
- 1项目开发-工具-前端开发_前端开发工具项目
- 2小红书-社区搜索部 (NLP、CV算法实习生) 二面面经_cv岗面经
- 3uniapp navigateBack返回上一页携带参数_uni.navigateback携带参数
- 4设计模式简谈_设计模式 shape circle
- 5正点原子嵌入式linux驱动开发——STM32MP1启动详解
- 6大数据分析设计-基于Hadoop运动项目推荐系统_hadoop课程设计
- 7【Android Gradle】之一小时 Gradle及 wrapper 入门_android distribution wrapper
- 8大模型微调选型指南:我的企业需要微调或者训练一个自己的大模型吗?还是RAG更适合我?先说结论:微调duck不必_在通用大模型微调还需要训练吗
- 9【CSAPP】探究BombLab奥秘:Phase_1的解密与实战_sub $0x8,%rsp
- 10【保姆级教程】GPT4.0画画-生成绘本_gpt绘图
Mamba杀入ECCV 2024!最新成果让视频理解更加高效_videomamba
赞
踩
VideoMamba杀入ECCV!
这篇论文提出了一个仅基于状态空间模型(SSM)的高效视频理解架构VideoMamba。
作者通过大量的实验证明了它具备一系列良好的特性,包括 (1) Visual Domain Scalability; (2) Short-term Action Sensitivity; (3) Long-term Video Superiority; (4) Modality Compatibility。这使得VideoMamba在一系列视频benchmark上取得不俗的结果,尤其是长视频benchmark,为未来更全面的视频理解提供了更高效的方案。
论文链接:https://arxiv.org/abs/2403.06977
