
- 1大数据最全Spark分区 partition 详解_spark partition(2),2024年最新大数据开发插件化主流框架和实现原理_spark.sql.partitionprovider
- 2openlayers 结合echart 完成交互事件_layer echart
- 3SpringCloud Alibaba微服务-- Sentinel的使用(保姆级)_alibaba sentinel
- 4微信小程序 自定义组件_微信小程序 组件内部修改conf数据,然后通过this.selectcomponent 获取组件实例
- 5Python自动化办公:读取Excel数据并批量生成合同
- 6Robotstudio机器人系统解压,创建失败的解决方法_robotstudio添加不了机器人系统
- 7字节跳动超高难度三面java程序员面经_武汉字节java面试有多难
- 8AI百题--第十天突击题_为什么是根号dk
- 9MD5和base64加密_base64 md5
- 10git的取消commit_eclipse git 显示有三个要提交的,怎么取消
英伟达的这款GPU太强了!
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
今年 3 月 21 日 - 24 日举办的 NVIDIA GTC 2022 大会可谓是亮点十足。NVIDIA 不仅一口气更新了 60 多个 SDK 应用程序,继续加大在 Omniverse、机器人平台、自动驾驶和量子计算等领域中的布局 ,还重磅发布了基于全新 Hopper 架构的 H100 GPU!
Amusi 听说 H100 性能炸裂,应用在 AI 领域上会有数倍的性能提升。那么本文就带大家看看这一波刷屏的 Hopper 架构和首款产品 H100 GPU 究竟有多强!据了解,NVIDIA H100 将于 2022 年第三季度起开始供货,也期待能尽快上手实测一波~

