
- 1【K8S认证】2023年CKA考题汇总(解析+答案)_k8s证书认证考试
- 2Python实现代码雨效果_python画代码雨
- 3【目标检测】Faster R-CNN论文代码复现过程解读(含源代码)_使用voc格式进行训练,训练前需要下载好voc07+12的数据集
- 4unity中调用dll文件总结_unity调用dll
- 5【Spring Boot】集成Kafka实现消息发送和订阅_unexpected handshake request with client mechanism
- 6计划任务ScheduledExecutorService的使用_setremoveoncancelpolicy
- 7【书生·浦语大模型实战营】学习笔记1
- 8【JavaEE】传输层网络协议
- 9【无标题】Unity2021安装后无法打开的问题_unity pattern not found
- 10llama2大模型---商用部署(模型推理阶段)预算估算_v100 大模型推理
【AWS系列】第八讲:AWS Serverless之S3_aws s3
赞
踩

目录
序言
三言两语,不如细心探索。
希望读完此文,能帮助读者对AWS S3 有一个初步的了解
文章标记颜色说明:
- 黄色:重要标题
- 红色:用来标记结论
- 绿色:用来标记一级论点
- 蓝色:用来标记二级论点
1.基础介绍
1.1 概念介绍
Amazon Simple Storage Service (Amazon S3) 是一种对象存储服务
特点:
- 行业领先
- 可扩展性
- 数据可用性
- 安全性
- 性能高
其具有高成本效益的存储类和易于使用的管理功能
可以优化成本、组织数据并配置精细调整过的访问控制,从而满足特定的业务、组织和合规性要求。
1.2 原理介绍

Amazon S3 是一种数据元存储服务,可将数据以对象形式存储在存储桶中。对象指的是一个文件和描述该文件的任何元数据。存储桶是对象的容器。
要将数据存储在 Amazon S3 中,
- 需要先创建存储桶,
- 指定存储桶名称和 AWS 区域。
- 将数据作为 Amazon S3 中的数据元上传到该存储桶。
每个对象都带有密钥(或键名称),它是存储桶中对象的唯一标识符。
1.3 应用场景
S3除了用于对象存储,还可以做一下场景:
- 数据湖
- 网站
- 移动应用程序
- 备份和恢复
- 归档
- 企业应用程序
- IoT 设备和大数据分析
1.3.1 构建数据湖
运行大数据分析、人工智能 (AI)、机器学习 (ML) 和高性能计算 (HPC) 应用程序来获得数据见解。
数据湖基础:Amazon S3、AWS Lake Formation、Amazon Athena、Amazon EMR 和 AWS Glue
使用在 Amazon S3 上构建的数据湖,可以使用原生 AWS 服务运行大数据分析、人工智能(AI)、机器学习、高性能计算(HPC)和媒体数据处理应用程序,以便从非结构化数据集中获得洞察信息。
与 AWS Lake Formation 和 AWS Glue 结合使用时,可以通过端到端数据集成和集中的、类似数据库的权限和治理来轻松简化数据湖的创建和管理。Glue、Amazon EMR 和 Amazon Athena 等 AWS 分析解决方案可让您轻松直接查询数据湖。
1.3.2 备份和还原关键数据
通过 S3 强大的复制功能达到恢复时间目标 (RTO)、恢复点目标 (RPO) 以及符合合规要求。
优势:
- 数据持久性
- 灵活性和可扩展性
- 成本效益
- 适合所有数据类型的备份
- 安全性与合规性
- 数据传输方法
1.3.3 以最低成本存档数据
将数据存档移动到 Amazon S3 Glacier 存储类以降低成本、消除运营复杂性并获得新见解。
优势:
- 检索速度快至毫秒
- 无与伦比的持久性和可扩展性
- 最全面的安全与合规性功能
- 最低成本
- 在整个数据生命周期中保持一致
1.3.4 运行云原生应用程序
构建快速、功能强大的移动和基于 Web 的云原生应用程序,可在高度可用的配置中自动扩展。
云原生应用程序实现功能的速度更快,因为微服务在准备就绪时提供其功能,而无需等待单片应用程序完成。Amazon S3为IT团队交付的内部员工应用程序和产品团队交付的外部客户应用程序提供即时、弹性的容量。
1.4 S3 的功能
功能分为以下几个模块
