于Kafka最新版kafka_2.12-2.8.0进行配置,这里ZooKeeper服务器的搭建主要是用kafka内置的ZooKeeper便捷脚本来快速简单地创建一个单节点ZooKeeper实例。
1、本地下载kafka文件,然后再把文件放到linux中
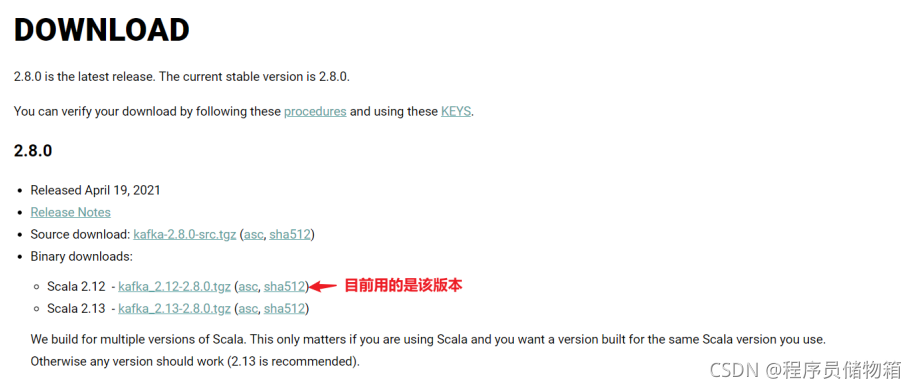
官网下载地址:https://kafka.apache.org/downloads
小提示:
小伙伴们看到kafka_2.12-2.8.0.tgz压缩包会很疑惑到底kafka的版本号是什么?
以kafka_2.12-2.8.0.tgz为例,2.12表示scala的版本,因为Kafka服务器端代码完全由Scala语音编写,”-“ 后面的2.8.0表示的kafka的版本信息,kafka的命名都是遵循这个规则的。但是Kafka新版客户端代码完全由Java语言编写,当然,不是Scala不行了,那是因为之前的Scala程序员隐退了,所以在社区找来了一批Java程序员来写Kafka新版客户端。
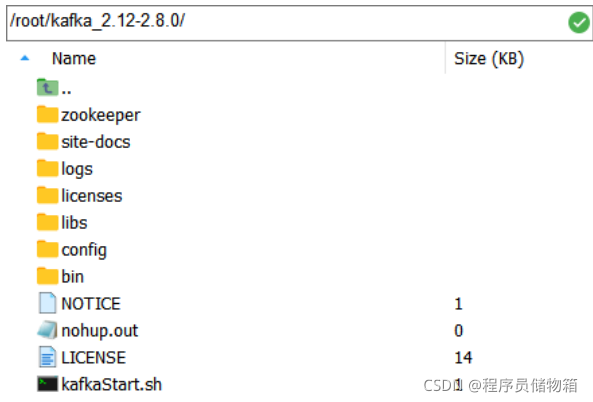
2、解压kafka_2.12-2.8.0.tgz文件
tar -xzf kafka_2.12-2.8.0.tgz
cd kafka_2.12-2.8.0
Kafka解压后,具体目录结构如下图所示:
Kafka中重要的四大配置文件如下:
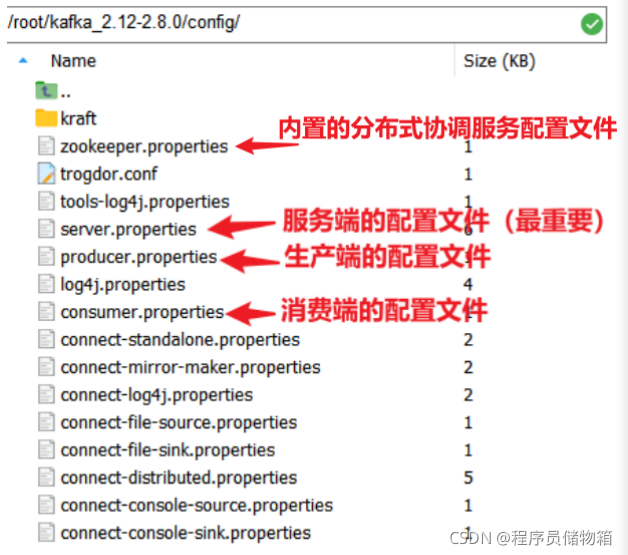
kafka最重要的配置文件server.properties内容详细说明:
- # 每个broker在集群中唯一存在,数值必须是正数;kafka根据id来识别broker机器,当该服务的地址发生变化时,broker.id没有变化,则不会影响consumers的消息情况。
- broker.id=0
-
- # broker server服务端口
- port=9092
-
- # broker的主机地址
- host.name=localhost
-
- # 套接字服务器侦听的地址
- listeners=PLAINTEXT://192.168.243.133:9092
-
- # 代理将向生产者和消费者公布主机名和端口。如果没有设置,
- # 如果已配置,它将使用“侦听器”的值。否则,它将使用该值从java.net.InetAddress.getCanonicalHostName()返回
- advertised.listeners=PLAINTEXT://192.168.243.133:9092
-
- # broker处理消息的最大线程数,一般情况下不需要去修改
- num.network.threads=3