【Mamba】Mamba从出现就在学术圈引起了广泛关注。Mamba在语言、音频、DNA序列模态上都实现SOTA,在最受关注的语言任务上,Mamba-3B超越同等规模的Transformer,与两倍大的Transformer匹敌。
为了帮助大家全面掌握Mamba的方法并寻找创新点,本文总结了最近两年【Mamba】相关的40篇顶会论文的研究成果,这些论文的文章、来源以及论文的代码都整理好了,希望给大家的学习提供帮助。
需要的同学关注公众号“沃的顶会”
回复“Mamba40”即可全部领取
综述
A Survey on Vision Mamba: Models, Applications and Challenges
首篇Mamba综述来了!本文旨在对视觉曼巴方法进行全面综述。
本文的主要贡献如下:
-
曼巴的形成:本文提供了曼巴和状态空间模型的操作原理的介绍性概述。
-
主干网络:我们提供了几个具有代表性的视觉曼巴骨干网络的详细检查。本分析旨在阐明支撑Visual Mamba框架的核心原则和创新。
-
应用:我们根据不同的模态对曼巴的其他应用进行分类,如图像、视频、点云、多模态数据等。深入探讨了每个类别,以突出曼巴框架如何适应每种模态并使其受益。对于涉及图像的应用,我们进一步将其划分为各种任务,包括但不限于分类、检测和分割。
-
挑战:我们通过分析视觉数据的独特特征、算法的潜在机制以及现实世界应用程序的实际问题,来研究与CV相关的挑战。
-
未来方向:我们探索视觉曼巴的未来研究方向,重点关注数据利用和算法开发方面的潜在进展。
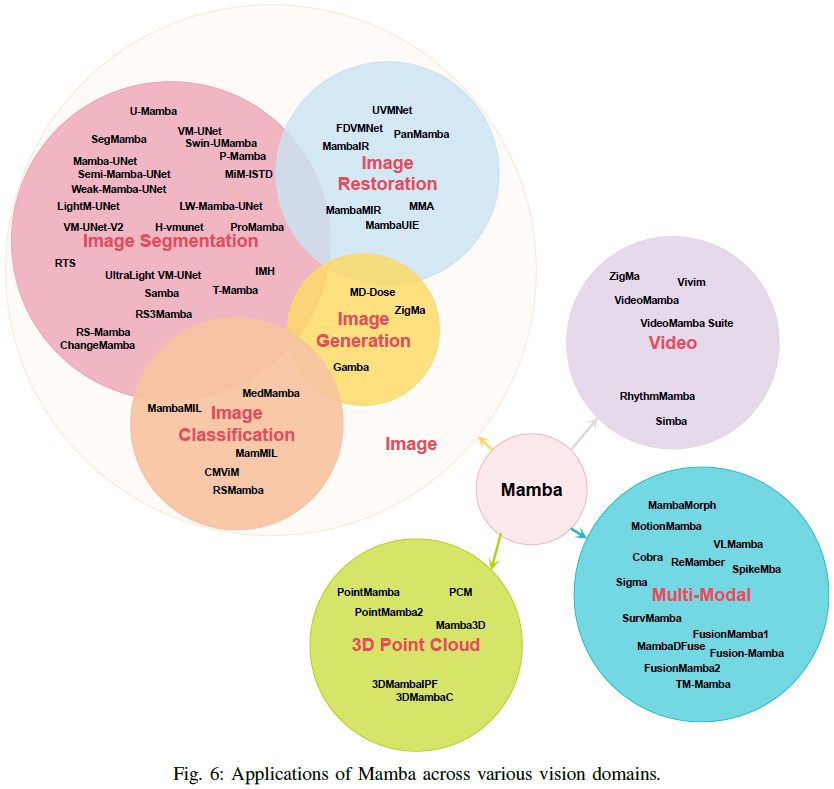
本节系统地对曼巴在计算机视觉领域的各种应用进行了分类和讨论。分类方案以及本次调查中回顾的相关文献概述如图所示。
前沿成果
Mamba: Linear-Time Sequence Modeling with Selective State Spaces
方法:
