
大语言模型系列-BERT_bert大语言模型
赞
踩
前言
前文提到的GPT-1开创性的将Transformer Decoder架构引入NLP任务,并明确了预训练(学习 text 表征)+微调这种半监督训练方法,但Transformer Decoder的Masked attention部分,屏蔽了来自未来的信息,因此GPT是单向的模型,只能考虑语境上文,无法考虑语境的下文。
因此,BERT转而使用了Transformer Encoder架构,核心其实就是注意力层的区别。
和GPT-1一样,BERT既可以用于特征抽取,将新的embedding应用到下游任务,也可以直接基于BERT进行微调,对于特定任务进行一个整体的训练。
ps:
18年以后,深度学习直接端到端,不需要用词嵌入了
19年NAACL Google团队提出的BERT里就摈弃预训练词向量的方法了,而是集成到BERT模型里的字嵌入、词嵌入和位置嵌入。
提示:以下是本篇文章正文内容,下面内容可供参考
一、BERT的网络结构和流程
1.网络结构
下图很好的展示了BERT的网络结构
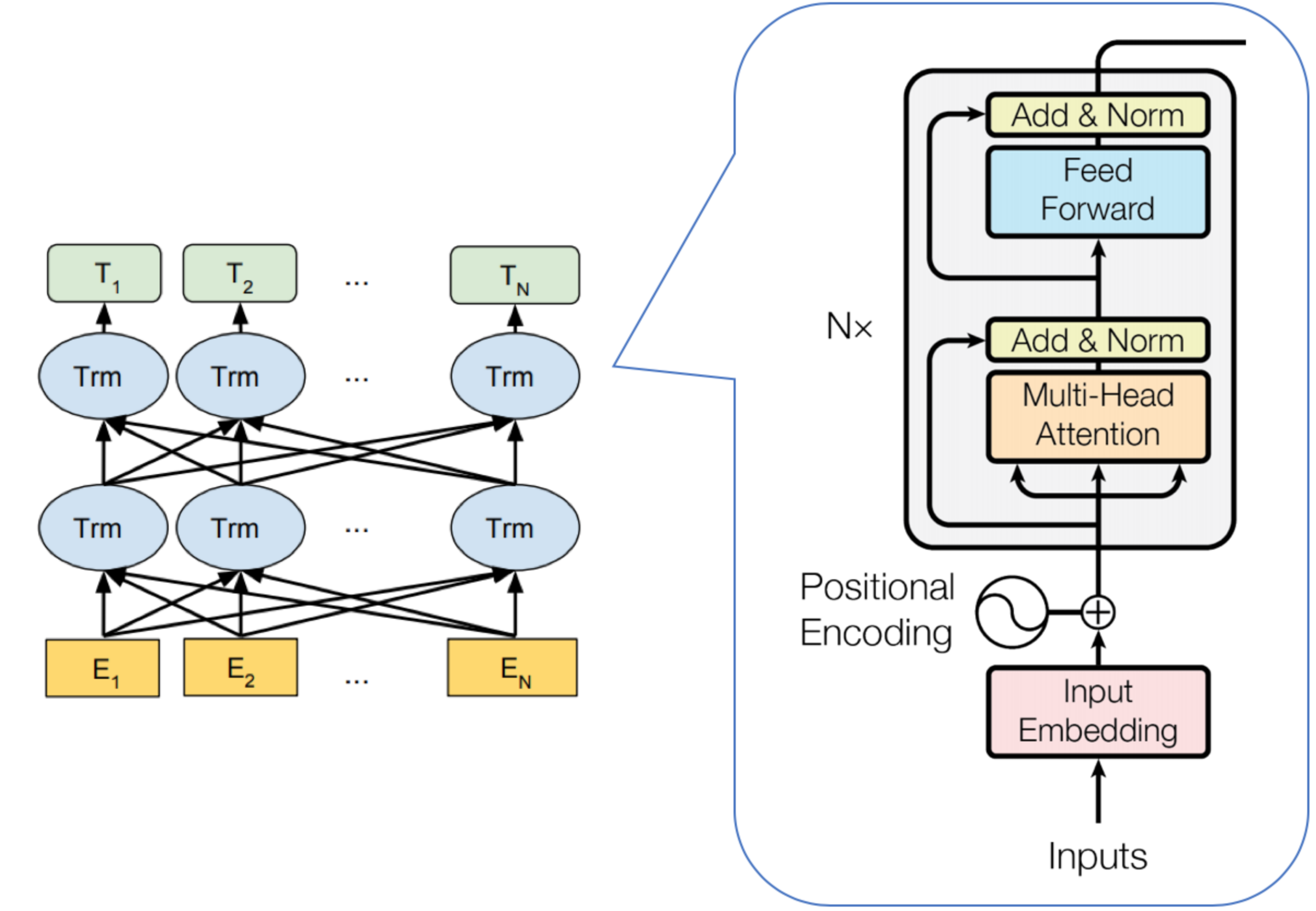
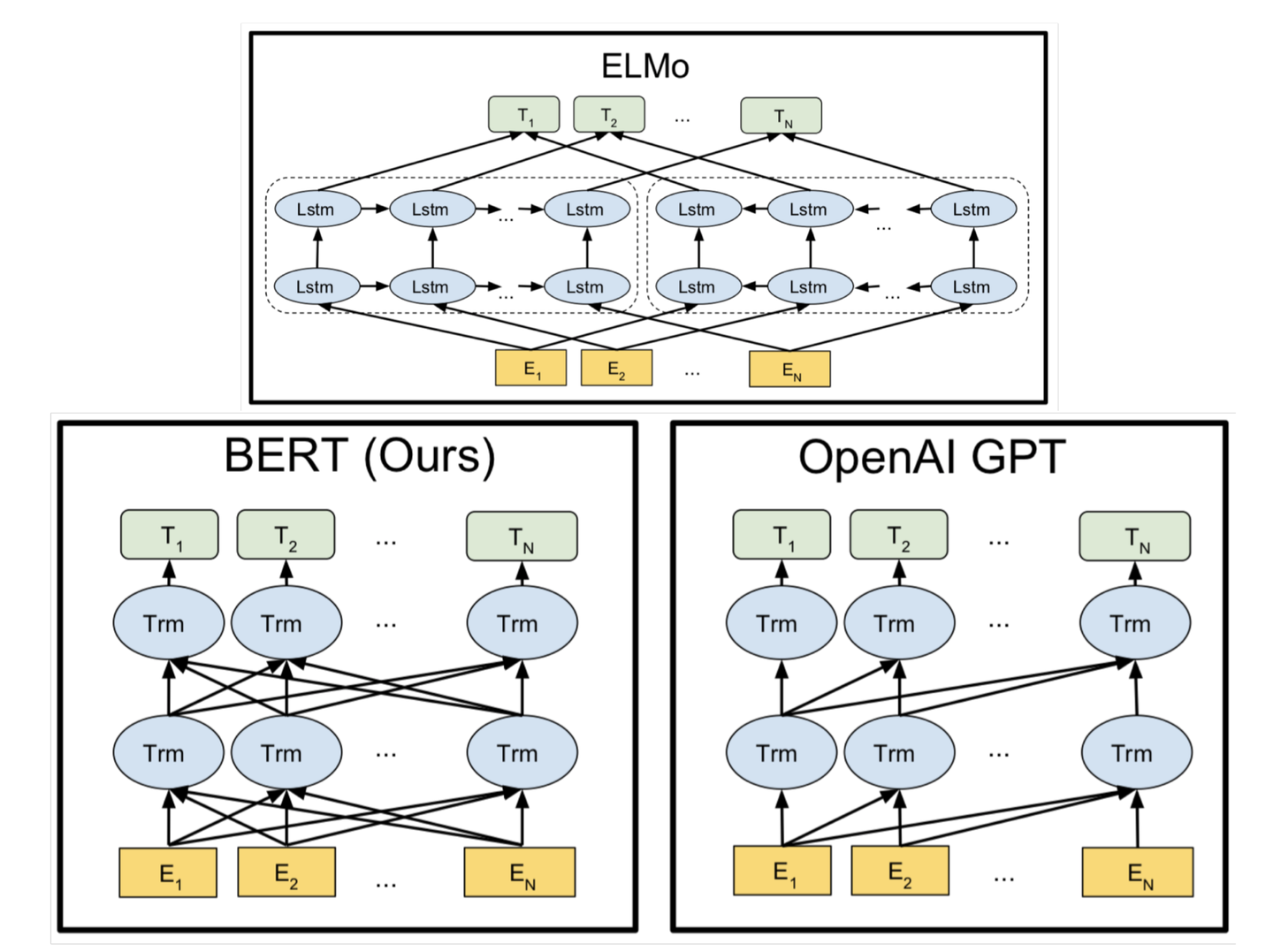
下图很好的展示了ELMo、GPT1和BERT的区别
2.输入
BERT的输入embeddings由三部分组成:分词对应的token,可学习的分割embeddings([SEP])和位置 embeddings,其中分割embeddings是用于分割不同的句子。