-
- # broker处理磁盘IO的线程数,数值应该大于你的硬盘数
- num.io.threads=8
-
- # socket的发送缓冲区,socket的调优参数SO_SNDBUFF
- socket.send.buffer.bytes=102400
-
- # socket的接受缓冲区,socket的调优参数SO_RCVBUFF
- socket.receive.buffer.bytes=102400
-
- # socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖
- socket.request.max.bytes=104857600
-
- # kafka数据的存放地址,多个地址的话用逗号分割/root/kafka_2.12-2.8.0/log-1,/root/kafka_2.12-2.8.0/log-2
- log.dirs=/root/kafka_2.12-2.8.0/logs
-
- # 每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖
- num.partitions=1
-
- # 在启动时用于日志恢复和在关闭时刷新的每个数据目录的线程数。
- num.recovery.threads.per.data.dir=1
-
- # 组元数据内部主题“__consumer_offsets”和“__transaction_state”的复制因子
- # 对于除开发测试之外的任何其他内容,建议使用大于1的值以确保可用性,例如3。
- offsets.topic.replication.factor=1
- transaction.state.log.replication.factor=1
- transaction.state.log.min.isr=1
-
- # 日志文件因使用年限而有资格删除的最短使用年限
- log.retention.hours=168
-
- # topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖
- log.segment.bytes=1073741824
-
- # 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略
- log.retention.check.interval.ms=300000
-
- # 必须配置项,zookeeper集群的地址,可以是多个,以逗号分隔开,一般端口都为2181。hostname1:port1,hostname2:port2,hostname3:port3