Mamba模型是一个创新的线性时间序列建模方法,巧妙地结合了递归神经网络(RNN)和卷积神经网络(CNN)的特点,解决了处理长序列时的计算效率问题。它通过状态空间模型(SSM)的框架,实现了RNN的逐步处理能力和CNN的全局信息处理能力的融合。在训练阶段,Mamba使用卷积模式来一次性处理整个输入序列,而在推理阶段则采用递归模式,逐步处理输入,这样的设计使得Mamba既能充分利用CNN的高效并行处理能力,又能保持RNN在序列数据处理上的灵活性。
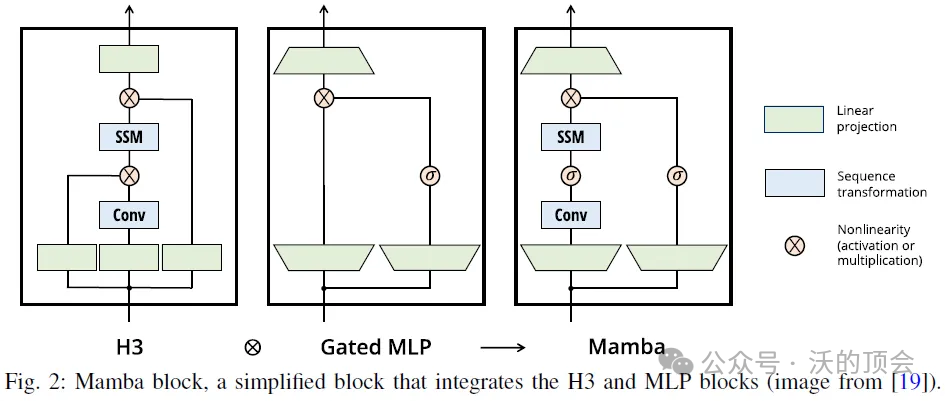
创新点:
1. 引入选择机制(Selection Mechanism): 论文发现之前的标准SSM模型缺乏有效地根据输入选择性地处理信息的能力,这限制了它们在离散数据建模上的表现。作者提出了一种简单但关键的改进,就是让SSM的参数(A, B, C)依赖于当前输入x,从而赋予模型动态选择和过滤信息的能力。
2. 硬件感知的高效算法: 上述选择机制带来了计算效率的挑战,因为标准SSM依赖于时间不变性来实现高效的卷积计算。作者设计了一种基于扫描(scan)的硬件感知算法,在不损失计算效率的情况下解决了这一问题。
3. 简单而统一的架构设计: 作者将选择性SSM与Transformer中的MLP块结合,设计出了一种名为Mamba的新型序列建模架构。Mamba去除了Transformer中的注意力机制和MLP层,具有更简单和统一的结构。
4. 强大的泛化性能: 实验结果显示,Mamba在合成任务、音频建模、基因组建模以及语言建模等多个领域都取得了出色的表现。特别是在语言建模上,Mamba-3B的性能可以与Transformer两倍大小的模型媲美。
需要的同学关注公众号“沃的顶会”
回复“Mamba40”即可全部领取
SegMamba: Long-range Sequential Modeling Mamba For 3D Medical Image Segmentation
方法:
SegMamba主要由三个部分组成:1)具有多个Mamba块的Mamba编码器,用于提取不同尺度的特征;2)基于卷积层的三维解码器,用于预测分割结果;3)跳过连接将多尺度特征连接到解码器,用于特征重用。下图说明了所提出的SegMamba的概述。
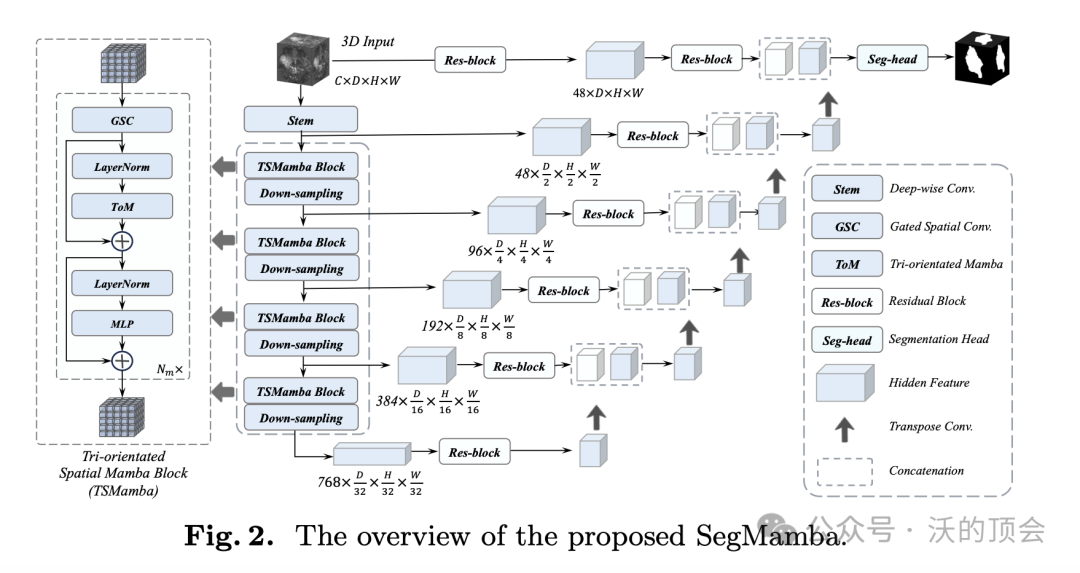
创新点:
-
引入了SegMamba框架,将u形结构与Mamba结合起来,在各种尺度上模拟整个体量的全局特征。
-
是利用Mamba专门用于3D医学图像分割的第一种方法。
-
与传统的基于cnn的和基于transformer的方法相比,SegMamba在体积数据中表现出卓越的远程依赖关系建模能力,同时保持了出色的推理效率。
U-Mamba Enhancing Long-range Dependency for Biomedical Image Segmentation
方法:
U-Mamba遵循编码器-解码器网络结构,以有效的方式捕获本地特征和远程上下文。下图显示了U-Mamba区块的概况和完整的网络结构。
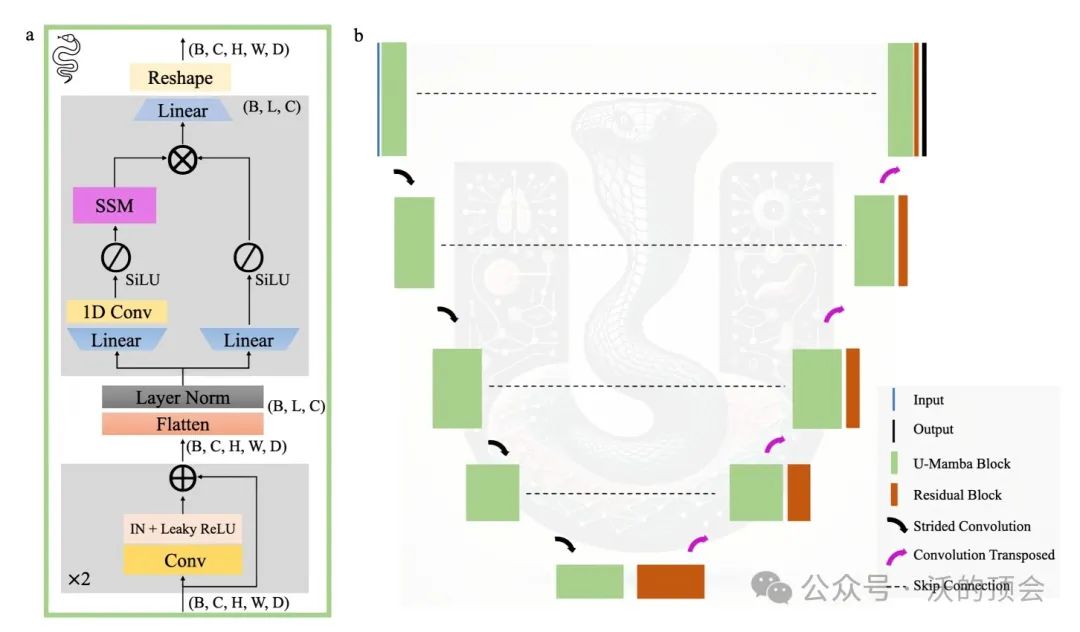
U-Mamba (Enc)架构概述:a,U-Mamba构建块包含两个连续的残余块,后面是基于ssm的Mamba块,用于增强的远程依赖关系建模。b,U-Mamba采用编码器-解码器框架,其中U-Mamba块在编码器中,剩余块在解码器中,以及跳过连接。(注:此图作为概念性表示。)U-Mamba继承了nnU-Net的自配置特性,并且在数据集之间自动确定网络块的数量。
创新点:
1. 设计了U-Mamba网络,引入了混合CNN-SSM (卷积神经网络与状态空间序列模型相结合)模块,能够充分利用CNN在提取局部特征方面的优势,并借鉴SSMs在处理长序列时的强大能力来捕捉长程依赖性。
2. U-Mamba网络实现了自我配置机制,即该网络能够自动适应不同的数据集,不需要手动调整网络结构或超参数,从而增强了泛化能力和实用性。
