
Meta发布抽象链,大模型工具利用精度+6%,速度+40%!
赞
踩
在人工智能领域,大型语言模型(LLMs)的发展已经取得了显著进步,特别是在理解和执行指令方面。然而,当涉及到需要调用和组合真实世界知识来生成响应时,这些模型仍然存在错误。例如,它们可能会做出不符合事实的陈述或错误的计算。为了解决这些问题,研究人员提出了使用辅助工具(如搜索引擎提供可靠事实,计算器进行精确数学运算等)来减少这些错误,这激发了集成外部API调用到输出生成中的工具增强型语言模型的发展。
尽管如此,当前的工具增强型LLMs,例如Toolformer,仍然面临在多步推理中可靠和高效利用工具的挑战。特别是在多步推理任务中,工具调用往往是交错的,即一个API调用的响应常常是后续调用的一部分查询。如果不显式地建模这些推理链中的相互连接,LLMs将无法学习有效的工具使用规划,导致使用工具的推理准确性降低。同时,将文本生成与API调用交错也引入了推理效率低下的问题,模型必须等待API调用的响应才能继续解码过程。在多步推理场景中,这种低效率变得更加明显,因为每个推理过程通常需要多轮API调用。
本文提出了一种新的方法,通过训练LLMs学习抽象推理链(CoA),在两个代表性的多步推理领域(数学推理和基于维基百科的问答)上评估了微调模型,并展示了该方法如何提高LLMs的性能,同时提高了工具使用的效率,并通过广泛的人类评估证明了该方法指导LLMs学习更准确的推理。
论文标题:Chain of Abstraction: A New Approach to Align Large Language Models with Real-World Knowledge
论文链接:https://arxiv.org/pdf/2401.17464.pdf
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。
多步推理中的工具调用问题:Toolformer的局限性
在多步推理任务中,大型语言模型(LLMs)需要依靠外部知识(例如网络事实、数学和物理规则)来实现与人类期望相符的推理。辅助工具可以帮助LLMs访问这些外部知识,但是在微调LLMs代理(例如Toolformer)以调用工具时仍然存在挑战。特别是在多步推理问题中,工具调用通常是交错的,即一个API调用的响应常常是后续调用的查询的一部分。如果不显式地建模这些推理链中的相互连接,LLMs将无法学习有效的工具使用规划,导致使用工具的推理准确性降低。同时,将文本生成与API调用交错也会引入低效的推理“等待时间”,模型必须等待API调用的响应才能继续解码过程。在多步推理场景中,这种低效性变得更加显著,因为每个推理过程通常需要多轮API调用。
CoA推理方法介绍
1. CoA推理的定义与目标
CoA(Chain-of-Abstraction)推理是一种新的训练方法,旨在让LLMs学习如何规划抽象的多步推理链。与传统的CoT(Chain-of-Thought)推理相比,CoA推理不生成具体的值,而是生成抽象的占位符,使LLMs能够专注于学习通用和整体的推理策略,而不需要为模型的参数生成特定实例的知识。此外,将通用推理与领域特定知识解耦,使得LLM解码能够在API调用的同时并行处理不同的样本,即LLM可以在工具填充当前链的同时开始生成下一个抽象链,从而加快了整体的推理过程。