- zookeeper.connect=192.168.243.133:2181
-
- # ZooKeeper的连接超时时间
- zookeeper.connection.timeout.ms=18000
-
- # ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大
- #zookeeper.session.timeout.ms=6000
-
- #ZooKeeper集群中leader和follower之间的同步实际时间
- #zookeeper.sync.time.ms =2000
-
- #随着新成员加入组,重新平衡将进一步延迟的时长,默认最大延迟为3秒,这里将其覆盖为0,因为这有助于为开发和测试提供更好的开箱即用体验。
- #但是,在生产环境中,默认值3秒更合适,因为这将有助于避免在应用程序启动期间进行不必要且可能代价高昂的重新平衡。
- group.initial.rebalance.delay.ms=0

注意:测试kafka时(比如创建主题)用的IP地址和端口要跟listeners的一致。
3、启动ZooKeeper和Kafka服务器
(1)启动ZooKeeper服务器,要一直保存连接状态(这里用kafka包内的便携脚本快速创建一个单节点ZooKeeper实例)
bin/zookeeper-server-start.sh config/zookeeper.properties
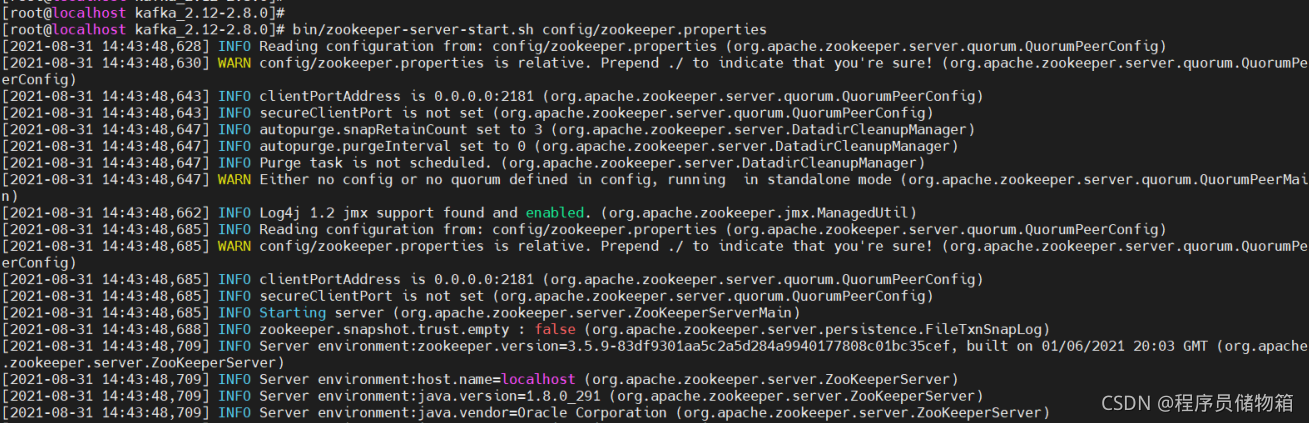
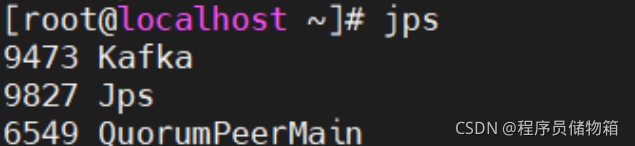
测试Zookeeper服务是否开启,重新开一个连接。输入jps会发现多了一个进程

(2)启动kafka服务器,要一直保存连接状态(在新开的连接上启动)
bin/kafka-server-start.sh config/server.properties
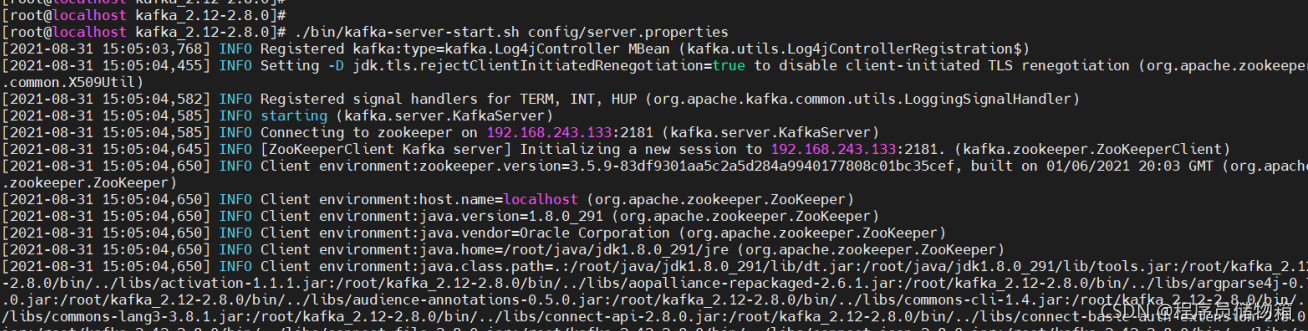
测试Kafka服务是否启动,在重新开一个连接,输入jps查看当前运行进程
启动时容易出现的问题:
1)默认情况下,进程是在前台运行的,这时就把shell操作框给占据了,一旦Ctrl+c就会关闭掉服务,所以上面在启动服务器后为保存连接状态,就一直在新开连接。但是我们希望将其在后台启动,可以在启动ZooKeeper和kakfa服务器命令后面加一个‘ &’实现这个目的。
比如:bin/zookeeper-server-start.sh config/zookeeper.properties &
这时候Ctrl+c,也不用担心服务器的进程关闭了,可以接着进行操作!