3. 在广泛的实验证明中,U-Mamba在处理3D腹部器官分割、内窥镜图像中的器械分割以及显微镜图像中的细胞分割等多个生物医学图像分割任务上,均显示出优于当前基于CNN和Transformer的最先进的分割网络的性能,尤其是在处理外观异质性强的物体时,UMamba产生的分割异常值更少,表现更为稳健。
Swin-UMamba:Mamba-based UNet with ImageNet-based pretraining
方法:
我们在图1中展示了Swin-UMamba的整体架构。它主要由三部分组成:1) 基于Mamba的编码器,该编码器在大规模数据集(即ImageNet)上进行预训练,以提取不同尺度的特征;2) 具有多个上采样块的解码器,用于预测分割结果;3) 跳跃连接,用于弥合低级细节和高级语义之间的差距。我们将在以下部分中介绍Swin-UMamba的详细结构。
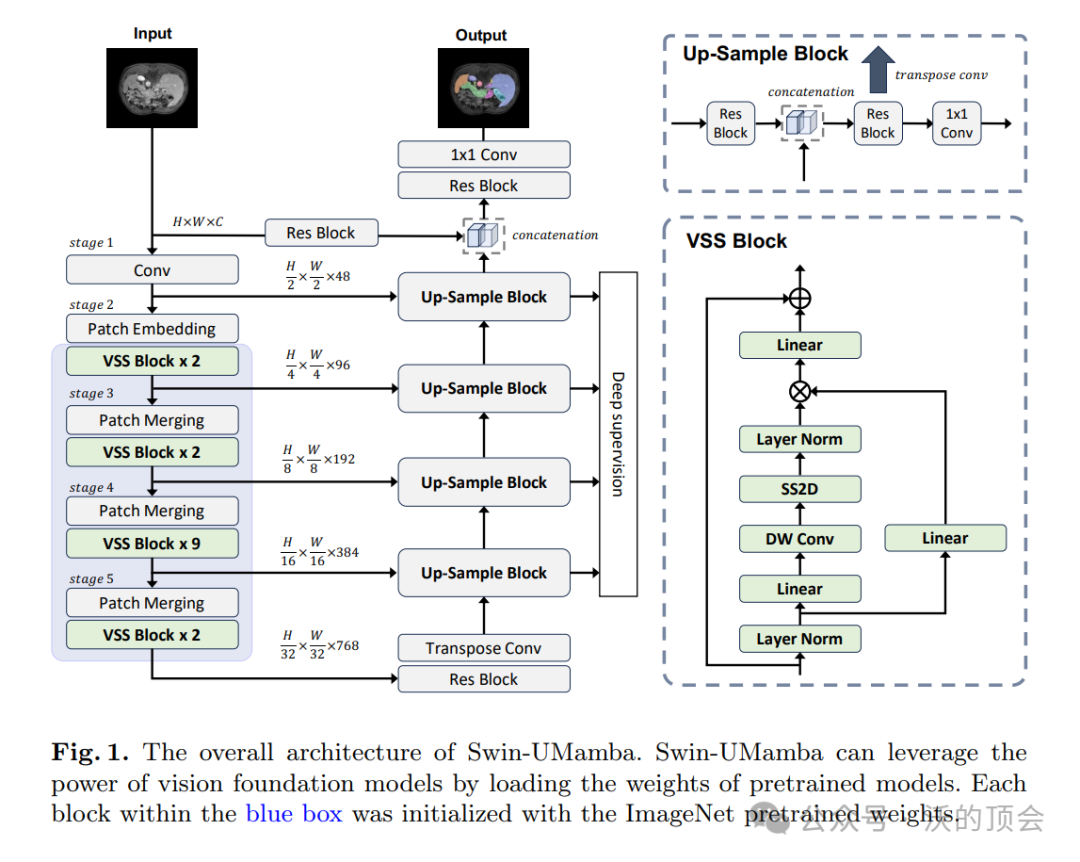
创新点:
1. 相比较于U-Mamba,Swin-UMamba在三种医学图像分割任务指标上可以取得平均3.58%的提升。
2. 该篇工作通过实验验证了ImageNet预训练对基于Mamba的医学图像分割模型起到非常重要的作用,在迭代次数不变的情况下最高可为Swin-UMamba带来13.08%的DSC提升。
3. 提出了一种变体网络Swin-UMamba,其仅需要相比于U-Mamba不到1/2的网络参数量和约1/3的FLOPs就能够实现与Swin-UMamba相近的性能。
需要的同学关注公众号“沃的顶会”
回复“Mamba40”即可全部领取
LightM-UNet: Mamba Assists in Lightweight UNetfor Medical Image Segmentation
方法:
