
- 1C++入门:初识类和对象
- 212:go语言中的流程控制_go语言中的流程控制 go语言中的条件 条件语句是用来判断给定的条件是否满足(表达
- 3最近的一个小项目的总结(诶呦,CSDN博客好难用啊!)_关于java小项目的总结
- 4函数式接口及常用接口_函数式接口的好处
- 5MySQL相关参数配置及性能优化_mysql 事务 相关 参数
- 6C#的正则表达式_c#正则表达式匹配空格
- 7开启物联网的魔法之门 - 深入探索发布/订阅模式
- 8Docker学习系列(一):windows下安装docker_docker windchill
- 9蓝桥杯-平面切分(欧拉定理)_平面上有 条直线,其中第 条直线是 。 请计算这些直线将平面分成了几个部分
- 10设置ubutnu18.04开机自启动python脚本_ubuntu 开机自动启动python
2021年第十届数学建模国际赛小美赛D题为什么百年一遇的天气事件如此频繁解题全过程文档及程序_2021小美赛d题
赞
踩
2021年第十届数学建模国际赛小美赛
D题 为什么百年一遇的天气事件如此频繁
原题再现:
今年3月下旬,居住在澳大利亚东海岸的人们经历了一次罕见的气象事件。一些地区创纪录的降雨,以及其他地区持续的强降雨,导致了严重的洪灾。在不同的地方,这被描述为30年一遇、50年一遇或100年一遇。那么,这意味着什么?
首先,让我们澄清一个关于百年一遇事件含义的常见误解。这并不意味着这一事件每100年就会发生一次,也不意味着它在未来100年内不会再次发生。对于气象学家来说,百年一遇事件是指平均每100年发生一次与之相等或超过其规模的事件。这意味着在1000年的时间里,你会期望百年一遇的事件等于或超过十次。但这十次中有几次可能在几年内发生,之后很长一段时间内都不会发生。理想情况下,我们应该避免使用“百年一遇”这一短语,因为这是一个常见的误解,但这个词现在太普遍了,很难改变。另一种思考百年一遇事件含义的方法是,在任何给定年份,至少有1%的概率发生这种规模的事件(这称为“年度超越概率”)。
许多人感到惊讶的是,百年一遇的事件似乎比他们预期的要频繁得多。虽然1%的概率听起来很少见,也不太可能,但实际上它比你想象的要普遍得多。对于给定的位置(例如您居住的地方),100年一遇的事件预计平均每100年发生一次。然而,纵观整个美国,你会期望百年一遇的事件在某个地方远远超过一个世纪一次!
根据非营利组织德国观察(Germanwatch)的最新发现,在过去20年中,近50万人死于与气候灾害相关的疾病,其中大部分来自世界上最贫穷的国家。2000年至2019年间,全世界大约发生了11000次极端天气灾害。这些事件给160多个国家造成了约475000人死亡和2.5万亿美元的经济损失。
我们的任务:
1、请建立数学模型,评估数据中的天气事件是30年一遇、50年一遇还是100年一遇。
2、研究某些天气事件的发生是否具有一定的时空规律,并做出一定的预测。
3、近年来极端天气事件的发生是否越来越频繁?请给出一个科学的解释。
4、请向国家保险公司提交一份1-2页的极端天气风险评估报告,并估算可能造成的损失。
整体求解过程概述(摘要)
今年澳大利亚的洪水被描述为在不同地方发生的三十年一遇、五分之一次或百年一遇的事件。因此,如何描述“百年一遇”是一个模棱两可的问题。对于气象学家来说,百年一遇并不意味着它平均每一百年只发生一次。此外,气候灾害造成的危害不可低估。它在20年内造成了50万人死亡。因此,开展气象灾害相关数据分析和风险评估具有重要意义。
为了建立天气事件频率分析模型。对于问题1,我们考虑六个指标。采用P-Ⅲ分布进行拟合计算。选取Gamma、对数正态分布、GEV和指数四种边缘分布对损伤程度、损伤范围和天气事件持续时间序列进行拟合,得出Gumbel Copula拟合效果最好的结论。其次,用极大似然法估计边际分布参数,并用K-S检验法验证拟合。然后,基于选取的Gumbel Copula函数,建立天气事件的三变量联合分布,分别计算不同单变量重现期下的联合共现重现期和三变量联合分布重现期。最后,利用支持向量机模型对所得结果进行分类,以更好地体现数据特征。
针对第二个问题,我们首先对数据进行Daniel检验,检验2000-2021年数据中各种天气事件重现期数据的序列平稳性。然后利用Moran指数判断天气事件之间是否存在空间相关性。结果表明:雷暴、山洪暴发、严寒/风寒和浓雾具有显著的空间聚集效应;暴雪和霜冻具有较低的空间聚集效应。随后,建立地理加权回归模型,探索天气事件的具体空间规律。研究发现,美国雷暴和山洪灾害发生频率最高,呈现出从西向东、从北向南递增的空间趋势。最后,通过建立ARIMA模型对天气事件发生频率进行预测,发现雷暴总数呈上升趋势。可以看出,随着时间的推移,雷雨变得越来越频繁。Torrent数据接近稳定。暴风雪、浓雾和霜冻/结冰的频率普遍增加。