图1 NVIDIA H100 GPU
首款 Hopper 架构 GPU:H100
NVIDIA 每代 GPU 的架构命名都是有出处的,今年 Hopper 架构是以计算机科学家先驱 Grace Murray Hopper 的姓氏命名(Hopper 为夫姓)。她是世界最早一批的程序员之一,也是最早的女性程序员之一,而且创造了现代第一个编译器 A-0 系统,以及第一个高级商用计算机程序语言 “COBOL” ,还被誉为 “COBOL 之母” ,据说是世界上第一个发现【bug】的人,debug 这个词也因此诞生。

图2 1960年在 UNIVAC 键盘前的 Hopper
一图看尽 Hopper H100 GPU 上的六大项突破性创新:

图3 H100 上的六大项突破性创新
集成超过 800 亿个晶体管(台积电 4nm 工艺)
Transformer Engine
第二代 MIG:多实例 GPU(Multi-Instance GPU)
NVIDIA 机密计算(Confidential Computing)
第四代 NVLink
全新 DPX 指令
NVIDIA H100 GPU 硬件上的参数太炸裂,比如有:英伟达定制的台积电4nm工艺、单芯片设计、800 亿个晶体管、132 组 SM、16896 个 CUDA Core,528 个第四代Tensor Core,3TB/s 的 HBM3 显存等等。
特别值得提一下:4 nm 工艺使得 H100 时钟频率速度增加了 1.3 倍,SM 数量增加了 1.2 倍。
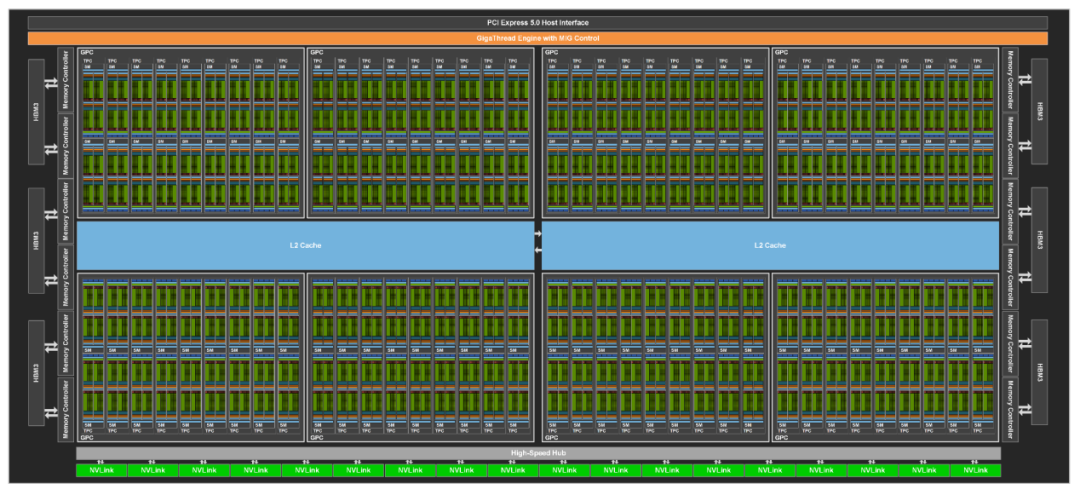
图4 GH100 Full GPU with 144 SMs
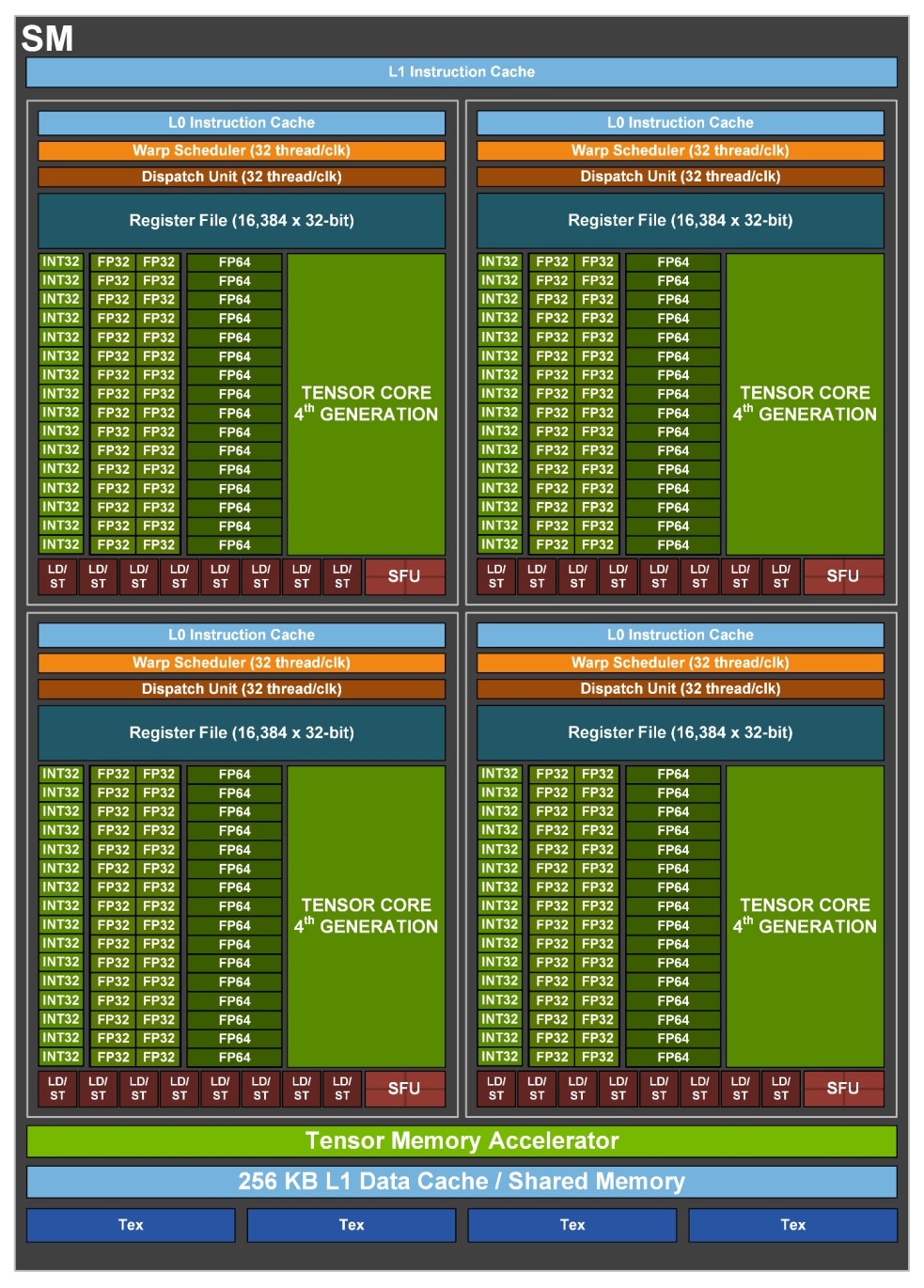