2. CoA数据构建与训练过程
为了构建CoA数据进行LLMs的微调,研究者们从现有的开源QA数据集中收集问题回答(QA)样本,并提示LLaMa-70B重写每个样本问题的答案。具体来说,他们提示LLaMa-70B标记出金标准答案中对应于知识操作(例如数学推导、基于维基百科参考的陈述)的跨度,然后将带有标记跨度的句子重写为可填充的CoA痕迹,其中操作结果被替换为抽象占位符。例如,一个数学推导被重写为“[20 + 35 = y1]”和“[90 − y1 = y2]”。通过这种方式,中间结果可能在重写答案中多次出现,例如图2中的数学计算结果55。这种重写方法不仅提高了LLMs在数学和Wiki QA领域的平均准确性,而且还提高了推理效率,使得模型在多步推理任务中更加高效。
实验设计:评估CoA推理方法的有效性
1. 数学推理领域的实验设置
为了评估CoA方法在数学推理领域的有效性,我们采用了一系列开源的数学问题解答数据集,包括GSM8K和ASDiv等。我们使用LLaMa-70B模型,通过提示它将原始答案重写为抽象推理链(CoA),其中具体的数值被抽象占位符替代。例如,原始答案中的数学运算“20 + 35 = 55”被重写为“[20 + 35 = y1]”。这种设计旨在训练模型学习通用的推理策略,而不是生成特定实例的知识。
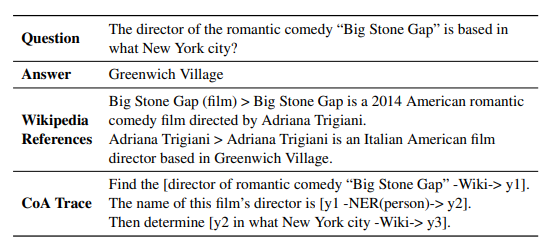
2. Wiki QA领域的实验设置
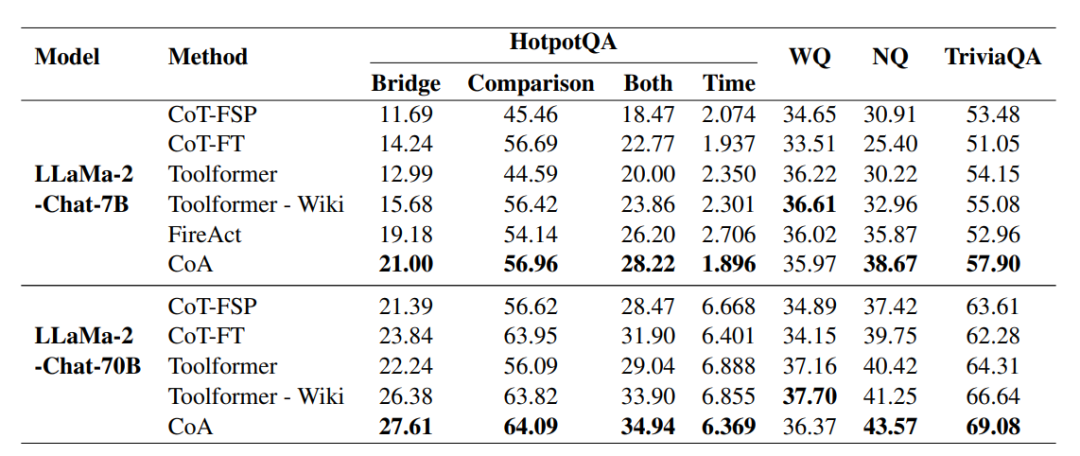
在Wiki QA领域,我们使用HotpotQA数据集构建了细化的CoA数据。HotpotQA包含113K个多跳问答示例,每个示例都标记了提供支持知识的两篇维基百科文章。我们从中选取了Bridge QA和Comparison QA两种类型的问题,分别涉及到识别中间实体以连接问题与答案,以及比较两个实体的属性。我们利用LLaMa-70B模型将这些问题重写为包含WikiSearch和NER查询的CoA链,并通过专门的工具(如维基百科搜索引擎和NER工具包)验证每个CoA的正确性。

实验结果与分析:CoA方法的性能提升
1. 数学推理领域的结果
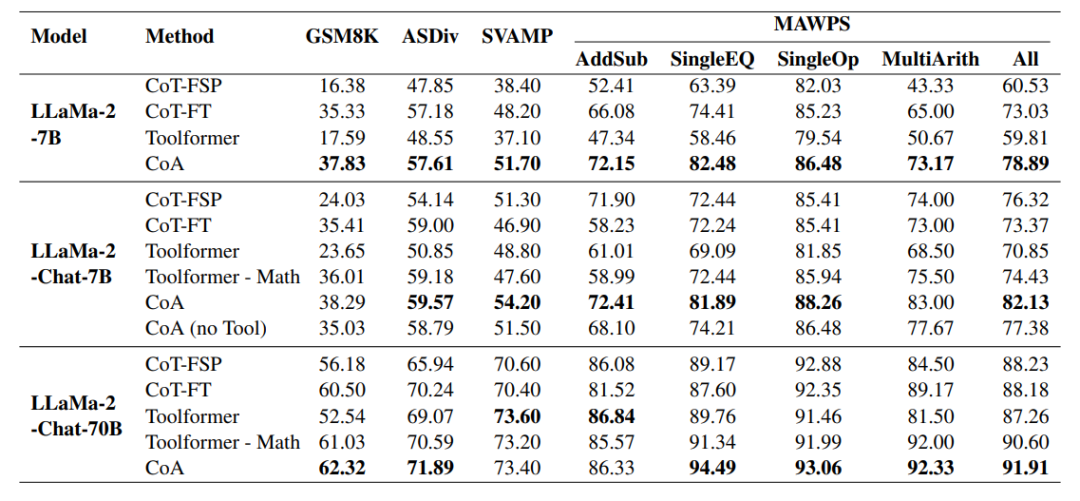
在数学推理领域,CoA方法在GSM8K和ASDiv数据集上的表现超过了几种基线方法,包括CoT-FSP和CoT-FT。CoA方法在SVAMP和MAWPS这两个分布外数据集上的表现尤为突出,显示了其在多步推理任务中的鲁棒性。此外,CoA方法还优于Toolformer,这表明在CoA中规划抽象变量可以提高使用工具进行推理的准确性。人类评估结果显示,CoA方法有效减少了算术错误,并且相比于基线方法,推理错误也有所减少。
2. Wiki QA领域的结果