UNet 及其变体已广泛应用于医学图像分割。然而,这些模型,特别是基于 Transformer 架构的模型,由于参数数量大和计算负载大而带来挑战,使其不适合移动健康应用。最近,以 Mamba 为代表的状态空间模型 (SSM) 已成为 CNN 和 Transformer 架构的竞争替代品。在此基础上,我们采用 Mamba 作为 UNet 中 CNN 和 Transformer 的轻量级替代品,旨在解决实际医疗环境中计算资源限制带来的挑战。为此,我们引入了轻量级 Mamba UNet(LightM-UNet),它将 Mamba 和 UNet 集成在一个轻量级框架中。具体来说,LightM-UNet 以纯 Mamba 方式利用残差视觉 Mamba 层来提取深层语义特征并以线性计算复杂度对远程空间依赖性进行建模。
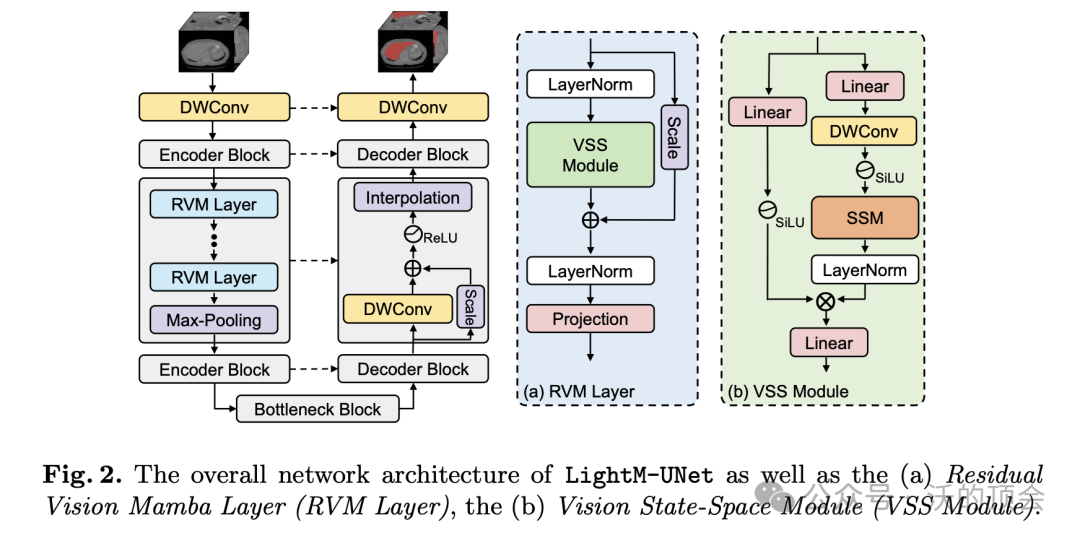
创新点:
1. 引入LightM-UNet,一个由UNet和曼巴组成的轻量级融合体,仅拥有1M的参数计数。通过对二维和三维真实数据集的验证,LightM-UNet超越了现有的最先进的模型。与著名的nnU-Net [8]和同期的UMamba [14]相比,LightM-UNet的参数计数分别减少了116×和224×。
2. 从技术上讲,我们提出了残余视觉曼巴层(RVM层),以纯曼巴的方式从图像中提取深度特征。在最小限度地引入新参数和计算开销的情况下,我们进一步增强了SSM通过利用残差连接和调整因子来建模视觉图像中的长期空间依赖性的能力。
3. 难看的是,与将UNet与曼巴集成的同期努力[14,23,17]相比,我们提倡在UNet中使用曼巴作为CNN和变压器的轻量级替代品,旨在解决真实医疗环境中计算资源限制带来的挑战。
MoE-Mamba: Efficient Selective State Space Models with Mixture of Experts
方法:
尽管 Mamba 的主要底层机制与 Transformer 中使用的注意力机制有很大不同,但 Mamba 仍然保留了 Transformer 模型的层次结构(即块叠加)。例如包含一层或多层的相同块依次堆叠,每一层的输出会被汇聚到残差信息流中再送入到下一个块中,残差流的最终状态随后被用于预测语言建模任务中的下一个token。下图展示了这些架构的细节对比,从左到右分别是vanilla Transformer、MoE-Transformer、Mamba、MoE-Mamba。
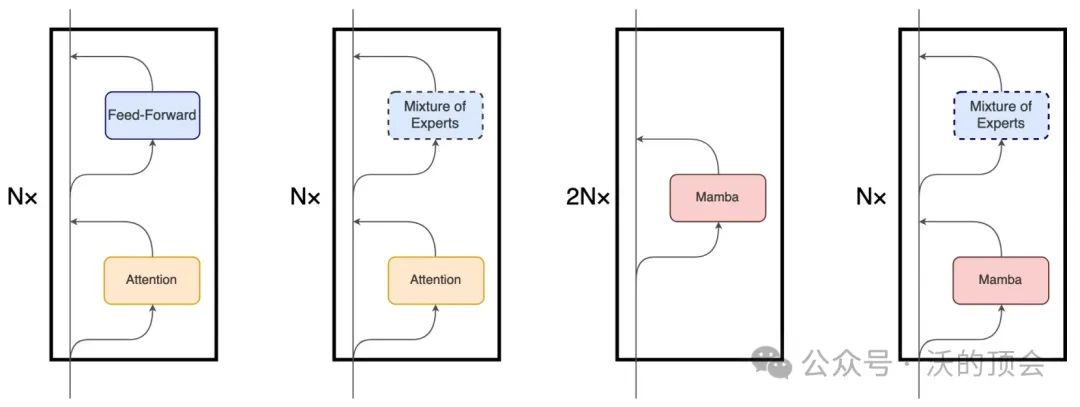
本文提出的MoE-Mamba充分利用了前两种架构的兼容性,例如,在原有Mamba结构的基础上仿照MoE-Transformer将两个mamba块中的其中一个替换成一个可选择的MoE块。这种将mamba层与MoE交错设置的模式可以有效地将序列的整个上下文集成到mamba块的内部表示中,从而将其与MoE层的条件处理分开。
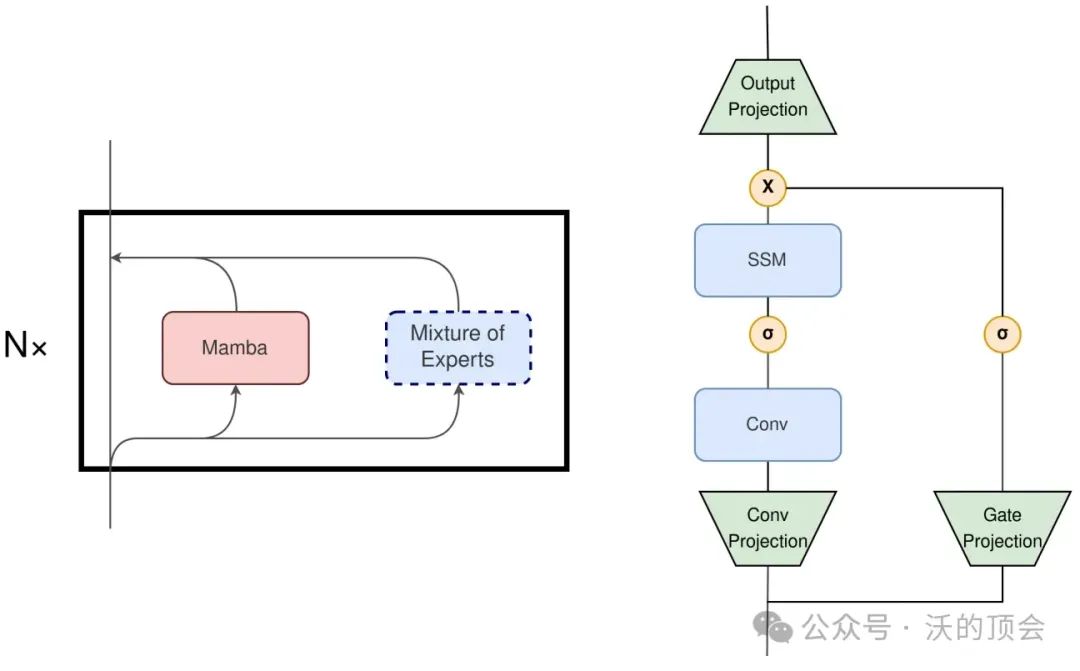
此外,本文作者认为如果将Mamba块和MoE块在局部层的范围内进行并行执行也是一个非常有前景的改进方向,如上图左侧展示了一种并行的Mamba+MoE 架构,右侧展示了Mamba Block的构成。如果将Mamba Block中的输出投影也替换为MoE,模型可以选择更少的模块来匹配当前输入计算的需要,也能实现与原始Mamba架构相当的效果。当然,也可以进一步将MoE替换Conv Projection层来进一步减少计算量。
创新点:
1. 基于并行计算的天然优势,Mamba减轻了大模型中复杂循环顺序性质的影响,并且对硬件进行感知来实现参数扩展。
2. Mamba相比普通注意力机制Transformer解决了序列模型中效率和有效性之间的基本权衡,强调了状态压缩的重要性。
3. 将Mamba与高度稀疏的MoE前馈层交错设置可以实现更高推理效率的LLM,但目前的组合方式仍然非常简单,作者也探索了一种局部并行的Mamba+MoE架构以实现更高的预测准确率和更稀疏的推理效果。