图5 GH100 Streaming Multiprocessor (SM)
更多硬件参数这里就不展开说了,感兴趣的同学可以直接看 NVIDIA H100 白皮书深入了解。这里重点介绍 NVIDIA H100 GPU 在 AI 上的性能突破。
与上一代 A100 相比,H100 的 AI 性能更加强大。在计算机视觉、自然语言处理等领域,H100 比 A100 的性能增强数倍,部分数据如下图所示:
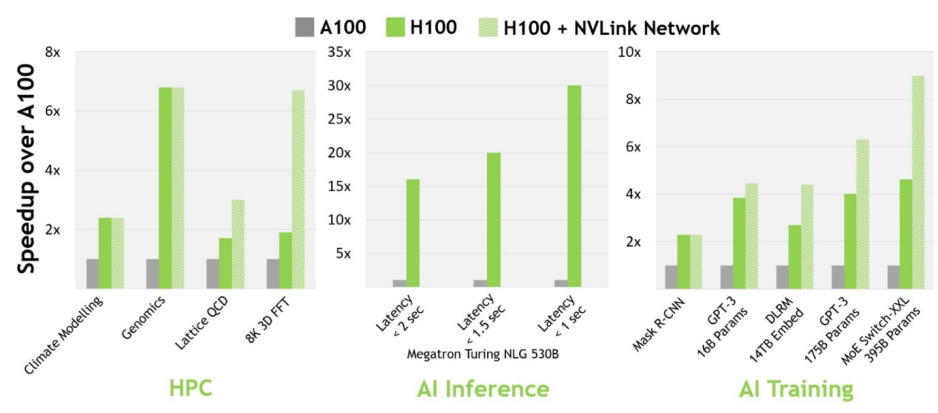
图6 H100 实现 AI 和 HPC 突破
第四代 Tensor Core Architecture
第四代 Tensor Core 是 H100 AI 性能提升的一大神器!Tensor Core 是用于矩阵乘积和累加(MMA)数学运算的专用高性能计算核心 ,可为人工智能(AI)高性能计算(HPC)提供突破性的性能加速。第一代 Tensor Core 首次出现在 Volta 架构,从 Volta 到 Turing、Ampere 再到2022 最新的 Hopper 架构,Tensor Core 已经发展到了第四代。
H100 GPU 中特别加入了 FP8 Tensor Core 来加速 AI 训练和推理。与上一代 A100 GPU(Ampere 架构)上的 FP16 相比,FP8 精度可提供高达 6 倍的性能。

图7 H100 FP8 和 A100 FP16
FP8 Tensor Core 支持 FP32、FP16 累加器和两种新的 FP8 输入类型:E4M3 和 E5M2。E5M2 是与 FP16 保持相同的动态范围,但精度大大降低,而 E4M3 精度稍高但动态范围较小。Tensor Core 中的 FP8 matrix 可以累加成 FP16 或 FP32,并且根据神经网络中的偏差,进一步输出转换为 FP8、BF16、FP16 或 FP32 格式。
