
- 1Cohere继Command-R+之后发布大模型Aya-23,性能超越 Gemma、Mistral 等,支持中文_aya23 gemma mistral mixtral phi3 哪个强
- 2matlab实现动态目标追踪代码_40行不到的Python代码实现超燃动态排序图
- 35.javaSE基础__集合(List+Set+Map实现类)
- 4Spring cloud入门-OAuth 2.0(四)授权之基于JWT完成单点登录_oauth2.0 jwt单点登录
- 5【算法leetcode每日一练】2161. 根据给定数字划分数组_给你一个下标从0开始的整数数组nums
- 6HarmonyOS NEXT Beta 版开发者及先锋用户招募(第一期)报名答题题库(持续更新中,仅供学习分享使用)_下面属于arkts函数声明的语句的是?
- 7利用for循环,计算1+2+3+……+100。等差数列求和_使用for循环输出1+2+3+。。。+100的结果
- 8在GitHub上建立个人主页的方法
- 9发散阅读、拓宽思路【PageRank、Tf-Idf、协同过滤、分布式训练、StyleTransfer、Node2vec】_pagerank和tfidf
- 10neo4j导入csv数据_neo4j 加载csv 数据都是第一行
最全一篇文章搞懂数据仓库:常用ETL工具、方法(1),2024年最新大数据开发面试题_常用etl和数据库(结构化和非结构化)管理工具知识
赞
踩
网上学习资料一大堆,但如果学到的知识不成体系,遇到问题时只是浅尝辄止,不再深入研究,那么很难做到真正的技术提升。
一个人可以走的很快,但一群人才能走的更远!不论你是正从事IT行业的老鸟或是对IT行业感兴趣的新人,都欢迎加入我们的的圈子(技术交流、学习资源、职场吐槽、大厂内推、面试辅导),让我们一起学习成长!
一、什么是ETL?
二、ETL & ELT
三、常用的ETL工具
3.1 sqoop
3.2 DataX
3.3 Kettle
3.4 canal
3.5 StreamSets
四、ETL加载策略
4.1 增量
4.2 全量
4.3 流式
小编有话
一、什么是ETL?
ETL,是英文Extract-Transform-Load的缩写,用来描述将数据从来源端经过抽取(extract)、转换(transform)、加载(load)至目的端的过程,是数据仓库的生命线。
**抽取(Extract)**主要是针对各个业务系统及不同服务器的分散数据,充分理解数据定义后,规划需要的数据源及数据定义,制定可操作的数据源,制定增量抽取和缓慢渐变的规则。
**转换(transform)**主要是针对数据仓库建立的模型,通过一系列的转换来实现将数据从业务模型到分析模型,通过ETL工具可视化拖拽操作可以直接使用标准的内置代码片段功能、自定义脚本、函数、存储过程以及其他的扩展方式,实现了各种复杂的转换,并且支持自动分析日志,清楚的监控数据转换的状态并优化分析模型。
**装载(Load)**主要是将经过转换的数据装载到数据仓库里面,可以通过直连数据库的方式来进行数据装载,可以充分体现高效性。在应用的时候可以随时调整数据抽取工作的运行方式,可以灵活的集成到其他管理系统中。
二、ETL & ELT
伴随着数据仓库的发展(传送门:数据仓库的八个发展阶段),数据量从小到大,数据实时性从T+1到准实时、实时,ETL也在不断演进。
在传统数仓中,数据量小,计算逻辑相对简单,我们可以直接用ETL工具实现数据转换(T),转换之后再加载到目标库,即(Extract-Transform-Load)。但在大数据场景下,数据量越大越大,计算逻辑愈发复杂,数据清洗需放在运算能力更强的分布式计算引擎中完成,ETL也就变成了ELT(Extract-Load-Transform)。
即:Extract-Transform-Load >> Extract-Load-Transform
通常我们所说的ETL,已经泛指数据同步、数据清洗全过程,而不仅限于数据的抽取-转换-加载。
三、常用的ETL工具
下面小编将介绍几类ETL工具(sqoop,DataX,Kettle,canal,StreamSets)。
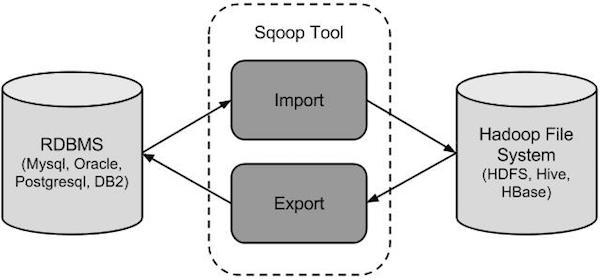
3.1 sqoop
-
是Apache开源的一款在Hadoop和关系数据库服务器之间传输数据的工具。
-
可以将一个关系型数据库(MySQL ,Oracle等)中的数据导入到Hadoop的HDFS中,也可以将HDFS的数据导出到关系型数据库中。
-
sqoop命令的本质是转化为MapReduce程序。
-
sqoop分为导入(import)和导出(export),
-
策略分为table和query
-
模式分为增量和全量。

3.2 DataX
-
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台
-
实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。



既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新