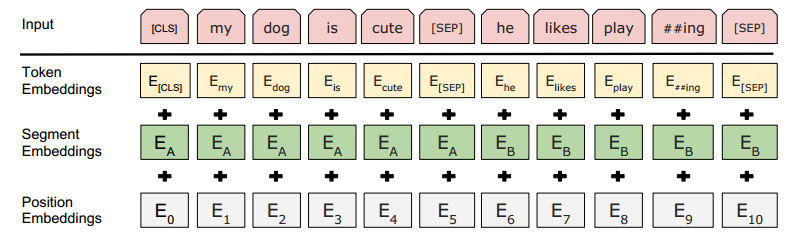
3.输出
输出的数量和输入是一致的,如下图所示:
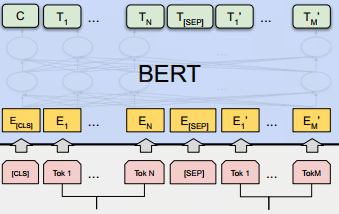
C为分类token([CLS])对应的输出,
T
i
T_i
Ti代表其他token对应的输出。
- 对于一些token级别的任务(如序列标注和问答任务),就把 T i T_i Ti输入到额外的输出层中进行预测。
- 对于一些句子级别的任务(如自然语言推断和情感分类任务),就把C输入到额外的输出层中。
这里也就解释了为什么要在每一个token序列前都要插入特定的分类token。
4.预训练
在总述中提到了,BERT主要用于自然语言理解,这是由于它的预训练机制导致的。
BERT基于两种任务进行了预训练:Masked Language Model和Next Sentence Prediction。
Masked Language Model
Masked LM是BERT能够不受单向语言模型所限制的重要原因。
简单来说就是以15%的概率用mask token ([MASK])随机地对每一个训练序列中的token进行替换,然后预测出[MASK]位置原有的单词。(通俗理解,让模型做完形填空)
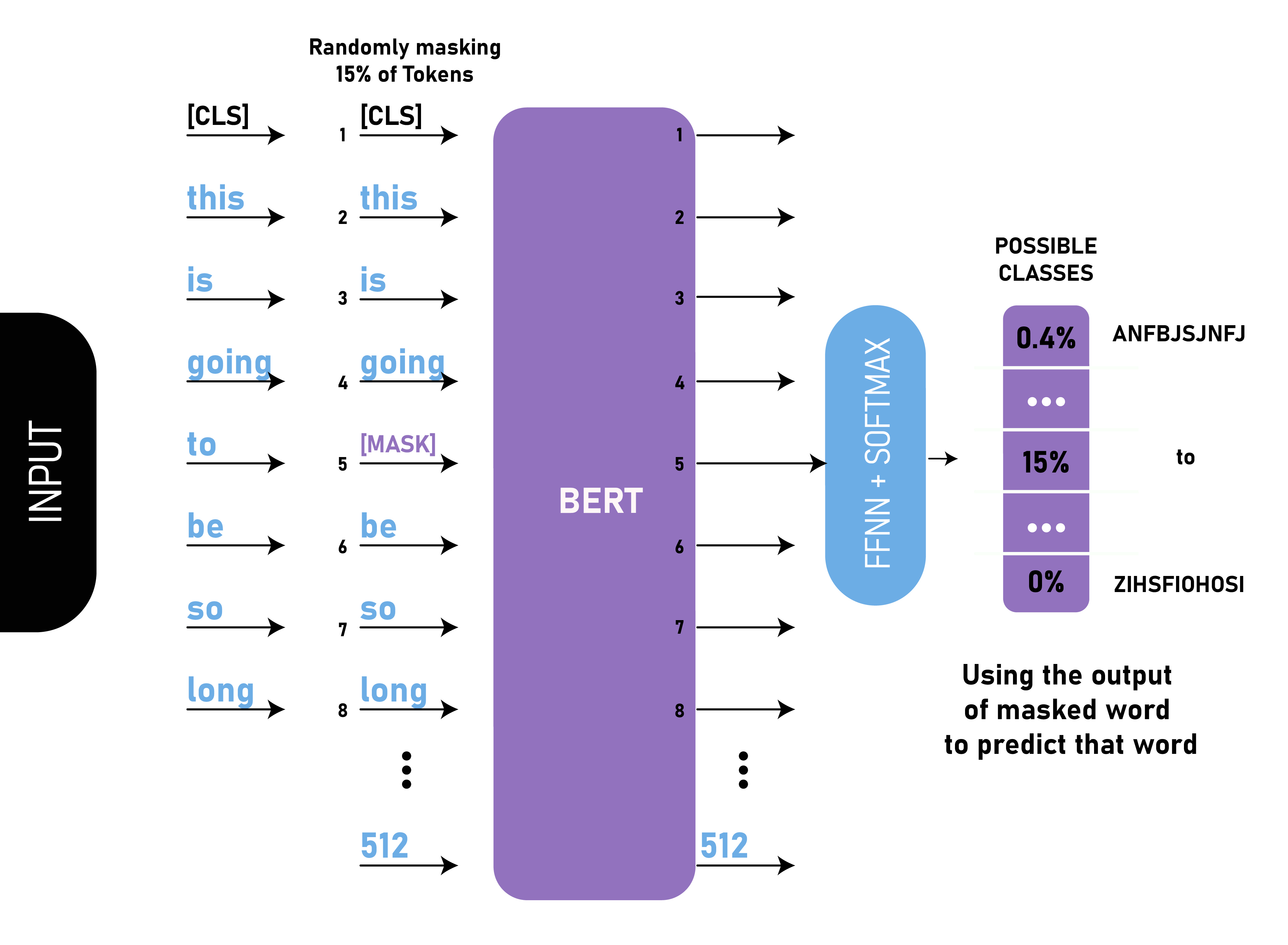