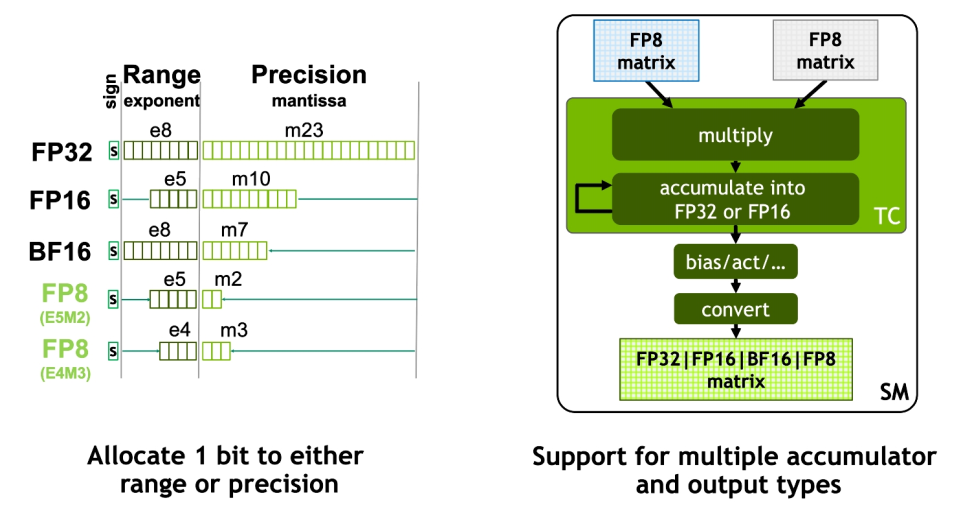
图8 Hopper FP8
除了新增的 FP8 有恐怖的性能之外,第四代 Tensor Core 还整体加强了 FP16、FP64、TF32 和 INT8 等 Tensor Core。基本都是 3 倍及以上的性能提升,具体参数如下图所示(太强了):
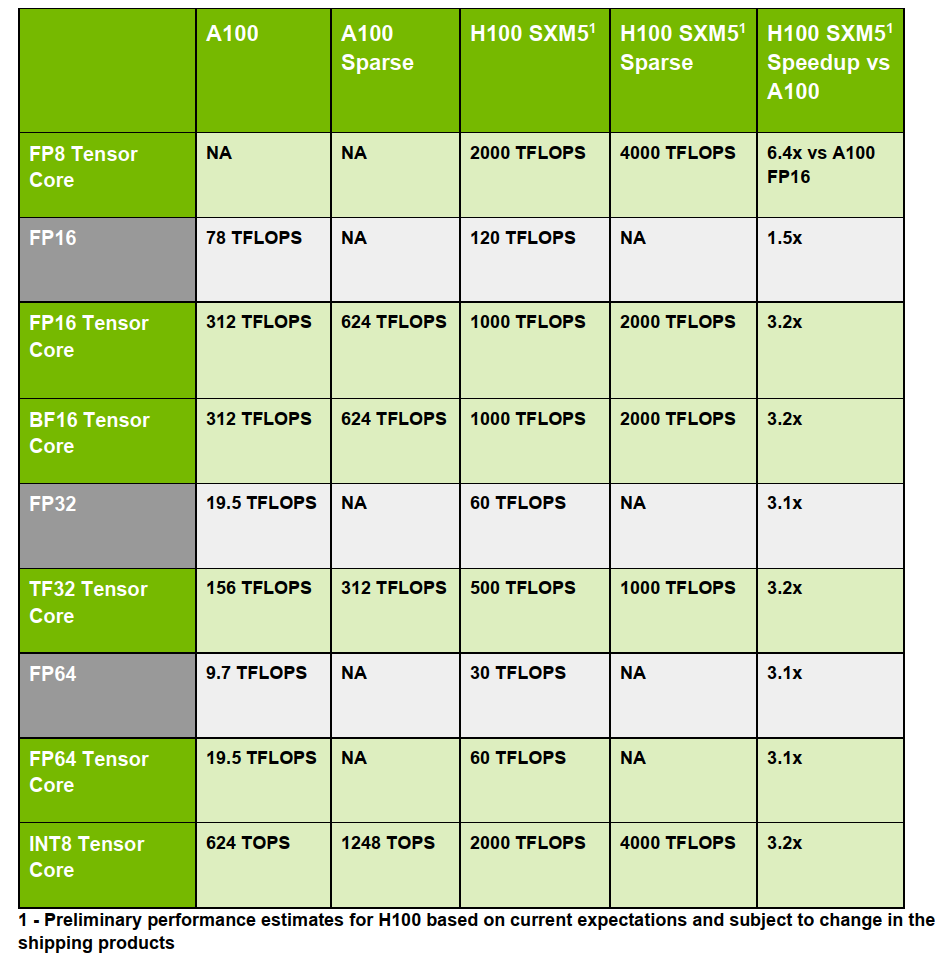
图9 H100 和 A100 Tensor Core对比
Transformer Engine
这里要重点聊聊 NVIDIA H100 最新推出的 Transformer Engine!
先介绍一下 Transformer 是什么来头?AI 领域的人应该都知道,但还是要强调一下其重要性(不然也不会特别推出定制版的 Engine)。
2017 年,Transformer 横空出世!快速席卷并统治了自然语言处理(NLP)领域;接着 2020 年,Vision Transformer 横空出世,成功将 Transformer 应用到了计算机视觉(CV)领域,目前也是屠榜了 CV 领域中的很多方向,比如目标检测、图像分割、目标跟踪等;而且 Transformer 在音频/语音、药物发现等领域也都有广泛应用。
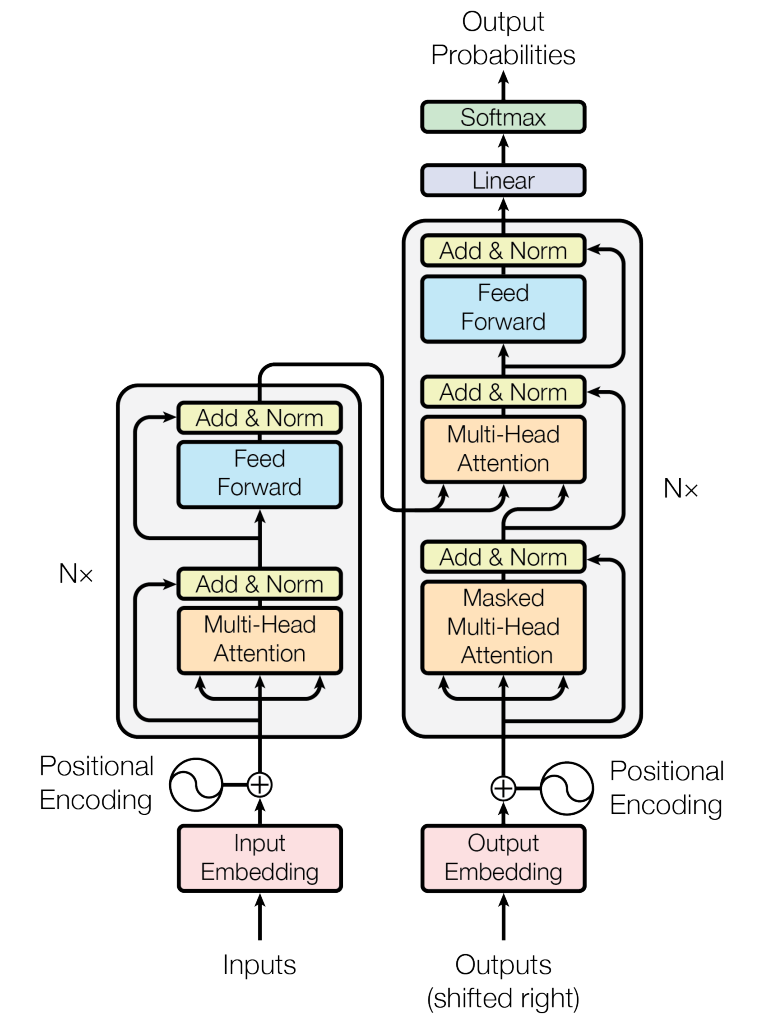
图10 Transformer 架构
可见 Transformer 已经成为 AI 领域中举足轻重的通用模型,但由于在过去五年中,Transformer 模型大小的增长速度比大多数其他 AI 模型快得多,每两年接近增长 275 倍,所以 Transformer 网络的训练时间会很长,而且部署应用也会因为算力原因受到很大限制。
