
- 1一文搞懂大模型框架:LangChain
- 21、aigc图像相关
- 3C#正则表达式实例
- 4Android Activity启动模式及其区别_简述activity的四种启动模式及其区别。
- 5讯为IMX6UL开发板CAN接口测试学习笔记_flexcan 2090000.can can0: bit-timing not yet defin
- 6node的基础api
- 7GIS+=地理信息+大数据技术——GIS大数据可视化分析工具_gis大数据处理框架
- 8基于WebUploader实现大文件分片上传
- 9用Python发送通知到企业微信,实现消息推送_python 企业微信
- 10FastGPT,知识库AI !保姆级教程,5分钟上手
语音识别中强制对齐_AI语音评测技术简述与应用层级
赞
踩

一、前言
「AI语音评测」技术,指的是针对口语发音水平和差错,进行自动评价、检错并提供指导纠正的技术。
该技术经过几十年的发展,在中英文发音标准程度、口语表达能力等评测任务上已经超越了人类口语评测专家水平,目前该技术被普遍使用在中英文的口语评测和定级中。
接下来我们会讨论:
「AI语音评测」技术简述;
「AI语音评测」多维度应用层级。
二、AI语音评测基本技术简述
1. AI语音评基本规则
对于AI语音评测技术,目前相对流行的是基于DNN-HMM的声学模型,获得音素级别的解码结果以及单词和音素级别的强制对齐结果的方法。
音素:根据语音的自然属性划分出来的最小语音单位。
DNN-HMM:深层神经网络-隐藏马尔科夫模型(Deep Neural Network-Hidden Markov Model),是目前相对流行的声学模型。它的出现基本替代了之前的GMM-HMM模型。
简单的说,能够对音素、单词、句子、段落等多个级别的发音情况进行评价和指导反馈;测评维度包括发音准确度(音素/声调)和流利度、语调、断句、完整度等。
使用该技术方法须满足以下条件:
开发前确定针对的评测语种(如英语、日语、德语等);
以评测语种母语者标准语音为蓝本;
针对评测发音特点设计评测维度;
针对学习者母语(如汉语)发音特点定位可能存在的缺陷。
可以得到的结果:
段落、句子、单词、音素多个级别维度的,包括语调、断句、完整度、 流利度等多个方面的指导反馈;
针对各个级别和维度的分项和综合得分。
2. AI语音评测基本原理
1)整体架构
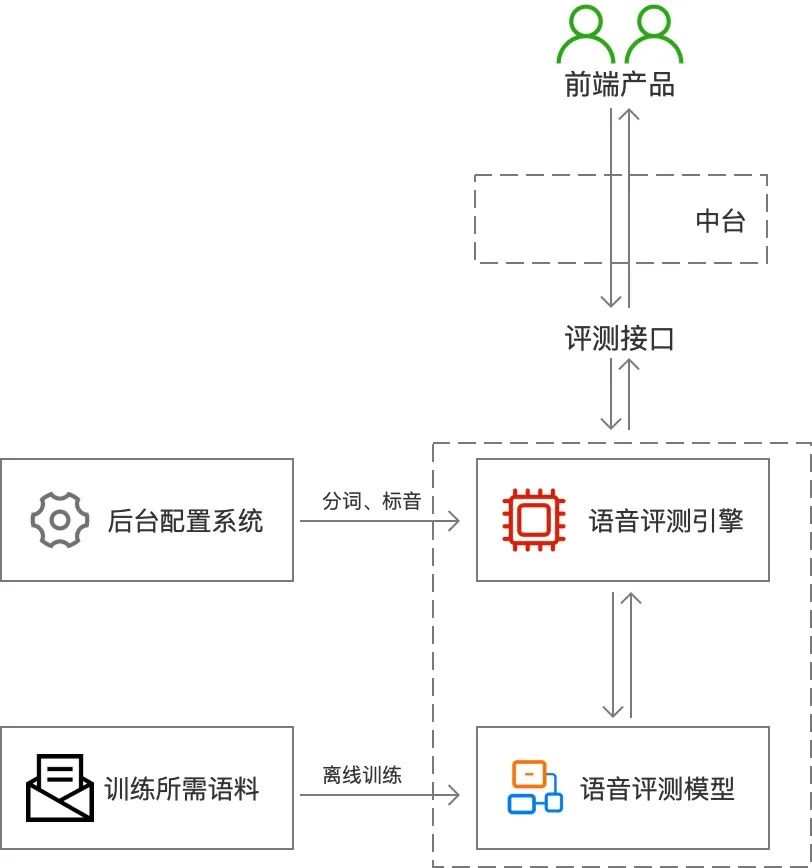
流程:
用户根据给定的文本生成语音;
前端产品通过「评测接口」上传音频至「语音评测引擎」;
引擎以「语音评测模型」为基准,通过解码计算处理得到评测结果;
通过「评测接口」将评测结果返回至用户。
几个概念:
语音评测引擎:AI评测解码和计算的核心模块,通过语音识别(ASR)解码转译,与给定的文本强制对齐,通过不同维度的算法得出指导反馈和评测得分。
后台配置系统:语音评测前,需将给定的文本拆分成独立的单词或单音/音素并存储在后台配置系统中,为语音评测引擎提供对齐标准。
语音评测模型 & 训练所需语料:使用评测引擎前,需使用适量的语料离线训练形成语音评测模型,该模型是引擎进行解码计算处理的依据。
2)语音评测引擎原理
通过对整体架构的解读,我们不难发现很大部分工作都是由「AI评测引擎」完成的,接下来我们再简单了解一下评测引擎内部的流程和原理。