对于问题3,我们首先对数据进行描述性统计分析。通过发生山洪和龙卷风两类典型天气事件可以看出,并非所有极端天气事件都受到全球气候变化的影响。然后,建立小波神经网络模型对美洲极端天气事件发生概率进行预测。结果表明,近10年来极端天气事件发生的总概率大致呈上升趋势,由预测值可知,到2021年,整个美洲发生极端天气事件的概率可达0.016左右。
关于问题4,我们编写了一份提交给国家保险局的风险评估报告,利用空间计量聚类分析了解各大洲的财产损失情况,明确各大洲的财产损失水平。研究发现,美国东部地区的财产损失高于西部地区,并在此基础上提出了相关建议。从灰色关联度评价模型可以看出,死亡人数与极端天气事件发生的关联度最高。
最后,通过鲁棒性检验和误差分析对模型进行了验证,客观分析了模型的优缺点和改进之处。同时,我们发现本文的模型能够预测世界各国经济水平的空间分布特征。
模型假设:
为了简化这个问题,我们做了以下基本假设,每个假设都是正确的。
假设1:所有研究对象都是随机分布的。
理由:对于Moran指数分析,我们可以通过此假设将观测指数放置在相同的空间状态来计算指数值。
假设2:并非所有观测指标在空间上都是独立的,空间关系是非平稳的。
理由:对于空间地理加权回归模型,由于指标之间的空间相关性。不同的空间具有异质性和非平稳性,对观测指标的影响也不同。
假设3:每个单元的观测指标可以看作是空间中的一个点。
理由:对于谱聚类分析,由于空间不同区域的点构成一个点集,且点集内部具有紧性,这种方法可以通过距离来度量观测指标的空间相关性程度。
假设4:第一个问题中得到的百年一遇事件被视为极端天气事件。
理由:针对小波神经网络预测模型,子假设可以更好地简化模型,预测极端天气事件发生的概率。
问题重述:
今年3月下旬,居住在澳大利亚东海岸的人们经历了一次罕见的气象事件。一些地区创纪录的降雨,以及其他地区持续的强降雨,导致了严重的洪灾。但在不同的地方,这场灾难被描述为三十分之一、五分之一或百年一遇。因此,“百年一遇”一词存在歧义。百年一遇的自然灾害并不意味着每100年就发生一次,也不意味着在未来100年内不会再发生。对于气象学家来说,百年一遇意味着在一百年内平均会发生一个或多个事件。然而,具体的概率仍然取决于不同的地方。对于给定位置,预计每100年发生一次的事件平均每100年发生一次。然而,在美国部分地区,百年一遇的事件比百年一遇的事件更为频繁。此外,根据非营利组织德国天文台的最新调查结果,在过去20年中,近50万人死于与气候灾害有关的条件,其中大多数来自世界上最贫穷的国家。
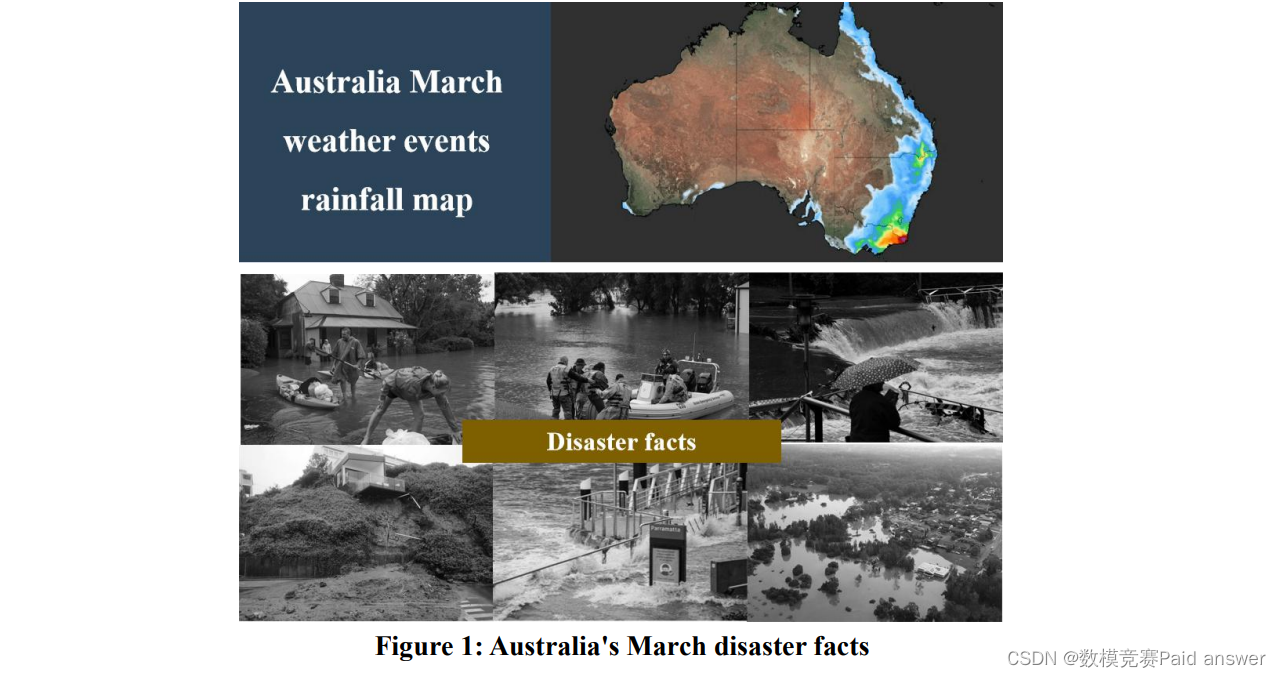
问题重述
考虑到问题陈述中确定的背景信息和限制条件,我们需要解决以下问题:
建立一个数学模型来评估天气事件的重现期,以确定该事件是30年发生一次,50年发生一次,还是100年发生一次。
研究某些天气事件的发生是否具有一定的风暴性和空间规律性,并做出一定的预报。
根据您的预测分析,近年来极端天气事件是否变得更加频繁?
写一份极端天气风险评估报告给国家保险公司,并估计可能的损失。
模型的建立与求解整体论文缩略图


全部论文请见下方“ 只会建模 QQ名片” 点击QQ名片即可
部分程序代码:(代码和文档not free)
1. clear all; 2. clc; 3. x = xlsread('data1.xlsx') 4. 5. [h,p] = jbtest(X) % Jarque-Bera Test 6. [h,p] = kstest(X,[X,normcdf(X,mean(X),std(X))]) % KolmogorovSmirnov Test 7. [h, p] = lillietest(X) % Lilliefors Test 8. 9. [h,p] = jbtest(Y) % Jarque-Bera Test 10. [h,p] = kstest(Y,[Y,normcdf(Y,mean(Y),std(Y))]) % KolmogorovSmirnov Test 11. [h, p] = lillietest(Y) % Lilliefors Test 12. 13. [fx, Xsort] = ecdf(X); 14. [fy, Ysort] = ecdf(Y); 15. U1 = spline(Xsort(2:end),fx(2:end),X); 16. V1 = spline(Ysort(2:end),fy(2:end),Y); 17. [fx, Xsort] = ecdf(X); 18. [fy, Ysort] = ecdf(Y); 19. fx = fx(2:end); 20. fy = fy(2:end); 21. 