存储类
1.4.1 存储类
Amazon S3 提供一系列适合不同使用案例的存储类。
使用方法:
频繁访问存储在:
- S3 Standard
不经常访问,存储在:
- S3 Standard-IA
- S3 One Zone-IA
成本归档,存储在:
- S3 Glacier Instant Retrieval
- S3 Glacier Flexible Retrieval
- S3 Glacier Deep Archive
不断变化或未知访问模式的数据:
- S3 Intelligent-Tiering
这四个访问层包括两个低延迟访问层(针对频繁和不频繁访问进行了优化),以及两个为异步访问很少访问的数据而设计的 opt-in archive 访问层。
1.4.2 存储管理
Amazon S3 具有存储管理功能,可以使用这些功能来管理成本、满足法规要求、减少延迟并保存数据的多个不同副本以满足合规性要求。
生命周期: 配置生命周期策略以管理对象,并在其整个生命周期内经济高效地存储。您可以将对象转换为其他 S3 存储类,也可以使其生命周期结束的对象过期。
对象锁定:可以在固定的时间段内或无限期地阻止删除或覆盖 Amazon S3 对象。可以使用对象锁定来满足需要一次写入多次读取 (WORM) 存储的法规要求,或只是添加另一个保护层来防止对象被更改和删除。
复制: 将对象及其各自的元数据和对象标签复制到同一或不同的 AWS 区域 目标存储桶中的一个或多个目标存储桶,以减少延迟、合规性、安全性和其他使用案例。
分批操作:通过单个 S3 API 请求或在 Amazon S3 控制台中单击几次,大规模管理数十亿个对象。可以使用分批操作来执行诸如复制、调用 AWS Lambda 函数, 和恢复数百万或数十亿对象。
1.4.3 访问管理
Amazon S3 提供了用于审核和管理对存储桶和数据元的访问的功能。默认情况下,S3 存储桶和对象都是私有的。
用户只能访问自己创建的 S3 资源。
如果需要授予支持特定使用案例的细粒度资源权限或审核 Amazon S3 资源的权限,可以使用以下功能。
阻止共有访问:阻止对 S3 存储桶和对象的公有访问。默认情况下,在账户和存储桶级别打开 “阻止公共访问” 设置。
AWS Identity and Access Management (IAM):为 AWS 账户 管理对 Amazon S3 资源的访问。例如,可以将 IAM 用于 Amazon S3,控制用户或用户组对您的 AWS 账户 所拥有 S3 存储桶的访问类型。
存储桶策略:使用基于 IAM 的策略语言为 S3 存储桶及其中的对象配置基于资源的权限。
Amazon S3 访问点:使用专用访问策略配置命名网络终端节点,以便大规模管理对 Amazon S3 中共享数据集的访问。
访问控制列表 (ACL) :向授权用户授予单个存储桶和对象的读写权限。作为一般规则,建议使用基于 S3 资源的策略(存储桶策略和访问点策略)或 IAM 策略进行访问控制,而不是 ACL。ACL 是一种访问控制机制,早于基于资源的策略和 IAM。
(S3 对象所有权): 禁用 ACL 并获取存储桶中每个对象的所有权,从而简化了对存储在 Amazon S3 中的数据的访问管理。作为存储桶所有者,会自动拥有并完全控制桶中的每个对象,并且数据的访问控制是基于策略而进行。
S3 访问分析器:评估和监控S3 存储桶访问策略,确保这些策略仅提供对 S3 资源的预期访问。
2 使用方法
2.1 创建存储桶
先找到S3
进入S3控制台,点击创建存储桶

根据业务,设置不同的参数 然后点击创建,即可创建一个简单的存储桶
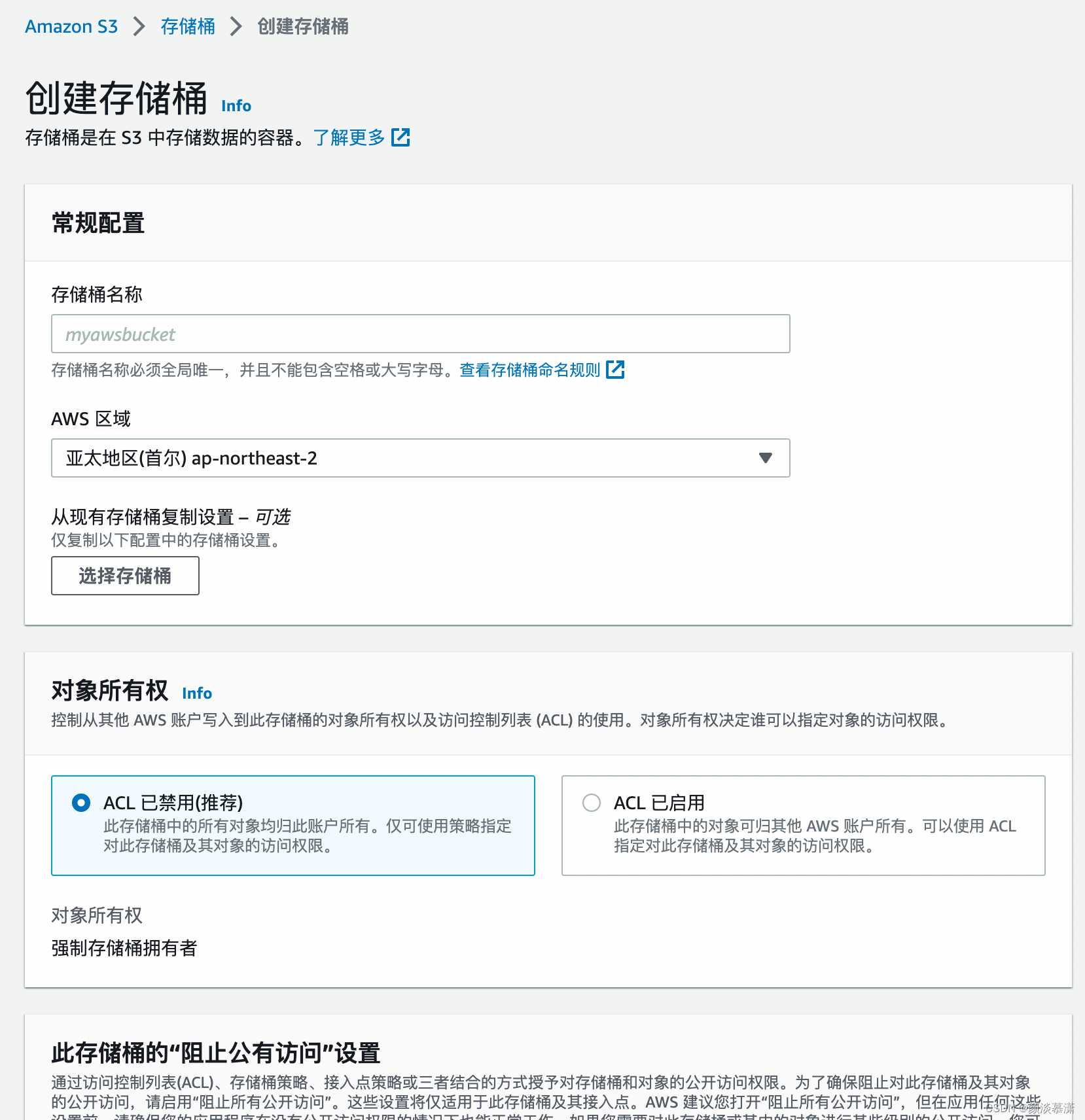
 2.2 配置 CORS 规则
2.2 配置 CORS 规则
以下代码示例显示如何向 S3 桶添加跨源资源共享 (CORS) 规则。示例为Java
其他的学习。可以查阅github
- public static void deleteBucketCorsInformation(S3Client s3, String bucketName, String accountId) {
- try {
- DeleteBucketCorsRequest bucketCorsRequest = DeleteBucketCorsRequest.builder()