但由于[MASK]并不会出现在下游任务的微调(fine-tuning)阶段,因此预训练阶段和微调阶段之间产生了不匹配(这里很好解释,就是预训练的目标会令产生的语言表征对[MASK]敏感,但是却对其他token不敏感)
因此BERT采用了以下策略来解决这个问题:
首先在每一个训练序列中以15%的概率随机地选中某个token位置用于预测,假如是第i个token被选中,则会被替换成以下三个token之一:
-
1)80%的时候是[MASK]。如,my dog is hairy——>my dog is [MASK]
-
2)10%的时候是随机的其他token。如,my dog is hairy——>my dog is apple
-
3)10%的时候是原来的token。如,my dog is hairy——>my dog is hairy
再用该位置对应 T i T_i Ti的去预测出原来的token(输入到全连接,然后用softmax输出每个token的概率,最后用交叉熵计算loss)。
该策略令到BERT不再只对[MASK]敏感,而是对所有的token都敏感,以致能抽取出任何token的表征信息。
Next Sentence Prediction
一些如问答、自然语言推断等任务需要理解两个句子之间的关系,而MLM任务倾向于抽取token层次的表征,因此不能直接获取句子层次的表征。为了使模型能够有能力理解句子间的关系,BERT使用了NSP任务来预训练,简单来说就是预测两个句子是否连在一起。具体的做法是:对于每一个训练样例,在语料库中挑选出句子A和句子B来组成,50%的时候句子B就是句子A的下一句(标注为IsNext),剩下50%的时候句子B是语料库中的随机句子(标注为NotNext)。接下来把训练样例输入到BERT模型中,用[CLS]对应的C信息去进行二分类的预测。
loss
总结一下训练样例:
Input1=[CLS] the man went to [MASK] store [SEP] he bought a gallon [MASK] milk [SEP]
Label1=IsNext
Input2=[CLS] the man [MASK] to the store [SEP] penguin [MASK] are flight ##less birds [SEP]
Label2=NotNext
- 1
- 2
- 3
- 4
- 5
- 6
- 7
把每一个训练样例输入到BERT中可以相应获得两个任务对应的loss,再把这两个loss加在一起就是整体的预训练loss(也就是两个任务同时进行训练)。
可以明显地看出,这两个任务所需的数据其实都可以从无标签的文本数据中构建(自监督性质),大大减少了工作量(无需人工标注)。
二、BERT创新点
- 换为Encoder only架构,从而能够考虑语境上下文
- 提出了行之有效的双向语言模型训练机制:MLM和NSP
总结
尽管BERT能够看到上下文信息,并提出了行之有效的训练方式,但是这种训练模式不具有自回归特性,因此BERT这类模型更适合于自然语言理解式任务(NLU),如文本分类、情感分析,命名实体识别。对于生成式任务则存在不足。