在Wiki QA领域,CoA方法在HotpotQA数据集上的推理效率超过了Toolformer和FireAct。CoA方法不仅在HotpotQA开发集上取得了显著的性能提升,而且在其他开放域QA数据集上的零样本泛化能力也得到了验证,包括NaturalQuestions和TriviaQA。这些结果表明,CoA方法通过将抽象推理链的生成与知识检索(即工具使用)解耦,实现了更高效的多步推理性能。
CoA方法的推理步骤分析:长链推理的优势
在解决多步推理问题时,大型语言模型(LLMs)需要将推理过程与现实世界知识相结合,例如网络事实、数学和物理规则。为了提高推理的准确性,研究者们提出了链式抽象(CoA)方法,该方法通过引入抽象变量来规划工具的使用,从而提高了模型在多步推理任务中的表现。
1. 链式抽象推理的设计
CoA方法的核心在于将推理过程中的具体知识操作转化为抽象变量。这种设计允许模型专注于学习通用的推理策略,而不需要为模型的参数生成特定实例的知识。例如,在数学问题解答中,CoA方法将具体的数学运算转换为带有抽象占位符的表达式,如将“20 + 35 = 55”重写为“[20 + 35 = y1]”,其中“y1”是一个抽象变量。这样的设计使得模型能够在调用外部API(如计算器)之前,先生成一个完整的抽象推理链。
2. 长链推理的优势
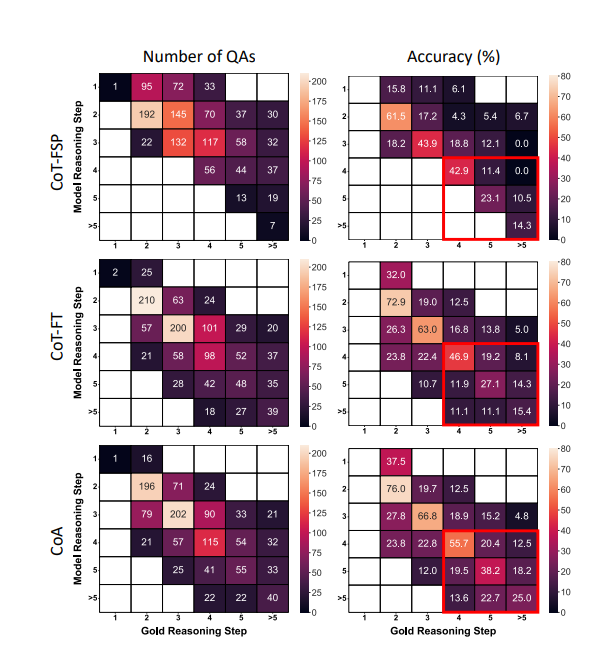
CoA方法在处理需要长链推理的问题时表现出显著的优势。研究发现,当问题需要更多的推理步骤时,CoA方法相比于传统的链式推理(CoT)方法,能够生成与黄金推理链长度更匹配的推理链。这一点在下面的热图统计中得到了体现,其中CoA方法生成的推理链长度更接近对角线,即与黄金推理链的长度更为一致。此外,模型在生成的答案中推理步骤的数量与黄金参考答案一致时,达到了更高的问答准确性。这些结果表明,经过CoA方法训练的模型更擅长产生匹配的推理链。
人类评估:CoA方法的准确性验证
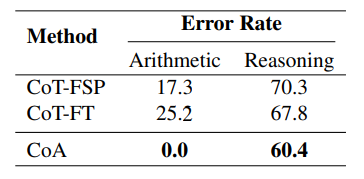
为了全面验证CoA方法提高了知识操作(例如数学运算)和推理准确性,研究者们进行了人类评估。在这项评估中,研究者们随机选取了200个GSM8K测试问题,并让人类工作人员判断模型的答案是否包含任何算术错误(例如错误的计算、无效的方程式)或与数学推导无关的推理错误(例如误解问题、解决问题的不当策略)。
1. 人类评估结果
研究中发现CoA方法有效地将算术错误减少到零,这得益于使用方程求解器进行精确计算。更重要的是,CoA方法相比于基线方法产生的推理错误更少,这验证了CoA方法通过抽象推理链的整体规划指导模型学习了更准确的推理。相比之下,普通的微调(即CoT-FT)相比于少数示例的CoT-FSP,推理改进有限,同时也未能有效抑制算术错误。
2. 推理效率
CoA推理的性能优势并没有带来更高的计算成本。研究展示了CoA和基线方法(以LLaMa-2-Chat-7B为基础)回答问题所需的平均时间(秒)。与CoT基线方法相比,CoA所需的时间少于少数示例基线CoT-FSP,后者的生成需要依赖额外的示例。然而,CoA与CoT-FT相比略微效率低下,这可能是由于解码额外标记(例如“[”和“]”)所致。与Toolformer相比,CoA具有更低和更平坦的推理时间曲线,表明其在推理步骤数量增加时具有更好的扩展性。这种差异产生的原因是CoA将(抽象的)推理链的生成与知识检索(即工具使用)解耦,允许在调用任何工具之前完整地解码推理链。这种过程以两种方式分摊了推理成本:首先,在解码CoA链后进行工具调用,允许对同一链进行并行工具调用(例如,一次使用方程求解器而不是多次调用计算器),并避免了等待外部API响应所导致的时间延迟。其次,在多个示例中,模型可以在为前一个示例进行工具调用的同时生成下一个示例的CoA链,实现了CoA解码和工具调用的并行化。