- .bucket(bucketName)
- .expectedBucketOwner(accountId)
- .build();
-
- s3.deleteBucketCors(bucketCorsRequest) ;
-
- } catch (S3Exception e) {
- System.err.println(e.awsErrorDetails().errorMessage());
- System.exit(1);
- }
- }
-
- public static void getBucketCorsInformation(S3Client s3, String bucketName, String accountId) {
-
- try {
- GetBucketCorsRequest bucketCorsRequest = GetBucketCorsRequest.builder()
- .bucket(bucketName)
- .expectedBucketOwner(accountId)
- .build();
-
- GetBucketCorsResponse corsResponse = s3.getBucketCors(bucketCorsRequest);
- List<CORSRule> corsRules = corsResponse.corsRules();
- for (CORSRule rule: corsRules) {
- System.out.println("allowOrigins: "+rule.allowedOrigins());
- System.out.println("AllowedMethod: "+rule.allowedMethods());
- }
-
- } catch (S3Exception e) {
-
- System.err.println(e.awsErrorDetails().errorMessage());
- System.exit(1);
- }
- }
-
- public static void setCorsInformation(S3Client s3, String bucketName, String accountId) {
-
- List<String> allowMethods = new ArrayList<>();
- allowMethods.add("PUT");
- allowMethods.add("POST");
- allowMethods.add("DELETE");
-
- List<String> allowOrigins = new ArrayList<>();
- allowOrigins.add("http://example.com");
- try {
- // Define CORS rules.
- CORSRule corsRule = CORSRule.builder()
- .allowedMethods(allowMethods)
- .allowedOrigins(allowOrigins)
- .build();
-
- List<CORSRule> corsRules = new ArrayList<>();
- corsRules.add(corsRule);
- CORSConfiguration configuration = CORSConfiguration.builder()
- .corsRules(corsRules)
- .build();
-
- PutBucketCorsRequest putBucketCorsRequest = PutBucketCorsRequest.builder()
- .bucket(bucketName)
- .corsConfiguration(configuration)
- .expectedBucketOwner(accountId)
- .build();
-
- s3.putBucketCors(putBucketCorsRequest);
-
- } catch (S3Exception e) {
- System.err.println(e.awsErrorDetails().errorMessage());
- System.exit(1);
- }
- }
-