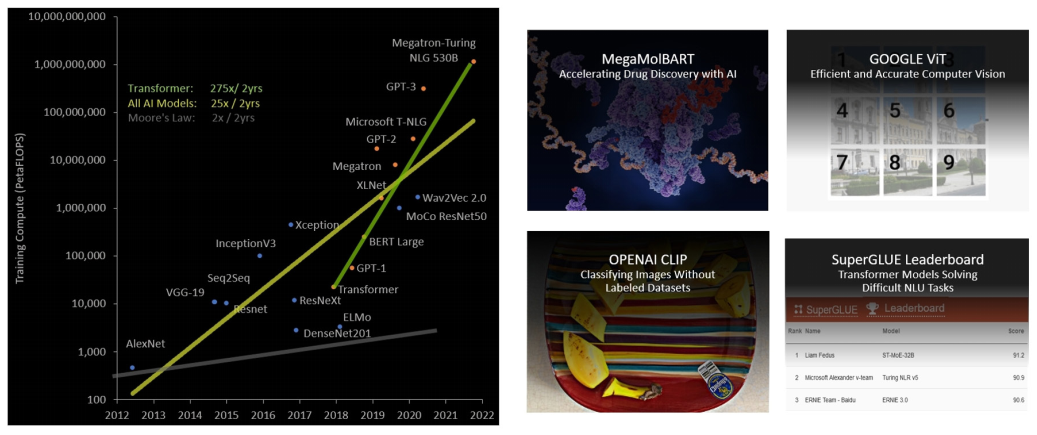
图11 Transformer 模型大小呈指数增长
为此,NVIDIA 特别打造了 Transformer Engine:一项由软件和定制的 Hopper Tensor Core 硬件相结合的专门用于加速 Transformer 模型计算的技术。Hopper Tensor Core 能够利用混合的 FP8 和 FP16 精度格式,减少内存使用,大幅加速 Transformer 训练的 AI 计算,同时保持准确性。
具体工作原理:在 Transformer 模型的每一层,Transformer Engine 都会分析 Tensor Core 产生的输出值的统计数据。了解了接下来会出现哪种类型的神经网络层以及它需要什么精度后,Transformer Engine 还会决定将 Tensor 转换为哪种目标格式,然后再将其存储到内存中。FP8 的范围比其他数字格式更有限。为了优化使用可用范围,Transformer Engine 还使用从 Tensor 统计中计算出的缩放因子(Scaling Factors)动态地将 Tensor 数据缩放到可表示的范围内。因此,每一层都在会其所需的范围内运行,并以最佳方式加速。
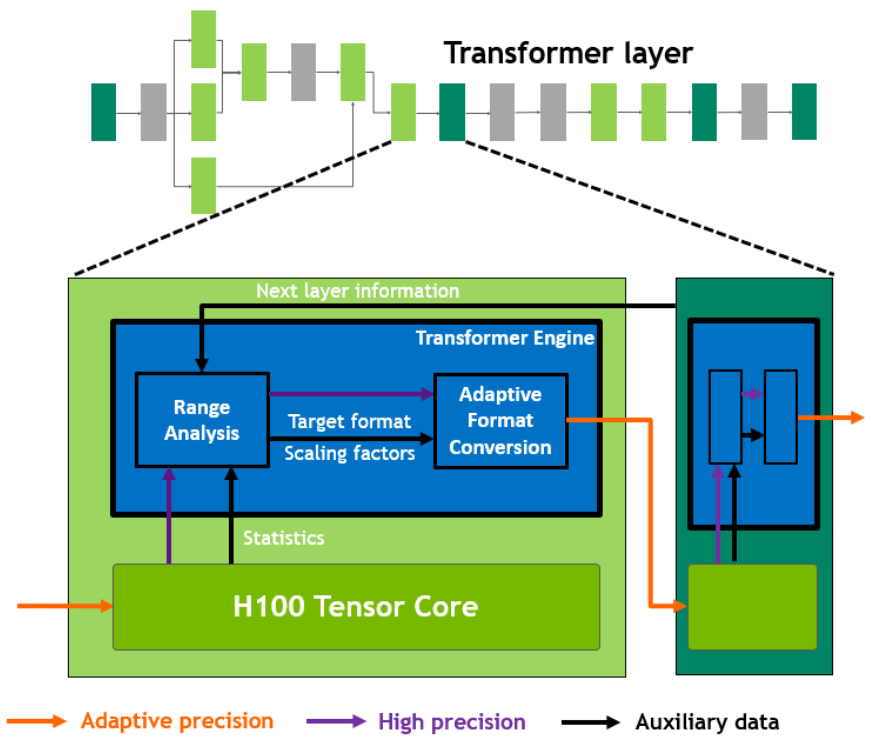
图12 Transformer Engine 概念操作
借助全新 Transformer Engine 和基本硬件参数提升使 H100 在大型语言模型上的 AI 训练速度提高了 9 倍,AI 推理速度提高了 30 倍。
下面举几个例子,1750 亿参数的 GPT-3 训练时间从 5 天缩短至 19 个小时;3950 亿参数的混合专家模型训练时间从 7 天 缩短至 20 个小时。
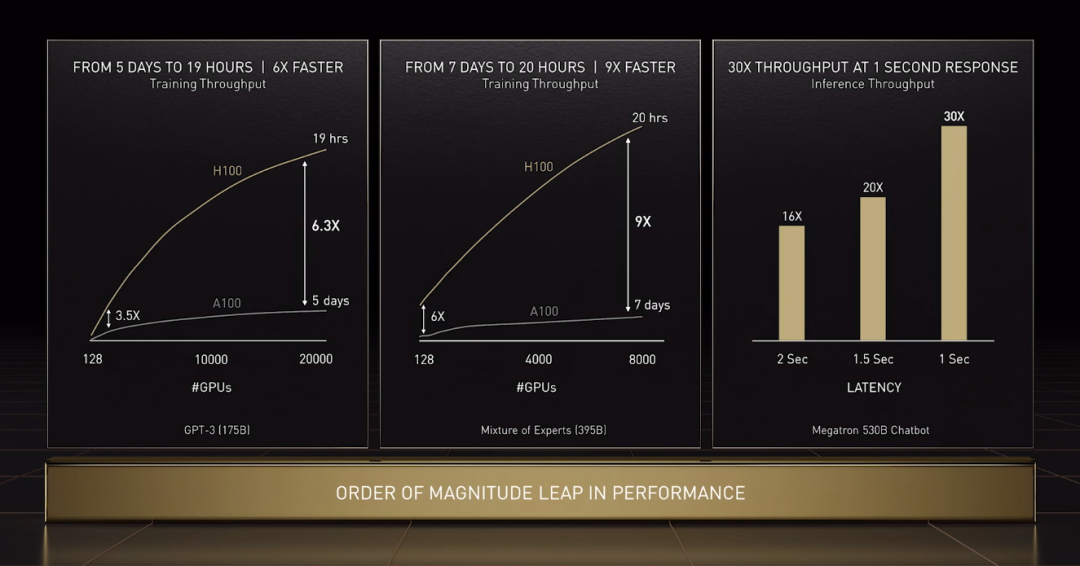