22. [Xsort,id] = sort(X); 23. [idsort,id] = sort(id); 24. U1 = fx(id); 25. [Ysort,id] = sort(Y); 26. [idsort,id] = sort(id); 27. V1 = fy(id); 28. % Calculate the kernel distribution estimates at the original samp le X and Y respectively 29. U2 = ksdensity(X,X,'function','cdf'); 30. V2 = ksdensity(Y,Y,'function','cdf'); 31. 32. rho_norm = copulafit('Gaussian',[U(:), V(:)]) 33. 34. [rho_t,nuhat,nuci] = copulafit('t',[U(:), V(:)]) 35. 36. % Find the Kendall rank correlation coefficient corresponding to the bivariate normal Copula 37. Kendall_norm = copulastat('Gaussian',rho_norm) 38. % Find the Spearman rank correlation coefficient corresponding to the bivariate normal Copula 39. Spearman_norm = copulastat('Gaussian',rho_norm,'type','Spearman') 40. % Find the Kendall rank correlation coefficient corresponding to t he binary t-Copula 41. Kendall_t = copulastat('t',rho_t) 42. % Find the Spearman rank correlation coefficient corresponding to the binary t-Copula 43. Spearman_t = copulastat('t',rho_t,'type','Spearman') 44. 45. [fx, Xsort] = ecdf(X); 46. [fy, Ysort] = ecdf(Y); 47. U = spline(Xsort(2:end),fx(2:end),X); 48. V = spline(Ysort(2:end),fy(2:end),Y); 49. C = @(u,v)mean((U <= u).*(V <= v)); 50. % Generate new grid data for mapping needs 51. [Udata,Vdata] = meshgrid(linspace(0,1,31)); 52. for i=1:numel(Udata) 53. CopulaEmpirical(i) = C(Udata(i),Vdata(i)); 54. end

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
1. clear all 2. clc 3. load 2_data.mat 4. n = randperm(size(matrix,1)); 5. train_matrix = matrix(n(1:71),:); 6. train_label = label(n(1:71),:); 7. [Train_matrix,PS] = mapminmax(train_matrix'); 8. Train_matrix = Train_matrix'; 9. Test_matrix = mapminmax('apply',test_matrix',PS); 10. Test_matrix = Test_matrix'; 11. 12. %% IV. SVM creation/training (RBF kernel function) 13. %% 14. % 1. Find the best c/g parameter-cross-validation method 15. [c,g] = meshgrid(-10:0.2:10,-10:0.2:10); 16. [m,n] = size(c); 17. cg = zeros(m,n); 18. eps = 10^(-4); 19. v = 5; 20. bestc = 1; 21. bestg = 0.1; 22. bestacc = 0; 23. for i = 1:m 24. for j = 1:n 25. cmd = ['-v ',num2str(v),' -t 2',' - c ',num2str(2^c(i,j)),' -g ',num2str(2^g(i,j))]; 26. cg(i,j) = svmtrain(train_label,Train_matrix,cmd); 27. if cg(i,j) > bestacc 28. bestacc = cg(i,j); 29. bestc = 2^c(i,j); 30. bestg = 2^g(i,j); 31. end 32. if abs( cg(i,j)-bestacc )<=eps && bestc > 2^c(i,j) 33. bestacc = cg(i,j); 34. bestc = 2^c(i,j); 35. bestg = 2^g(i,j); 36. end 37. end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