2)启动zookeeper和kafka服务器一定要按顺序启动,否则kafka服务器会报错。
下面通过杀死已存在的zookeeper服务器进程,来查看kafka服务器的报错情况。其实再重启zookeeper服务器,kafka服务器就会自动连上了。
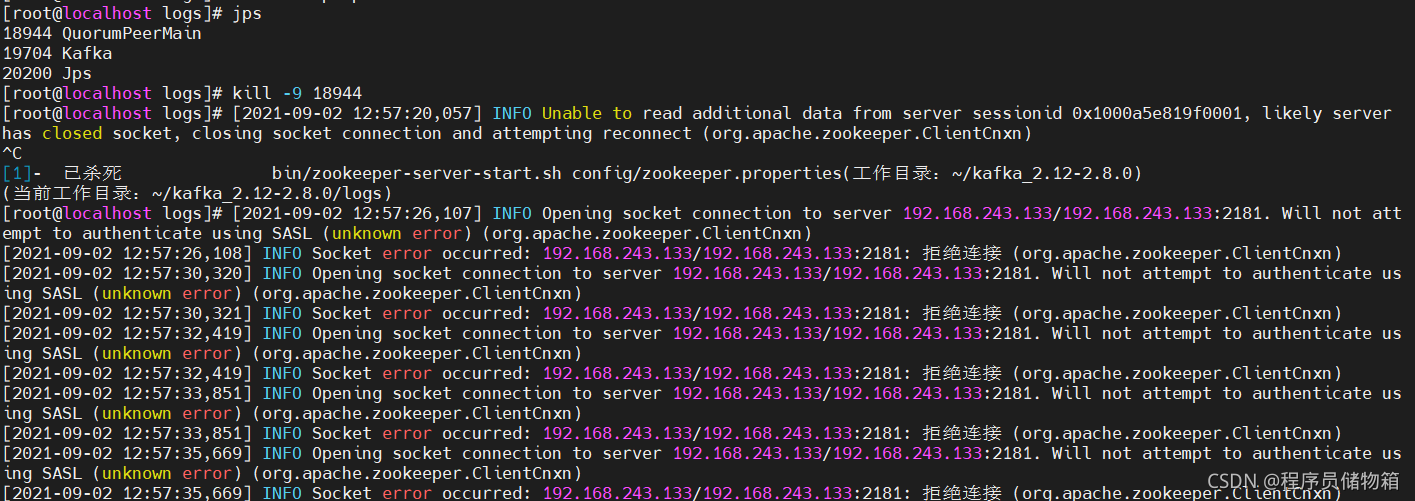
3)在我第二次启动Kafka服务时候报错The broker is trying to join the wrong cluster. Configured zookeeper.connect may be wrong.(翻译下:代理正在尝试加入错误的群集。配置的zookeeper.connect可能错误。)
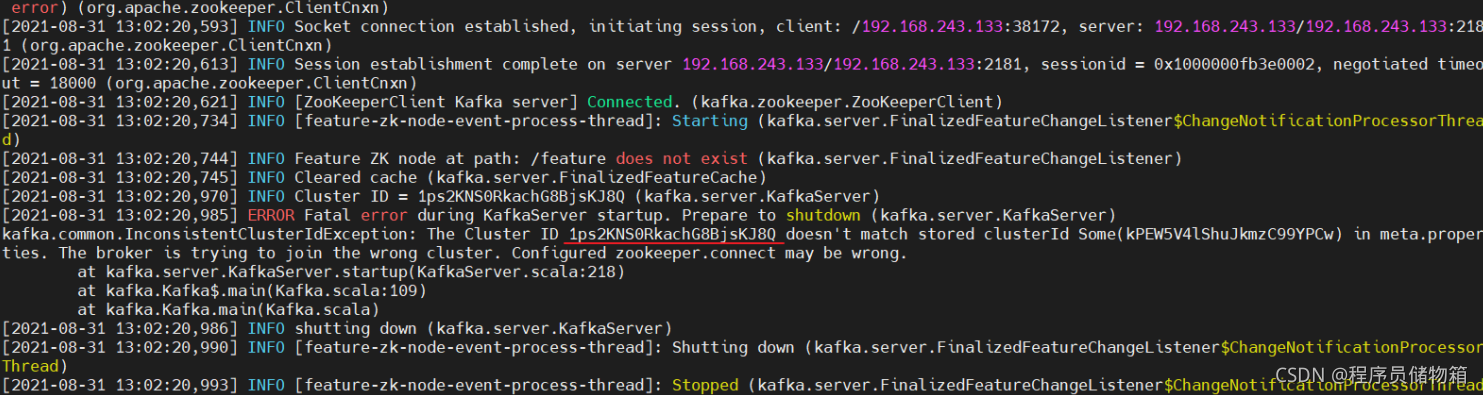
另一种查看日志方式:报错的日志也可以在server.log文件中查看。
查看kafka配置文件server.properties,找配置的日志目录具体地址
vim server.properties
去到/root/kafka_2.12-2.8.0/logs下的server.log日志文件中查看报错问题:
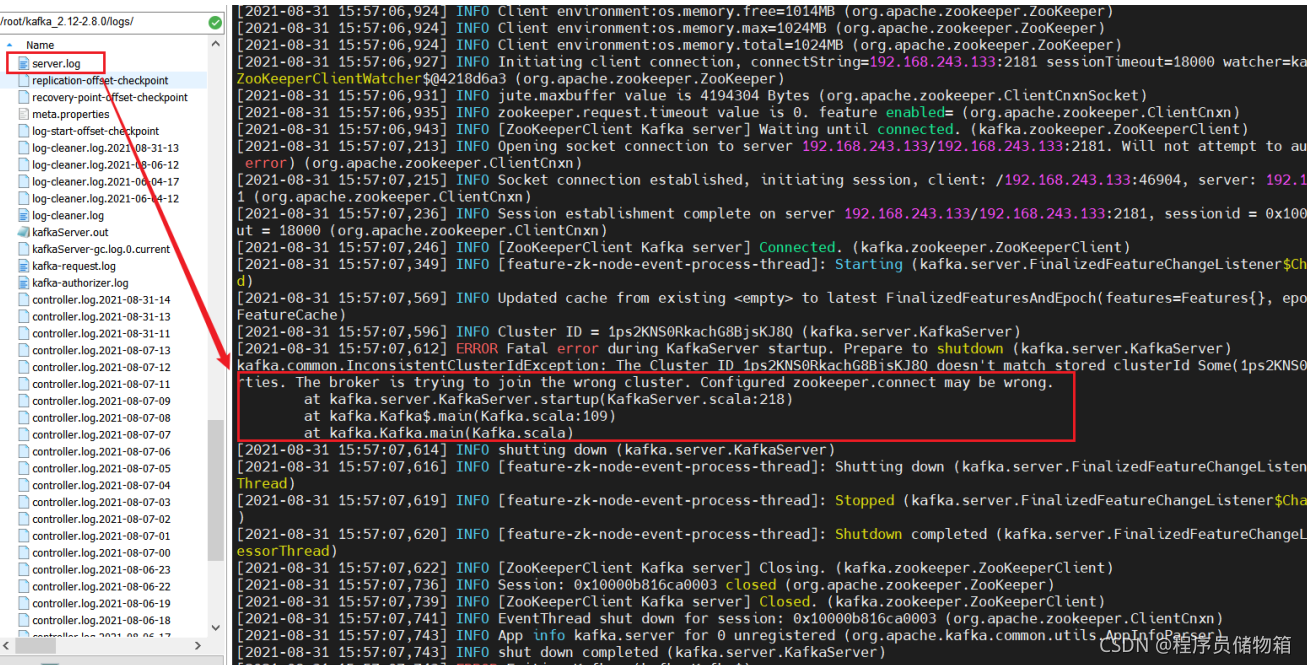
具体解决办法是:
打开该日志目录(/root/kafka_2.12-2.8.0/logs)下的meta.properties文件,更新cluster.id=【报错的Cluster ID】,并保存文件。