图12 GPT-3/MoE/Megatron
上面介绍的第四代 Tensor Core 和 Transformer Engine 对于 H100 的计算性能(Compute Performance)提升尤为重要,如下图所示:
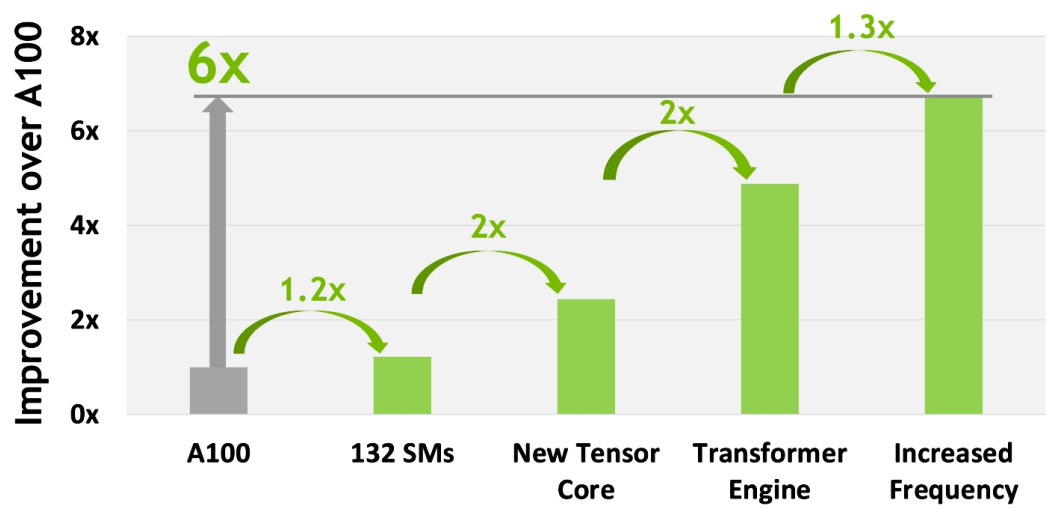
图13 H100 计算性能改进
DPX 指令
NVIDIA H100 新推出的 DPX 指令可以将动态规划(Dynamic Programming)的性能提高多达 7 倍,可大大加快疾病诊断、物流路径优化和缩短图分析的时间。
下图展示的两个示例包括用于基因组学和蛋白质测序的 Smith-Waterman 算法,以及用于为机器人车队在动态仓库环境中寻找最佳路线的 Floyd-Warshall 算法。
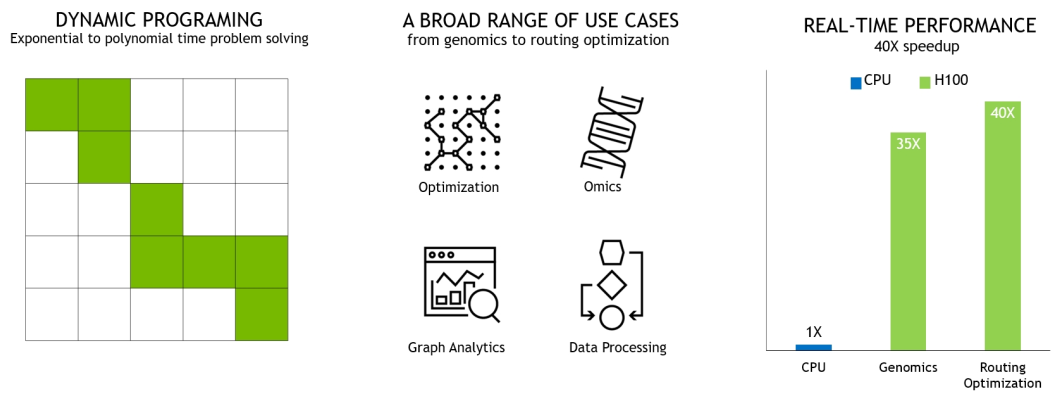
图14 DPX 指令加速动态规划

图15 用于基因组测序的 Smith-Waterman 算法
第四代 NVLink 和 第三代 NVSwitch
NVLink 是 NVIDIA 开发的一种高带宽、节能、低延迟、高速 GPU 互连技术,能够实现显存和性能扩展。

图16 NVIDIA NVLink
NVIDIA NVLink 第四代互连技术与上一代 NVLink 相比,通信带宽增加了 50%。H100 包含 18 条第四代 NVLink 链路,可提供 900 GB/秒的总带宽,是 PCIe Gen 5 带宽的 7 倍。
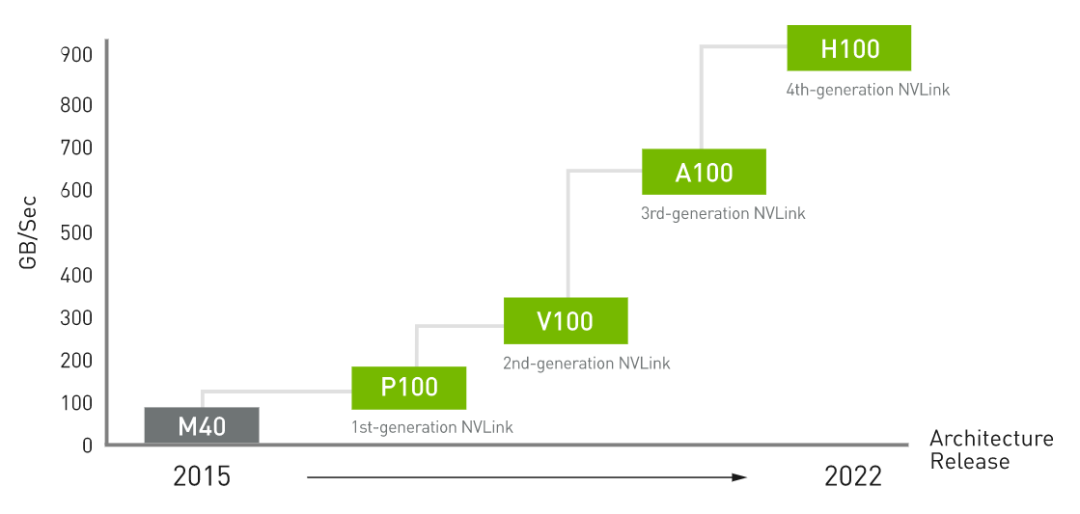
图17 NVLink 性能改进