1. % Solve an Autoregression TimeSeries Problem with a NAR Neural Network 2. % Script generated by Neural Time Series app 3. T = tonndata(data,false,false); 4. % Choose a Training Function 5. % For a list of all training functions type: help nntrain 6. % 'trainlm' is usually fastest. 7. % 'trainbr' takes longer but may be better for challenging problem s. 8. % 'trainscg' uses less memory. Suitable in low memory situations. 9. trainFcn = 'trainlm'; % Levenberg-Marquardt backpropagation. 10. 11. % Create a Nonlinear Autoregressive Network 12. hiddenLayerSize = 10; 13. net = narnet(feedbackDelays,hiddenLayerSize,'open',trainFcn); 14. 15. [x,xi,ai,t] = preparets(net,{},{},T); 16. 17. % Setup Division of Data for Training, Validation, Testing 18. net.divideParam.trainRatio = 70/100; 19. net.divideParam.valRatio = 15/100; 20. net.divideParam.testRatio = 15/100; 21. 22. % Train the Network 23. [net,tr] = train(net,x,t,xi,ai); 24. 25. % Test the Network 26. y = net(x,xi,ai); 27. e = gsubtract(t,y); 28. performance = perform(net,t,y) 29. 30. % View the Network 31. view(net) 32. 33. % Plots 34. % Uncomment these lines to enable various plots. 35. %figure, plotperform(tr) 36. %figure, plottrainstate(tr) 37. %figure, ploterrhist(e) 38. %figure, plotregression(t,y) 39. %figure, plotresponse(t,y) 40. %figure, ploterrcorr(e) 41. %figure, plotinerrcorr(x,e) 42. 43. netc = closeloop(net); 44. netc.name = [net.name ' - Closed Loop']; 45. view(netc) 46. [xc,xic,aic,tc] = preparets(netc,{},{},T); 47. yc = netc(xc,xic,aic); 48. closedLoopPerformance = perform(net,tc,yc) 49. 50. nets = removedelay(net); 51. nets.name = [net.name ' - Predict One Step Ahead']; 52. view(nets) 53. [xs,xis,ais,ts] = preparets(nets,{},{},T); 54. ys = nets(xs,xis,ais); 55. stepAheadPerformance = perform(nets,ts,ys)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56