vim meta.properties
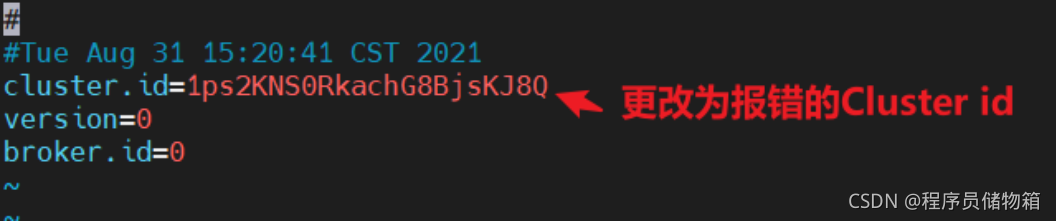
Ctrl+i启动修改模式,修改完Cluster id后,点击Esc退出修改,输入“:wq!”保存修改。
接着重启Kafka服务器,就不会再报这个问题了!(我几次重启时Kafka都会报错这个问题,额......感觉气到了)
4、创建一个topic(接下步骤在新开的连接上)
bin/kafka-topics.sh --create --bootstrap-server 192.168.243.133:9092 --replication-factor 1 --partitions 1 --topic TEST

5、查看已经创建的topic
bin/kafka-topics.sh --list --bootstrap-server 192.168.243.133:9092

6、生产者发送消息到主题TEST
bin/kafka-console-producer.sh --broker-list 192.168.243.133:9092 --topic TEST

7、消费者拉取主题TEST中的消息(重新再开一个连接)
bin/kafka-console-consumer.sh --bootstrap-server 192.168.243.133:9092 --topic TEST --from-beginning


- swagger:swagger 引入
[详细] 赞
踩