推理效率:CoA方法的计算成本分析
在探讨大型语言模型(LLMs)进行多步推理时,CoA(Chain of Abstraction)方法的计算成本分析是一个重要的议题。CoA方法旨在通过引入抽象变量来提高推理的准确性,并通过外部工具来实现具体知识的执行。这种方法在数学推理和维基百科问答(Wiki QA)等多步推理领域已经显示出了显著的性能提升。
1. 推理链的生成与工具调用的解耦
CoA方法通过将推理链的生成与工具调用解耦,实现了更高的推理效率。在传统的Toolformer模型中,推理过程中的工具调用是顺序进行的,这导致了在等待API响应时的推理“等待时间”。而CoA方法允许模型在等待工具填充当前链的同时,开始生成下一个抽象推理链,从而加快了整体的推理过程。
2. 推理效率的实证分析
在实证分析中,CoA方法在数学和Wiki QA任务上的推理速度分别比之前的增强方法快约1.47倍和1.33倍。这一结果表明,CoA方法不仅提高了推理的准确性,还显著提升了推理速度。
3. 多步推理场景中的效率
在多步推理场景中,CoA方法的效率尤为突出,可以使大模型工具利用速度提升40%。由于CoA方法在解码抽象推理链之后才进行工具调用,这允许对同一推理链进行并行工具调用,避免了等待外部API响应的时间延迟。此外,CoA方法在处理需要多个推理步骤的问题时,推理时间的增长曲线更为平缓,表明其在推理步骤增加时能够更好地保持效率。
结论与展望
CoA方法通过将LLMs的一般推理能力与执行特定知识的外部工具使用解耦,不仅提高了推理的准确性,还显著提升了多步推理的速度。这种方法的简单而有效的实现在数学推理和开放领域问答等多样化的任务上展示了其潜力,为将来适应新的推理场景提供了可能性。
1. CoA方法的潜力
CoA方法在提高LLMs进行多步推理的准确性和效率方面显示出显著的潜力。通过抽象推理链的规划,CoA方法能够更好地适应分布外知识的变化,并且在不同的推理场景中都表现出了良好的性能。
2. 未来方向
未来的研究可以探索CoA方法在更广泛的应用场景中的潜力,例如在法律、金融或其他需要复杂推理的领域。此外,研究者们可以进一步优化CoA方法的推理效率,减少对外部工具调用的依赖,从而实现更快速的推理过程。
3. 对未来LLMs的启示
CoA方法为未来LLMs的发展提供了新的视角,即通过抽象推理链的规划和外部工具的有效利用,可以提高模型的推理性能。这为设计更智能、更高效的LLMs提供了重要的指导,有望推动人工智能在多步推理任务中的应用和发展。
声明:本期论文解读非人类撰写,全文由赛博马良「AI论文解读达人」智能体自主完成,经人工审核、配图后发布。
公众号「夕小瑶科技说」后台回复“智能体内测”获取智能体内测邀请链接。


