
- 1资源分配 (c实现)_请使用c语言动态规划策略编写算法,实现资源分配问题。要求:输入资源个数与资金金
- 2[Java反序列化]JavaCC链学习(8u71前)_java8u71版本之前
- 3【git】恢复因git reset --hard 但未提交全部文件到仓库导致的文件丢失问题_git reset --hard 文件去哪了
- 4大数据技术应用4-2MapRuduce编程组件、运行模式、性能优化策略_mapreduce编程组件中,哪个组件主要用于描述输入数据的格式,什么组件主要用于
- 5【网络信息安全】身份认证
- 6教你用Python画哆啦A梦、海绵宝宝、皮卡丘、史迪仔!(附完整源码)_python哆啦a梦代码
- 7sklearn中TF-IDF值的计算方式_如何计算 seo tf-idf sklearn
- 8手把手教你:个人信贷违约预测模型
- 9探索Go与Web的无缝融合:golang-wasm-example项目深度解析与推荐
- 10MySQL-触发器:触发器概述、触发器的创建、查看删除触发器、 触发器的优缺点_mysql 创建触发器
【论文笔记】实时多人姿态评估 (OpenPose)Realtime Multi-Person 2D Pose Estimation using Part Affinity Fields_openpose研究现状
赞
踩
1.摘要翻译
我们提出了一种高效检测图片中多个人2D姿态的方法。这种方法使用了一种无参表示法,来学习如何将人的身体部分与其个人联系起来, 我们称这种方法为“Part Affinity Fields”。这种结构将全局上下文(全体信息)编码,允许使用一种贪心的自底向上的的解析方法来维持高准确率和实时检测,无论图片中有多少人。这种结构被设计成使用两个分支的相同顺序预测过程,同时学习零件(单个人)的位置和他们之间的联系。这种方法能吊打目前最强的实时姿态检测。
2.文章的研究现状
2.1 当前的问题:
- 人数不确定,出现的位置和尺寸也不确定。
- 人类之间的交互,使得姿态识别更加困难
- 运行时的复杂度随着识别人数的增加而增加
2.2 现有的解决方法
- 自顶向下的方法:先识别出一副图片中的所有人物对象,再对每一个对象进行单个对象的姿态估计。
- 自底向上的方法:不能保证效率的提高,因为最终解析需要耗时的全局推理。有学者采用ResNet的方法,已经大大提高了速度,但依然需要几分钟来处理一张图片。
3.这篇文章解决了什么问题
进一步提高了多人条件下,人体姿态识别的速度和准确性。
4.它的创新点在哪里
- 使用了显式的无参表示法,编码了肢体的位置和方向信息(PAF)
- 设计了一种同时训练肢体位置和关键点之间联系的训练方法
- 证明了一种贪心的解码方法高效地完成了人体姿态确定
5.比别的算法好在哪里
- 能识别更多人物对象,速度更快
6.算法框架与网络结构
本文首先采用两个并行的CNN结构,分别来提取置信度图S(关节点)和部分亲和域L(四肢),最后,置信度图和亲和域所代表的点和边进行贪心算法构成人体结构。
6.1 检测与联系的同步

在输入图片时候,我们首先采用经过微调的VGG-19网络的前十层得到一个激活映射F。F中存在这张图片的基本特征词典,时接下来两个分支的输入。
上图中branch1用来训练置信度点集S,branch2用来训练亲和域集L。可以看到相似的训练过程不止一次,每个分支的训练都要经过多轮(Stage t t>=2)。每一轮作者都通过一系列CNN进行一次特征提取,然后结合(branch1的结果,branch2的结果,以及最初输入F),作为下一轮训练的输入。同时也进行损失函数的监督,做一些避免梯度消失的操作。
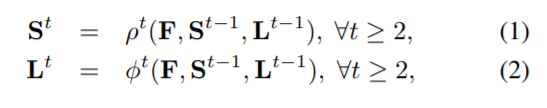
用公式表示就是上面这样St,Lt表示第t轮训练的结果,ρt表示第t轮置信点训练过程,φt表示第t轮亲和域训练过程,其中的三个输入对应上一段括号里的三个内容。
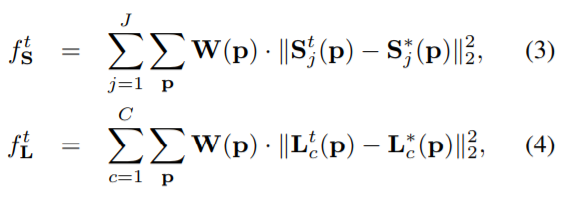
上面是对每一轮训练损失函数的定义,W是一个【0,1】函数,如果p点没有标注,则W§=0,其意义在于避免惩罚正确的正预测(?其实这里不太明白,大概是未经标注的点不能计算到损失函数中去);
中间结果监督可以用来避免梯度消失,方法是进行及时的梯度补充。
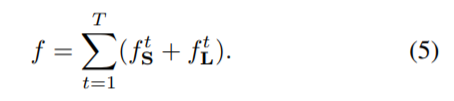
最后总的损失函数按以上公式计算
6.2 部分检测的置信图
这一部分介绍了置信图的损失函数中,标准置信度(Sj 中文名可能不准确)的计算方法;
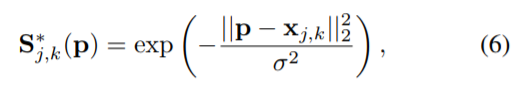
作者定义由一个个体产生的置信图Sj,k,
由(6)公式可知,对于k这个人的第j个部位,在某个输入点的置信度该怎么计算。
|| x || 符号用来计算范数,公式中为二阶范数,下面的σ用来控制尖峰的分布
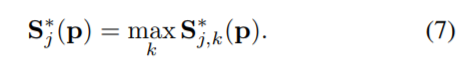
整个人体的置信度定义为他所有组成部分的置信度中的最大值。
6.3 各部分连接的部分亲和域
假设已经得到了各部分身体点,如何将他们连接起来成为一个个完整的人体呢?
当前的各种方法(比如在置信度点之间添加一些辅助点)有以下两个问题:
- 只考虑了位置信息,而没有考虑指向情况。
- 将四肢的支持区域缩小成了一个点
为了解决上面的问题,作者提出了一种新的特征表示:Part Affinity Field。核心是将“方向”考虑进来。
Part Affinity Field(部分连接域)定义为每一个四肢的二维向量场
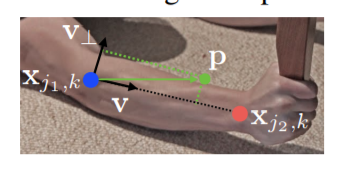
比如上图,蓝色点和红色点是这条手臂上关节的真实位置,绿色点p为输入点。那么Lc,k ( p )的定义为:若p点在这个肢体上,那么Lc,k ( p )是一个从蓝色点到红色点的单位向量,否则为0. 公式如下所示:

那么如何定义p点在肢体上呢?
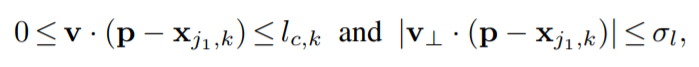
简单地说,p点需要在以红蓝连线为长,肢体宽度为宽的长方形内,才能被认为是在肢体上
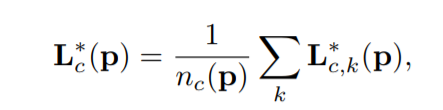
在连接域的汇总上,作者使用了向量的平均值。
在测试时,作者使用沿着连接候选部位线段,计算对应部位的PAF上线积分的方法,检测各个部位之间的关联度。换句话说,作者测量了预测PAF和通过联系检测的身体部位构成的候选肢体间的一致性。
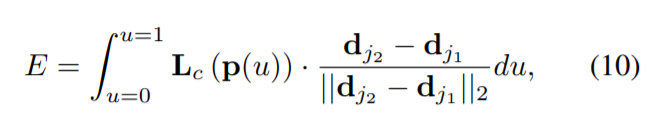
比如说,有两个候选部位点dj1,dj2
6.4 运用PAF进行多人身体检测
当要识别的图像中有多个人的时候,PAF之后的工作变成了一个K分图最大匹配:

比如上图,红绿蓝三种颜色之间要实现最佳匹配,这是一个NP-Hard问题。而在这篇文章中,作者使用了一种巧妙地贪心算法稳定地输出较优解。他们推断,大概是PAF得到的结果包含了某种全局上下文,给与这幅图一些比较微妙地性质。
首先我们做一些定义:
DJ={dmj: for j∈{1…J},m∈{1…Nj}} ,j是人体部位数量,Nj是部位j的候选数量,并且dmj∈R2是对于候选身体部位j的第m−th个检测的坐标。
我们定义一个变量zm nj1 j2∈{0,1}来表示两个候选检测dmj1和dmj2是否能够连接
如果只考虑一个肢体c,比如右手手肘到手腕,那么手肘有Ni个候选点,手腕有Nj个,对这两个部位的候选点做二分图匹配,权值通过公式(10)进行计算,就可以得到四肢的选择结果。
但人的身体有很多部位,K分图匹配是NP-Hard的问题。这时候,作者提出了两个额外的松弛操作:
1 选择尽量少的边组成一个生成树骨架,而不是使用整张图。
生成树的边数不是固定的吗?何为最少呢?
有一个假设,这里的生成树将所有同一个身体部位的点看作一个点,缩点过后不同点之间有很多条连线(原候选点之间的),这些连线要么都删,要么都留。所以有一个留下最少的删法。
2 然后将原来的匹配问题,简化成生成树上相邻节点集之间的二分图匹配
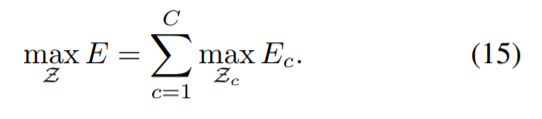
由此公式可以简化成上图
作者因此可以独立地使用匈牙利算法对于每一个肢体类别获得肢体联系候选。有了全部的候选肢体连接,我们就可以将共享同个候选检测部位的连接综合起来形成对于多个体的全身姿势检测。我们在三个结构上的优化策略比在整个连接图上的优化快了几个数量级。
问题:
这个贪心算法的基础是选择最少数量的边,这个边的数量是按照什么进行定义的?是指两类点之间的边数目最少吗?
如果存在两组边数目相同,该删去哪一组呢?
7.它的实验采用了哪些指标
本文采用了两个公开数据集:
(1) the MPII human multi-person dataset
(2) the COCO 2016 keypoints challenge dataset
实验采用了以下指标:
对于数据集1:
各个身体部位的回归率以及 mean Average Precision(mAP 各种回归率的均值)
运行速度
对于数据集2:
OKS(Object Keypoint Similarity)对象关键点相似度
PCKh (头部长度归一化参考)关键点识别比率
实验结果:
在第一个数据集上,mAP较之前最佳方法提高了13%左右,时间上快了6个数量级,达到毫秒级别。
在第二个数据集上,mAP仅比从上到下的方法在小尺寸人物的识别上劣势。
8.它的方法有什么缺点吗
- 在CNN的过程上花了绝大多数时间

