
YOLOv5和v8实验对比,训练效果,哪个更好呢?_yolov8和yolov5对比
赞
踩
写在最前:实验数据比较
目前更新到v8版本,但是在国产边缘设备部署,厂商给的demo都是v5版本,开发之余比较一下异同。
- 1
本次实验使用的数据集为cub-200鸟类分类数据集,就目前博主最近的实验结果来看(工程角度),X模型训练中呈现出的精确度和召回率基本一致,但收敛速度大相径庭,可以看出v8 100轮就能呈现出一个很好的效果,快了将近一半时间:
200类 train19 yolov8x模型 100轮
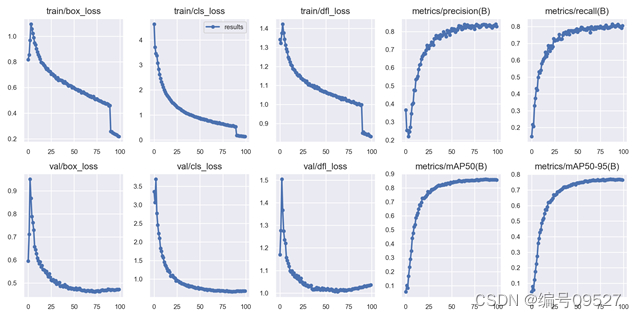
200类 train19 yolov5x 200轮
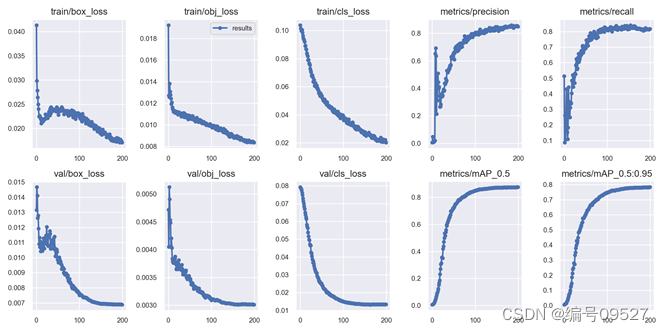
x和l博主进行了多次实验,测试了三种数据集分别为cub-200,ap10k动物目标检测,fish分类检测,效果与以上展示的结果契合,v8的优势就是训练速度更快,更容易收敛。
论文图中真正碾压v5的是n和s模型,追求推理速度和FPS的同时也能有高精度
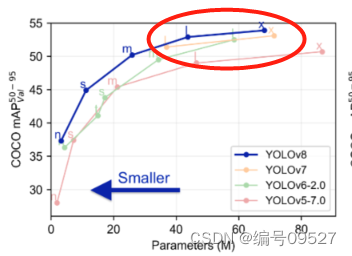
200类 yolov8n,可以看到n模型的精度几乎没有下降,在部署时推理速度极佳
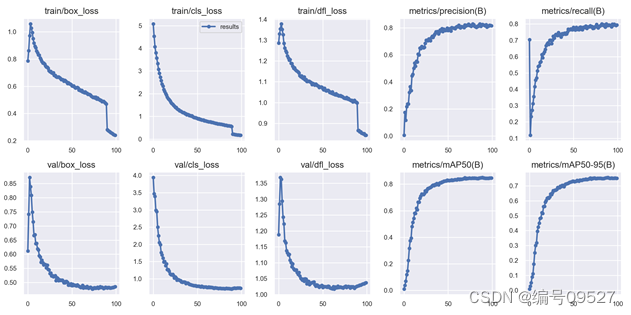
v5优势
v5的目录结构简单,麻雀虽小五脏俱全,训练,检测,导出工程部署模型上手快,开发文档多,前人都把坑踩得差不多了,如果不是特殊需求例如追求极致的FPS或者精度,只需要跟着教程走,百度一下就能满足开发要求。
YOLOv5的边缘端部署
在部署RKNN给出的demo,边缘端部署YOLO,给出了v5版本,博主在部署时量化后达到了150+FPS。
有现成的开发文档,弱鸡必备!

YOLOv5的Web部署
GitHub也有许多Flask的部署方法,但是大多都是老旧版本的v5,可能会报错,结合新版本更改一下文件和方法就能实现部署。博主在web部署v5x模型时也有25+的FPS,大致能实现实时检测。
如果你只想实现功能,不妨多用一下v5
v8优势
v8相比于原始v5,一口气更新了分类,分割,检测,关键点四种任务,几乎能适用所有视觉方向的开发,并且封装的很好,训练与v5略有不同
就实验结果来看,v8超快的训练速度,v5是比不了的,英语不好外国论坛上的帖子很少去看,等国内大佬吧。。
V8目前博主正在尝试部署jetson nano端的边缘设备,GitHub也给出了YOLOv8-TensorRT
的文件,国产芯片的Git没有更新最新款的demo,部署效果待更新。。。