第三代 NVSwitch 技术包括位于节点内部和外部的交换机,用于连接服务器、集群和数据中心环境中的多个 GPU。每个 NVSwitch 提供 64 个第四代 NVLink 链路端口,以加速多 GPU 连接。总交换机吞吐量从上一代的 7.2 Tbits/sec 增加到 13.6 Tbits/sec。新的第三代 NVSwitch 技术并配有 NVIDIA SHARP 引擎,可用于网络内归约和组播加速。
新的 NVLink Switch System
为加速大型 AI 模型,可以将第四代 NVLink 和第三代 NVSwitch 结合以构建 NVLink Switch System networks。最多支持连接 256 个 H100 GPU(全新的NVIDIA SuperPOD 因此而生),实现 57.6 TB/s 的多对多总带宽。而且新的 NVLink Switch System 在针对一些大型计算工作负载任务,比如需要在多个GPU加速节点上进行模型并行化时,能够通过互联调整负载,可以再次提高性能。
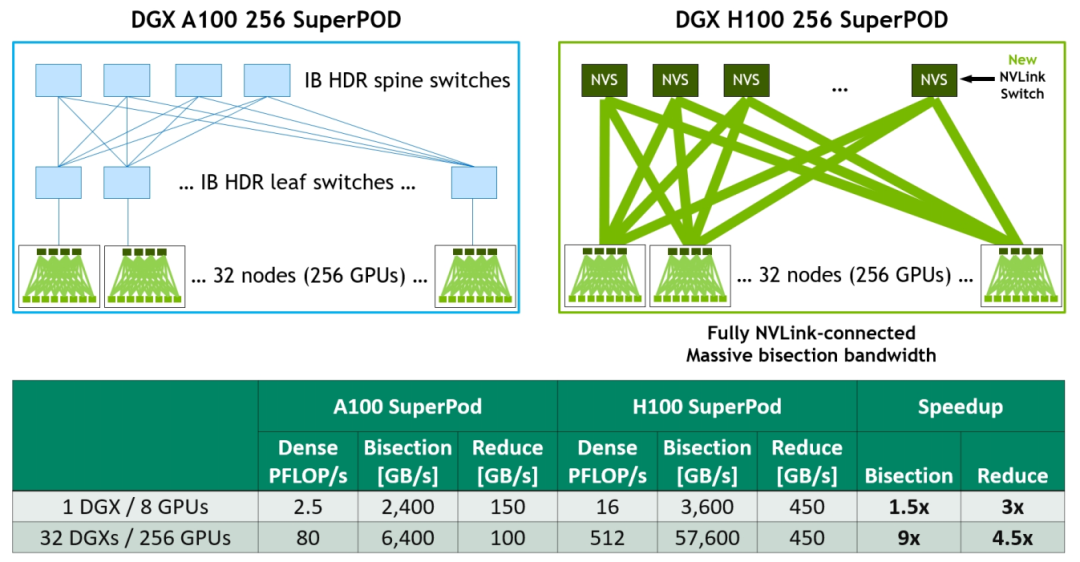
图18 DGX A100 vs DGX H100 32-node, 256 GPU NVIDIA SuperPOD Comparison
下面再介绍几款以 H100 为"基本单位" 构建的大型 AI 计算产品。
NVIDIA DGX H100
NVIDIA DGX H100 是世界上第一个专用 AI 基础架构的第四代产品 ,也是一个专用于训练,推理和分析的通用高性能 AI 系统,集成了 8 个 NVIDIA H100 GPU, 拥有总计 6400 亿个晶体管,总 GPU 显存高达 640GB ,可满足自然语言处理、深度学习推荐系统和医疗健康研究等大型工作负载的需求。

图19 DGX H100
NVIDIA DGX H100 SuperPOD
专为企业级 AI 设计的全新 DGX SuperPOD !预计 2022 年底即将推出!