RS-Mamba for Large Remote Sensing Image Dense Prediction
方法:
RSM在语义分割和变化检测任务上的对应模型分别为RSM-SS和RSM-CD。RSM-SS使用简单的U-Net架构,RSM-CD使用简单的孪生网络架构,它们都是遥感密集预测任务中非常常用和简单的架构,不包含任何花哨的模块。
RSM-SS和RSM-CD的encoder都由若干全向状态空间块(Omnidirectional state space block, OSS)构成,OSS的内部结构为类Mamba结构,具有线性复杂度和全局建模能力。而其中的OSSM(Omnidirectional selective scan module)在八个方向上对图像进行选择性扫描,从而能够提取多个方向的大尺度空间特征。
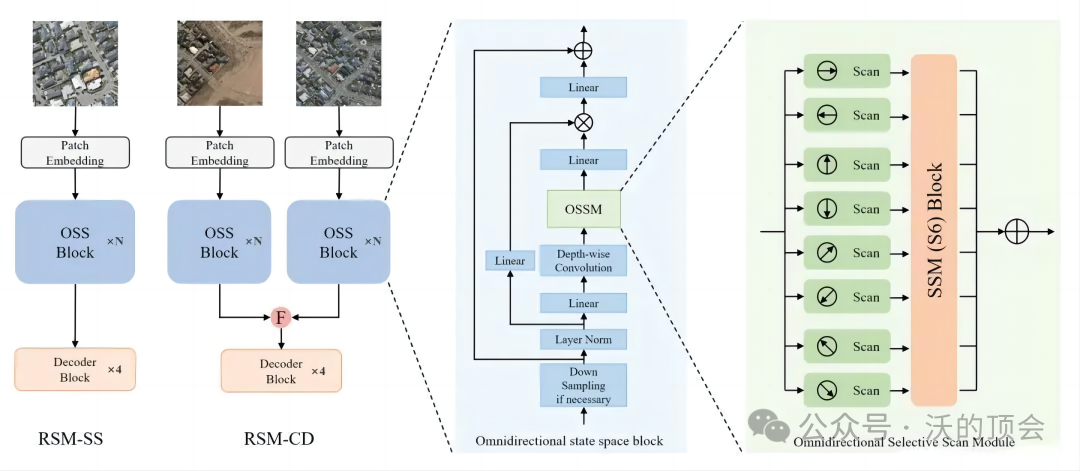
创新点:
1. 提出了Remote Sensing Mamba来处理超高分辨率遥感任务。RSM首次使用SSM来处理超高分辨率遥感图像,它能够处理包含整个物体的超高分辨率遥感图像,并建立起遥感图像的全局联系。
2. 设计了一个Omnidirectional selective scan module提取超高分辨率遥感图像中具有大空间尺度和多个方向的空间特征。OSSM通过在多个方向上使用SSM对遥感图像进行选择性扫描,能够增强遥感图像在多个方向上的全局联系。
3. 证明了RSM在超高分辨率遥感任务中的高效性和优越性。在语义分割数据集WHU-SS和变化检测数据集LEVIR-CD,和WHU-CD上的实验表明,RSM在使用简单的模型架构和训练方法的情况下,在语义分割和变化检测任务上均能够达到SOTA。
需要的同学关注公众号“沃的顶会”
回复“Mamba40”即可全部领取