DGX SuperPOD 由 32 个 DGX H100 组成,被称为“可扩展单元”,共集成了 256 个 H100 GPU,通过基于第三代 NVSwitch 技术的新的第二级 NVLink 交换机连接,提供前所未有的 FP8 稀疏 AI 计算性能的 exaFLOP 。非常适合扩展基础架构,支持更大规模、更复杂的 AI 工作负载,例如使用 NVIDIA NeMo 的大型语言模型和深度学习推荐系统。

图20 NVIDIA DGX H100 SuperPOD
NVIDIA Eos 全球最快 AI 超算
NVIDIA Eos 是目前世界上最快的人工智能超算(AI Supercomputer),共有 576 个 DGX H100 系统,4,608 个 H100 GPU。NVIDIA Eos 预计将提供 18 exaflops 的 AI 计算性能,比目前世界上最快的系统日本的 Fugaku 超算快 4 倍的 AI 处理速度。

图21 NVIDIA Eos
总结和展望
基于全新 Hopper 架构的 H100 GPU 算力再创新高!最新换代的 TensorCore,最新推出的 FP8、Transformer Engine 等等创新都将助力 H100 在 AI 上的性能提升。
而且 H100 GPU 上面还有一些专项的增强,比如专门针对 Video 解码的 NVDEC(支持 H264 / HEVC / VP9 等格式)和专门针对 JPEG 解码的 NVJPG (JPEG) Decode。NVDEC 和 NVJPG 可以大大提高计算机视觉数据在训练和推理过程中的处理性能(高速吞吐量)。H100 相较于上一代 A100 ,NVDEC 和 NVJPG 的解码吞吐能力提高了2倍以上。
Amusi 相信 H100 GPU 可以进一步推进 AI、元宇宙、自动驾驶等领域的发展!也期待更优秀的相关衍生产品和应用!

整理不易,请点赞和在看![]()

